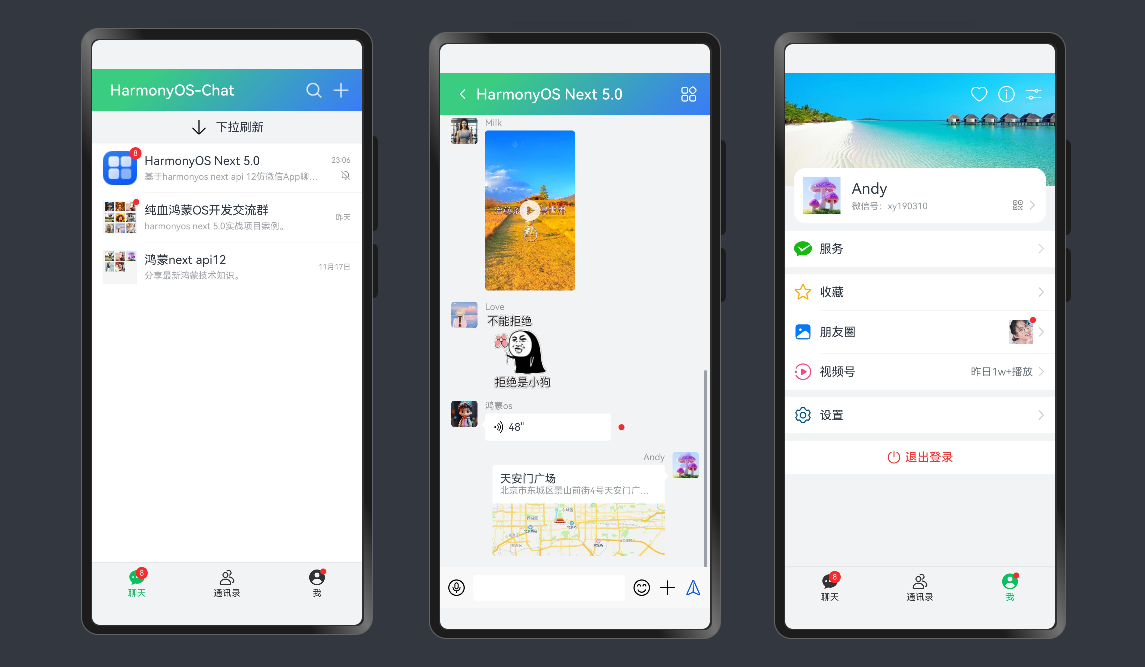
HarmonyOS-Chat聊天室|纯血鸿蒙Next5 api12聊天app|ArkUI仿微信
自研
原生鸿蒙NEXT5.0 API12 ArkTS
仿微信
app聊天
模板
HarmonyOSChat
。
harmony-wechat
原创重磅实战
纯血鸿蒙OS ArkUI+ArkTs仿微信App
聊天实例。包括
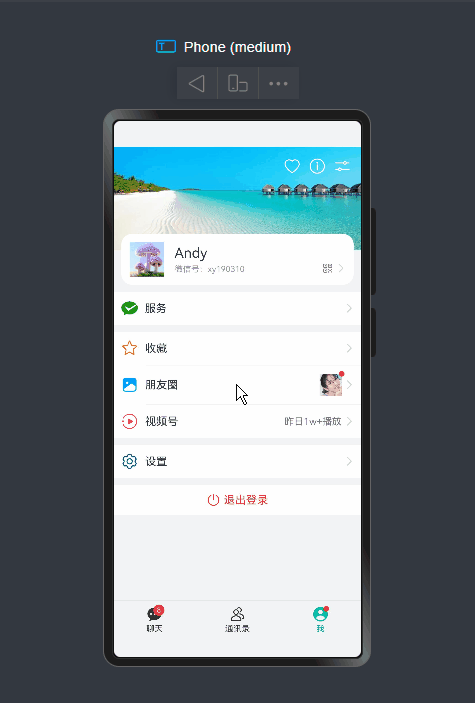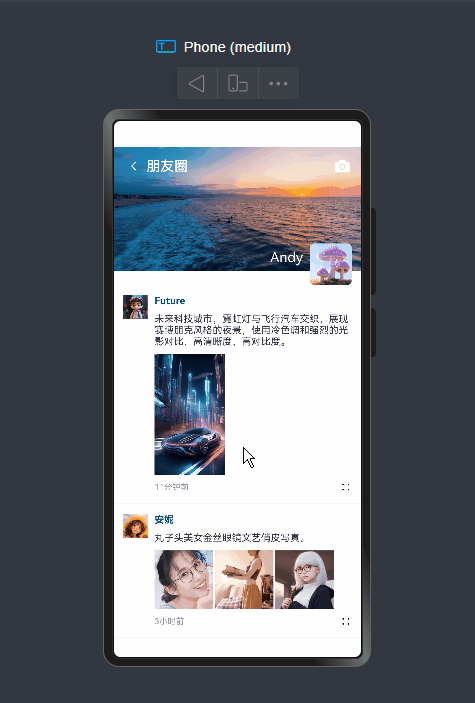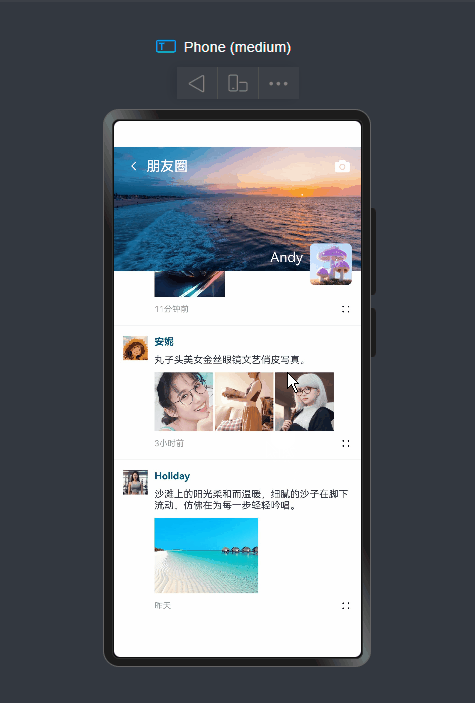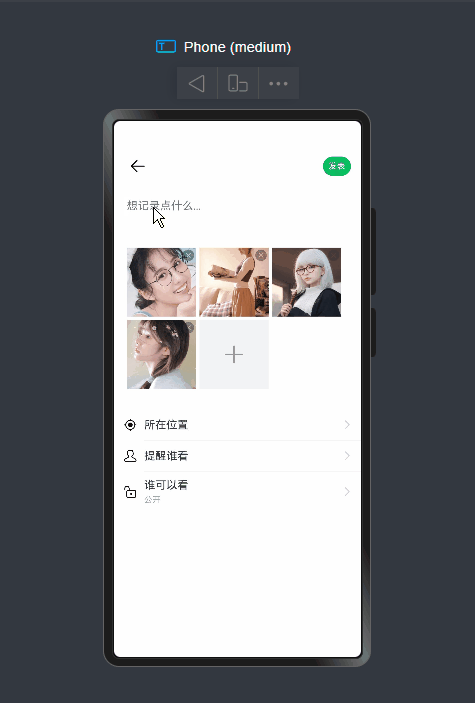
聊天、通讯录、我、朋友圈
等模块,实现类似
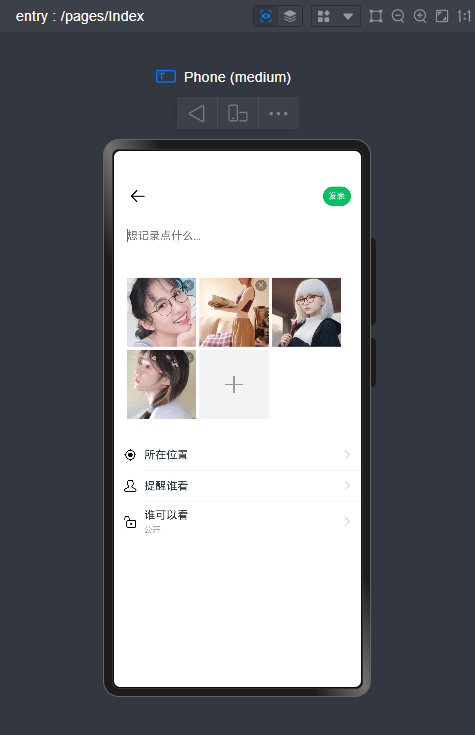
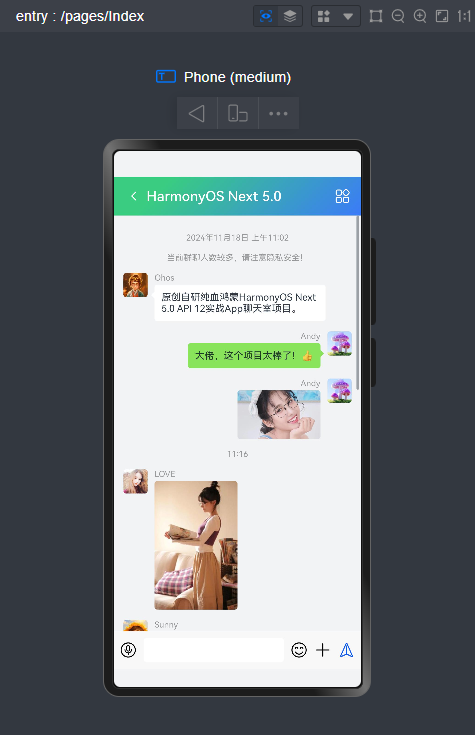
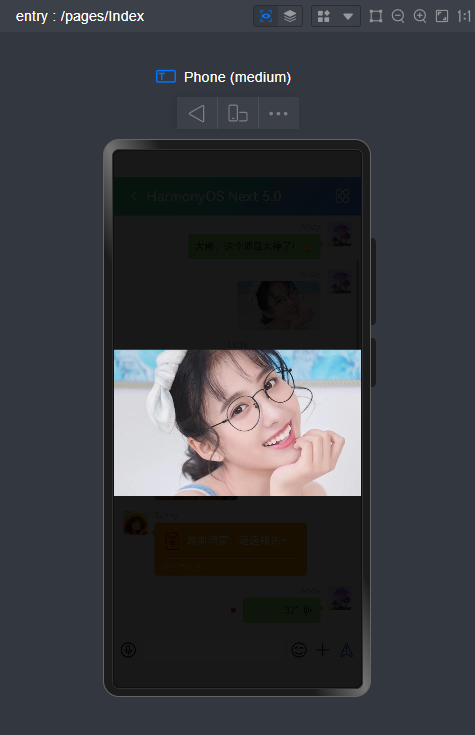
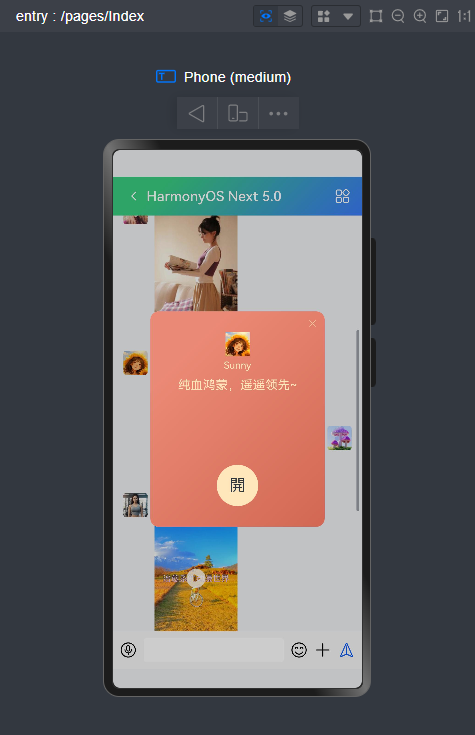
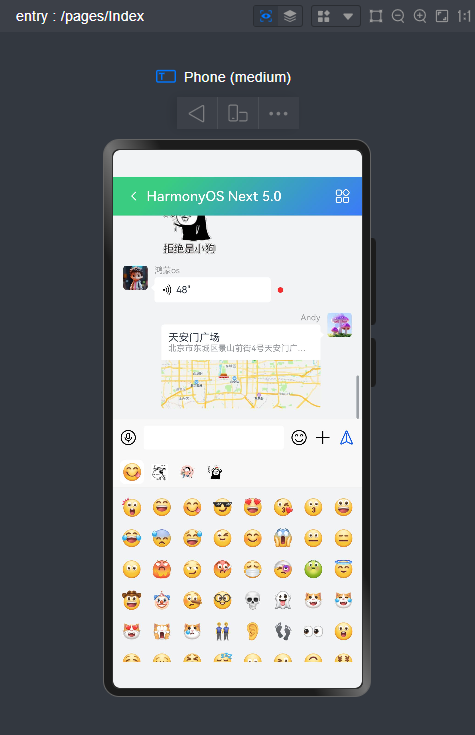
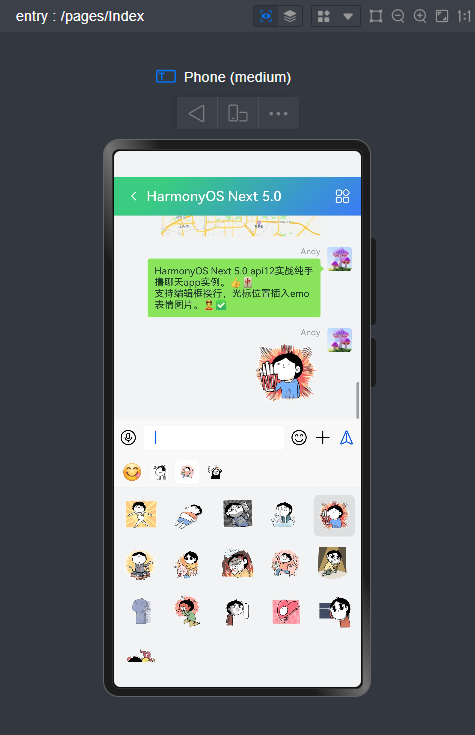
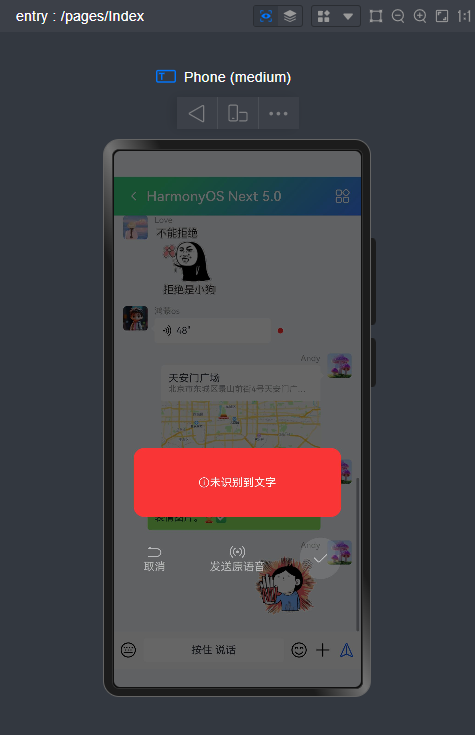
微信消息UI布局、编辑器光标处输入文字+emo表情图片/GIF动图、图片预览、红包、语音/位置UI、长按语音面板
等功能。
版本信息
DevEco Studio 5.0.3.906HarmonyOS5.0.0API12 Release SDK
commandline-tools-windows-x64-5.0.3.906

纯血鸿蒙OS元年已来,华为大力推广自主研发的全场景分布操作系统HarmonyOS,赶快加入鸿蒙原生应用开发,未来可期!
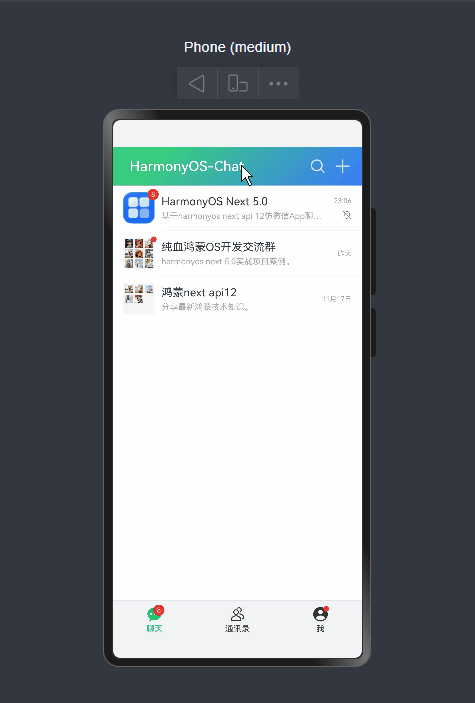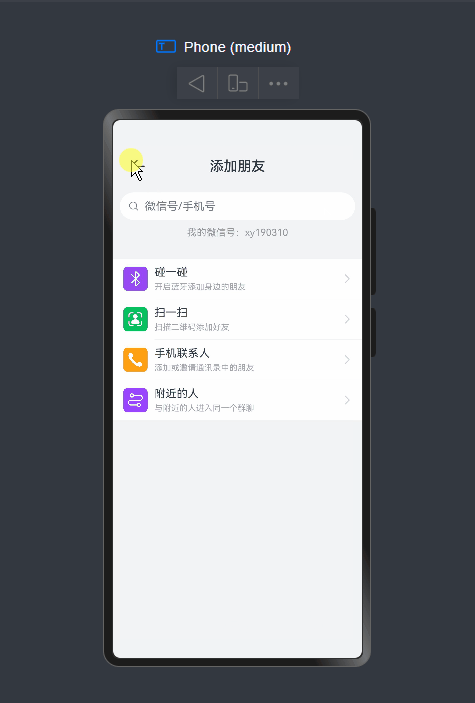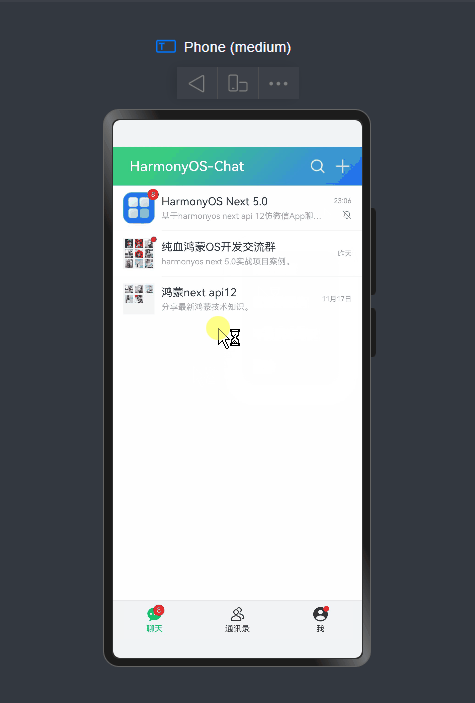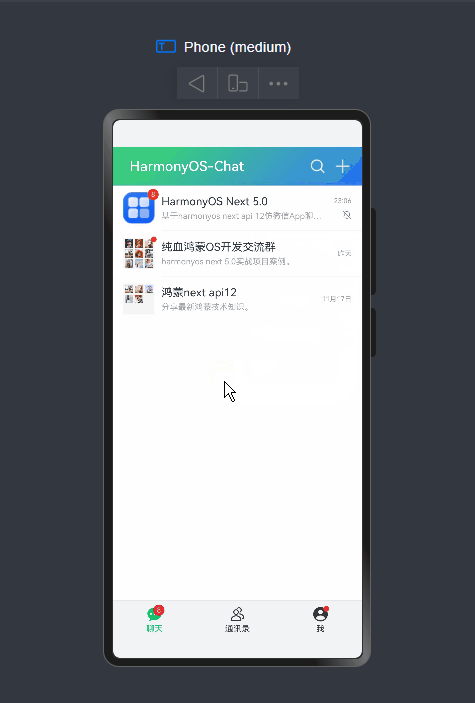
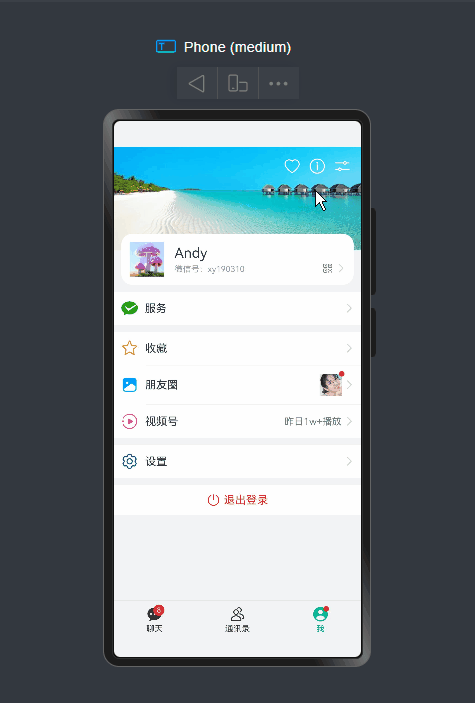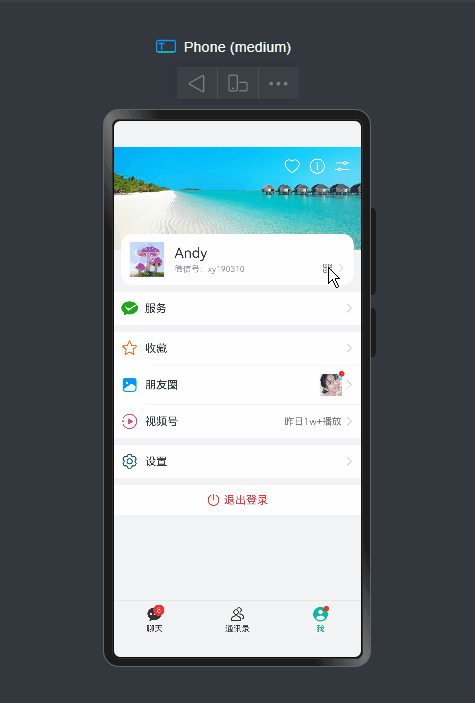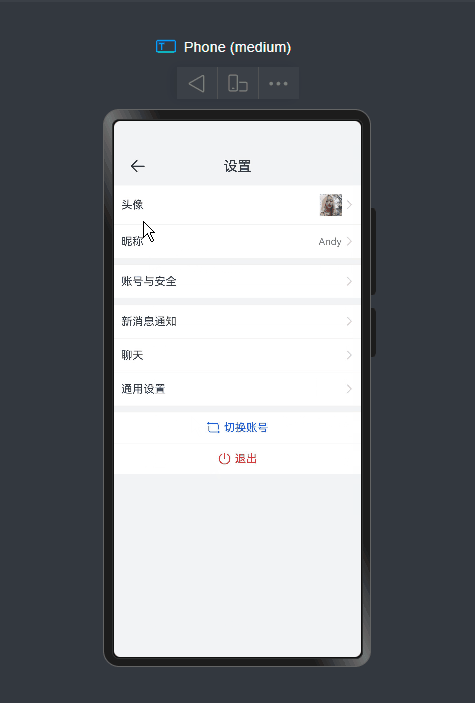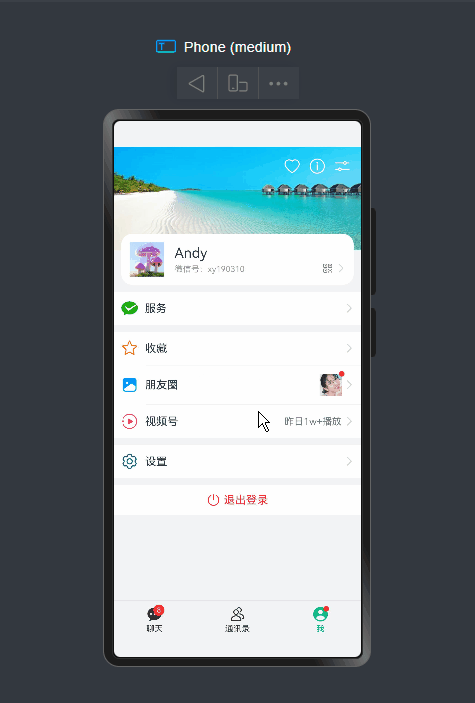
基于鸿蒙os
ArkTs
和
ArkUI
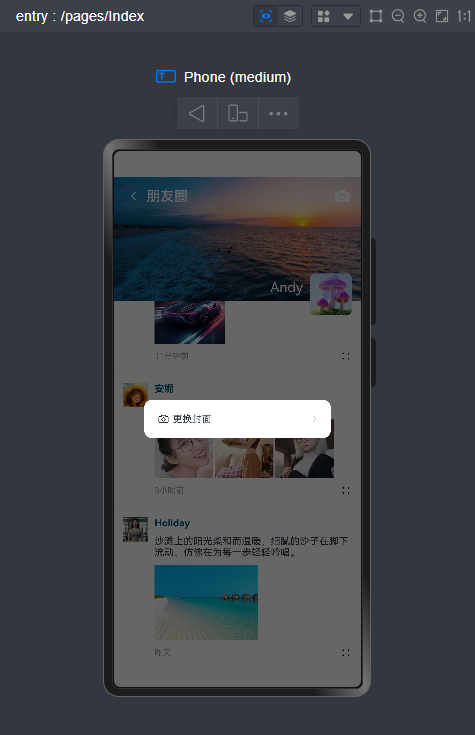
实现下拉刷新、右键长按/下拉菜单、自定义弹窗、朋友圈等功能。
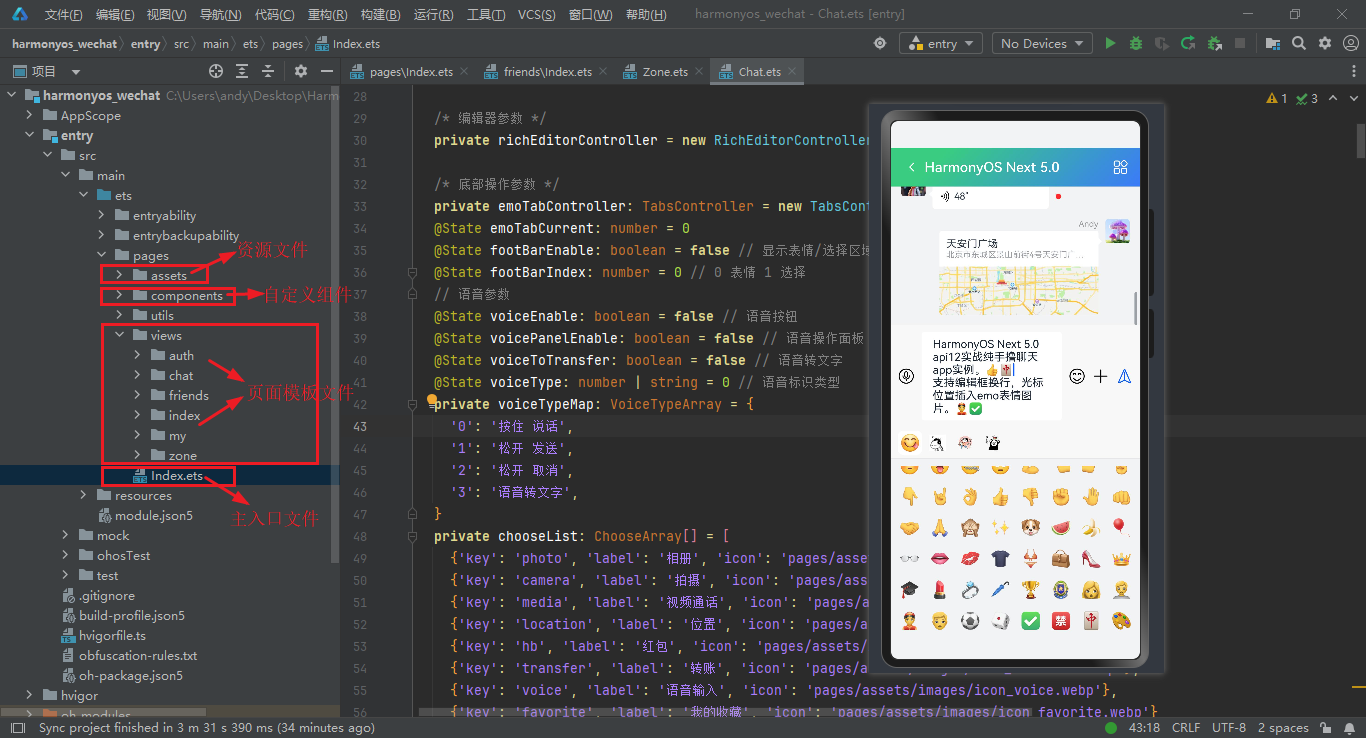
项目框架结构
基于最新版
DevEco Studio 5.0.3.906
编码工具构建鸿蒙app聊天项目模板。
https://developer.huawei.com/consumer/cn/deveco-studio/
HarmonyOS-Chat聊天app项目已经发布到我的原创作品集,有需要的可以去拍哈~
如果大家想快速的入门到进阶开发,先把官方文档撸一遍,然后找个实战项目案例练练手。

华为鸿蒙os开发官网
https://developer.huawei.com/consumer/cn/
HarmonyOS开发设计规范
https://developer.huawei.com/consumer/cn/design/
ArkUI方舟UI框架
https://developer.huawei.com/consumer/cn/doc/harmonyos-references-V5/arkui-declarative-comp-V5
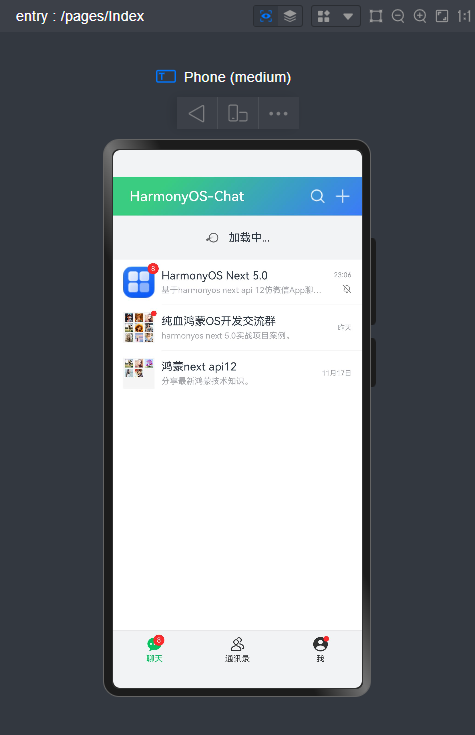
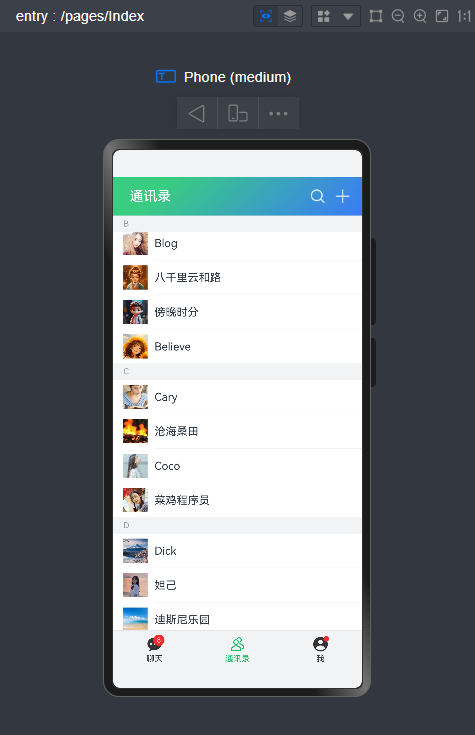
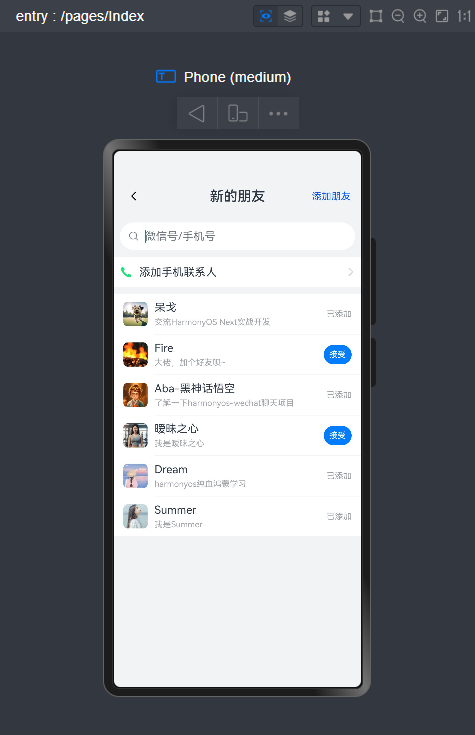
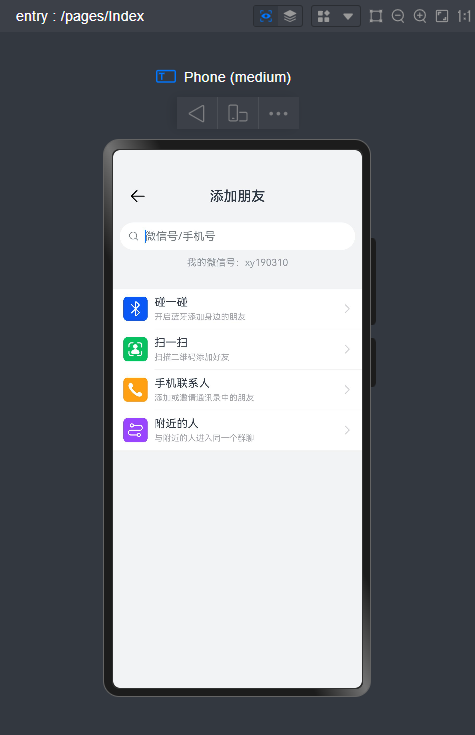


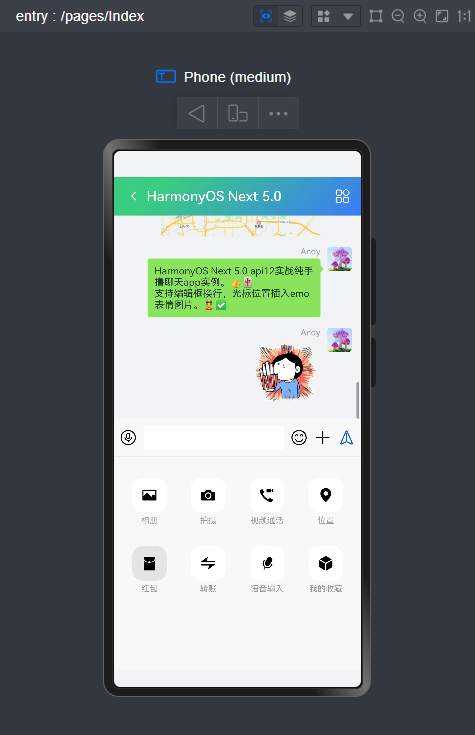
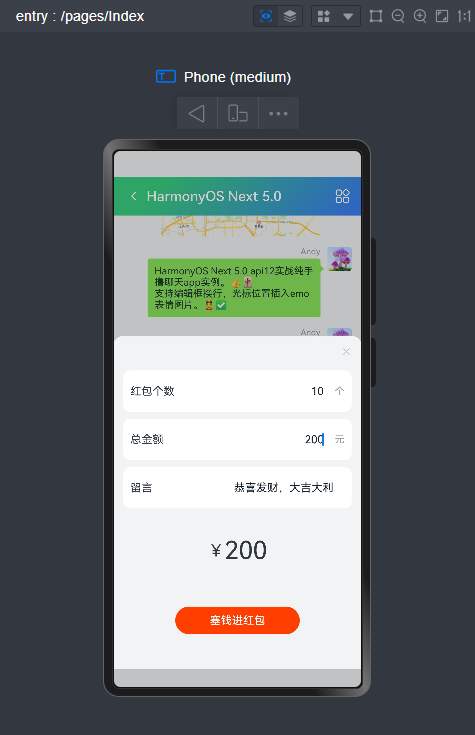
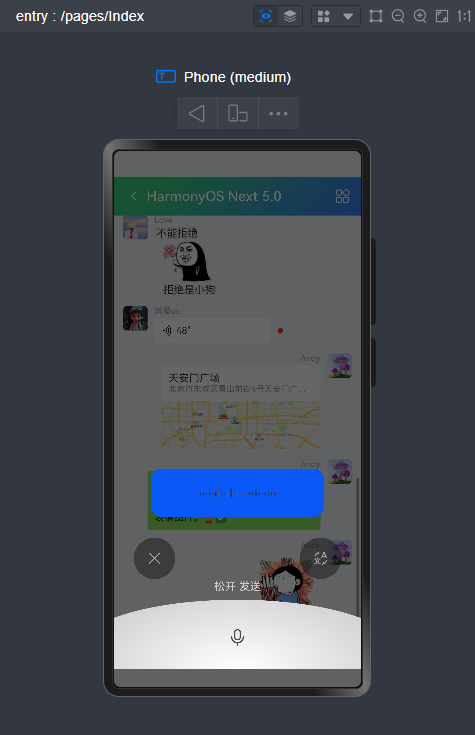
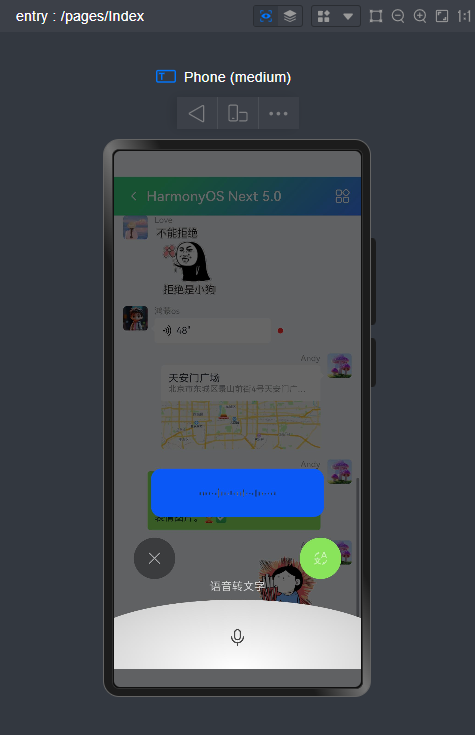
路由页面JSON文件

HarmonyOS ArkUI自定义顶部导航条






项目中所有顶部标题导航栏均是自定义封装ArkUI组件实现功能效果。之前有写过一篇专门的分享介绍,感兴趣的可以去看看下面这篇文章。
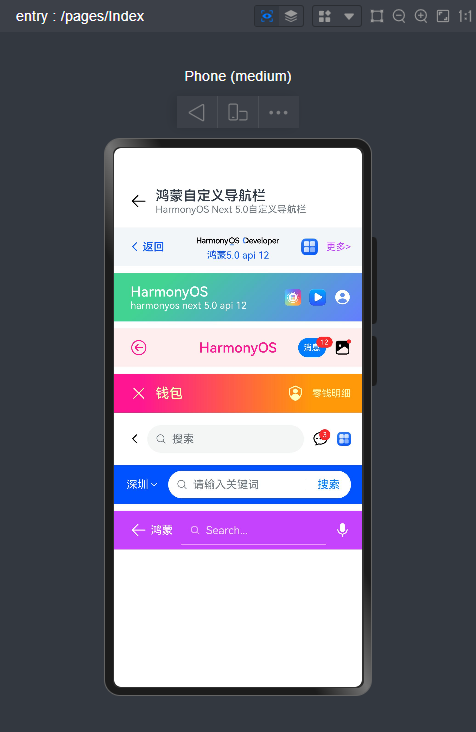
HarmonyOS NEXT 5.0自定义增强版导航栏组件|鸿蒙ArkUI自定义标题栏
Index.ets入口模板
//自定义页面 @Builder customPage() {if(this.pageIndex === 0) {
IndexPage()
}else if(this.pageIndex === 1) {
FriendPage()
}else if(this.pageIndex === 2) {
MyPage()
}
}
build() {
Navigation() {this.customPage()
}
.toolbarConfiguration(this.customToolBar)
.height('100%')
.width('100%')
.backgroundColor($r('sys.color.background_secondary'))
.expandSafeArea([SafeAreaType.SYSTEM], [SafeAreaEdge.TOP, SafeAreaEdge.BOTTOM])
}

//自定义底部菜单栏 @Builder customToolBar() {
Row() {
Row() {
Badge({
count:8,
style: {},
position: BadgePosition.RightTop
}) {
Column({space:2}) {
SymbolGlyph($r('sys.symbol.ellipsis_message_fill'))Text('聊天').fontSize(12)}
}
}
.layoutWeight(1)
.justifyContent(FlexAlign.Center)
.onClick(()=>{this.pageIndex = 0})
Row() {
Column({space:2}) {
SymbolGlyph($r('sys.symbol.person_2'))Text('通讯录').fontSize(12)}
}
.layoutWeight(1)
.justifyContent(FlexAlign.Center)
.onClick(()=>{this.pageIndex = 1})
Row() {
Badge({
value:'',
style: { badgeSize:8, badgeColor: '#fa2a2d'}
}) {
Column({space:2}) {
SymbolGlyph($r('sys.symbol.person_crop_circle_fill_1'))Text('我').fontSize(12)}
}
}
.layoutWeight(1)
.justifyContent(FlexAlign.Center)
.onClick(()=>{this.pageIndex = 2})
}
.height(56)
.width('100%')
.backgroundColor($r('sys.color.background_secondary'))
.borderWidth({top:1})
.borderColor($r('sys.color.background_tertiary'))
}
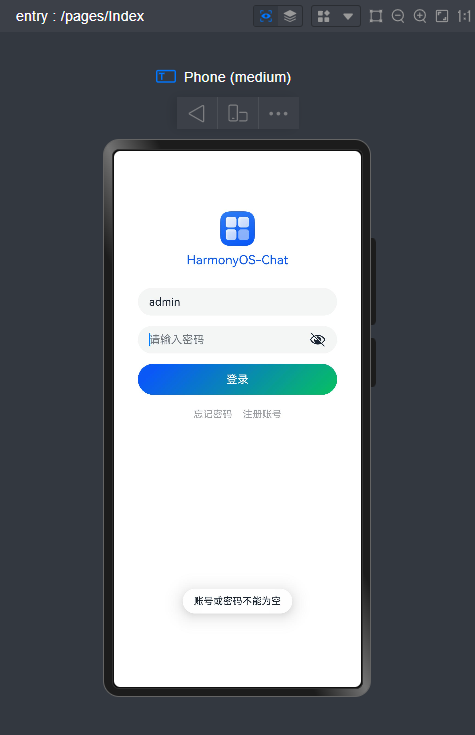
HarmonyOS实现登录/注册/倒计时验证

登录模板
/**
* 登录模板
* @author andy*/import { router, promptAction } from'@kit.ArkUI'@Entry
@Component
struct Login {
@State name: string= ''@State pwd: string= '' //提交 handleSubmit() {if(this.name === '' || this.pwd === '') {
promptAction.showToast({ message:'账号或密码不能为空'})
}else{//登录接口逻辑... promptAction.showToast({ message:'登录成功'})
setTimeout(()=>{
router.replaceUrl({ url:'pages/Index'})
},2000)
}
}
build() {
Column() {
Column({space:10}) {
Image('pages/assets/images/logo.png').height(50).width(50)
Text('HarmonyOS-Chat').fontSize(18).fontColor('#0a59f7')
}
.margin({top:50})
Column({space:15}) {
TextInput({placeholder:'请输入账号'})
.onChange((value)=>{this.name =value
})
TextInput({placeholder:'请输入密码'}).type(InputType.Password)
.onChange((value)=>{this.pwd =value
})
Button('登录').height(45).width('100%')
.linearGradient({ angle:135, colors: [['#0a59f7', 0.1], ['#07c160', 1]] })
.onClick(()=>{this.handleSubmit()
})
}
.margin({top:30})
.width('80%')
Row({space:15}) {
Text('忘记密码').fontSize(14).opacity(0.5)
Text('注册账号').fontSize(14).opacity(0.5)
.onClick(()=>{
router.pushUrl({url:'pages/views/auth/Register'})
})
}
.margin({top:20})
}
.height('100%')
.width('100%')
.expandSafeArea([SafeAreaType.SYSTEM], [SafeAreaEdge.TOP, SafeAreaEdge.BOTTOM])
}
}
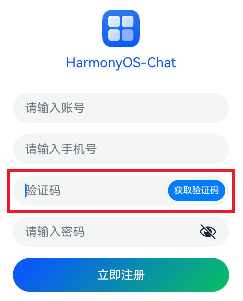
Stack({alignContent: Alignment.End}) {
TextInput({placeholder:'验证码'})
.onChange((value)=>{this.code =value
})
Button(`${this.codeText}`).enabled(!this.disabled).controlSize(ControlSize.SMALL).margin({right: 5})
.onClick(()=>{this.handleVCode()
})
}
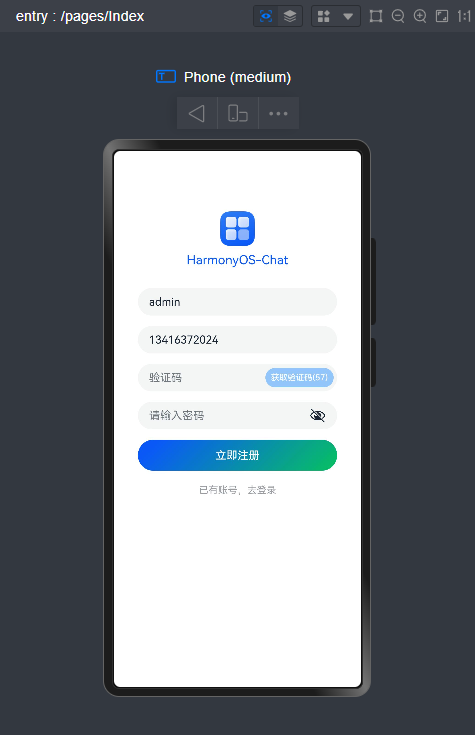
鸿蒙arkts实现60s倒计时验证码
//验证码参数 @State codeText: string = '获取验证码'@State disabled:boolean = false@State time: number= 60 //获取验证码 handleVCode() {if(this.tel === '') {
promptAction.showToast({ message:'请输入手机号'})
}else if(!checkMobile(this.tel)) {
promptAction.showToast({ message:'手机号格式错误'})
}else{
const timer= setInterval(() =>{if(this.time > 0) {this.disabled = true this.codeText = `获取验证码(${this.time--})`
}else{
clearInterval(timer)this.codeText = '获取验证码' this.time = 5 this.disabled = false}
},1000)
}
}
鸿蒙os下拉刷新/九宫格图像/长按菜单
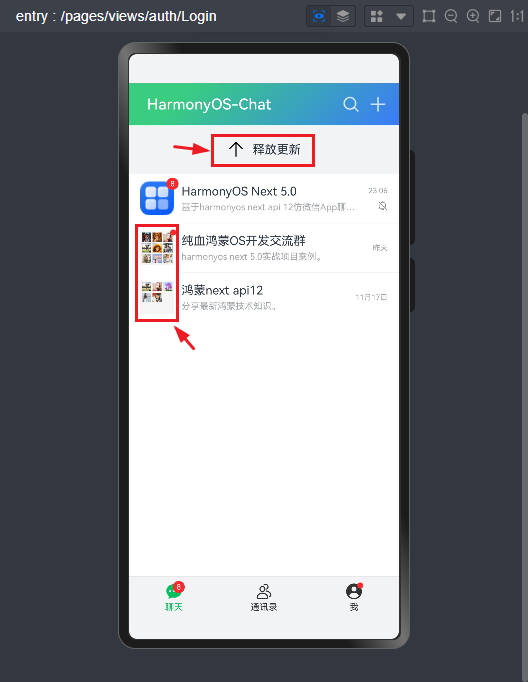
- 下拉刷新组件
Refresh({
refreshing: $$this.isRefreshing,
builder:this.customRefreshTips
}) {
List() {
ForEach(this.queryData, (item: RecordArray) =>{
ListItem() {//... }
.stateStyles({pressed:this.pressedStyles, normal: this.normalStyles})
.bindContextMenu(this.customCtxMenu, ResponseType.LongPress)
.onClick(()=>{//... })
}, (item: RecordArray)=>item.cid.toString())
}
.height('100%')
.width('100%')
.backgroundColor('#fff')
.divider({ strokeWidth:1, color: '#f5f5f5', startMargin: 70, endMargin: 0})
.scrollBar(BarState.Off)
}
.pullToRefresh(true)
.refreshOffset(64)//当前刷新状态变更时触发回调 .onStateChange((refreshStatus: RefreshStatus) =>{
console.info('Refresh onStatueChange state is ' +refreshStatus)this.refreshStatus =refreshStatus
})//进入刷新状态时触发回调 .onRefreshing(() =>{
console.log('onRefreshing...')
setTimeout(()=>{this.isRefreshing = false},2000)
})
- 自定义刷新提示
@State isRefreshing: boolean = false@State refreshStatus: number= 1 //自定义刷新tips @Builder customRefreshTips() {
Stack() {
Row() {if(this.refreshStatus == 1) {
SymbolGlyph($r('sys.symbol.arrow_down')).fontSize(24)
}else if(this.refreshStatus == 2) {
SymbolGlyph($r('sys.symbol.arrow_up')).fontSize(24)
}else if(this.refreshStatus == 3) {
LoadingProgress().height(24)
}else if(this.refreshStatus == 4) {
SymbolGlyph($r('sys.symbol.checkmark')).fontSize(24)
}
Text(`${this.refreshStatus == 1 ? '下拉刷新':this.refreshStatus == 2 ? '释放更新':this.refreshStatus == 3 ? '加载中...':this.refreshStatus == 4 ? '完成' : ''}`).fontSize(16).margin({left:10})
}
.alignItems(VerticalAlign.Center)
}
.align(Alignment.Center)
.clip(true)
.constraintSize({minHeight:32})
.width('100%')
}
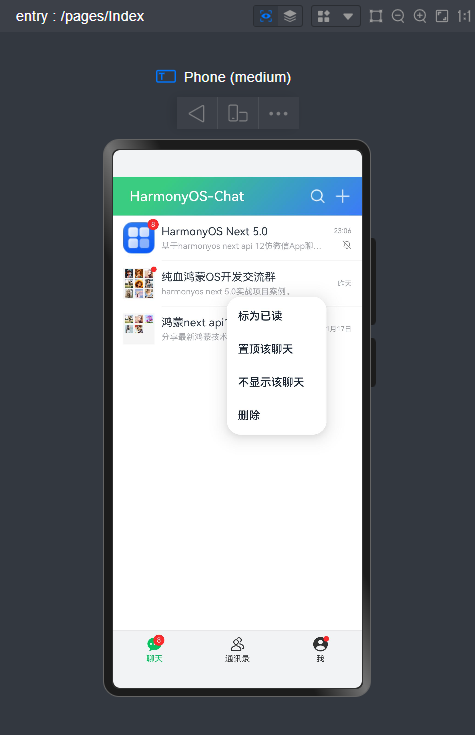
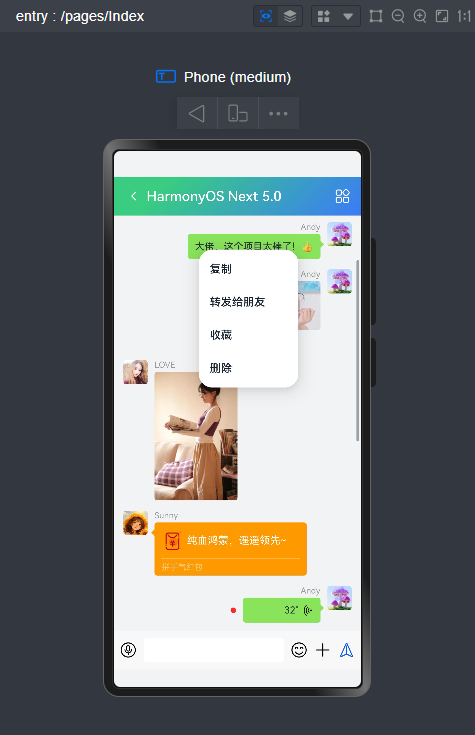
- 长按右键菜单
.bindContextMenu(
this
.customCtxMenu, ResponseType.LongPress)
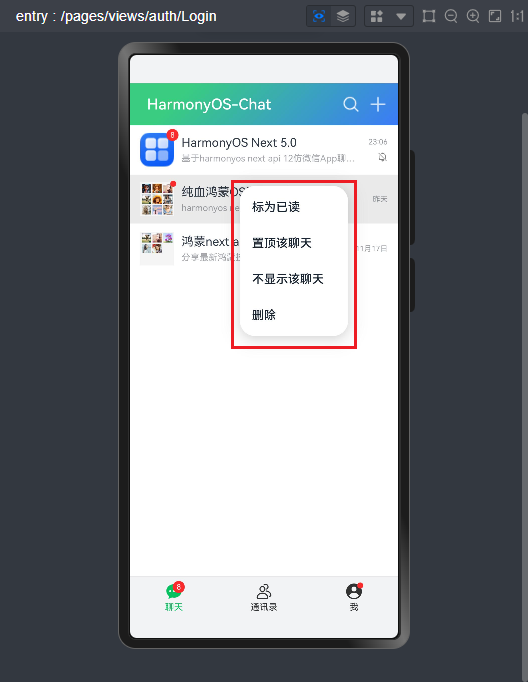
//自定义长按右键菜单 @Builder customCtxMenu() {
Menu() {
MenuItem({
content:'标为已读'})
MenuItem({
content:'置顶该聊天'})
MenuItem({
content:'不显示该聊天'})
MenuItem({
content:'删除'})
}
}
- 下拉菜单
.bindMenu([ ... ])
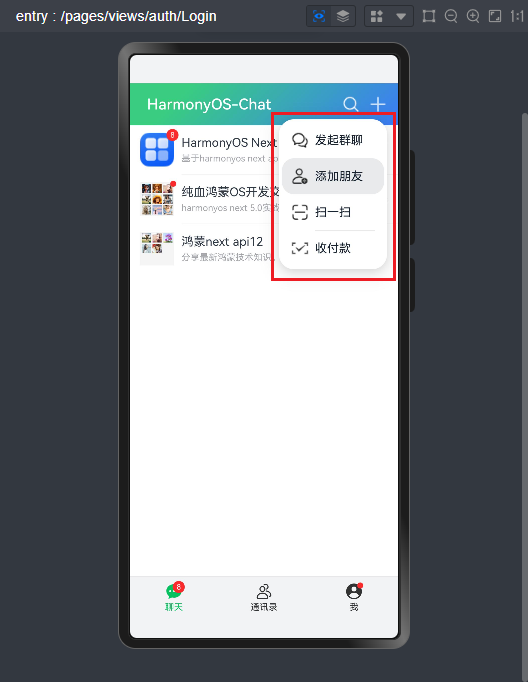
Image($r('app.media.plus')).height(24).width(24)
.bindMenu([
{
icon: $r('app.media.message_on_message'),
value:'发起群聊',
action: ()=>{}
},
{
icon: $r('app.media.person_badge_plus'),
value:'添加朋友',
action: ()=> router.pushUrl({url: 'pages/views/friends/AddFriend'})
},
{
icon: $r('app.media.line_viewfinder'),
value:'扫一扫',
action: ()=>{}
},
{
icon: $r('app.media.touched'),
value:'收付款',
action: ()=>{}
}
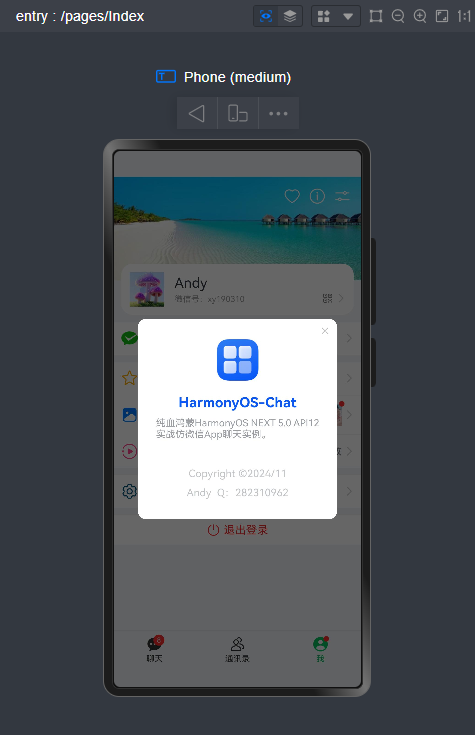
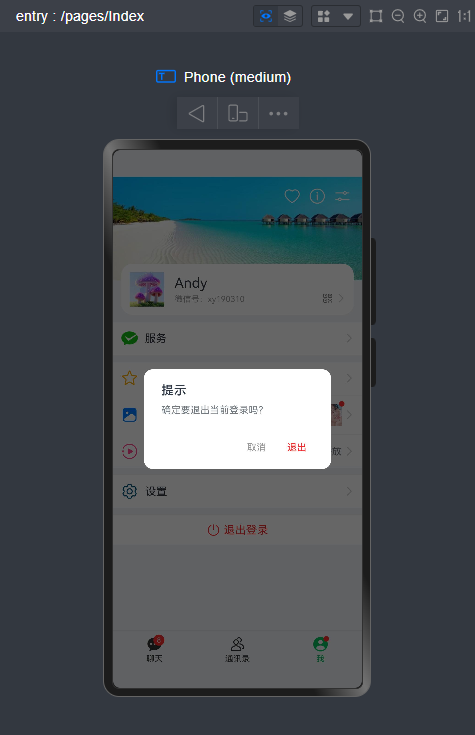
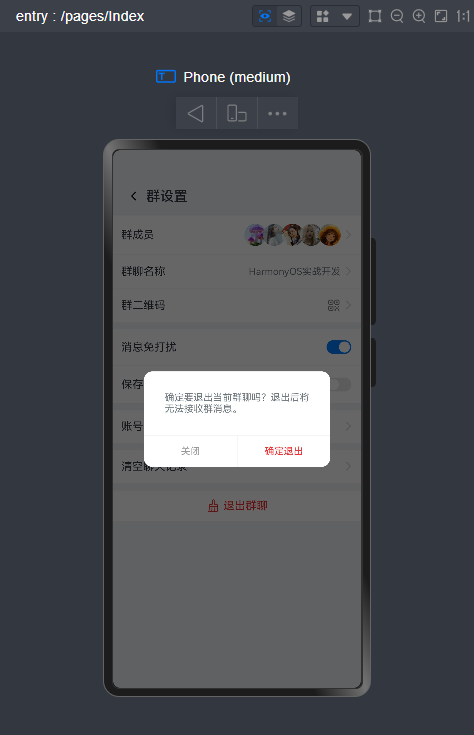
])HarmonyOS arkui自定义dialog弹框组件
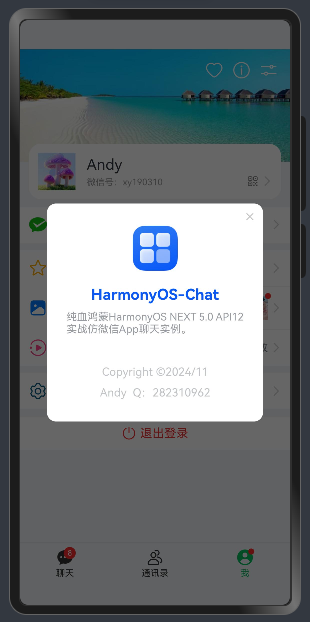
支持参数配置如下:
//标题(支持字符串|自定义组件) @BuilderParam title: ResourceStr | CustomBuilder =BuilderFunction//内容(字符串或无状态组件内容) @BuilderParam message: ResourceStr | CustomBuilder =BuilderFunction//响应式组件内容(自定义@Builder组件是@State动态内容) @BuilderParam content: () => void =BuilderFunction//弹窗类型(android | ios | actionSheet) @Prop type: string//是否显示关闭图标 @Prop closable: boolean //关闭图标颜色 @Prop closeColor: ResourceColor//是否自定义内容 @Prop custom: boolean //自定义操作按钮 @BuilderParam buttons: Array<ActionItem> | CustomBuilder = BuilderFunction
调用方式非常简单。
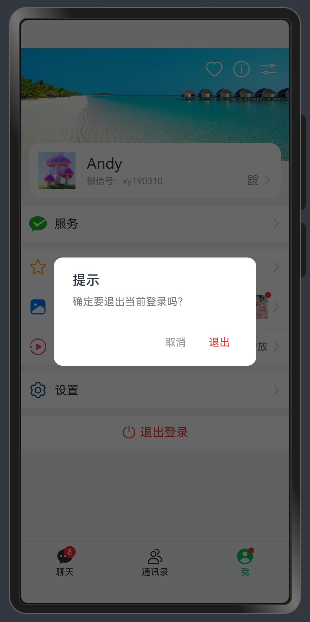
//自定义退出弹窗 logoutController: CustomDialogController = newCustomDialogController({
builder: HMPopup({
type:'android',
title:'提示',
message:'确定要退出当前登录吗?',
buttons: [
{
text:'取消',
color:'#999'},
{
text:'退出',
color:'#fa2a2d',
action: ()=>{
router.replaceUrl({url:'pages/views/auth/Login'})
}
}
]
}),
maskColor:'#99000000',
cornerRadius:12,
width:'75%'})
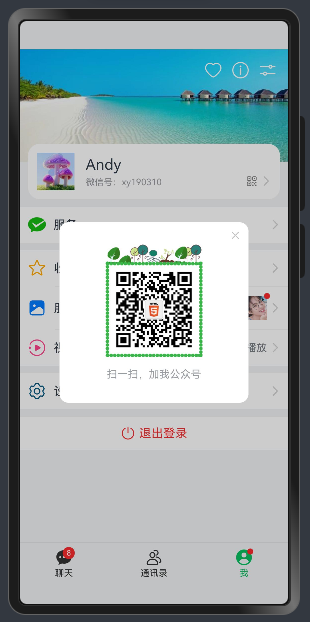
//自定义公众号弹窗 @Builder customQRContent() {
Column({space:15}) {
Image('pages/assets/images/qrcode.png').height(150).objectFit(ImageFit.Contain)
Text('扫一扫,加我公众号').fontSize(14).opacity(.5)
}
}
qrController: CustomDialogController= newCustomDialogController({
builder: HMPopup({
message:this.customQRContent,
closable:true}),
cornerRadius:12,
width:'70%'})
好了,以上就是harmonyos next实战开发聊天app的一些知识分享,希望对大家有所帮助~
整个项目涉及到的知识点非常多,限于篇幅就先分享到这里。感谢大家的阅读与支持。
https://www.cnblogs.com/xiaoyan2017/p/18396212
https://www.cnblogs.com/xiaoyan2017/p/18437155
https://www.cnblogs.com/xiaoyan2017/p/18467237