使用 NodeLocalDNS 提升集群 DNS 性能和可靠性

本文主要分享如何使用 NodeLocal DNSCache 来提升集群中的 DNS 性能以及可靠性,包括部署、使用配置以及原理分析,最终通过压测表明使用后带来了高达 50% 的性能提升。
1.背景
什么是 NodeLocalDNS
NodeLocal DNSCache
是一套 DNS 本地缓存解决方案。
NodeLocal DNSCache 通过在集群节点上运行一个 DaemonSet 来提高集群 DNS 性能和可靠性
。
为什么需要 NodeLocalDNS
处于 ClusterFirst 的 DNS 模式下的 Pod 可以连接到 kube-dns 的 serviceIP 进行 DNS 查询,通过 kube-proxy 组件添加的 iptables 规则将其转换为 CoreDNS 端点,最终请求到 CoreDNS Pod。
通过在每个集群节点上运行 DNS 缓存,
NodeLocal DNSCache
可以缩短 DNS 查找的延迟时间、使 DNS 查找时间更加一致,以及减少发送到 kube-dns 的 DNS 查询次数。
在集群中运行
NodeLocal DNSCache
有如下几个好处:
- 如果本地没有 CoreDNS 实例,则具有最高 DNS QPS 的 Pod 可能必须到另一个节点进行解析,使用
NodeLocal DNSCache
后,拥有本地缓存将有助于改善延迟 - 跳过 iptables DNAT 和连接跟踪将有助于减少 conntrack 竞争并避免 UDP DNS 条目填满 conntrack 表(上面提到的 5s 超时问题就是这个原因造成的)
- 从本地缓存代理到 kube-dns 服务的连接可以升级到 TCP,TCP conntrack 条目将在连接关闭时被删除,而 UDP 条目必须超时(默认
nfconntrackudp_timeout
是 30 秒) - 将 DNS 查询从 UDP 升级到 TCP 将减少归因于丢弃的 UDP 数据包和 DNS 超时的尾部等待时间,通常长达 30 秒(3 次重试+ 10 秒超时)
2. 如何使用 NodeLocalDNS
NodeLocalDNS 部署
要安装
NodeLocal DNSCache
也非常简单,直接获取官方的资源清单即可:
wget -c https://raw.githubusercontent.com/kubernetes/kubernetes/master/cluster/addons/dns/nodelocaldns/nodelocaldns.yaml
默认使用的镜像为
registry.k8s.io/dns/k8s-dns-node-cache
如果无法拉取镜像,可以替换成国内的
docker.io/dyrnq/k8s-dns-node-cache
cp nodelocaldns.yaml nodelocaldns.yaml.bak
sed -i 's#registry\.k8s\.io/dns/k8s-dns-node-cache#docker\.io/dyrnq/k8s-dns-node-cache#g' nodelocaldns.yaml
该资源清单文件中包含几个变量,各自含义如下:
__PILLAR__DNS__DOMAIN__
:表示集群域,默认为
cluster.local
,它是用于解析 Kubernetes 集群内部服务的域名后缀。__PILLAR__LOCAL__DNS__
:表示 DNSCache 本地的 IP,也就是 NodeLocalDNS 要使用的 IP,默认为 169.254.20.10- _
_PILLAR__DNS__SERVER__
:表示 kube-dns 这个 Service 的 ClusterIP,一般默认为 10.96.0.10。通过
kubectl get svc -n kube-system -l k8s-app=kube-dns -o jsonpath='{$.items[*].spec.clusterIP}'
命令获取
下面两个变量则不需要关系,NodeLocalNDS Pod 会自动配置,对应的值来源于 kube-dns 的 ConfigMap 和定制的
Upstream Server
配置。直接执行如下所示的命令即可安装:
__PILLAR__CLUSTER__DNS__
: 表示集群内查询的上游 DNS 服务器,一般也指向 kube-dns 的 service IP,默认为 10.96.0.10。__PILLAR__UPSTREAM__SERVERS__
:表示为外部查询的上游服务器,如果没有专门的自建 DNS 服务的话,也可以填 kube-dns 的 service ip。
接下来将对应变量替换为真实值,具体如下:
kubedns=`kubectl get svc kube-dns -n kube-system -o jsonpath={.spec.clusterIP}`
domain=cluster.local
localdns=169.254.20.10
echo kubedns=$kubedns, domain=$domain, localdns=$localdns
需要注意的是:
根据 kube-proxy 运行模式不同,要替换的参数也不同
,使用以下命令查看 kube-proxy 所在模式
kubectl -n kube-system get cm kube-proxy -oyaml|grep mode
如果kube-proxy在
iptables
模式下运行, 则运行以下命令创建
cp nodelocaldns.yaml nodelocaldns-iptables.yaml
sed -i "s/__PILLAR__LOCAL__DNS__/$localdns/g;
s/__PILLAR__DNS__DOMAIN__/$domain/g;
s/__PILLAR__DNS__SERVER__/$kubedns/g" nodelocaldns-iptables.yaml
node-local-dns Pod 会设置
PILLAR__CLUSTER__DNS
和
PILLAR__UPSTREAM__SERVERS
。
如果 kube-proxy 在
ipvs
模式下运行, 则运行以下命令创建
cp nodelocaldns.yaml nodelocaldns-ipvs.yaml
sed -i "s/__PILLAR__LOCAL__DNS__/$localdns/g;
s/__PILLAR__DNS__DOMAIN__/$domain/g;
s/,__PILLAR__DNS__SERVER__//g;
s/__PILLAR__CLUSTER__DNS__/$kubedns/g" nodelocaldns-ipvs.yaml
node-local-dns Pod 会设置
PILLAR__UPSTREAM__SERVERS
然后就是将替换后的 yaml apply 到集群里:
#kubectl apply -f nodelocaldns-iptables.yaml
kubectl apply -f nodelocaldns-ipvs.yaml
会创建以下对象
serviceaccount/node-local-dns created
service/kube-dns-upstream created
configmap/node-local-dns created
daemonset.apps/node-local-dns created
service/node-local-dns created
创建完成后,就能看到每个节点上都运行了一个pod,这里只有一个节点,所以就运行了一个
[root@caas ~]# kubectl -n kube-system get po
NAME READY STATUS RESTARTS AGE
node-local-dns-m8ktq 1/1 Running 0 8s
需要注意的是这里使用 DaemonSet 部署 node-local-dns 使用了 hostNetwork=true,会占用宿主机的
8080
端口,所以需要保证该端口未被占用。
NodeLocalDNS 配置
上一步部署好
NodeLocal DNSCache,
但是还差了很重要的一步,
配置
pod
使用 NodeLocal DNSCache 作为优先的
DNS
服务器。
有以下几种方式:
- 方式一:修改 kubelet 中的 dns nameserver 参数,并重启节点 kubelet。
存在业务中断风险,不推荐使用此方式
。
- 测试时可以用这个方式,比较简单
- 方式二:创建 Pod 时手动指定 DNSConfig,
比较麻烦,不推荐。 - 方式三:借助 DNSConfig 动态注入控制器在 Pod 创建时配置 DNSConfig 自动注入,
推荐使用此方式。
- 需要自己实现一个 webhook,相当于把方式二自动化了,
方式一:修改 kubelet 参数
kubelet通过
--cluster-dns
和
--cluster-domain
两个参数来全局控制Pod DNSConfig。
- cluster-dns
:部署Pod时,默认采用的DNS服务器地址,默认只引用了
kube-dns
的 ServiceIP,需要增加一个 NodeLocalDNS 的 169.254.20.10 。 - cluster-domain
:部署 Pod 时,默认采用的 DNS 搜索域,保持原有搜索域即可,一般为
cluster.local
。
在
/etc/systemd/system/kubelet.service.d/10-kubeadm.conf
配置文件中需要
增加
一个
--cluster-dns
参数,设置值为NodeLocalDNS 的 169.254.20.10。
注意是在原有的前面增加一个 --cluster-dns,不是把原本的改了。
这样 Pod 中就会有两个 dns nameserver,如果新增的这个失效了,也可以使用旧的。
vi /etc/systemd/system/kubelet.service.d/10-kubeadm.conf
# 增加 --cluster-dns
--cluster-dns=169.254.20.10 --cluster-dns=<kube-dns ip> --cluster-domain=<search domain>
然后重启 kubelet 使其生效
sudo systemctl daemon-reload
sudo systemctl restart kubelet
方式二:自定义 Pod dnsConfig
通过 dnsConfig 字段自定义
Pod
的
dns
配置
,nameservers 中除了指定 NodeLocalDNS 之外还指定了 KubeDNS,这样即使 NodeLocalDNS 异常也不影响 Pod 中的 DNS 解析。
apiVersion: v1
kind: Pod
metadata:
name: alpine
namespace: default
spec:
containers:
- image: alpine
command:
- sleep
- "10000"
imagePullPolicy: Always
name: alpine
dnsPolicy: None
dnsConfig:
nameservers: ["169.254.20.10","10.96.0.10"]
searches:
- default.svc.cluster.local
- svc.cluster.local
- cluster.local
options:
- name: ndots
value: "3"
- name: attempts
value: "2"
- name: timeout
value: "1"
- dnsPolicy:必须为
None
。 - nameservers:配置成 169.254.20.10 和 kube-dns 的 ServiceIP 地址。
- searches:设置搜索域,保证集群内部域名能够被正常解析。
- ndots:默认为 5,可以适当降低 ndots 以提升解析效率。
方式三:Webhook 自动注入 dnsConfig
DNSConfig 动态注入控制器可用于自动注入DNSConfig至新建的Pod中,避免您手工配置Pod YAML进行注入。本应用默认会监听包含
node-local-dns-injection=enabled
标签的命名空间中新建Pod的请求,您可以通过以下命令给命名空间打上Label标签。
部署后,只需要给 Namespace 打上
node-local-dns-injection=enabled
label 即可,Webhook 检测就会自动给该 Namespace 下所有 Pod 配置 DNSConfig。
先挖个坑,下一篇做一个简单实现。
3. 压测
接下来进行压测,看一下性能提升。
这里使用修改 kubelet 参数方式暂时让 Pod 都使用 NodeLocalDNS,便于测试
测试环境:
1 master 1 worker 的 k8s 集群,节点规则统一 4C8G,空闲状态,未运行其他负载。
可以参考
Kubernetes教程(十一)---使用 KubeClipper 通过一条命令快速创建 k8s 集群
快速创建一个集群。
压测脚本
使用下面这个文件进行性能测试
// main.go
package main
import (
"context"
"flag"
"fmt"
"net"
"sync/atomic"
"time"
)
var host string
var connections int
var duration int64
var limit int64
var timeoutCount int64
func main() {
flag.StringVar(&host, "host", "", "Resolve host")
flag.IntVar(&connections, "c", 100, "Connections")
flag.Int64Var(&duration, "d", 0, "Duration(s)")
flag.Int64Var(&limit, "l", 0, "Limit(ms)")
flag.Parse()
var count int64 = 0
var errCount int64 = 0
pool := make(chan interface{}, connections)
exit := make(chan bool)
var (
min int64 = 0
max int64 = 0
sum int64 = 0
)
go func() {
time.Sleep(time.Second * time.Duration(duration))
exit <- true
}()
endD:
for {
select {
case pool <- nil:
go func() {
defer func() {
<-pool
}()
resolver := &net.Resolver{}
now := time.Now()
_, err := resolver.LookupIPAddr(context.Background(), host)
use := time.Since(now).Nanoseconds() / int64(time.Millisecond)
if min == 0 || use < min {
min = use
}
if use > max {
max = use
}
sum += use
if limit > 0 && use >= limit {
timeoutCount++
}
atomic.AddInt64(&count, 1)
if err != nil {
fmt.Println(err.Error())
atomic.AddInt64(&errCount, 1)
}
}()
case <-exit:
break endD
}
}
fmt.Printf("request count:%d\nerror count:%d\n", count, errCount)
fmt.Printf("request time:min(%dms) max(%dms) avg(%dms) timeout(%dn)\n", min, max, sum/count, timeoutCount)
}
首先配置好 golang 环境,然后直接构建上面的测试应用:
go build -o testdns main.go
构建完成后生成一个 testdns 的二进制文件
跨节点 DNS 性能测试
首先测试跨节点 DNS 性能测试,因为随着集群规模扩大,CoreDNS 副本数和节点数很明显不能做到 1:1,因此大部分 DNS 请求都是跨节点的,这个性能也更能反映正常情况下的 DNS 性能。
一般推荐是 1:8,即 8 个节点对应 1 个 CoreDNS Pod
首先将 CoreDNS 副本数调整为 1,便于测试。
kubectl -n kube-system scale deploy coredns --replicas=1
这样就是两个节点对应一个 CoreDNS Pod,就可以测试跨节点 DNS 解析性能了。
[root@dns-1 go]# kubectl get node
NAME STATUS ROLES AGE VERSION
dns-1 Ready control-plane 48m v1.27.4
dns-2 Ready <none> 48m v1.27.4
[root@dns-1 go]# kubectl -n kube-system get po -owide -l k8s-app=kube-dns
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
coredns-5d78c9869d-l7vgv 1/1 Running 0 12m 172.25.173.4 dns-1 <none> <none>
当前 CoreDNS 在 dns-1 节点,那我们把测试 Pod 指定调度到 dns-2 节点。
通过 overrides 直接指定 nodeName,让 Pod 和 CoreDNS 分散到不同节点。
kubectl run busybox3 --image=busybox:latest --restart=Never --overrides='{ "spec": { "nodeName": "dns-2" } }' -- sleep 10000
然后我们将这个二进制文件拷贝到 Pod 中去进行测试:
kubectl cp testdns busybox:/
拷贝完成后进入这个测试的 Pod 中去:
kubectl exec -it busybox -- /bin/sh
然后我们执行 testdns 程序来进行压力测试,比如执行 200 个并发,持续 30 秒:
# 对地址 kube-dns.kube-system 进行解析
/ # ./testdns -host kube-dns.kube-system -c 200 -d 30 -l 5000
lookup kube-dns.kube-system on 10.96.0.10:53: no such host
lookup kube-dns.kube-system on 10.96.0.10:53: no such host
lookup kube-dns.kube-system on 10.96.0.10:53: no such host
lookup kube-dns.kube-system on 10.96.0.10:53: no such host
lookup kube-dns.kube-system on 10.96.0.10:53: no such host
lookup kube-dns.kube-system on 10.96.0.10:53: no such host
lookup kube-dns.kube-system on 10.96.0.10:53: no such host
lookup kube-dns.kube-system on 10.96.0.10:53: no such host
lookup kube-dns.kube-system on 10.96.0.10:53: no such host
lookup kube-dns.kube-system on 10.96.0.10:53: no such host
lookup kube-dns.kube-system on 10.96.0.10:53: no such host
lookup kube-dns.kube-system on 10.96.0.10:53: no such host
lookup kube-dns.kube-system on 10.96.0.10:53: no such host
lookup kube-dns.kube-system on 10.96.0.10:53: no such host
lookup kube-dns.kube-system on 10.96.0.10:53: no such host
lookup kube-dns.kube-system on 10.96.0.10:53: no such host
lookup kube-dns.kube-system on 10.96.0.10:53: no such host
lookup kube-dns.kube-system on 10.96.0.10:53: no such host
lookup kube-dns.kube-system on 10.96.0.10:53: no such host
lookup kube-dns.kube-system on 10.96.0.10:53: no such host
lookup kube-dns.kube-system on 10.96.0.10:53: no such host
lookup kube-dns.kube-system on 10.96.0.10:53: no such host
lookup kube-dns.kube-system on 10.96.0.10:53: no such host
request count:131063
error count:23
request time:min(1ms) max(15050ms) avg(39ms) timeout(624n)
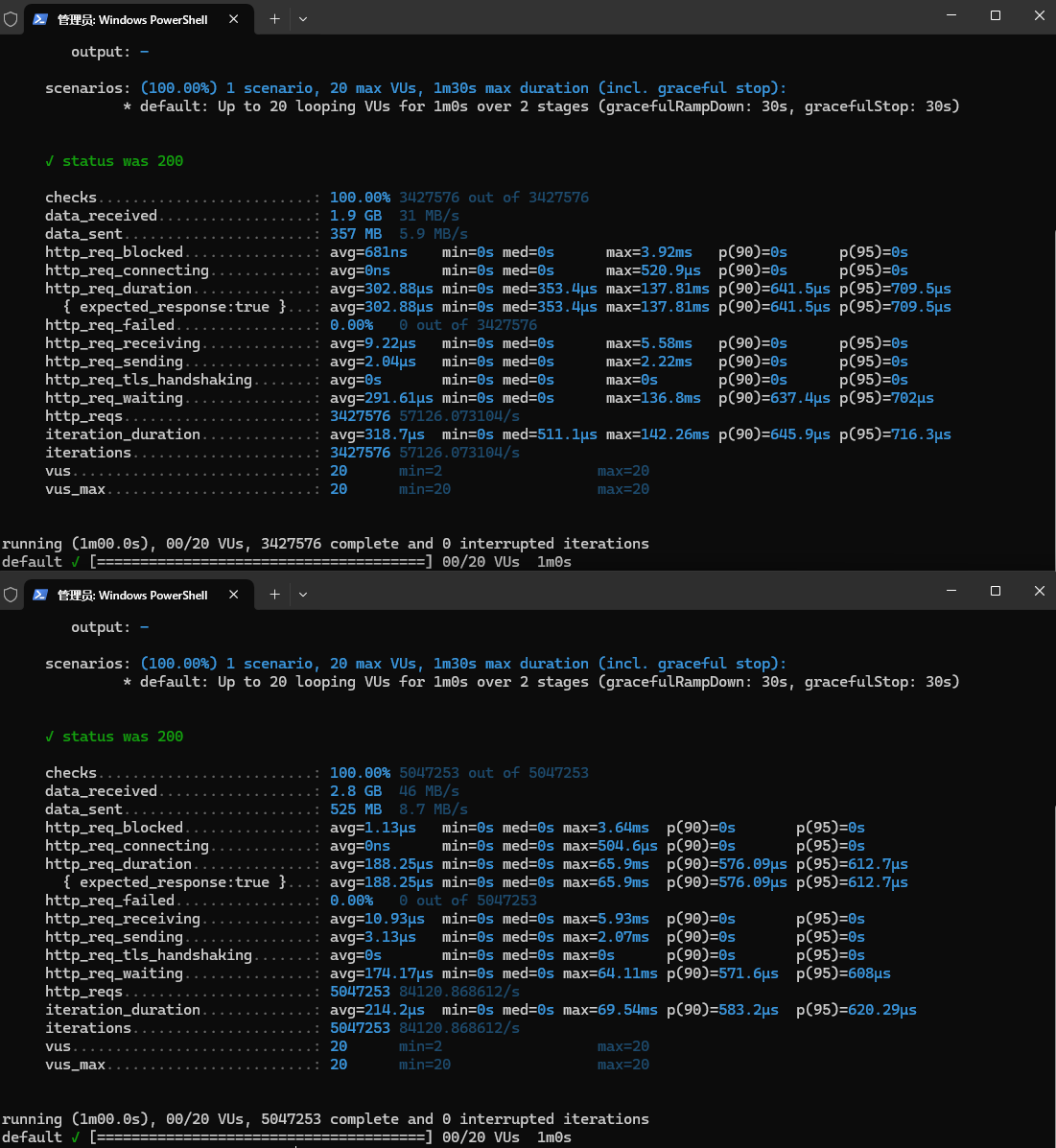
我们可以看到平均耗时为 39ms 左右,这个性能是比较差的,而且还有部分解析失败的条目。
同节点 DNS 性能测试
重新创建 busybox pod,指定调度到和 CoreDNS 同一个节点,测试同节点 DNS 解析性能。
理论上同节点性能会比跨节点提升不少
然后创建一个 Busybox Pod 用于测试,通过 overrides 直接指定 nodeName,让 Pod 和 CoreDNS 分散到不同节点。
kubectl delete pod busybox
kubectl run busybox --image=busybox:latest --restart=Never --overrides='{ "spec": { "nodeName": "dns-1" } }' -- sleep 10000
然后我们将这个二进制文件拷贝到 Pod 中去进行测试:
kubectl cp testdns busybox:/
拷贝完成后进入这个测试的 Pod 中去:
kubectl exec -it busybox -- /bin/sh
然后我们执行 testdns 程序来进行压力测试,比如执行 200 个并发,持续 30 秒:
# 对地址 kube-dns.kube-system 进行解析
/ # ./testdns -host kube-dns.kube-system -c 200 -d 30 -l 5000
request count:217030
error count:0
request time:min(1ms) max(5062ms) avg(26ms) timeout(311n)
我们可以看到大部分平均耗时都是在 26ms 左右,相比之前的 40ms,提升了接近 50%,而且也没有出现超时、失败的情况。
NodeLocalDNS 测试
直接启动 Pod
kubectl delete pod busybox
kubectl run busybox --image=busybox:latest --restart=Never -- sleep 10000
然后我们将这个二进制文件拷贝到 Pod 中去进行测试:
kubectl cp testdns busybox:/
拷贝完成后进入这个测试的 Pod 中去:
kubectl exec -it busybox -- /bin/sh
然后我们执行 testdns 程序来进行压力测试,比如执行 200 个并发,持续 30 秒:
把 Pod 中的 DNS Nameserver 指向 169.254.20.10(即 NodeLocalDNS 地址),然后再次测试
vi /etc/resolv.conf
增加以下内容
nameserver 169.254.20.10
然后再次测试
/ # ./testdns -host kube-dns.kube-system -c 200 -d 30 -l 5000
request count:224103
error count:0
request time:min(1ms) max(5057ms) avg(24ms) timeout(333n)
可以看到,平均耗时都是 24ms,比跨节点的 39ms 提升 50%,和同节点的 26ms 接近,这样说明跨节点 DNS 解析有大量性能损失。
而
NodeLocalDNS 和同节点对比依旧存在一些提升
,因为:
- 访问 CoreDNS 使用的是 service 的 clusterIP 10.96.0.10 最终会进过 iptables / ipvs 等规则转发到后端 CoreDNS Pod 中
- 而访问 NodeLocalDNS 则是使用的 link-local ip 169.254.20.10,不会经过 iptables / ipvs 规则跳转,直接就会进入 NodeLocalDNS Pod。
因此,有略微的性能提升。
4.NodeLocal DNSCache 工作原理
这部分主要分析 NodeLocal DNSCache 工作原理。
工作原理分析
NodeLocalDNS 实际就是在每个节点上加了一个缓存,
类似于
CDN
,把 中心 CoreDNS 看做源站的话,node-local-dns 就是运行在不同区域的缓存。
Pod 优先从本地 NodeLocalDNS 做 DNS 解析,有数据则直接返回,否则 NodeLocalDNS 再找 KubeDNS 解析,然后本地把数据缓存下来。
具体流程正如
阿里云文档
) 中的这个图所示:

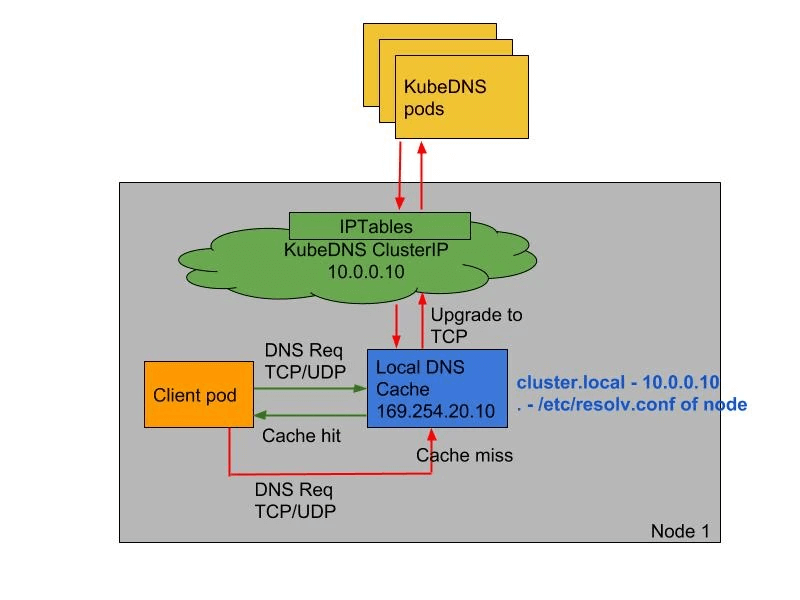
首先控制面,创建 Pod 时 Admission Webhook 会自动注入 DNSConfig,已经注入 DNSConfig 和 未注入 DNSConfig 的 Pod 会拥有不同的情况。
具体如下:
1)已注入 DNS 本地缓存的Pod,默认会通过 NodeLocal DNSCache 监听于节点上的IP(169.254.20.10)解析域名。
Pod 内的 DNS 配置如下:
/ # cat /etc/resolv.conf
search default.svc.cluster.local svc.cluster.local cluster.local
nameserver 169.254.20.10
nameserver 10.96.0.10
options ndots:5
169.254.20.10 为第一个 nameserver,因此会优先使用。
2)NodeLocal DNSCache 本地若无缓存应答解析请求,则会通过 kube-dns 服务请求 CoreDNS 进行解析。
NodeLocalDNS 的 Corefile 中相关配置如下:
.:53 {
errors
cache 30
reload
loop
bind 169.254.20.10 __PILLAR__DNS__SERVER__
forward . __PILLAR__UPSTREAM__SERVERS__
prometheus :9253
}
当无法解析时,会转发到上游服务,也就是 kube-dns。
3)已注入 DNS 本地缓存的 Pod,当无法连通 NodeLocal DNSCache 时,会继而直接通过 kube-dns 服务连接到CoreDNS 进行解析,此链路为备用链路。
Pod 中的 DNS 配置:
/ # cat /etc/resolv.conf
search default.svc.cluster.local svc.cluster.local cluster.local
nameserver 169.254.20.10
nameserver 10.96.0.10
options ndots:5
Kube-dns 对应的 IP 10.96.0.10 也做为第二 nameserver ,因此NodeLocal DNS 异常时 Pod 也能正常进行 DNS 解析。
4)未注入 DNS本地缓存的 Pod,会通过标准的 kube-dns 服务链路连接到 CoreDNS 进行解析。
未注入 DNSConfig 的 Pod 默认 DNS 配置如下:
/ # cat /etc/resolv.conf
search default.svc.cluster.local svc.cluster.local cluster.local
nameserver 10.96.0.10
options ndots:5
自然会直接请求 kube-dns
5)CoreDNS 对于非集群内域名,则会根据当前节点上的 /etc/resolv.conf 转发到外部
DNS
服务器。
Kube-dns 的 Corefile 中相关配置如下:
.:53 {
errors
health {
lameduck 5s
}
// 省略...
forward . /etc/resolv.conf {
max_concurrent 1000
}
}
省略了其他无关配置,
forward . /etc/resolv.conf
表示,遇到无法解析的请求时会根据 /etc/resolv.conf 文件中的配置进行转发。
而 CoreDNS Pod 中的 /etc/resolv.conf 文件又是 Pod 启动时从当前节点 copy 进去的,因此具体转发到哪儿就和 Pod 启动时节点上的 /etc/resolv.conf 配置有关。
为什么是 169.254.20.10 ?
为什么访问
169.254.20.10
这个
IP
就可以访问到 NodeLocalDNS ?
NodeLocalDNS 以 DaemonSet 方式运行,因此会在集群中每个节点上都启动一个 Pod。该 Pod 会为当前节点增加一张网卡,并将 IP 指定为
169.254.20.10
。
就像下面这样:
47: nodelocaldns: <BROADCAST,NOARP> mtu 1500 qdisc noop state DOWN group default
link/ether 56:9b:08:18:a6:75 brd ff:ff:ff:ff:ff:ff
inet 169.254.20.10/32 scope global nodelocaldns
valid_lft forever preferred_lft forever
NodelocalDNS 会以 hostNetwork 网络模式启动,并在前面新增网卡对应 IP (169.254.20.20)上启动服务。
由于我们前面的配置(修改 kubelet 或者 Pod 的 dnsConfig),Pod 里优先级最高的 DNS 服务器就是 169.254.20.20,因此 Pod 需要 DNS 解析时会优先访问 169.254.20.10,最终请求被同节点的 NodelocalDNS Pod 处理。
添加这个网卡的具体作用如下:
- 本地 DNS 服务:
nodelocaldns
在每个节点上运行,通过监听
169.254.20.10
地址提供本地 DNS 服务。这个地址是一个 link-local 地址,仅在本地节点可达。Pod 内的 DNS 查询会被重定向到这个地址,从而实现在节点内解析服务的域名。 - 避免 DNS 查询离开节点: 由于
nodelocaldns
提供了节点内的 DNS 解析服务,这张网卡确保 DNS 查询不会离开节点。这对于集群内部的 DNS 查询来说是非常高效的,不需要离开节点就能解析服务的域名。 - 降低 DNS 查询延迟: 由于
nodelocaldns
在每个节点上运行,节点内的 DNS 查询可以更快速地完成,而不必经过集群网络。
简单的做一个实验
# 创建一个新的网络接口 mynic
sudo ip link add mynic type dummy
# 分配IP地址给 eth1
sudo ip addr add 1.1.1.1/24 dev mynic
# 启动你的程序,让它监听在指定的IP地址上
# 例如,如果你有一个基于Python的简单HTTP服务器:
python3 -m http.server 9090 --bind 1.1.1.1
# 同一节点打开新终端测试能否访问到
curl 1.1.1.1:9090
是可以直接访问到的,NodeLocalDNS 添加网卡就是这个作用。
至于为什么是 169.254.20.10 这个 IP?
则是因为 169.254.0.0/16 地址范围是专门用于 link-local 通信的。这意味着这些地址仅在同一子网内可用,并且不需要经过路由器来进行通信。
在这个网络内使用 169.254.20.10 而不是.1 .2 这些则是留出几个位置,以避免冲突。
5. 小结
CoreDNS 本身性能差是因为
跨节点访问导致的大量性能损耗
,同时由于内核 DNAT bug 导致超时等情况。
NodeLocal DNSCache 具有以下优势:
- 减少了平均 DNS 查找时间
- 从 Pod 到其本地缓存的连接不会创建 conntrack 表条目。这样可以防止由于 conntrack 表耗尽和竞态条件而导致连接中断和连接被拒绝。
使用 NodeLocalDNS 后性能提升接近 40%, DNS 解析延迟从 39ms 降低到 24ms,且报错次数大幅下降。
NodeLocalDNS 则使用 DaemonSet 方式启动在每个节点都启动一个 Pod,同时使用 hostnetwork + link-local 地址来保证 Pod 中的 DNS 请求只会请求到本地的 NodeLocalDNS Pod,从而避免了跨节点问题,大幅提升性能。
最后 NodeLocalDNS 使用 Link-local 地址也避免了默认情况下使用 service 的 clusterIP 需要 iptables/ipvs 等规则跳转的的问题,在同节点基础上也实现了略微的性能提升。
因此,对于大规模集群,存在高并发的 DNS 请求,推荐使用 NodeLocal DNSCache。