CountDownLatch是一个常用的共享锁,其功能相当于一个多线程环境下的倒数门闩。CountDownLatch可以指定一个计数值,在并发环境下由线程进行减一操作,当计数值变为0之后,被await方法阻塞的线程将会唤醒。通过CountDownLatch可以实现线程间的计数同步。
为什么说CountDownLatch是一种共享锁?因为CountDownLatch提供了一种“计数器”机制,允许N个线程在CountDownLatch的协调下同时运行,计数器归零才会触发阻塞的线程继续执行后续代码。
可能还是有人无法明白“共享”两个字,举个例子:如果计数器初始值是10,那开始的时候会有十个线程自动获取到共享锁,由于计数器的值是10,所以业务上如果有更多的线程想要获取锁,就要等待(主线程await);十个线程调用countDown方法之后锁才会释放,这时候阻塞的主线程才能获取到共享锁。
一、基本使用
CountDownLatch的使用步骤如下所示:
(1)创建倒数闩,初始化CountDownLatch时设置倒数的总次数,比如为100。
(2)等待线程调用倒数闩的await()方法阻塞自己,等待倒数闩的计数器数值为0(倒数线程全部执行结束)。
(3)倒数线程执行完,调用CountDownLatch.countDown()方法将计数器数值减一。
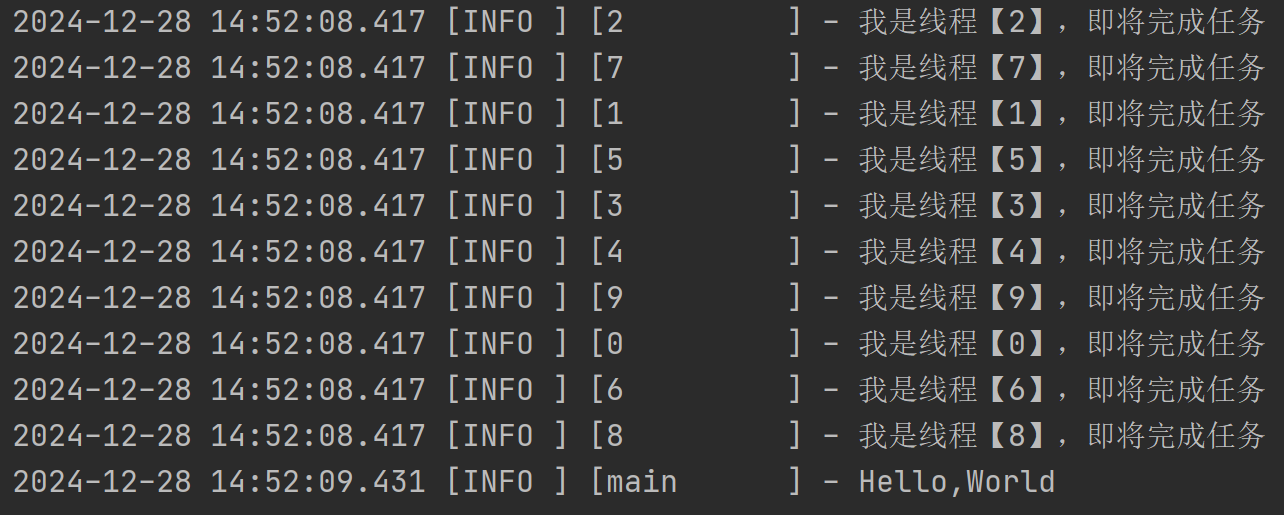
现在我们定义10个线程,十个线程都运行任务结束后,打印“Hello,World”。
import lombok.SneakyThrows;
import lombok.extern.slf4j.Slf4j;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.TimeUnit;
/**
* @author kdyzm
* @date 2024/12/28
*/
@Slf4j
public class CountdownLatchDemo {
private static final CountDownLatch countDownLatch = new CountDownLatch(10);
public static void main(String[] args) throws InterruptedException {
for (int i = 0; i < 10; i++) {
new Thread(new Task(), "" + i).start();
}
countDownLatch.await();
log.info("Hello,World");
}
static class Task implements Runnable {
@SneakyThrows
@Override
public void run() {
log.info("我是线程【{}】,即将完成任务", Thread.currentThread().getName());
TimeUnit.SECONDS.sleep(1);
countDownLatch.countDown();
}
}
}
代码运行结果如下:
CountDownLatch很神奇,竟然能同步多个线程的执行,让多个线程都执行完才进行下一步行动,那么它实现的原理是什么呢?
搂一眼CountDownLatch类:
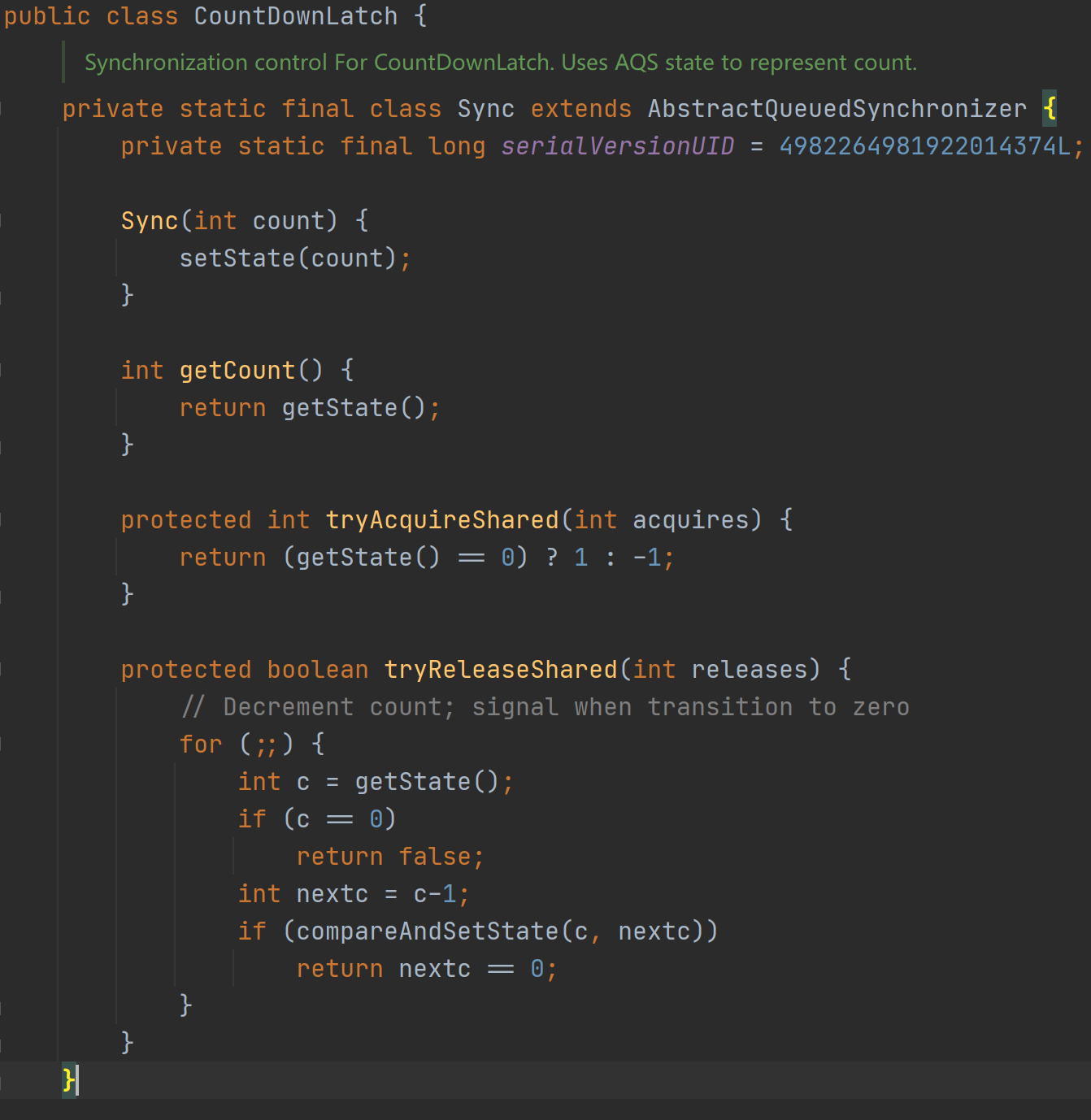
这代码可太熟悉了,和ReentrantLock非常相似啊。。。内部也是定义了Sync类继承了AQS类,大体上可以明白了,CountDownLatch类也是基于AQS类实现的。
CountDownLatch有两个重要的方法:await方法和countDown方法。
二、CountDownLatch实例的创建
CountDownLatch构造方法需要传递一个整数
public CountDownLatch(int count) {
if (count < 0) throw new IllegalArgumentException("count < 0");
this.sync = new Sync(count);
}
在构造方法中初始化了Sync类的实例。
private static final class Sync extends AbstractQueuedSynchronizer {
private static final long serialVersionUID = 4982264981922014374L;
Sync(int count) {
//使用传递的count参数初始化state数值
setState(count);
}
......
}
可以看到,在Sync类的构造方法中,会使用传入的count参数初始化state参数。在ReetrantLock类中,state参数代表着重入锁的重入次数,在CountDownLatch中将其设置成count数值有什么意义呢?
实际上在CountDownLatch中state参数表示可以执行countDown方法的次数。
二、await方法
一般而言,await方法是先开始执行的方法,然后迅速进入阻塞状态,等待其它线程计数到0,就会触发唤醒,然后主线程执行await方法之后的代码。
public void await() throws InterruptedException {
sync.acquireSharedInterruptibly(1);
}
await方法很简单,它的逻辑都委托给Sync类实例来实现了,但是实际上这里的acquireSharedInterruptibly方法调用是AQS的模板方法。
1、可中断获取共享锁:acquireSharedInterruptibly
public final void acquireSharedInterruptibly(int arg)
throws InterruptedException {
if (Thread.interrupted())
throw new InterruptedException();
//查看计数器是否归零
if (tryAcquireShared(arg) < 0)
//如果没归零,就开始执行可中断获取共享锁流程
doAcquireSharedInterruptibly(arg);
}
这个方法非常简单,这个方法是一个可中断的方法,可中断意味着它可以抛出InterruptedException异常。所以上来它先检查了当前线程是否发生了中断,如果发生了中断,就立刻抛出InterruptedException异常。
接下来调用了tryAcquireShared方法查看计数器是否归零
2、查看计数器是否归零:tryAcquireShared
tryAcquireShared方法是AQS的钩子方法,被CountDownLatch实现,用于检查计数器是否变成了0。
protected int tryAcquireShared(int acquires) {
return (getState() == 0) ? 1 : -1;
}
可以看到,传过来的acquires参数并没有被用到,实际上该方法就是检查了state参数是否变成了0。
这里其实有个疑问,根据ReentrantLock的经验,tryAcquireShared是尝试获取锁的方法,但是它仅仅只是判断了state的值是否为0,这是为何?
3、执行获取共享锁:doAcquireSharedInterruptibly
private void doAcquireSharedInterruptibly(int arg)
throws InterruptedException {
//将节点标记为共享类型,并加入AQS同步队列。
final Node node = addWaiter(Node.SHARED);
boolean failed = true;
try {
for (;;) {
//获取节点的前置节点
final Node p = node.predecessor();
//判断是否是头结点,是头结点就表示自己可以尝试获取锁了。
if (p == head) {
//尝试获取共享锁,实际上是检查了state参数是否为0
int r = tryAcquireShared(arg);
//r>=0的条件只有一个,那就是r为1,表示state值已经变成了0
if (r >= 0) {
//执行获取锁成功的流程。
setHeadAndPropagate(node, r);
p.next = null; // help GC
failed = false;
return;
}
}
//检查是否应该在失败后挂起。
if (shouldParkAfterFailedAcquire(p, node) &&
//挂起线程
parkAndCheckInterrupt())
//如果发生了中断,就抛出IE异常。
throw new InterruptedException();
}
} finally {
if (failed)
cancelAcquire(node);
}
}
在这里,AQS队列的规则和ReentrantLock中AQS队列一样,头部节点表示已经获取锁的节点,一旦被唤醒,头部节点的后续节点就可以抢锁了。
CountDownLatch的抢锁逻辑比较简单,只是检查下state参数是否已经变成了0,变成了0,就表示其余线程都执行完了countDown方法,计数器已经变成了0,当前线程需要释放了;没变成0,就表示不是所有线程都执行了countDown方法,还不满足获取锁的条件。
不满足获取锁的条件的话,就开始判定是否需要挂起线程,执行
shouldParkAfterFailedAcquire
方法,该方法会被执行两次,然后执行
parkAndCheckInterrupt
方法,将当前主线程挂起。
主线程挂起之后,就开始等待其余线程执行执行countDown方法之后唤醒它。
4、获取锁成功之后:setHeadAndPropagate
执行到
setHeadAndPropagate
方法,就表示当前线程已经获取到了锁,执行到该方法的时候,计数器必定已经变成了0,parkAndCheckInterrupt()方法原本是被阻塞的现在已经被释放。
private void setHeadAndPropagate(Node node, int propagate) {
Node h = head;
setHead(node);
//propagate值为1,满足if条件
if (propagate > 0 || h == null || h.waitStatus < 0 ||
(h = head) == null || h.waitStatus < 0) {
Node s = node.next;
//AQS队列中只有node一个等待节点,所以next必定为null,满足if条件
if (s == null || s.isShared())
//后续没有等待节点了,执行锁释放流程
doReleaseShared();
}
}
该方法中有两处if,有很多判断根本用不到,大概是给其它共享锁使用的。总之CountDownLatch的await方法执行到这里之后会执行doReleaseShared方法执行锁释放,因为后续已经没有节点了。
5、锁释放:doReleaseShared
await方法中刚获取到锁就开始执行锁释放了,这是因为AQS中等待队列中就一个节点,该节点后续没有了等待节点,就需要释放锁。
rivate void doReleaseShared() {
for (;;) {
Node h = head;
//此时AQS队列就一个head节点,head == tail,不满足if条件
if (h != null && h != tail) {
int ws = h.waitStatus;
if (ws == Node.SIGNAL) {
if (!compareAndSetWaitStatus(h, Node.SIGNAL, 0))
continue;
unparkSuccessor(h);
}
else if (ws == 0 &&
!compareAndSetWaitStatus(h, 0, Node.PROPAGATE))
continue;
}
//满足if条件,结束循环
if (h == head)
break;
}
}
CountDownLatch的await方法中执行到doReleaseShared的时候是有附件条件的:AQS队列中只有一个头结点,没有等待节点了,所以第一个if条件没有满足条件,第二个if条件满足了,所以结束了循环。
doReleaseShared方法什么都没做。
这样await方法结束后,主线程继续执行await方法后的代码。
三、countDown方法
通常情况下,await方法会先执行,并在doAcquireSharedInterruptibly方法中的parkAndCheckInterrupt处阻塞,countDown方法在其它线程中被调用,并在计数器归零时唤醒被阻塞在await方法的线程。
public void countDown() {
sync.releaseShared(1);
}
countDown方法依然调用了sync的方法:releaseShared方法是AQS的模板方法。
1、释放共享锁:releaseShared
public final boolean releaseShared(int arg) {
//尝试释放锁,计数器减一
if (tryReleaseShared(arg)) {
//释放共享锁
doReleaseShared();
return true;
}
return false;
}
releaseShared是AQS的模板方法,该方法会调用钩子方法tryReleaseShared方法执行计数器减一,如果满足了释放共享锁的条件,就执行doRelease方法释放共享锁。
比如计数器初始值是10,则前九个线程调用countDown方法都不会满足if条件,第十个线程调用countDown方法时,调用tryReleaseShared方法之后会满足if条件,然后执行doReleaseShared方法。
2、计数器减一:tryReleaseShared
tryReleaseShared是AQS的钩子方法,在CountDownLatch中,被Sync实现了该方法。
protected boolean tryReleaseShared(int releases) {
//循环防止之后的CAS失败
for (;;) {
int c = getState();
//如果计数器的值已经是0,就返回失败,这里是为了防止出现超出计数器初始值的线程数调用countDown方法
if (c == 0)
return false;
//计数器减一
int nextc = c-1;
//CAS设置state值
if (compareAndSetState(c, nextc))
/**
* 如果设置成功了,再次判断计数器是否为0:
* 如果是0表示当前操作使得计数器归零,应当触发释放共享锁的操作
* 如果不是0表示计数器还未归零,不到释放共享锁的时机
*/
return nextc == 0;
}
}
由于多个线程可能会同时执行countDown方法,可能会并行修改state值,所以该方法使用了for循环+CAS的方式保证了线程安全性。
需要注意的唯一一点就是
if (c == 0)
return false;
这个判断语句,该判断语句用于防止出现超出计数器初始值的线程数调用countDown方法,当超出计数器初始值的线程调用countDown方法,会因为计数器已经归零而导致tryReleaseShared方法返回false。
3、释放锁:doReleaseShared
在众多执行countDown方法的线程中,只有将计数器置为零的那个线程有执行doReleaseShared方法的机会。
doReleaseShared方法在之前await方法中已经讲过一部分,在await方法中如果当前节点是最后一个节点,那最后将调用doRelease方法释放锁。为什么这里会释放锁?因为执行countDown方法的线程都是获取到锁的线程,执行完毕之后要调用countDown方法释放锁,当然还是那句话,只有将计数器置为零的那个线程有执行doReleaseShared方法的机会。
和await方法中调用doReleaseShared方法什么都没做不一样,在countDown方法中调用doReleaseShared执行逻辑就变得不一样了。一般来说,由于await方法会先于countDown方法执行,所以在执行countDown方法的时候,AQS队列中会有两个节点,一个是头结点(AQS初始化创建的虚拟节点),一个是等待队列中的主线程节点。
private void doReleaseShared() {
for (;;) {
//获取头结点,并暂存到h变量
Node h = head;
//当前AQS队列中有两个节点,满足if条件
if (h != null && h != tail) {
//获取到头结点状态
int ws = h.waitStatus;
//由于await方法已经将头结点状态更改成了SIGNAL,所以这里会满足if条件
if (ws == Node.SIGNAL) {
//将头结点状态改为0
if (!compareAndSetWaitStatus(h, Node.SIGNAL, 0))
continue;
//唤醒后继结点
unparkSuccessor(h);
}
else if (ws == 0 &&
!compareAndSetWaitStatus(h, 0, Node.PROPAGATE))
continue; // loop on failed CAS
}
//一般情况下,执行countDown方法的线程执行速度比较快,会满足该if条件并结束循环
if (h == head)
break;
}
}
可以看到将计数器归零的countDown方法调用的线程,最后会在doReleaseShared方法中调用unparkSuccessor方法唤醒后继线程。后继线程实际上就是await方法被阻塞的主线程,它将会在doAcquireSharedInterruptibly方法中的parkAndCheckInterrupt方法处被唤醒后继续执行后续代码。
四、扩展问题
1、countDown方法先于await方法执行
一般情况下await方法会先执行,执行后线程被挂起阻塞;countDown方法后执行,最后将计数器归零的线程负责将调用await方法被挂起的线程唤醒。想一个问题:如果cuontDown方法先都执行完了,最后再执行await方法,会发生什么呢?
答案是:什么都不会发生,因为这就是正确的逻辑啊。await方法和countDown方法均为此做了防范措施。
countDown方法:
最后将计数器清零的线程会将被阻塞的线程唤醒,但是如果说await方法没有被调用,则AQS队列中就没有需要被唤醒的线程,doReleaseShared方法会如何做呢?
private void doReleaseShared() {
for (;;) {
//由于AQS队列为空,所以head为null
Node h = head;
//head为null,不满足if条件
if (h != null && h != tail) {
int ws = h.waitStatus;
if (ws == Node.SIGNAL) {
if (!compareAndSetWaitStatus(h, Node.SIGNAL, 0))
continue;
unparkSuccessor(h);
}
else if (ws == 0 &&
!compareAndSetWaitStatus(h, 0, Node.PROPAGATE))
continue;
}
//h == head == null,满足if条件,结束循环
if (h == head)
break;
}
}
doReleaseShared方法此时什么都没做,由于没有满足触发条件,因此都没有机会执行
unparkSuccessor(h);
唤醒后继节点。
await方法:
await方法中调用了
acquireShardInterruptibly
方法,该方法在执行的过程中会先判定当前计数器的值,如果是0,就不会再继续执行
doAcquireSharedInterruptibly
方法,避免了线程被挂起无人唤醒的尴尬局面。
public final void acquireSharedInterruptibly(int arg)
throws InterruptedException {
if (Thread.interrupted())
throw new InterruptedException();
//由于计数器的值已经归零,所以这里没有满足if条件
if (tryAcquireShared(arg) < 0)
doAcquireSharedInterruptibly(arg);
}
2、超出计数器初始值的线程数执行countDown方法
如下代码所示
@Slf4j
public class CountdownLatchDemo {
//计数器初始值是1
private static final CountDownLatch countDownLatch = new CountDownLatch(1);
public static void main(String[] args) throws InterruptedException {
//10个线程执行了countDown方法
for (int i = 0; i < 10; i++) {
new Thread(new Task(), "" + i).start();
}
countDownLatch.await();
log.info("Hello,World");
}
static class Task implements Runnable {
@SneakyThrows
@Override
public void run() {
log.info("我是线程【{}】,即将完成任务", Thread.currentThread().getName());
//等待一秒钟模拟业务执行,确保await方法先执行
TimeUnit.SECONDS.sleep(1);
countDownLatch.countDown();
}
}
}
CountDownLatch对多余执行countDown方法的线程的处理策略就是:忽略它。看看countDown方法中调用的releaseShared方法
//该方法为AQS的模板方法
public final boolean releaseShared(int arg) {
//tryReleaseShared方法是关键
if (tryReleaseShared(arg)) {
doReleaseShared();
return true;
}
return false;
}
//该方法文为CountDownLatch中实现AQS的钩子方法
protected boolean tryReleaseShared(int releases) {
for (;;) {
int c = getState();
//如果计数器值已经变成了0,就直接返回false,防止超量的线程执行countDown方法。
if (c == 0)
return false;
int nextc = c-1;
if (compareAndSetState(c, nextc))
return nextc == 0;
}
}
releaseShared方法仅仅是通过判断一次
if (c == 0)
return false;
就解决了超量线程调用countDown方法的问题。
3、CountDownLatch使用进阶
本篇文章通篇均是以以下代码示例分析的:
import lombok.SneakyThrows;
import lombok.extern.slf4j.Slf4j;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.TimeUnit;
/**
* @author kdyzm
* @date 2024/12/28
*/
@Slf4j
public class CountdownLatchDemo {
private static final CountDownLatch countDownLatch = new CountDownLatch(10);
public static void main(String[] args) throws InterruptedException {
for (int i = 0; i < 10; i++) {
new Thread(new Task(), "" + i).start();
}
countDownLatch.await();
log.info("Hello,World");
}
static class Task implements Runnable {
@SneakyThrows
@Override
public void run() {
log.info("我是线程【{}】,即将完成任务", Thread.currentThread().getName());
TimeUnit.SECONDS.sleep(1);
countDownLatch.countDown();
}
}
}
这种CountDownLatch的使用方式比较简单,实际上CountDownLatch还有另外一种经典的使用方式,其源码示例如下所示
import java.util.concurrent.CountDownLatch;
class Driver { // ...
void main() throws InterruptedException {
CountDownLatch startSignal = new CountDownLatch(1);
CountDownLatch doneSignal = new CountDownLatch(N);
for (int i = 0; i < N; ++i) // create and start threads
new Thread(new Worker(startSignal, doneSignal)).start();//线程刚开始执行全部进入阻塞状态
doSomethingElse(); // 先执行一些动作
startSignal.countDown(); // 让所有阻塞的线程开始执行
doSomethingElse();
doneSignal.await(); // 等待所有线程执行完毕
}
}
class Worker implements Runnable {
private final CountDownLatch startSignal;
private final CountDownLatch doneSignal;
Worker(CountDownLatch startSignal, CountDownLatch doneSignal) {
this.startSignal = startSignal;
this.doneSignal = doneSignal;
}
public void run() {
try {
startSignal.await();
doWork();
doneSignal.countDown();
} catch (InterruptedException ex) {
} // return;
}
void doWork() { ...}
}
这种模式巧妙的使用了双CountDownLatch实例精准控制线程的开始运行时间,并在开始执行前、执行中间、执行之后插入一些自定义的方法执行。实际上使用了CountDownLatch的两种使用模式:
模式一:N次countDown方法调用,一次await方法调用
:这种模式用于等待所有线程执行完毕之后再执行await方法之后的代码
模式二:N次await方法调用,一次countDown方法调用
:这种模式用于需要在所有线程开始执行前插入一些自定义操作。
本篇文章一直围绕模式一分析,模式二一直没有提及,因为模式二用的实在太少,在实际开发中没见到过。。。
现在将模式二的核心代码提炼出来,看看到底它做了什么事情:
import lombok.extern.slf4j.Slf4j;
import java.util.concurrent.CountDownLatch;
@Slf4j
public class Driver {
public static void main(String[] args) throws InterruptedException {
CountDownLatch startSignal = new CountDownLatch(1);
for (int i = 0; i < 10; ++i) {
new Thread(new Worker(startSignal)).start();
}
log.info("在所有线程执行前先执行一些任务");
startSignal.countDown();
}
}
@Slf4j
class Worker implements Runnable {
private final CountDownLatch startSignal;
Worker(CountDownLatch startSignal) {
this.startSignal = startSignal;
}
@Override
public void run() {
try {
startSignal.await();
doWork();
} catch (InterruptedException ex) {
log.error("", ex);
}
}
void doWork() {
log.info("正在执行任务。。。");
}
}
我们分析下这个过程,由于10个线程运行时上来就调用了await方法,所以它们会在AQS队列中排队,其数据结构如下所示
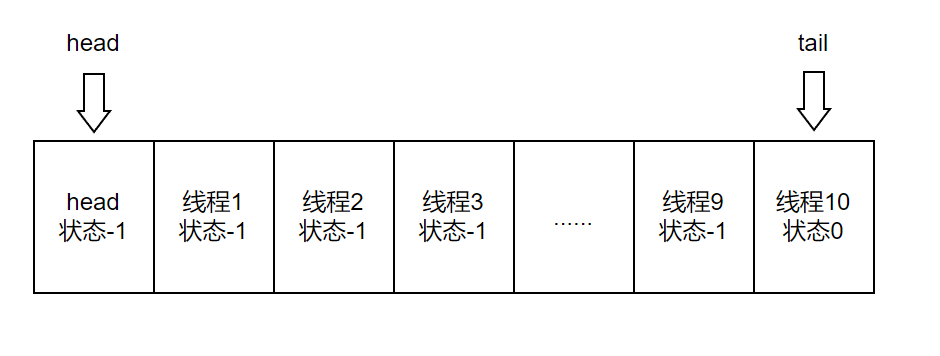
此时AQS队列中有11个节点,第一个头部节点是队列初始化的时候创建的虚拟节点,剩余十个节点,前9个节点状态都是SIGNAL(-1),因为它们在抢锁失败后会调用shouldParkAfterFailedAcquire方法,该方法会将当前节点的前置节点修改成SIGNAL(-1),最后一个节点入队后默认状态是0,由于没有后续节点入队了,所以其状态没有变成-1,而是0。
接下来主线程调用了countDown方法,由于计数器的初始值是1,所以CountDownLatch方法一次调用就会触发唤醒后继结点。接着,head节点后的节点将会在
parkAndCheckInterrupt
方法处继续执行后续代码:
private void doAcquireSharedInterruptibly(int arg)
throws InterruptedException {
//将节点标记为共享类型,并加入AQS同步队列。
final Node node = addWaiter(Node.SHARED);
boolean failed = true;
try {
for (;;) {
//获取节点的前置节点
final Node p = node.predecessor();
//判断是否是头结点,是头结点就表示自己可以尝试获取锁了。
if (p == head) {
//尝试获取共享锁,实际上是检查了state参数是否为0
int r = tryAcquireShared(arg);
//r>=0的条件只有一个,那就是r为1,表示state值已经变成了0
if (r >= 0) {
//执行获取锁成功的流程。
setHeadAndPropagate(node, r);
p.next = null; // help GC
failed = false;
return;
}
}
//检查是否应该在失败后挂起。
if (shouldParkAfterFailedAcquire(p, node) &&
//挂起线程
parkAndCheckInterrupt())
//如果发生了中断,就抛出IE异常。
throw new InterruptedException();
}
} finally {
if (failed)
cancelAcquire(node);
}
}
在该方法中,会执行
setHeadAndPropagate
方法:
private void setHeadAndPropagate(Node node, int propagate) {
Node h = head;
setHead(node);
//propagate值为1,满足if条件
if (propagate > 0 || h == null || h.waitStatus < 0 ||
(h = head) == null || h.waitStatus < 0) {
Node s = node.next;
//此时AQS队列中有很多节点,节点类型都是SHARED类型,所以依然满足if条件
if (s == null || s.isShared())
//执行锁释放,并唤醒后续节点
doReleaseShared();
}
}
接着执行doReleaseShared方法:在N次countDown,一次await模式中,该方法在await方法中的调用什么都没做就结束了循环;在N次await调用,一次countDown调用的模式中,await方法调用将唤醒后继节点
private void doReleaseShared() {
for (;;) {
//head节点已经变成当前执行线程节点
Node h = head;
//满足if条件
if (h != null && h != tail) {
//当前节点状态是SIGNAL
int ws = h.waitStatus;
//满足if条件
if (ws == Node.SIGNAL) {
//唤醒后继结点前,先将头部节点状态更改为初始状态0
if (!compareAndSetWaitStatus(h, Node.SIGNAL, 0))
continue; // loop to recheck cases
//唤醒后继结点
unparkSuccessor(h);
}
else if (ws == 0 &&
!compareAndSetWaitStatus(h, 0, Node.PROPAGATE))
continue; // loop on failed CAS
}
if (h == head) // loop if head changed
break;
}
}
可以看到,AQS队列中的节点一个一个唤醒后继结点,然后去做自己的事情,直到最后一个节点;最后一个节点由于不满足
h != tail
的条件,会什么都不做就结束循环。
最后考虑一个问题,如果countDown方法先被执行了,那await方法执行的时候会怎样?
答案是什么事情都不会发生,因为await方法执行前需要先判断计数器的值,如果等于0,就不会有后续的获取锁、释放锁流程了。
public final void acquireSharedInterruptibly(int arg)
throws InterruptedException {
if (Thread.interrupted())
throw new InterruptedException();
//countDown计数器为0的时候不满足该if条件。
if (tryAcquireShared(arg) < 0)
doAcquireSharedInterruptibly(arg);
}
总结一下,ReentrantLock中lock方法和unlock方法中间是临界区代码,临界区代码是抢锁线程依次轮流进入执行的,所以ReetrantLock是“独占锁”;而在CountDownLatchd的“N次await方法调用,一次countDown方法调用”的模式中,中,所有线程排队进入AQS队列之后,一旦被唤醒,被唤醒的节点还会自动唤醒后边节点,然后各自做各自的事情,所有线程都是并行运行的,所以CountDownLatch是“共享锁”。
最后的最后,欢迎关注我的个人博客呀:
https://blog.kdyzm.cn
END.