基于.NET8.0实现RabbitMQ的Publish/Subscribe发布订阅以及死信队列
本文github源码附上:
https://github.com/yangshuqi1201/RabbitMQ.Core
【前言】
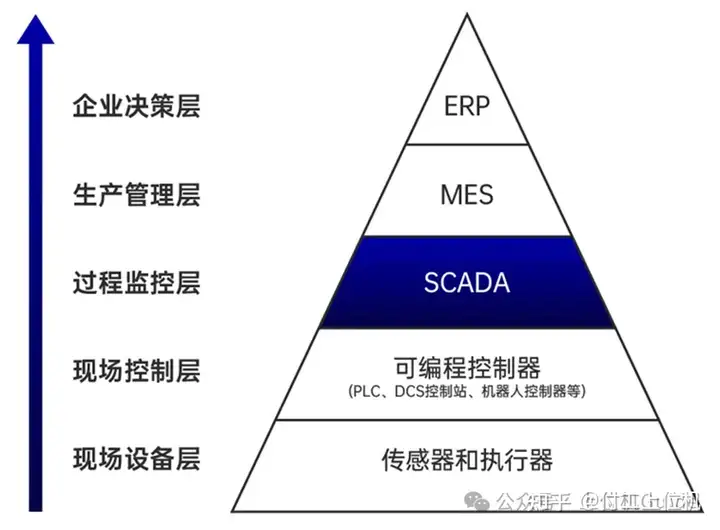
RabbitMQ提供了五种消息模型,分别是简单模型、工作队列模型、发布/订阅模型、路由模型和主题模型。
简单模型
(Simple)
:在这种模式下,一个生产者将消息发送到一个队列,只有一个消费者监听并处理该队列中的消息。这种模型适用于简单的场景,但存在消息可能未被正确处理就被删除的风险。工作队列模型
(Work Queue)
:此模型允许多个消费者共同处理队列中的任务,实现负载均衡。生产者将消息发送到队列,多个消费者竞争获取并处理这些消息。这种模型适用于需要高效处理大量任务的场景。发布/订阅模型
(Publish/Subscribe)
:在这种模式下,生产者将消息发送到一个交换机,交换机以广播
(Fanout)
的形式将消息发送给所有订阅了相应队列的消费者。这种模型适用于需要广播消息给所有感兴趣消费者的场景。路由模型
(Routing)
:使用direct交换机,生产者发送消息时需要指定路由键,交换机根据路由键将消息路由到相应的队列。这种模型适用于需要对消息进行精确控制的场景。主题模型
(Topics)
:使用topic交换机,支持使用通配符进行模式匹配,生产者发送的消息可以通过特定的路由键匹配到多个队列。这种模型适用于需要灵活匹配消息的场景。这些模型在应用场景、消息传递方式和交换机使用上有所不同,用户可以根据具体需求选择合适的模型来优化系统的性能和可靠性。
在之前我使用RabbitMQ实现了Direct类型的交换机实现了基础的生产消费。
RabbitMQ的部署请见:
https://www.cnblogs.com/sq1201/p/18635209
这篇文章我将基于.NET8.0来实现RabbitMQ的广播模式,以及死信队列的基础用法。
【一】首先创建项目,安装RabbitMQ的包(此处我没有选择最新版,因为最新版全面使用异步,关于IModel也改为了IChannel,最新版的语法有待研究),我的项目结构如下:
在这里延伸一下Asp.netcore的小知识点,以实现灵活而强大的配置管理系统。
1. Microsoft.Extensions.Configuration.Abstractions
功能:
提供配置的基础接口和抽象,定义了与应用程序配置相关的核心机制。
是依赖注入(DI)配置的一部分,为应用程序提供了对配置源的抽象访问。
包含的核心功能和接口:IConfiguration: 表示应用程序的配置,支持按层级结构访问配置值。
var value = configuration["MySetting"];IConfigurationSection: 表示配置中的一个具体部分,用于访问嵌套的层级配置。
var section = configuration.GetSection("MySection");var subValue = section["SubSetting"];IConfigurationProvider: 表示一个提供配置值的源(如文件、环境变量等)。
IConfigurationRoot: 是配置的根对象,支持动态监控配置变更。
适用场景:
- 基础配置系统的搭建。
- 当你需要自定义自己的配置提供程序时(例如:将数据库或远程 API 作为配置源)。
示例:
using Microsoft.Extensions.Configuration;
var builder = new ConfigurationBuilder()
.AddJsonFile("appsettings.json")
.AddEnvironmentVariables();
var configuration = builder.Build();
Console.WriteLine(configuration["MySetting"]);
2. Microsoft.Extensions.Configuration.Binder
功能:
- 提供了扩展方法,用于 将配置绑定到强类型对象。
- 在读取配置时,通常需要将配置值转换为 C# 对象(例如类或结构),而这个包提供了关键的绑定功能。
包含的核心功能:
- Bind 方法
: 将配置值绑定到自定义类型。
var myOptions = new MyOptions();
configuration.Bind("MySection", myOptions);
- Get 方法:
从配置中直接返回类型化对象。
var myOptions = configuration.Get<MyOptions>("MySection");
- GetValue 方法:
直接从配置中获取某个特定的值,并将其转换为指定的类型。
int timeout = configuration.GetValue<int>("Timeout");
适用场景:
- 强类型配置的支持:
当需要将配置文件内容(如 JSON、环境变量)与代码中的类型对应时。 - 简化复杂配置读取逻辑。
示例:
using Microsoft.Extensions.Configuration;
public class MyOptions
{
public string Setting1 { get; set; }
public int Setting2 { get; set; }
}
// 读取配置
var builder = new ConfigurationBuilder()
.AddJsonFile("appsettings.json");
var configuration = builder.Build();
// 将配置绑定到强类型对象
var options = new MyOptions();
configuration.Bind("MySection", options);
Console.WriteLine(options.Setting1);
Console.WriteLine(options.Setting2);
// 或者直接获取类型化对象
var options2 = configuration.Get<MyOptions>("MySection");
【二】编写appsettings.json文件
【三】定义有关于配置文件信息的DTO

【四】编写RabbitMQ生产消费通用类,RabbitMQManager类。
点击查看代码
using RabbitMQ.Client.Events;
using RabbitMQ.Client;
using RabbitMQ.Model;
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using Microsoft.Extensions.Configuration;
namespace RabbitMQ.Service
{
public class RabbitMQManager
{
//使用数组的部分,是给消费端用的,目前生产者只设置了一个,消费者可能存在多个。
/// <summary>
/// RabbitMQ工厂发送端
/// </summary>
private IConnectionFactory _connectionSendFactory;
/// <summary>
/// RabbitMQ工厂接收端
/// </summary>
private IConnectionFactory _connectionReceiveFactory;
/// <summary>
/// 连接 发送端
/// </summary>
private IConnection _connectionSend;
/// <summary>
/// 连接 消费端
/// </summary>
private IConnection[] _connectionReceive;
/// <summary>
/// MQ配置信息
/// </summary>
public MqConfigInfo _mqConfigs;
/// <summary>
/// 通道 发送端
/// </summary>
private IModel _modelSend;
/// <summary>
/// 通道 消费端
/// </summary>
private IModel[] _modelReceive;
/// <summary>
/// 事件
/// </summary>
private EventingBasicConsumer[] _basicConsumer;
/// <summary>
/// 消费者个数
/// </summary>
public int _costomerCount;
public RabbitMQManager(IConfiguration configuration)
{
_mqConfigs = new MqConfigInfo
{
Host = configuration["MQ:Host"],
Port = Convert.ToInt32(configuration["MQ:Port"]),
User = configuration["MQ:User"],
Password = configuration["MQ:Password"],
ExchangeName = configuration["MQ:ExchangeName"],
DeadLetterExchangeName = configuration["MQ:DeadLetterExchangeName"],
DeadLetterQueueName = configuration["MQ:Queues:2:QueueName"]
};
}
/// <summary>
/// 初始化生产者连接
/// </summary>
public void InitProducerConnection()
{
Console.WriteLine("【开始】>>>>>>>>>>>>>>>生产者连接");
_connectionSendFactory = new ConnectionFactory
{
HostName = _mqConfigs.Host,
Port = _mqConfigs.Port,
UserName = _mqConfigs.User,
Password = _mqConfigs.Password
};
if (_connectionSend != null && _connectionSend.IsOpen)
{
return; //已有连接
}
_connectionSend = _connectionSendFactory.CreateConnection(); //创建生产者连接
if (_modelSend != null && _modelSend.IsOpen)
{
return; //已有通道
}
_modelSend = _connectionSend.CreateModel(); //创建生产者通道
// 声明主交换机 为 Fanout 类型,持久化
_modelSend.ExchangeDeclare(
exchange: _mqConfigs.ExchangeName,
type: ExchangeType.Fanout,
durable: true, // 明确设置为持久化
autoDelete: false,
arguments: null
);
// 声明死信交换机 为Fanout类型,持久化
_modelSend.ExchangeDeclare(
exchange: _mqConfigs.DeadLetterExchangeName,
type: ExchangeType.Fanout,
durable: true, // 明确设置为持久化
autoDelete: false,
arguments: null
);
// 声明死信队列
_modelSend.QueueDeclare(
queue: _mqConfigs.DeadLetterQueueName,
durable: true,
exclusive: false,
autoDelete: false,
arguments: null
);
// 绑定死信队列到死信交换机
_modelSend.QueueBind(_mqConfigs.DeadLetterQueueName, _mqConfigs.DeadLetterExchangeName, routingKey: "");
Console.WriteLine("【结束】>>>>>>>>>>>>>>>生产者连接");
}
/// <summary>
/// 消息发布到交换机(Fanout模式)
/// </summary>
/// <param name="message">消息内容</param>
/// <param name="exchangeName">交换机名称</param>
/// <returns>发布结果</returns>
public async Task<(bool Success, string ErrorMessage)> PublishAsync(string message, string exchangeName)
{
try
{
byte[] body = Encoding.UTF8.GetBytes(message);
await Task.Run(() =>
{
_modelSend.BasicPublish(
exchange: exchangeName,
routingKey: string.Empty, // Fanout 模式无需 RoutingKey
basicProperties: null,
body: body
);
});
return (true, string.Empty);
}
catch (Exception ex)
{
return (false, $"发布消息时发生错误: {ex.Message}");
}
}
/// <summary>
/// 消费者初始化连接配置
/// </summary>
public void InitConsumerConnections(List<QueueConfigInfo> queueConfigs)
{
Console.WriteLine("【开始】>>>>>>>>>>>>>>>消费者连接");
//创建单个连接工厂
_connectionReceiveFactory = new ConnectionFactory
{
HostName = _mqConfigs.Host,
Port = _mqConfigs.Port,
UserName = _mqConfigs.User,
Password = _mqConfigs.Password
};
_costomerCount = queueConfigs.Sum(q => q.ConsumerCount); // 获取所有队列的消费者总数
// 初始化数组
_connectionReceive = new IConnection[_costomerCount];
_modelReceive = new IModel[_costomerCount];
_basicConsumer = new EventingBasicConsumer[_costomerCount];
int consumerIndex = 0; // 用于跟踪当前消费者索引
foreach (var queueConfig in queueConfigs)
{
for (int i = 0; i < queueConfig.ConsumerCount; i++)
{
string queueName = queueConfig.QueueName;
// 创建连接
_connectionReceive[consumerIndex] = _connectionReceiveFactory.CreateConnection();
_modelReceive[consumerIndex] = _connectionReceive[consumerIndex].CreateModel();
_basicConsumer[consumerIndex] = new EventingBasicConsumer(_modelReceive[consumerIndex]);
// 声明主交换机(确保交换机存在)
_modelReceive[consumerIndex].ExchangeDeclare(_mqConfigs.ExchangeName, ExchangeType.Fanout, durable: true, autoDelete: false, arguments: null);
// 声明死信交换机为 Fanout 类型
_modelReceive[consumerIndex].ExchangeDeclare(_mqConfigs.DeadLetterExchangeName, ExchangeType.Fanout, durable: true, autoDelete: false, arguments: null);
if (queueName == _mqConfigs.DeadLetterQueueName)
{
// 死信队列的声明和绑定
_modelReceive[consumerIndex].QueueDeclare(
queue: queueName,
durable: true,
exclusive: false,
autoDelete: false,
arguments: null
);
// 只将死信队列绑定到死信交换机
_modelReceive[consumerIndex].QueueBind(queueName, _mqConfigs.DeadLetterExchangeName, routingKey: "");
}
else
{
// 业务队列的声明和绑定
_modelReceive[consumerIndex].QueueDeclare(
queue: queueName,
durable: true,
exclusive: false,
autoDelete: false,
arguments: new Dictionary<string, object>
{
{ "x-dead-letter-exchange", _mqConfigs.DeadLetterExchangeName },
{ "x-dead-letter-routing-key", "" }
}
);
// 只将业务队列绑定到主交换机
_modelReceive[consumerIndex].QueueBind(queueName, _mqConfigs.ExchangeName, routingKey: "");
}
// 设置QoS,确保每次只处理一个消息
_modelReceive[consumerIndex].BasicQos(prefetchSize: 0, prefetchCount: 1, global: false);
consumerIndex++;
}
}
Console.WriteLine("【结束】>>>>>>>>>>>>>>>消费者连接初始化完成");
}
/// <summary>
/// 消费者连接
/// </summary>
public async Task ConncetionReceive(int consumeIndex, string exchangeName, string queueName, Func<string, Task> action)
{
await StartListenerAsync(async (model, ea) =>
{
try
{
byte[] message = ea.Body.ToArray();
string msg = Encoding.UTF8.GetString(message);
Console.WriteLine($"队列 {queueName},消费者索引 {consumeIndex} 接收到消息:{msg}");
await action(msg);
_modelReceive[consumeIndex].BasicAck(ea.DeliveryTag, true);//确认消息
}
catch (Exception ex)
{
Console.WriteLine($"处理消息时发生错误: {ex.Message}");
// 拒绝消息且不重新入队,触发死信机制
_modelReceive[consumeIndex].BasicNack(ea.DeliveryTag, false, false);
}
}, queueName, consumeIndex);
}
/// <summary>
/// 手动确认消费机制
/// </summary>
/// <param name="handler"></param>
/// <param name="queueName"></param>
/// <param name="consumeIndex"></param>
/// <returns></returns>
private async Task StartListenerAsync(AsyncEventHandler<BasicDeliverEventArgs> handler, string queueName, int consumeIndex)
{
_basicConsumer[consumeIndex].Received += async (sender, ea) => await handler(sender, ea);
_modelReceive[consumeIndex].BasicConsume(
queue: queueName,
autoAck: false,
consumer: _basicConsumer[consumeIndex]
);
Console.WriteLine($"队列 {queueName} 的消费者 {consumeIndex} 已启动监听");
}
}
}
【五】编写 RabbitMQService服务类,负责初始化 RabbitMQManager,并调用其方法完成 RabbitMQ 的连接和配置。
using Microsoft.Extensions.Configuration;
using RabbitMQ.Model;
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace RabbitMQ.Service
{
public class RabbitMQService
{
private readonly RabbitMQManager _rabbitmqManager;
public RabbitMQService(IConfiguration configuration)
{
_rabbitmqManager = new RabbitMQManager(configuration);
//初始化生产者连接
_rabbitmqManager.InitProducerConnection();
var queueConfigs = configuration.GetSection("MQ:Queues").Get<List<QueueConfigInfo>>();
//初始化消费者连接
_rabbitmqManager.InitConsumerConnections(queueConfigs);
}
public RabbitMQManager Instance => _rabbitmqManager;
}
}
【六】编写ActionService服务类,来实现模拟的消费者调用方法以及死信队列处理死信消息的逻辑
点击查看代码
namespace RabbitMQ.Service
{
public class ActionService
{
/// <summary>
/// 付款
/// </summary>
public async Task ExActionOne(string msg)
{
Console.WriteLine($"消费成功了【{msg}】消息以后正在执行付款操作");
// 模拟失败条件
if (msg.Contains("fail"))
{
throw new Exception("Simulated processing failure in ExActionOne");
}
await Task.Delay(1000); // 替换 Thread.Sleep
}
/// <summary>
/// 库存扣减
/// </summary>
public async Task ExActionTwo(string msg)
{
Console.WriteLine($"消费成功了【{msg}】消息以后正在执行库存扣减操作");
// 模拟失败条件
if (msg.Contains("fail"))
{
throw new Exception("Simulated processing failure in ExActionTwo");
}
await Task.Delay(1000); // 替换 Thread.Sleep
}
/// <summary>
/// 处理死信队列的消息
/// </summary>
public async Task ExActionDeadLetter(string message)
{
Console.WriteLine($"处理死信消息: {message}");
// 在这里可以记录日志、发送通知等
await Task.Delay(1000);
}
}
}
【七】在启动项Program文件中注入我们的服务注册为单例模式
【八】在Webapi控制器中编写测试方法,模拟实现给主交换机发送消息,当消费失败的时候,消息被发送到死信队列由死信队列消费进行后续操作
namespace RabbitMQ.Core.Controllers
{
[Route("api/[controller]/[action]")]
[ApiController]
public class TestController : ControllerBase
{
private readonly RabbitMQService _rabbitmqService;
private readonly IConfiguration _configuration;
public TestController(RabbitMQService rabbitmqService, IConfiguration configuration)
{
_rabbitmqService = rabbitmqService;
_configuration = configuration;
}
/// <summary>
/// 测试rabbitmq发送消息
/// </summary>
/// <returns></returns>
[HttpPost]
public async Task<IActionResult> TestRabbitMqPublishMessage(string pubMessage)
{
var result = await _rabbitmqService.Instance.PublishAsync(
pubMessage,
_configuration["MQ:ExchangeName"]
);
if (!result.Success)
{
Console.WriteLine($"【生产者】消息发送失败:{result.ErrorMessage}");
}
Console.WriteLine("【生产者】消息发送完成");
return Ok();
}
}
}
【九】演示结果

PS:
我这里的死信交换机声明的还是广播模式,其实对于死信队列来说,交换机声明为Direct模式,使用RouteKey去匹配队列也是完全没问题的,而且针对于一条消息,不同队列有不同的消费结果,具体实现场景是所有队列的消费者都消费失败以后才算是一个失败的消息还是说有队列消费成功就不算是失败消息,这都是要结合实际业务场景去进行构思的。