1.概述
cornerstone中核心即为raft_server的实现。
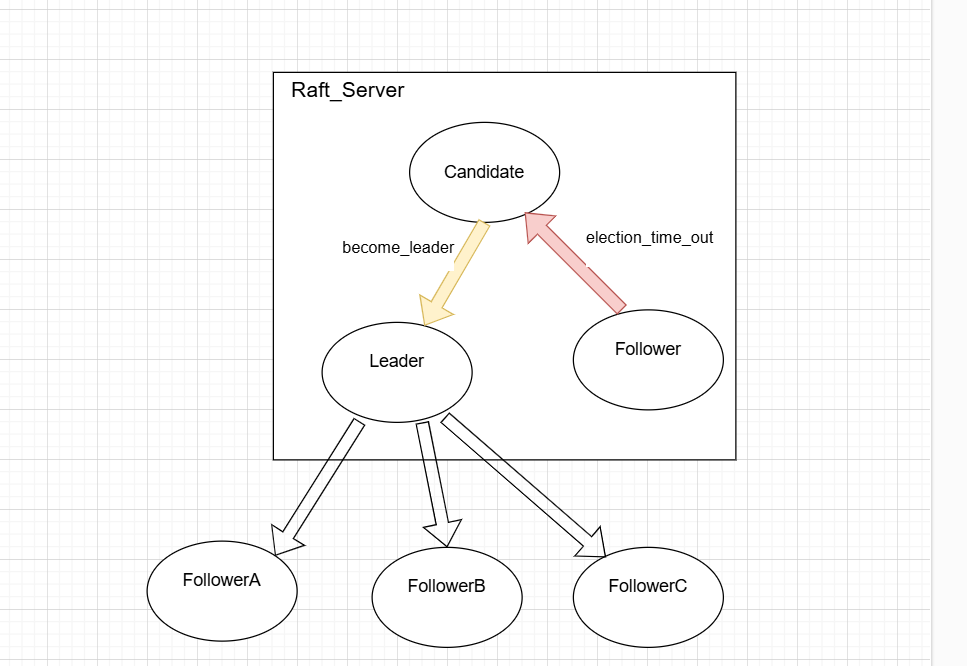
在raft里面有follower,leader,candidate三种角色,且角色身份还可以相互切换。
写三个类follower,leader,candidate显得没必要,因为三个类可以共享许多成员变量,如term,log_store等等。因此在cornerstone中抽象出raft_server这一个类,而raft_server的角色可以在三种状态相互切换。
下图为cornerstone中关于管理三种角色的示意图。
在本文中我们先解析单个raft_server节点中角色变化的过程,再关注leader与follower的通信。
2. raft_server节点中角色变化
2.1.1 逻辑概览
示意图如下
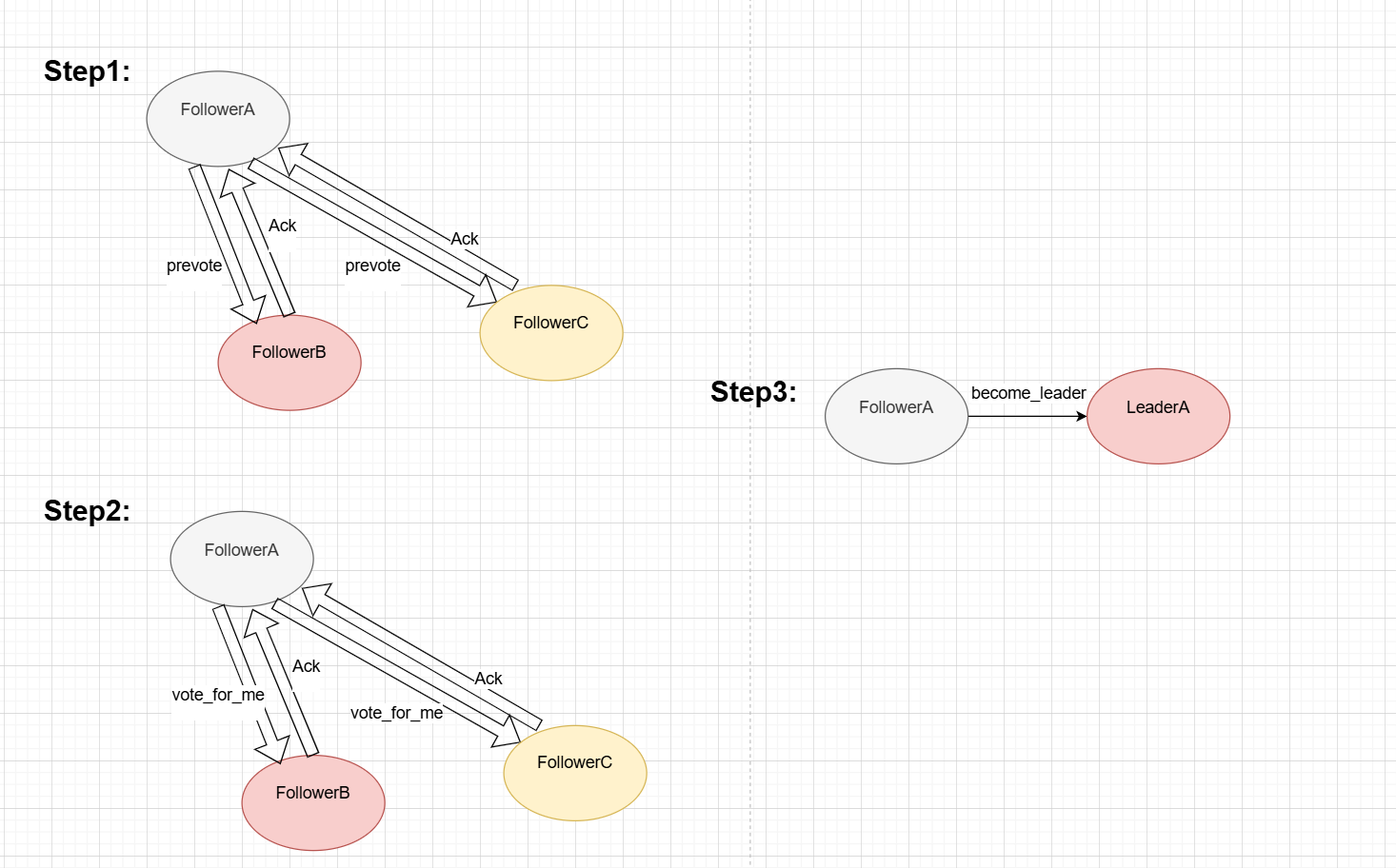
- 1.当election_timeout事件发生后,followerA便按照上图的顺序先向自己的peer-follower发送prevote,得到半数以上的同意后开始下一步。
- 2.followerA通过prevote知道自己网络状态良好,成为candidate,然后发送正式的request_vote请求,得到半数以上的同意后开始下一步。
- 3.followerA调用become_leader,成为leader
2.1.2 election_timeout代码解析:
void raft_server::handle_election_timeout()
{
recur_lock(lock_);
if (steps_to_down_ > 0)
{
if (--steps_to_down_ == 0)
{
l_->info("no hearing further news from leader, remove this server from cluster and step down");
for (std::list<ptr<srv_config>>::iterator it = config_->get_servers().begin();
it != config_->get_servers().end();
++it)
{
if ((*it)->get_id() == id_)
{
config_->get_servers().erase(it);
ctx_->state_mgr_->save_config(*config_);
break;
}
}
ctx_->state_mgr_->system_exit(-1);
return;
}
l_->info(sstrfmt("stepping down (cycles left: %d), skip this election timeout event").fmt(steps_to_down_));
restart_election_timer();
return;
}
if (catching_up_)
{
// this is a new server for the cluster, will not send out vote req until conf that includes this srv is
// committed
l_->info("election timeout while joining the cluster, ignore it.");
restart_election_timer();
return;
}
if (role_ == srv_role::leader)
{
l_->err("A leader should never encounter election timeout, illegal application state, stop the application");
ctx_->state_mgr_->system_exit(-1);
return;
}
if (ctx_->params_->prevote_enabled_ && role_ == srv_role::follower)
{
if (prevote_state_ && !prevote_state_->empty())
{
l_->debug("Election timeout, but there is already a prevote ongoing, ignore this event");
}
else
{
l_->debug("Election timeout, start prevoting");
request_prevote();
}
}
else
{
l_->debug("Election timeout, change to Candidate");
become_candidate();
}
}
- 1.首先steps_to_down_--,判断steps_to_down_是否减为0了,为0则继续下一步,不为0则不处理,重置election_timer。
- 2.判断是不是新加入的server在catching-up集群的log_entry及相应配置信息,是则不处理,重置election_timer,否则继续下一步。
- 3.判断进行了prevote没有,进行了就become_candidate,否则就去prevote。
知识点:
采用step_down机制,给server可能因偶然网络故障一次缓冲的机会,初始化step_down为2,先给step_down--,如果是偶然故障减为1依然还有1次机会。
2.1.3 request_prevote源码解析
void raft_server::request_prevote()
{
l_->info(sstrfmt("prevote started with term %llu").fmt(state_->get_term()));
bool change_to_candidate(false);
{
read_lock(peers_lock_);
if (peers_.size() == 0)
{
change_to_candidate = true;
}
}
if (change_to_candidate)
{
l_->info("prevote done, change to candidate and start voting");
become_candidate();
return;
}
if (!prevote_state_)
{
prevote_state_ = std::make_unique<prevote_state>();
}
prevote_state_->inc_accepted_votes();
prevote_state_->add_voted_server(id_);
{
read_lock(peers_lock_);
for (peer_itor it = peers_.begin(); it != peers_.end(); ++it)
{
ptr<req_msg> req(cs_new<req_msg>(
state_->get_term(),
msg_type::prevote_request,
id_,
it->second->get_id(),
term_for_log(log_store_->next_slot() - 1),
log_store_->next_slot() - 1,
quick_commit_idx_));
l_->debug(sstrfmt("send %s to server %d with term %llu")
.fmt(__msg_type_str[req->get_type()], it->second->get_id(), state_->get_term()));
it->second->send_req(req, ex_resp_handler_);
}
}
}
- 1.特判peer的大小是否为0,为0直接跳过prevote与vote阶段,直接become_candidate,否则继续。
- 2.遍历每一个peer,向peer发送req_msg,类型为msg_type::prevote_request,req_msg里面包含自身的log_store中entry的last_idx,last_term,commit_idx情况给peer决定是否投票。
知识点:
为什么peer的大小为0就直接become_candidate而不是报持follower状态呢?
2.1.4 request_vote源码解析
void raft_server::request_vote()
{
l_->info(sstrfmt("requestVote started with term %llu").fmt(state_->get_term()));
state_->set_voted_for(id_);
ctx_->state_mgr_->save_state(*state_);
votes_granted_ += 1;
voted_servers_.insert(id_);
bool change_to_leader(false);
{
read_lock(peers_lock_);
// is this the only server?
if (votes_granted_ > (int32)(peers_.size() + 1) / 2)
{
election_completed_ = true;
change_to_leader = true;
}
else
{
for (peer_itor it = peers_.begin(); it != peers_.end(); ++it)
{
ptr<req_msg> req(cs_new<req_msg>(
state_->get_term(),
msg_type::vote_request,
id_,
it->second->get_id(),
term_for_log(log_store_->next_slot() - 1),
log_store_->next_slot() - 1,
quick_commit_idx_));
l_->debug(sstrfmt("send %s to server %d with term %llu")
.fmt(__msg_type_str[req->get_type()], it->second->get_id(), state_->get_term()));
it->second->send_req(req, resp_handler_);
}
}
}
if (change_to_leader)
{
become_leader();
}
}
- 整体与prevote类似,关键点在于计算是否有一半以上的节点支持的技巧:
if (votes_granted_ > (int32)(peers_.size() + 1) / 2)
。不管奇数还是偶数,一半以上都是⌊(x + 1) / 2⌋。
2.1.5 become_leader源码解析
void raft_server::become_leader()
{
stop_election_timer();
role_ = srv_role::leader;
leader_ = id_;
srv_to_join_.reset();
ptr<snapshot> nil_snp;
{
read_lock(peers_lock_);
for (peer_itor it = peers_.begin(); it != peers_.end(); ++it)
{
it->second->set_next_log_idx(log_store_->next_slot());
it->second->set_snapshot_in_sync(nil_snp);
it->second->set_free();
enable_hb_for_peer(*(it->second));
}
}
if (config_->get_log_idx() == 0)
{
config_->set_log_idx(log_store_->next_slot());
bufptr conf_buf = config_->serialize();
ptr<log_entry> entry(cs_new<log_entry>(state_->get_term(), std::move(conf_buf), log_val_type::conf));
log_store_->append(entry);
l_->info("save initial config to log store");
config_changing_ = true;
}
if (ctx_->event_listener_)
{
ctx_->event_listener_->on_event(raft_event::become_leader);
}
request_append_entries();
}
- 1.把election_timer给停了,同时更新自身的role等属性。
- 2.清空每一个peer原有leader的信息,同时给每个peer设置hb来宣示自己主权。
- 3.如果config_为空,更新config_
知识点:
这里的election_timeout事件其实不发生在election里面,而是在正常任期内发生的,用于触发election。follower在给定时间内没收到leader消息那么就启动vote,就是通过election_timer来实现的,如果收到了leader消息就restart_election_timer继续定时。
3.leader向follower发送消息
3.1 request_append_entries源码解析
void raft_server::request_append_entries()
{
read_lock(peers_lock_);
if (peers_.size() == 0)
{
commit(log_store_->next_slot() - 1);
return;
}
for (peer_itor it = peers_.begin(); it != peers_.end(); ++it)
{
request_append_entries(*it->second);
}
}
bool raft_server::request_append_entries(peer& p)
{
if (p.make_busy())
{
ptr<req_msg> msg = create_append_entries_req(p);
p.send_req(msg, resp_handler_);
return true;
}
l_->debug(sstrfmt("Server %d is busy, skip the request").fmt(p.get_id()));
return false;
}
ptr<req_msg> raft_server::create_append_entries_req(peer& p)
{
ulong cur_nxt_idx(0L);
ulong commit_idx(0L);
ulong last_log_idx(0L);
ulong term(0L);
ulong starting_idx(1L);
{
recur_lock(lock_);
starting_idx = log_store_->start_index();
cur_nxt_idx = log_store_->next_slot();
commit_idx = quick_commit_idx_;
term = state_->get_term();
}
{
std::lock_guard<std::mutex> guard(p.get_lock());
if (p.get_next_log_idx() == 0L)
{
p.set_next_log_idx(cur_nxt_idx);
}
last_log_idx = p.get_next_log_idx() - 1;
}
if (last_log_idx >= cur_nxt_idx)
{
l_->err(
sstrfmt("Peer's lastLogIndex is too large %llu v.s. %llu, server exits").fmt(last_log_idx, cur_nxt_idx));
ctx_->state_mgr_->system_exit(-1);
return ptr<req_msg>();
}
// for syncing the snapshots, for starting_idx - 1, we can check with last snapshot
if (last_log_idx > 0 && last_log_idx < starting_idx - 1)
{
return create_sync_snapshot_req(p, last_log_idx, term, commit_idx);
}
ulong last_log_term = term_for_log(last_log_idx);
ulong end_idx = std::min(cur_nxt_idx, last_log_idx + 1 + ctx_->params_->max_append_size_);
ptr<std::vector<ptr<log_entry>>> log_entries(
(last_log_idx + 1) >= cur_nxt_idx ? ptr<std::vector<ptr<log_entry>>>()
: log_store_->log_entries(last_log_idx + 1, end_idx));
l_->debug(
lstrfmt("An AppendEntries Request for %d with LastLogIndex=%llu, LastLogTerm=%llu, EntriesLength=%d, "
"CommitIndex=%llu and Term=%llu")
.fmt(p.get_id(), last_log_idx, last_log_term, log_entries ? log_entries->size() : 0, commit_idx, term));
ptr<req_msg> req(cs_new<req_msg>(
term, msg_type::append_entries_request, id_, p.get_id(), last_log_term, last_log_idx, commit_idx));
std::vector<ptr<log_entry>>& v = req->log_entries();
if (log_entries)
{
v.insert(v.end(), log_entries->begin(), log_entries->end());
}
return req;
}
- 1.cornerstone无处不体现封装隔离的思想,将append-entry向所有peer的请求的实现下放到更小粒度的针对单个peer的append-entry,而即使是针对单个peer的append-entry,依然把底层的发送请求与对peer的状态管理分隔开来。
- 2.create_append_entries_req才是底层的发送请求,这里要分三种情况讨论
(1).follower的last_log_idx >= leader的cur_nxt_idx,说明follower
(2).last_log_idx > 0 && last_log_idx < starting_idx - 1,说明follower的log_store差太多,直接给follower安装snapshot而不是按传统发送leader的log_store。
(3).最后一种情况说明follower与leader的log_store有重合,选出非重合的log_store发送给follower。
知识点:
follower的日志落后很多的时候,可以直接发送snapshot加快同步速度。
3.2 create_sync_snapshot_req源码解析
ptr<req_msg> raft_server::create_sync_snapshot_req(peer& p, ulong last_log_idx, ulong term, ulong commit_idx)
{
std::lock_guard<std::mutex> guard(p.get_lock());
ptr<snapshot_sync_ctx> sync_ctx = p.get_snapshot_sync_ctx();
ptr<snapshot> snp;
if (sync_ctx != nilptr)
{
snp = sync_ctx->get_snapshot();
}
if (!snp || (last_snapshot_ && last_snapshot_->get_last_log_idx() > snp->get_last_log_idx()))
{
snp = last_snapshot_;
if (snp == nilptr || last_log_idx > snp->get_last_log_idx())
{
l_->err(lstrfmt("system is running into fatal errors, failed to find a snapshot for peer %d(snapshot null: "
"%d, snapshot doesn't contais lastLogIndex: %d")
.fmt(p.get_id(), snp == nilptr ? 1 : 0, last_log_idx > snp->get_last_log_idx() ? 1 : 0));
ctx_->state_mgr_->system_exit(-1);
return ptr<req_msg>();
}
if (snp->size() < 1L)
{
l_->err("invalid snapshot, this usually means a bug from state machine implementation, stop the system to "
"prevent further errors");
ctx_->state_mgr_->system_exit(-1);
return ptr<req_msg>();
}
l_->info(sstrfmt("trying to sync snapshot with last index %llu to peer %d")
.fmt(snp->get_last_log_idx(), p.get_id()));
p.set_snapshot_in_sync(snp);
}
ulong offset = p.get_snapshot_sync_ctx()->get_offset();
int32 sz_left = (int32)(snp->size() - offset);
int32 blk_sz = get_snapshot_sync_block_size();
bufptr data = buffer::alloc((size_t)(std::min(blk_sz, sz_left)));
int32 sz_rd = state_machine_->read_snapshot_data(*snp, offset, *data);
if ((size_t)sz_rd < data->size())
{
l_->err(
lstrfmt(
"only %d bytes could be read from snapshot while %d bytes are expected, must be something wrong, exit.")
.fmt(sz_rd, data->size()));
ctx_->state_mgr_->system_exit(-1);
return ptr<req_msg>();
}
bool done = (offset + (ulong)data->size()) >= snp->size();
std::unique_ptr<snapshot_sync_req> sync_req(new snapshot_sync_req(snp, offset, std::move(data), done));
ptr<req_msg> req(cs_new<req_msg>(
term,
msg_type::install_snapshot_request,
id_,
p.get_id(),
snp->get_last_log_term(),
snp->get_last_log_idx(),
commit_idx));
req->log_entries().push_back(cs_new<log_entry>(term, sync_req->serialize(), log_val_type::snp_sync_req));
return req;
}
- 1.首先获取旧的snapshot,判断是否能更新,能的话就更新。
- 2.把snapshot绑定到peer身上,因为snapshot挺大,需要分段发,所以要绑定到peer身上。
- 3.offset记录snapshot发送到哪里了,bool done就是记录是否发送完了snapshot。
- 4.发送snapshot_req。
知识点:
即使使用了offset记录发送的偏移,但是根据这里的代码很明显只发送了一次,那怎么能做到分段发送呢?
答案在cornerstone对于resp的处理里面,因为客户端接受snapshot,安装snapshot需要一定时间。不可能leader发送完一段snapshot紧跟着又发送下一段,leader需要等待follower处理完当前一段snapshot发送ack过来后再发送下一段,收到follower的resp后leader会再次调用这个函数,实现分段发送。
4.集群cluster的变更
4.1 cluster添加server
ptr<async_result<bool>> raft_server::add_srv(const srv_config& srv)
{
bufptr buf(srv.serialize());
ptr<log_entry> log(cs_new<log_entry>(0, std::move(buf), log_val_type::cluster_server));
ptr<req_msg> req(cs_new<req_msg>((ulong)0, msg_type::add_server_request, 0, 0, (ulong)0, (ulong)0, (ulong)0));
req->log_entries().push_back(log);
return send_msg_to_leader(req);
}
ptr<async_result<bool>> raft_server::send_msg_to_leader(ptr<req_msg>& req)
{
typedef std::unordered_map<int32, ptr<rpc_client>>::const_iterator rpc_client_itor;
int32 leader_id = leader_;
ptr<cluster_config> cluster = config_;
bool result(false);
if (leader_id == -1)
{
return cs_new<async_result<bool>>(result);
}
if (leader_id == id_)
{
ptr<resp_msg> resp = process_req(*req);
result = resp->get_accepted();
return cs_new<async_result<bool>>(result);
}
ptr<rpc_client> rpc_cli;
{
auto_lock(rpc_clients_lock_);
rpc_client_itor itor = rpc_clients_.find(leader_id);
if (itor == rpc_clients_.end())
{
ptr<srv_config> srv_conf = config_->get_server(leader_id);
if (!srv_conf)
{
return cs_new<async_result<bool>>(result);
}
rpc_cli = ctx_->rpc_cli_factory_->create_client(srv_conf->get_endpoint());
rpc_clients_.insert(std::make_pair(leader_id, rpc_cli));
}
else
{
rpc_cli = itor->second;
}
}
if (!rpc_cli)
{
return cs_new<async_result<bool>>(result);
}
ptr<async_result<bool>> presult(cs_new<async_result<bool>>());
rpc_handler handler = [presult](ptr<resp_msg>& resp, const ptr<rpc_exception>& err) -> void
{
bool rpc_success(false);
ptr<std::exception> perr;
if (err)
{
perr = err;
}
else
{
rpc_success = resp && resp->get_accepted();
}
presult->set_result(rpc_success, perr);
};
rpc_cli->send(req, handler);
return presult;
}
- add_srv先生成一个req,把变更的srv信息存到req附带的log里面。由于不是用于follower与leader之间的log_store同步,所以原来的last_log_idx,last_log_term,commit_idx全部为0。
- 调用send_msg_to_leader向leader发送变更srv的信息
4.2 cluster移除server
ptr<async_result<bool>> raft_server::remove_srv(const int srv_id)
{
bufptr buf(buffer::alloc(sz_int));
buf->put(srv_id);
buf->pos(0);
ptr<log_entry> log(cs_new<log_entry>(0, std::move(buf), log_val_type::cluster_server));
ptr<req_msg> req(cs_new<req_msg>((ulong)0, msg_type::remove_server_request, 0, 0, (ulong)0, (ulong)0, (ulong)0));
req->log_entries().push_back(log);
return send_msg_to_leader(req);
}
5.总结
- 1.合理架构raft中各角色关系,采用一个server外加peers的组合,server内部可follower,candidate,leader相互转换。
- 2.采用step_down机制,给server可能因偶然网络故障一次缓冲的机会。
- 3.计算是否有一半以上的节点支持的技巧:if (votes_granted_ > (int32)(peers_.size() + 1) / 2)。不管奇数还是偶数,一半以上都是⌊(x + 1) / 2⌋。
- 4.follower的日志落后很多的时候,可以直接发送snapshot加快同步速度。
- 5.发送大文件采用offset机制分段传送。