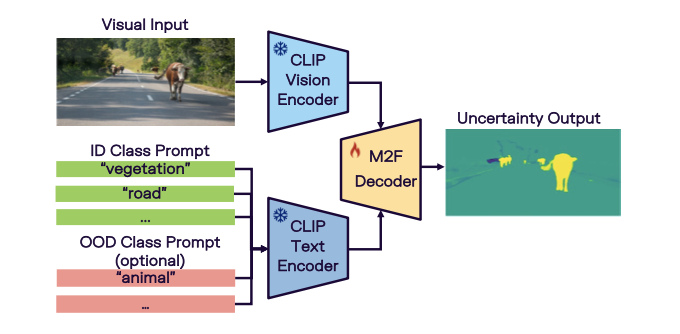
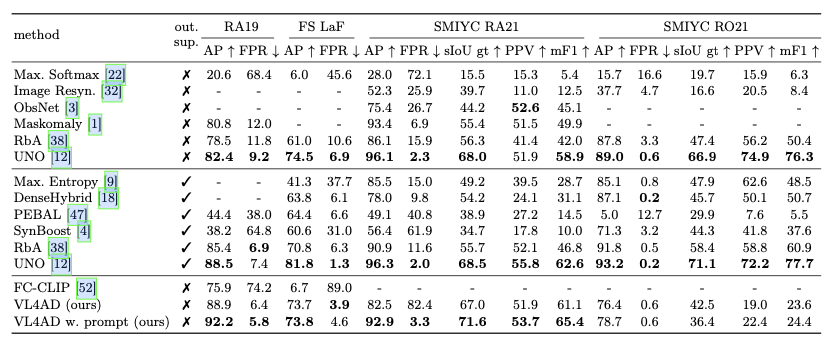
技术背景
在前面的一篇
博客
中我们介绍了MindSpore-2.4-gpu的安装和其中可能出现的一些问题。这里我们在安装完成之后,可以尝试使用一些MindSpore新版本的特性。那么在安装之后,如果是使用VSCode作为IDE,可以使用ctrl+shift+P快捷键,然后搜索
python:sele
将Python解释器切换到我们所需要的最新MindSpore环境下。
设备管理和资源监测
在mindspore-2.4版本中增加了
mindspore.hal
接口,可以用于管理设备、监测设备以及执行流的处理等等。例如,常用的获取设备的数量:
import mindspore as ms
ms.set_context(device_target="GPU")
device_target = ms.context.get_context("device_target")
print(ms.hal.device_count(device_target))
# 2
这个输出表明我们的环境下有两个GPU卡。也可以打印这两块显卡的名称:
import mindspore as ms
ms.set_context(device_target="GPU")
device_target = ms.context.get_context("device_target")
print(ms.hal.get_device_name(0, device_target))
print(ms.hal.get_device_name(1, device_target))
# Quadro RTX 4000
# Quadro RTX 4000
以及设备的可用状态:
import mindspore as ms
ms.set_context(device_target="GPU")
device_target = ms.context.get_context("device_target")
print(ms.hal.is_available(device_target))
# True
查询设备是否被初始化:
import mindspore as ms
ms.set_context(device_target="GPU")
device_target = ms.context.get_context("device_target")
print(ms.hal.is_initialized(device_target))
A = ms.Tensor([0.], ms.float32)
A2 = (A+A).asnumpy()
print(ms.hal.is_initialized(device_target))
# False
# True
这也说明,只有在计算的过程中,MindSpore才会将Tensor的数据传输到计算后端。除了设备管理之外,新版本的MindSpore还支持了一些内存监测的功能,对于性能管理非常的实用:
import mindspore as ms
import numpy as np
ms.set_context(device_target="GPU")
A = ms.Tensor(np.random.random(1000), ms.float32)
A2 = (A+A).asnumpy()
print(ms.hal.max_memory_allocated())
# 8192
这里输出的占用最大显存的Tensor的大小。需要说明的是,这里不能直接按照浮点数占用空间来进行计算,应该说MindSpore在构建图的过程中会产生一些额外的数据结构,这些数据结构也会占用一定的显存,但是显存增长的趋势是准确的。除了单个的打印,还可以整个的输出一个summary:
import mindspore as ms
import numpy as np
ms.set_context(device_target="GPU")
A = ms.Tensor(np.random.random(1000), ms.float32)
A2 = (A+A).asnumpy()
print(ms.hal.memory_summary())
输出的结果为:
|=============================================|
| Memory summary |
|=============================================|
| Metric | Data |
|---------------------------------------------|
| Reserved memory | 1024 MB |
|---------------------------------------------|
| Allocated memory | 4096 B |
|---------------------------------------------|
| Idle memory | 1023 MB |
|---------------------------------------------|
| Eager free memory | 0 B |
|---------------------------------------------|
| Max reserved memory | 1024 MB |
|---------------------------------------------|
| Max allocated memory | 8192 B |
|=============================================|
ForiLoop
其实简单来说就是一个内置的for循环的操作,类似于Jax中的fori_loop:
import mindspore as ms
import numpy as np
from mindspore import ops
ms.set_context(device_target="GPU")
@ms.jit
def f(_, x):
return x + x
A = ms.Tensor(np.ones(10), ms.float32)
N = 3
AN = ops.ForiLoop()(0, N, f, A).asnumpy()
print (AN)
# [8. 8. 8. 8. 8. 8. 8. 8. 8. 8.]
有了这个新的for循环体,我们可以对整个循环体做端到端自动微分:
import mindspore as ms
import numpy as np
from mindspore import ops, grad
ms.set_context(device_target="GPU", mode=ms.GRAPH_MODE)
@ms.jit
def f(_, x):
return x + x
@ms.jit
def s(x, N):
return ops.ForiLoop()(0, N, f, x)
A = ms.Tensor(np.ones(10), ms.float32)
N = 3
AN = grad(s, grad_position=(0, ))(A, N).asnumpy()
print (AN)
# [8. 8. 8. 8. 8. 8. 8. 8. 8. 8.]
流计算
CUDA Stream流计算是CUDA高性能编程中必然会用到的一个特性,其性能优化点来自于数据传输和浮点数运算的分离,可以做到在不同的Stream中传输数据,这样就达到了一边传输数据一边计算的效果。相比于单个Stream的
传输-计算-等待-传输-计算
这样的模式肯定是要更快一些,而有些深度学习框架其实很早就已经支持了Stream的调度,MindSpore目前也是跟上了节奏。关于Stream计算适用的一些场景,首先我们来看这样一个例子:
import mindspore as ms
import numpy as np
np.random.seed(0)
from mindspore import numpy as msnp
ms.set_context(device_target="GPU", mode=ms.GRAPH_MODE)
@ms.jit
def U(x, mu=1.0, k=1.0):
return msnp.sum(0.5 * k * (x-mu) ** 2)
x = ms.Tensor(np.ones(1000000000), ms.float32)
energy = U(x)
print (energy)
在本地环境下执行就会报错:
Traceback (most recent call last):
File "/home/dechin/projects/gitee/dechin/tests/test_ms.py", line 13, in <module>
energy = U(x)
File "/home/dechin/anaconda3/envs/mindspore-master/lib/python3.9/site-packages/mindspore/common/api.py", line 960, in staging_specialize
out = _MindsporeFunctionExecutor(func, hash_obj, dyn_args, process_obj, jit_config)(*args, **kwargs)
File "/home/dechin/anaconda3/envs/mindspore-master/lib/python3.9/site-packages/mindspore/common/api.py", line 188, in wrapper
results = fn(*arg, **kwargs)
File "/home/dechin/anaconda3/envs/mindspore-master/lib/python3.9/site-packages/mindspore/common/api.py", line 588, in __call__
output = self._graph_executor(tuple(new_inputs), phase)
RuntimeError:
----------------------------------------------------
- Memory not enough:
----------------------------------------------------
Device(id:0) memory isn't enough and alloc failed, kernel name: 0_Default/Sub-op0, alloc size: 4000000000B.
----------------------------------------------------
- C++ Call Stack: (For framework developers)
----------------------------------------------------
mindspore/ccsrc/runtime/graph_scheduler/graph_scheduler.cc:1066 Run
说明出现了内存不足的情况。通常情况下,可能需要手动做一个拆分,然后使用循环体遍历:
import time
import mindspore as ms
import numpy as np
from mindspore import numpy as msnp
ms.set_context(device_target="GPU", mode=ms.GRAPH_MODE)
@ms.jit
def U(x, mu=1.0, k=1.0):
return msnp.sum(0.5 * k * (x-mu) ** 2)
def f(x, N=1000, size=1000000):
ene = 0.
start_time = time.time()
for i in range(N):
x_tensor = ms.Tensor(x[i*size:(i+1)*size], ms.float32)
ene += U(x_tensor)
end_time = time.time()
print ("The calculation time cost is: {:.3f} s".format(end_time - start_time))
return ene.asnumpy()
x = np.ones(1000000000)
energy = f(x)
print (energy)
# The calculation time cost is: 11.732 s
# 0.0
这里至少没有报内存错误了,因为每次只有在计算的时候我们才把相应的部分拷贝到显存中。接下来使用流计算,也就是边拷贝边计算的功能:
def f_stream(x, N=1000, size=1000000):
ene = 0.
s1 = ms.hal.Stream()
s2 = ms.hal.Stream()
start_time = time.time()
for i in range(N):
if i % 2 == 0:
with ms.hal.StreamCtx(s1):
x_tensor = ms.Tensor(x[i*size:(i+1)*size], ms.float32)
ene += U(x_tensor)
else:
with ms.hal.StreamCtx(s2):
x_tensor = ms.Tensor(x[i*size:(i+1)*size], ms.float32)
ene += U(x_tensor)
ms.hal.synchronize()
end_time = time.time()
print ("The calculation with stream time cost is: {:.3f} s".format(end_time - start_time))
return ene.asnumpy()
因为要考虑到程序编译对性能带来的影响,所以这里使用与不使用Stream的对比需要分开执行。经过多次测试之后,不使用Stream的运行时长大约为:
The calculation time cost is: 10.925 s
41666410.0
而使用Stream的运行时长大约为:
The calculation with stream time cost is: 9.929 s
41666410.0
就直观而言,Stream计算在MindSpore中有可能带来一定的加速效果,但其实这种加速效果相比于直接写CUDA Stream带来的效果增益其实要弱一些,可能跟编译的逻辑有关系。但至少现在有了Stream这样的一个工具可以在MindSpore中直接调用,就可以跟很多同类型的框架同步竞争了。
总结概要
接上一篇对于MindSpore-2.4-gpu版本的安装介绍,本文主要介绍一些MindSpore-2.4版本中的新特性,例如使用hal对设备和流进行管理,进而支持Stream流计算。另外还有类似于Jax中的fori_loop方法,MindSpore最新版本中也支持了ForiLoop循环体,使得循环的执行更加高效,也是端到端自动微分的强大利器之一。
版权声明
本文首发链接为:
https://www.cnblogs.com/dechinphy/p/ms24.html
作者ID:DechinPhy
更多原著文章:
https://www.cnblogs.com/dechinphy/
请博主喝咖啡:
https://www.cnblogs.com/dechinphy/gallery/image/379634.html