开源的 API 学习平台「GitHub 热点速览」

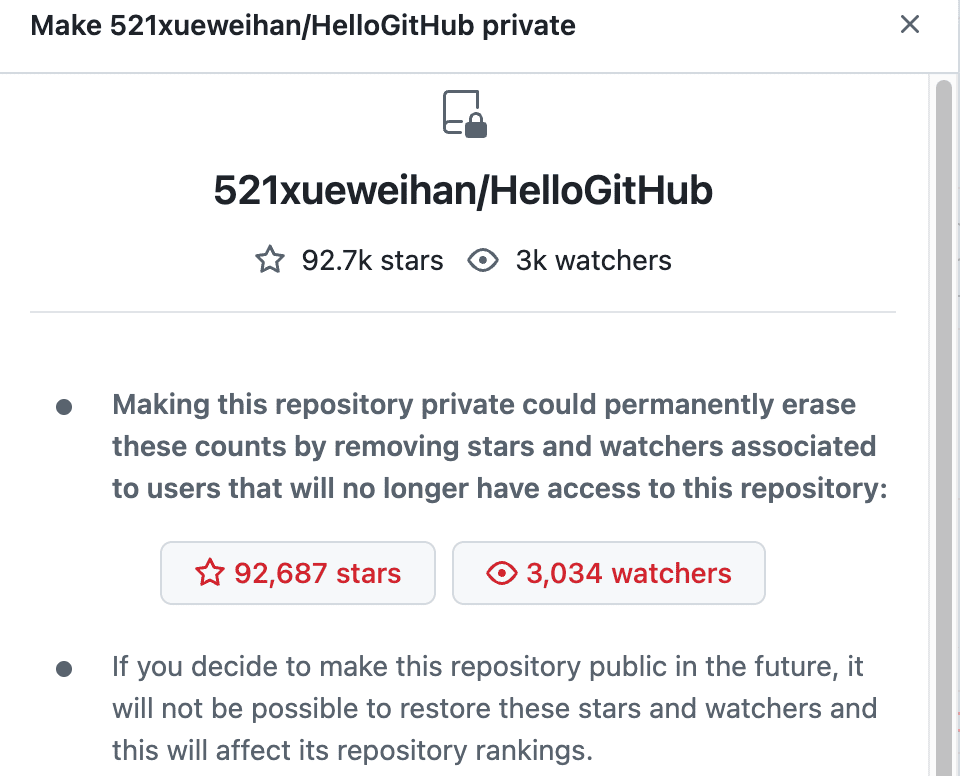
前有 5 万颗星标的开源项目 HTTPie 因误操作导致 Star 清零(2022 年),上周知名开源项目 Elasticsearch 也经历了 Star 一夜清零的事件。这些事故的原因均是管理员误将开源项目
从公开状态转为私有状态
所导致。为避免类似事件再次发生,GitHub 已在转为私有的功能处增加了两次确认步骤,并提醒用户星标清零后无法恢复。
希望大家引以为鉴,在做同样操作时一定要小心,并仔细阅读提醒。
说回本期的热门开源项目,都是一些能帮助你减轻工作和学习重担的利器。比如这款免费的 API 学习平台 APIHub,可以为初学者提供在线学习 API 开发的支持,并附有多种编程语言的示例。ChartDB 是一键生成数据库图表的工具,使用时无需输入数据库用户名和密码。Ophiuchi-desktop 让你在 5 秒内启动本地 HTTPS 代理,便于在本机上进行开发和测试。开源的 Android 虚拟定位应用 GoGoGo,一款帮你实现按时打卡的神器。有 AI 加持的浏览器自动化工具 Skyvern,无需写代码、且在网页结构变动时更具适应性,不易导致自动脚本失效。

最后,萌萌哒的网站计数器 Moe-Counter,内置了多款可爱的主题风格,我觉得都挺好看的。
- 本文目录
- 1. 热门开源项目
- 1.1 免费的 API 学习平台:apihub
- 1.2 多功能的自托管仪表盘:Dashy
- 1.3 一键生成数据库图表的工具:ChartDB
- 1.4 轻松启动本地 HTTPS 代理的工具:ophiuchi-desktop
- 1.5 AI 自动化浏览器工作流的工具:Skyvern
- 2. HelloGitHub 热评
- 2.1 可爱的网站计数器:Moe-Counter
- 2.2 开源的 Android 虚拟定位应用:GoGoGo
- 3. 结尾
- 1. 热门开源项目
1. 热门开源项目
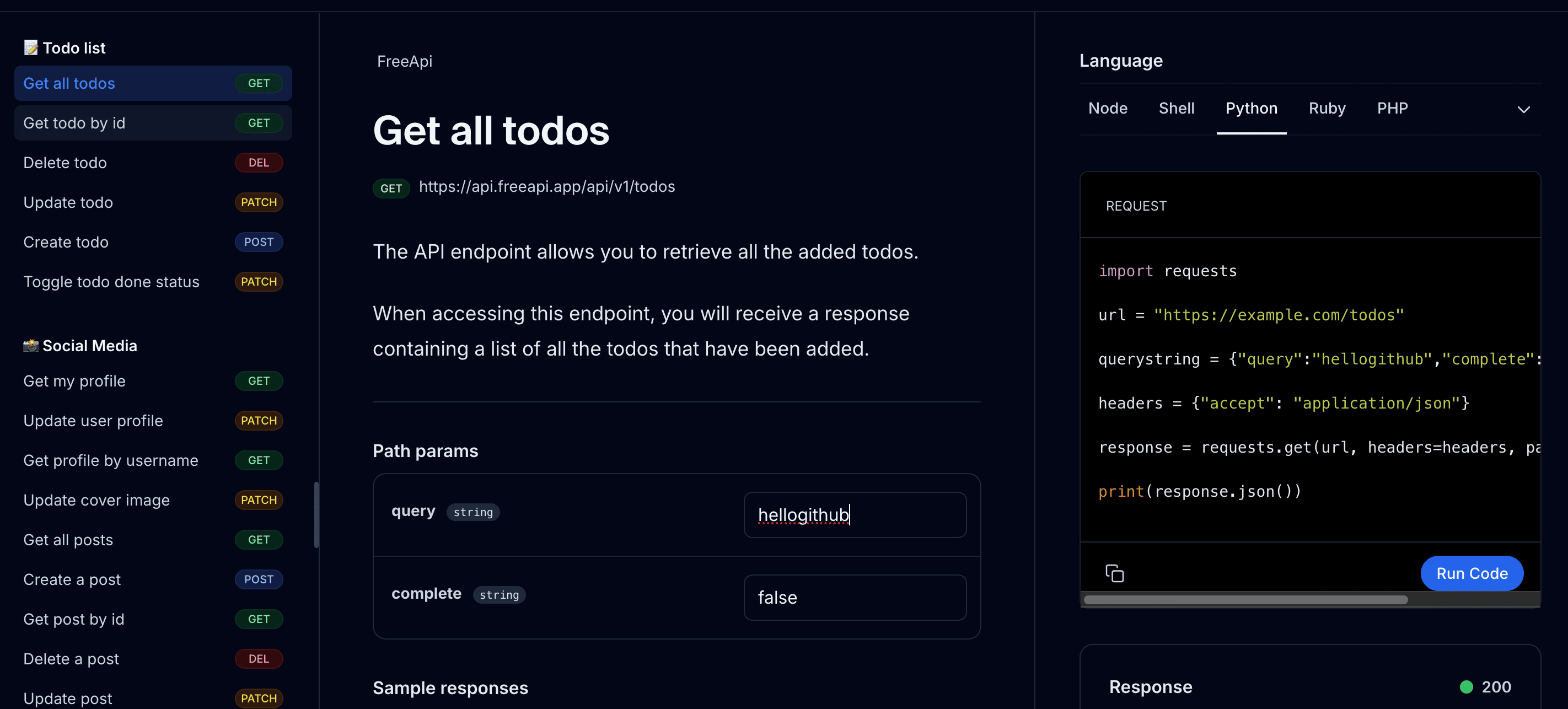
1.1 免费的 API 学习平台:apihub
主语言:JavaScript
,
Star:6.4k
,
周增长:1k
这是一个功能齐全的 API 学习平台,支持多种编程语言(Node.js、Python、Go 等)的 API 开发和学习。它免费提供丰富的 API 集合,涉及社交媒体集成、支付网关、物联网设备连接和机器学习等领域。你可以在该平台获取 API 开发的各类资源,包括详细教程、接口文档、代码示例和在线尝试。除了使用在线服务外,强烈推荐用户选择本地部署,以避免官网服务每两小时重置数据的限制。
GitHub 地址→
github.com/hiteshchoudhary/apihub
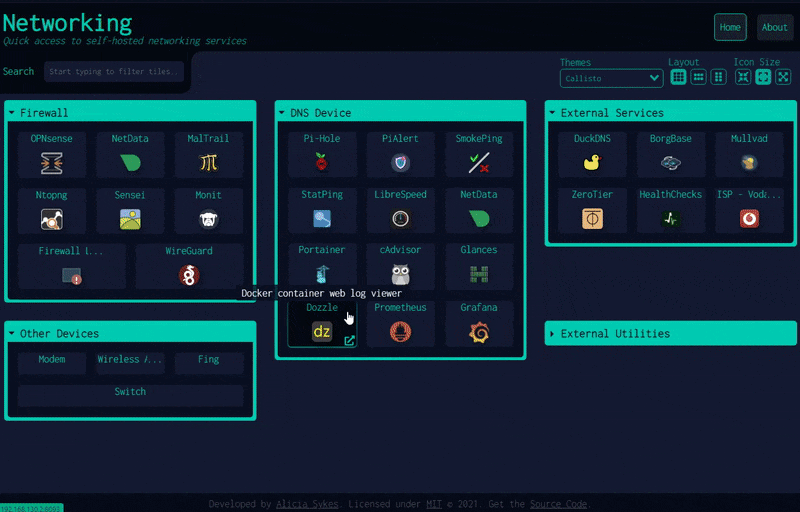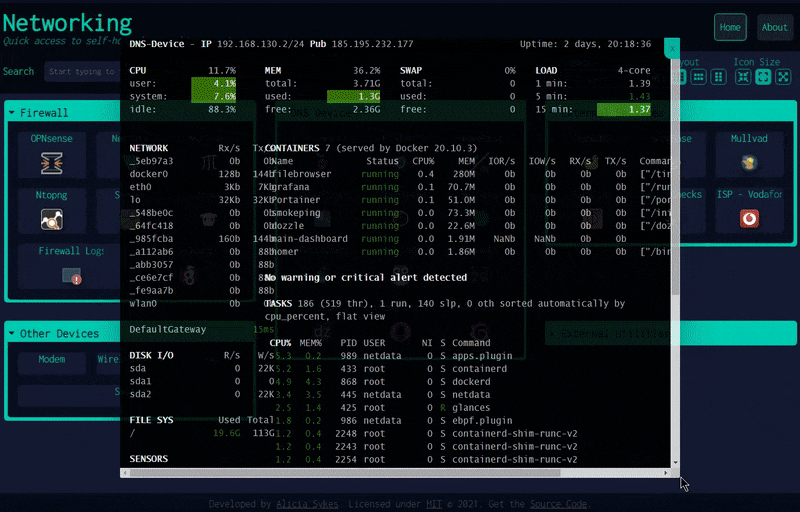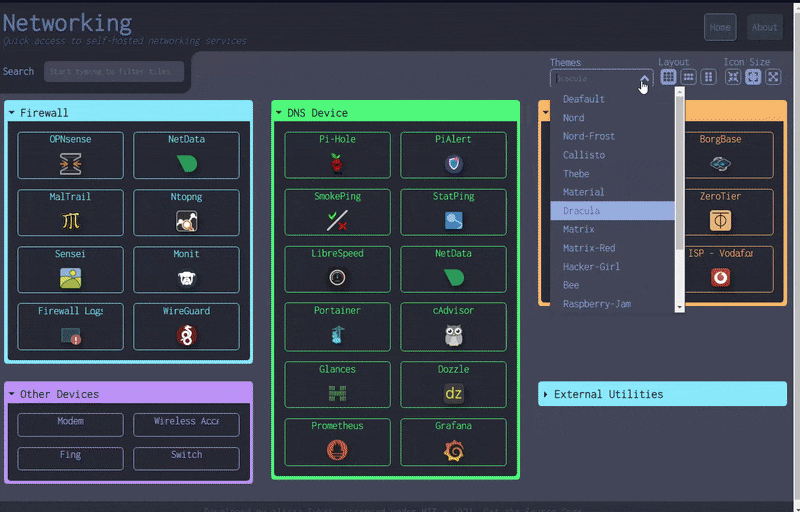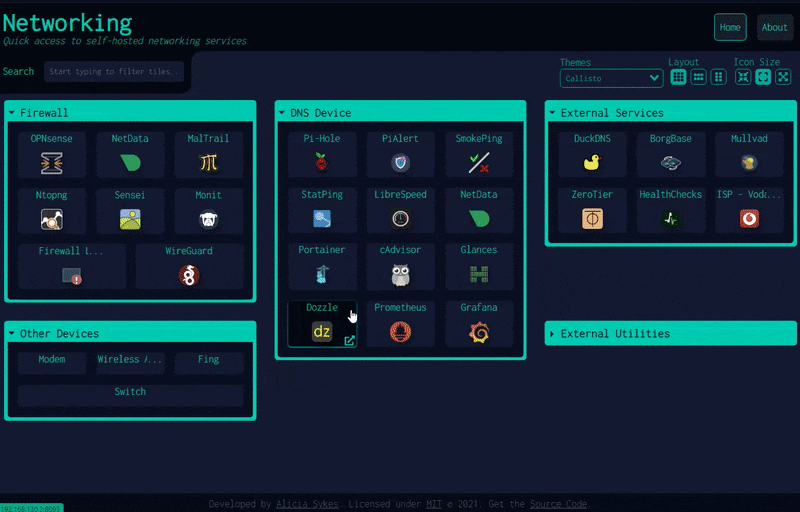
1.2 多功能的自托管仪表盘:Dashy
主语言:Vue
,
Star:17k
,
周增长:200
该项目是基于 Vue.js 开发的个人仪表盘(dashboard),旨在帮助用户通过一个 Web 界面管理和访问个人的自托管服务。它开箱即用、配置简单,内置多种颜色和图标,以便用户自定义界面,支持状态监控、多页面、多语言、小部件、自定义快捷键和搜索等功能。
GitHub 地址→
github.com/lissy93/dashy
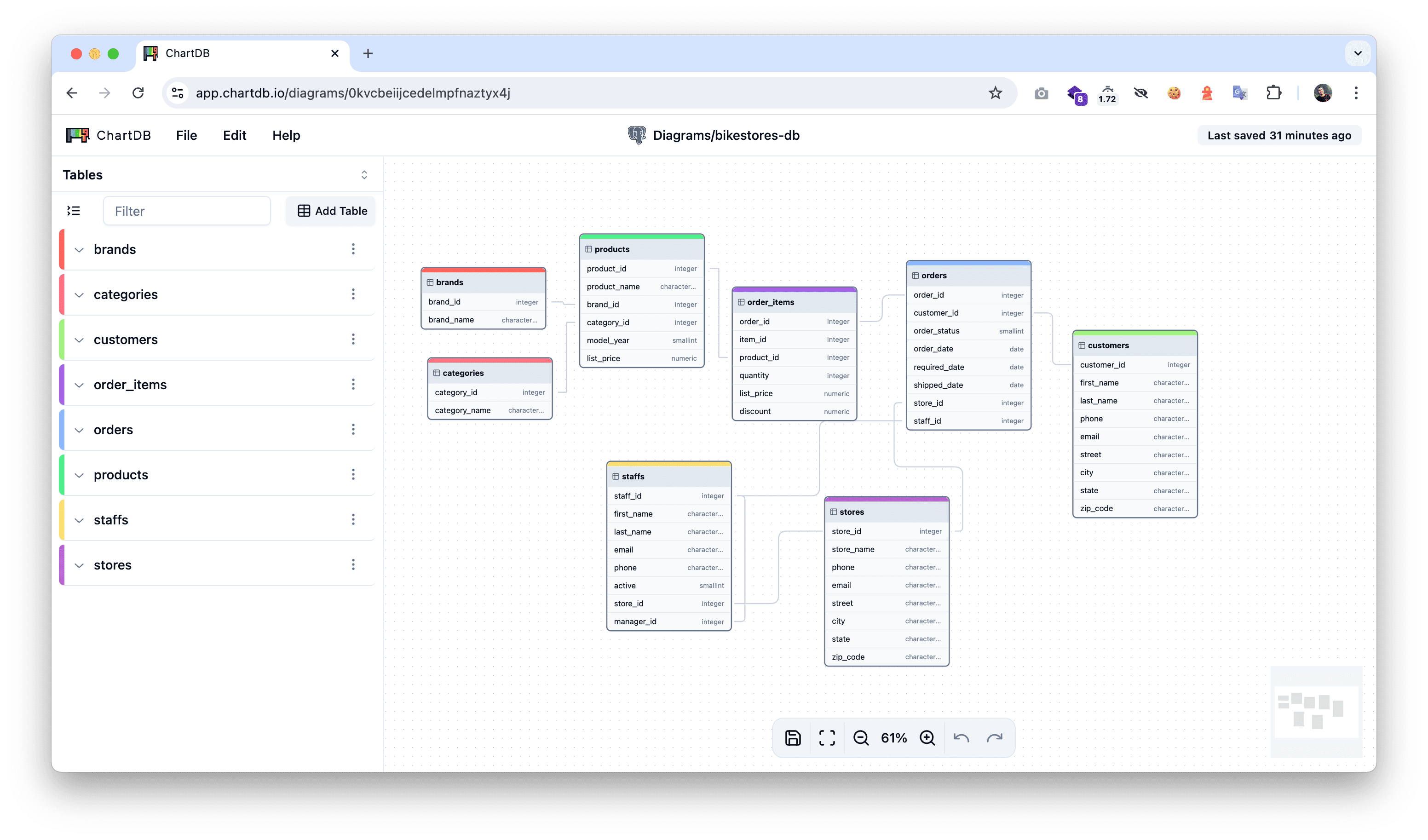
1.3 一键生成数据库图表的工具:ChartDB
主语言:TypeScript
,
Star:4.9k
,
周增长:1.1k
这是一款基于 Web 的数据库表编辑器,无需数据库密码,仅需提供一条 SQL 查询结果即可导入数据库表和结构。用户可以通过直观、交互式的界面编辑和导出建表 SQL。它支持 PostgreSQL、MySQL、SQL Server、SQLite、ClickHouse、MariaDB 数据库,适用于数据库迁移和优化过程中,快速生成和调整 DDL 脚本等场景。
GitHub 地址→
github.com/chartdb/chartdb
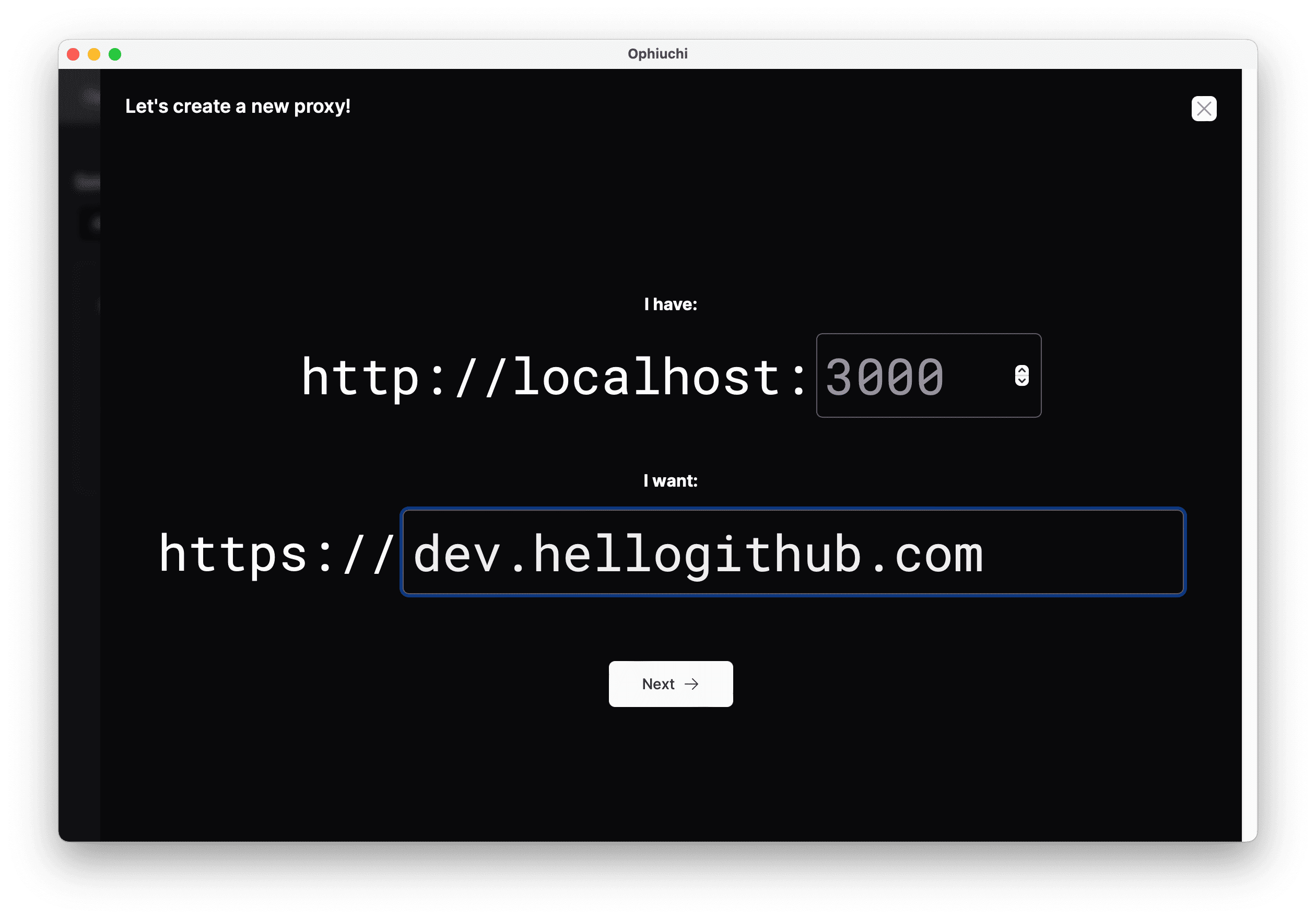
1.4 轻松启动本地 HTTPS 代理的工具:ophiuchi-desktop
主语言:TypeScript
,
Star:928
这是一个本地 HTTPS 代理服务器管理工具,无需复杂配置即可轻松设置本地 HTTPS 代理。它使用 Docker 作为后端,并采用 Tauri 编写 GUI 界面,极大地简化了本地 HTTPS 代理的配置流程。不过,使用前需确保本机已安装 Docker。
GitHub 地址→
github.com/apilylabs/ophiuchi-desktop
1.5 AI 自动化浏览器工作流的工具:Skyvern
主语言:Python
,
Star:9.8k
,
周增长:3k
该项目是基于大型语言模型(LLMs)和计算机视觉的浏览器自动化工具。与传统的代码依赖型浏览器自动化流程相比,它无需编写代码,并且在应对网站布局变动时,具备更高的适应能力。
GitHub 地址→
github.com/Skyvern-AI/skyvern
2. HelloGitHub 热评
在此章节中,我们将为大家介绍本周 HelloGitHub 网站上的热门开源项目,我们不仅希望您能从中收获灵感和知识,更渴望“听”到您的声音。希望您与我们分享
使用这些开源项目的亲身体验和评价
,用最真实反馈为开源项目的作者注入动力。
此外,HelloGitHub 网站的「用户贡献排行榜」功能已正式上线!
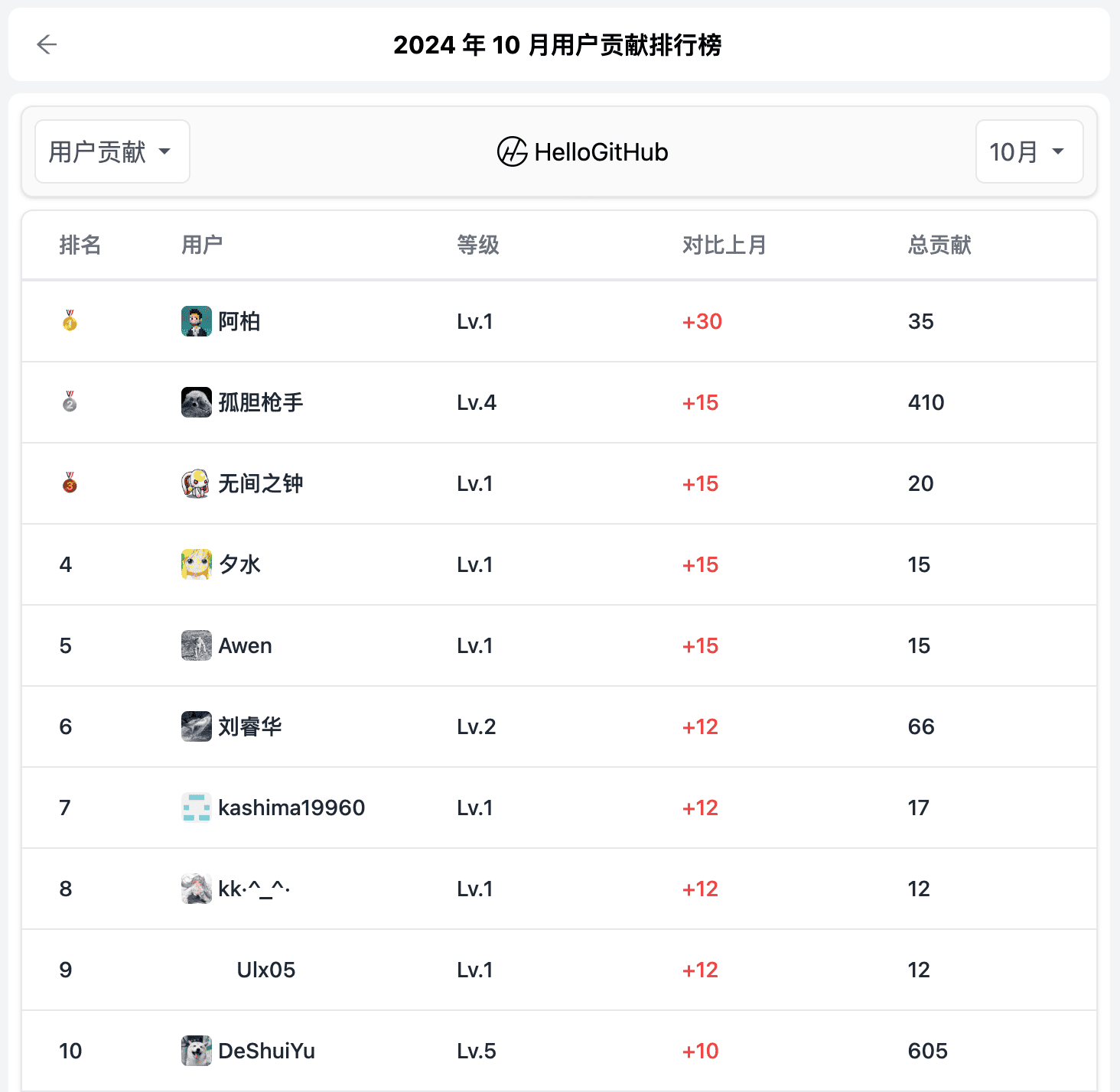
您的每一次分享和评论都将转化为
贡献值
,并在排行榜上展示您对开源的热情与贡献。您可能认为此举微不足道,但对于开源项目的作者来说,这是莫大的支持和鼓励。
勿以恶小而为之,勿以善小而不为。
2.1 可爱的网站计数器:Moe-Counter

主语言:JavaScript
该项目是一个用于统计页面访问人数的计数器。它不仅简单易用,还提供多种可爱风格的主题,用户可根据个人喜好进行选择。
项目详情→
hellogithub.com/repository/ed741b376efe46789ce9bb140ac19a52
2.2 开源的 Android 虚拟定位应用:GoGoGo
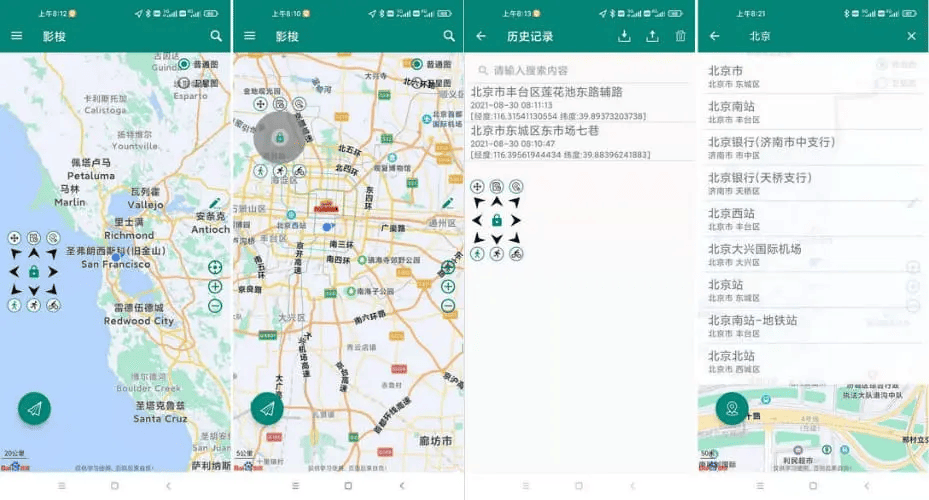
主语言:Java
该项目是一个基于 Android 调试 API 和百度地图实现的虚拟定位工具,无需 ROOT 权限即可修改地理位置。它支持位置搜索和手动输入坐标,并提供了一个可自由移动的摇杆来模拟位移。
项目详情→
hellogithub.com/repository/7cf3e8a7307b4767abd6ca2c98ae438f
3. 结尾
以上就是本期「GitHub 热点速览」的全部内容,希望你能够在这里找到自己感兴趣的开源项目,如果你有其他好玩、有趣的 GitHub 开源项目想要分享,欢迎来
HelloGitHub
与我们交流和讨论。
往期回顾