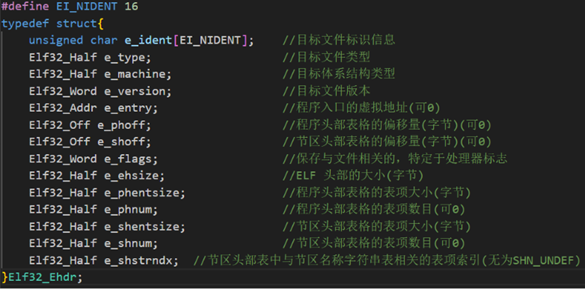
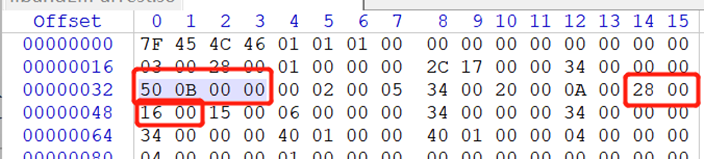
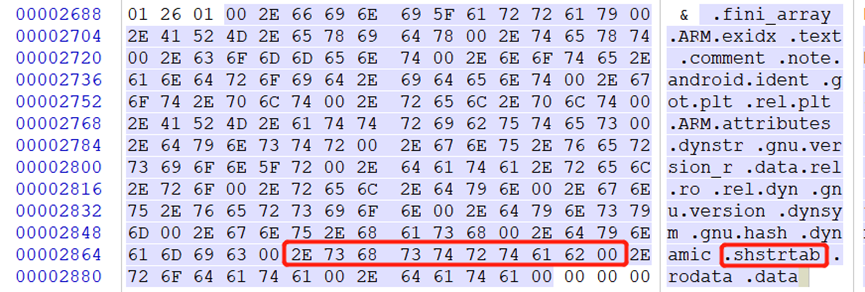
代码背后的智慧:20条编程感悟
大家好,我是木宛哥;在 10余年的工作经历让我深刻体会到软件开发不仅仅是写代码,更是一个系统化的交付过程。
为此我总结了20条编程感悟,涵盖了代码规范、设计原则、测试方法与交付流程等多个方面;通过遵循代码规范,让代码更加可读与可维护,同时合理的设计能够有效应对需求变化,模块化的单元测试又确保了产品的可靠性,顾全的交付流程最后提升了项目质量。
希望这些感悟更多程序员提供参考,帮助大家在编程的道路上不断进步。
1. 清晰的命名
● 原则:代码应该易于阅读和理解;例如:变量、函数和类的名称应能清楚表达其意图;
● 示例:
// 明确表示学生数量
int numberOfStudents = 30;
/**
* 计算圆面积
* @param radius 半径
* @return 面积
*/
public double calculateAreaOfCircle(double radius) {
return Math.PI * radius * radius;
}
2. 使用注释
● 原则:在复杂或重要的代码段添加注释,帮助他人理解;
● 示例:
/**
* 计算给定列表的平均值
*
* @param numbers 要计算的数字列表
* @return 返回数字的平均值,如果列表为空则返回0
*/
public static double calculateAverage(List<Double> numbers) {
if (numbers == null || numbers.isEmpty()) {
return 0;
}
double sum = 0.0; // 用于保存数字的总和
int count = 0; // 用于记录有效数字的数量
// 遍历列表中的每个数字并计算总和
//【注意】:检查列表中的每个元素是否为 null,需要过滤
for (Double num : numbers) {
if (num != null) {
sum += num;
count++;
}
}
if (count == 0) {
return 0;
}
double average = sum / count;
return average;
}
3. 一致的编码风格
● 原则:遵循团队的编码标准,保持代码风格一致;
● 示例:使用统一的缩进和大括号位置。例如 IDEA 等 IDE 中配置统一的 CodeStyle:Alibaba-CodeStyle 、Google-CodeStyle 等;
4. 代码模块化
● 原则:将功能分解成小模块,增加重用性;
● 示例:
public class Calculator {
/**
* 加
* @param a
* @param b
* @return
*/
public int add(int a, int b) {
return a + b;
}
/**
* 减
* @param a
* @param b
* @return
*/
public int subtract(int a, int b) {
return a - b;
}
}
5. 避免重复代码
● 原则:遵循DRY原则(Don’t Repeat Yourself);
● 示例:
//不好的实践:重复
public class Calculator {
public void addAndPrint(int a, int b) {
int result = a + b;
System.out.println("Result: " + result);
}
public void addAndPrintAnother(int x, int y) {
int result = x + y;
System.out.println("Result: " + result);
}
}
//好的实践:我们可以提取出一个公共方法来遵循DRY原则:
public class Calculator {
public void addAndPrint(int a, int b) {
printResult(add(a, b));
}
public int add(int a, int b) {
return a + b;
}
private void printResult(int result) {
System.out.println("Result: " + result);
}
}
6. 依赖接口而不是具体的实现
● 原则:依赖接口而不是具体的实现,增强灵活性;
● 示例:
public interface Shape {
double area();
}
public class Circle implements Shape {
private double radius;
public Circle(double radius) {
this.radius = radius;
}
@Override
public double area() {
return Math.PI * radius * radius;
}
}
public class Square implements Shape {
private double sideLength;
public Square(double sideLength) {
this.sideLength = sideLength;
}
@Override
public double area() {
return sideLength * sideLength;
}
}
//依赖接口而不是具体的实现
void printf(Shape shape);
7. 避免魔法数字
● 原则:使用常量代替魔法数字;
● 示例:
final double FIXED_RATE = 3
double area = FIXED_NO * radius
8. 简化条件语句
● 原则:避免复杂的条件逻辑。用快速 return 来减少 if 嵌套层次;
● 示例:
//不推荐:嵌套太深
public void checkUser(User user) {
if (user != null) {
if (user.getAge() > 18) {
if (user.isActive()) {
// 允许访问
System.out.println("Access granted");
} else {
System.out.println("User is not active");
}
} else {
System.out.println("User is underage");
}
} else {
System.out.println("User is null");
}
}
//推荐:快速失败返回
public void checkUser(User user) {
if (user == null) {
System.out.println("User is null");
return;
}
if (user.getAge() <= 18) {
System.out.println("User is underage");
return;
}
if (!user.isActive()) {
System.out.println("User is not active");
return;
}
// 允许访问
System.out.println("Access granted");
}
9. 异常处理
● 原则:通过适当的异常处理提高程序的健壮性;
● 示例:
//异常
try {
int result = 10 / 0;
} catch (ArithmeticException e) {
log.error("非法参数,不能被零除");
}
//熔断
try (Entry entry = SphU.entry("resourceName")) {
// 你的业务逻辑
} catch (BlockException ex) {
// 处理被阻止的请求
}
10. 标准化错误日志处理
● 原则:统一错误处理的方式和日志记录。方便日志采集和告警配置;
● 示例:
public void logError(String message) {
log.error("ERROR|Trace:{0}|Msg:{1} " Context.getTrace(), message);
}
11. 方法参数不宜过长
● 原则:方法参数应尽量少,避免混乱,超过3个推荐封装成模型;
● 示例:
//不推荐
void createUser(String name,int age,String email);
//推荐
public class UserService {
public void createUser(User user) {
}
}
class User {
private String name;
private int age;
private String email;
public User(String name, int age, String email) {
this.name = name;
this.age = age;
this.email = email;
}
// Getters and Setters
}
12. 使用现有工具类来简化操作
● 原则:优先使用现有工具类 如
apache.commons
来简化操作
● 示例:
StringUtils.isNotEmpty("");
CollectionUtils.isNotEmpty()
13. 尽量使用不变的变量
● 原则:使用
final
关键字声明不可变的变量,提高代码的可靠性;
● 示例:
final int MAX_VALUE = 100;
ImmutableList.of();
14. 测试驱动开发(TDD)
● 原则:先写测试,再写代码,确保代码的可测试性;
● 示例:
@Test
public void testAdd() {
Calculator calculator = new Calculator();
assertEquals(5, calculator.add(2, 3));
}
15. 避免过度优化
● 原则:优先考虑代码的可读性,优化通常是在识别出性能问题后进行的;
16. 使用版本控制
● 原则:使用版本控制工具(git)管理代码变化;
17. 重视系分文档
● 原则:
○ 开发前,考虑清楚为什么要做这个需求。从背景及现状分析->为什么要做(why)->要做什么(what)->如何去做(how) 体系化思考;
○ 再从业务用例分析->系统依赖分析->领域模型分析->架构设计分析->时序图分析等落地最终的系分;
18. 重视代码评审
● 原则:定期进行代码评审,提高代码质量,提高团队研发意识;
19. 重视每一次交付
● 原则:
○ 事前锁定资源,上下游达成一致,明确里程碑计划;
○ 事中按需推进,每周项目进度同步,及时通晒风险;
○ 事后组织复盘以及关注业务数据(关注价值)
20.重视交付质量
● 原则:新功能需多考虑灰度验证
○ 后端服务:可按分组进行灰度验证(gray 分组->default 分组)
○ 客户端:小范围升级验证无问题后,逐步放量升级;
写在最后
欢迎关注我的公众号:编程启示录,第一时间获取最新消息;
| 微信 | 公众号 |
|---|---|
 |
 |