0.背景
XtraBackup 优势
- 在线热备
:支持在不停止数据库的情况下进行 InnoDB 和 XtraDB 的热备份,适合高可用环境。
- 增量备份
:支持增量备份,能够显著减少备份时间和存储空间需求。
- 流压缩
:可以在备份过程中进行流压缩,减少传输数据量,提高传输效率。
- 主从同步
:XtraBackup 可以更方便地创建和维护主从同步关系,简化数据库扩展。
- 低负载备份
:在备份过程中对主数据库的负载相对较小,不会显著影响正常业务。
备份工具选择
- xtrabackup
:专门用于 InnoDB 和 XtraDB 表的备份。
- innobackupex
:一个脚本封装,能够同时处理 InnoDB 和 MyISAM 表,但在处理 MyISAM 时会加锁。
其他备份策略
一、备份方式 xtrabackup
1.安装
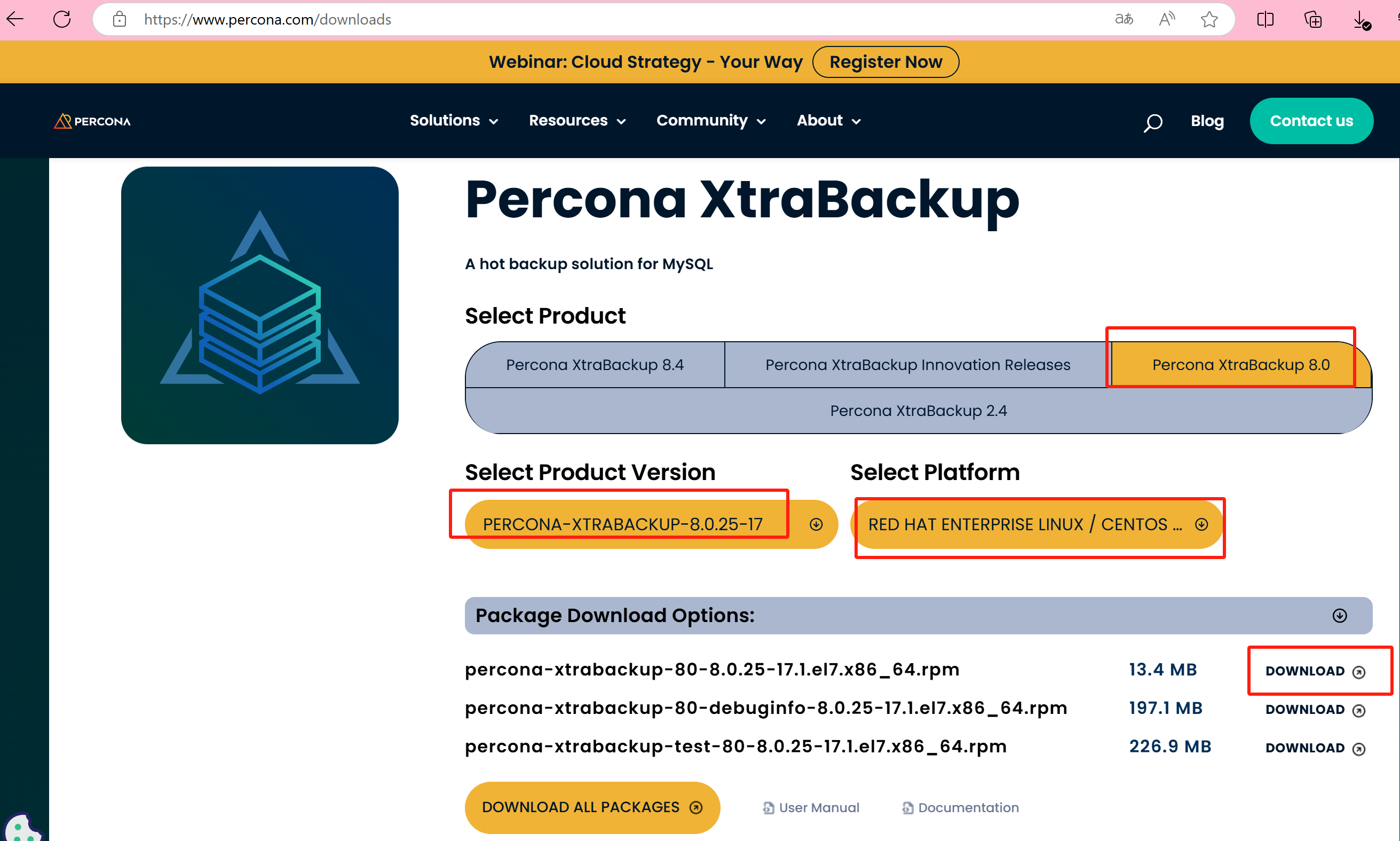
Software Downloads - Percona
mysql版本:mysql8.0.24
xtrabackup版本:8.0.25
版本对应关系
暂时没用
在线安装
yum install -y https://repo.percona.com/yum/percona-release-latest.noarch.rpm
yum install -y percona-xtrabackup-80
yum list | grep percona-xtrabackup
离线包下载地址
服务器更新yum源
sudo cp /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.bak
sudo wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
sudo yum clean all
sudo yum makecache
依赖包安装
sudo yum install epel-release
sudo yum install -y zstd
zstd --version
离线安装,需要网络解决依赖
yum -y localinstall percona-xtrabackup-80-8.0.25-17.1.el7.x86_64.rpm
2.备份
2.1 工具说明
Xtrabackup 工具简介
- xtrabackup
:用于热备份 InnoDB 和 XtraDB 表的数据工具,不能备份其他类型的表或数据表结构。
- innobackupex
:将
xtrabackup
封装的 Perl 脚本,提供了备份 MyISAM 表的能力。
常用选项
2.2 全量备份
xtrabackup --backup \
--target-dir=/var/backups/xtrabackup \
--datadir=/data/dstore/1.0.0.0/mysql/data \
--parallel=4 \
--user=root \
--password=Hbis@123 \
--socket=/srv/dstore/1.0.0.0/mysql/mysql.sock \
--host=localhost \
--compress \
--compress-threads=4 \
--compress-chunk-size=65536
gzip 本地压缩备份
使用流式备份,配合管道使用 gzip 命令对备份在本地进行压缩
--stream=xbstream \
| gzip - > /data/backup/backup1.gz
恢复时需要先使用 gunzip 解压,再使用 xbstream 解压,才能进行 Prepare 阶段。
# gzip 解压
gunzip backup1.gz
# xbstream 解压
xbstream -x --parallel=10 -C /data/backup/backup_full < ./backup1
说明
--target-dir
:备份目标目录需要事先创建,确保该目录存在。
--password
:建议使用环境变量或其他安全方式传递密码以保护敏感信息。
--compress=quicklz
指定使用
quicklz
作为压缩算法。
--compress-threads=4
指定使用 4 个线程进行压缩。
--compress-chunk-size=65536
指定压缩线程的工作缓冲区大小。
报错,没有权限
failed to execute query ‘LOCK INSTANCE FOR BACKUP’ : 1227 (42000) Access denied
grant BACKUP_ADMIN on *.* to 'root'@'%';
flush privileges;
LOCK INSTANCE FOR BACKUP 是MySQL 8.0引入的一种新的备份相关SQL语句,主要用于在进行数据库备份时,以一种更为细粒度和高效的方式控制对数据库实例的访问,以保证备份的一致性。这个命令的工作原理及特点如下:
目的:在执行备份操作时,此命令用于获取一个实例级别的锁,该锁允许在备份过程中继续执行DML(数据操作语言,如INSERT、UPDATE、DELETE)操作,同时防止那些可能导致数据快照不一致的DDL(数据定义语言,如CREATE、ALTER、DROP)操作和某些管理操作。这样可以在不影响数据库服务的情况下进行备份,特别适用于需要最小化服务中断的在线备份场景。
权限需求:执行LOCK INSTANCE FOR BACKUP语句需要用户具备BACKUP_ADMIN权限。这是一个专门为了备份相关的高级操作而设计的权限级别。
兼容性:此特性是在MySQL 8.0及以上版本中引入的,早于8.0的MySQL版本并不支持这一语句,因此在使用旧版本时,可能需要依赖其他机制(如FLUSH TABLES WITH READ LOCK)来确保备份的一致性。
解锁:执行备份后,需要使用UNLOCK INSTANCE语句来释放之前由LOCK INSTANCE FOR BACKUP获得的锁,从而恢复正常操作。
与传统备份命令的对比:相比于传统的备份方法,如使用FLUSH TABLES WITH READ LOCK,LOCK INSTANCE FOR BACKUP提供了更小的性能影响,因为它不会完全阻止写操作,只是限制了可能引起数据不一致的活动,更适合于高可用性和高性能要求的生产环境。
2.3 增量备份
xtrabackup 支持增量备份。在做增量备份之前,需要先做一个全量备份。xtrabackup 会基于 innodb page 的 lsn 号来判断是否需要备份一个 page。如果 page lsn 大于上次备份的 lsn 号,就需要备份该 page。
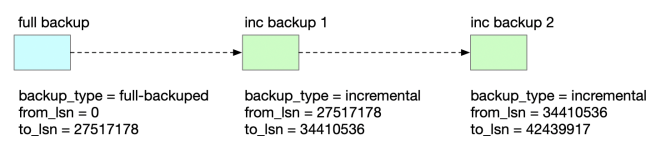
先进行一次全量备份。
xtrabackup --backup \
--target-dir=/var/backups/full \
--extra-lsndir=/var/backups/full \
--datadir=/data/dstore/1.0.0.0/mysql/data \
--parallel=4 \
--user=root \
--password=Hbis@123 \
--socket=/srv/dstore/1.0.0.0/mysql/mysql.sock \
--host=localhost \
--compress \
--compress-threads=4 \
--compress-chunk-size=65536 \
--stream=xbstream \
2>/var/backups/full/backup_full.log | gzip - > /var/backups/full/full.gz
备份命令加上 了–extra-lsndir 选项,将 xtrabackup_checkpoints 单独输出到文件。增量备份时需要根据 xtrabackup_checkpoints中的 lsn,以下是相关文件。
[root@node83 full]# ll
total 4684
-rw-r--r-- 1 root root 43918 Sep 25 15:40 backup_full.log
-rw-r--r-- 1 root root 4741603 Sep 25 15:40 full.gz
-rw-r--r-- 1 root root 102 Sep 25 15:40 xtrabackup_checkpoints
-rw-r--r-- 1 root root 794 Sep 25 15:40 xtrabackup_info
现在,发起增量备份。
xtrabackup --backup \
--target-dir=/var/backups/inc1 \
--extra-lsndir=/var/backups/inc1 \
--datadir=/data/dstore/1.0.0.0/mysql/data \
--user=root \
--password=Hbis@123 \
--socket=/srv/dstore/1.0.0.0/mysql/mysql.sock \
--host=localhost \
--compress \
--incremental-basedir=/var/backups/full \
--stream=xbstream \
2>/var/backups/full/backup_full.log | gzip - > /var/backups/inc1/backup_inc1.gz
- –incremental-basedir:全量备份或上一次增量备份 xtrabackup_checkpoints 文件所在目录
增量备份也可以在上一次增量备份的基础上进行
xtrabackup --backup \
--target-dir=/var/backups/inc2 \
--extra-lsndir=/var/backups/inc2 \
--datadir=/data/dstore/1.0.0.0/mysql/data \
--user=root \
--password=Hbis@123 \
--socket=/srv/dstore/1.0.0.0/mysql/mysql.sock \
--host=localhost \
--compress \
--incremental-basedir=/var/backups/inc1 \
--stream=xbstream \
| gzip - > /var/backups/inc2/backup_inc2.gz
结构如下
[root@node83 backups]# tree
.
├── full
│ ├── backup_full.log
│ ├── full.gz
│ ├── xtrabackup_checkpoints
│ └── xtrabackup_info
├── inc1
│ ├── backup_inc1.gz
│ ├── xtrabackup_checkpoints
│ └── xtrabackup_info
└── inc2
├── backup_inc2.gz
├── xtrabackup_checkpoints
└── xtrabackup_info
3 directories, 10 files
恢复增量备份时,需要先对基础全量备份进行恢复,然后再依次按增量备份的时间进行恢复。
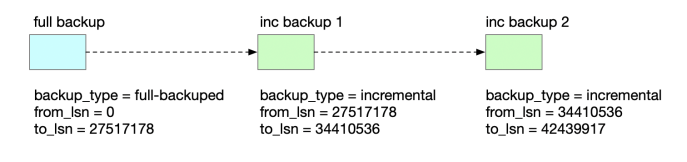
恢复全量备份
cd /var/backups/full
gunzip full.gz
# 需要先删除这两个文件,否则 xbstream 提取文件时有冲突
rm xtrabackup_checkpoints xtrabackup_info
xbstream -x -v < full
# 由于使用compress压缩,所有还有一层压缩
xtrabackup --decompress --target-dir=/var/backups/full
# 准备阶段
xtrabackup --prepare --apply-log-only --target-dir=. > prepare_full.log 2>&1
恢复增量备份时,切换到全量备份的目录执行
cd /var/backups/inc1
rm xtrabackup_checkpoints xtrabackup_info
gunzip full.gz
xbstream -x -v < full
# 由于使用compress压缩,所有还有一层压缩
xtrabackup --decompress --target-dir=/var/backups/inc1
cd ../full
xtrabackup \
--prepare \
--apply-log-only \
--incremental-dir=/data/backup/inc1 \
--target-dir=.
最后
2.4 流式备份
XtraBackup支持流式备份,将备份以指定的tar或xbstream格式发送到STDOUT,而不是直接将文件复制到备份目录。
在 xtrabackup 2.4 版中支持 tar 和 xbstream 流格式,但 tar 格式不支持并行备份。
在 xtrabackup 8.0 中,仅支持 xbstream 流格式,不再支持 tar 格式
xtrabackup --backup \
--datadir=/data/dstore/1.0.0.0/mysql/data \
--user=root \
--password=Hbis@123 \
--socket=/srv/dstore/1.0.0.0/mysql/mysql.sock \
--host=localhost \
--parallel=4 \
--compress \
--compress-threads=4 \
--compress-chunk-size=65536 \
--stream=xbstream | ssh -C root@192.168.2.41 "cat > /var/backups/backup.xbstream.gz"
登录远程主机解压
xbstream -x --parallel=10 -C /opt/backup < /opt/backups/backup.xbstream.gz
xbstream 中的 -x 表示解压,–parallel 表示并行度,-C 指定解压的目录,最后一级目录必须存在。
远程备份限速
直接备份到远程服务器,如果担心备份会占用较大的网络带宽,可以使用 pv 命令限速。
--stream=xbstream | pv -q -L10m | ssh -C root@192.168.2.41 "cat > /var/backups/backup.xbstream.gz"
pv 命令中,-q 是指 quiet 不输出进度信息,-L 是指传输速率 10m 指 10MB。
2.5 备份指定库
注意备份的单个库恢复到别的机器时,需要提前手动创建好数据库和表结构
我们可以备份数据库架构,并使用与上述相同的过程进行恢复。
使用
--databases
选项备份数据库
对于多个数据库,请将数据库指定为列表,例如
--databases=“db1 db2 db3”。
数据库也可以在文本文件中指定,并与选项
--databases-file
一起使用。要从备份中排除数据库,请使用选项
--databases-exclude
。
使用
--export
选项准备备份。
xtrabackup \
--defaults-file=/srv/dstore/1.0.0.0/mysql/conf/my.cnf \
--backup \
--target-dir=/var/backups/test2 \
--socket=/srv/dstore/1.0.0.0/mysql/mysql.sock \
--user=root \
--password=Hbis@123 \
--databases="test2" \
--stream=xbstream | gzip > test2.tar.gz
说明:
--defaults-file
:指定 MySQL 配置文件。
--backup
:表示执行备份操作。
--target-dir
:指定备份文件的目标目录。
--socket
:指定 MySQL socket 文件路径。
--user
和
--password
:指定连接数据库的用户和密码。
--databases
:指定要备份的数据库(在这里是
test2
)。
--stream=xbstream
:将备份数据以 xbstream 格式输出。
| gzip > test2.tar.gz
:将输出通过管道压缩为
test2.tar.gz
文件。
备份完成后scp到远端机器,如/var/backups ,执行导入命令
gunzip test2.tar.gz
xbstream -x --parallel=10 <test2
# 执行准备
xtrabackup --prepare --apply-log-only --export --target-dir=.
现在使用 ALTER TABLE
DISCARD TABLESPACE 删除数据库中所有 InnoDB 表的表空间。
ALTER TABLE person DISCARD TABLESPACE;
将所有表文件从备份目录 (/var/backups/test2/test/*) 复制到 mysql 数据目录 (/opt/mysql/data)。
注意:
在复制文件之前,请禁用 selinux。复制文件后,如果备份用户不同,请将复制文件的所有权更改为 mysql 用户。
最后,使用 ALTER TABLE
IMPORT TABLESPACE; 恢复表。
ALTER TABLE person IMPORT TABLESPACE;
这会将表还原到备份时。对于
时间点恢复
,二进制日志可以进一步应用于数据库,但应注意仅应用那些影响正在还原的表的事务。
使用此方法的优点是不需要停止数据库服务器。一个小缺点是每个表都需要单独恢复,尽管它可以在脚本的帮助下克服。
脚本如下:
#!/bin/bash
# 检查输入参数
if [ "$#" -lt 2 ]; then
echo "用法: \$0 <数据库名> <删除|导入>"
exit 1
fi
DB_NAME=\$1
ACTION=\$2
MYSQL_USER="root"
MYSQL_PASSWORD="Hbis@123"
MYSQL_SOCKET="/srv/dstore/1.0.0.0/mysql/mysql.sock"
# 获取所有表名
TABLES=$(mysql --user="$MYSQL_USER" --password="$MYSQL_PASSWORD" --socket="$MYSQL_SOCKET" -D "$DB_NAME" -e "SHOW TABLES;" | awk '{ print \$1 }' | grep -v '^Tables_in_')
echo "数据库 '$DB_NAME' 中的表: $TABLES"
# 根据操作参数执行删除或导入
for TABLE in $TABLES; do
if [ "$ACTION" == "删除" ]; then
echo "删除表空间: $TABLE"
mysql --user="$MYSQL_USER" --password="$MYSQL_PASSWORD" --socket="$MYSQL_SOCKET" -D "$DB_NAME" -e "ALTER TABLE $TABLE DISCARD TABLESPACE;"
elif [ "$ACTION" == "导入" ]; then
echo "导入表空间: $TABLE"
mysql --user="$MYSQL_USER" --password="$MYSQL_PASSWORD" --socket="$MYSQL_SOCKET" -D "$DB_NAME" -e "ALTER TABLE $TABLE IMPORT TABLESPACE;"
else
echo "无效的操作: $ACTION"
exit 1
fi
done
echo "操作完成."
3. 恢复备份
解压缩
压缩算法默认是
qpress
,所以解压缩需要有 qpress 命令
yum -y install qpress
使用 --decompress压缩的备份集在准备备份之前需要解压,解压工具是qpress。解压后的原文件不会被删除,可以使用--remove-original选项清除,--parallel可与--decompress选项一起使用以同时解压缩多个文件。
xtrabackup --defaults-file=/opt/mysql/conf/my.cnf --decompress --target-dir=/var/backups/xtrabackup
准备备份命令
首先要进行 Prepare 阶段,在该阶段 Xtrabackup 会启动一个嵌入的 InnoDB 实例来进行 Crash Recovery。该实例的缓冲池的大小由 --use-memory 参数指定,默认为 100MB。如果有充足的内存,通过设置较大的 memory 可以减少 Prepare 阶段花费的时间。
--use-memory=2G
xtrabackup --defaults-file=/opt/mysql/conf/my.cnf \
--prepare \
--target-dir=/var/backups/xtrabackup \
--user=root \
--password=123456 \
--socket=/opt/mysql/mysql.sock \
--host=localhost \
--apply-log-only
Prepare 阶段完成后,下面进入恢复阶段,可以手动拷贝文件到数据目录,也可以使用 xtrabackup 工具进行拷贝。
恢复备份命令
xtrabackup --defaults-file=/opt/mysql/conf/my.cnf \
--copy-back \
--parallel=10 \
--target-dir=/var/backups/xtrabackup \
--user=root \
--password=Hbis@123 \
--socket=/srv/dstore/1.0.0.0/mysql/mysql.sock \
--host=localhost
恢复全量备份时,需要加上 apply-log-only 参数。如果不加上 apply-log-only 参数,执行 prepare 的最后阶段,会回滚未提交的事务,但是这些事务可能在下一次增量备份时已经提交了。
- 恢复备份前需要保证数据目录为空
- 数据库必须处于停止状态
执行成功后,必须授权
chown -R mysql:mysql /opt/mysql/data
启动数据库
mysqld_safe --defaults-file=/etc/my.cnf &
二、测试数据完整性
方式一
- 模拟4个数据库,执行定时数据写入,模拟随机插入。
- 备份
- scp数据,恢复数据到从机
- 配置主从,停止主节点脚本,对比数据完整性
编写脚本
模拟数据
#!/bin/bash
# MySQL 配置
MYSQL_USER="root"
MYSQL_PASSWORD="Hbis@123"
MYSQL_SOCKET="/srv/dstore/1.0.0.0/mysql/mysql.sock"
# 创建数据库和插入数据的函数
create_databases_and_insert_data() {
for i in {1..4}; do
DB_NAME="test_db_$i"
TABLE_NAME="test_table"
# 创建数据库
mysql --user="$MYSQL_USER" --password="$MYSQL_PASSWORD" --socket="$MYSQL_SOCKET" -e "CREATE DATABASE IF NOT EXISTS $DB_NAME;"
# 创建表
mysql --user="$MYSQL_USER" --password="$MYSQL_PASSWORD" --socket="$MYSQL_SOCKET" -D "$DB_NAME" -e "
CREATE TABLE IF NOT EXISTS $TABLE_NAME (
id INT AUTO_INCREMENT PRIMARY KEY,
data_value VARCHAR(255) NOT NULL
);"
# 插入约10000条数据
for ((j=1; j<=10000; j++)); do
random_string=$(tr -dc 'A-Za-z0-9' < /dev/urandom | head -c 10)
mysql --user="$MYSQL_USER" --password="$MYSQL_PASSWORD" --socket="$MYSQL_SOCKET" -D "$DB_NAME" -e "
INSERT INTO $TABLE_NAME (data_value) VALUES ('$random_string');"
done
echo "数据库 $DB_NAME 创建完成,已插入 10000 条数据."
done
}
# 执行创建数据库和插入数据
create_databases_and_insert_data
单个库数据量:474K
模拟定时插入脚本
#!/bin/bash
# MySQL 配置
MYSQL_USER="root"
MYSQL_PASSWORD="Hbis@123"
MYSQL_SOCKET="/srv/dstore/1.0.0.0/mysql/mysql.sock"
# 数据库和表的名称
DB_COUNT=4
TABLE_NAME="test_table"
INSERT_COUNT=10 # 设置要插入的总数
# 模拟定时插入数据
insert_data() {
for ((n=1; n<=INSERT_COUNT; n++)); do
for i in $(seq 1 $DB_COUNT); do
DB_NAME="test_db_$i"
random_string=$(tr -dc 'A-Za-z0-9' < /dev/urandom | head -c 10)
mysql --user="$MYSQL_USER" --password="$MYSQL_PASSWORD" --socket="$MYSQL_SOCKET" -D "$DB_NAME" -e "
INSERT INTO $TABLE_NAME (data_value) VALUES ('$random_string');"
echo "向 $DB_NAME 插入数据: $random_string"
done
sleep 2 # 每次循环后暂停1秒
done
}
# 执行数据插入
insert_data
模拟数据生成后,开启定时写入脚本,接下来开始执行备份
nohup sh insert_data.sh > insert_data.log 2>&1 &
备份测试
首先备份全量数据
xtrabackup --backup \
--target-dir=/var/backups/xtrabackup \
--datadir=/data/dstore/1.0.0.0/mysql/data \
--parallel=4 \
--user=root \
--password=Hbis@123 \
--socket=/srv/dstore/1.0.0.0/mysql/mysql.sock \
--host=localhost \
--compress \
--compress-threads=4 \
--compress-chunk-size=65536
再执行增量备份
查看偏移点
mysql> show master status;
+---------------+----------+--------------+------------------+----------------------------------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+---------------+----------+--------------+------------------+----------------------------------------------+
| binlog.000029 | 26321 | | | 3949cf93-71b5-11ef-925f-fa163e75258c:1-40306 |
+---------------+----------+--------------+------------------+----------------------------------------------+
1 row in set (0.03 sec)
开始增量备份
xtrabackup --backup \
--target-dir=/var/backups/inc1 \
--extra-lsndir=/var/backups/inc1 \
--datadir=/data/dstore/1.0.0.0/mysql/data \
--user=root \
--password=Hbis@123 \
--socket=/srv/dstore/1.0.0.0/mysql/mysql.sock \
--host=localhost \
--compress \
--incremental-basedir=/var/backups/xtrabackup
执行完后,开始执行恢复操作,需要将xtrabackup目录和inc1 传输到从节点
scp -r /var/backups/ 192.168.2.41:`pwd`
执行恢复操作【参考上述3.0恢复备份】
数据迁移完成,启动数据库后执行主从配置
stop slave;
CHANGE MASTER TO
MASTER_HOST='192.168.2.83',
MASTER_USER='asyncuser',
MASTER_PASSWORD='Hbis@123',
MASTER_PORT=3306,
MASTER_LOG_FILE='binlog.000029',
MASTER_LOG_POS=26321;
start slave;
show slave status\G;
执行成功后,检查数据一致性
|
数据库
|
主
|
从
|
| test_table1 |
10033 |
10033 |
| test_table2 |
10033 |
10033 |
| test_table3 |
10033 |
10033 |
可以看到数据是一致的
方式二
在进行备份之前,您需要启用 innodb_file_per_table
开启数据循环插入脚本
备份 test_table1 、test_table2、test_table3、test_table4,命令示例:
xtrabackup \
--defaults-file=/srv/dstore/1.0.0.0/mysql/conf/my.cnf \
--backup \
--target-dir=/var/backups/db1 \
--socket=/srv/dstore/1.0.0.0/mysql/mysql.sock \
--user=root \
--password=Hbis@123 \
--databases="test_db_1"
数据备份完成并传输到从机,执行恢复操作
xtrabackup \
--prepare \
--export \
--apply-log-only \
--target-dir=/var/backups/db1
发现报错
[ERROR] [MY-012179] [InnoDB] Could not find any file associated with the tablespace ID: 10
暂时没有排查出来,测试发现当定时写入脚本运行时,导出的数据报错
依次恢复每个数据的表
检查发现数据存在无法同步,不一致
$.参考
https://blog.csdn.net/m0_66011019/article/details/136206192
https://blog.csdn.net/weixin_4156186
MySQL 社区开源备份工具 Xtrabackup 详解-CSDN博客
Percona XtraBackup:备份和恢复单个表或数据库
备份和恢复单个数据库 - MySQL & MariaDB / Percona XtraBackup - Percona社区论坛