前言
在Vue3.5版本中最大的改动就是
响应式重构
,重构后性能竟然炸裂的提升了
56%
。之所以重构后的响应式性能提升幅度有这么大,主要还是归功于:
双向链表
和
版本计数
。这篇文章我们来讲讲使用
双向链表
后,Vue内部是如何实现
依赖收集
和
依赖触发
的。搞懂了这个之后你就能掌握Vue3.5重构后的响应式原理,至于
版本计数
如果大家感兴趣可以在评论区留言,关注的人多了欧阳后面会再写一篇
版本计数
的文章。
关注公众号:【前端欧阳】,给自己一个进阶vue的机会
3.5版本以前的响应式
在Vue3.5以前的响应式中主要有两个角色:
Sub
(订阅者)、
Dep
(依赖)。其中的订阅者有watchEffect、watch、render函数、computed等。依赖有ref、reactive等响应式变量。
举个例子:
<script setup lang="ts">
import { ref, watchEffect } from "vue";
let dummy1, dummy2;
//Dep1
const counter1 = ref(1);
//Dep2
const counter2 = ref(2);
//Sub1
watchEffect(() => {
dummy1 = counter1.value + counter2.value;
console.log("dummy1", dummy1);
});
//Sub2
watchEffect(() => {
dummy2 = counter1.value + counter2.value + 1;
console.log("dummy2", dummy2);
});
counter1.value++;
counter2.value++;
</script>
在上面的两个watchEffect中都会去监听ref响应式变量:
counter1
和
counter2
。
初始化时会分别执行这两个watchEffect中的回调函数,所以就会对里面的响应式变量
counter1
和
counter2
进行
读操作
,所以就会走到响应式变量的get拦截中。
在get拦截中会进行依赖收集(此时的Dep依赖分别是变量
counter1
和
counter2
)。
因为在依赖收集期间是在执行
watchEffect
中的回调函数,所以依赖对应的
Sub订阅者
就是watchEffect。
由于这里有两个watchEffect,所以这里有两个
Sub订阅者
,分别对应这两个watchEffect。
在上面的例子中,watchEffect监听了多个ref变量。也就是说,一个
Sub订阅者
(也就是一个watchEffect)可以订阅多个依赖。
ref响应式变量
counter1
被多个watchEffect给监听。也就是说,一个
Dep依赖
(也就是
counter1
变量)可以被多个订阅者给订阅。
Sub订阅者
和
Dep依赖
他们两的关系是
多对多
的关系!!!
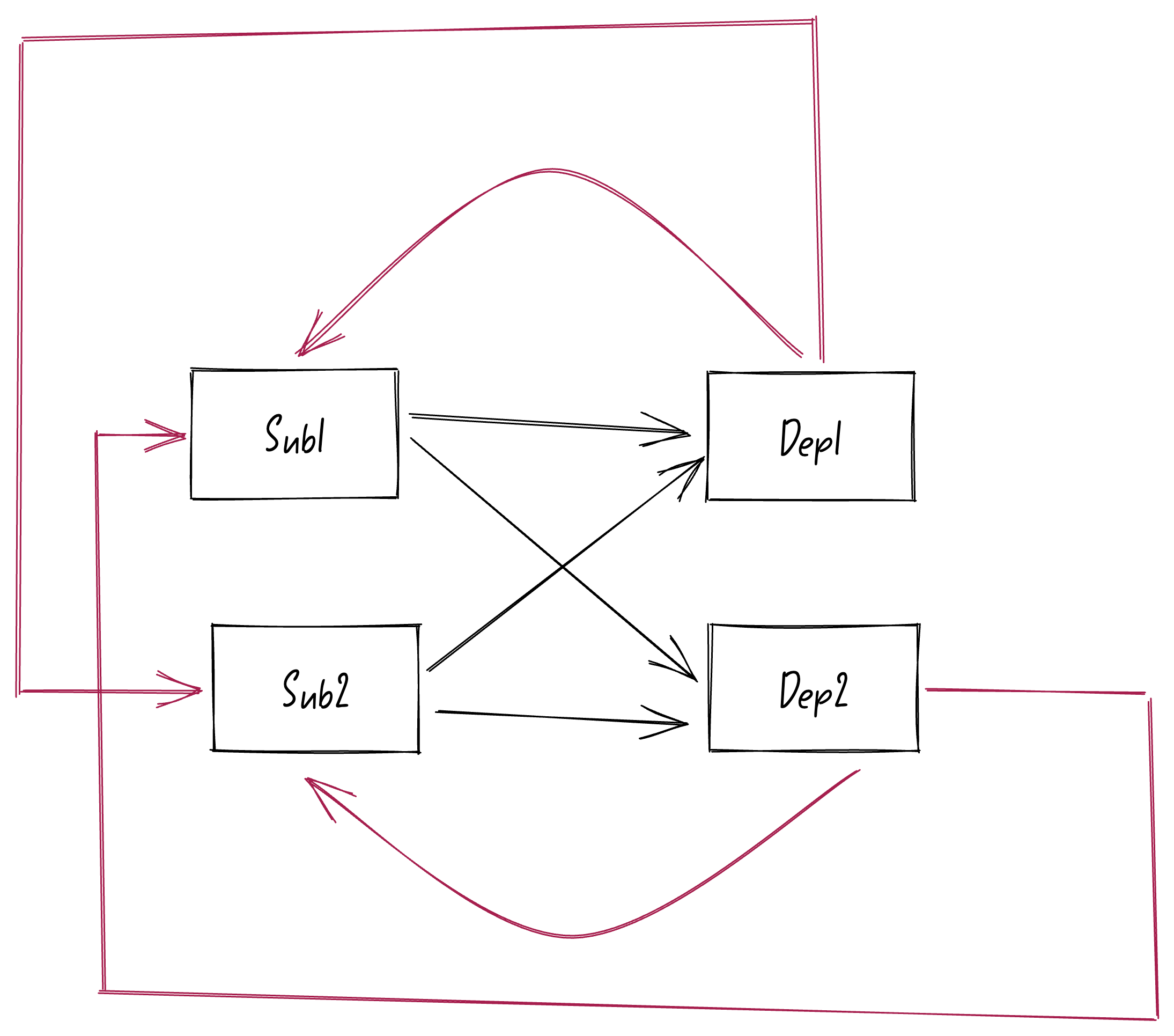
上面这个就是以前的响应式模型。
新的响应式模型
在Vue3.5版本新的响应式中,Sub订阅者和Dep依赖之间不再有直接的联系,而是新增了一个Link作为桥梁。Sub订阅者通过Link访问到Dep依赖,同理Dep依赖也是通过Link访问到Sub订阅者。如下图:
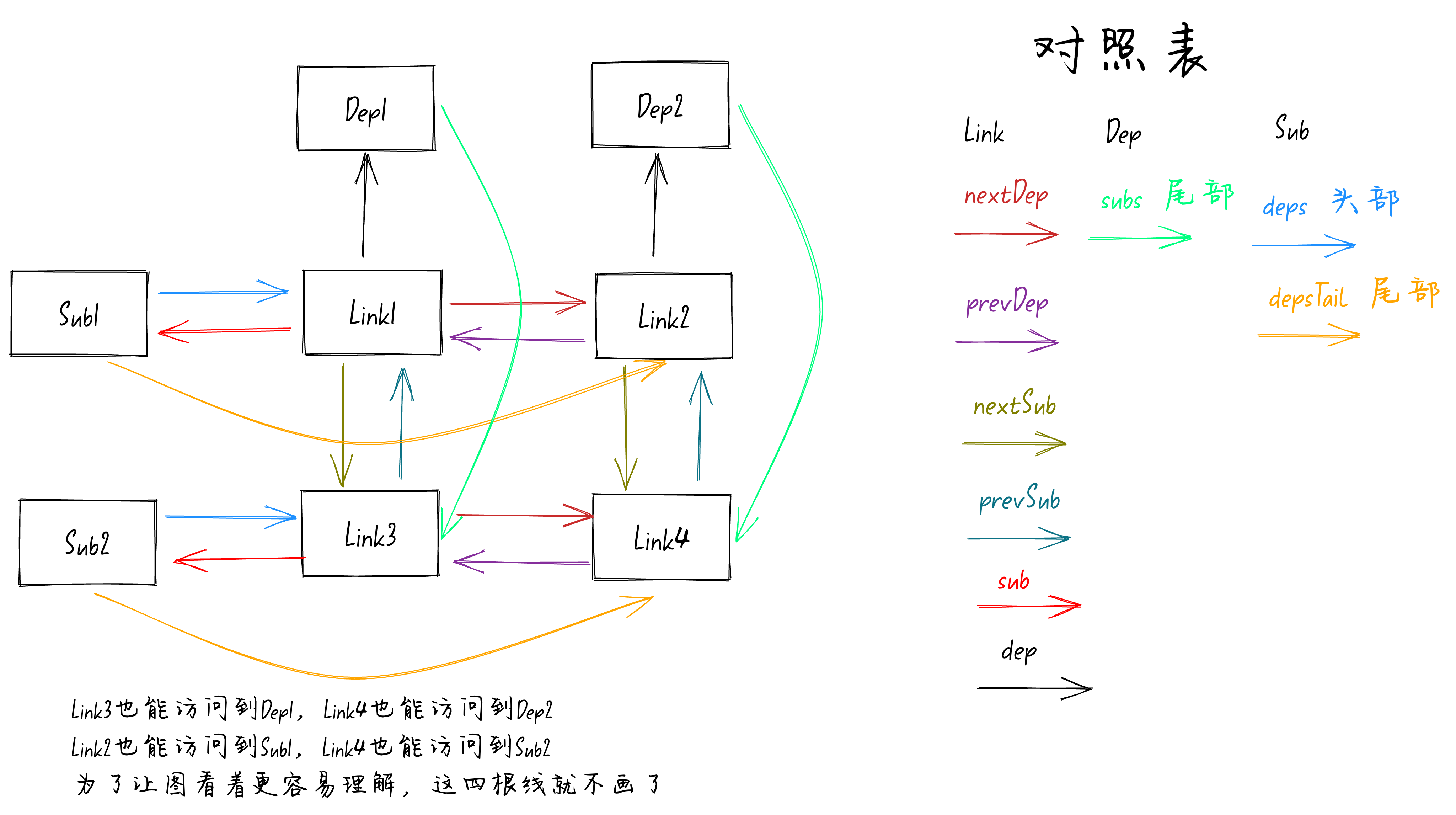
把上面这个图看懂了,你就能理解Vue新的响应式系统啦。现在你直接看这个图有可能看不懂,没关系,等我讲完后你就能看懂了。
首先从上图中可以看到Sub订阅者和Dep依赖之间没有任何直接的连接关系了,也就是说Sub订阅者不能直接访问到Dep依赖,Dep依赖也不能直接访问Sub订阅者。
Dep依赖我们可以看作是X轴,Sub订阅者可以看作是Y轴,这些Link就是坐标轴上面的坐标。
Vue响应式系统的核心还是没有变,只是多了一个Link,依然还是以前的那一套
依赖收集
和
依赖触发
的流程。
在
依赖收集
的过程中就会画出上面这个图,这个不要急,我接下来会仔细去讲图是如何画出来的。
那么依赖触发的时候又是如何利用上面这种图从而实现触发依赖的呢?我们来看个例子。
上面的这张图其实对应的是我之前举的例子:
<script setup lang="ts">
import { ref, watchEffect } from "vue";
let dummy1, dummy2;
//Dep1
const counter1 = ref(1);
//Dep2
const counter2 = ref(2);
//Sub1
watchEffect(() => {
dummy1 = counter1.value + counter2.value;
console.log("dummy1", dummy1);
});
//Sub2
watchEffect(() => {
dummy2 = counter1.value + counter2.value + 1;
console.log("dummy2", dummy2);
});
counter1.value++;
counter2.value++;
</script>
图中的
Dep1依赖
对应的就是变量
counter1
,
Dep2依赖
对应的就是变量
counter2
。
Sub1订阅者
对应的就是第一个
watchEffect
函数,
Sub2订阅者
对应的就是第二个
watchEffect
函数。
当执行
counter1.value++
时,就会被变量
counter1
(也就是
Dep1依赖
)的set函数拦截。从上图中可以看到
Dep1依赖
有个箭头(对照表中的
sub
属性)指向
Link3
,并且
Link3
也有一个箭头(对照表中的
sub
属性)指向
Sub2
。
前面我们讲过了这个
Sub2
就是对应的第二个
watchEffect
函数,指向
Sub2
后我们就可以执行
Sub2
中的依赖,也就是执行第二个
watchEffect
函数。这就实现了
counter1.value++
变量改变后,重新执行第二个
watchEffect
函数。
执行了第二个
watchEffect
函数后我们发现
Link3
在Y轴上面还有一个箭头(对照表中的
preSub
属性)指向了
Link1
。同理
Link1
也有一个箭头(对照表中的
sub
属性)指向了
Sub1
。
前面我们讲过了这个
Sub1
就是对应的第一个
watchEffect
函数,指向
Sub1
后我们就可以执行
Sub1
中的依赖,也就是执行第一个
watchEffect
函数。这就实现了
counter1.value++
变量改变后,重新执行第一个
watchEffect
函数。
至此我们就实现了
counter1.value++
变量改变后,重新去执行依赖他的两个
watchEffect
函数。
我们此时再来回顾一下我们前面画的新的响应式模型图,如下图:
我们从这张图来总结一下依赖触发的的规则:
响应式变量
Dep1
改变后,首先会指向Y轴(
Sub订阅者
)的
队尾
的Link节点。然后从Link节点可以直接访问到Sub订阅者,访问到订阅者后就可以触发其依赖,这里就是重新执行对应的
watchEffect
函数。
接着就是顺着Y轴的
队尾
向
队头
移动,每移动到一个新的Link节点都可以指向一个新的Dep依赖,在这里触发其依赖就会重新指向对应的
watchEffect
函数。
看到这里有的同学有疑问如果是
Dep2
对应的响应式变量改变后指向
Link4
,那这个
Link4
又是怎么指向
Sub2
的呢?他们中间不是还隔了一个
Link3
吗?
每一个Link节点上面都有一个
sub
属性直接指向Y轴上面的Sub依赖,所以这里的
Link4
有个箭头(对照表中的
sub
属性)可以直接指向
Sub2
,然后进行依赖触发。
这就是Vue3.5版本使用
双向链表
改进后的依赖触发原理,接下来我们会去讲依赖收集过程中是如何将上面的模型图画出来的。
Dep、Sub和Link
在讲Vue3.5版本依赖收集之前,我们先来了解一下新的响应式系统中主要的三个角色:
Dep依赖
、
Sub订阅者
、
Link节点
。
这三个角色其实都是class类,依赖收集和依赖触发的过程中实际就是在操作这些类new出来的的对象。
我们接下来看看这些类中有哪些属性和方法,其实在前面的响应式模型图中我们已经使用箭头标明了这些类上面的属性。
Dep依赖
简化后的
Dep
类定义如下:
class Dep {
// 指向Link链表的尾部节点
subs: Link
// 收集依赖
track: Function
// 触发依赖
trigger: Function
}
Dep依赖上面的
subs
属性就是指向队列的
尾部
,也就是队列中最后一个Sub订阅者对应的Link节点。
比如这里的
Dep1
,竖向的
Link1
和
Link3
就组成了一个队列。其中
Link3
是队列的队尾,
Dep1
的
subs
属性就是指向
Link3
。
其次就是
track
函数,对响应式变量进行读操作时会触发。触发这个函数后会进行依赖收集,后面我会讲。
同样
trigger
函数用于依赖触发,对响应式变量进行写操作时会触发,后面我也会讲。
Sub订阅者
简化后的
Sub
订阅者定义如下:
interface Subscriber {
// 指向Link链表的头部节点
deps: Link
// 指向Link链表的尾部节点
depsTail: Link
// 执行依赖
notify: Function
}
想必细心的你发现了这里的
Subscriber
是一个
interface
接口,而不是一个class类。因为实现了这个
Subscriber
接口的class类都是订阅者,比如watchEffect、watch、render函数、computed等。
比如这里的
Sub1
,横向的
Link1
和
Link2
就组成一个队列。其中的队尾就是
Link2
(
depsTail
属性),队头就是
Link1
(
deps
属性)。
还有就是
notify
函数,执行这个函数就是在执行依赖。比如对于watchEffect来说,执行
notify
函数后就会执行watchEffect的回调函数。
Link节点
简化后的
Link
节点类定义如下:
class Link {
// 指向Subscriber订阅者
sub: Subscriber
// 指向Dep依赖
dep: Dep
// 指向Link链表的后一个节点(X轴)
nextDep: Link
// 指向Link链表的前一个节点(X轴)
prevDep: Link
// 指向Link链表的下一个节点(Y轴)
nextSub: Link
// 指向Link链表的上一个节点(Y轴)
prevSub: Link
}
前面我们讲过了新的响应式模型中
Dep依赖
和
Sub订阅者
之间不会再有直接的关联,而是通过Link作为桥梁。
那么作为桥梁的Link节点肯定需要有两个属性能够让他直接访问到
Dep依赖
和
Sub订阅者
,也就是
sub
和
dep
属性。
其中的
sub
属性是指向
Sub订阅者
,
dep
属性是指向
Dep依赖
。
我们知道Link是坐标轴的点,那这个点肯定就会有上、下、左、右四个方向。
比如对于
Link1
可以使用
nextDep
属性来访问后面这个节点
Link2
,
Link2
可以使用
prevDep
属性来访问前面这个节点
Link1
。
请注意,这里名字虽然叫
nextDep
和
prevDep
,但是他们指向的却是Link节点。然后通过这个Link节点的
dep
属性,就可以访问到后一个
Dep依赖
或者前一个
Dep依赖
。
同理对于
Link1
可以使用
nextSub
访问后面这个节点
Link3
,
Link3
可以使用
prevSub
访问前面这个节点
Link1
。
同样的这里名字虽然叫
nextSub
和
prevSub
,但是他们指向的却是Link节点。然后通过这个Link节点的
sub
属性,就可以访问到下一个
Sub订阅者
或者上一个
Sub订阅者
。
如何收集依赖
搞清楚了新的响应式模型中的三个角色:
Dep依赖
、
Sub订阅者
、
Link节点
,我们现在就可以开始搞清楚新的响应式模型是如何收集依赖的。
接下来我将会带你如何一步步的画出前面讲的那张新的响应式模型图。
还是我们前面的那个例子,代码如下:
<script setup lang="ts">
import { ref, watchEffect } from "vue";
let dummy1, dummy2;
//Dep1
const counter1 = ref(1);
//Dep2
const counter2 = ref(2);
//Sub1
watchEffect(() => {
dummy1 = counter1.value + counter2.value;
console.log("dummy1", dummy1);
});
//Sub2
watchEffect(() => {
dummy2 = counter1.value + counter2.value + 1;
console.log("dummy2", dummy2);
});
counter1.value++;
counter2.value++;
</script>
大家都知道响应式变量有
get
和
set
拦截,当对变量进行读操作时会走到
get
拦截中,进行写操作时会走到
set
拦截中。
上面的例子第一个
watchEffect
我们叫做
Sub1
订阅者,第二个
watchEffect
叫做
Sub2
订阅者.
初始化时
watchEffect
中的回调会执行一次,这里有两个
watchEffect
,会依次去执行。
在Vue内部有个全局变量叫
activeSub
,里面存的是当前active的Sub订阅者。
执行第一个
watchEffect
回调时,当前的
activeSub
就是
Sub1
。
在
Sub1
中使用到了响应式变量
counter1
和
counter2
,所以会对这两个变量依次进行读操作。
第一个
watchEffect
对
counter1
进行读操作
先对
counter1
进行读操作时,会走到
get
拦截中。核心代码如下:
class RefImpl {
get value() {
this.dep.track();
return this._value;
}
}
从上面可以看到在get拦截中直接调用了dep依赖的
track
方法进行依赖收集。
在执行
track
方法之前我们思考一下当前响应式系统中有哪些角色,分别是
Sub1
和
Sub2
这两个
watchEffect
回调函数订阅者,以及
counter1
和
counter2
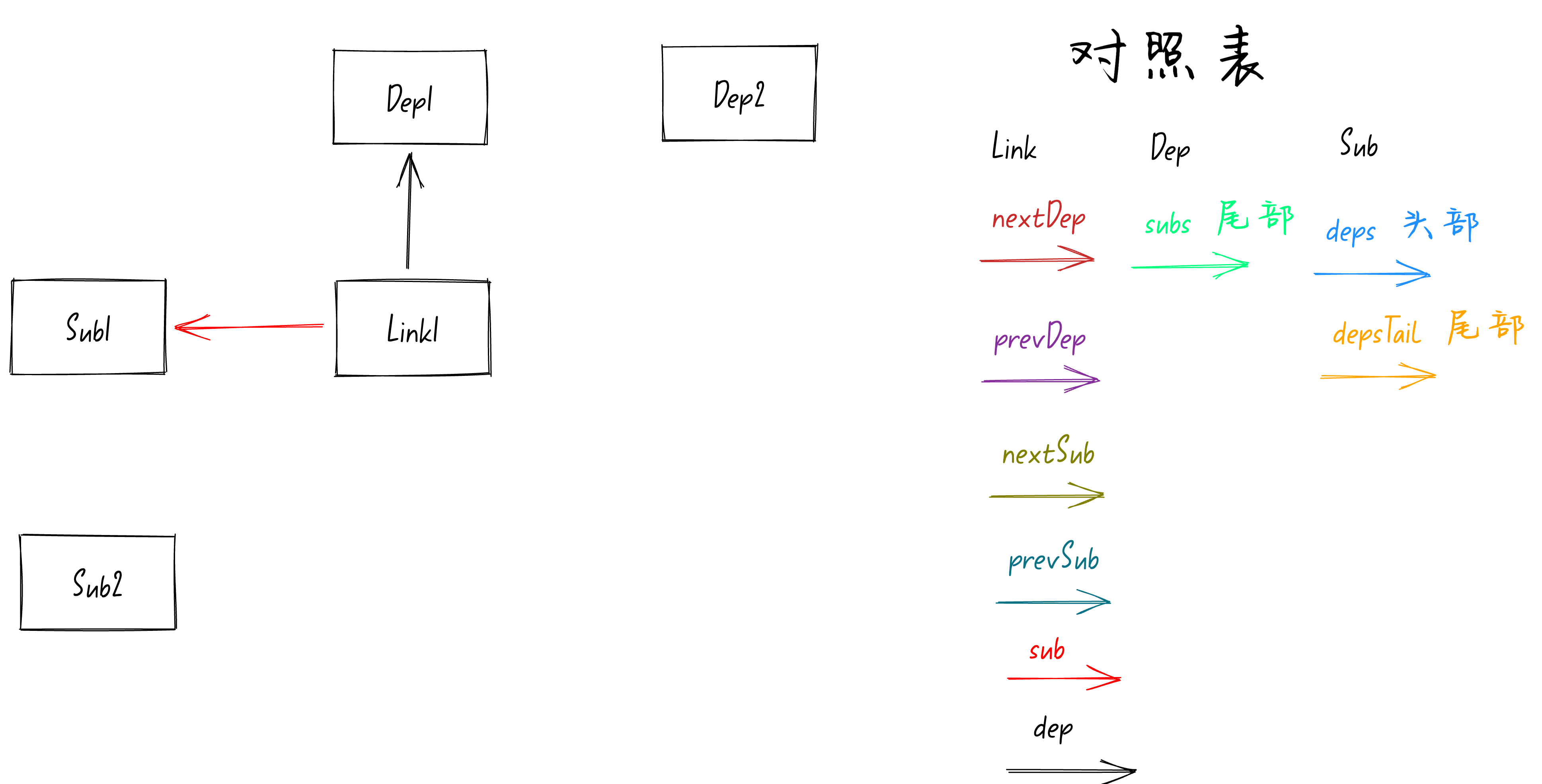
这两个Dep依赖。此时的响应式模型如下图:
从上图可以看到此时只有X坐标轴的Dep依赖,以及Y坐标轴的Sub订阅者,没有一个Link节点。
我们接着来看看dep依赖的
track
方法,核心代码如下:
class Dep {
// 指向Link链表的尾部节点
subs: Link;
track() {
let link = new Link(activeSub, this);
if (!activeSub.deps) {
activeSub.deps = activeSub.depsTail = link;
} else {
link.prevDep = activeSub.depsTail;
activeSub.depsTail!.nextDep = link;
activeSub.depsTail = link;
}
addSub(link);
}
}
从上面的代码可以看到,每执行一次
track
方法,也就是说每次收集依赖,都会执行
new Link
去生成一个Link节点。
并且传入两个参数,
activeSub
为当前active的订阅者,在这里就是
Sub1
(第一个
watchEffect
)。第二个参数为
this
,指向当前的Dep依赖对象,也就是
Dep1
(
counter1
变量)。
先不看
track
后面的代码,我们来看看
Link
这个class的代码,核心代码如下:
class Link {
// 指向Link链表的后一个节点(X轴)
nextDep: Link;
// 指向Link链表的前一个节点(X轴)
prevDep: Link;
// 指向Link链表的下一个节点(Y轴)
nextSub: Link;
// 指向Link链表的上一个节点(Y轴)
prevSub: Link;
- constructor(public sub: Subscriber, public dep: Dep) {
// ...省略
}
}
细心的小伙伴可能发现了在
Link
中没有声明
sub
和
dep
属性,那么为什么前面我们会说Link节点中的
sub
和
dep
属性分别指向Sub订阅者和Dep依赖呢?
因为在constructor构造函数中使用了
public
关键字,所以
sub
和
dep
就作为属性暴露出来了。
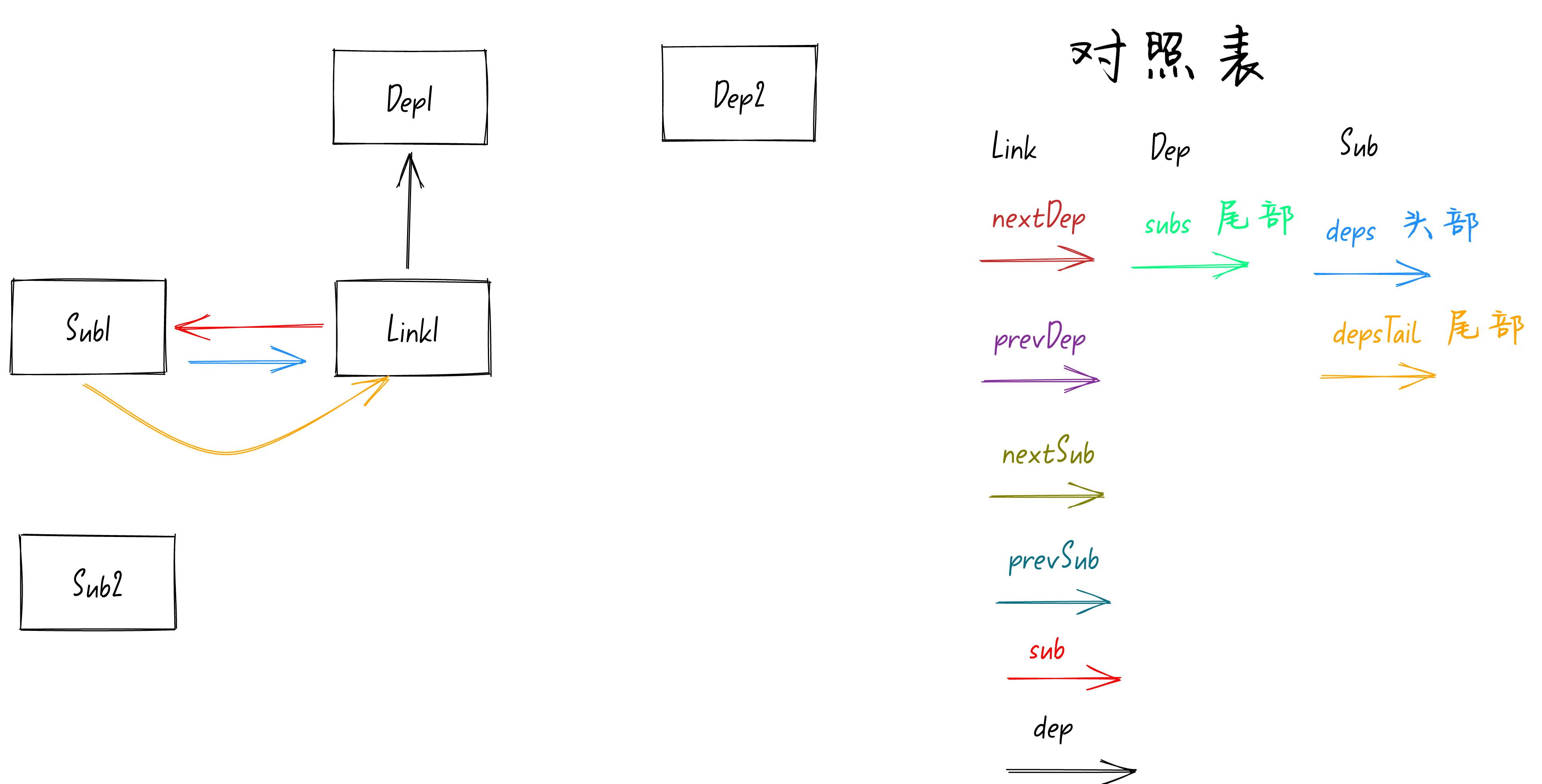
执行完
let link = new Link(activeSub, this)
后,在响应式系统模型中初始化出来第一个Link节点,如下图:
从上图可以看到
Link1
的
sub
属性指向
Sub1
订阅者,
dep
属性指向
Dep1
依赖。
我们接着来看
track
方法中剩下的代码,如下:
class Dep {
// 指向Link链表的尾部节点
subs: Link;
track() {
let link = new Link(activeSub, this);
if (!activeSub.deps) {
activeSub.deps = activeSub.depsTail = link;
} else {
link.prevDep = activeSub.depsTail;
activeSub.depsTail!.nextDep = link;
activeSub.depsTail = link;
}
addSub(link);
}
}
先来看
if (!activeSub.deps)
,
activeSub
前面讲过了是
Sub1
。
activeSub.deps
就是
Sub1
的
deps
属性,也就是
Sub1
队列上的第一个Link。
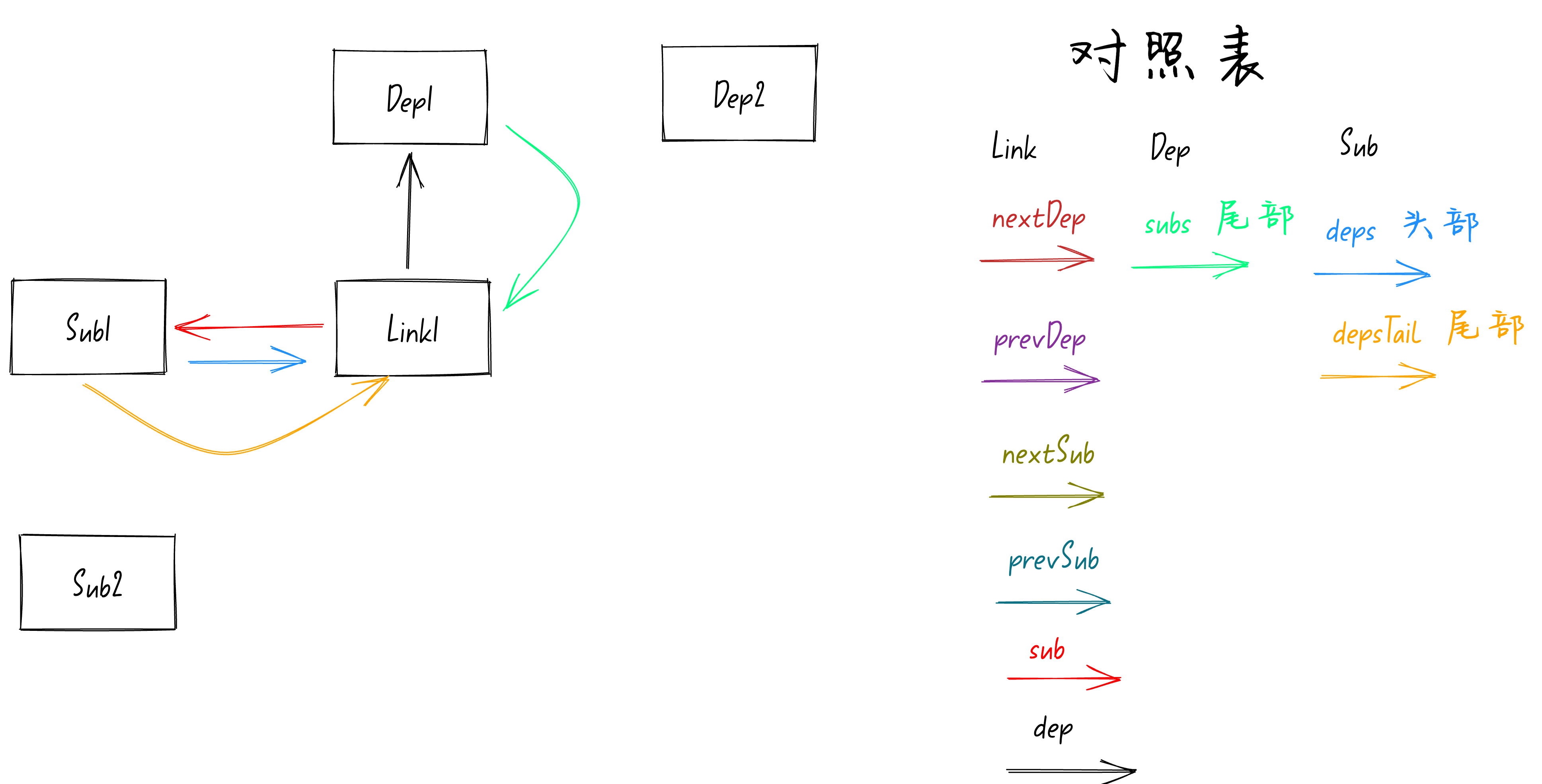
从上图中可以看到此时的
Sub1
并没有箭头指向
Link1
,所以
if (!activeSub.deps)
为true,代码会执行
activeSub.deps = activeSub.depsTail = link;
deps
和
depsTail
属性分别指向
Sub1
队列的头部和尾部,当前队列中只有
Link1
这一个节点,那么头部和尾部当然都指向
Link1
。
执行完这行代码后响应式模型图就变成下面这样的了,如下图:
从上图中可以看到
Sub1
的队列中只有
Link1
这一个节点,所以队列的头部和尾部都指向
Link1
。
处理完
Sub1
的队列,但是
Dep1
的队列还没处理,
Dep1
的队列是由
addSub(link)
函数处理的。
addSub
函数代码如下:
function addSub(link: Link) {
const currentTail = link.dep.subs;
if (currentTail !== link) {
link.prevSub = currentTail;
if (currentTail) currentTail.nextSub = link;
}
link.dep.subs = link;
}
由于
Dep1
队列中没有Link节点,所以此时在
addSub
函数中主要是执行第三块代码:
link.dep.subs = link
。`
link.dep
是指向
Dep1
,前面我们讲过了Dep依赖的
subs
属性指向队列的尾部。所以
link.dep.subs = link
就是将
Link1
指向
Dep1
的队列的尾部,执行完这行代码后响应式模型图就变成下面这样的了,如下图:
到这里对第一个响应式变量
counter1
进行读操作进行的依赖收集就完了。
第一个
watchEffect
对
counter2
进行读操作
在第一个watchEffect中接着会对
counter2
变量进行读操作。同样会走到
get
拦截中,然后执行
track
函数,代码如下:
class Dep {
// 指向Link链表的尾部节点
subs: Link;
track() {
let link = new Link(activeSub, this);
if (!activeSub.deps) {
activeSub.deps = activeSub.depsTail = link;
} else {
link.prevDep = activeSub.depsTail;
activeSub.depsTail!.nextDep = link;
activeSub.depsTail = link;
}
addSub(link);
}
}
同样的会执行一次
new Link(activeSub, this)
,然后把新生成的
Link2
的
sub
和
dep
属性分别指向
Sub1
和
Dep2
。执行后的响应式模型图如下图:
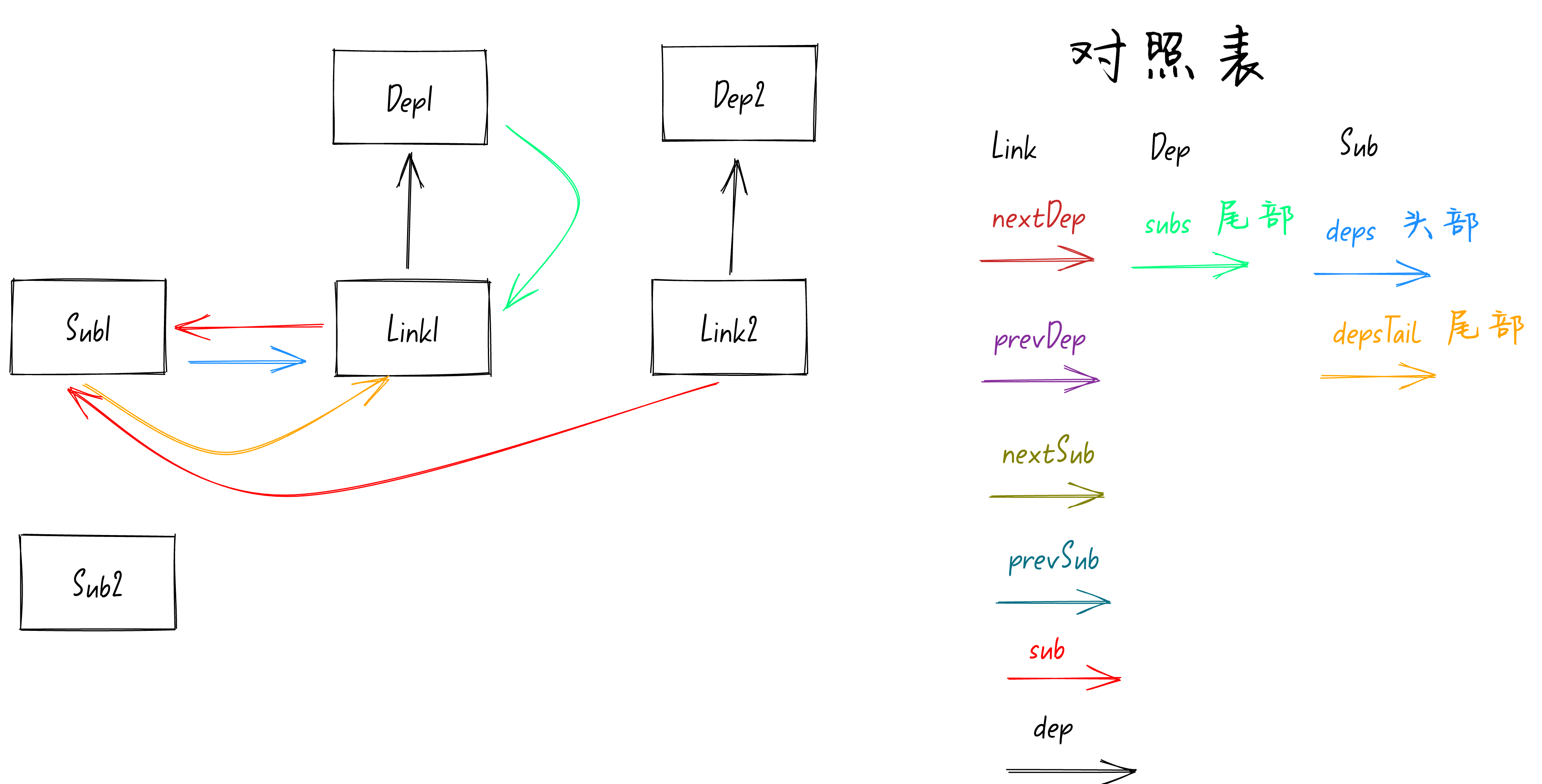
从上面的图中可以看到此时
Sub1
的
deps
属性是指向
Link1
的,所以这次代码会走进
else
模块中。
else
部分代码如下:
link.prevDep = activeSub.depsTail;
activeSub.depsTail.nextDep = link;
activeSub.depsTail = link;
activeSub.depsTail
指向
Sub1
队列尾部的Link,值是
Link1
。所以执行
link.prevDep = activeSub.depsTail
就是将
Link2
的
prevDep
属性指向
Link1
。
同理
activeSub.depsTail.nextDep = link
就是将
Link1
的
nextDep
属性指向
Link2
,执行完这两行代码后
Link1
和
Link2
之间就建立关系了。如下图:
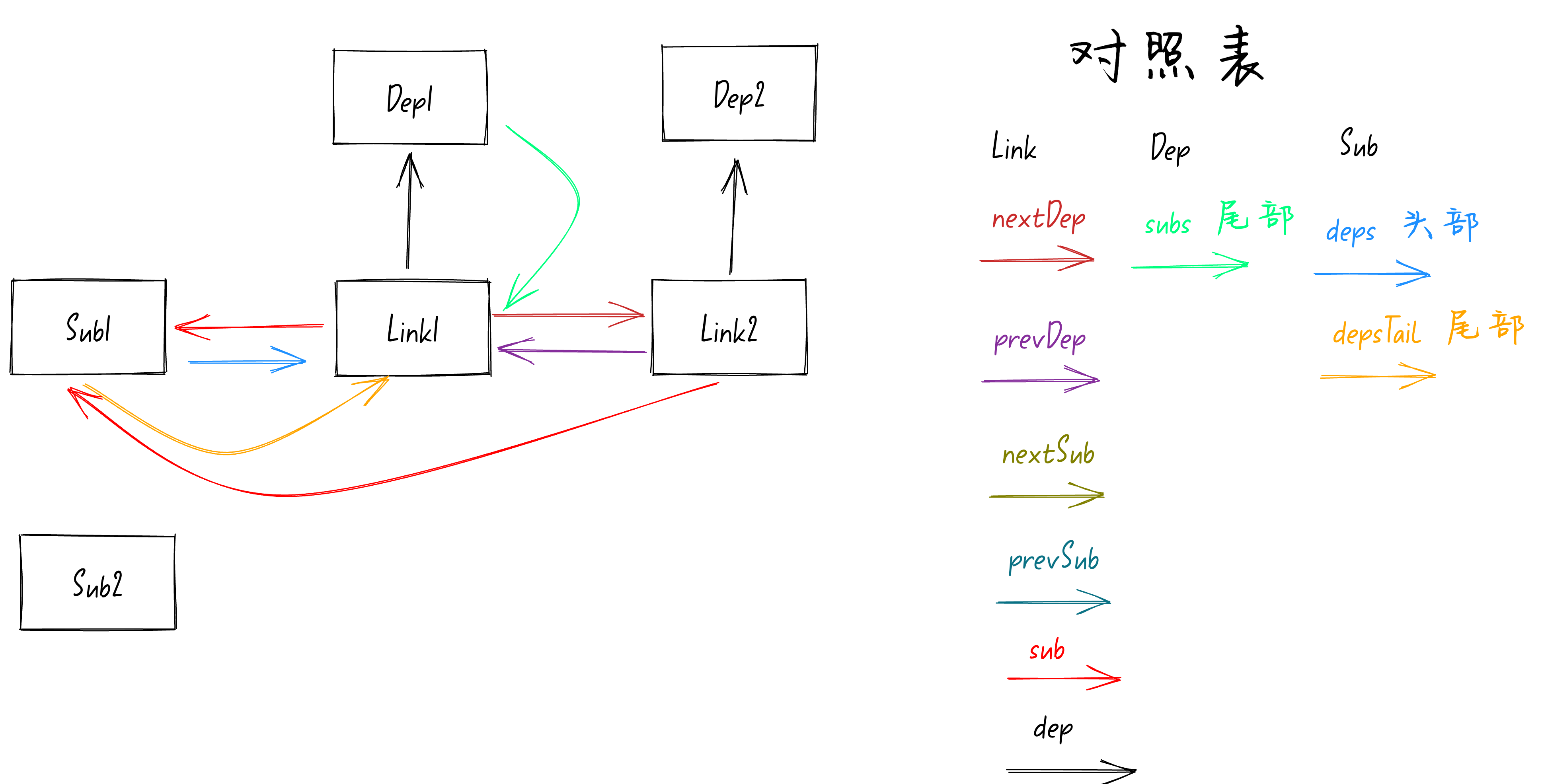
从上图中可以看到此时
Link1
和
Link2
之间就有箭头连接,可以互相访问到对方。
最后就是执行
activeSub.depsTail = link
,这行代码是将
Sub1
队列的尾部指向
Link2
。执行完这行代码后模型图如下:
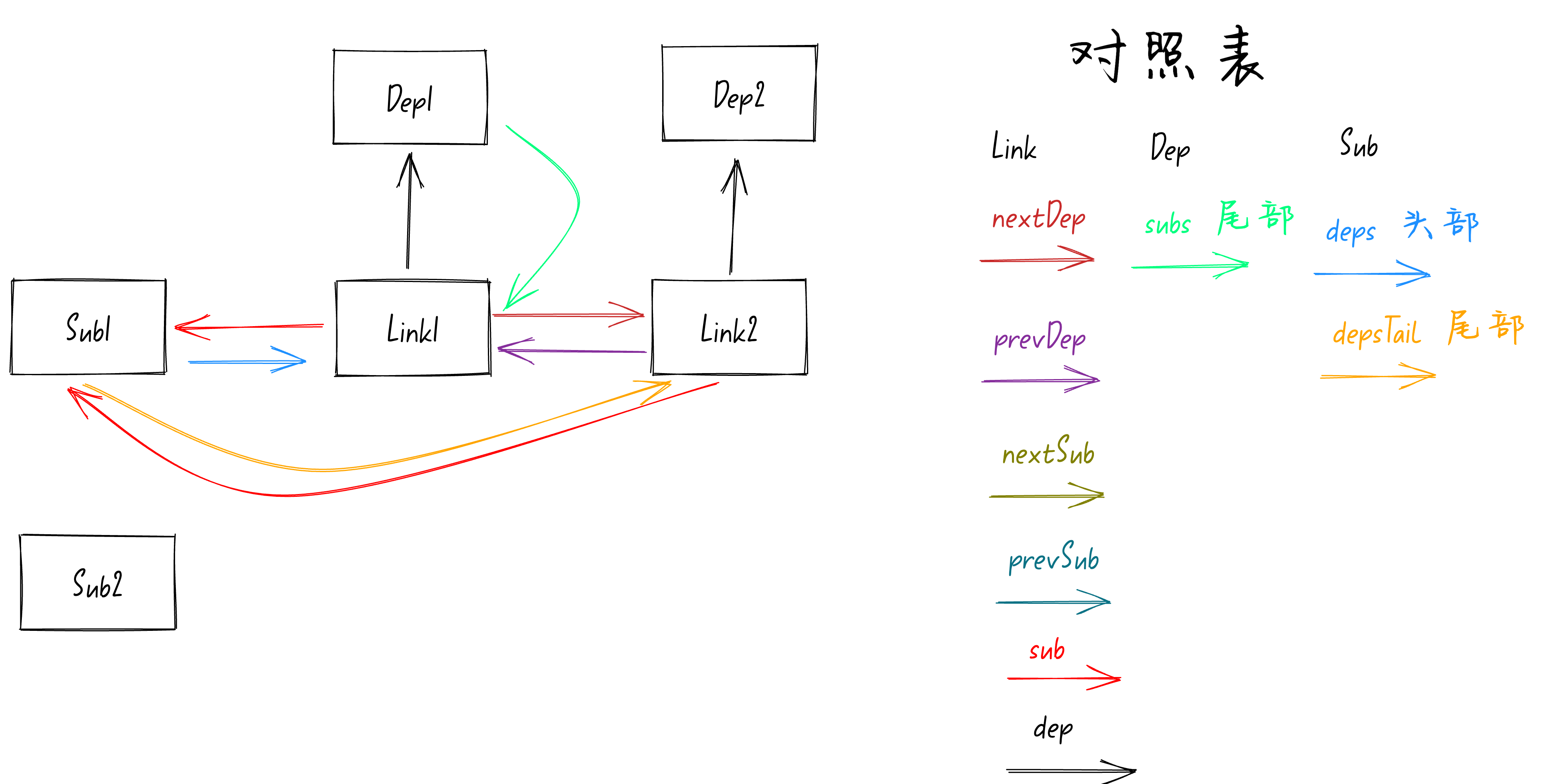
Sub1
订阅者的队列就处理完了,接着就是处理
Dep2
依赖的队列。
Dep2
的处理方式和
Dep1
是一样的,让
Dep2
队列的队尾指向
Link2
,处理完了后模型图如下:
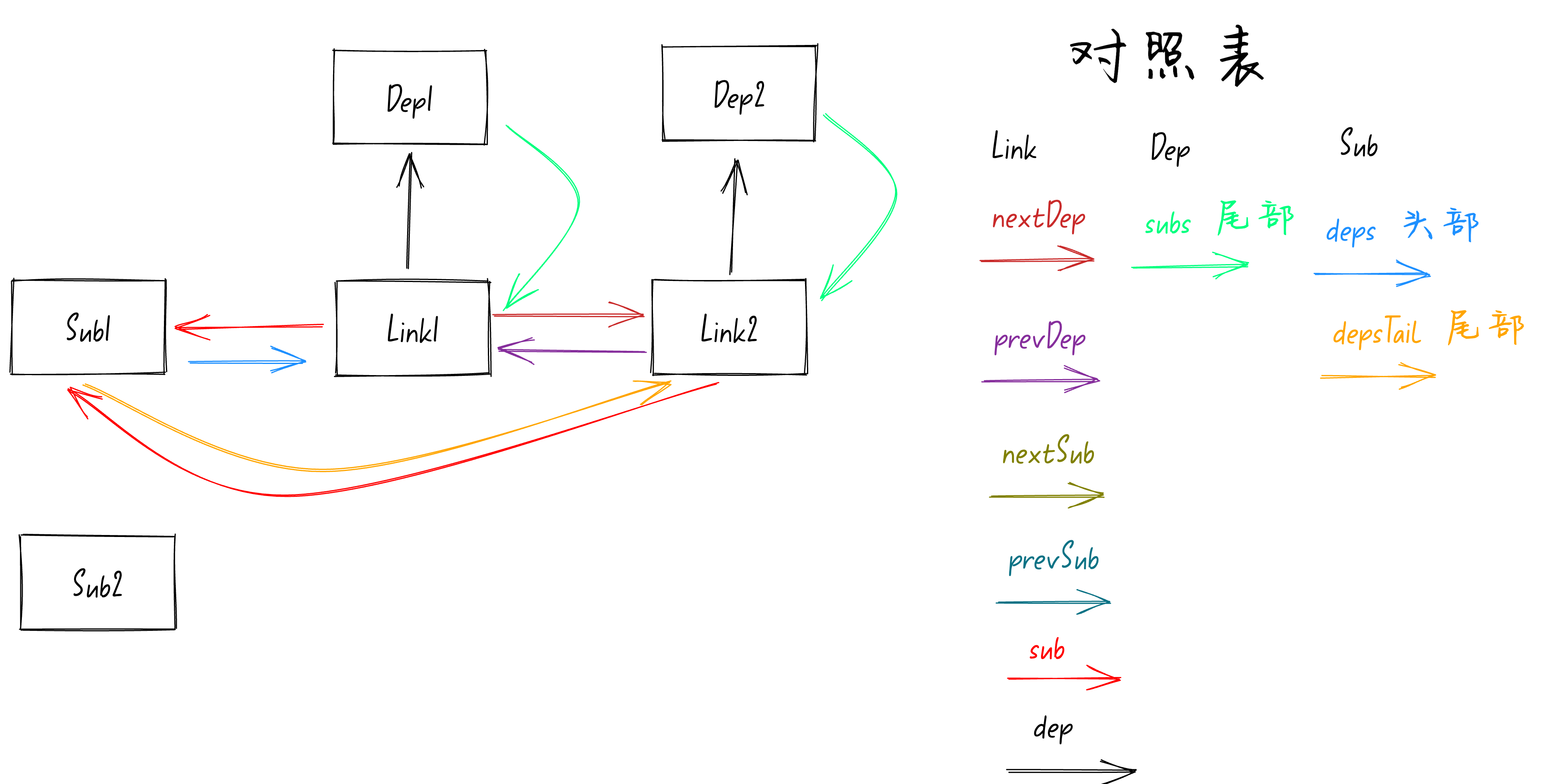
到这里第一个watchEffect(也就是
Sub1
)对其依赖的两个响应式变量
counter1
(也就是
Dep1
)和
counter2
(也就是
Dep2
),进行依赖收集的过程就执行完了。
第二个
watchEffect
对
counter1
进行读操作
接着我们来看第二个
watchEffect
,同样的还是会对
counter1
进行读操作。然后触发其
get
拦截,接着执行
track
方法。回忆一下
track
方法的代码,如下:
class Dep {
// 指向Link链表的尾部节点
subs: Link;
track() {
let link = new Link(activeSub, this);
if (!activeSub.deps) {
activeSub.deps = activeSub.depsTail = link;
} else {
link.prevDep = activeSub.depsTail;
activeSub.depsTail!.nextDep = link;
activeSub.depsTail = link;
}
addSub(link);
}
}
这里还是会使用
new Link(activeSub, this)
创建一个
Link3
节点,节点的
sub
和
dep
属性分别指向
Sub2
和
Dep1
。如下图:
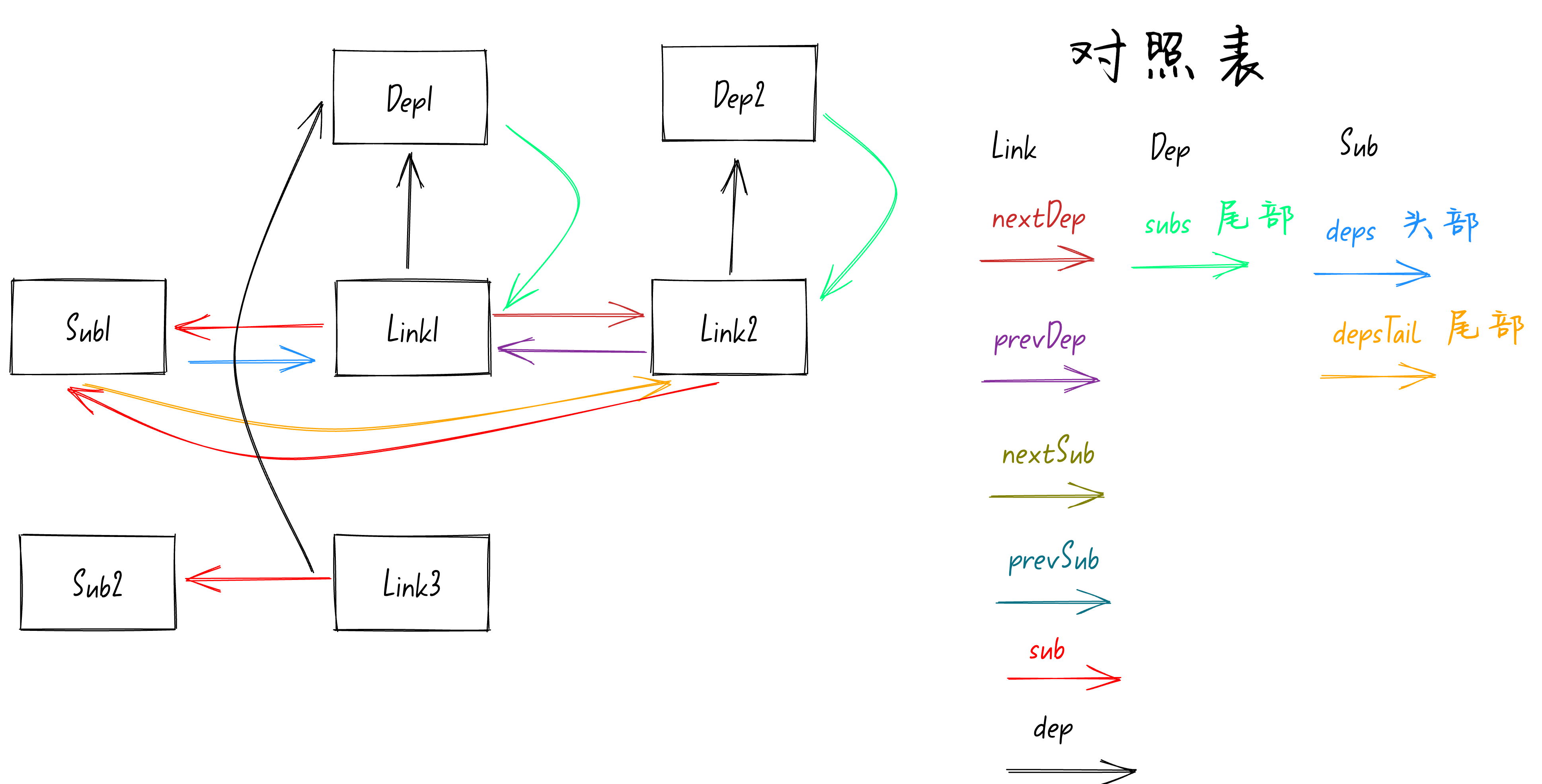
同样的
Sub2
队列上此时还没任何值,所以
if (!activeSub.deps)
为true,和之前一样会去执行
activeSub.deps = activeSub.depsTail = link;
将
Sub2
队列的头部和尾部都设置为
Link3
。如下图:
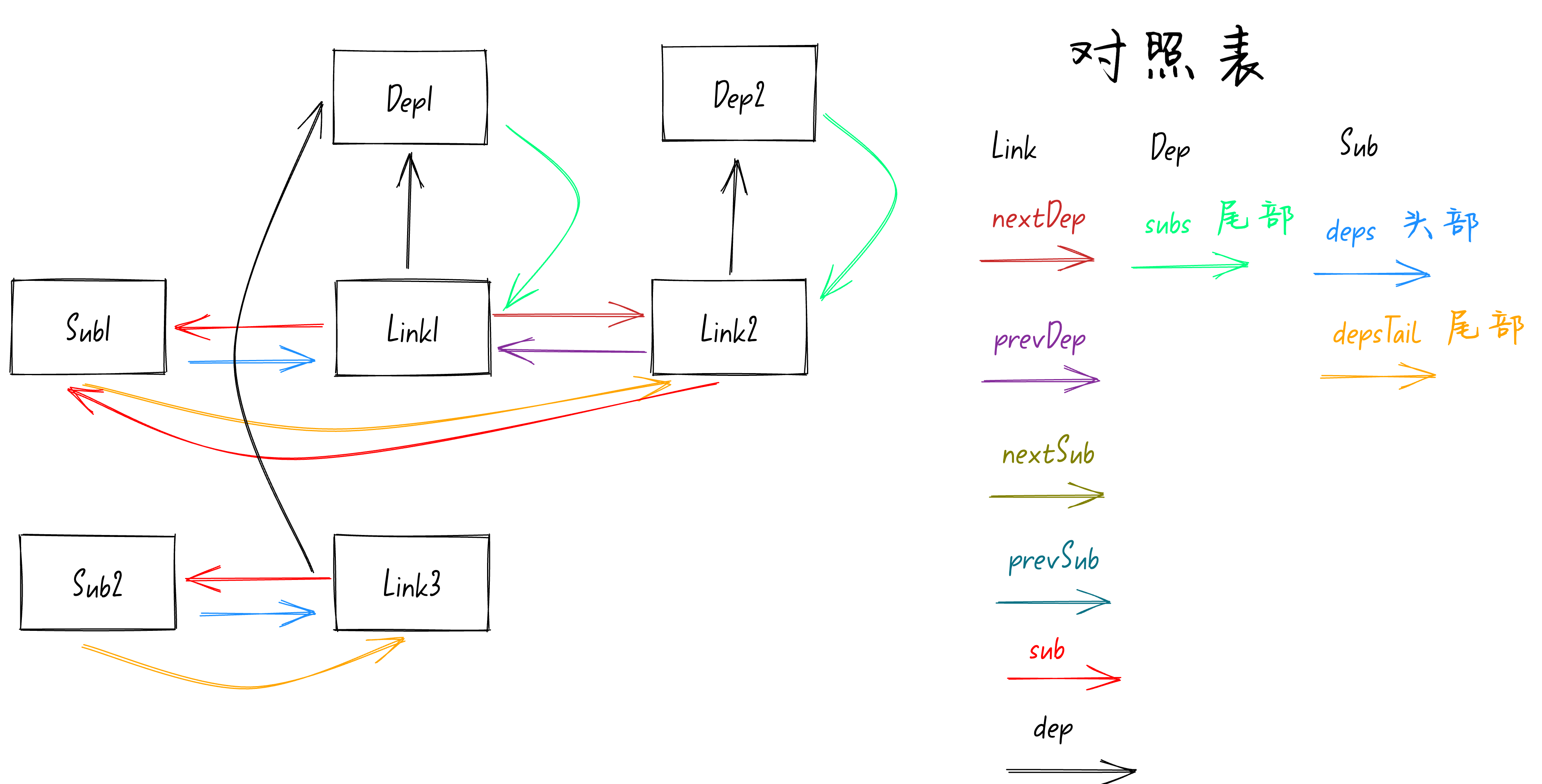
处理完
Sub2
队列后就应该调用
addSub
函数来处理
Dep1
的队列了,回忆一下
addSub
函数,代码如下:
function addSub(link: Link) {
const currentTail = link.dep.subs;
if (currentTail !== link) {
link.prevSub = currentTail;
if (currentTail) currentTail.nextSub = link;
}
link.dep.subs = link;
}
link.dep
指向
Dep1
依赖,
link.dep.subs
指向
Dep1
依赖队列的尾部。从前面的图可以看到此时队列的尾部是
Link1
,所以
currentTail
的值就是
Link1
。
if (currentTail !== link)
也就是判断
Link1
和
Link3
是否相等,很明显不相等,就会走到if的里面去。
接着就是执行
link.prevSub = currentTail
,前面讲过了此时
link
就是
Link3
,
currentTail
就是
Link1
。执行这行代码就是将
Link3
的
prevSub
属性指向
Link1
。
接着就是执行
currentTail.nextSub = link
,这行代码是将
Link1
的
nextSub
指向
Link3
。
执行完上面这两行代码后
Link1
和
Link3
之间就建立联系了,可以通过
prevSub
和
nextSub
属性访问到对方。如下图:
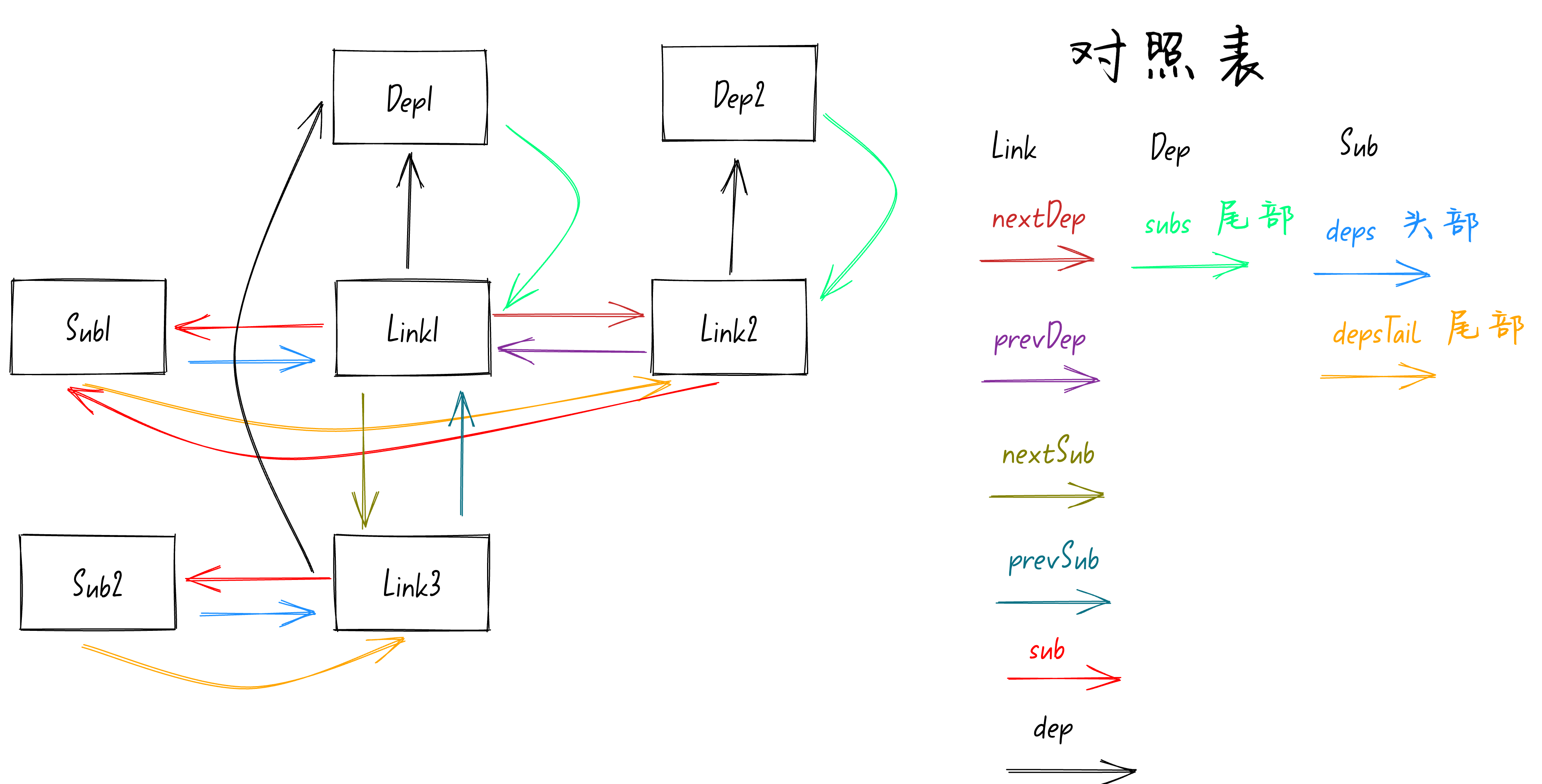
接着就是执行
link.dep.subs = link
,将
Dep1
队列的尾部指向
Link3
,如下图:
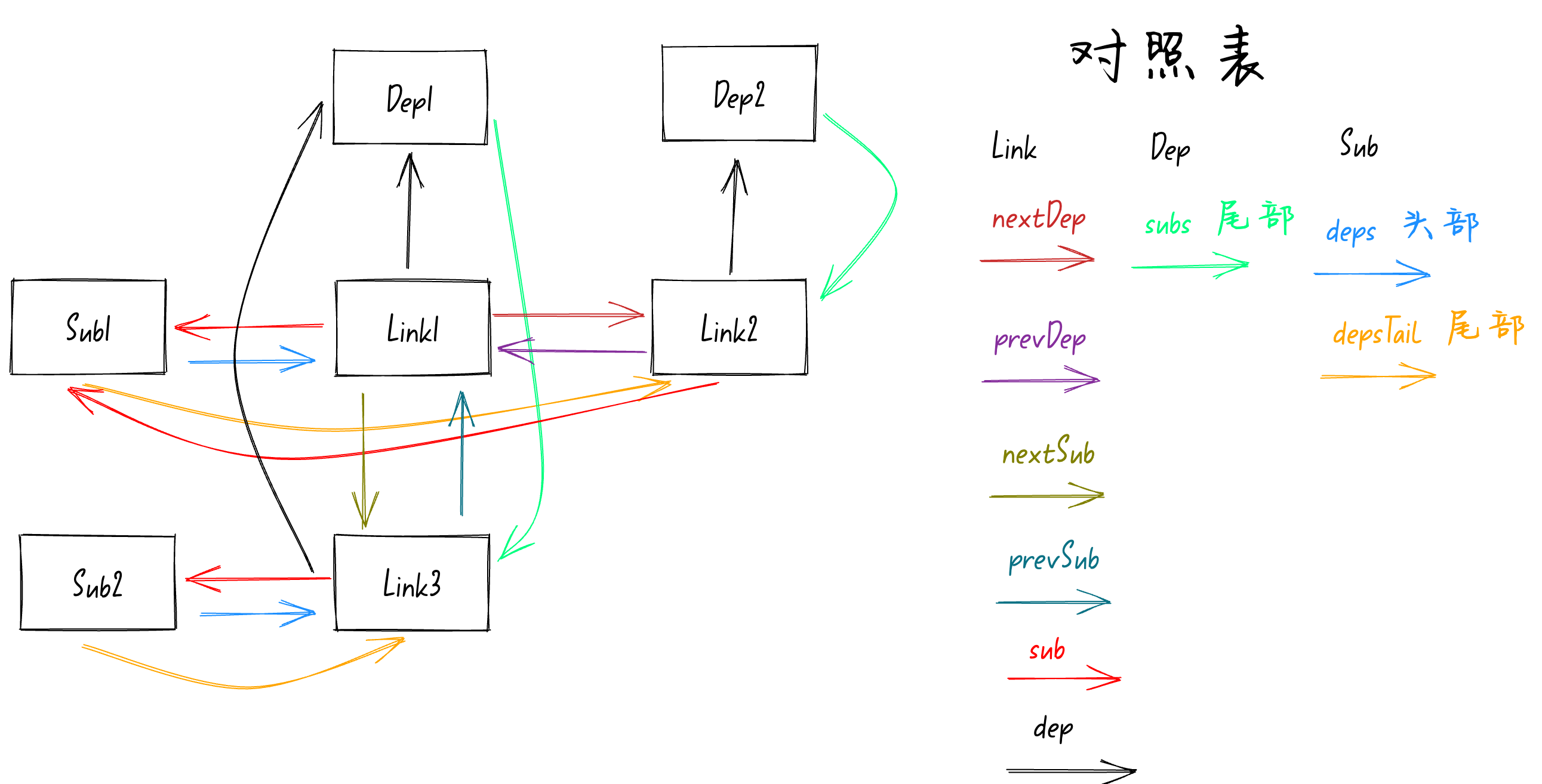
到这里第一个响应式变量
counter1
进行依赖收集就完成了。
第二个
watchEffect
对
counter2
进行读操作
在第二个watchEffect中接着会对
counter2
变量进行读操作。同样会走到
get
拦截中,然后执行
track
函数,代码如下:
class Dep {
// 指向Link链表的尾部节点
subs: Link;
track() {
let link = new Link(activeSub, this);
if (!activeSub.deps) {
activeSub.deps = activeSub.depsTail = link;
} else {
link.prevDep = activeSub.depsTail;
activeSub.depsTail!.nextDep = link;
activeSub.depsTail = link;
}
addSub(link);
}
}
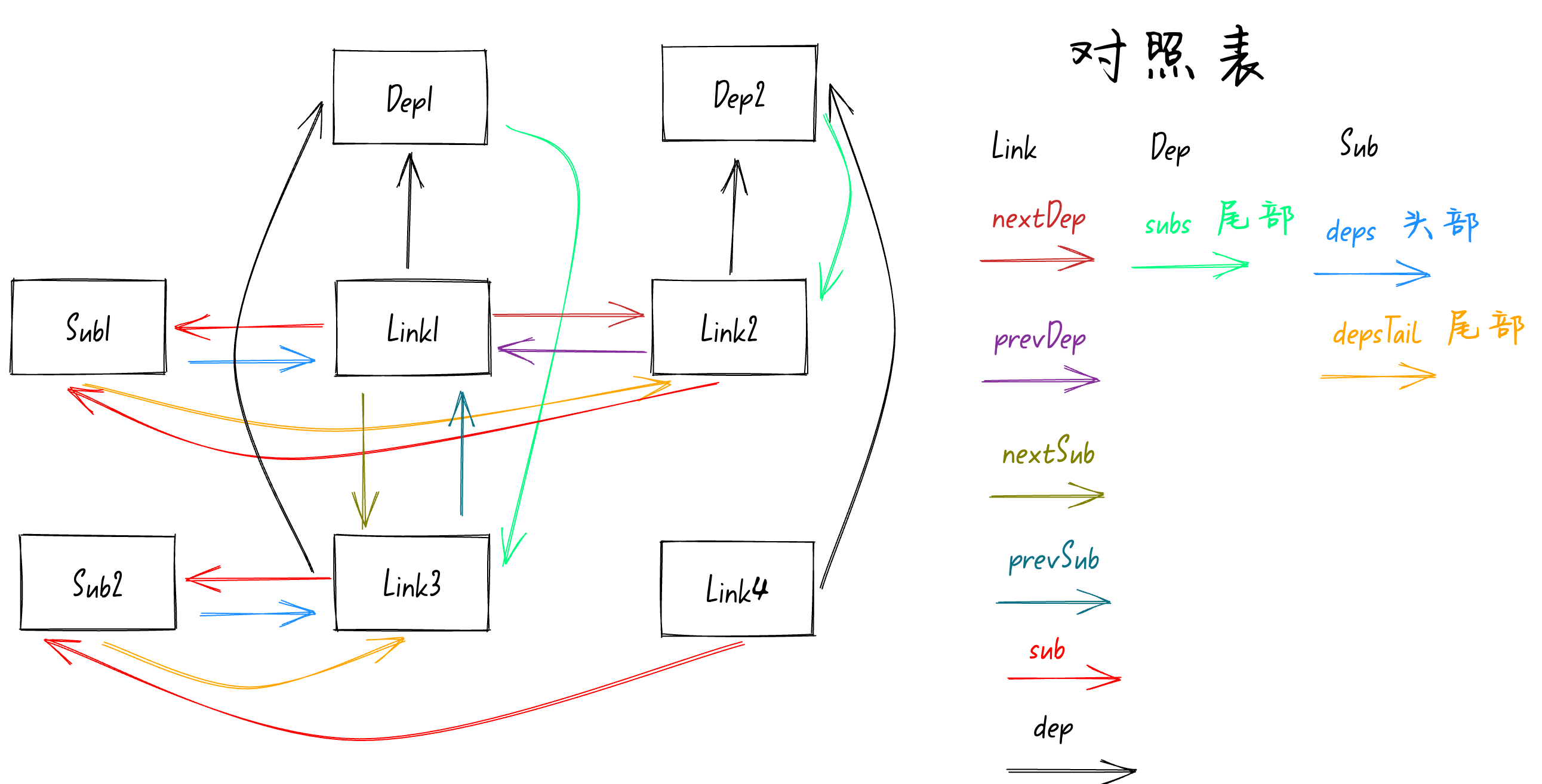
这里还是会使用
new Link(activeSub, this)
创建一个
Link4
节点,节点的
sub
和
dep
属性分别指向
Sub2
和
Dep2
。如下图:
此时的
activeSub
就是
Sub2
,
activeSub.deps
就是指向
Sub2
队列的头部。所以此时头部是指向
Link3
,代码会走到else模块中。
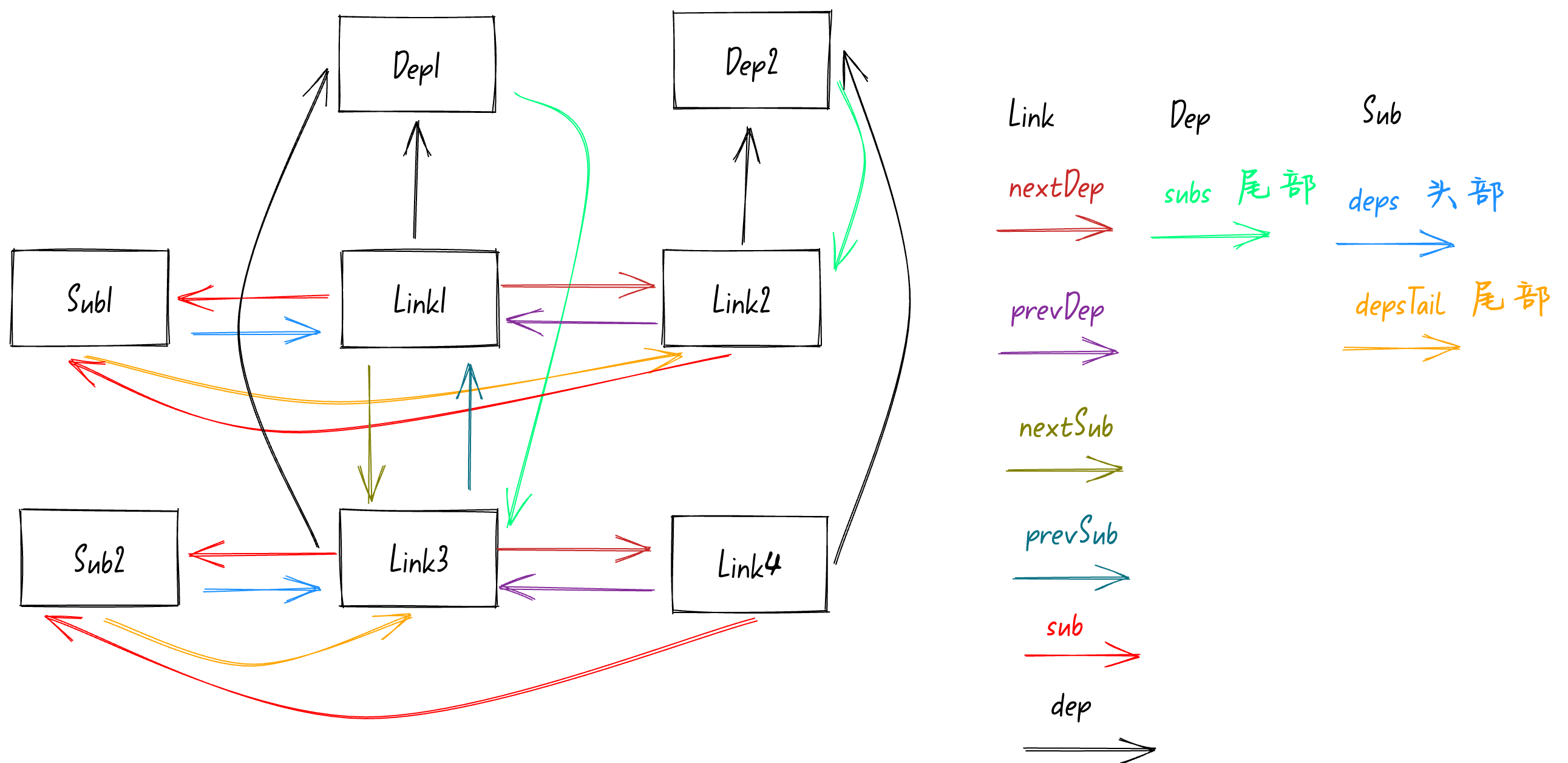
在else中首先会执行
link.prevDep = activeSub.depsTail
,
activeSub.depsTail
是指向
Sub2
队列的尾部,也就是
Link3
。执行完这行代码后会将
Link4
的
prevDep
指向
Link3
。
接着就是执行
activeSub.depsTail!.nextDep = link
,前面讲过了
activeSub.depsTail
是指向
Link3
。执行完这行代码后会将
Link3
的
nextDep
属性指向
Link4
。
执行完上面这两行代码后
Link3
和
Link4
之间就建立联系了,可以通过
nextDep
和
prevDep
属性访问到对方。如下图:
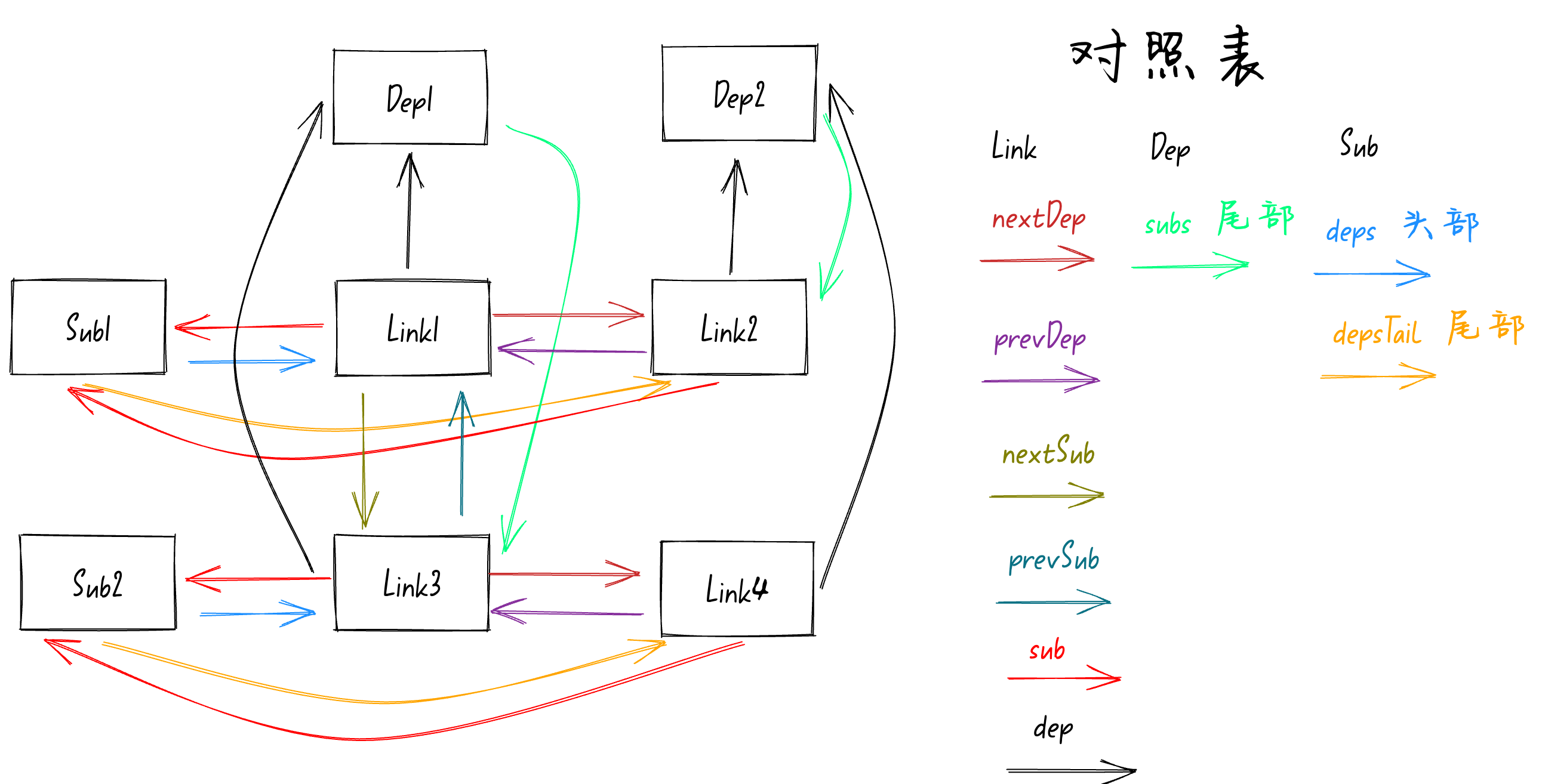
接着就是执行
activeSub.depsTail = link
,将
Sub2
队列的尾部指向
Link4
。如下图:
接着就是执行
addSub
函数处理
Dep2
的队列,代码如下:
function addSub(link: Link) {
const currentTail = link.dep.subs;
if (currentTail !== link) {
link.prevSub = currentTail;
if (currentTail) currentTail.nextSub = link;
}
link.dep.subs = link;
}
link.dep
指向
Dep2
依赖,
link.dep.subs
指向
Dep2
依赖队列的尾部。从前面的图可以看到此时队列的尾部是
Link2
,所以
currentTail
的值就是
Link2
。前面讲过了此时
link
就是
Link4
,
if (currentTail !== link)
也就是判断
Link2
和
Link4
是否相等,很明显不相等,就会走到if的里面去。
接着就是执行
link.prevSub = currentTail
,
currentTail
就是
Link2
。执行这行代码就是将
Link4
的
prevSub
属性指向
Link2
。
接着就是执行
currentTail.nextSub = link
,这行代码是将
Link2
的
nextSub
指向
Link4
。
执行完上面这两行代码后
Link2
和
Link4
之间就建立联系了,可以通过
prevSub
和
nextSub
属性访问到对方。如下图:
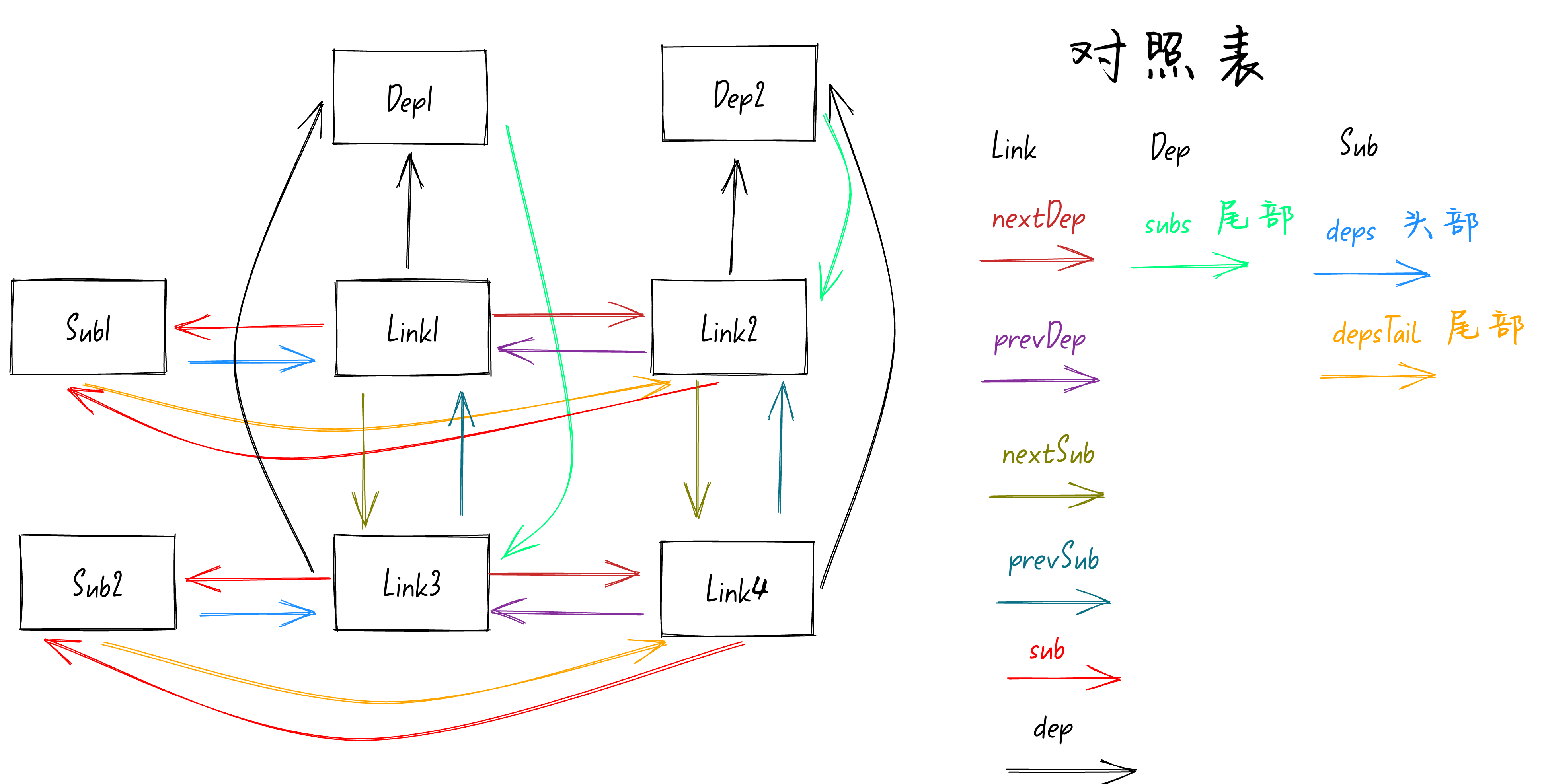
最后就是执行
link.dep.subs = link
将
Dep2
队列的尾部指向
Link4
,如下图:
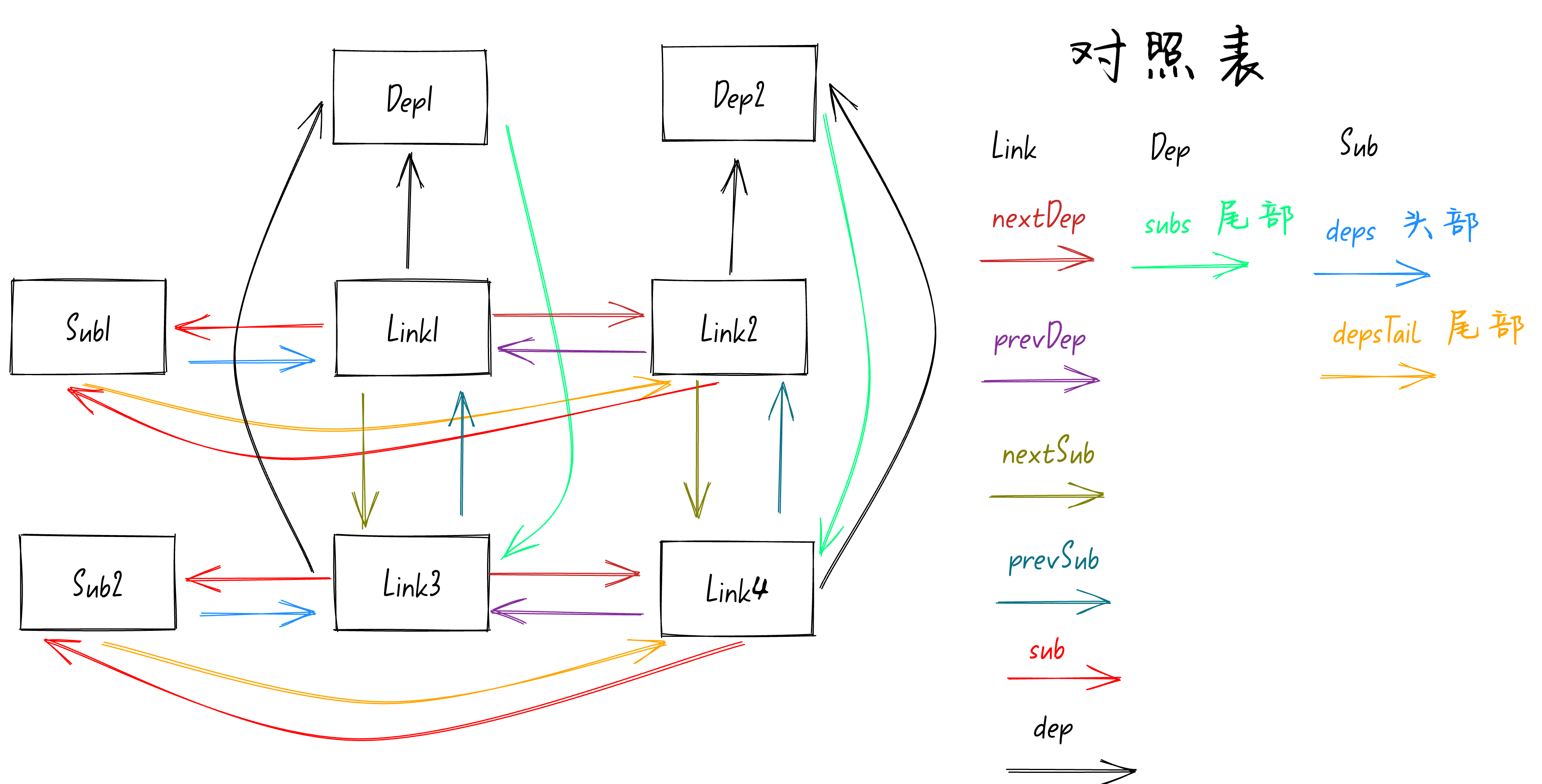
至此整个依赖收集过程就完成了,最终就画出了Vue新的响应式模型。
依赖触发
当执行
counter1.value++
时,就会被变量
counter1
(也就是
Dep1依赖
)的set函数拦截。
此时就可以通过
Dep1
的
subs
属性指向队列的尾部,也就是指向
Link3
。
Link3
中可以直接通过
sub
属性访问到订阅者
Sub2
,也就是第二个
watchEffect
,从而执行第二个
watchEffect
的回调函数。
接着就是使用Link的
preSub
属性从队尾依次移动到队头,从而触发
Dep1
队列中的所有Sub订阅者。
在这里就是使用
preSub
属性访问到
Link1
(就到队列的头部啦),
Link1
中可以直接通过
sub
属性访问到订阅者
Sub1
,也就是第一个
watchEffect
,从而执行第一个
watchEffect
的回调函数。
总结
这篇文章讲了Vue新的响应式模型,里面主要有三个角色:
Dep依赖
、
Sub订阅者
、
Link节点
。
Dep依赖
和
Sub订阅者
不再有直接的联系,而是通过
Link节点
作为桥梁。
依赖收集的过程中会构建
Dep依赖
的队列,队列是由
Link节点
组成。以及构建
Sub订阅者
的队列,队列同样是由
Link节点
组成。
依赖触发时就可以通过
Dep依赖
的队列的队尾出发,
Link节点
可以访问和触发对应的
Sub订阅者
。
然后依次从队尾向队头移动,依次触发队列中每个
Link节点
的
Sub订阅者
。
关注公众号:【前端欧阳】,给自己一个进阶vue的机会

另外欧阳写了一本开源电子书
vue3编译原理揭秘
,看完这本书可以让你对vue编译的认知有质的提升。这本书初、中级前端能看懂,完全免费,只求一个star。