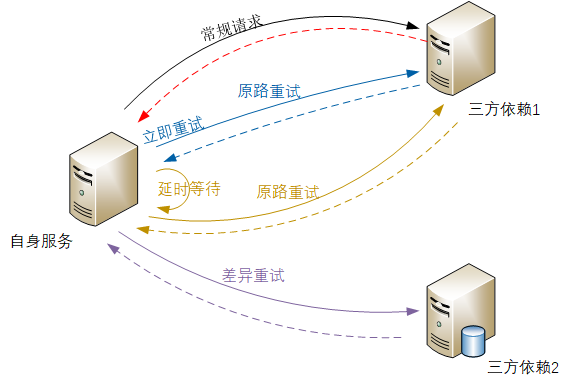
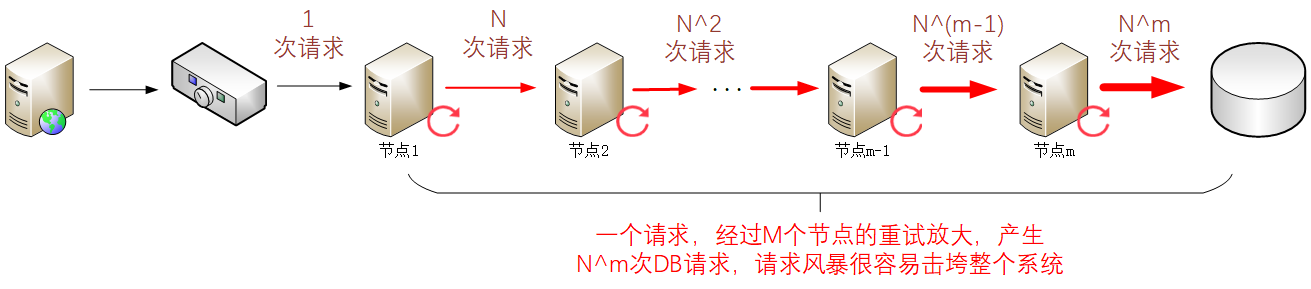
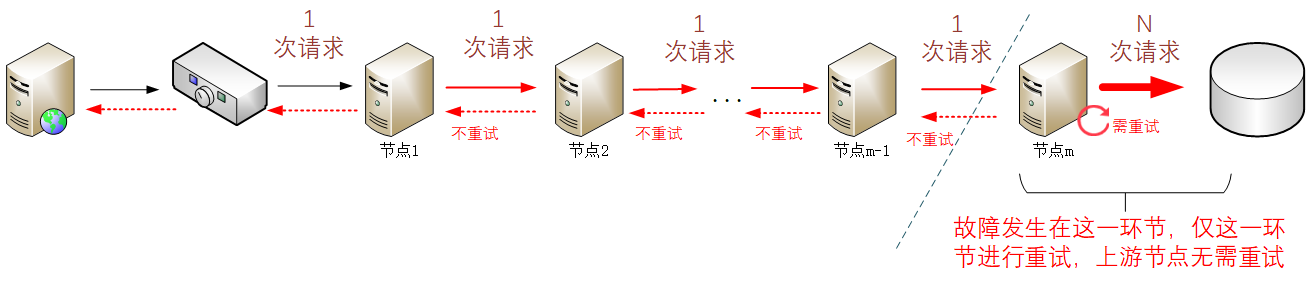
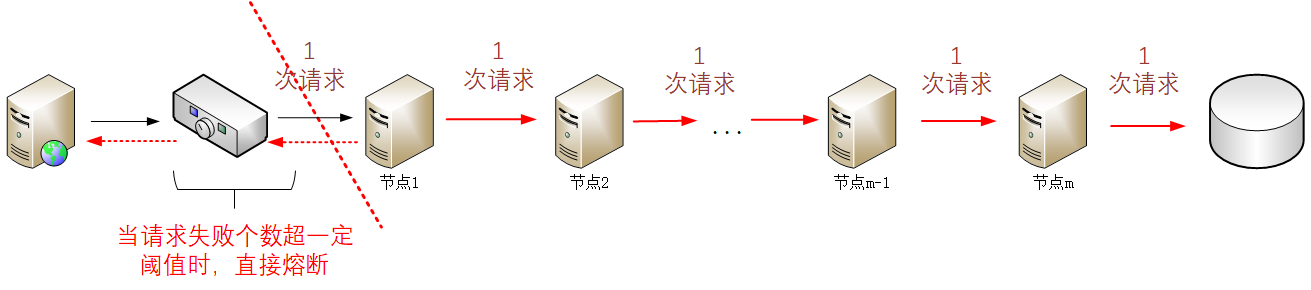
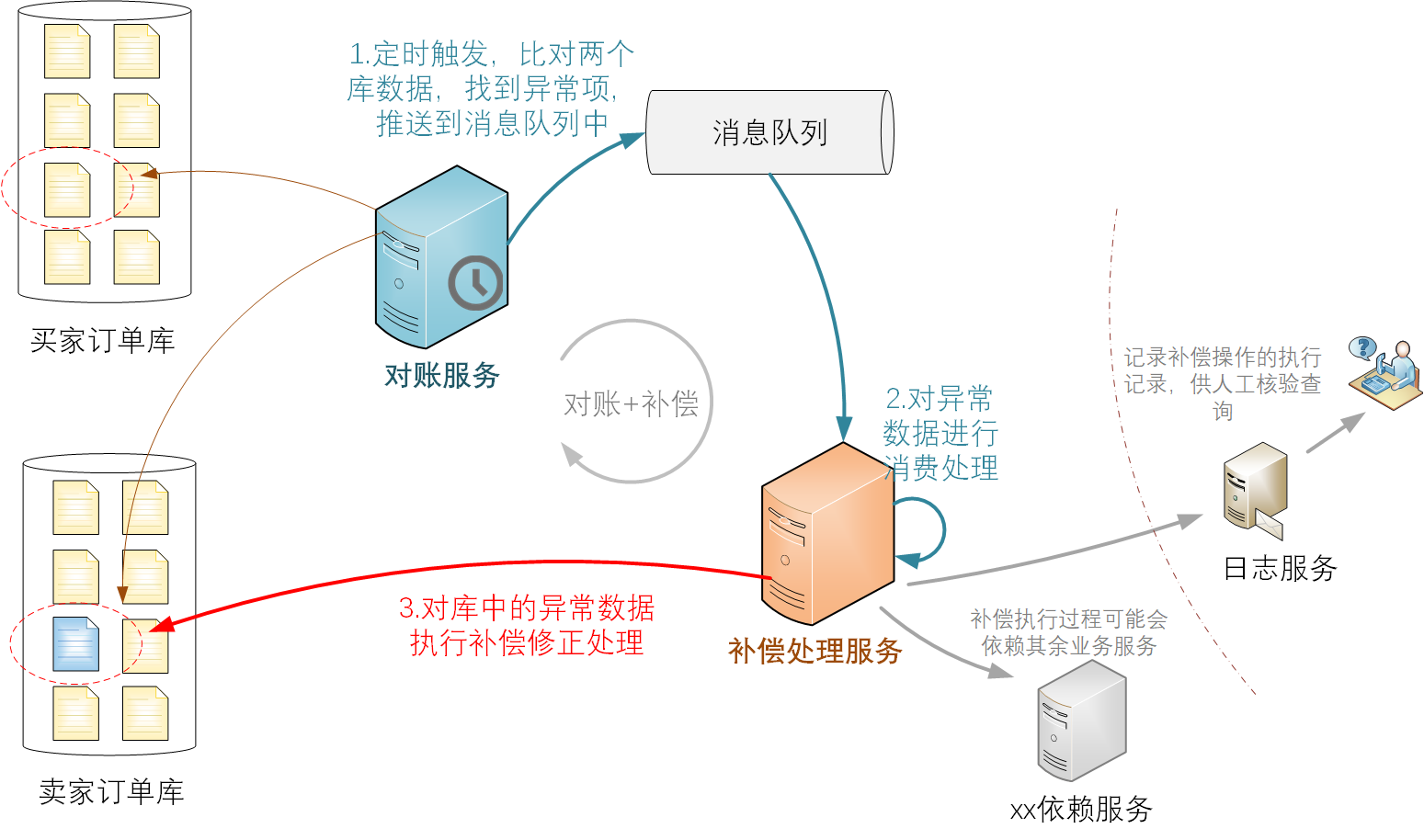
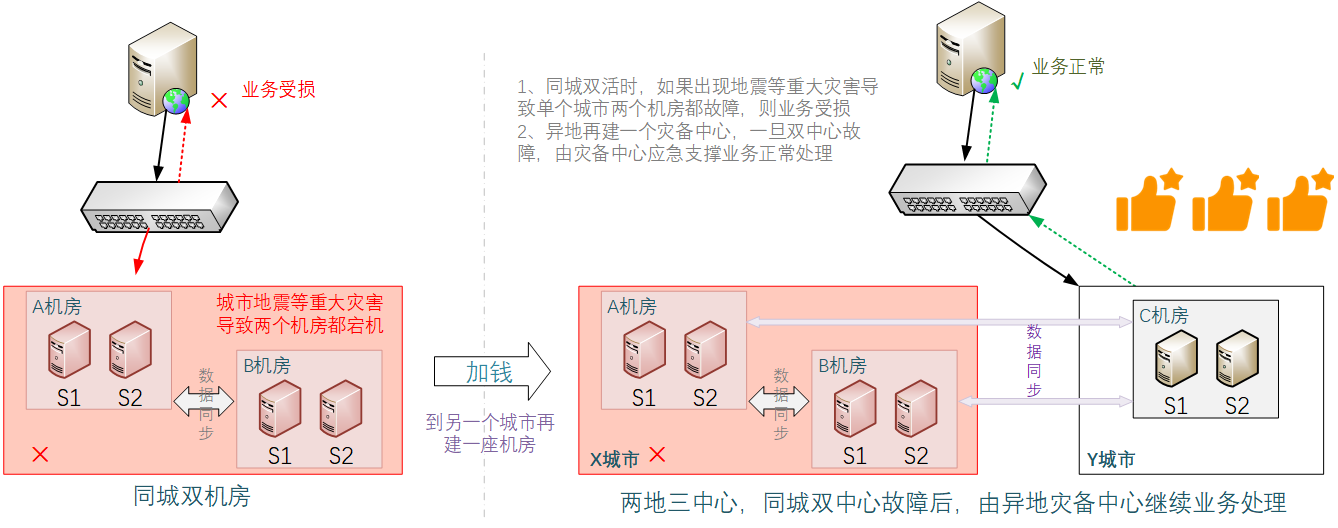
[这可能是最好的Spring教程!]Maven的模块管理——如何拆分大项目并且用parent继承保证代码的简介性
问题的提出
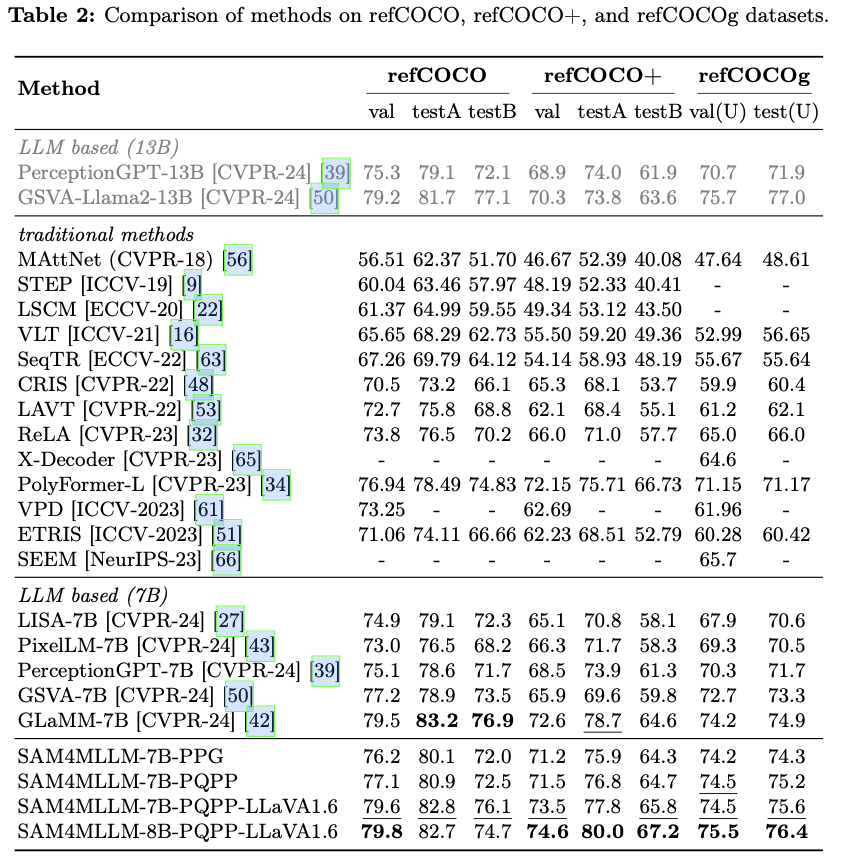
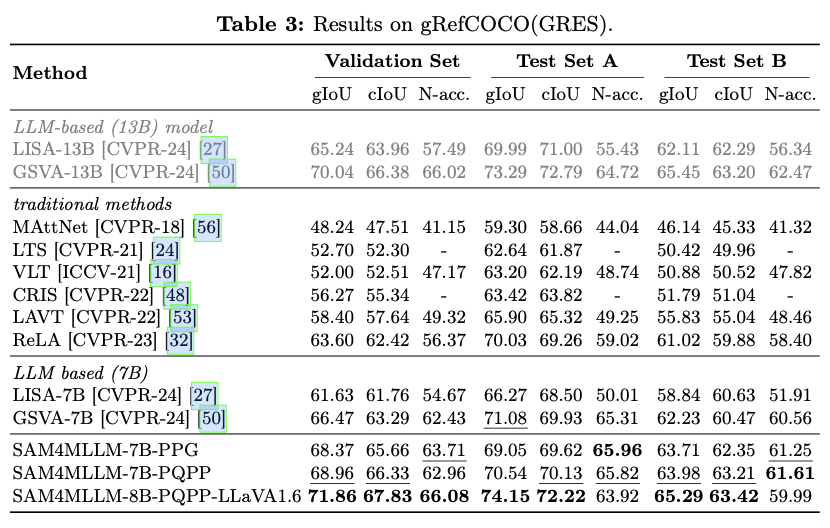
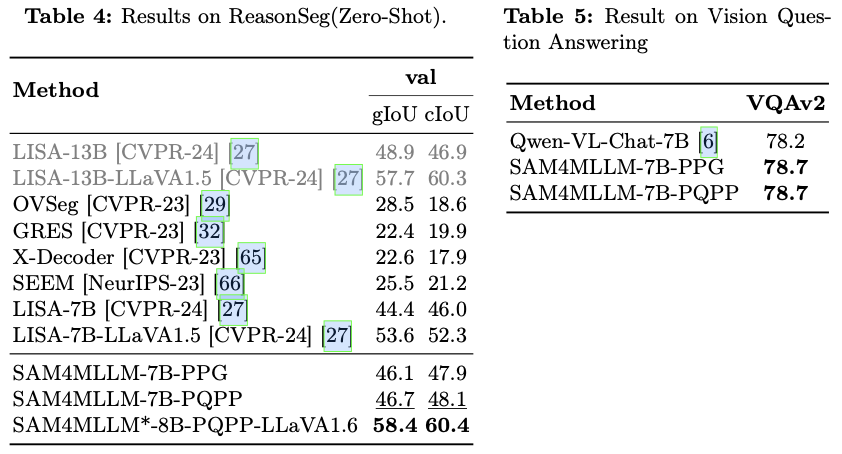
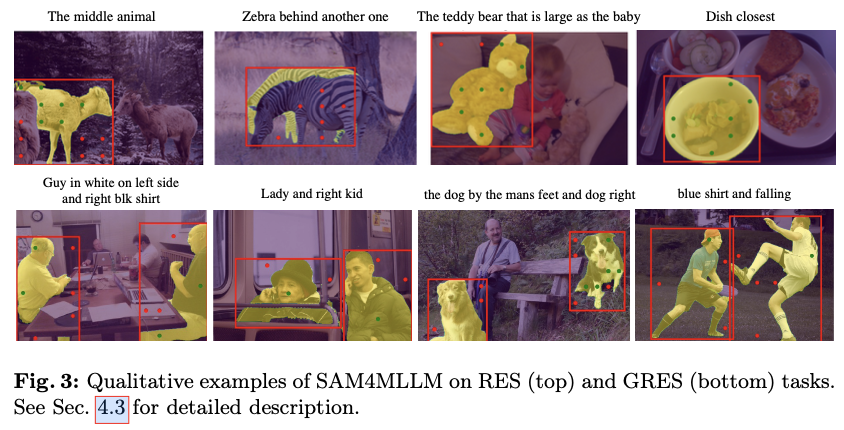
在软件开发中,我们为了减少软件的复杂度,是不会把所有的功能都塞进一个模块之中的,塞在一个模块之中对于软件的管理无疑是极其困难且复杂的。所以把一个项目拆分为模块无疑是一个好方法
┌ ─ ─ ─ ─ ─ ─ ┐
┌─────────┐
│ │Module A │ │
└─────────┘
┌──────────────┐ split │ ┌─────────┐ │
│Single Project│───────▶ │Module B │
└──────────────┘ │ └─────────┘ │
┌─────────┐
│ │Module C │ │
└─────────┘
└ ─ ─ ─ ─ ─ ─ ┘
对于Maven工程来说,原来是一个大项目:
single-project
├── pom.xml
└── src
现在可以分拆成3个模块:
multiple-projects
├── module-a
│ ├── pom.xml
│ └── src
├── module-b
│ ├── pom.xml
│ └── src
└── module-c
├── pom.xml
└── src
我们能看到的是每一个模块都有属于自己的
pom.xml
,然后模块A的
pom.xml
是这样的:
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.itranswarp.learnjava</groupId>
<artifactId>module-a</artifactId>
<version>1.0</version>
<packaging>jar</packaging>
<name>module-a</name>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<maven.compiler.source>11</maven.compiler.source>
<maven.compiler.target>11</maven.compiler.target>
<java.version>11</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.28</version>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.2.3</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter-engine</artifactId>
<version>5.5.2</version>
<scope>test</scope>
</dependency>
</dependencies>
</project>
之后B的
pom.xml
也大同小异,只用把
<artifactId>module-a</artifactId>
和
<name>module-a</name>
改为自己的就行。这个时候我们就会发现一个很麻烦的事,我们很多地方都是一样的,但是每一个模块的pom都需要我们重复声明出来,那我们能不能用像对象那样继承下来,这样就不用重复声明了呢?Maven无疑是有这样的功能的
问题的解决
简化后的结构
我们现在看看简化后的模块结构式如何的
multiple-project
├── pom.xml
├── parent
│ └── pom.xml
├── module-a
│ ├── pom.xml
│ └── src
├── module-b
│ ├── pom.xml
│ └── src
└── module-c
├── pom.xml
└── src
与之对比的是根目录多了一个pom,然后多加了一个"模块"parent,里面没有代码src,只有一个裸的pom。
看了对比之后我们一个一个讲是怎么修改的,结构又是怎么样的
修改细则
parent
我们先来看parent里面的pom是怎么个事
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.itranswarp.learnjava</groupId>
<artifactId>parent</artifactId>
<version>1.0</version>
<packaging>pom</packaging>
<name>parent</name>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<maven.compiler.source>11</maven.compiler.source>
<maven.compiler.target>11</maven.compiler.target>
<java.version>11</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.28</version>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.2.3</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter-engine</artifactId>
<version>5.5.2</version>
<scope>test</scope>
</dependency>
</dependencies>
</project>
我们能发现的是,对于之前的模块A修改其实也不多,修改的分别是
<artifactId>parent</artifactId>
<packaging>pom</packaging>
<name>parent</name>
这里我们着重讲一下
<packaging>pom</packaging>
,首先我们先明白
<packaging>
这个标签代表了什么,
<packaging>
这个标签他表示打包的方式,常见的值为
jar
(Java库)、
war
(Web应用)、
pom
(父项目)等。这个地方
parent
的
packaging
设置为
pom
,因为它不生成任何可执行的JAR文件,仅提供配置和依赖管理。
其他模块的简化思路
看完了parent的代码之后我们就慢慢地去理清简化的思路
编码与java版本配置
首当其冲的无疑就是这个部分,这个地方模块AB都是需要的,而且都是一样的,那么这个元素就是可以被继承的,也就是
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<maven.compiler.source>11</maven.compiler.source>
<maven.compiler.target>11</maven.compiler.target>
<java.version>11</java.version>
</properties>
公共依赖项
其次就是AB都需要的依赖项如
slf4j-api
、
logback-classic
和
junit-jupiter-engine
,以及作用域的设置
<dependencies>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.28</version>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.2.3</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter-engine</artifactId>
<version>5.5.2</version>
<scope>test</scope>
</dependency>
</dependencies>
修改后的模块A的pom
我们再开看看修改后模块A的pom是怎么样的
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>com.itranswarp.learnjava</groupId>
<artifactId>parent</artifactId>
<version>1.0</version>
<relativePath>../parent/pom.xml</relativePath>
</parent>
<artifactId>module-a</artifactId>
<packaging>jar</packaging>
<name>module-a</name>
</project>
不得不说有了parent之后,整个模块都变得简洁了起来
在设置好
parent
模块后,我们只需要引用
parent
作为其他模块的父模块。
首先通过
<parent>
标签引用
parent
模块
<parent>
<groupId>com.itranswarp.learnjava</groupId>
<artifactId>parent</artifactId>
<version>1.0</version>
<relativePath>../parent/pom.xml</relativePath>
</parent>
有了这些之后就相当于继承了parent里面的元素了。
之后我们再导入自己独有的元素就基本上完成了对此模块的配置
<artifactId>module-a</artifactId>
<packaging>jar</packaging>
<name>module-a</name>
继承
parent
模块后,模块A和模块B的
pom.xml
文件已经大幅简化。所有公共配置项,如
UTF-8
编码、Java编译版本、以及日志和测试的依赖库,均已在
parent
中配置好。这样,模块A和模块B仅需保留独有的内容,简化了配置并降低了维护成本。
相互的引用
如果模块A需要引用模块B的代码,可以在模块A的
<dependencies>
中增加对模块B的依赖项,如下:
<dependencies>
<dependency>
<groupId>com.itranswarp.learnjava</groupId>
<artifactId>module-b</artifactId>
<version>1.0</version>
</dependency>
</dependencies>
通过这一配置,Maven会在构建模块A时自动获取模块B生成的JAR文件,使得模块A可以使用模块B中的代码和功能。
根目录pom的配置
最后的最后,我们配置最后根目录pom的思路就是为了完成所有项目的统一编译:
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.itranswarp.learnjava</groupId>
<artifactId>build</artifactId>
<version>1.0</version>
<packaging>pom</packaging>
<name>build</name>
<modules>
<module>parent</module>
<module>module-a</module>
<module>module-b</module>
<module>module-c</module>
</modules>
</project>
这样,在根目录执行
mvn clean package
时,Maven根据根目录的
pom.xml
找到包括
parent
在内的共4个
<module>
,一次性全部编译。
这可能是最好的Spring教程!
感谢您看到这里
这可能是最好的Spring教程系列
更多的文章可以到这查看
这可能是最好的Spring教程!即便无基础也能看懂的入门Spring,仍在持续更新。
,我还在荔枝更新出最详细的Spring教程