Dubbo 路由及负载均衡性能优化
作者:vivo 互联网中间件团队- Wang Xiaochuang
本文主要介绍在vivo内部针对Dubbo路由模块及负载均衡的一些优化手段,主要是异步化+缓存,可减少在RPC调用过程中路由及负载均衡的CPU消耗,极大提升调用效率。
一、概要
vivo内部Java技术栈业务使用的是Apache Dubbo框架,基于开源社区2.7.x版本定制化开发。在海量微服务集群的业务实践中,我们发现Dubbo有一些性能瓶颈的问题会极大影响业务逻辑的执行效率,尤其是在集群规模数量较大时(提供方数量>100)时,路由及负载均衡方面有着较大的CPU消耗,从采集的火焰图分析高达30%。为此我们针对vivo内部常用路由策略及负载均衡进行相关优化,并取得了较好的效果。接下来主要跟大家分析一下相关问题产生的根源,以及我们采用怎样的方式来解决这些问题。当前vivo内部使用的Dubbo的主流版本是基于2.7.x进行相关定制化开发。
二、背景知识
2.1 Dubbo客户端调用流程
1. 相关术语介绍

2. 主要流程
客户端通过本地代理Proxy调用ClusterInvoker,ClusterInvoker从服务目录Directory获取服务列表后经过路由链获取新的服务列表、负载均衡从路由后的服务列表中根据不同的负载均衡策略选取一个远端Invoker后再发起远程RPC调用。
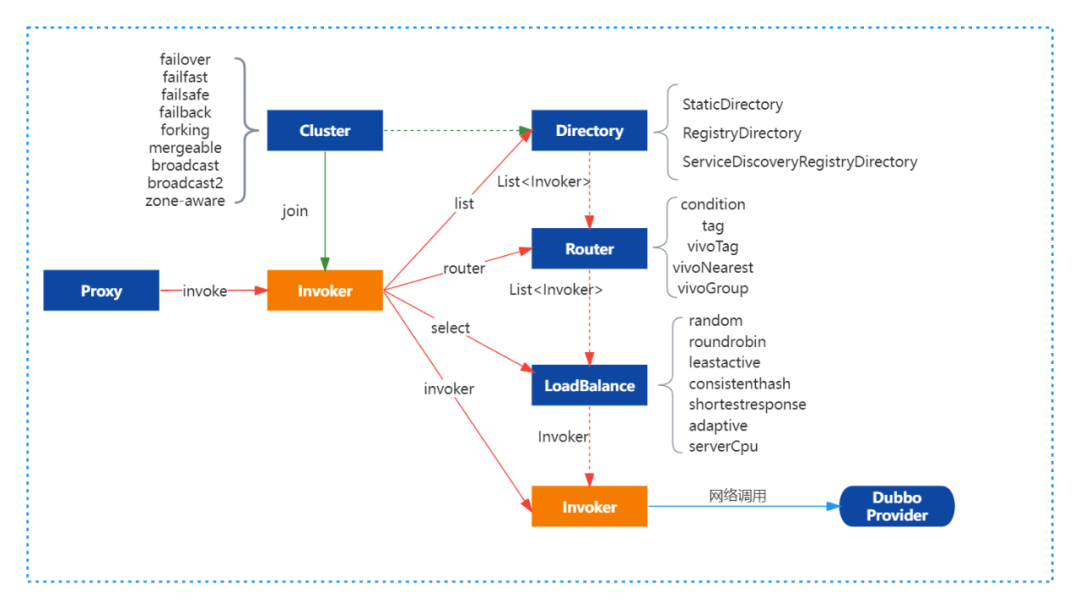
2.2 Dubbo路由机制
Dubbo的路由机制实际是基于简单的责任链模式实现,同时Router继承了Comparable接口,自定义的路由可以设置不同的优先级进而定制化责任链上Router的顺序。基于责任链模式可以支持多种路由策略串行执行如就近路由+标签路由,或条件路由+就近路由等,且路由的配置支持基于接口级的配置也支持基于应用级的配置。常见的路由方式主要有:就近路由,条件路由,标签路由等。具体的执行过程如下图所示:
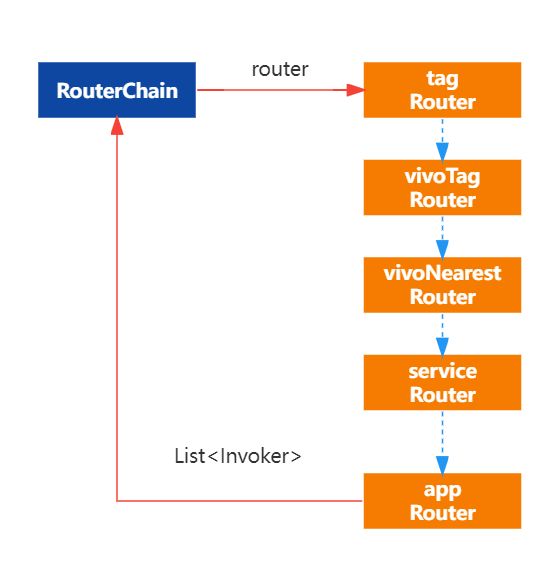
1. 核心类
Dubbo路由的核心类主要有:
RouterChain、RouterFactory 与 Router 。
(1)RouterChain
RouterChain是路由链的入口,其核心字段有
invokers(List<invoker> 类型)
初始服务列表由服务目录Directory设置,当前RouterChain要过滤的Invoker集合
builtinRouters(List类型)
当前RouterChain包含的自动激活的Router集合
routers(List类型)
包括所有要使用的路由由builtinRouters加上通过addRouters()方法添加的Router对象
RouterChain核心逻辑:
public class RouterChain<T> {
// 注册中心最后一次推送的服务列表
private List<Invoker<T>> invokers = Collections.emptyList();
// 所有路由,包括原生Dubbo基于注册中心的路由规则如“route://” urls .
private volatile List<Router> routers = Collections.emptyList();
// 初始化自动激活的路由
private List<Router> builtinRouters = Collections.emptyList();
private RouterChain(URL url) {
//通过ExtensionLoader加载可自动激活的RouterFactory
List<RouterFactory> extensionFactories = ExtensionLoader.getExtensionLoader(RouterFactory.class)
.getActivateExtension(url, ROUTER_KEY);
// 由工厂类生成自动激活的路由策略
List<Router> routers = extensionFactories.stream()
.map(factory -> factory.getRouter(url))
.collect(Collectors.toList());
initWithRouters(routers);
}
// 添加额外路由
public void addRouters(List<Router> routers) {
List<Router> newRouters = new ArrayList<>();
newRouters.addAll(builtinRouters);
newRouters.addAll(routers);
Collections.sort(newRouters, comparator);
this.routers = newRouters;
}
public List<Invoker<T>> route(URL url, Invocation invocation) {
List<Invoker<T>> finalInvokers = invokers;
// 遍历全部的Router对象,执行路由规则
for (Router router : routers) {
finalInvokers = router.route(finalInvokers, url, invocation);
}
return finalInvokers;
}
}(2)RouterFactory为Router的工厂类
RouterFactory接口定义:
@SPI
public interface RouterFactory {
@Adaptive("protocol")
Router getRouter(URL url);
}(3)Router
Router是真正的路由实现策略,由RouterChain进行调用,同时Router继承了Compareable接口,可以根据业务逻辑设置不同的优先级。
Router主要接口定义:
public interface Router extends Comparable<Router> {
/**
*
* @param invokers 带过滤实例列表
* @param url 消费方url
* @param invocation 会话信息
* @return routed invokers
* @throws RpcException
*/
<T> List<Invoker<T>> route(List<Invoker<T>> invokers, URL url, Invocation invocation) throws RpcException;
/**
* 当注册中心的服务列表发现变化,或有动态配置变更会触发实例信息的变化
* 当时2.7.x的Dubbo并没有真正使用这个方法,可基于此方法进行路由缓存
* @param invokers invoker list
* @param <T> invoker's type
*/
default <T> void notify(List<Invoker<T>> invokers) {
}
}2. 同机房优先路由的实现
为方便大家了解路由的实现,给大家展示一下就近路由的核心代码逻辑:
public <T> List<Invoker<T>> route(List<Invoker<T>> invokers, URL consumerUrl, Invocation invocation) throws RpcException {
if (!this.enabled) {
return invokers;
}
// 获取本地机房信息
String local = getSystemProperty(LOC);
if (invokers == null || invokers.size() == 0) {
return invokers;
}
List<Invoker<T>> result = new ArrayList<Invoker<T>>();
for (Invoker invoker: invokers) {
// 获取与本地机房一致的invoker并加入列表中
String invokerLoc = getProperty(invoker, invocation, LOC);
if (local.equals(invokerLoc)) {
result.add(invoker);
}
}
if (result.size() > 0) {
if (fallback){
// 开启服务降级,available.ratio = 当前机房可用服务节点数量 / 集群可用服务节点数量
int curAvailableRatio = (int) Math.floor(result.size() * 100.0d / invokers.size());
if (curAvailableRatio <= availableRatio) {
return invokers;
}
}
return result;
} else if (force) {
return result;
} else {
return invokers;
}
}2.3 Dubbo负载均衡
Dubbo的负载均衡实现比较简单基本都是继承抽象类进行实现,主要作用就是根据具体的策略在路由之后的服务列表中筛选一个实例进行远程RPC调用,默认的负载均衡策略是随机。
整体类图如下所示:
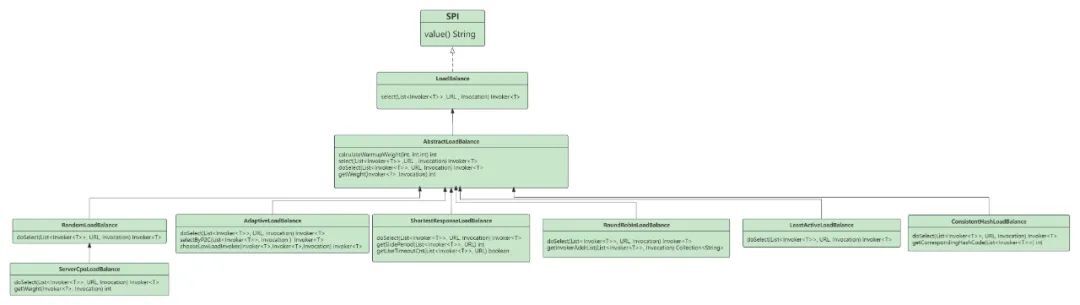
LoadBalance接口定义:
@SPI(RandomLoadBalance.NAME)
public interface LoadBalance {
/**
* 从服务列表中筛选一个.
*
* @param invokers invokers.
* @param url refer url
* @param invocation invocation.
* @return selected invoker.
*/
@Adaptive("loadbalance")
<T> Invoker<T> select(List<Invoker<T>> invokers, URL url, Invocation invocation) throws RpcException;
}随机负载均衡核心代码解析:
// 预热过程权重计算
static int calculateWarmupWeight(int uptime, int warmup, int weight) {
int ww = (int) (uptime / ((float) warmup / weight));
return ww < 1 ? 1 : (Math.min(ww, weight));
}
int getWeight(Invoker<?> invoker, Invocation invocation) {
int weight;
URL url = invoker.getUrl();
// 多注册中心场景下的,注册中心权重获取
if (UrlUtils.isRegistryService(url)) {
weight = url.getParameter(REGISTRY_KEY + "." + WEIGHT_KEY, DEFAULT_WEIGHT);
} else {
weight = url.getMethodParameter(invocation.getMethodName(), WEIGHT_KEY, DEFAULT_WEIGHT);
if (weight > 0) {
// 获取实例启动时间
long timestamp = invoker.getUrl().getParameter(TIMESTAMP_KEY, 0L);
if (timestamp > 0L) {
long uptime = System.currentTimeMillis() - timestamp;
if (uptime < 0) {
return 1;
}
// 获取预热时间
int warmup = invoker.getUrl().getParameter(WARMUP_KEY, DEFAULT_WARMUP);
if (uptime > 0 && uptime < warmup) {
weight = calculateWarmupWeight((int)uptime, warmup, weight);
}
}
}
}
return Math.max(weight, 0);
}
@Override
protected <T> Invoker<T> doSelect(List<Invoker<T>> invokers, URL url, Invocation invocation) {
// Number of invokers
int length = invokers.size();
// Every invoker has the same weight?
boolean sameWeight = true;
// the weight of every invokers
int[] weights = new int[length];
// the first invoker's weight
int firstWeight = getWeight(invokers.get(0), invocation);
weights[0] = firstWeight;
// The sum of weights
int totalWeight = firstWeight;
for (int i = 1; i < length; i++) {
int weight = getWeight(invokers.get(i), invocation);
// save for later use
weights[i] = weight;
// Sum
totalWeight += weight;
if (sameWeight && weight != firstWeight) {
sameWeight = false;
}
}
if (totalWeight > 0 && !sameWeight) {
// If (not every invoker has the same weight & at least one invoker's weight>0), select randomly based on totalWeight.
int offset = ThreadLocalRandom.current().nextInt(totalWeight);
// Return a invoker based on the random value.
for (int i = 0; i < length; i++) {
offset -= weights[i];
if (offset < 0) {
return invokers.get(i);
}
}
}
// If all invokers have the same weight value or totalWeight=0, return evenly.
return invokers.get(ThreadLocalRandom.current().nextInt(length));
}预热解释
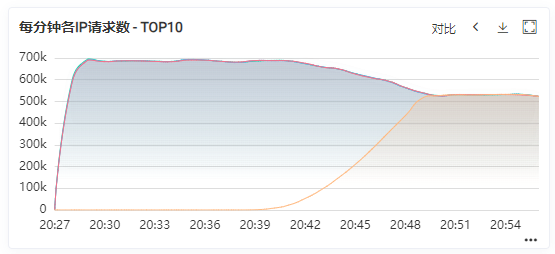
预热是为了让刚启动的实例流量缓慢增加,因为实例刚启动时各种资源可能还没建立连接,相关代码可能还是处于解释执行,仍未变为JIT执行,此时业务逻辑较慢,不应该加载过大的流量,否则有可能造成较多的超时。Dubbo默认预热时间为10分钟,新部署的实例的流量会在预热时间段内层线性增长,最终与其他实例保持一致。Dubbo预热机制的实现就是通过控制权重来实现。如默认权重100,预热时间10分钟,则第一分钟权重为10,第二分钟为20,以此类推。
具体预热效果图如下:
三、问题分析
使用Dubbo的业务方反馈,他们通过火焰图分析发现Dubbo的负载均衡模块+路由模块占用CPU超过了30%,框架层面的使用率严重影响了业务逻辑的执行效率急需进行优化。通过火焰图分析,具体占比如下图,其中该机器在业务忙时的CPU使用率在60%左右,闲时在30%左右。
通过火焰图分析,负载均衡主要的消耗是在 getWeight方法。

路由的主要消耗是在route方法:
同机房优先路由

- 接口级标签路由+应用级标签路由

这些方法都有一个特点,那就是遍历执行。如负载均衡,针对每一个invoker都需要通过getWeight方法进行权重的计算;就近路由的router方法对于每一个invoker都需要通过url获取及机房信息进行匹配计算。
我们分析一下getWeight及router时间复杂度,发现是O(n)的时间复杂度,而且路由是由路由链组成的,每次每个 Router的route方法调用逻辑都会遍历实例列表,那么当实例列表数量过大时,每次匹配的计算的逻辑过大,那么就会造成大量的计算成本,导致占用大量cpu,同时也导致路由负载均衡效率低下。
综上所述,罪恶的的根源就是遍历导致的,当服务提供方数量越多,影响越大。
四、优化方案
知道了问题所在,我们来分析一下是否有优化空间。
4.1 路由优化
1. 优化一:关闭无效路由
通过火焰图分析,我们发现有部分业务即使完全不使用应用级的标签路由,原生的TagRouter也存在遍历逻辑,原因是为了支持静态的标签路由,其实这部分的开销也不少,那对于根本不会使用应用级标签路由的可以手动进行关闭。关闭方式如下:
客户端统一关闭
dubbo.consumer.router=-tag服务级别关闭
注解方式:
@DubboReference(parameters = {"router","-tag"})xml方式:
<dubbo:reference id="demoService" check="false" interface="com.dubbo.study.n.api.DemoService" router="-tag" />2. 优化二:提前计算路由结果并进行缓存
每次路由目前都是进行实时计算,但是在大多数情况下,我们的实例列表是稳定不变的,只有在发布窗口或配置变更窗口内实例列表才会发生变更,那我们是否可以考虑缓存呢。如就近路由,可以以机房为key进行机房实例的全量缓存。针对接口级标签路由可以缓存不同标签值指定的实例信息。
我们知道路由的执行过程是责任链模式,每一个Router的实例列表入参实际上是一个Router的结果,可参考公式:target = rn(…r3(r2(r1(src))))。那么所有的路由可以基于注册中心推送的原始服务列表进行路由计算并缓存,然后不同的路由结果相互取交集就能得到最终的结果,当实例信息发生变更时,缓存失效并重新计算。
3. 缓存更新时机
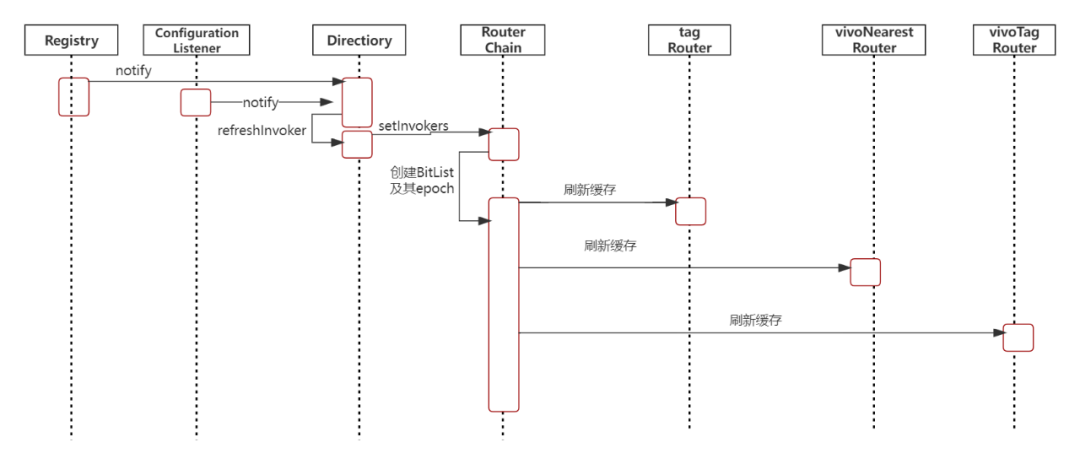
当注册中心或者动态配置有变更时,相关通知会给到服务目录Directory,Directory收到通知后会重新创建服务列表,并把服务列表同步到路由链RouterChain,RouterChain再按顺序通知其链上的Router,各个Router再进行缓存清除并重新进行路由结果的计算及进行缓存。相关时序图如下所示:
4. 具体路由流程
进入具体路由方法时,先判断是否存在缓存的路由值,且缓存值的epoch必须与上一个路由的epoch需一致,此时缓存才生效,然后缓存值与上个Router的结果取交集。
如果不存在缓存或epoch不一致则重新进行实时的路由计算。
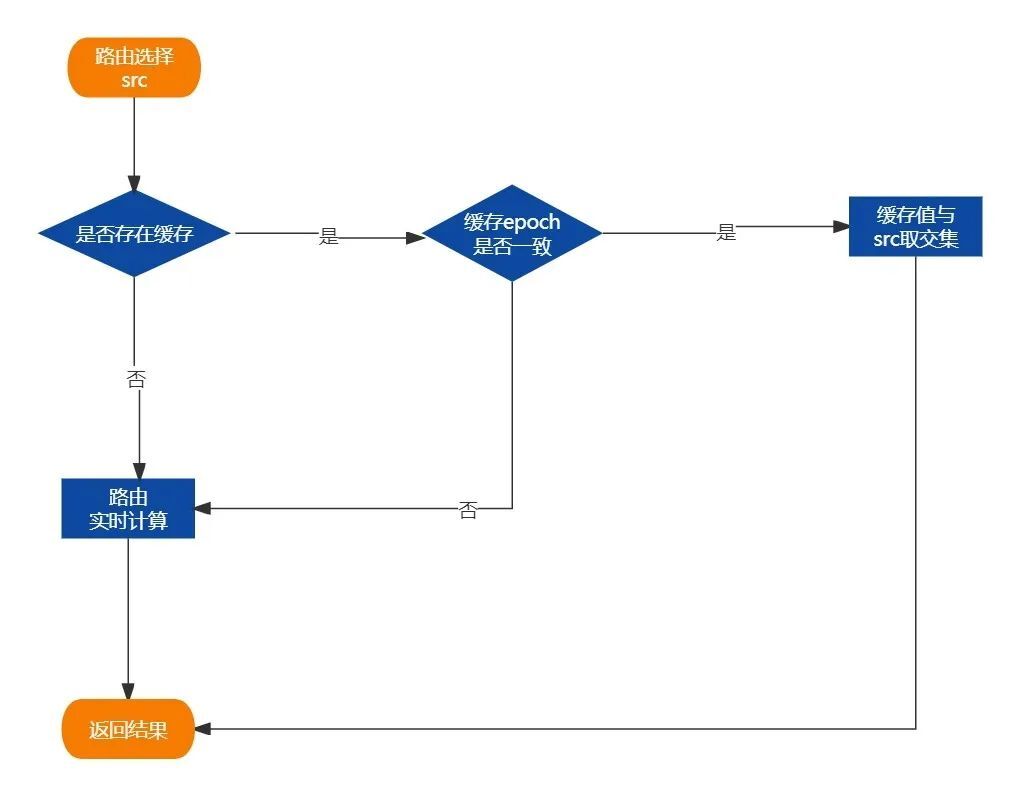
引入epoch的原因主要是保证各个路由策略缓存信息的一致性,保证所有的缓存计算都是基于同一份原始数据。当实例信息发生变更时,epoch会自动进行更新。
5. BitMap引入
上文我们说到,不同的路由策略之间的结果是取交集的,然后最终的结果才送入负载均衡流程。那如何在缓存的同时,加快交集的计算呢。答案就是基于位图:BitMap。
BitMap的基本原理就是用一个bit位来存放某种状态,适用于大规模数据的查找及位运算操作。如在路由场景,先基于全量的推送数据进行计算缓存。如果某个实例被路由选中,则其值为1,若两个路由的结果要取交集,那直接对BitMap进行"&"运行即可。
全量缓存示意图:
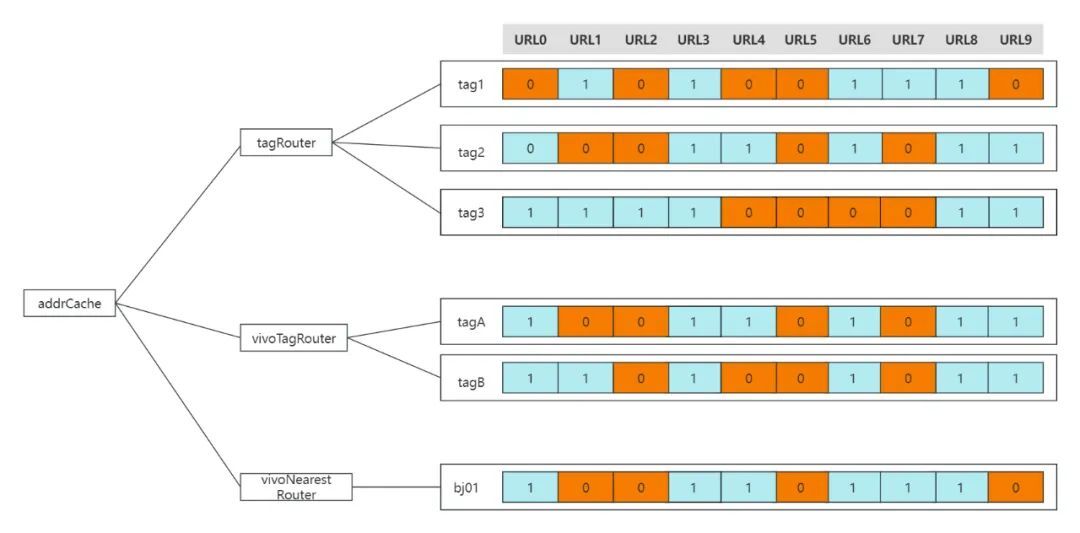
路由交集计算示步骤:
按照路由链依次计算,tagRouter->vivoTag->vivoNearestRouter
(1)tagRouter计算逻辑:
按照Invocation计算出目标的Tag,假设是tag1
然后从缓存Cache根据key:tag1,取出对应的targetAddrPool
将原始传入的addrPool与targetAddrPool,得到结果resultAddrPool
将resultAddrPool传入vivoTagRouter
(2)vivoTag计算逻辑:
按照Invocation计算出目标的Tag,假设是tabB
然后从缓存Cache根据key:tag1,取出对应的targetAddrPool
将上一次传入的addrPool与targetAddrPool,得到结果resultAddrPooll
将resultAddrPool传入vivoNearestRouter
(3)vivoNearestRouter计算逻辑
从环境变量取出当前机房,假设是bj01
然后从缓存Cache根据key:bj01,取出对应的targetAddrPool
将上一次传入的addrPool与targetAddrPool,取出resultAddrPool
将上一次传入的addrPool与targetAddrPool,得到结果resultAddrPool
将resultAddrPool为最终路由结果,传递给LoadBalance
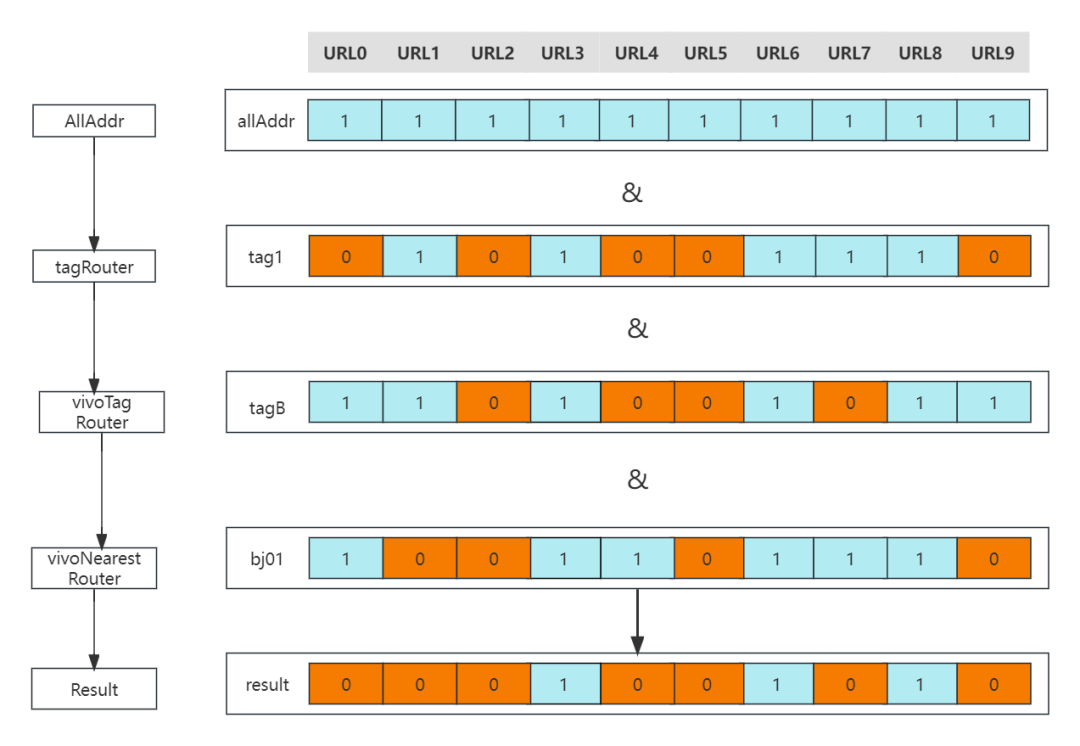
6. 基于缓存的同机房优先路由源码解析
缓存刷新:
/**
* Notify router chain of the initial addresses from registry at the first time.
* Notify whenever addresses in registry change.
*/
public void setInvokers(List<Invoker<T>> invokers) {
// 创建带epoch的BitList
this.invokers = new BitList<Invoker<T>>(invokers == null ? Collections.emptyList() : invokers,createBitListEpoch());
routers.forEach(router -> router.notify(this.invokers));
}同机房优先路由源码解读:
public <T> List<Invoker<T>> route(List<Invoker<T>> invokers, URL consumerUrl, Invocation invocation) throws RpcException {
…………//省略非核心代码
BitList<Invoker<T>> bitList = (BitList<Invoker<T>>) invokers;
//获取路由结果
BitList<Invoker<T>> result = getNearestInvokersWithCache(bitList);
if (result.size() > 0) {
if (fallback) {
// 开启服务降级,available.ratio = 当前机房可用服务节点数量 / 集群可用服务节点数量
int curAvailableRatio = (int) Math.floor(result.size() * 100.0d / invokers.size());
if (curAvailableRatio <= availableRatio) {
return invokers;
}
}
return result;
} else if (force) {
return result;
} else {
return invokers;
}
}
/**
* 获取缓存列表
* @param invokers
* @param <T>
* @return
*/
private <T> BitList<Invoker<T>> getNearestInvokersWithCache(BitList<Invoker<T>> invokers) {
ValueWrapper valueWrapper = getCache(getSystemProperty(LOC));
// 是否存在缓存
if (valueWrapper != null) {
BitList<Invoker<T>> invokerBitList = (BitList<Invoker<T>>) valueWrapper.get();
// 缓存的epoch与源列表是否一致
if (invokers.isSameEpoch(invokerBitList)) {
BitList<Invoker<T>> tmp = invokers.clone();
// 结果取交集
return tmp.and(invokerBitList);
}
}
// 缓存不存在 实时计算放回
return getNearestInvokers(invokers);
}
/**
* 新服务列表通知
* @param invokers
* @param <T>
*/
@Override
public <T> void notify(List<Invoker<T>> invokers) {
clear();
if (invokers != null && invokers instanceof BitList) {
BitList<Invoker<T>> bitList = (BitList<Invoker<T>>) invokers;
// 设置最后一次更新的服务列表
lastNotify = bitList.clone();
if (!CollectionUtils.isEmpty(invokers) && this.enabled) {
// 获取机房相同的服务列表并进行缓存
setCache(getSystemProperty(LOC), getNearestInvokers(lastNotify));
}
}
}4.2 负载均衡优化
1. 优化一
针对getWeight方法,我们发现有部分业务逻辑较为消耗cpu,但是在大多数场景下业务方并不会使用到,于是进行优化。
getWeight方法优化:
优化前:
//这里主要要用多注册中心场景下,注册中心权重的获取,绝大多数情况下并不会有这个逻辑
if (UrlUtils.isRegistryService(url)) {
weight = url.getParameter(REGISTRY_KEY + "." + WEIGHT_KEY, DEFAULT_WEIGHT);
}
优化后:
if (invoker instanceof ClusterInvoker && UrlUtils.isRegistryService(url)) {
weight = url.getParameter(REGISTRY_KEY + "." + WEIGHT_KEY, DEFAULT_WEIGHT);
}2. 优化二
遍历是罪恶的源泉,而实例的数量决定这罪恶的深浅,我们有什么办法减少负载均衡过程中的遍历呢。一是根据group及version划分不同的集群,但是这需要涉及到业务方代码或配置层面的改动,会带来额外的成本。所以我们放弃了。
二是没有什么是加一层解决不了的问题,为了尽量减少进入负载均衡的节点数量,考虑新增一个垫底的路由策略,在走完所有的路由策略后,若节点数量>自定义数量后,进行虚拟分组,虚拟分组的策略也可进行自定义,然后随机筛选一组进入负载均衡。此时进入负载均衡的实例数量就会有倍数的下降。
需要注意的是分组路由必须保证是在路由链的最后一环,否则会导致其他路由计算错误。
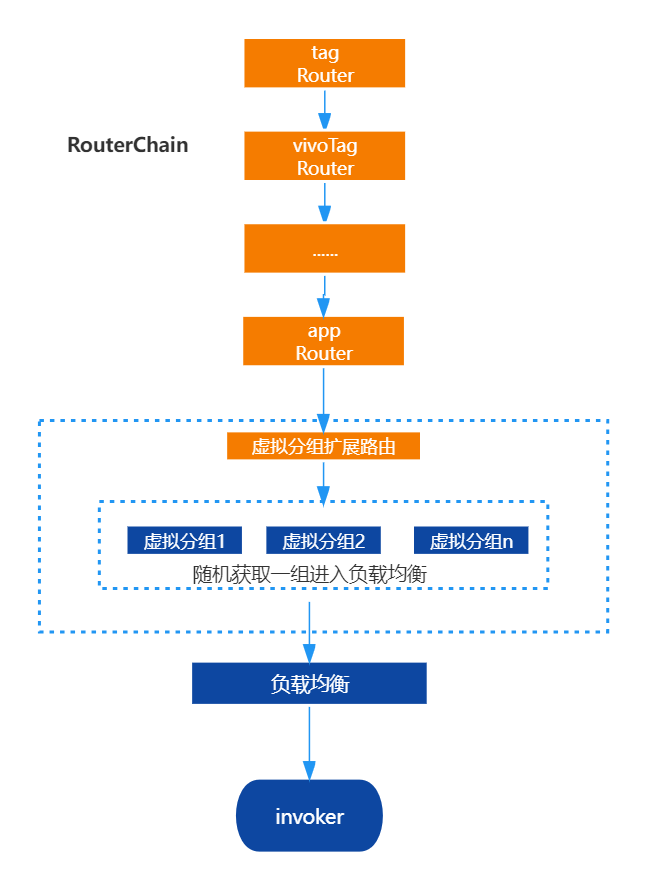
分组路由示意:
/**
*
* @param invokers 待分组实例列表
* @param groupNum 分组数量
* @param <T>
* @return
*/
public <T> List<Invoker<T>> doGroup(List<Invoker<T>> invokers, int groupNum) {
int listLength = invokers.size() / groupNum;
List<Invoker<T>> result = new ArrayList<>(listLength);
int random = ThreadLocalRandom.current().nextInt(groupNum);
for (int i = random; i < invokers.size(); i = i + groupNum) {
result.add(invokers.get(i));
}
return result;
}五、优化效果
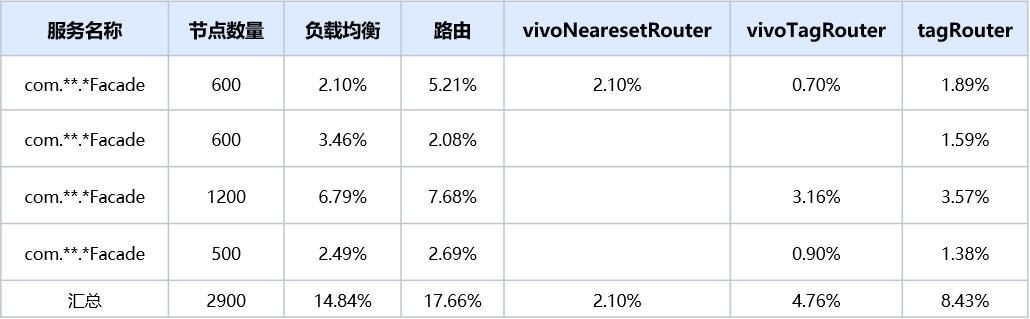
针对优化前和优化后,我们编写Demo工程分别压测了不配置路由/配置就近+标签路由场景。Provider节点梯度设置100/500/1000/2000/5000,TPS在1000左右,记录了主机的cpu等性能指标,并打印火焰图。发现,配置路由后,采用相同并发,优化后的版本tps明显高于优化前版本,且新版本相较于没有配置路由时tps显著提高,下游节点数大于2000时,tps提升达到100%以上,下游节点数越多,AvgCpu优化效果越明显,并且路由及负载均衡CPU占比明显更低,详细数据可见下表:
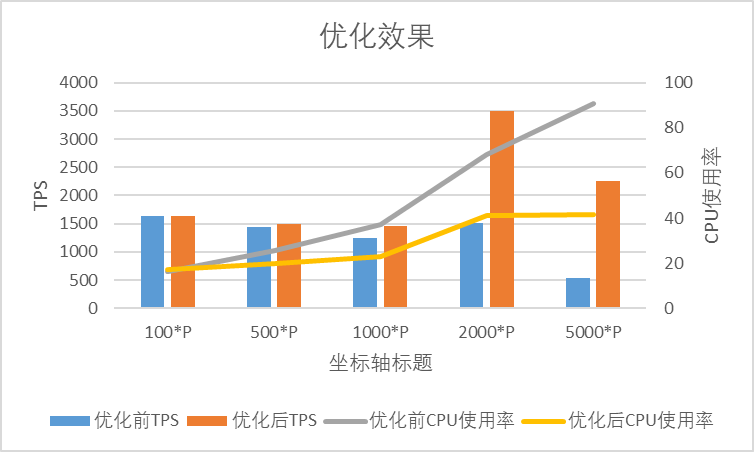
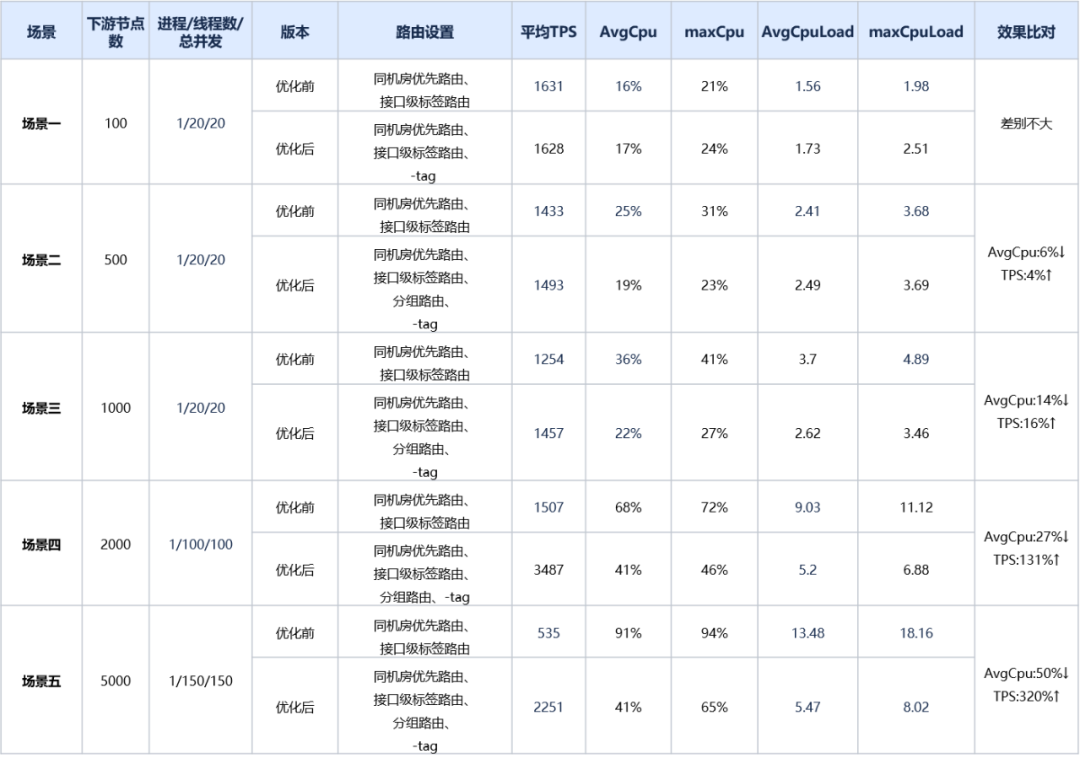
备注:-tag,表示显示禁用原生Dubbo应用级标签路由。该路由默认开启。
六、总结
经过我们关闭不必要的路由逻辑、对路由缓存+异步化计算、新增分组路由等优化后,Dubbo在负载均衡及路由模块整体的性能有了显著的提升,为业务方节省了不少CPU资源。在正常业务场景下当提供方数量达到2000及以上时,tps提升可达100%以上,消费方平均CPU使用率下降约27%,且提供方数量越多优化效果越明显。但是我们也发现当前的随机负载均衡依然还是会消耗一定的CPU资源,且只能保证流量是均衡的。当前我们的应用基本部署在虚拟机及容器上。这两者均存在超卖的状况,且同等配置的宿主机性能存在较大差异等问题。最终会导致部分请求超时、无法最大化利用提供方的资源。我们下一步将会引入Dubbo 3.2的自适应负载均衡并进行调优减少其CPU使用率波动较大的问题,其次我们自身也扩展了基于CPU负载均衡的单一因子算法,最终实现不同性能的机器CPU负载趋于均衡,最大程度发挥集群整体的性能。
参考资料: