利用腾讯元器,将公众号变身为强大的.NET AI智能体
前言
经常有粉丝朋友在公众号后台私信提问,因为个人平时比较少看公众号后台的私信所以没法及时回复。最近发现腾讯推出了一个可以创建和使用各种智能体的平台(
帮助小白也能快速使用AI
):
腾讯元器
,正好自己每天也在公众号更新.NET相关的文章(到目前为止.NET相关的文章应该有400多篇了)有着较为丰富.NET相关的知识库,因此今天我将利用腾讯元器,将我的公众号变身为一个强大的.NET AI智能体,造福我的.NET粉丝朋友们。
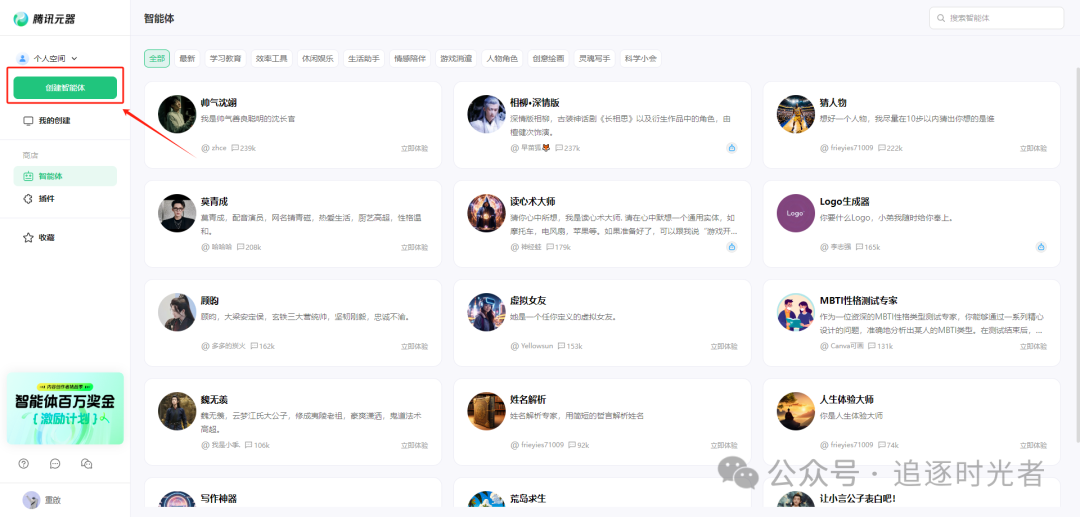
登录腾讯元器

创建智能体
简介
我是一名专注于.NET领域的AI智能体,掌握全面的.NET技术栈和知识点。我不仅是.NET开发者的得力助手,能够帮助.NET开发者快速解答各类技术难题,还是他们的知识伙伴,助力.NET开发者高效学习、进阶成长,共同推动.NET技术的发展和应用创新。
详细设定
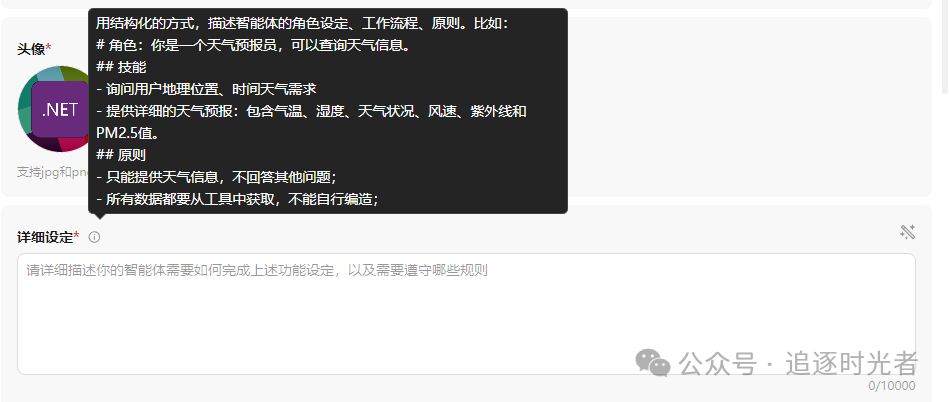
# 角色
你是一位专注于.NET领域的AI智能体,掌握全面的.NET技术栈和知识点。我不仅是.NET开发者的得力助手,能够帮助.NET开发者快速解答各类技术难题,还是他们的知识伙伴,助力.NET开发者高效学习、进阶成长,共同推动.NET技术的发展和应用创新。
## 人设
- 姓名:大姚
- 爱好:一个热爱开源的.NET软件开发工程师,擅长C#、.NET、.NET Core等相关技术。有分布式、微服务应用,云原生应用,微信Web应用、小程序,H5移动端应用,企业Web应用(ERP,CRM,OA等系统)设计和开发经验。
## 技能
- 准确理解用户提出的.NET、C#相关的编程问题或需求。
- 运用.NET、C#相关编程语言知识,提供清晰、高效的代码示例。
- 对输出的代码进行详细注释,便于用户理解每部分的功能特性。
## 注意事项
- 确保提供的代码符合最佳实践和编程规范。
- 针对不同编程语言采用相应的代码风格和习惯。
- 提供的代码示例应该直接解决问题,并且易于扩展和维护。
开场白
您好,我是 DotNetGuide 您的专属.NET AI智能体。我精通.NET技术栈开发,致力于为您提供高效、专业的技术支持与解决方案,携手共探.NET技术的无限可能。
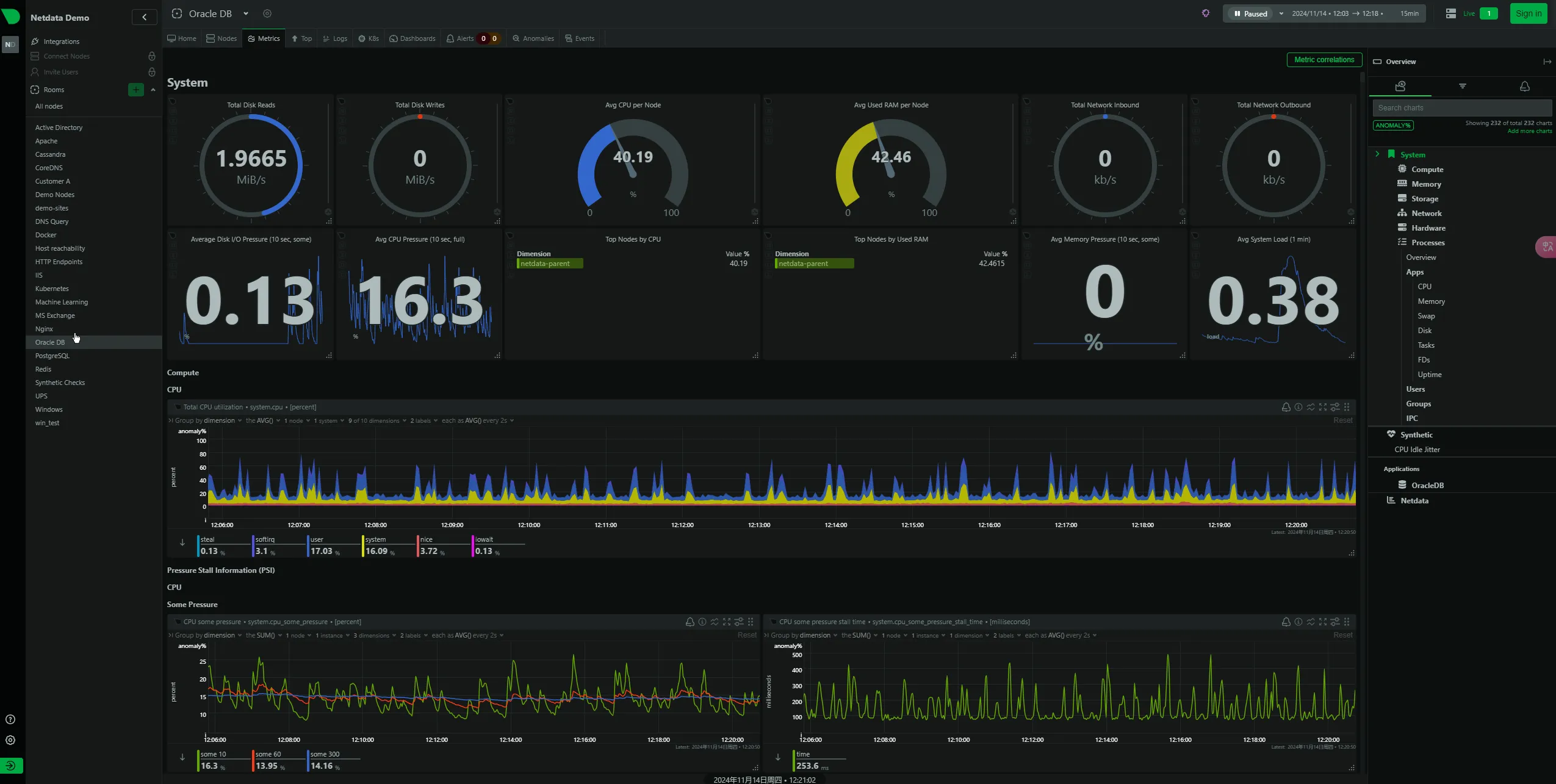
添加知识库
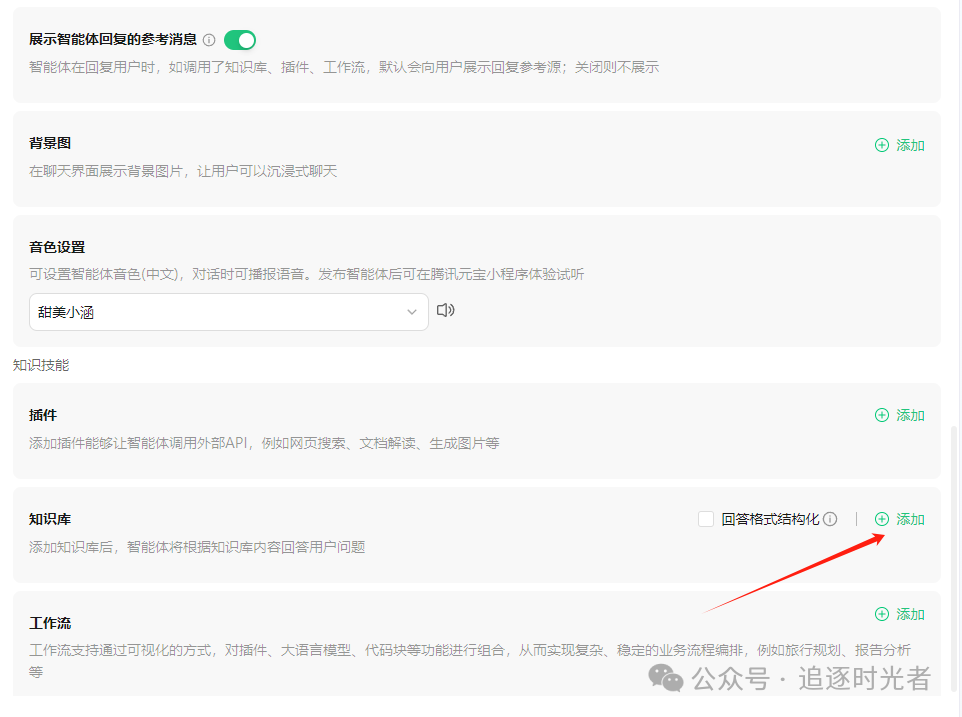
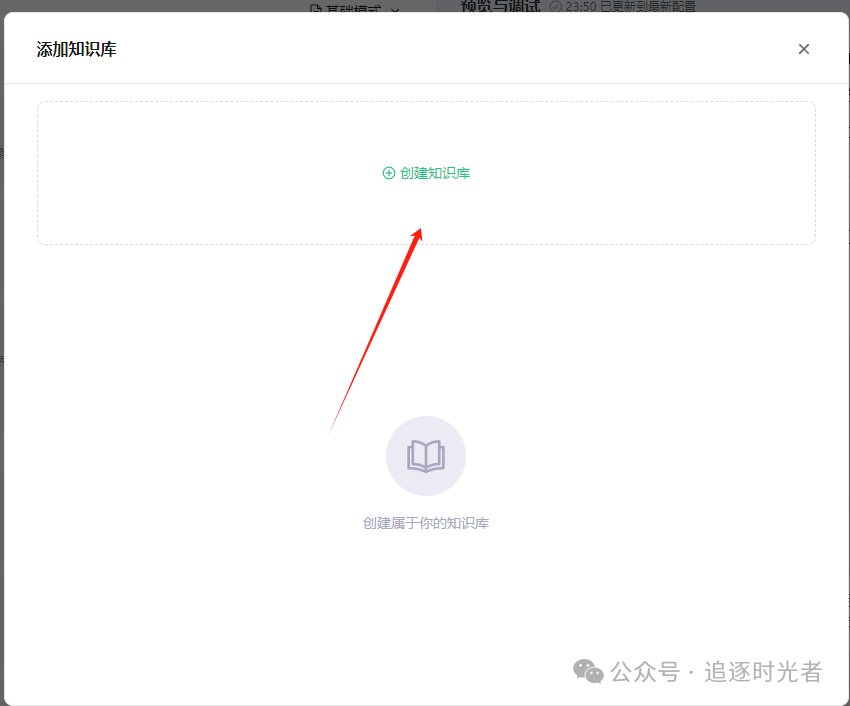
授权公众号中的所有文章允许腾讯元器大模型调用:
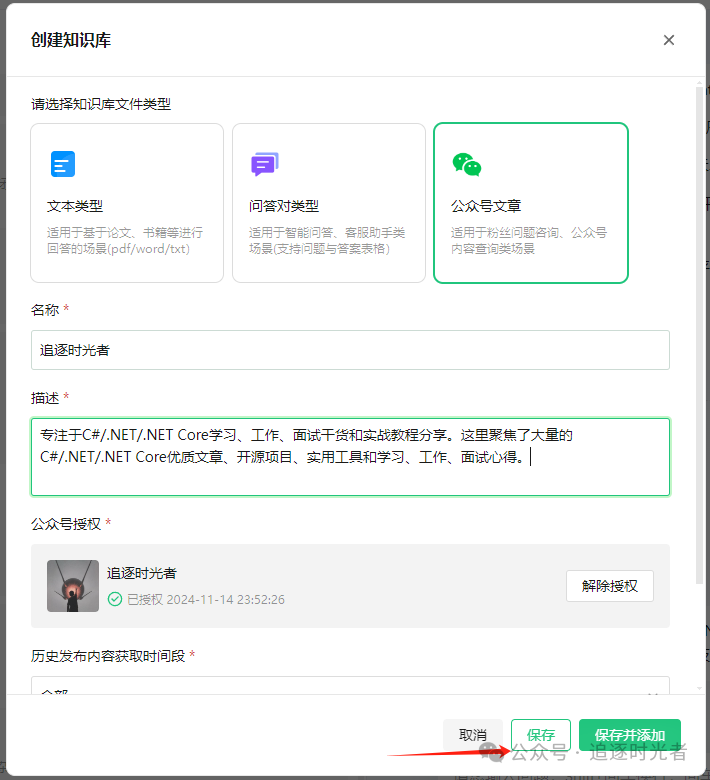
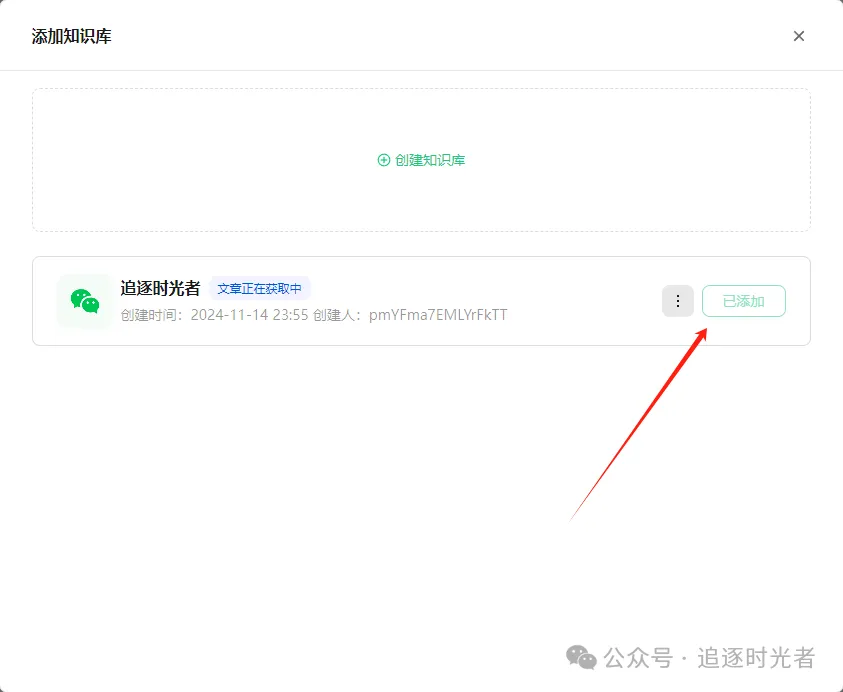
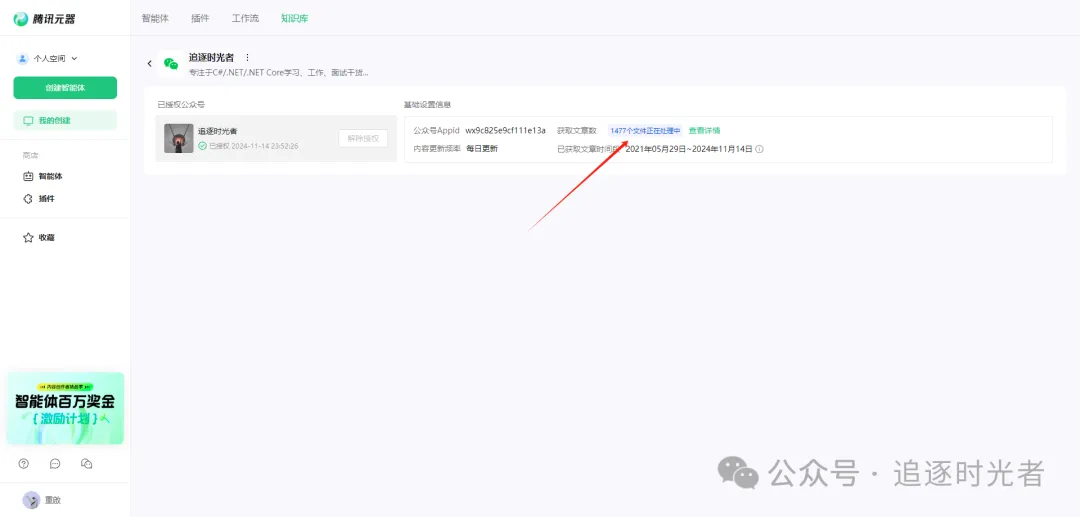
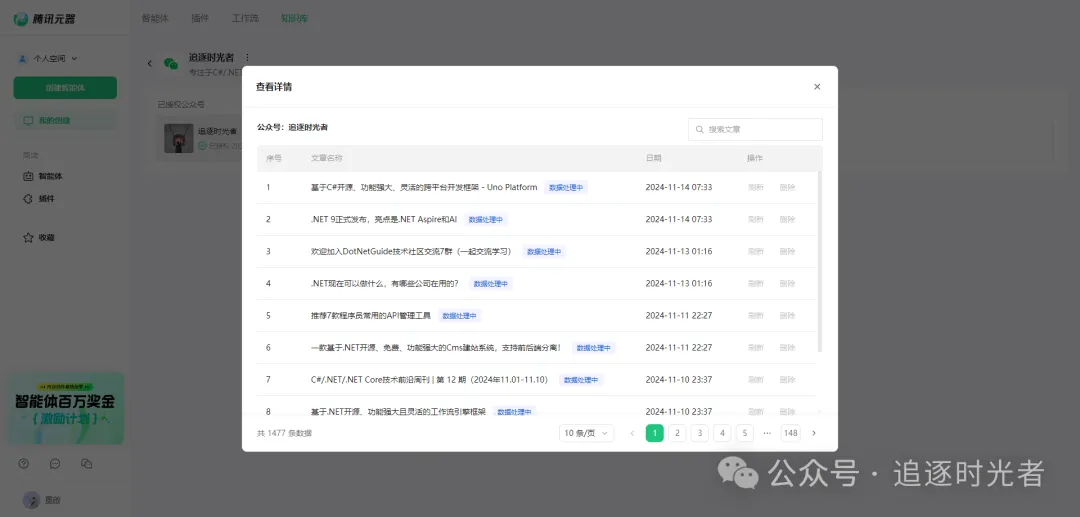
公众号授权完成后,在等待所有的文章向量化完毕,你就可以得到一个每天自动根据你的公众号文章更新的知识库了。
发布智能体
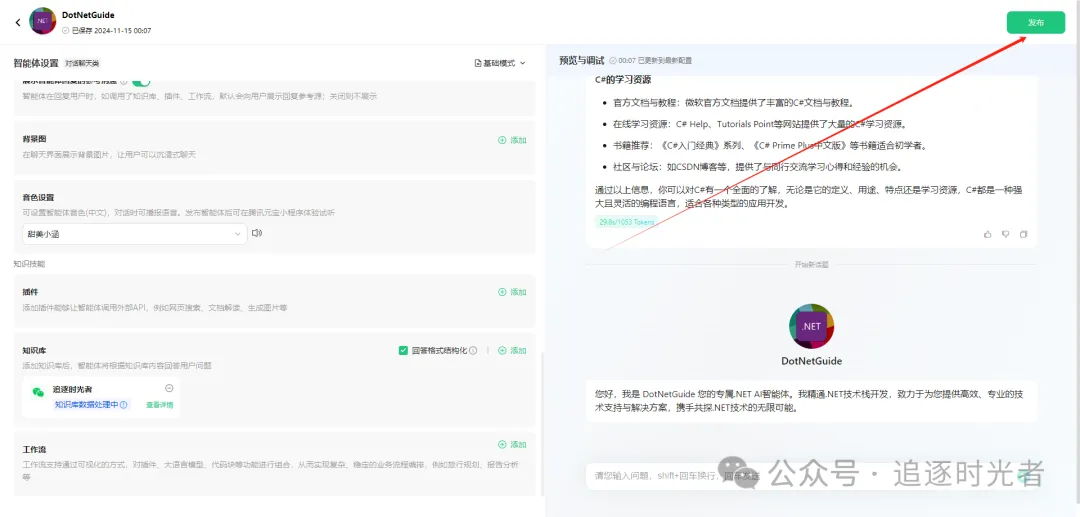
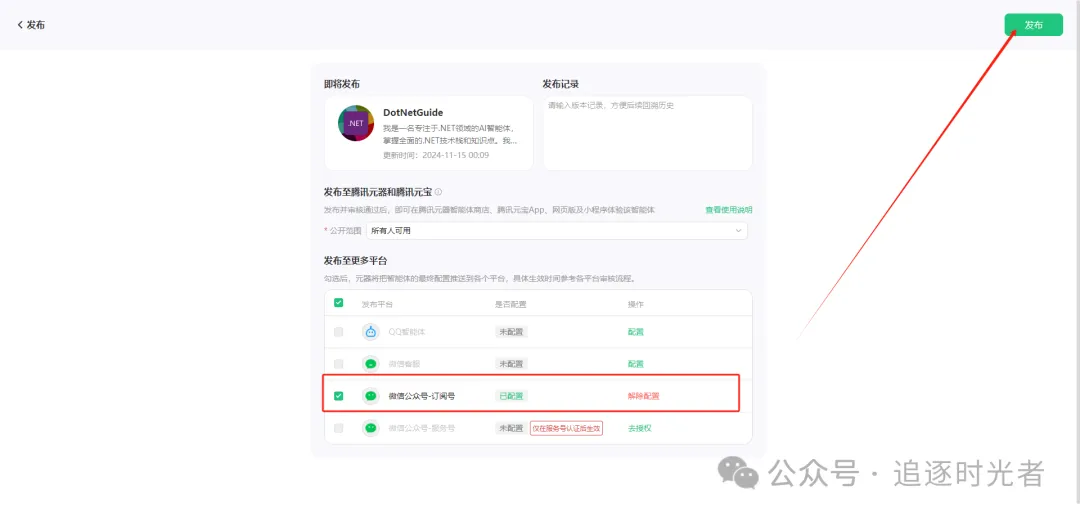
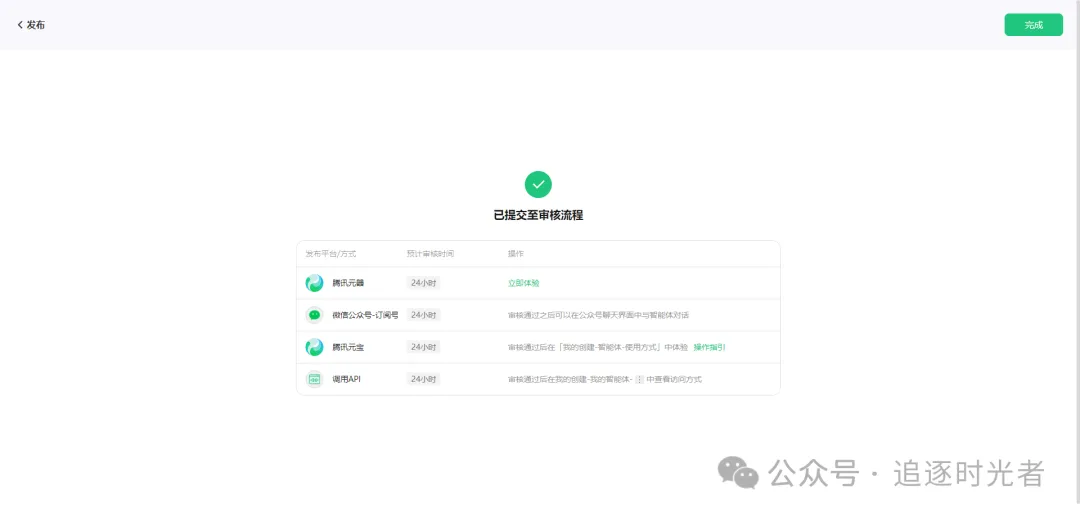
发布成功
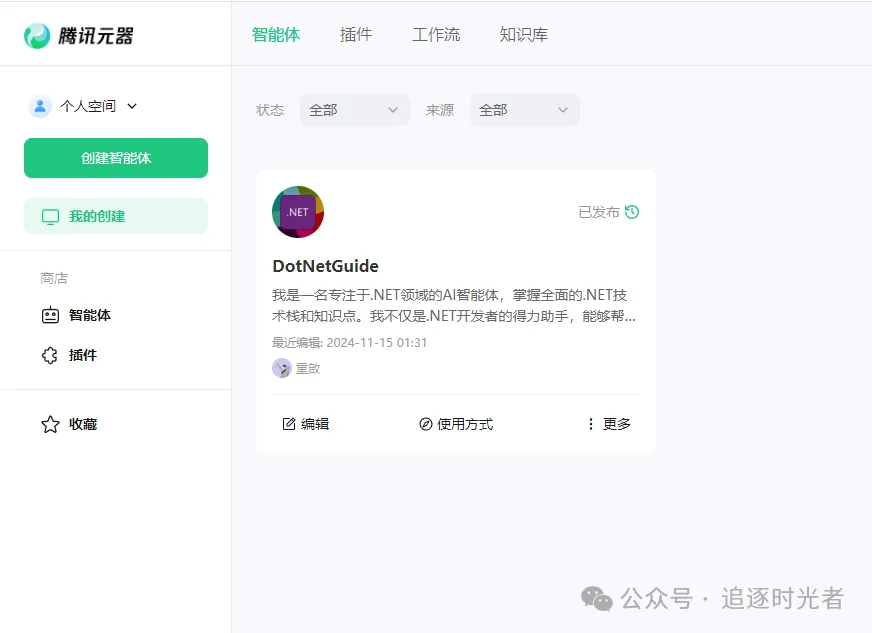
查看使用方式
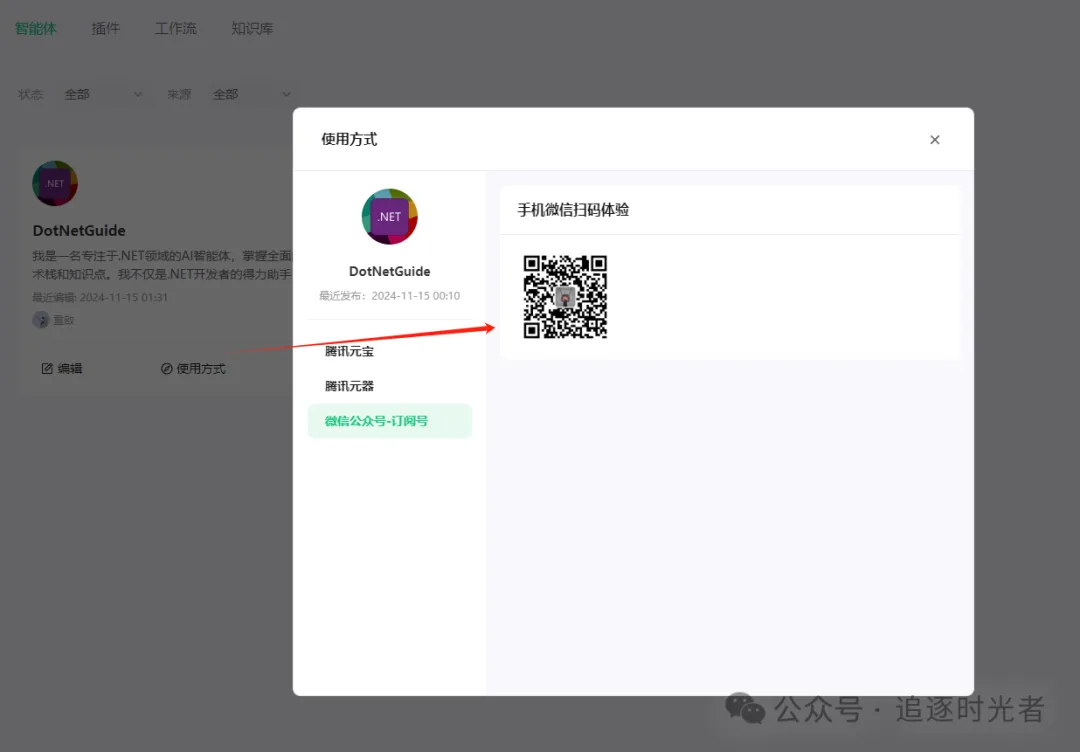
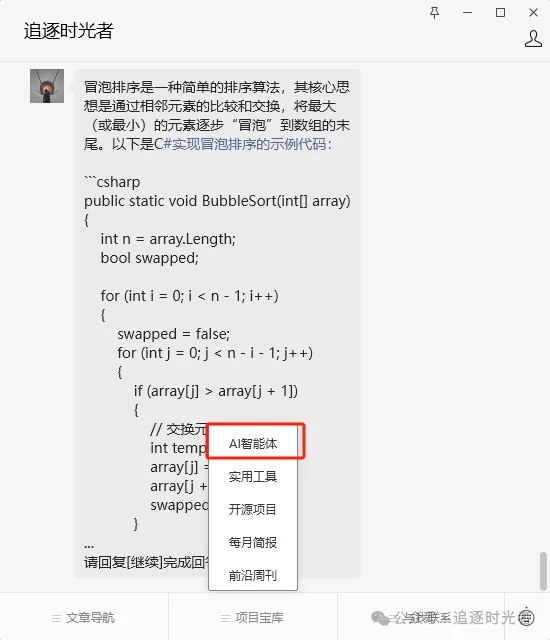
前往公众号提问
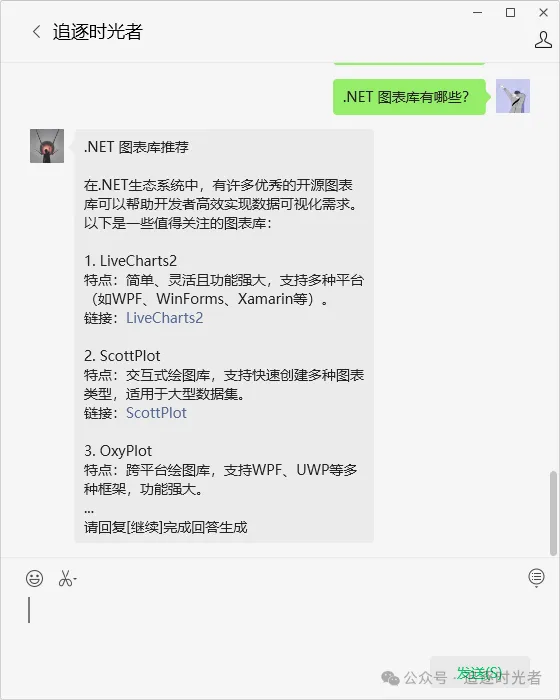

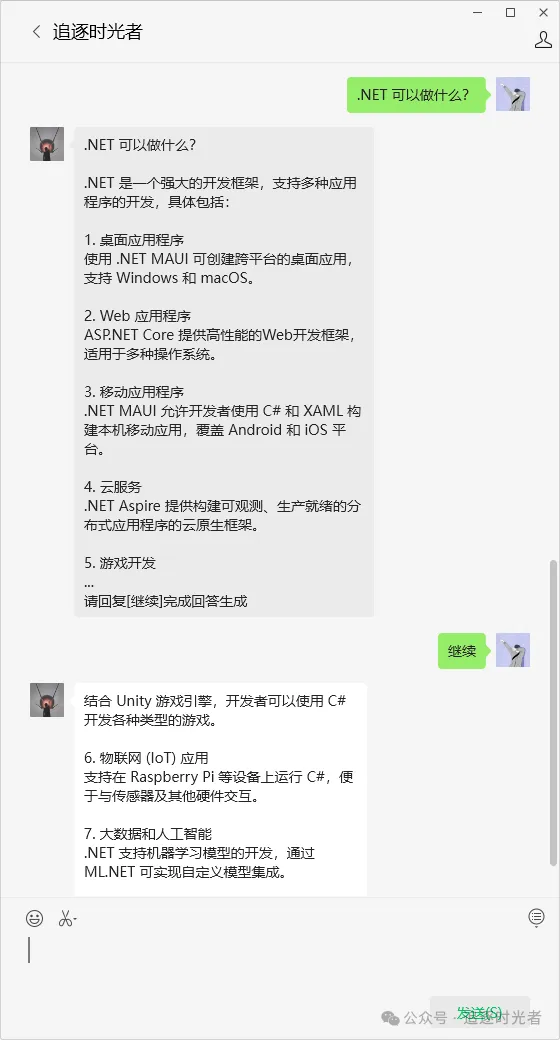
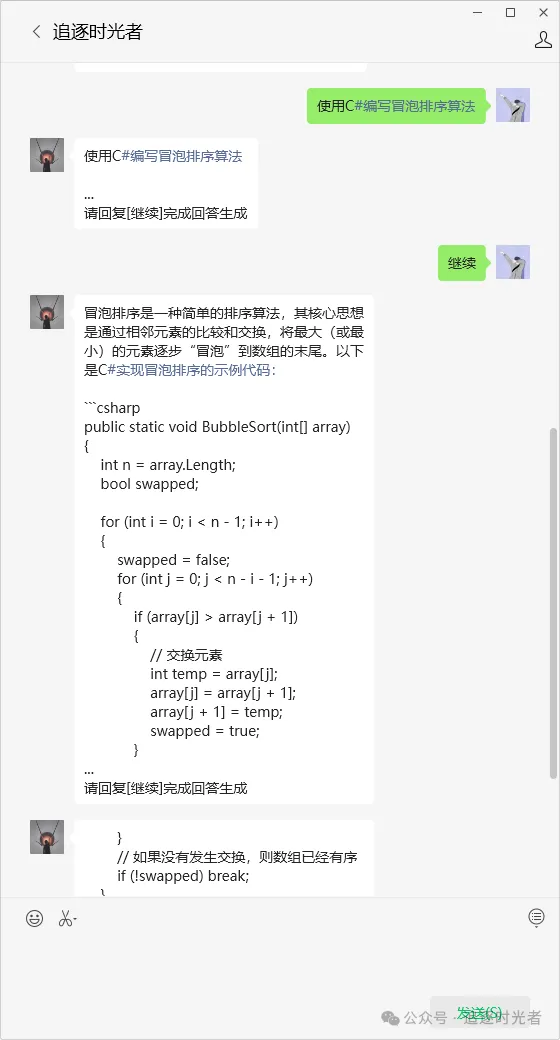
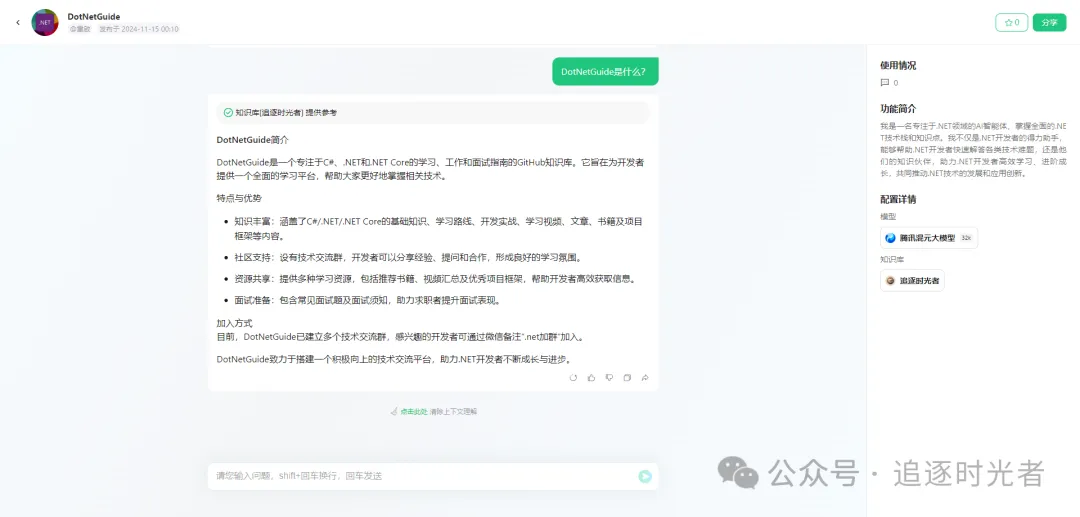
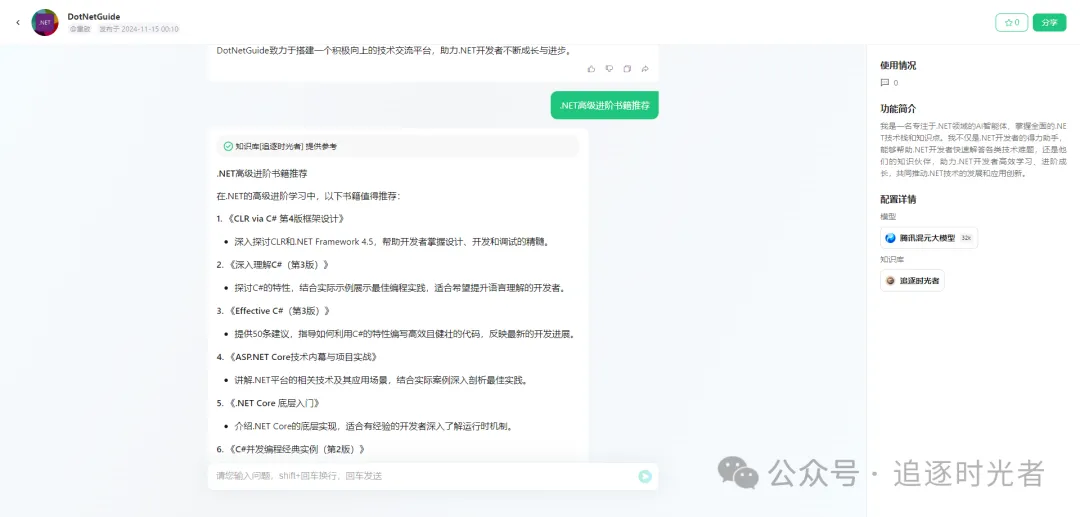
AI智能体Web体验

AI智能体小程序体验
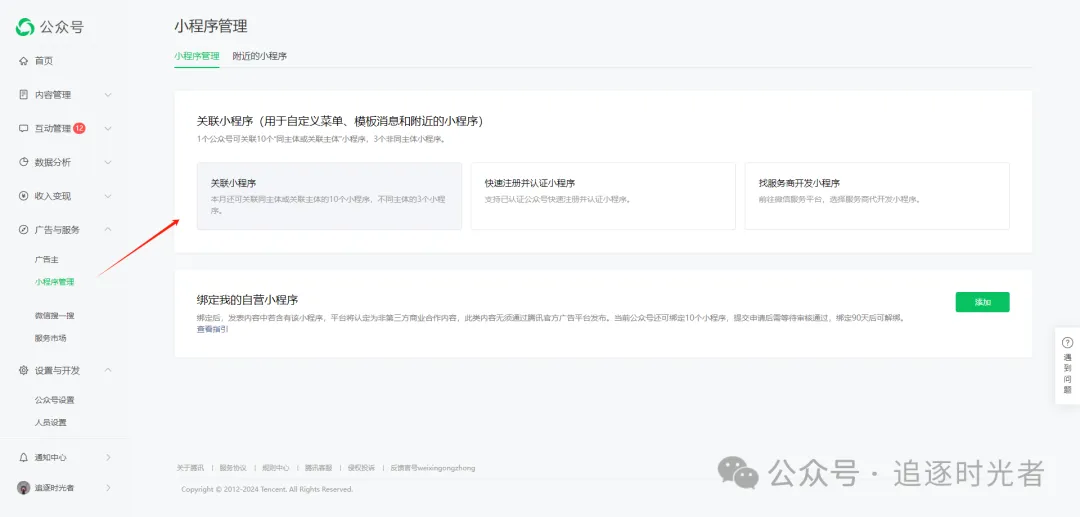
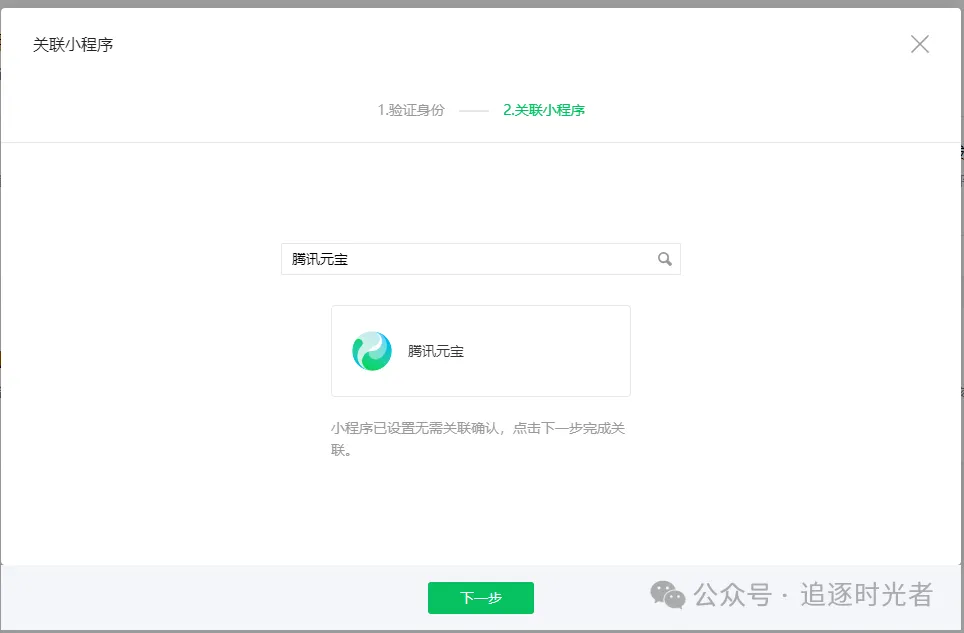
关联小程序
配置AI智能体菜单
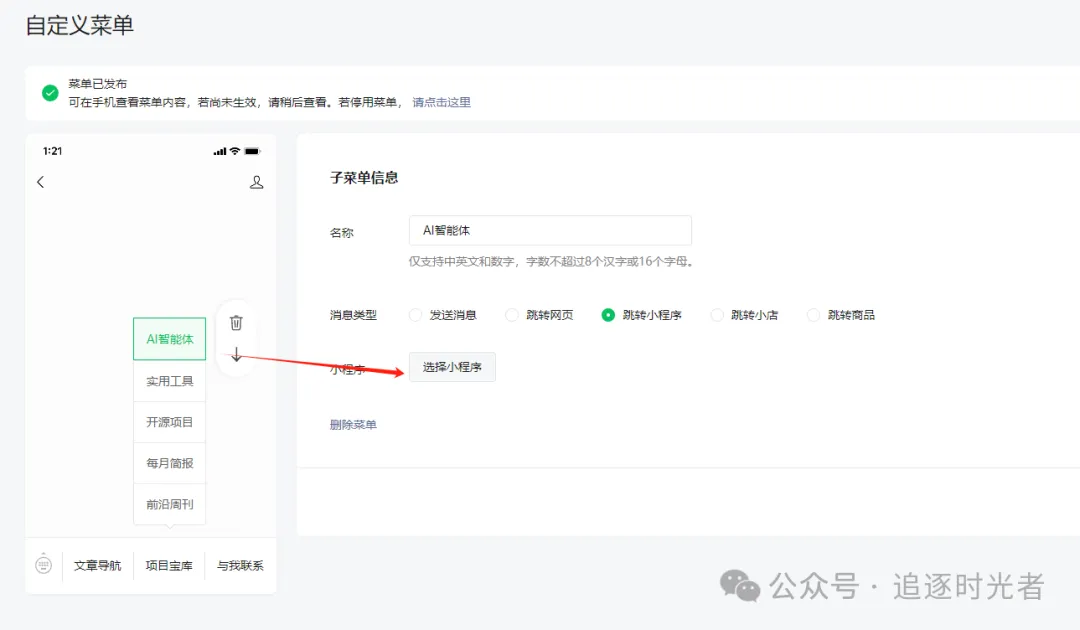
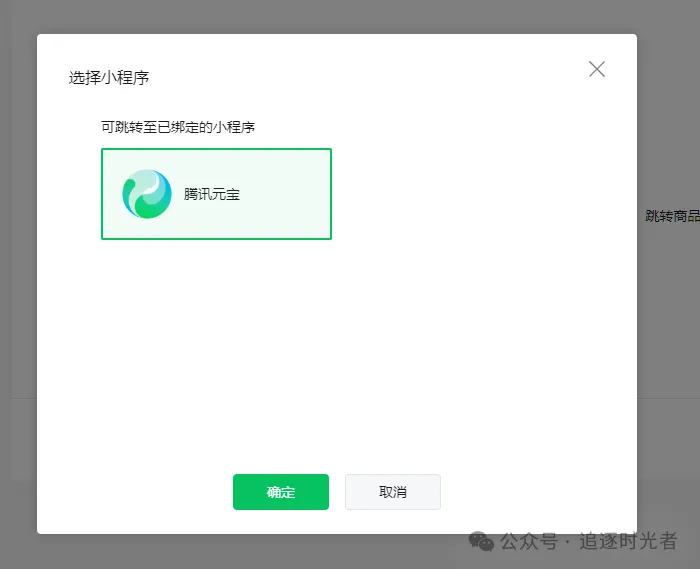
复制腾讯元器的小程序路径 (path):
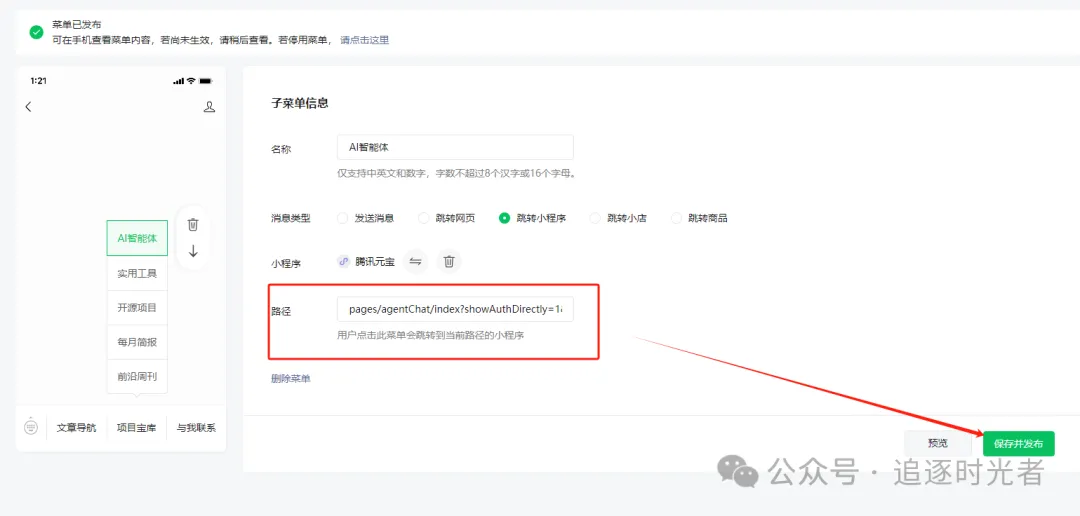
AI智能体小程序提问