绝了!一次性掌握 6 种超厉害在线测试数据自动生成神器!
在软件测试领域,测试数据的生成是一个至关重要的环节。手动生成数据不仅耗时耗力,而且难以保证数据的质量和多样性。因此,使用在线测试数据生成器成为了许多测试人员的首选。
本文将介绍6种超牛的在线测试数据生成器,帮助你更高效地生成测试数据。
1、Mockaroo
Mockaroo
是一款在线数据生成工具,提供超过125种数据类型,包括姓名、地址、日期、图片等。用户可以自定义数据结构,生成符合实际需求的测试数据。
在线地址:
https://www.mockaroo.com/
特点:
- 支持大量数据类型和自定义结构
- 一次可生成高达100万条数据
- 支持多种数据导出格式(如CSV、JSON、SQL等)
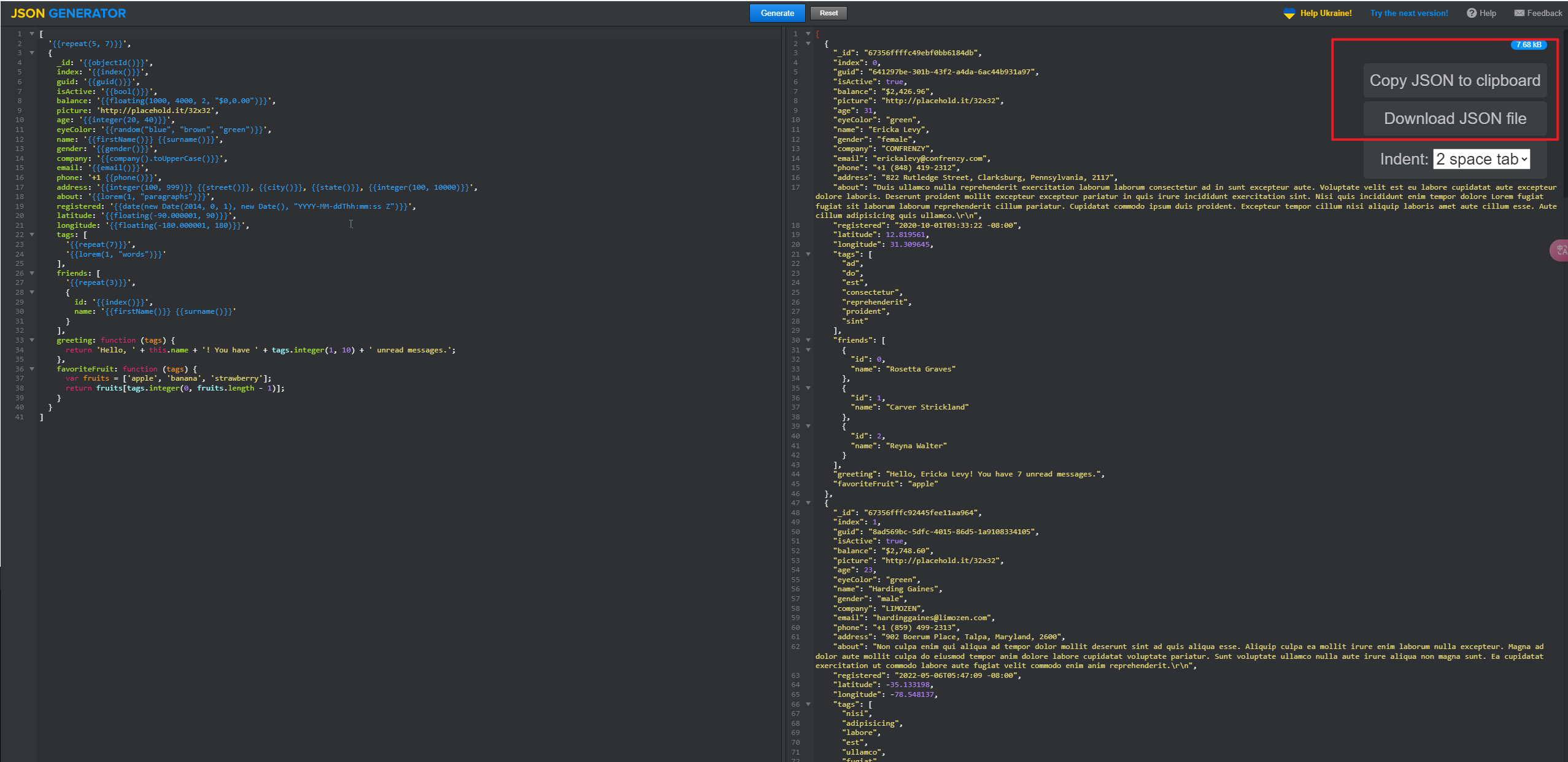
2、JSON-Generator
JSON-Generator
主要专注于生成 JSON 格式的测试数据。
在线地址:
https://json-generator.com/
特点:
- 针对 JSON 优化:它对 JSON 数据结构有着深入的理解和优化。用户可以轻松地定义 JSON 对象、数组等复杂结构。例如,可以快速生成一个包含多个嵌套对象和数组的 JSON 数据,用于测试处理复杂 JSON 数据的 API 或系统。
- 可视化编辑界面:拥有一个直观的可视化编辑界面,即使是没有深厚技术背景的用户也能快速上手。通过简单的拖放和设置参数操作,就可以构建出复杂的 JSON 数据结构。例如,用户可以在界面上添加新的 JSON 属性、设置属性的值类型和范围,然后立即看到生成的 JSON 数据示例。
- 代码生成功能:除了直接生成 JSON 数据外,JSON - Generator 还可以生成用于生成 JSON 数据的代码。这对于需要在程序中动态生成 JSON 数据的开发人员来说非常方便。用户可以选择不同的编程语言(如 JavaScript、Python 等),生成相应的代码片段。
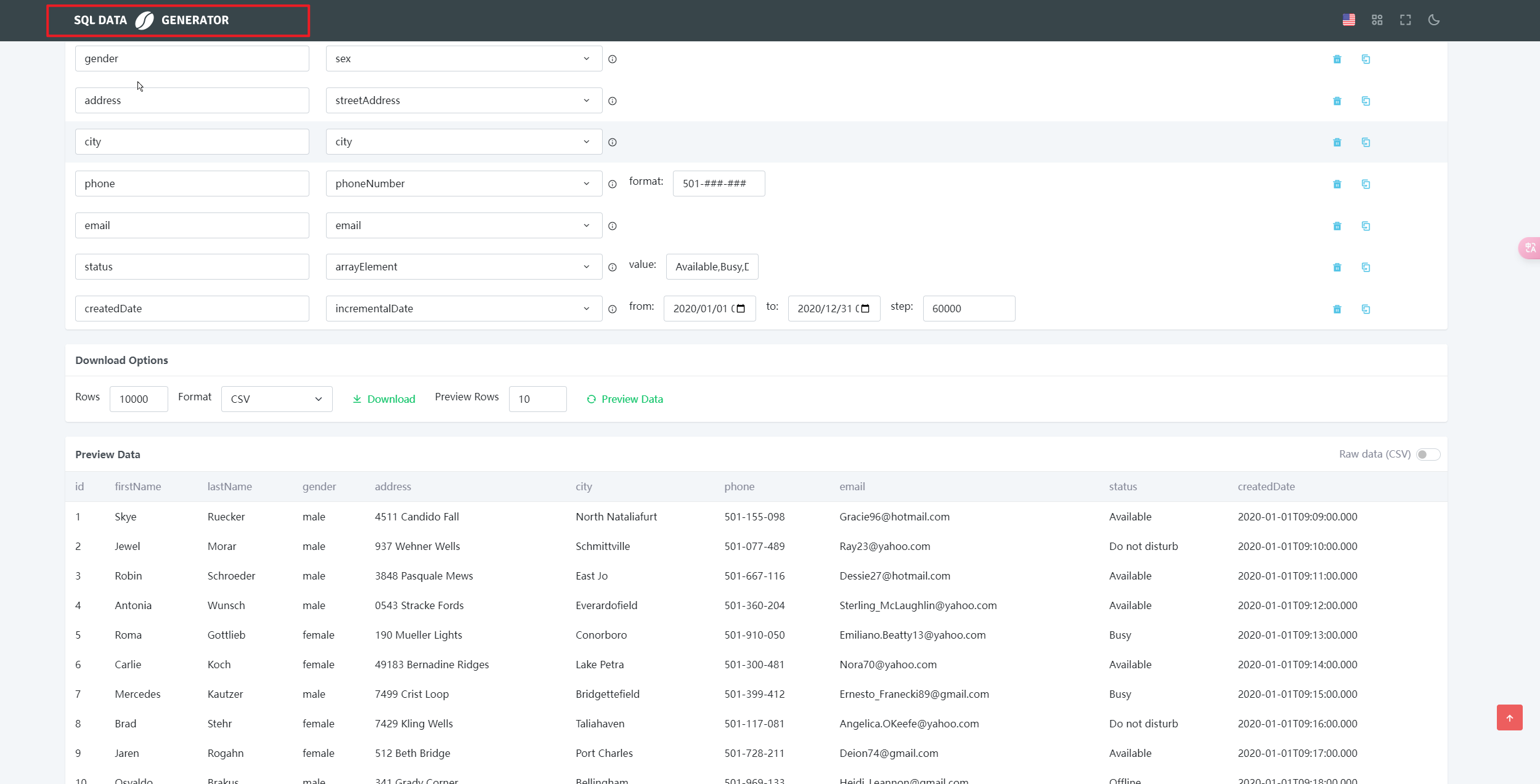
3、SQL-Data Generator
SQL-Data Generator
是专门为生成用于 SQL 数据库测试数据而设计的工具。
在线地址:
https://sqldatagenerator.com/generator
特点:
数据库兼容性强:它支持多种主流的 SQL 数据库,如 MySQL、Oracle、SQL Server 等。无论你的测试环境使用哪种数据库管理系统,都可以使用 SQL - Data - Generator 生成合适的数据。例如,它可以根据不同数据库的特定数据类型和语法规则,生成符合要求的插入语句或数据文件。
数据库架构感知:能够识别数据库的架构信息,根据表结构、字段类型、约束条件等生成有效的测试数据。如果数据库中有表之间的关联关系(如外键约束),SQL - Data - Generator 可以生成符合这些关系的数据。例如,在生成订单数据和客户数据时,会根据订单表中的客户外键关系,确保生成的订单数据中的客户 ID 与客户表中的数据相匹配。
数据更新和删除模拟:除了生成插入数据外,还可以模拟数据库中的数据更新和删除操作。用户可以指定数据更新的规则和条件,以及删除数据的范围,用于测试数据库的更新和删除功能的正确性和性能。例如,可以设置按照一定比例更新某些字段的值,或者根据特定条件删除部分数据,以模拟实际数据库操作中的各种情况。
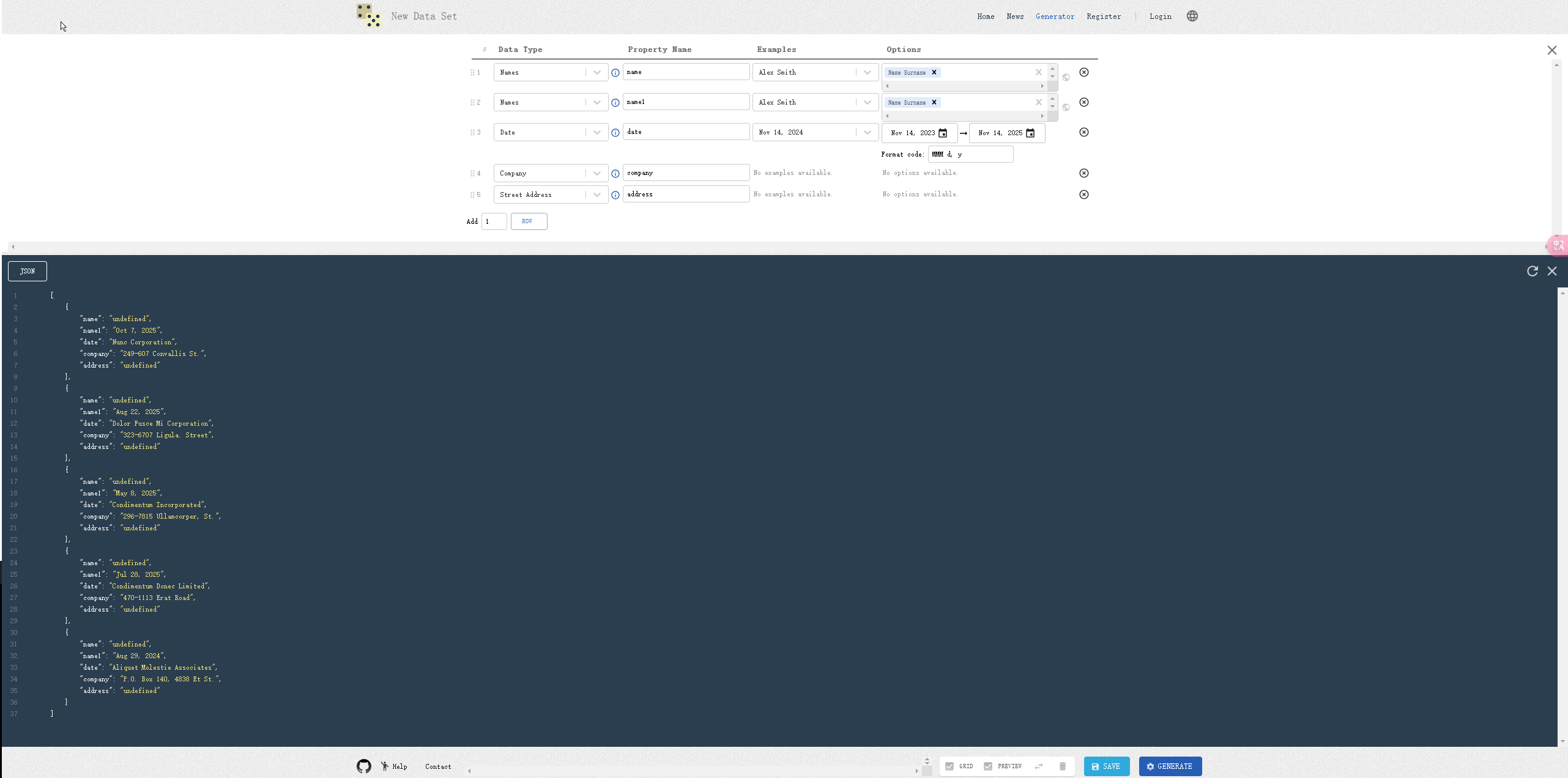
4、Generatedata
Generatedata
是一款开源的在线测试数据生成器,它支持30多种数据类型,包括姓名、电子邮件、地址、电话号码等,并支持多种导出格式,如CSV、SQL、JSON等。此外它还支持自定义数据类型和生成规则,用户可以创建复杂的数据结构,生成大量测试数据。且支持REST API,可以方便地进行数据生成和集成。
在线地址:
https://generatedata.com/generator
特点:
- 开源、免费
- 支持自定义数据类型和生成规则
- 支持多种数据导出格式(如CSV、JSON、SQL等)
5、Randat
Randat
是一个免费的在线工具,可以生成包含随机个人信息的表格,如姓名、年龄、职业、薪水等。用户只需选择首选列和行数,然后点击“Generate”按钮即可生成表格。生成的表格可以以XLS、XLSX或CSV格式导出,方便用户进行后续处理。Randat非常适合用于生成具有特定属性的测试数据。
在线地址:
http://www.randat.com/

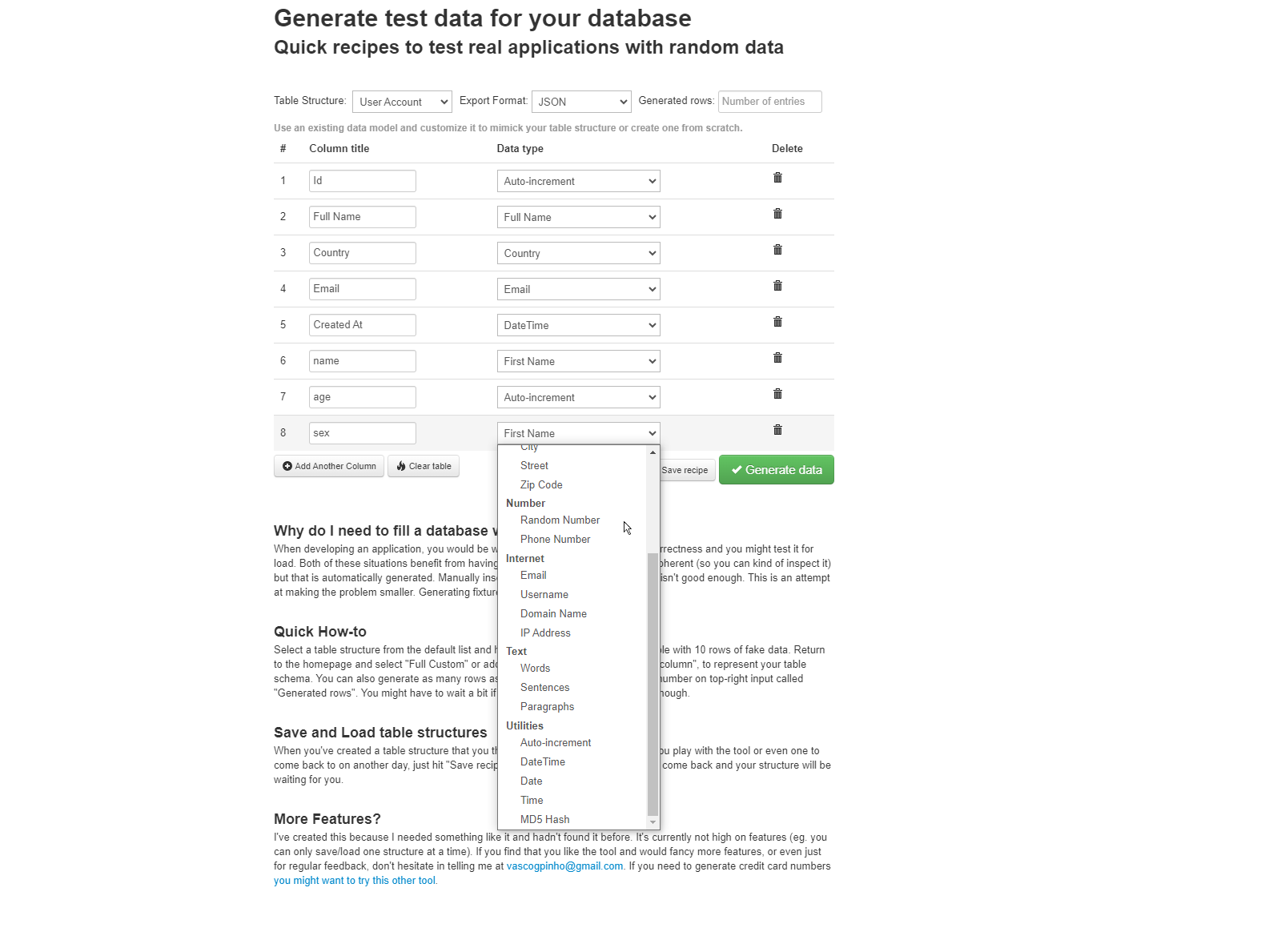
6、DatabaseTestData
DatabaseTestData
用于生成测试数据。它允许用户基于现有数据模型进行自定义,以重现表结构或从头开始创建一个表。这使得数据生成更加贴近实际场景,提高了测试数据的可用性。DatabaseTestData界面简洁易用,适合快速生成测试数据。
在线地址:
https://www.databasetestdata.com/
小结
测试数据生成器是软件测试中不可或缺的工具,它们可以自动生成大量具有各种属性的测试数据,从而节省时间和精力,提高测试效率。本文介绍的8种在线测试数据生成器各具特色,适用于不同的测试场景和需求。在选择测试数据生成器时,应根据自己的实际需求进行选择和配置,以生成高质量的测试数据,确保软件质量和稳定性。