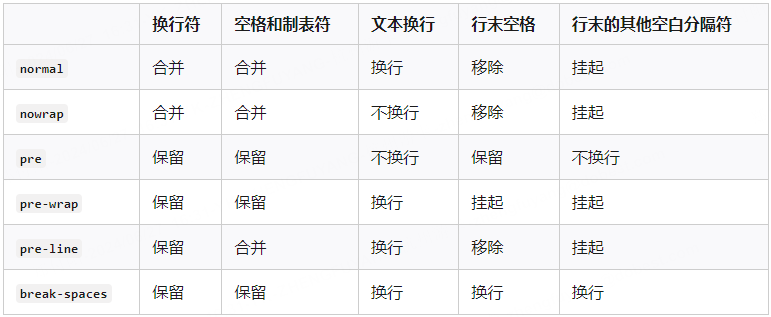
记一次 .NET某hdp智能柜系统 卡死分析
一:背景
1. 讲故事
停了一个月时间没有更新博客了,主要是这段时间有些许事情导致心神不宁,我这个人也比较浮躁所以无法潜心修炼,事情如下:
- 被狗咬了
也不知道是不是出门没看黄历,在小区门口店里买烟,被店老板家狗来了个猝不及防,天降横祸。让店老板赔了个疫苗钱,人生第一次被狗咬,第一次打这种狂犬疫苗,头两天总焦虑这辈子是不是要画一个句号了,想着这几年在社区里免费给人家分析dump,应该也积了不少阴德阳善,老天不会在这个时候收我的,昨天结束了四针剂的最后一针,算是放下了心头事,真是人间好时节。
- 买房
孩子明年就要上一年级了,所以给孩子上哪所有教育资源的学校又是一件焦虑的事情,家门口的学校都是菜小,村小,不想耽误孩子的前程,在贝壳焦虑着泡了大半个月加上实地考察,把这件事情也搞定了。
- 幼儿跳绳比赛
这个真的最耽误我的时间,孩子参加市级的跳绳比赛,每天早上6:45集训,每天 6:00 跟着孩子起床,送去集训,全程陪护,作为程序员晚上12点前下电脑都是对工作的不尊敬,导致睡眠不足,整天精神状态都不是很好。
跟大家简单的汇报了这一个月的事情,接下来我们分析个比较经典的dump吧,前段时间有位朋友找到我,说他的程序会偶发卡死,自己有一定的分析能力,但还是找不出来根源在哪里,让我帮忙看下,毕竟在国内搜索
.NET高级调试
的文章,最终都会通向我这边。
二:WinDbg分析
1. 主线程怎么了
因为是主线程的卡死,所以首看主线程的调用栈来寻找其中的蛛丝马迹,输出如下:
0:000:x86> k
CvRegToMachine(x86) conversion failure for 0x14f
X86MachineInfo::SetVal: unknown register 0 requested
# ChildEBP RetAddr
00 0047e8f8 76c41629 ntdll_774f0000!NtWaitForSingleObject+0x15
01 0047e8f8 76d71194 KERNELBASE!WaitForSingleObjectEx+0x98
02 0047e910 58d52bf6 kernel32!WaitForSingleObjectExImplementation+0x75
03 (Inline) -------- coreclr!CLREventWaitHelper2+0x9 [D:\a\_work\1\s\src\coreclr\vm\synch.cpp @ 372]
04 0047e964 58d52bc4 coreclr!CLREventWaitHelper+0x2d [D:\a\_work\1\s\src\coreclr\vm\synch.cpp @ 397]
05 0047e974 58d52821 coreclr!CLREventBase::WaitEx+0x49 [D:\a\_work\1\s\src\coreclr\vm\synch.cpp @ 469]
06 0047e988 58df0848 coreclr!CLREventBase::Wait+0x1a [D:\a\_work\1\s\src\coreclr\vm\synch.cpp @ 413]
07 (Inline) -------- coreclr!GCEvent::Impl::Wait+0xb [D:\a\_work\1\s\src\coreclr\vm\gcenv.os.cpp @ 1283]
08 (Inline) -------- coreclr!GCEvent::Wait+0x10 [D:\a\_work\1\s\src\coreclr\vm\gcenv.os.cpp @ 1361]
09 0047e9a0 58d5222c coreclr!SVR::GCHeap::WaitUntilGCComplete+0x28 [D:\a\_work\1\s\src\coreclr\gc\gcee.cpp @ 287]
0a 0047e9fc 58f26769 coreclr!Thread::RareDisablePreemptiveGC+0x1ad [D:\a\_work\1\s\src\coreclr\vm\threadsuspend.cpp @ 2172]
0b 0047ea08 58df7f88 coreclr!JIT_ReversePInvokeEnterRare2+0xd [D:\a\_work\1\s\src\coreclr\vm\jithelpers.cpp @ 5462]
0c 0047ea2c 2d8fd592 coreclr!JIT_ReversePInvokeEnterTrackTransitions+0x98 [D:\a\_work\1\s\src\coreclr\vm\jithelpers.cpp @ 5509]
WARNING: Frame IP not in any known module. Following frames may be wrong.
0d 0047ea90 76f862fa 0x2d8fd592
0e 0047eabc 76f86d3a user32!InternalCallWinProc+0x23
0f 0047eb34 76f86de8 user32!UserCallWinProcCheckWow+0x109
10 0047eb90 76fae062 user32!DispatchClientMessage+0xd5
11 0047ebf8 7750013a user32!__fnINDEVICECHANGE+0x2a9
12 0047ec64 76f8790d ntdll_774f0000!KiUserCallbackDispatcher+0x2e
13 0047ec64 30d6e999 user32!GetMessageW+0x33
从卦中可以看到有一个
WaitUntilGCComplete
函数,说明主线程正在等待GC完成,那到底是哪一个线程触发了GC呢?可以用
~* k
命令观察每个线程的调用栈,经过一顿搜索,发现是
3号
线程挂了GC相关函数
SuspendEE
,参考输出如下:
3 Id: ff0.608 Suspend: 0 Teb: fff9a000 Unfrozen
CvRegToMachine(x86) conversion failure for 0x14f
X86MachineInfo::SetVal: unknown register 0 requested
# ChildEBP RetAddr
00 02c3f5d0 76c41629 ntdll_774f0000!NtWaitForSingleObject+0x15
01 02c3f5d0 76d71194 KERNELBASE!WaitForSingleObjectEx+0x98
02 02c3f5e8 58d52bf6 kernel32!WaitForSingleObjectExImplementation+0x75
03 (Inline) -------- coreclr!CLREventWaitHelper2+0x9 [D:\a\_work\1\s\src\coreclr\vm\synch.cpp @ 372]
04 02c3f63c 58d52bc4 coreclr!CLREventWaitHelper+0x2d [D:\a\_work\1\s\src\coreclr\vm\synch.cpp @ 397]
05 02c3f64c 58d52821 coreclr!CLREventBase::WaitEx+0x49 [D:\a\_work\1\s\src\coreclr\vm\synch.cpp @ 469]
06 02c3f664 58d8947b coreclr!CLREventBase::Wait+0x1a [D:\a\_work\1\s\src\coreclr\vm\synch.cpp @ 413]
07 02c3f6e8 58d86aa2 coreclr!ThreadSuspend::SuspendRuntime+0x553 [D:\a\_work\1\s\src\coreclr\vm\threadsuspend.cpp @ 3590]
08 02c3f790 58d868f0 coreclr!ThreadSuspend::SuspendEE+0xf9 [D:\a\_work\1\s\src\coreclr\vm\threadsuspend.cpp @ 5741]
09 02c3f7b8 58d95aa5 coreclr!GCToEEInterface::SuspendEE+0x26 [D:\a\_work\1\s\src\coreclr\vm\gcenv.ee.cpp @ 28]
0a 02c3f7b8 58d96ae8 coreclr!SVR::gc_heap::gc_thread_function+0x11f [D:\a\_work\1\s\src\coreclr\gc\gc.cpp @ 6680]
0b 02c3f7e4 58d96ad4 coreclr!SVR::gc_heap::end_space_after_gc [D:\a\_work\1\s\src\coreclr\gc\gc.cpp @ 39175]
0c (Inline) -------- coreclr!GCToOSInterface::BoostThreadPriority+0xf [D:\a\_work\1\s\src\coreclr\vm\gcenv.os.cpp @ 699]
0d 02c3f7e4 58e0c182 coreclr!SVR::gc_heap::gc_thread_stub+0x64 [D:\a\_work\1\s\src\coreclr\gc\gc.cpp @ 31990]
0e 02c3f7f8 76d7343d coreclr!<lambda_e12851d373e238e6372df6ec280c8fc6>::operator()+0x42 [D:\a\_work\1\s\src\coreclr\vm\gcenv.ee.cpp @ 1471]
0f 02c3f804 77529802 kernel32!BaseThreadInitThunk+0xe
10 02c3f844 775297d5 ntdll_774f0000!__RtlUserThreadStart+0x70
从卦中看,GC正处于
SuspendEE
阶段,即冻结执行引擎,它的实现途径就是通过
while threads
的方式让每一个线程暂停,C++参考代码如下:
void ThreadSuspend::SuspendRuntime(ThreadSuspend::SUSPEND_REASON reason)
{
while (true)
{
Thread* thread = NULL;
while ((thread = ThreadStore::GetThreadList(thread)) != NULL)
{
}
}
}
所以接下来的探索方向就是看看当前的 SupendEE 到底正在处理哪一个线程?
2. 如何挖到处理线程
要挖处理线程方法比较多,你可以逆向的分析汇编代码,第二种就是写个脚本在线程栈空间中搜索托管线程地址。这里选择后者,毕竟简单粗暴。
- 托管线程列表,即下面的
ThreadOBJ
字段。
0:000:x86> !t
ThreadCount: 176
UnstartedThread: 1
BackgroundThread: 26
PendingThread: 0
DeadThread: 148
Hosted Runtime: no
Lock
DBG ID OSID ThreadOBJ State GC Mode GC Alloc Context Domain Count Apt Exception
0 1 fec 023BDF08 26020 Preemptive 0F608E60:0F60A528 023452a8 -00001 Ukn
7 2 2c0c 023CAC98 2b220 Preemptive 03230120:03231900 023452a8 -00001 Ukn (Finalizer)
11 4 2d48 24738AF0 102b220 Preemptive 0738C3C0:0738DC8C 023452a8 -00001 Ukn (Threadpool Worker)
12 5 2d4c 24774BE0 102b220 Preemptive 00000000:00000000 023452a8 -00001 Ukn (Threadpool Worker)
16 8 2d68 247C9820 20220 Preemptive 0356A5EC:0356B150 023452a8 -00001 Ukn
13 9 2d54 247C1878 20220 Preemptive 0B6A3384:0B6A33AC 023452a8 -00001 Ukn
XXXX 11 0 247F8B28 1600 Preemptive 00000000:00000000 023452a8 -00001 Ukn
28 12 2dbc 24825760 21220 Preemptive 00000000:00000000 023452a8 -00001 Ukn
29 13 2dc0 2482D088 21220 Preemptive 00000000:00000000 023452a8 -00001 Ukn
...
58 156 2910 246714A8 102b222 Cooperative 0F56F618:0F56F884 023452a8 -00001 Ukn (Threadpool Worker)
...
0:000:x86> !address -f:Stack
BaseAddr EndAddr+1 RgnSize Type State Protect Usage
-----------------------------------------------------------------------------------------------
2bc0000 2c3d000 7d000 MEM_PRIVATE MEM_RESERVE Stack32 [~3; ff0.608]
2c3d000 2c3e000 1000 MEM_PRIVATE MEM_COMMIT PAGE_READWRITE | PAGE_GUARD Stack32 [~3; ff0.608]
2c3e000 2c40000 2000 MEM_PRIVATE MEM_COMMIT PAGE_READWRITE Stack32 [~3; ff0.608]
- 搜索脚本
脚本的目的是在
2c3e000 ~ 2c40000
中搜索托管线程address。
use strict;
// 32bit
let arr = [];
function initializeScript() { return [new host.apiVersionSupport(1, 7)]; }
function log(str) { host.diagnostics.debugLog(str + "\n"); }
function exec(str) { return host.namespace.Debugger.Utility.Control.ExecuteCommand(str); }
function invokeScript() {
var output = exec("!t").Skip(8);
for (var line of output) {
if (!line) continue;
log(line);
var address = line.substr(19, 8);
log(address);
searchmemory(address);
}
}
function searchmemory(address) {
var output = exec("s-d 02c3e960 2c40000 " + address);
for(var line of output){
log(line);
}
}

执行完之后,发现 SuspendEE 正在处理的是 58号线程,细心的朋友会发现上面的
!t
输出的58号线程正是 Cooperative 状态,即协作状态,也就是还没有被 SuspendEE 处理。 哈哈,马上就要看到光明顶了,接下来的方向就是洞察 58号线程正在做什么?
3. 58号线程正在做什么
这就比较简单了,使用
~58s
切到该线程查看线程栈即可。
0:000:x86> ~58s
02c52da4 807e3400 cmp byte ptr [esi+34h],0 ds:002b:0b15cc78=01
0:058:x86> !clrstack
OS Thread Id: 0x2910 (58)
Child SP IP Call Site
40EAFA0C 02c52da4 xxx.xxx.PlayWavStream(System.IO.Stream, System.String)
40EAFA54 024e4915 xxx.xxx+c__DisplayClass8_0.b__0()
40EAFA94 024c849d System.Threading.Tasks.Task.InnerInvoke() [/_/src/libraries/System.Private.CoreLib/src/System/Threading/Tasks/Task.cs @ 2397]
40EAFAA0 024c2abd System.Threading.Tasks.Task+c.<.cctor>b__272_0(System.Object) [/_/src/libraries/System.Private.CoreLib/src/System/Threading/Tasks/Task.cs @ 2376]
40EAFAA8 00536547 System.Threading.ExecutionContext.RunFromThreadPoolDispatchLoop(System.Threading.Thread, System.Threading.ExecutionContext, System.Threading.ContextCallback, System.Object) [/_/src/libraries/System.Private.CoreLib/src/System/Threading/ExecutionContext.cs @ 268]
40EAFAD8 024c2852 System.Threading.Tasks.Task.ExecuteWithThreadLocal(System.Threading.Tasks.Task ByRef, System.Threading.Thread) [/_/src/libraries/System.Private.CoreLib/src/System/Threading/Tasks/Task.cs @ 2337]
40EAFB3C 39d3925f System.Threading.ThreadPoolWorkQueue.Dispatch()
40EAFB90 00538145 System.Threading.PortableThreadPool+WorkerThread.WorkerThreadStart() [/_/src/libraries/System.Private.CoreLib/src/System/Threading/PortableThreadPool.WorkerThread.cs @ 107]
40EAFB94 00537f5c [InlinedCallFrame: 40eafb94]
40EAFC38 00537f5c System.Threading.Thread.StartCallback() [/_/src/coreclr/System.Private.CoreLib/src/System/Threading/Thread.CoreCLR.cs @ 106]
40EAFD8C 58dfd24f [DebuggerU2MCatchHandlerFrame: 40eafd8c]
根据线程栈上的 PlayWavStream 方法来检查源码,发现了一个无语的写法,截图如下:

从源码看是用一个死循环来强留一个线程,无语了,这也疑似导致 GC 因为找不到safepoint而长时间不能暂停它,这里说疑似,是因为在coreclr中是有支撑的。

解决办法就比较简单了。
- 加个 Thread.Sleep
- 换种截停的写法。
- 升级 coreclr 的版本
三:总结
这次生产事故,对一般人来说还是有一定的难度,毕竟这种东西不是几个命令就能弄出来的,还是需要考察你对coreclr 一些底层知识的熟悉度。