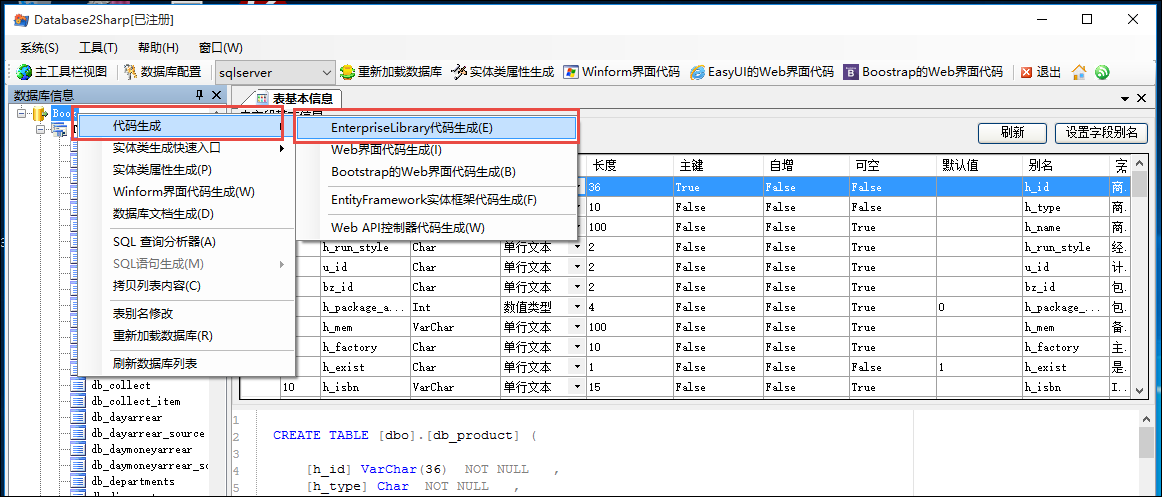
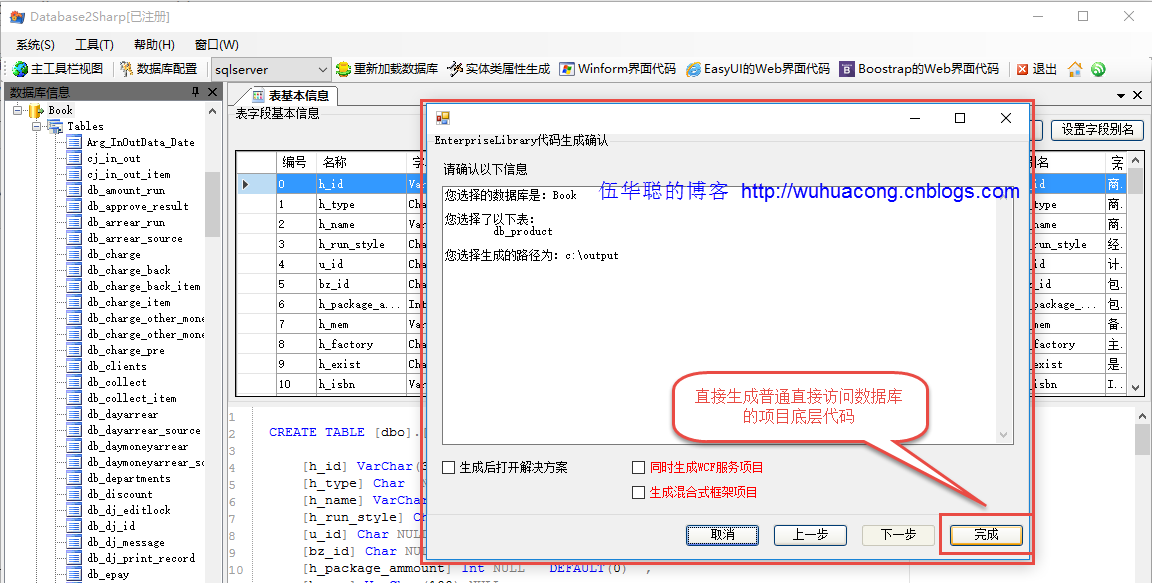
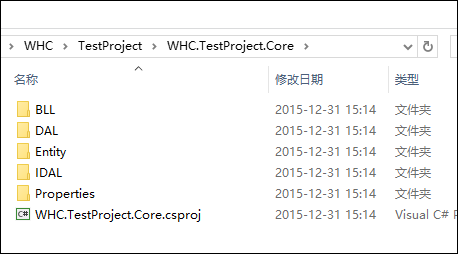
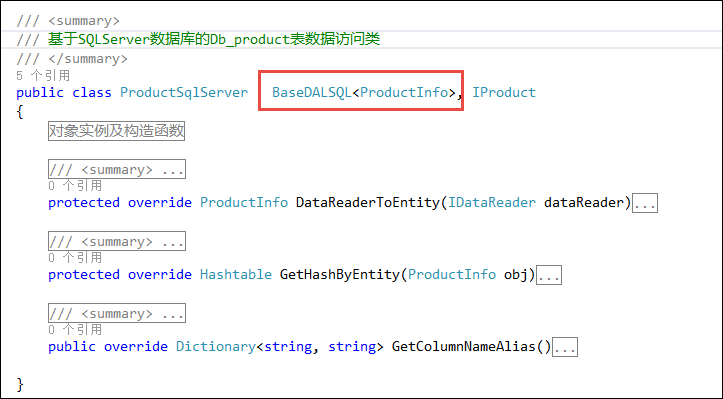
Winform开发主界面菜单的动态树形列表展示
我在之前很多文章里面,介绍过Winform主界面的开发,基本上都是标准的界面,在顶部放置工具栏,中间区域则放置多文档的内容,但是在顶部菜单比较多的时候,就需要把菜单分为几级处理,如可以在顶部菜单放置一二级菜单,这种方式在一般功能点不算太多的情况下,呈现的界面效果较为直观、也较为美观。不过随着一些系统功能的增多,这种方式可能就会显得工具栏比较拥挤,那么我们是否可以在左侧放置一个树形列表,这样通过树形列表的收缩折叠,就可以放置非常多的菜单功能了。
1、菜单的树形列表展示
一般情况下,树形列表的显示可以分为多个节点,节点可以收缩也可以展开,当然节点是有不同的图标的了。这样就可以把很多功能点整合在一个树列表里面了,树的节点也可以分为很多级别,很多层次
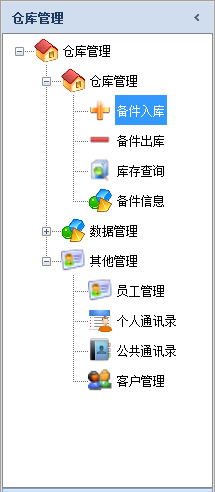
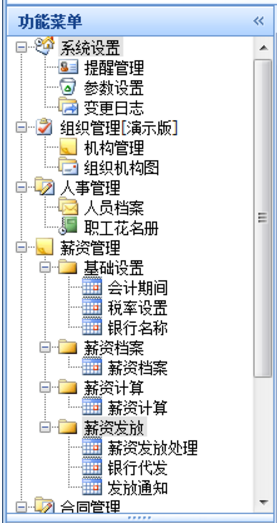
如果我们想按照业务的范畴来区分,也可以分为多个模块展示,类似选项卡的方式,一个模块的功能菜单列表集合在一起展示,如下所示。

上面这样的折叠展示,有利于业务范畴的区分,并且可以让树菜单菜单不会很大,是一种比较好的界面组织方式。
2、菜单的动态配置
管理
上面介绍了树形菜单的展示,以及如何组织菜单的内容,做好这些,就为我们奠定了界面菜单组织的雏形了。
那么问题来了,我们一般是需要根据系统创建很多菜单的,如果是能通过配置的方式,这样才能较好的管理这些菜单,而且可以动态给菜单指定权限,实现不同角色用户的权限控制。
那么我们就需要在系统里面引入一个菜单管理模块,实现菜单的配置管理功能,方便我们后面的动态创建菜单操作。
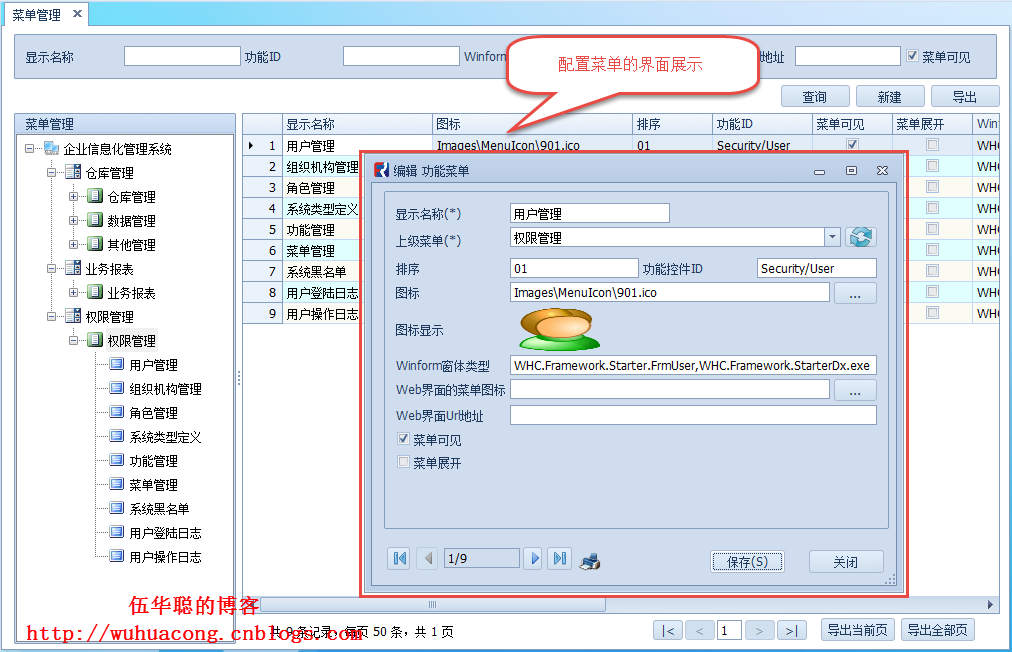
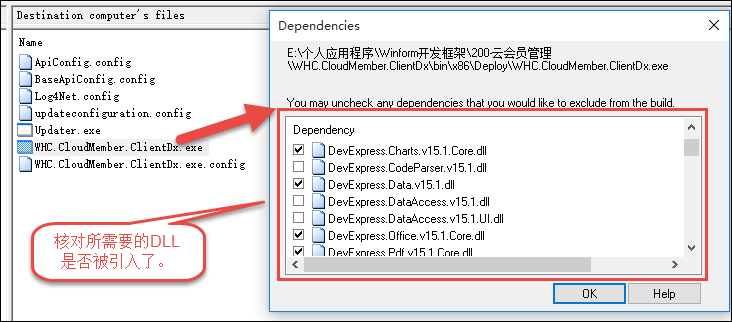
通过菜单的配置,我们可以指定菜单的图标,是否可见,是否展开,权限控制点,以及菜单触发点击后,处理的窗体对象等信息,有了这些基础信息,我们就很方便把菜单在树形列表里面进行合适、美观的展示了。
3、菜单动态构建的实现
前面介绍了,如何在数据库里面对菜单数据进行了存储,这样我们就可以在系统主界面里面,动态的构建属性列表进行菜单的展示操作了。
首先,我们需要在设计时刻对主界面的布局进行一定的设计,放置一些初始化的树形列表,方便查看效果。至于里面的内容,我们可以根据数据库的菜单配置,动态从数据库里面获取菜单信息,在左侧树形列表里面进行构建。

我们可以通过一个辅助类进行菜单的动态创建,如下所示。
private voidInitToolbar()
{
TreeMenuHelper helper= new TreeMenuHelper(this, this.nvBarMenu, this.imageList1);
helper.Init();
}
也就是辅助类,传入当前窗体,以及左侧的导航控件等参数后,我们在辅助类里面封装对应的动态构建菜单的逻辑处理。
首先我们动态创建的开始,先要清空原来控件展示的菜单内容,并重新从数据库里面获取,如下代码所示。
//清空所有导航控件的内容 barControl.Controls.Clear();
barControl.Groups.Clear();
barControl.Items.Clear();this.imageList.Images.Clear();//限定显示几个导航选项卡 barControl.NavigationPaneMaxVisibleGroups = 3;//约定菜单共有3级,第一级为大的类别,第二级为小模块分组,第三级为具体的菜单 List<MenuNodeInfo> menuList = BLLFactory<SysMenu>.Instance.GetTree(Portal.gc.SystemType);if (menuList.Count == 0) return;
然后我们会对菜单进行遍历,并判断是否具有对应的权限点,如果没有对应的权限,那么对应菜单的子菜单也不会进一步展示。
//递归遍历所有的菜单,进行分级展示 foreach (MenuNodeInfo firstInfo inmenuList)
{//如果没有菜单的权限,则跳过 if (!Portal.gc.HasFunction(firstInfo.FunctionId)) continue;
创建菜单的时候,我们注意到整个菜单项是动态构建的,因此我们需要根据NavBarControl的控件属性,动态构建对应的选项卡NavBarGroup、展示容器NavBarGroup、树形对象TreeView、树形节点TreeNode等内容,如下代码所示。
TreeView treeView = newTreeView();
treeView.Dock=DockStyle.Fill;
treeView.ImageList= this.imageList;
treeView.ItemHeight= 30;//设置高度,显示更美观 NavBarGroupControlContainer container= newNavBarGroupControlContainer();
container.Size= new System.Drawing.Size(213, 412);
container.Controls.Add(treeView);
barControl.Controls.Add(container);//加载图标 this.imageList.Images.Add(LoadIcon(firstInfo.Icon));int index = this.imageList.Images.Count - 1;//最后一个序号 NavBarGroup group= newNavBarGroup();
group.Caption=firstInfo.Name;
group.ControlContainer=container;
group.Expanded= true;
group.GroupClientHeight= 410;
group.GroupStyle=NavBarGroupStyle.ControlContainer;
group.LargeImageIndex=index;
group.SmallImageIndex=index;
barControl.Groups.Add(group);//创建一级列表 TreeNode pNode = newTreeNode();
pNode.Text=firstInfo.Name;
pNode.Tag=firstInfo.WinformType;
pNode.ImageIndex=index;
pNode.SelectedImageIndex=index;
treeView.Nodes.Add(pNode);//递归创建子列表 AddTreeItems(pNode, firstInfo.Children);
通过递归的方式,我们就很容易递归构建了所有层次的树形菜单,并进行合适的展示了。
菜单的单击事件,我们通过一个函数代码实现对它进行处理就可以了。
//处理树形菜单的点击操作,如果TAG存在,则解析并加载对应的页面到多文档里面 treeView.AfterSelect += (sender, e) =>{string tag = e.Node.Tag as string;if (!string.IsNullOrEmpty(tag))
{
LoadPlugInForm(tag);
}
};
这里面就是对它的AfterSelect 事件进行处理,实现我们动态加载窗体对象到多文档界面的处理了。
其中加载窗体是根据菜单配置的选项,动态构建界面出来的,具体分析代码如下所示。
/// <summary> ///加载插件窗体/// </summary> private void LoadPlugInForm(stringtypeName)
{try{string[] itemArray = typeName.Split(new char[] { ',', ';'});string type = itemArray[0].Trim();string filePath = itemArray[1].Trim();//必须是相对路径//判断是否配置了显示模式,默认窗体为Show非模式显示 string showDialog = (itemArray.Length > 2) ? itemArray[2].ToLower() : "";bool isShowDialog = (showDialog == "1") || (showDialog == "dialog");string dllFullPath =Path.Combine(Application.StartupPath, filePath);
Assembly tempAssembly=System.Reflection.Assembly.LoadFrom(dllFullPath);if (tempAssembly != null)
{
Type objType=tempAssembly.GetType(type);if (objType != null)
{
LoadMdiForm(this.mainForm, objType, isShowDialog);
}
}
}catch(Exception ex)
{
LogTextHelper.Error(string.Format("加载模块【{0}】失败,请检查书写是否正确。", typeName), ex);
}
}
加载多文档的操作,就是在集合里面判断是否存在,如果没有存在就创建,否则就激活显示即可,具体处理如下所示。
/// <summary> ///唯一加载某个类型的窗体,如果存在则显示,否则创建。/// </summary> /// <param name="mainDialog">主窗体对象</param> /// <param name="formType">待显示的窗体类型</param> /// <returns></returns> public Form LoadMdiForm(Form mainDialog, Type formType, boolisShowDialog)
{
Form tableForm= null;bool bFound = false;if (!isShowDialog) //如果是模态窗口,跳过 {foreach (Form form inmainDialog.MdiChildren)
{if (form.GetType() ==formType)
{
bFound= true;
tableForm=form;break;
}
}
}//没有在多文档中找到或者是模态窗口,需要初始化属性 if (!bFound ||isShowDialog)
{
tableForm=(Form)Activator.CreateInstance(formType);//如果窗体集成了IFunction接口(第一次创建需要设置) IFunction function = tableForm asIFunction;if (function != null)
{//初始化权限控制信息 function.InitFunction(Portal.gc.LoginUserInfo, Portal.gc.FunctionDict);//记录程序的相关信息 function.AppInfo = newAppInfo(Portal.gc.AppUnit, Portal.gc.AppName, Portal.gc.AppWholeName, Portal.gc.SystemType);
}
}if(isShowDialog)
{
tableForm.ShowDialog();
}else{
tableForm.MdiParent=mainDialog;
tableForm.Show();
}
tableForm.BringToFront();
tableForm.Activate();returntableForm;
}
4、系统界面的总体效果
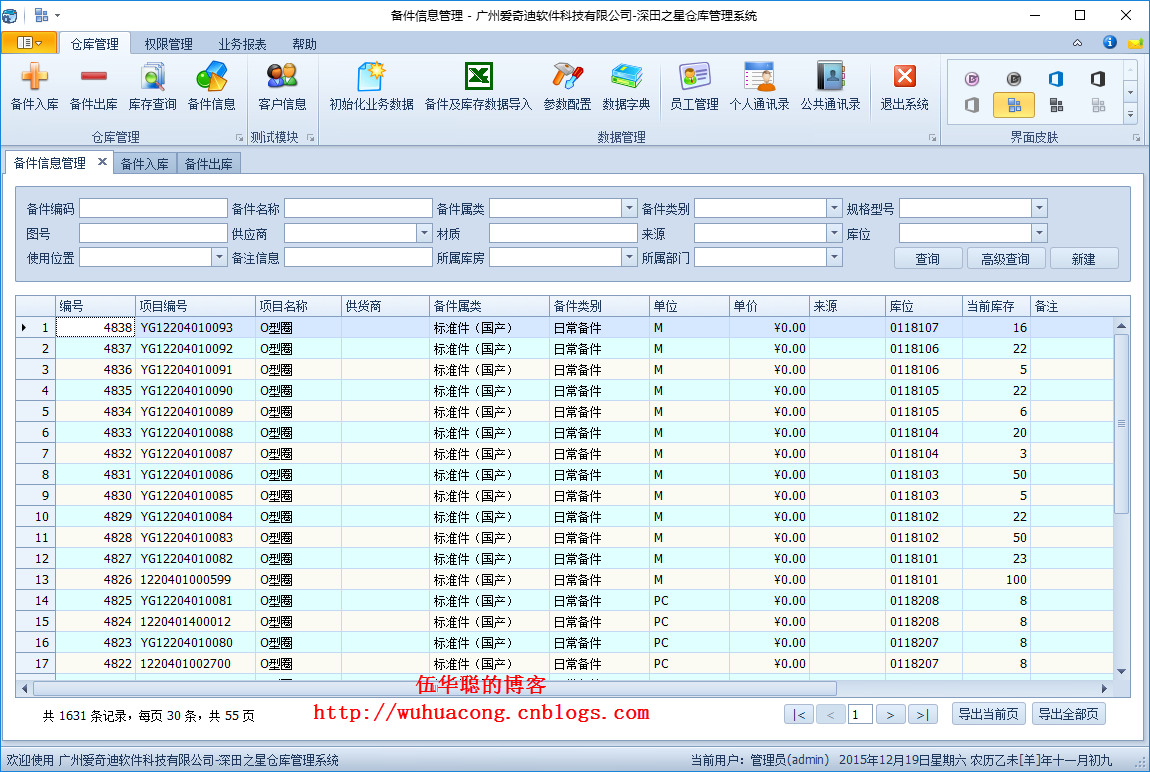
最后,为了更好理解整个动态菜单的界面效果,贴出几个做好的界面展示图,供参考学习。
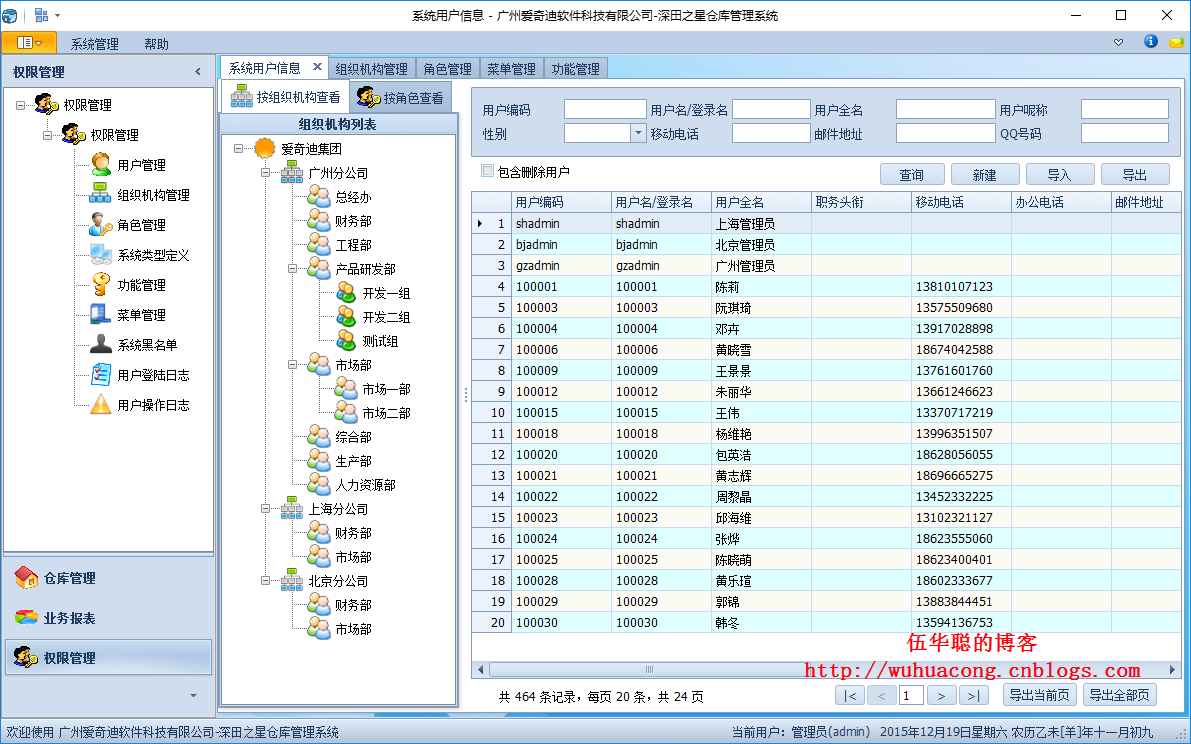
1)标准界面的处理方式
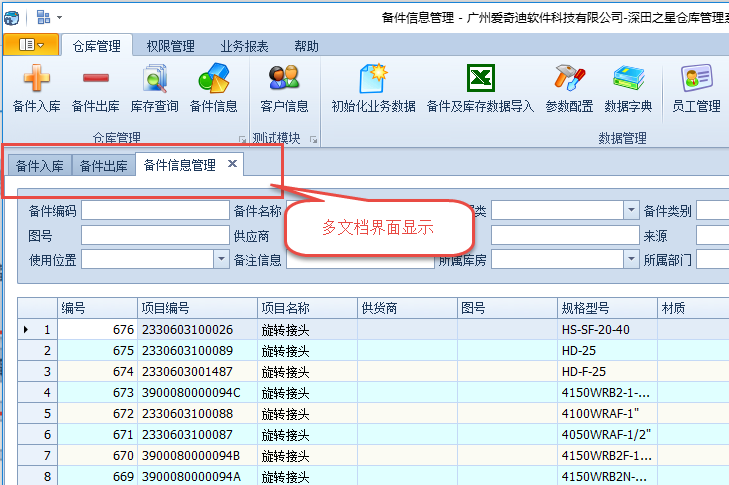
2)树形列表界面的处理方式
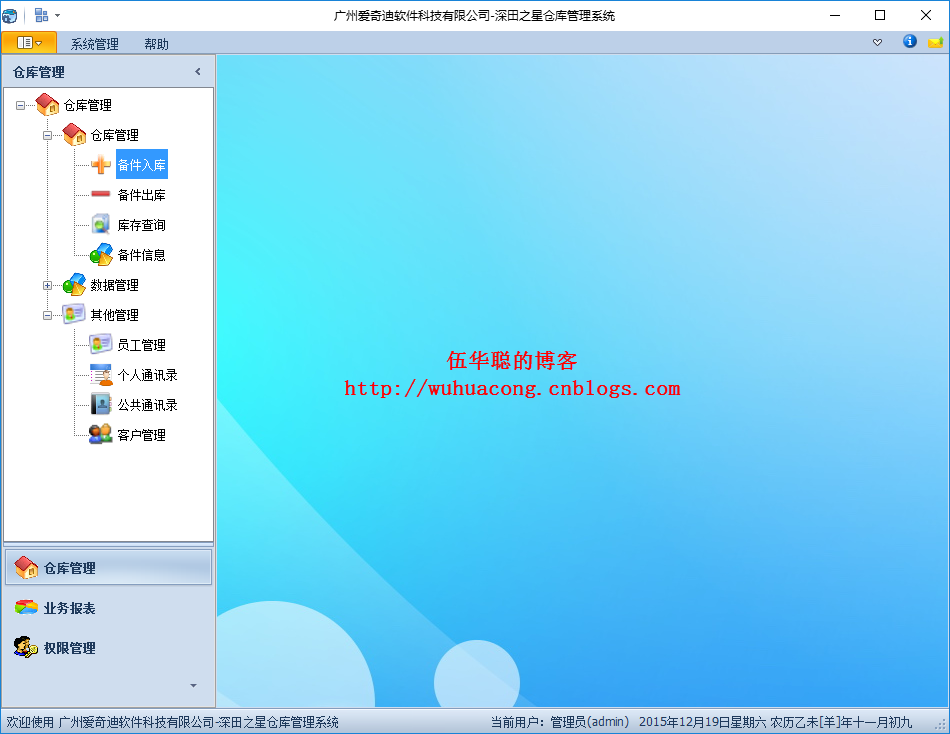
打开多文档页面后如下所示。