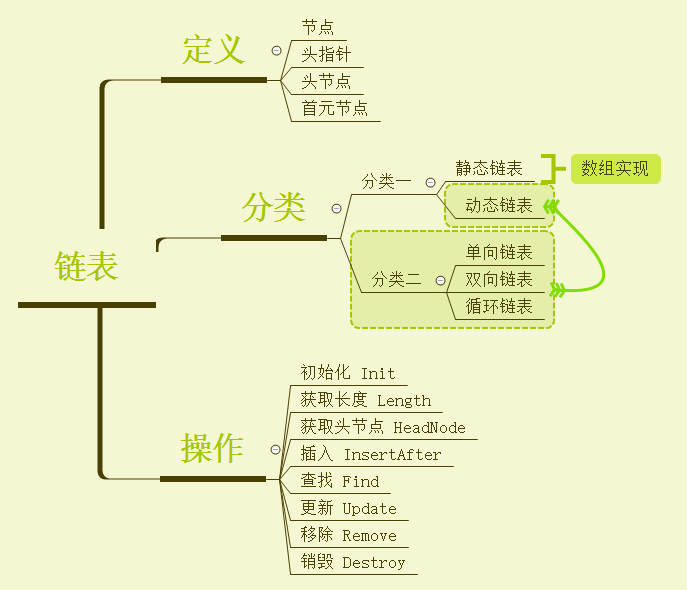
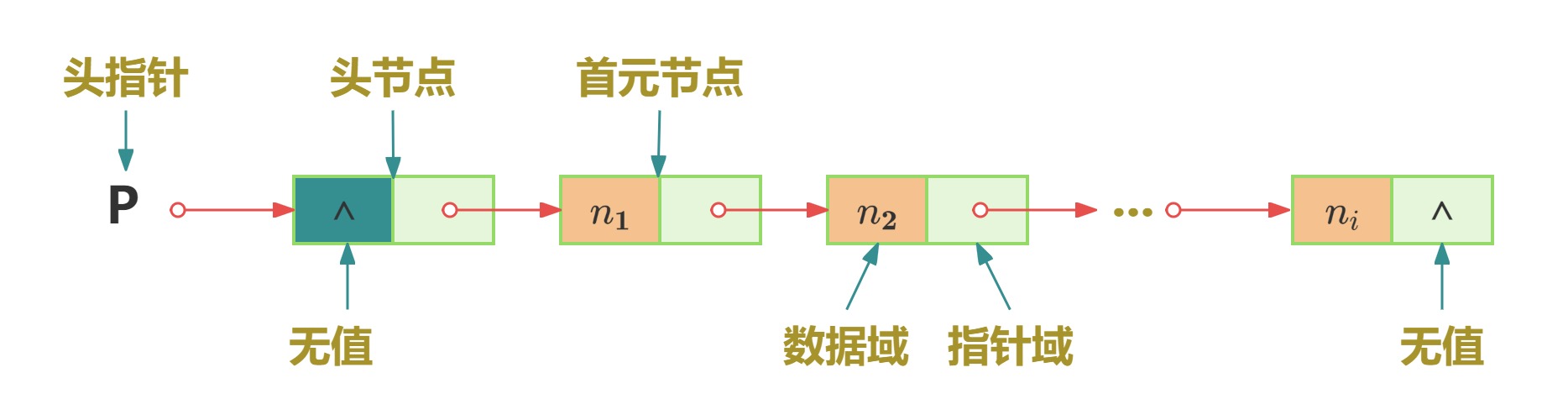
1、背景
最近在开发的过程中遇到这么一个问题,当产生某种类型的工单后,需要实时通知到另外的系统,由另外的系统进行数据的研判操作。
由于某种原因
, 像向消息队列中推送工单消息、或直接调用另外系统的接口、或者部署
Cannal
等都不可行,因此此处使用
mysql-binlog-connector-java
这个库来完成数据库
binlog
的监听,从而通知到另外的系统。
2、mysql-binlog-connector-java简介
mysql-binlog-connector-java
是一个Java库,通过它可以实现
mysql binlog
日志的监听和解析操作。它提供了一系列可靠的方法,使开发者通过监听数据库的binlog日志,来
实时
获取数据库的变更信息,比如:数据的
插入
、
更新
、
删除
等操作。
github地址
https://github.com/osheroff/mysql-binlog-connector-java
3、准备工作
1、验证数据库是否开启binlog
mysql> show variables like '%log_bin%';
+---------------------------------+------------------------------------+
| Variable_name | Value |
+---------------------------------+------------------------------------+
| log_bin | ON |
| log_bin_basename | /usr/local/mysql/data/binlog |
| log_bin_index | /usr/local/mysql/data/binlog.index |
| log_bin_trust_function_creators | OFF |
| log_bin_use_v1_row_events | OFF |
| sql_log_bin | ON |
+---------------------------------+------------------------------------+
log_bin
的值为
ON
时,表示开启了
binlog
2、开启数据库的binlog
# 修改 my.cnf 配置文件
[mysqld]
#binlog日志的基本文件名,需要注意的是启动mysql的用户需要对这个目录(/usr/local/var/mysql/binlog)有写入的权限
log_bin=/usr/local/var/mysql/binlog/mysql-bin
# 配置binlog日志的格式
binlog_format = ROW
# 配置 MySQL replaction 需要定义,不能和已有的slaveId 重复
server-id=1
3、创建具有REPLICATION SLAVE权限的用户
CREATE USER binlog_user IDENTIFIED BY 'binlog#Replication2024!';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'binlog_user'@'%';
FLUSH PRIVILEGES;

4、事件类型 eventType 解释
注意:不同的mysql版本事件类型可能不同,我们本地是mysql8
TABLE_MAP: 在表的 insert、update、delete 前的事件,用于记录操作的数据库名和表名。
EXT_WRITE_ROWS: 插入数据事件类型,即 insert 类型
EXT_UPDATE_ROWS: 插入数据事件类型,即 update 类型
EXT_DELETE_ROWS: 插入数据事件类型,即 delete 类型
ROTATE: 当mysqld切换到新的二进制日志文件时写入。当发出一个FLUSH LOGS 语句。或者当前二进制日志文件超过max_binlog_size。
1、TABLE_MAP 的注意事项
一般情况下,当我们向数据库中执行
insert
、
update
或
delete
事件时,一般会先有一个
TABLE_MAP
事件发出,通过这个事件,我们就知道当前操作的是那个数据库和表。
但是
如果我们操作的表上存在触发器时,那么可能顺序就会错乱,导致我们获取到错误的数据库名和表名。

2、获取操作的列名
此处以
EXT_UPDATE_ROWS
事件为列,当我们往数据库中
update
一条记录时,触发此事件,事件内容为:
Event{header=EventHeaderV4{timestamp=1727498351000, eventType=EXT_UPDATE_ROWS, serverId=1, headerLength=19, dataLength=201, nextPosition=785678, flags=0}, data=UpdateRowsEventData{tableId=264, includedColumnsBeforeUpdate={0, 1, 2, 3, 4, 5, 6, 7}, includedColumns={0, 1, 2, 3, 4, 5, 6, 7}, rows=[
{before=[1, zhangsan, 张三-update, 0, [B@7b720427, [B@238552f, 1727524798000, 1727495998000], after=[1, zhangsan, 张三-update, 0, [B@21dae489, [B@2c0fff72, 1727527151000, 1727498351000]}
]}}
从上面的语句中可以看到
includedColumnsBeforeUpdate
和
includedColumns
这2个字段表示更新前的列名和更新后的列名,
但是这个时候展示的数字,那么如果展示具体的列名呢?
可以通过
information_schema.COLUMNS
获取。

5、监听binlog的position
1、从最新的binlog位置开始监听
默认情况下,就是从最新的binlog位置开始监听。
BinaryLogClient client = new BinaryLogClient(hostname, port, username, password);
2、从指定的位置开始监听
BinaryLogClient client = new BinaryLogClient(hostname, port, username, password);
// binlog的文件名
client.setBinlogFilename("");
// binlog的具体位置
client.setBinlogPosition(11);
3、断点续传
这个指的是,当我们的
mysql-binlog-connector-java
程序宕机后,如果数据发生了binlog的变更,我们应该从程序上次宕机的位置的position进行监听,而不是程序重启后从最新的binlog position位置开始监听。默认情况下
mysql-binlog-connector-java
程序没有为我们实现,需要我们自己去实现。大概的实现思路为:
- 监听
ROTATE
事件,可以获取到最新的binlog文件名和位置。
- 记录每个事件的position的位置。
6、创建表和准备测试数据
CREATE TABLE `binlog_demo`
(
`id` int NOT NULL AUTO_INCREMENT COMMENT '主键',
`user_name` varchar(64) DEFAULT NULL COMMENT '用户名',
`nick_name` varchar(64) DEFAULT NULL COMMENT '昵称',
`sex` tinyint DEFAULT NULL COMMENT '性别 0-女 1-男 2-未知',
`address` text COMMENT '地址',
`ext_info` json DEFAULT NULL COMMENT '扩展信息',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
`update_time` timestamp NULL DEFAULT NULL COMMENT '修改时间',
PRIMARY KEY (`id`),
UNIQUE KEY `uidx_username` (`user_name`)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='测试binlog'
-- 0、删除数据
truncate table binlog_demo;
-- 1、添加数据
insert into binlog_demo(user_name, nick_name, sex, address, ext_info, create_time, update_time)
values ('zhangsan', '张三', 1, '地址', '[
"aaa",
"bbb"
]', now(), now());
-- 2、修改数据
update binlog_demo
set nick_name = '张三-update',
sex = 0,
address = '地址-update',
ext_info = '{
"ext_info": "扩展信息"
}',
create_time = now(),
update_time = now()
where user_name = 'zhangsan';
-- 3、删除数据
delete
from binlog_demo
where user_name = 'zhangsan';
4、功能实现
通过
mysql-binlog-connector-java
库,当
数据库
中的
表数据
发生
变更
时,
进行监听
。
1、从最新的binlog位置开始监听
1、引入jar包
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- 监听 mysql binlog -->
<dependency>
<groupId>com.zendesk</groupId>
<artifactId>mysql-binlog-connector-java</artifactId>
<version>0.29.2</version>
</dependency>
</dependencies>
2、监听binlog数据
package com.huan.binlog;
import com.github.shyiko.mysql.binlog.BinaryLogClient;
import com.github.shyiko.mysql.binlog.event.Event;
import com.github.shyiko.mysql.binlog.event.EventType;
import com.github.shyiko.mysql.binlog.event.deserialization.EventDeserializer;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.stereotype.Component;
import javax.annotation.PostConstruct;
import javax.annotation.PreDestroy;
import java.io.IOException;
import java.util.concurrent.TimeoutException;
/**
* 初始化 binary log client
*
* @author huan.fu
* @date 2024/9/22 - 16:23
*/
@Component
public class BinaryLogClientInit {
private static final Logger log = LoggerFactory.getLogger(BinaryLogClientInit.class);
private BinaryLogClient client;
@PostConstruct
public void init() throws IOException, TimeoutException {
/**
* # 创建用户
* CREATE USER binlog_user IDENTIFIED BY 'binlog#Replication2024!';
* GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'binlog_user'@'%';
* FLUSH PRIVILEGES;
*/
String hostname = "127.0.0.1";
int port = 3306;
String username = "binlog_user";
String password = "binlog#Replication2024!";
// 创建 BinaryLogClient客户端
client = new BinaryLogClient(hostname, port, username, password);
// 这个 serviceId 不可重复
client.setServerId(12);
// 反序列化配置
EventDeserializer eventDeserializer = new EventDeserializer();
eventDeserializer.setCompatibilityMode(
// 将日期类型的数据反序列化成Long类型
EventDeserializer.CompatibilityMode.DATE_AND_TIME_AS_LONG
);
client.setEventDeserializer(eventDeserializer);
client.registerEventListener(new BinaryLogClient.EventListener() {
@Override
public void onEvent(Event event) {
EventType eventType = event.getHeader().getEventType();
log.info("接收到事件类型: {}", eventType);
log.warn("接收到的完整事件: {}", event);
log.info("============================");
}
});
client.registerLifecycleListener(new BinaryLogClient.AbstractLifecycleListener() {
@Override
public void onConnect(BinaryLogClient client) {
log.info("客户端连接到 mysql 服务器 client: {}", client);
}
@Override
public void onCommunicationFailure(BinaryLogClient client, Exception ex) {
log.info("客户端和 mysql 服务器 通讯失败 client: {}", client);
}
@Override
public void onEventDeserializationFailure(BinaryLogClient client, Exception ex) {
log.info("客户端序列化失败 client: {}", client);
}
@Override
public void onDisconnect(BinaryLogClient client) {
log.info("客户端断开 mysql 服务器链接 client: {}", client);
}
});
// client.connect 在当前线程中进行解析binlog,会阻塞当前线程
// client.connect(xxx) 会新开启一个线程,然后在这个线程中解析binlog
client.connect(10000);
}
@PreDestroy
public void destroy() throws IOException {
client.disconnect();
}
}
3、测试

从上图中可以看到,我们获取到了更新后的数据,但是具体更新了哪些列名这个我们是不清楚的。
2、获取数据更新具体的列名
此处以
更新数据为例
,大体的实现思路如下:
- 通过监听
TABLE_MAP
事件,用于获取到
insert
、
update
或
delete
语句操作前的
数据库
和
表
。
- 通过查询
information_schema.COLUMNS
表获取 某个表在某个数据库中具体的列信息(比如:列名、列的数据类型等操作)。
2.1 新增common-dbutils依赖用于操作数据库
<!-- 操作数据库 -->
<dependency>
<groupId>commons-dbutils</groupId>
<artifactId>commons-dbutils</artifactId>
<version>1.8.1</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.33</version>
</dependency>
2.2 监听TABLE_MAP事件,获取数据库和表名
- 定义2个
成员变量
,
database
和
tableName
用于接收数据库和表名。
/**
* 数据库
*/
private String database;
/**
* 表名
*/
private String tableName;
- 监听
TABLE_MAP
事件,获取数据库和表名
// 成员变量 - 数据库名
private String database;
// 成员变量 - 表名
private String tableName;
client.registerEventListener(new BinaryLogClient.EventListener() {
@Override
public void onEvent(Event event) {
EventType eventType = event.getHeader().getEventType();
log.info("接收到事件类型: {}", eventType);
log.info("============================");
if (event.getData() instanceof TableMapEventData) {
TableMapEventData eventData = (TableMapEventData) event.getData();
database = eventData.getDatabase();
tableName = eventData.getTable();
log.info("获取到的数据库名: {} 和 表名为: {}", database, tableName);
}
}
});

2.3 编写工具类获取表的列名和位置信息

/**
* 数据库工具类
*
* @author huan.fu
* @date 2024/10/9 - 02:39
*/
public class DbUtils {
public static Map<String, String> retrieveTableColumnInfo(String database, String tableName) throws SQLException {
Connection connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/temp_work", "binlog_user", "binlog#Replication2024!");
QueryRunner runner = new QueryRunner();
Map<String, String> columnInfoMap = runner.query(
connection,
"select a.COLUMN_NAME,a.ORDINAL_POSITION from information_schema.COLUMNS a where a.TABLE_SCHEMA = ? and a.TABLE_NAME = ?",
resultSet -> {
Map<String, String> result = new HashMap<>();
while (resultSet.next()) {
result.put(resultSet.getString("ORDINAL_POSITION"), resultSet.getString("COLUMN_NAME"));
}
return result;
},
database,
tableName
);
connection.close();
return columnInfoMap;
}
public static void main(String[] args) throws SQLException {
Map<String, String> stringObjectMap = DbUtils.retrieveTableColumnInfo("temp_work", "binlog_demo");
System.out.println(stringObjectMap);
}
}

2.4 以更新语句为例获取 更新的列名和对应的值
1、编写java代码获取更新后的列和值信息
client.registerEventListener(new BinaryLogClient.EventListener() {
@Override
public void onEvent(Event event) {
EventType eventType = event.getHeader().getEventType();
log.info("接收到事件类型: {}", eventType);
log.warn("接收到的完整事件: {}", event);
log.info("============================");
// 通过 TableMap 事件获取 数据库名和表名
if (event.getData() instanceof TableMapEventData) {
TableMapEventData eventData = (TableMapEventData) event.getData();
database = eventData.getDatabase();
tableName = eventData.getTable();
log.info("获取到的数据库名: {} 和 表名为: {}", database, tableName);
}
// 监听更新事件
if (event.getData() instanceof UpdateRowsEventData) {
try {
// 获取表的列信息
Map<String, String> columnInfo = DbUtils.retrieveTableColumnInfo(database, tableName);
// 获取更新后的数据
UpdateRowsEventData eventData = ((UpdateRowsEventData) event.getData());
// 可能更新多行数据
List<Map.Entry<Serializable[], Serializable[]>> rows = eventData.getRows();
for (Map.Entry<Serializable[], Serializable[]> row : rows) {
// 更新前的数据
Serializable[] before = row.getKey();
// 更新后的数据
Serializable[] after = row.getValue();
// 保存更新后的一行数据
Map<String, Serializable> afterUpdateRowMap = new HashMap<>();
for (int i = 0; i < after.length; i++) {
// 因为 columnInfo 中的列名的位置是从1开始,而此处是从0开始
afterUpdateRowMap.put(columnInfo.get((i + 1) + ""), after[i]);
}
log.info("监听到更新的数据为: {}", afterUpdateRowMap);
}
} catch (Exception e) {
log.error("监听更新事件发生了异常");
}
}
// 监听插入事件
if (event.getData() instanceof WriteRowsEventData) {
log.info("监听到插入事件");
}
// 监听删除事件
if (event.getData() instanceof DeleteRowsEventData) {
log.info("监听到删除事件");
}
}
});
2、执行更新语句
update binlog_demo
set nick_name = '张三-update11',
-- sex = 0,
-- address = '地址-update1',
-- ext_info = '{"ext_info":"扩展信息"}',
-- create_time = now(),
update_time = now()
where user_name = 'zhangsan';
3、查看监听到更新数据信息

3、自定义序列化字段
从下图中可知,针对
text
类型的字段,默认转换成了
byte[]
类型,那么怎样将其转换成
String
类型呢?
此处针对更新语句来演示

3.1 自定义更新数据text类型字段的反序列
注意:断点跟踪源码发现text类型的数据映射成了blob类型,因此需要重写 deserializeBlob 方法
public class CustomUpdateRowsEventDataDeserializer extends UpdateRowsEventDataDeserializer {
public CustomUpdateRowsEventDataDeserializer(Map<Long, TableMapEventData> tableMapEventByTableId) {
super(tableMapEventByTableId);
}
@Override
protected Serializable deserializeBlob(int meta, ByteArrayInputStream inputStream) throws IOException {
byte[] bytes = (byte[]) super.deserializeBlob(meta, inputStream);
if (null != bytes && bytes.length > 0) {
return new String(bytes, StandardCharsets.UTF_8);
}
return null;
}
}
3.2 注册更新数据的反序列
注意: 需要通过 EventDeserializer 来进行注册
// 反序列化配置
EventDeserializer eventDeserializer = new EventDeserializer();
Field field = EventDeserializer.class.getDeclaredField("tableMapEventByTableId");
field.setAccessible(true);
Map<Long, TableMapEventData> tableMapEventByTableId = (Map<Long, TableMapEventData>) field.get(eventDeserializer);
eventDeserializer.setEventDataDeserializer(EventType.EXT_UPDATE_ROWS, new CustomUpdateRowsEventDataDeserializer(tableMapEventByTableId)
.setMayContainExtraInformation(true));
3.3 更新text类型的字段,看输出的结果

4、只订阅感兴趣的事件
// 反序列化配置
EventDeserializer eventDeserializer = new EventDeserializer();
eventDeserializer.setCompatibilityMode(
// 将日期类型的数据反序列化成Long类型
EventDeserializer.CompatibilityMode.DATE_AND_TIME_AS_LONG
);
// 表示对 删除事件不感兴趣 ( 对于DELETE事件的反序列化直接返回null )
eventDeserializer.setEventDataDeserializer(EventType.EXT_DELETE_ROWS, new NullEventDataDeserializer());
对于不感兴趣的事件直接使用
NullEventDataDeserializer
,可以提高程序的性能。
5、断点续传
当binlog的信息发生变更时,需要保存起来,下次程序重新启动时,读取之前保存好的binlog信息。
5.1 binlog信息持久化
此处为了模拟,将binlog的信息保存到文件中。
/**
* binlog position 的持久化处理
*
* @author huan.fu
* @date 2024/10/11 - 12:54
*/
public class FileBinlogPositionHandler {
/**
* binlog 信息实体类
*/
public static class BinlogPositionInfo {
/**
* binlog文件的名字
*/
public String binlogName;
/**
* binlog的位置
*/
private Long position;
/**
* binlog的server id的值
*/
private Long serverId;
}
/**
* 保存binlog信息
*
* @param binlogName binlog文件名
* @param position binlog位置信息
* @param serverId binlog server id
*/
public void saveBinlogInfo(String binlogName, Long position, Long serverId) {
List<String> data = new ArrayList<>(3);
data.add(binlogName);
data.add(position + "");
data.add(serverId + "");
try {
Files.write(Paths.get("binlog-info.txt"), data);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
/**
* 获取 binlog 信息
*
* @return BinlogPositionInfo
*/
public BinlogPositionInfo retrieveBinlogInfo() {
try {
List<String> lines = Files.readAllLines(Paths.get("binlog-info.txt"));
BinlogPositionInfo info = new BinlogPositionInfo();
info.binlogName = lines.get(0);
info.position = Long.parseLong(lines.get(1));
info.serverId = Long.parseLong(lines.get(2));
return info;
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
5.2、构建BinaryLogClient时,传递已存在的binlog信息
// 设置 binlog 信息
FileBinlogPositionHandler fileBinlogPositionHandler = new FileBinlogPositionHandler();
FileBinlogPositionHandler.BinlogPositionInfo binlogPositionInfo = fileBinlogPositionHandler.retrieveBinlogInfo();
if (null != binlogPositionInfo) {
log.info("获取到了binlog 信息 binlogName: {} position: {} serverId: {}", binlogPositionInfo.binlogName,
binlogPositionInfo.position, binlogPositionInfo.serverId);
client.setBinlogFilename(binlogPositionInfo.binlogName);
client.setBinlogPosition(binlogPositionInfo.position);
client.setServerId(binlogPositionInfo.serverId);
}
5.3 更新binlog信息
// FORMAT_DESCRIPTION(写入每个二进制日志文件前的描述事件) HEARTBEAT(心跳事件)这2个事件不进行binlog位置的记录
if (eventType != EventType.FORMAT_DESCRIPTION && eventType != EventType.HEARTBEAT) {
// 当有binlog文件切换时产生
if (event.getData() instanceof RotateEventData) {
RotateEventData eventData = event.getData();
// 保存binlog position 信息
fileBinlogPositionHandler.saveBinlogInfo(eventData.getBinlogFilename(), eventData.getBinlogPosition(), event.getHeader().getServerId());
} else {
// 非 rotate 事件,保存位置信息
EventHeaderV4 header = event.getHeader();
FileBinlogPositionHandler.BinlogPositionInfo info = fileBinlogPositionHandler.retrieveBinlogInfo();
long position = header.getPosition();
long serverId = header.getServerId();
fileBinlogPositionHandler.saveBinlogInfo(info.binlogName, position, serverId);
}
}
5.4 演示
- 启动程序
- 修改
address
的值为
地址-update2
- 停止程序
- 修改
address
的值为
地址-offline-update
- 启动程序,看能否收到 上一步修改address的值为
地址-offline-update
的事件

5、参考地址
- github地址 - https://github.com/osheroff/mysql-binlog-connector-java
- maven仓库地址https://mvnrepository.com/artifact/com.zendesk/mysql-binlog-connector-java/0.29.2
- TABLE_MAP事件顺序问题. - https://github.com/shyiko/mysql-binlog-connector-java/issues/67
- dbutils的官网 - https://commons.apache.org/proper/commons-dbutils/examples.html