.NET Core + Kafka 开发指南

什么是Kafka
Apache Kafka是一个分布式流处理平台,由LinkedIn开发并开源,后来成为Apache软件基金会的顶级项目。Kafka主要用于构建实时数据管道和流式应用程序。
Kafka 架构
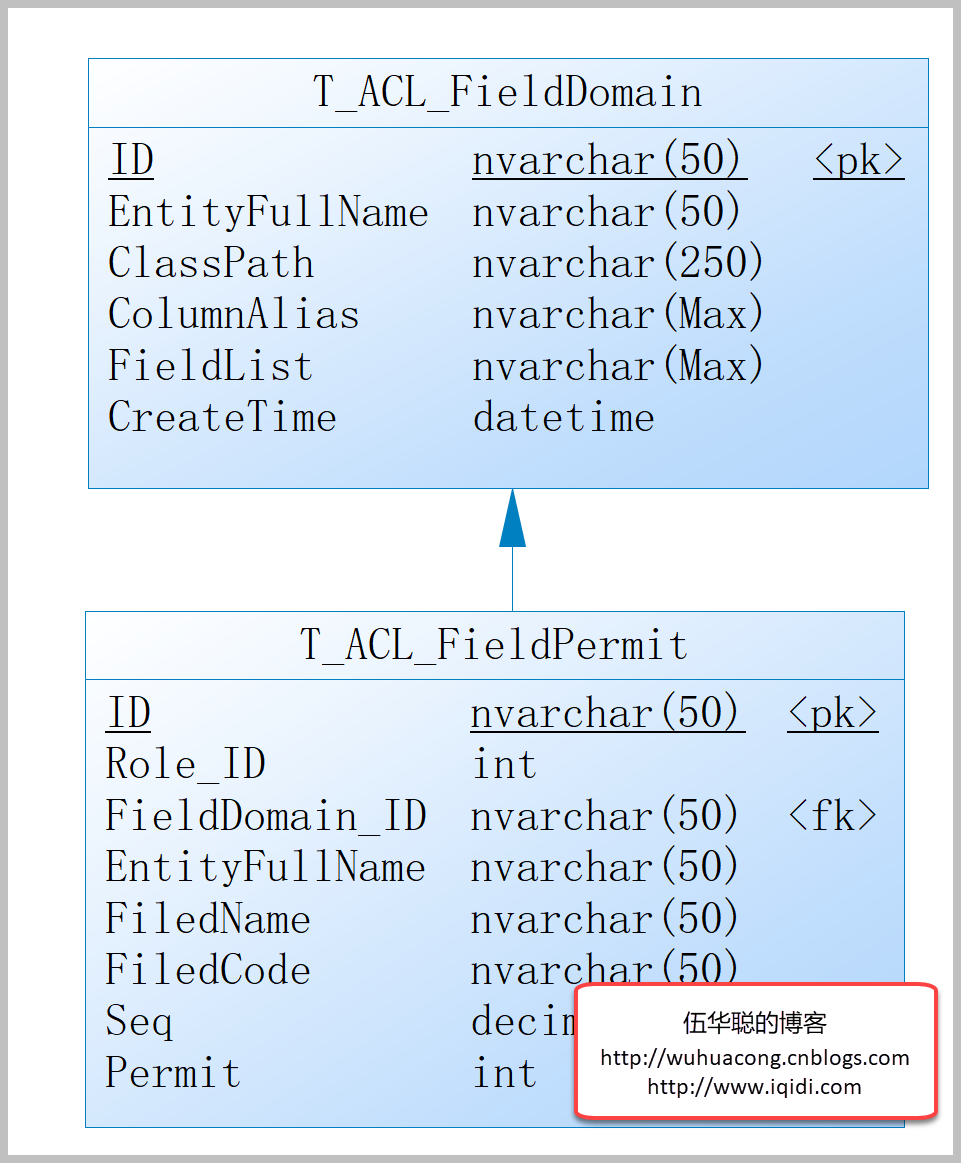
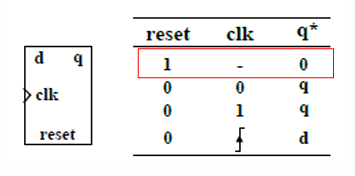
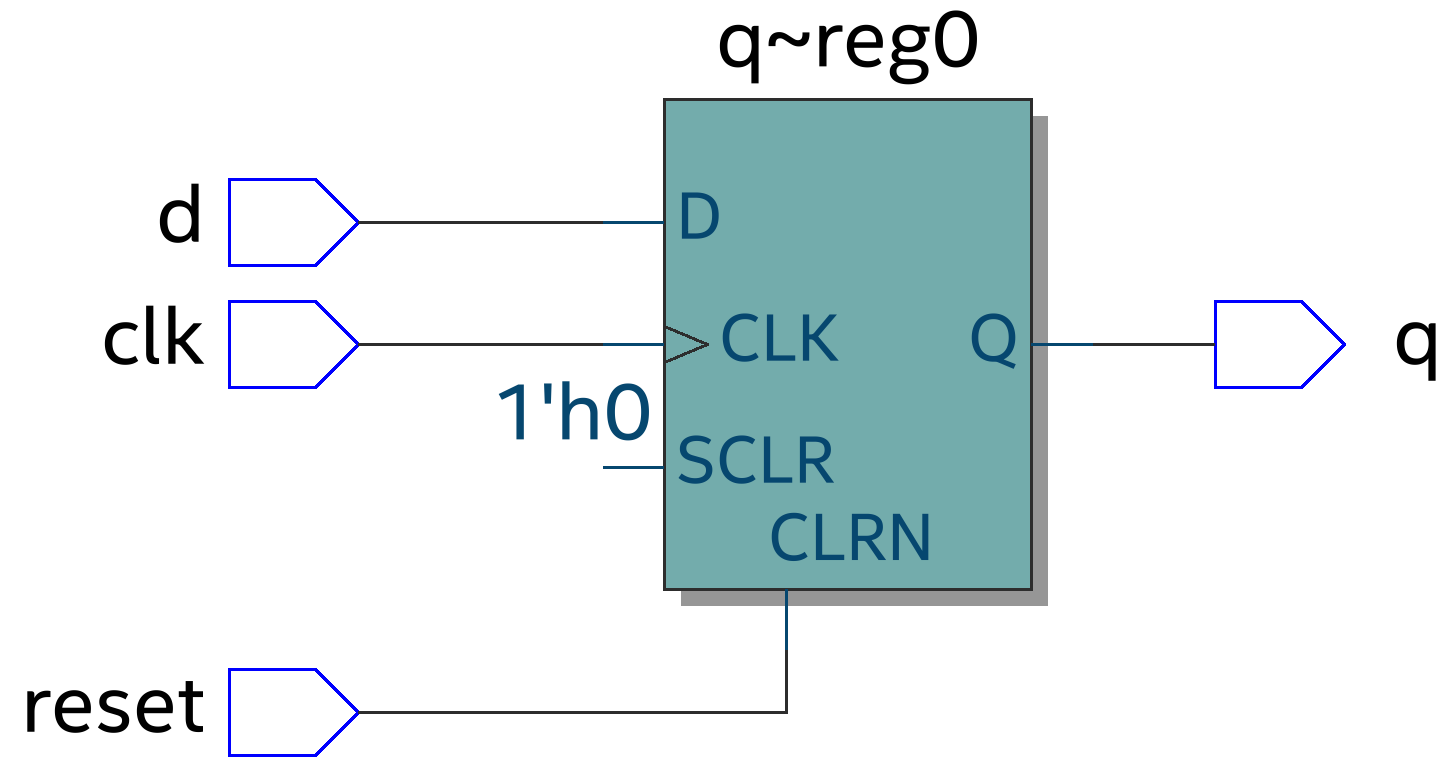
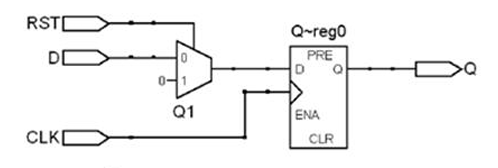
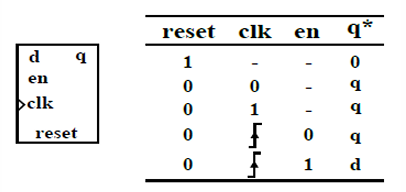
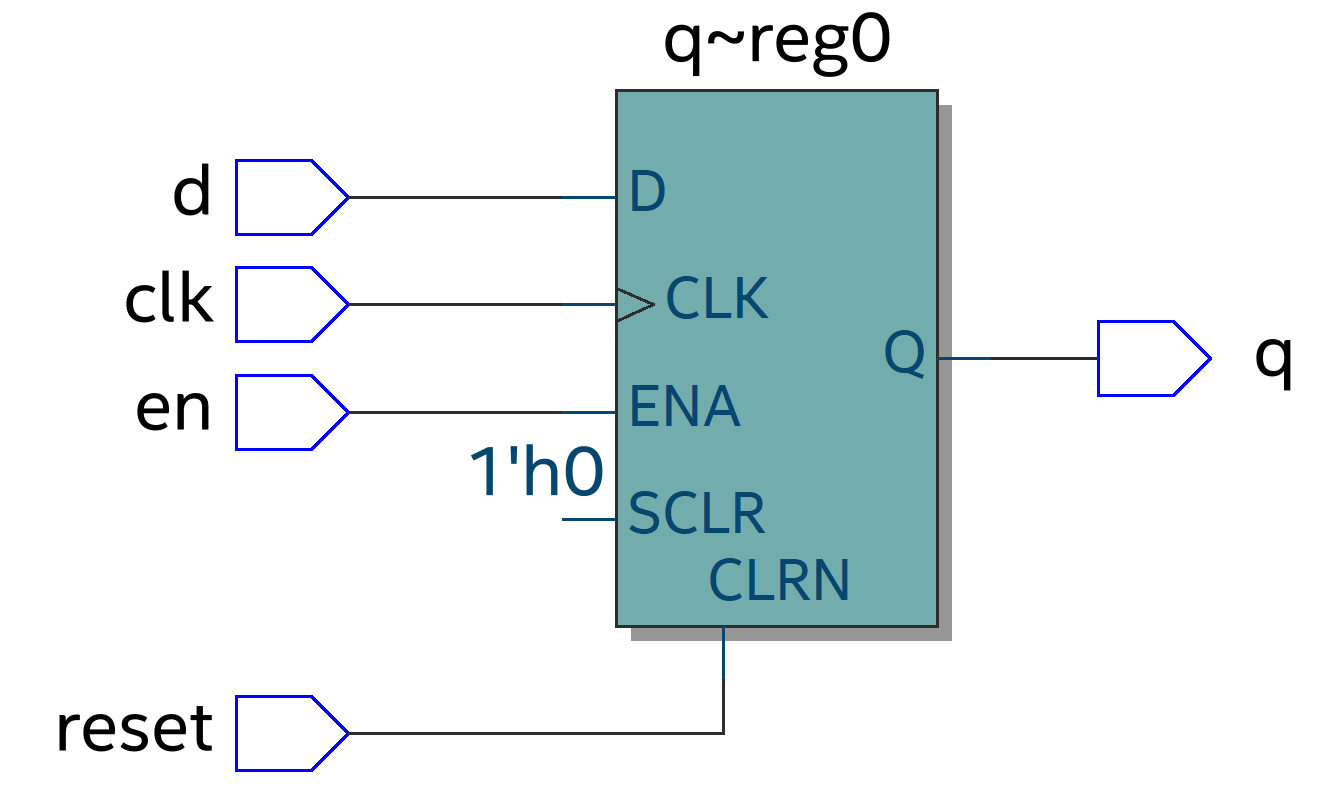
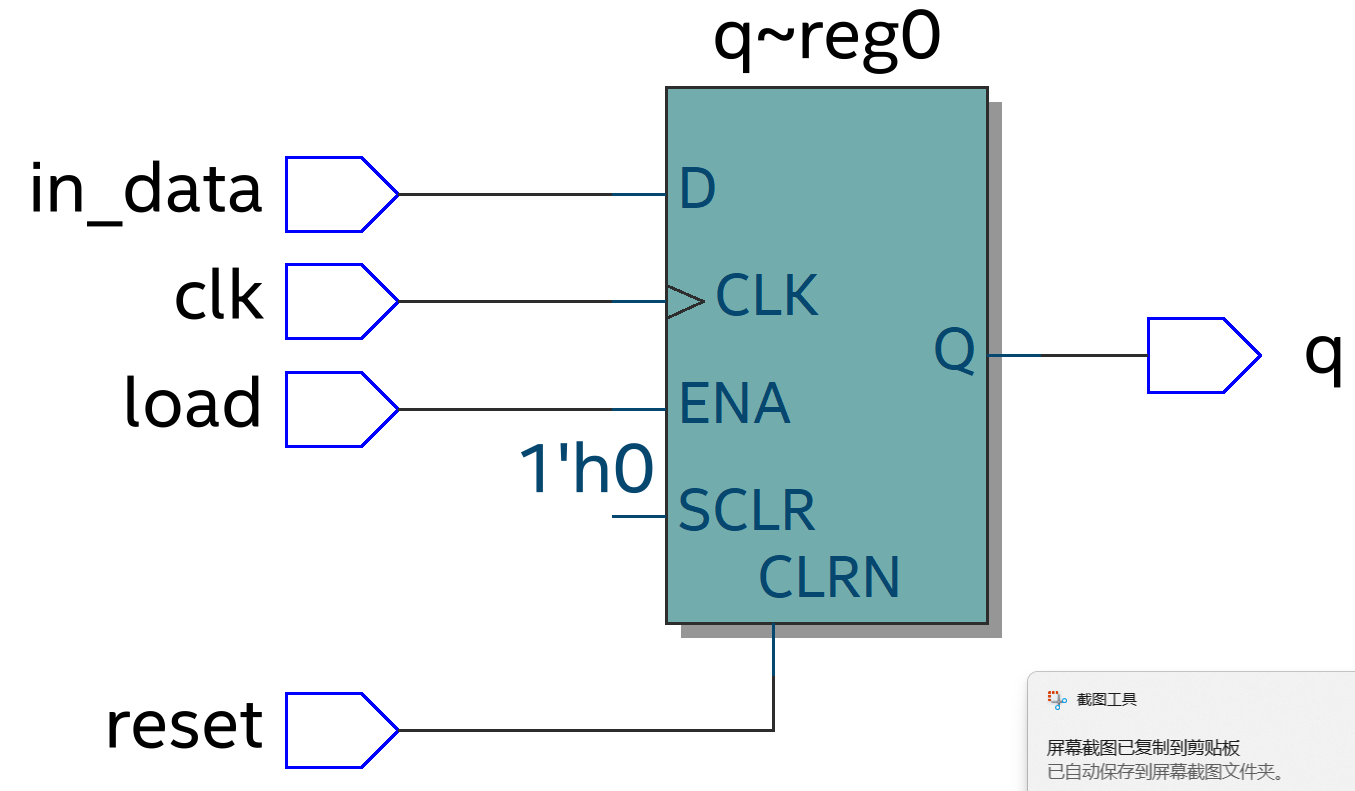
从下面3张架构图中可以看出Kafka Server 实际扮演的是Broker的角色, 一个Kafka Cluster由多个Broker组成, 或者可以说是多个Topic组成。
图 1
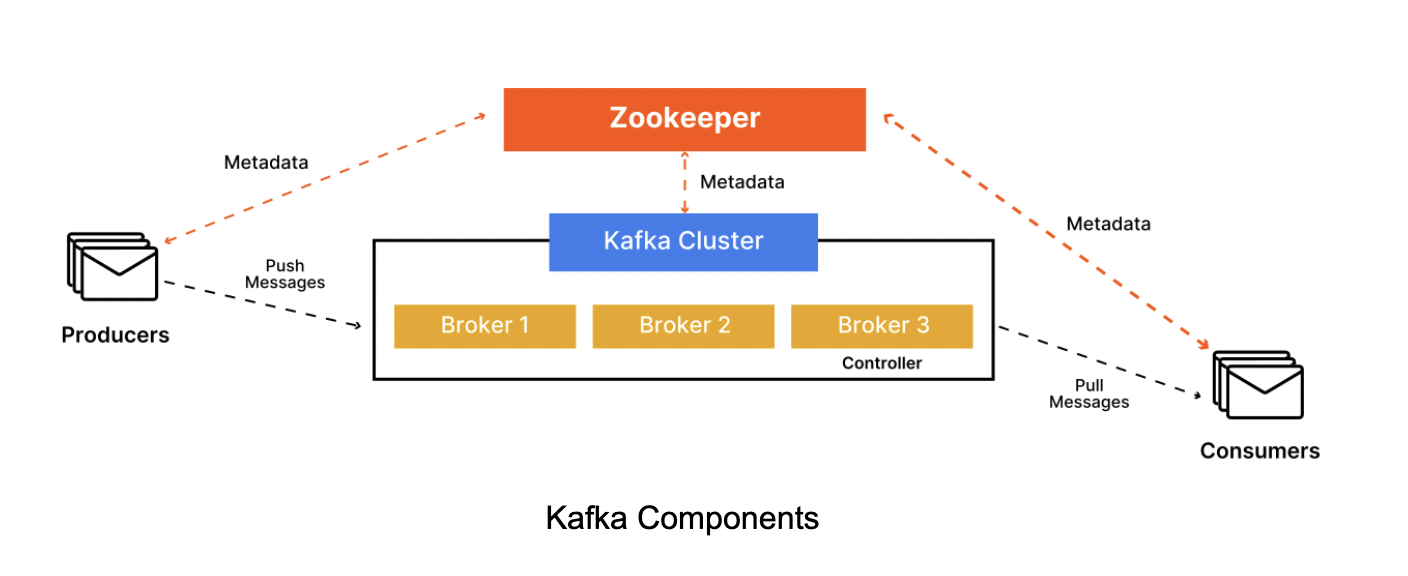
图 2

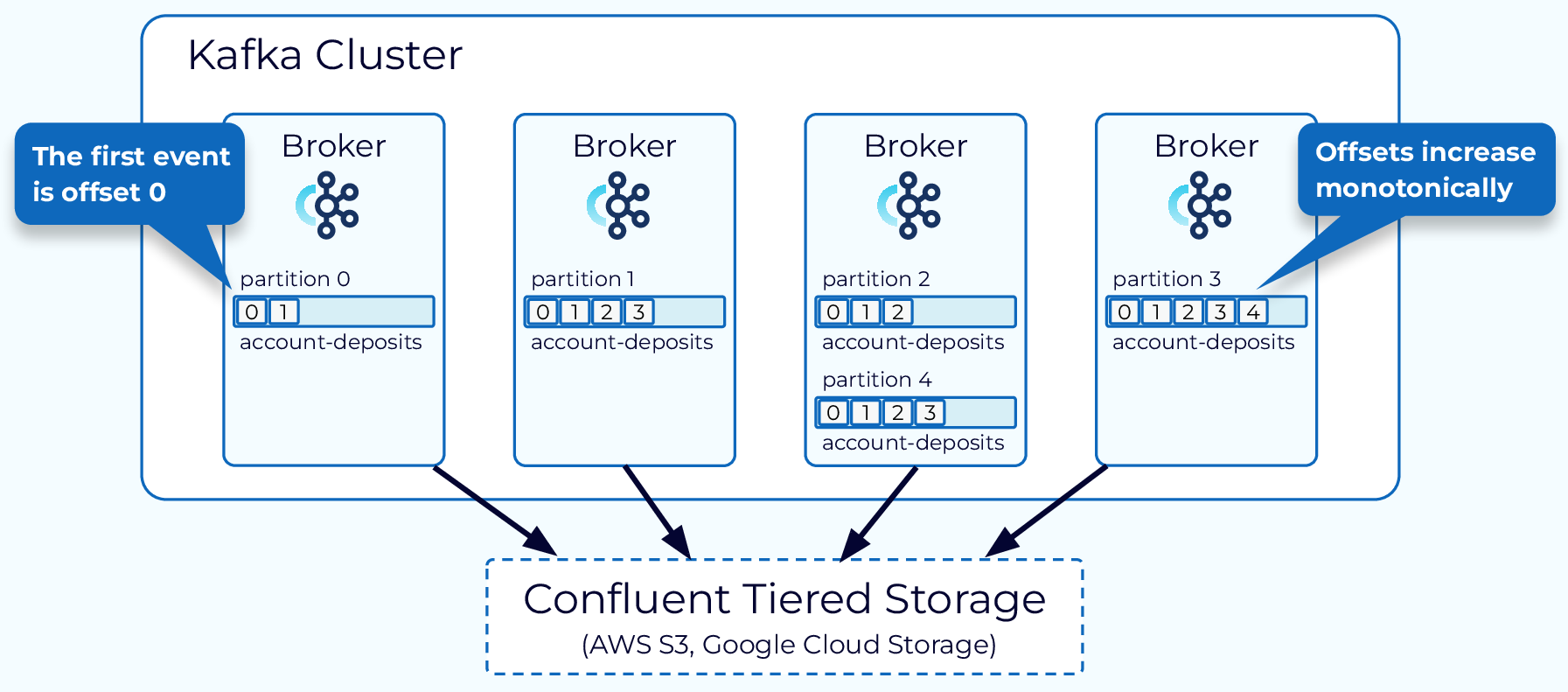
图 3
主要概念(Main Concepts)和术语(Terminology)
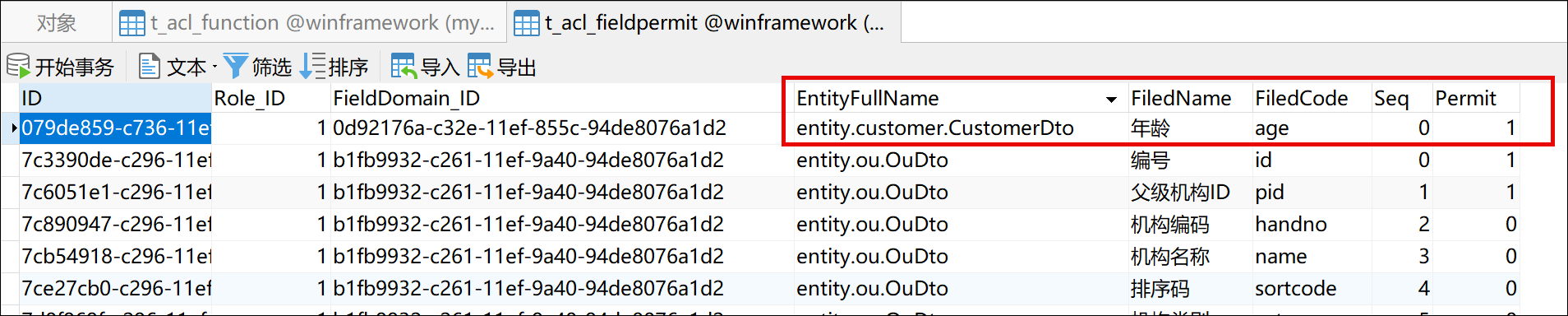
Kafka Cluster
一个Kafka集群是一个由多个Kafka代理组成的分布式系统,它们协同工作以处理实时流数据的存储和处理。它为大规模应用程序中高效的数据流和消息传递提供了容错性、可扩展性和高可用性。
Broker
Broker是构成Kafka集群的服务器。 每个Broker负责接收、存储和提供数据。 它们处理来自生产者和消费者的读写操作。 Broker还管理数据的复制以确保容错性。
Topic and Partitions
Kafka中的数据被组织成主题(Topics),这些是生产者发送数据和消费者读取数据的逻辑通道。每个主题被划分为分区(partitions),它们是Kafka中并行处理的基本单位。分区允许Kafka通过在多个Broker 之间分布数据来水平扩展。
Producers
生产者是发布(写入)数据到Kafka主题的客户端应用程序。它们根据分区策略将记录发送到适当的主题和分区,分区策略可以是基于键(key-based)或轮询(round-robin)。
Consumers
消费者是订阅Kafka主题并处理数据的客户端应用程序。它们从主题中读取记录,并且可以是消费者组的一部分,这允许负载均衡和容错。每个组中的消费者从一组独特的分区中读取数据。
Zookeeper
ZooKeeper是一个集中式服务,用于维护配置信息、命名、提供分布式同步和提供群组服务。在Kafka中,ZooKeeper用于管理和协调Kafka Broker。ZooKeeper被展示为与Kafka集群交互的独立组件。
Offsets
偏移量(offsets)是分配给分区中每条消息的唯一标识符。消费者将使用这些偏移量来跟踪他们在消费主题中消息的进度。
Kafka vs RabbitMQ
相同点
- 消息队列功能
- Kafka和RabbitMQ都是流行的消息队列工具,支持生产者-消费者模式,能够解耦系统,提高系统的可扩展性和可靠性。
- 异步通信
- 两者都支持异步通信,允许生产者发送消息后立即返回,消费者可以异步处理消息。
- 多种消息传递模式
- 均支持点对点(P2P)和发布/订阅(Pub/Sub)模式。
- 持久化支持
- Kafka和RabbitMQ都支持消息的持久化,以确保在系统故障或重启后消息不会丢失。
- 高可用性
- 两者都支持集群部署,具有高可用性和容错能力。
- 语言支持
- 提供多种语言的客户端库,支持不同编程语言的集成。
不同点
架构和设计
- 数据存储
- Kafka:基于日志分区存储设计,适合高吞吐量的顺序读写。
- RabbitMQ:基于AMQP协议,消息存储在队列中,适合低延迟的场景。
- 消息消费模式
- Kafka:消息由消费者主动拉取,支持多次消费。
- RabbitMQ:消息通过推送方式传递给消费者,消费后消息默认从队列中移除。
- 使用场景
- Kafka:适用于大数据场景(日志聚合、流式处理),擅长处理高吞吐量、大规模消息传递。
- RabbitMQ:适用于需要复杂路由和消息确认的场景(如事务性消息和实时通信)。
性能与延迟
- 高吞吐量
- Kafka:设计针对高吞吐量场景优化,能够支持百万级消息每秒。
- RabbitMQ:吞吐量相对较低,但延迟更低。
- 延迟
- Kafka:适合高吞吐量但对实时性要求不高的应用。
- RabbitMQ:更适合低延迟应用,提供实时性支持。
协议支持
- 协议类型
- Kafka:自定义的二进制协议。
- RabbitMQ:基于AMQP协议,支持丰富的消息功能(如TTL、优先级)。
- 兼容性
- Kafka:需要Kafka专用客户端。
- RabbitMQ:支持AMQP标准协议,兼容性较强。
开发一个Producer和一个Consumer
本地docker环境启动一个kafka
version: '2'
services:
zookeeper:
image: confluentinc/cp-zookeeper:7.4.4
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
ports:
- 22181:2181
kafka:
image: confluentinc/cp-kafka:7.4.4
depends_on:
- zookeeper
ports:
- 29092:29092
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka:9092,PLAINTEXT_HOST://localhost:29092
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
使用.NET CORE + Kafka开发一个消息生产者, 一个消息消费者, 客户端需要安装组件** Confluent.Kafka**
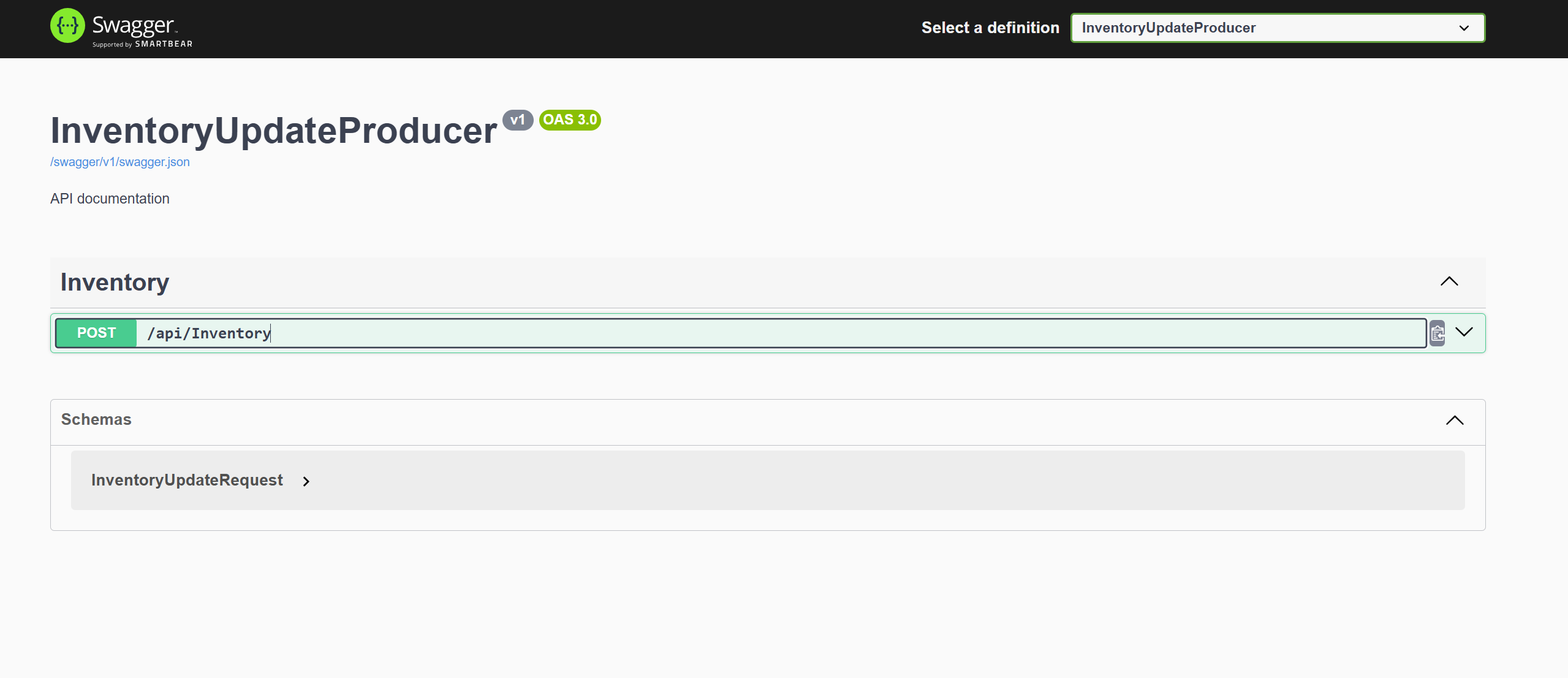
InventoryUpdateProducer
public class ProducerService
{
private readonly IConfiguration _configuration;
private readonly IProducer<Null, string> _producer;
private readonly ILogger<ProducerService> _logger;
public ProducerService(IConfiguration configuration, ILogger<ProducerService> logger)
{
_configuration = configuration;
_logger = logger;
var config = new ProducerConfig
{
BootstrapServers = _configuration["Kafka:BootstrapServers"],
};
_producer = new ProducerBuilder<Null, string>(config).Build();
}
public async Task ProductAsync(string topic, string message)
{
var orderPlacedMessage = new Message<Null, string>
{
Value = message
};
await _producer.ProduceAsync(topic, orderPlacedMessage);
_logger.LogInformation("Message sent to topic: {Topic}", topic);
}
}
[Route("api/[controller]")]
[ApiController]
public class InventoryController : ControllerBase
{
private readonly ProducerService _producerService;
public InventoryController(ProducerService producerService)
{
_producerService = producerService;
}
[HttpPost]
public async Task<IActionResult> Post([FromBody] InventoryUpdateRequest request)
{
var message = System.Text.Json.JsonSerializer.Serialize(request);
await _producerService.ProductAsync("inventory-update", message);
return Ok("Inventory Updated Successfully...");
}
}
启动项目,查看Swagger
InventoryUpdateConsumer
消息消费者程序使用.net core BackgroundService开发, 这个类需要在程序启动时注入进去,不要忘记。
public class ConsumerService : BackgroundService
{
private readonly ILogger<ConsumerService> _logger;
private readonly IConfiguration _configuration;
private readonly IConsumer<Ignore, string> _consumer;
public ConsumerService(ILogger<ConsumerService> logger, IConfiguration configuration)
{
_logger = logger;
_configuration = configuration;
var consumerConfig = new ConsumerConfig
{
BootstrapServers = configuration["Kafka:BootstrapServers"],
GroupId = "InventoryConsumerGroup",
AutoOffsetReset = AutoOffsetReset.Earliest
};
_consumer = new ConsumerBuilder<Ignore, string>(consumerConfig).Build();
}
protected override async Task ExecuteAsync(CancellationToken stoppingToken)
{
_consumer.Subscribe("inventory-update");
try
{
while (!stoppingToken.IsCancellationRequested)
{
HandleMessage(stoppingToken);
await Task.Delay(TimeSpan.FromSeconds(5), stoppingToken);
}
}
catch (OperationCanceledException)
{
_logger.LogInformation("Consumer service has been cancelled.");
}
catch (Exception ex)
{
_logger.LogError($"Error in consuming messages: {ex.Message}");
}
finally
{
_consumer.Close();
}
}
public void HandleMessage(CancellationToken cancellation)
{
try
{
var consumeResult = _consumer.Consume(cancellation);
var message = consumeResult.Message.Value;
_logger.LogInformation($"Received inventory update: {message}");
}
catch (Exception ex)
{
_logger.LogError($"Error processing Kafka message: {ex.Message}");
}
}
}
var builder = WebApplication.CreateBuilder(args);
builder.Services.AddHostedService<ConsumerService>();
运行程序
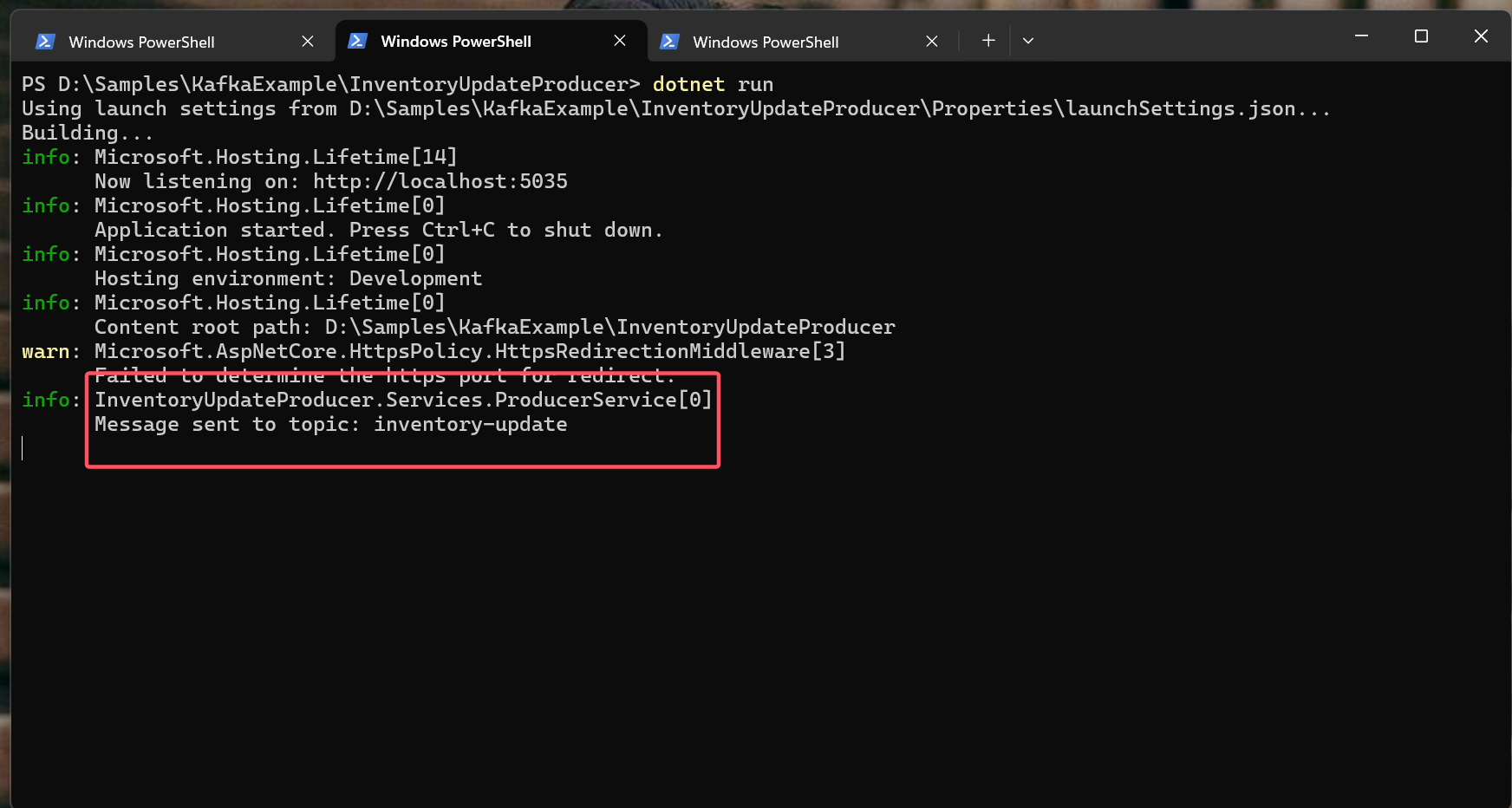
Publish Message
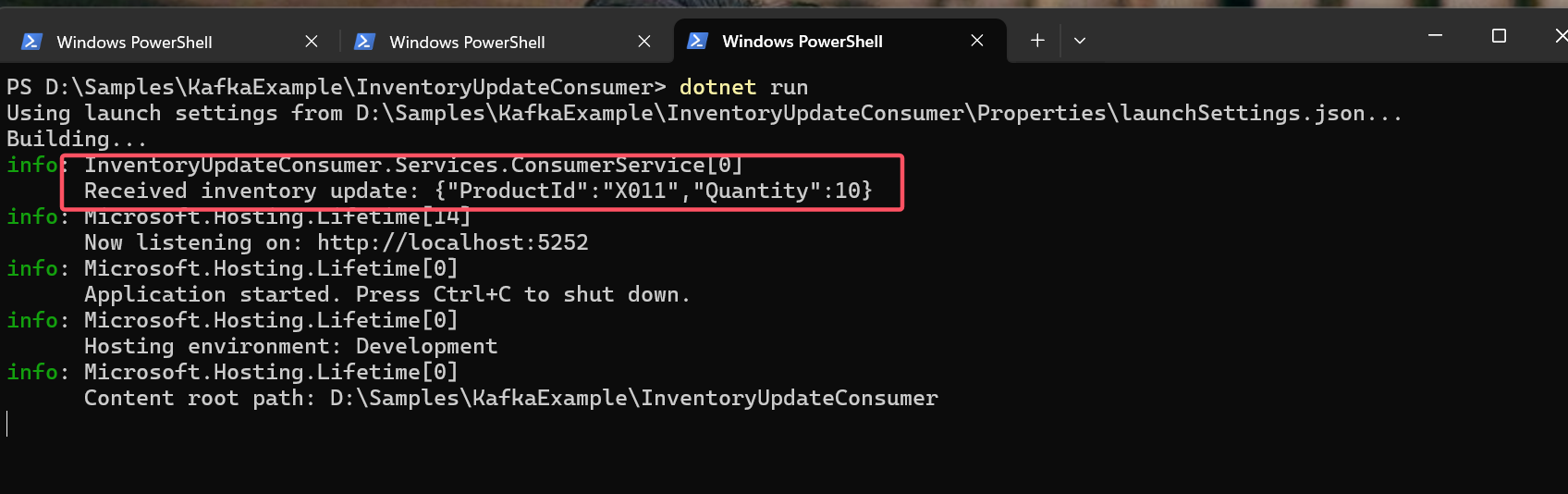
Consume Message
总结
Apache Kafka不是消息中间件的一种实现。相反,它只是一种分布式流式系统。 不同于基于队列和交换器的RabbitMQ,Kafka的存储层是使用分区事务日志来实现的。Kafka也提供流式API用于实时的流处理以及连接器API用来更容易的和各种数据源集成。