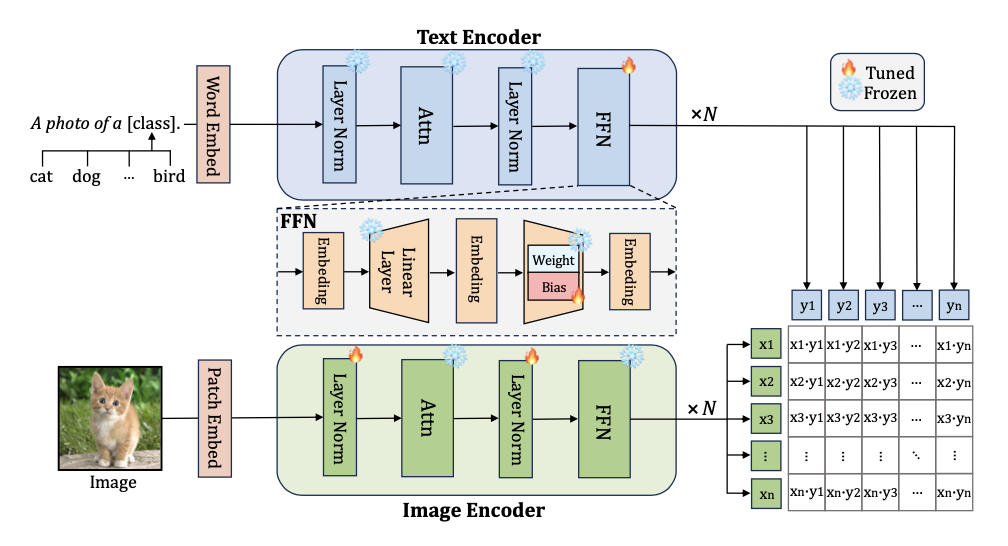
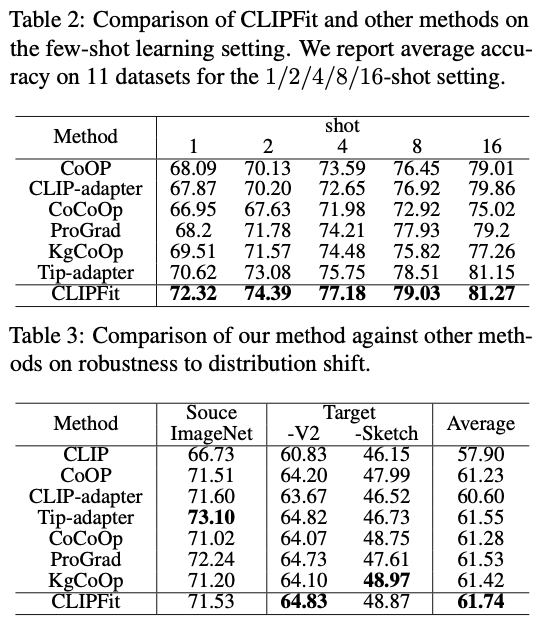
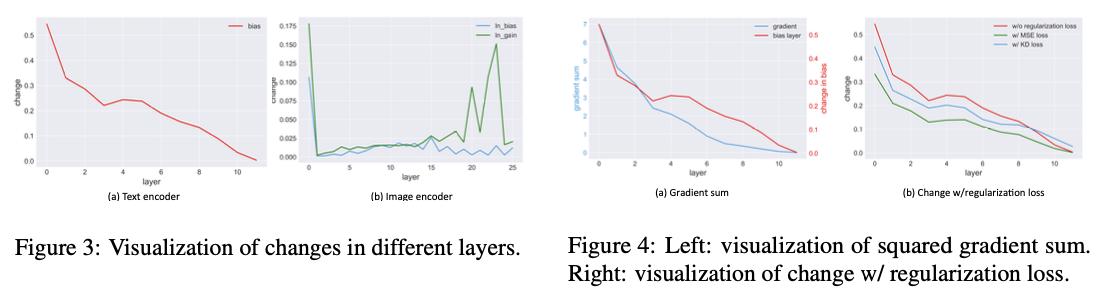
一、概述
上篇文章介绍了木舟通过HTTP网络组件接入设备,那么此篇文章将介绍如何利用Tcp或者UDP网络组件接入设备.
木舟 (Kayak) 是什么?
木舟(Kayak)是基于.NET6.0软件环境下的surging微服务引擎进行开发的, 平台包含了微服务和物联网平台。支持异步和响应式编程开发,功能包含了物模型,设备,产品,网络组件的统一管理和微服务平台下的注册中心,服务路由,模块,中间服务等管理。还有多协议适配(TCP,MQTT,UDP,CoAP,HTTP,Grpc,websocket,rtmp,httpflv,webservice,等),通过灵活多样的配置适配能够接入不同厂家不同协议等设备。并且通过设备告警,消息通知,数据可视化等功能。能够让你能快速建立起微服务物联网平台系统。
那么下面就为大家介绍如何从创建组件、协议、设备网关,设备到设备网关接入,再到设备数据上报,把整个流程通过此篇文章进行阐述。
二、网络组件
1.编辑创建Tcp协议的网络组件,可以选择共享配置和独立配置(独立配置是集群模式). 下图是解析方式选择了自定义脚本进行解码操作。

还可以选择其它解析方式:如下图

2. 编辑创建UDP协议的网络组件,可以选择共享配置和独立配置(独立配置是集群模式). 可以选择单播或组播。

三、自定义协议
如果是网络编程开发,必然会涉及到协议报文的编码解码处理,那么对于平台也是做到了灵活处理,首先是协议模块创建,通过以下代码看出协议模块可以添加协议说明md文档, 身份鉴权处理,消息编解码,元数据配置。下面一一介绍如何进行编写
public classDemo3ProtocolSupportProvider : ProtocolSupportProvider
{public override IObservable<ProtocolSupport>Create(ProtocolContext context)
{var support = newComplexProtocolSupport();
support.Id= "demo_3";
support.Name= "演示协议3";
support.Description= "演示协议3";
support.AddAuthenticator(MessageTransport.Tcp,newDemo5Authenticator());
support.AddDocument(MessageTransport.Tcp,"Document/document-tcp.md");
support.Script= "\r\nvar decode=function(buffer)\r\n{\r\n parser.Fixed(5).Handler(\r\n function(buffer){ \r\n var bytes = BytesUtils.GetBytes(buffer,1,4);\r\n var len = BytesUtils.LeStrToInt(bytes,1,4);//2. 获取消息长度.\r\n var buf = BytesUtils.Slice(buffer,0,5); \r\n parser.Fixed(len).Result(buf); \r\n }).Handler(function(buffer){ parser.Result(buffer).Complete(); \r\n }\r\n )\r\n}\r\nvar encode=function(buffer)\r\n{\r\n}";
support.AddMessageCodecSupport(MessageTransport.Tcp, ()=> Observable.Return(newScriptDeviceMessageCodec(support.Script)));
support.AddConfigMetadata(MessageTransport.Tcp, _tcpConfig);
support.AddAuthenticator(MessageTransport.Udp,newDemo5Authenticator());
support.Script= "\r\nvar decode=function(buffer)\r\n{\r\n parser.Fixed(5).Handler(\r\n function(buffer){ \r\n var bytes = BytesUtils.GetBytes(buffer,1,4);\r\n var len = BytesUtils.LeStrToInt(bytes,1,4);//2. 获取消息长度.\r\n var buf = BytesUtils.Slice(buffer,0,5); \r\n parser.Fixed(len).Result(buf); \r\n }).Handler(function(buffer){ parser.Result(buffer).Complete(); \r\n }\r\n )\r\n}\r\nvar encode=function(buffer)\r\n{\r\n}";
support.AddMessageCodecSupport(MessageTransport.Udp, ()=> Observable.Return(newScriptDeviceMessageCodec(support.Script)));
support.AddConfigMetadata(MessageTransport.Udp, _udpConfig);returnObservable.Return(support);
}
}
1. 添加协议说明文档如代码:
support.AddDocument(MessageTransport.Tcp,
"
Document/document-tcp.md
"
);,文档仅支持
markdown文件,如下所示
### 认证说明
CONNECT报文:
```text
clientId: 设备ID
password: md5(timestamp+"|"+secureKey)
```
2. 添加身份鉴权如代码:
support.AddAuthenticator(MessageTransport.Http, new Demo5Authenticator()) ,自定义身份鉴权
Demo5Authenticator 代码如下:
public classDemo5Authenticator : IAuthenticator
{public IObservable<AuthenticationResult>Authenticate(IAuthenticationRequest request, IDeviceOperator deviceOperator)
{var result = Observable.Return<AuthenticationResult>(default);if (request isDefaultAuthRequest)
{var authRequest = request asDefaultAuthRequest;
deviceOperator.GetConfig(authRequest.GetTransport()==MessageTransport.Http?"token": "key").Subscribe( config =>{var password = config.Convert<string>();if(authRequest.Password.Equals(password))
{
result=result.Publish(AuthenticationResult.Success(authRequest.DeviceId));
}else{
result= result.Publish(AuthenticationResult.Failure(StatusCode.CUSTOM_ERROR, "验证失败,密码错误"));
}
});
}elseresult= Observable.Return<AuthenticationResult>(AuthenticationResult.Failure(StatusCode.CUSTOM_ERROR, "不支持请求参数类型"));returnresult;
}public IObservable<AuthenticationResult>Authenticate(IAuthenticationRequest request, IDeviceRegistry registry)
{var result = Observable.Return<AuthenticationResult>(default);var authRequest = request asDefaultAuthRequest;
registry
.GetDevice(authRequest.DeviceId)
.Subscribe(async p =>{var config= await p.GetConfig(authRequest.GetTransport() == MessageTransport.Http ? "token" : "key");var password= config.Convert<string>();if(authRequest.Password.Equals(password))
{
result=result.Publish(AuthenticationResult.Success(authRequest.DeviceId));
}else{
result= result.Publish(AuthenticationResult.Failure(StatusCode.CUSTOM_ERROR, "验证失败,密码错误"));
}
});returnresult;
}
}
3.添加消息编解码代码
support.AddMessageCodecSupport(MessageTransport.Tcp, () => Observable.Return(new ScriptDeviceMessageCodec(support.Script)));, 可以自定义编解码,
ScriptDeviceMessageCodec
代码如下:
usingDotNetty.Buffers;usingJint;usingJint.Parser;usingMicrosoft.CodeAnalysis.Scripting;usingMicrosoft.Extensions.Logging;usingRulesEngine.Models;usingSurging.Core.CPlatform.Codecs.Core;usingSurging.Core.CPlatform.Utilities;usingSurging.Core.DeviceGateway.Runtime.Device.Message;usingSurging.Core.DeviceGateway.Runtime.Device.Message.Event;usingSurging.Core.DeviceGateway.Runtime.Device.Message.Property;usingSurging.Core.DeviceGateway.Runtime.Device.MessageCodec;usingSurging.Core.DeviceGateway.Runtime.RuleParser.Implementation;usingSurging.Core.DeviceGateway.Utilities;usingSystem;usingSystem.Collections.Generic;usingSystem.Linq;usingSystem.Reactive.Linq;usingSystem.Reactive.Subjects;usingSystem.Runtime;usingSystem.Text;usingSystem.Text.Json;usingSystem.Text.RegularExpressions;usingSystem.Threading.Tasks;namespaceSurging.Core.DeviceGateway.Runtime.Device.Implementation
{public classScriptDeviceMessageCodec : DeviceMessageCodec
{public string GlobalVariable { get; private set; }public string EncoderScript { get; private set; }public string DecoderScript { get; private set; }public IObservable<Task<RulePipePayloadParser>>_rulePipePayload;private readonly ILogger<ScriptDeviceMessageCodec>_logger;public ScriptDeviceMessageCodec(stringscript) {
_logger= ServiceLocator.GetService<ILogger<ScriptDeviceMessageCodec>>();
RegexOptions options= RegexOptions.Singleline |RegexOptions.IgnoreCase;string matchStr = Regex.Match(script, @"var\s*[\w$]*\s*\=.*function.*\(.*\)\s*\{[\s\S]*\}.*?v", options).Value;if (!string.IsNullOrEmpty(matchStr))
{
DecoderScript= matchStr.TrimEnd('v');
DecoderScript= Regex.Replace(DecoderScript, @"var\s*[\w$]*\s*\=[.\r|\n|\t|\s]*?(function)\s*\([\w$]*\s*\)\s*\{", "", RegexOptions.IgnoreCase);
DecoderScript= DecoderScript.Slice(0, DecoderScript.LastIndexOf('}'));
EncoderScript= script.Replace(DecoderScript, "");
}var matchStr1 = Regex.Matches(script, @"(?<=var).*?(?==)|(?=;)|(?=v)", options).FirstOrDefault(p=>!string.IsNullOrEmpty(p.Value))?.Value;if (!string.IsNullOrEmpty(matchStr1))
{
GlobalVariable= matchStr1.TrimEnd(';');
}var ruleWorkflow = newRuleWorkflow(DecoderScript);
_rulePipePayload=Observable.Return( GetParser( GetRuleEngine(ruleWorkflow), ruleWorkflow));
}public override IObservable<IDeviceMessage>Decode(MessageDecodeContext context)
{var result = Observable.Return<IDeviceMessage>(null);
_rulePipePayload.Subscribe(async p =>{var parser = awaitp;
parser.Build(context.GetMessage().Payload);
parser.HandlePayload().Subscribe(async p =>{try{var headerBuffer=parser.GetResult().FirstOrDefault();var buffer =parser.GetResult().LastOrDefault();var str =buffer.GetString(buffer.ReaderIndex, buffer.ReadableBytes, Encoding.UTF8);var session = awaitcontext.GetSession();if (session?.GetOperator() == null)
{var onlineMessage = JsonSerializer.Deserialize<DeviceOnlineMessage>(str);
result=result.Publish(onlineMessage);
}else{var messageType = headerBuffer.GetString(0, 1, Encoding.UTF8);if (Enum.Parse<MessageType>(messageType.ToString()) ==MessageType.READ_PROPERTY)
{var onlineMessage = JsonSerializer.Deserialize<ReadPropertyMessage>(str);
result=result.Publish(onlineMessage);
}else if (Enum.Parse<MessageType>(messageType.ToString()) ==MessageType.EVENT)
{var onlineMessage = JsonSerializer.Deserialize<EventMessage>(str);
result=result.Publish(onlineMessage);
}
}
}catch(Exception e)
{
}finally{
p.Release();
parser.Close();
}
});
});returnresult;
}public override IObservable<IEncodedMessage>Encode(MessageEncodeContext context)
{
context.Reply(((RespondDeviceMessage<IDeviceMessageReply>)context.Message).NewReply().Success(true));return Observable.Empty<IEncodedMessage>();
}privateRulesEngine.RulesEngine GetRuleEngine(RuleWorkflow ruleWorkflow)
{var reSettingsWithCustomTypes = new ReSettings { CustomTypes = new Type[] { typeof(RulePipePayloadParser) } };var result = new RulesEngine.RulesEngine(new Workflow[] { ruleWorkflow.GetWorkflow() }, null, reSettingsWithCustomTypes);returnresult;
}private async Task<RulePipePayloadParser>GetParser(RulesEngine.RulesEngine engine, RuleWorkflow ruleWorkflow)
{var payloadParser = newRulePipePayloadParser();var ruleResult = await engine.ExecuteActionWorkflowAsync(ruleWorkflow.WorkflowName, ruleWorkflow.RuleName, new RuleParameter[] { new RuleParameter("parser", payloadParser) });if (ruleResult.Exception != null &&_logger.IsEnabled(LogLevel.Error))
_logger.LogError(ruleResult.Exception, ruleResult.Exception.Message);returnpayloadParser;
}
}
}
4.添加元数据配置代码
support.AddConfigMetadata(MessageTransport.Tcp, _tcpConfig)
;
_tcpConfig
代码如下:
private readonly DefaultConfigMetadata _tcpConfig = newDefaultConfigMetadata("TCP认证配置","key为tcp认证密钥")
.Add("tcp_auth_key", "key", "TCP认证KEY", StringType.Instance);_udpConfig代码如下:
private readonly DefaultConfigMetadata _udpConfig = newDefaultConfigMetadata("udp认证配置","key为udp认证密钥")
.Add("udp_auth_key", "key", "TCP认证KEY", StringType.Instance);
- 如何加载协议模块,协议模块包含了协议模块支持自定义脚本、添加引用、上传热部署加载。
自定义脚本,选择了自定义脚本解析,如果本地有设置消息编解码,会进行覆盖

引用加载模块

上传热部署协议模块
首先利用以下命令发布模块:

然后打包上传协议模块

四、设备网关
创建TCP设备网关

创建UDP设备网关

五、产品管理
以下是添加产品。

设备接入

六、设备管理
添加设备

Tcp认证配置

添加告警阈值

事件定义

七、测试
利用测试工具进行Tcp测试,以调用
tcp://127.0.0.1:993
为例,
测试设备上线
字符串: 293\0\0{"MessageType":2,"Headers":{"token":"123456"},"DeviceId":"scro-34","Timestamp":1726540220311}
说明:第一个字符表示类型,第二个表示消息内容长度
16进制:32393300007b224d65737361676554797065223a322c2248656164657273223a7b22746f6b656e223a22313233343536227d2c224465766963654964223a227363726f2d3334222c2254696d657374616d70223a313732363534303232303331317d
结果如下:

测试上报属性
字符串:195\0\0{"MessageType":1,"Properties":{"temp":"38.24"},"DeviceId":"scro-34","Timestamp":1726560007339}
16进制:31393500007b224d65737361676554797065223a312c2250726f70657274696573223a7b2274656d70223a2233382e3234227d2c224465766963654964223a227363726f2d3334222c2254696d657374616d70223a313732363536303030373333397d
结果如下:

测试事件
字符串:8307\0{"MessageType":8,"Data":{"deviceId":"scro-34","level":"alarm","alarmTime":"2024-11-07 19:47:00","from":"device","alarmType":"设备告警","coordinate":"33.345,566.33","createTime":"2024-11-07 19:47:00","desc":"温度超过阈值"},"DeviceId":"scro-34","EventId":"alarm","Timestamp":1726540220311}
16进制:38333037007b224d65737361676554797065223a382c2244617461223a7b226465766963654964223a227363726f2d3334222c226c6576656c223a22616c61726d222c22616c61726d54696d65223a22323032342d31312d30372031393a34373a3030222c2266726f6d223a22646576696365222c22616c61726d54797065223a22e8aebee5a487e5918ae8ada6222c22636f6f7264696e617465223a2233332e3334352c3536362e3333222c2263726561746554696d65223a22323032342d31312d30372031393a34373a3030222c2264657363223a22e6b8a9e5baa6e8b685e8bf87e99888e580bc227d2c224465766963654964223a227363726f2d3334222c224576656e744964223a22616c61726d222c2254696d657374616d70223a313732363534303232303331317d
结果如下:

可以在平台界面看到上报的数据


利用测试工具进行Udp测试,以调用udp
://127.0.0.1:267为例,
测试设备上线
字符串:295\0\0{"MessageType":2,"Headers":{"token":"123456"},"DeviceId":"srco-2555","Timestamp":1726540220311}
说明:第一个字符表示类型,第二个表示消息内容长度
16进制:32393500007b224d65737361676554797065223a322c2248656164657273223a7b22746f6b656e223a22313233343536227d2c224465766963654964223a227372636f2d32353535222c2254696d657374616d70223a313732363534303232303331317d
结果如下:

测试上报属性
字符串:197\0\0{"MessageType":1,"Properties":{"temp":"38.24"},"DeviceId":"srco-2555","Timestamp":1726560007339}
说明:第一个字符表示类型,第二个表示消息内容长度
16进制:31393700007b224d65737361676554797065223a312c2250726f70657274696573223a7b2274656d70223a2233382e3234227d2c224465766963654964223a227372636f2d32353535222c2254696d657374616d70223a313732363536303030373333397d
结果如下:

测试事件
字符串:8301\0{"MessageType":8,"Data":{"deviceId":"srco-2555","level":"alarm","alarmTime":"2024-11-07 19:47:00","from":"device","alarmType":"设备告警","coordinate":"33.345,566.33","createTime":"2024-11-07 19:47:00","desc":"温度超过阈值"},"DeviceId":"srco-2555","EventId":"alarm","Timestamp":1726540220311}
说明:第一个字符表示类型,第二个表示消息内容长度
16进制:38333031007b224d65737361676554797065223a382c2244617461223a7b226465766963654964223a227372636f2d32353535222c226c6576656c223a22616c61726d222c22616c61726d54696d65223a22323032342d31312d30372031393a34373a3030222c2266726f6d223a22646576696365222c22616c61726d54797065223a22e8aebee5a487e5918ae8ada6222c22636f6f7264696e617465223a2233332e3334352c3536362e3333222c2263726561746554696d65223a22323032342d31312d30372031393a34373a3030222c2264657363223a22e6b8a9e5baa6e8b685e8bf87e99888e580bc227d2c224465766963654964223a227372636f2d32353535222c224576656e744964223a22616c61726d222c2254696d657374616d70223a313732363534303232303331317d
结果如下:

可以在平台界面看到上报的数据


七、总结
以上是基于Tcp和UDP网络组件设备接入,现有平台网络组件可以支持TCP,MQTT,UDP,CoAP,HTTP,Grpc,websocket,rtmp,httpflv,webservice,tcpclient, 而设备接入支持TCP,UDP,HTTP网络组件,年前尽量完成国标28181和MQTT,也会开始着手开始开发规则引擎, 然后定于11月20日发布1.0测试版平台。也请大家到时候关注捧场。