在基于MVC的Web项目中使用Web API和直接连接两种方式混合式接入
在我之前介绍的混合式开发框架中,其界面是基于Winform的实现方式,后台使用Web API、WCF服务以及直接连接数据库的几种方式混合式接入,在Web项目中我们也可以采用这种方式实现混合式的接入方式,虽然Web API或者WCF方式的调用,相对直接连接数据库方式,响应效率上略差一些,不过扩展性强,也可以调动更多的设备接入,包括移动应用接入,网站接入,Winfrom客户端接入,这样可以使得服务逻辑相对独立,负责提供接口即可。这种方式中最有代表性的就是当前Web API的广泛应用,促进了各个接入端的快速开发和独立维护,极大提高了并行开发的速度和效率。在企业中,我们可以合理规范好各种业务服务的Web API接口,各个应用接入端可以独立开发,也可以交给外包团队进行开发即可。
1、Winform混合式接入方式回顾
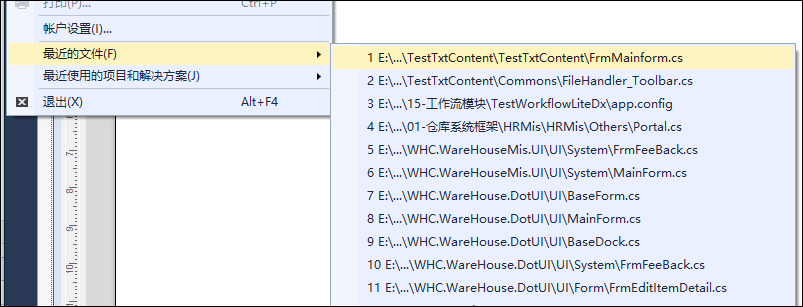
从一开始,我们的Web API 的设计目的就是为了给各种不同的应用进行接入的,例如需要接入Winform客户端、APP程序、网站程序、以及微信应用等等,由于Web API层作为一个公共的接口层,我们就很好保证了各个界面应用层的数据一致性。
上图介绍了各种应用在Web API的接口层之上,一般情况下,我们这层的接口都是提供标准的各种接口,以及对身份的认证处理等等,在Web API层更多考虑的业务范畴的相关接口,而在各个界面层,考虑的是如何对Web API进行进一步的封装,以方便调用,虽然Winform和Web调用Web API的机制有所不同,不过我们还是可以对Web API的客户端封装层进行重用的。
在Winfrom界面调用混合式接入的接口方式,它的示意图如下所示,主要的思路是通过一个统一的门面层Facade接口层进行服务提供,以及客户端调用的封装处理接口。

随着Web API层的广泛使用,这种方式带来了非常大的灵活性,通过在框架层面对各个层的基类进行封装,可以大大简化所需的编码,以及提供统一、丰富的基础接口供调用。
由于Winform调用Web API的时候,客户端对Web API层进行了一个简单的包装,这种方式可以简化对Web API接口的使用,只需要通过调用封装类,并传入相关的参数就可以获得序列化后的对象(包括基础对象和自定义类对象)。
这种封装的方式,由于对基类的统一实现,以及提供对URL地址、参数的组装等处理,非常利于Winform界面后台代码进行调用 ,加快Winfom界面功能的开发。例如我们从进一步细化的架构图上,可以看到整体各个层的一些基类(绿色部分)。

在基于Web API层的构建上,我们提供了Web API服务层的提供了BaseApiController和BusinessController<B, T> 的Web API控制器基类对常规的业务处理进行封装;在Web API服务调用层上,我们提供了BaseApiService<T>的基类进行封装常规接口;
同时提供IBaseService<T>的Facade门面层的统一接口,以及CallerFactory<T>的调用方式供Winform后台代码进行接口调用。
这种在Web API的基础上进行接口的封装,可以极大简化接口的调用,同时也可以提供给Web端的后台控制器使用,非常便于使用,下面就介绍在Web项目中进行混合式接入的实现过程。
2、Web混合式接入介绍
参照Winform混合式接入的方式,我们也可以利用这种方式应用于Web框架上,具体的分层关系如下所示。

上图整合了两种非常常用的接入方式:Web API服务接入、直接连接数据库的接入,一种具有非常强大的特性,一种具有快速的访问效率,各有其应用场景,我们在不同的业务环境进行配置,使其适应我们实际的应用即可,一般情况下,我们建议采用Web API方式进行构建整个业务系统的生态链。
Web API的接口调用,可以通过两种方式进行,一种是采用纯JS框架,类似AngularJS的方式,通过其控制器进行相关接口的调用;还有一种方式,采用Asp.NET的MVC方式,前端界面通过JS调用后端的控制器实现数据处理,具体逻辑有后端逻辑控制器进行Web API的处理,我们这里采用后者,以实现较为弹性的处理。
相对Winform来说,Web上的混合方式接入相对复杂一些,虽然Winform的界面类似Web的MVC中的视图HTML代码,Winform后台逻辑代码类似视图的控制器对象,但是确实麻烦一些,相当于我们还需要在Web界面的后台控制器Controller上在封装下相关的处理接口。
在整个基于混合式接入方式的Web 项目中,对于Web API接口的使用,整个项目的结构如下所示。

有了这些图示的说明,我们应该对整体有一个大概的了解,对于进一步的细节问题,我们可能依然不是太清楚,需要以具体的项目代码工程进行介绍。
1)对于数据库层
我们可以考虑的是多种数据库的接入支持,如SQLServer、Oracle、SQLite、Access,或者PostgreSQL的支持,这些都是基于关系型数据库的支持,具有很好的可替代性和标准一致性。
它们可以通过遵循统一的SQL或者部分自定义的SQL语句进行,或者通过存储过程实现,均可以实现相应的功能。
对于数据库不同的支持方案,我这里采用了Enterprise Library的数据库访问组件进行一致性的支持,这样可以降低各个不同数据库模型的处理,统一使用这种组件访问方式,实现不同数据库的访问。
2)对于业务逻辑层
业务逻辑层,是有几个不同的层进行综合的使用。如项目中的核心层如下所示,包括了业务逻辑层BLL、数据访问层DAL(不同的实现层)、数据访问接口层IDAL、以及传递数据的Entity实体层。

这些模块,在各个层上都有标准的基类用来实现对接口或者功能的封装处理。
如BLL层的继承关系如下
/// <summary> ///基于BootStrap的图标/// </summary> public class BootstrapIcon : BaseBLL<BootstrapIconInfo>
如IDAL层的继承关系如下
/// <summary> ///基于BootStrap的图标/// </summary> public interface IBootstrapIcon : IBaseDAL<BootstrapIconInfo>
基于Oracle的数据访问层在DALOracle里面,我们看到起继承关系如下。
/// <summary> ///基于BootStrap的图标/// </summary> public class BootstrapIcon : BaseDALOracle<BootstrapIconInfo>, IBootstrapIcon
实体层继承关系如下所示。
/// <summary> ///基于BootStrap的图标/// </summary> public class BootstrapIconInfo : BaseEntity
这些模块,由于有了基类的封装处理,多数逻辑不用再重写代码,关于它们具体的内容,可以参考之前的开发框架介绍文章了解,这里不再赘述,主要用来介绍其他模块层的继承关系。
3)对于Web API服务层
Web API如果业务模块比较多,可以参考我上篇随笔《
Web API项目中使用Area对业务进行分类管理
》使用Area区域对业务进行分类管理,一般情况下,我们为每个Web API的接口类提供了基类的管理,和我们其他模块的做法一样。
/// <summary> ///所有接口基类/// </summary> [ExceptionHandling]public class BaseApiController : ApiController
以及
/// <summary> ///本控制器基类专门为访问数据业务对象而设的基类/// </summary> /// <typeparam name="B">业务对象类型</typeparam> /// <typeparam name="T">实体类类型</typeparam> public class BusinessController<B, T>: BaseApiControllerwhere B : class where T : WHC.Framework.ControlUtil.BaseEntity, new()
这样,基本的增删改查等常规接口,我们就可以在基类里面直接调用业务逻辑类实现数据的处理,具体的业务子类这不需要重写这些接口实现了。
/// <summary> ///查询数据库,检查是否存在指定ID的对象/// </summary> /// <param name="id">对象的ID值</param> /// <returns>存在则返回指定的对象,否则返回Null</returns> [HttpGet]public virtual T FindByID(string id, stringtoken)
{//如果用户token检查不通过,则抛出MyApiException异常。//检查用户是否有权限,否则抛出MyDenyAccessException异常 base.CheckAuthorized(AuthorizeKey.ViewKey, token);
T info=baseBLL.FindByID(id);returninfo;
}
对于HttpGet和HttpPost的约定,我们对于常规的获取数据,使用前者,如果对数据发生修改,或者需要复杂类型的参数,使用POST方式处理。
子类的继承关系如下所示
/// <summary> ///权限系统中用户信息管理控制器/// </summary> public class UserController : BusinessController<User, UserInfo>
这样这个UserController就具有了基类的一切功能,只需要实现一些特定的接口处理即可。
例如我们可以定义一个新的Web API接口,如下所示。
/// <summary> ///通过用户名称获取用户对象/// </summary> /// <param name="userName">用户名称</param> /// <param name="token">访问令牌</param> /// <returns></returns> [HttpGet]public UserInfo GetUserByName(string userName, stringtoken)
{//令牌检查,不通过则抛出异常 CheckResult checkResult =CheckToken(token);return BLLFactory<User>.Instance.GetUserByName(userName);
}
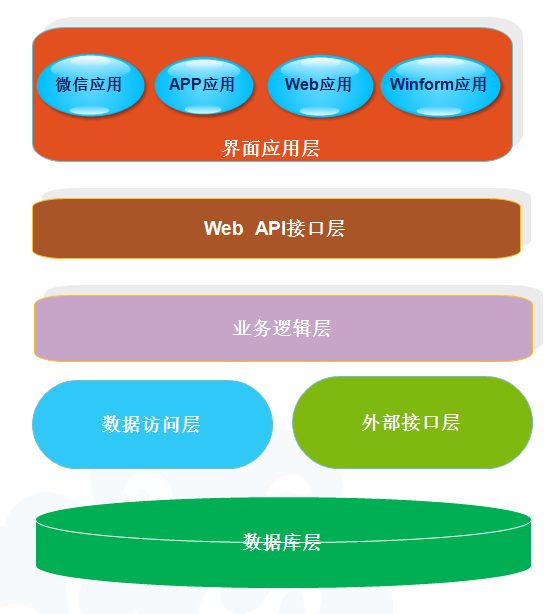
这样对于Web API架构来说,控制器的整个继承关系大概如下所示。
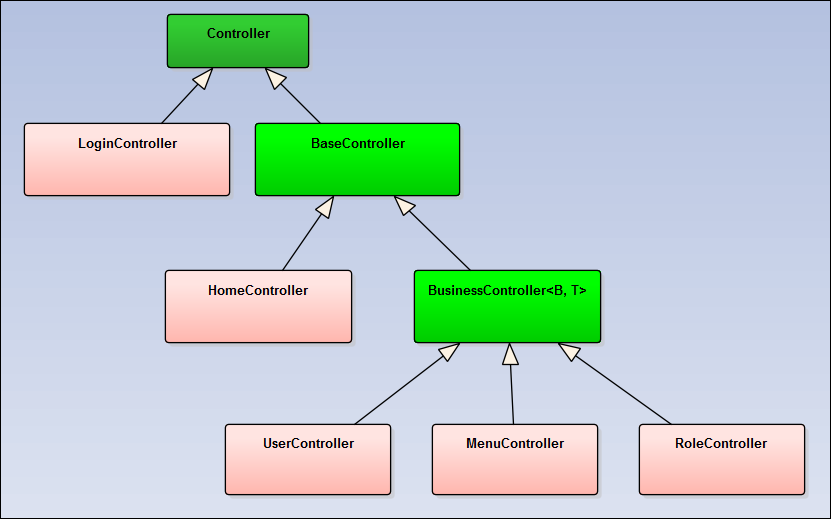
如果使用Area区域来对业务模块进行分类,那么整个Web API项目的结构如下所示,各个业务区域分开,有利于对业务模块代码的维护,其中BaseApiController和BusinessController则是对常规Web API接口的封装处理。

4)对于Web API封装层
为了实现Winform混合式框架和Web混合式框架的共同使用Web API服务的封装层,那么我们需要独立一个Web API封装层,也就是***Caller层,包含了直接访问数据库方式、Web API服务接口访问方式,或者加上WCF服务访问方式等的封装层。
这个层的目的是动态读取Web API 接口的URL地址,以及封装对Web API接口访问的繁琐细节,是调用者能够简单、快速的访问Web API接口。
整个Web API封装层的架构,就是基于Facade接口层进行不同的适配,如直接访问数据库方式、Web API服务访问方式的适配处理,以便在客户端调用的时候,自动从不同的接口实现实例化对象,从不同方式来获取所需要的接口数据。

对于用户User对象来说,我们来举一个例子来说明Caller层之间的继承关系。
在Facade层的接口定义如下所示。
public interface IUserService : IBaseService<UserInfo>
在WebAPI的Caller层实现类代码如下所示。
/// <summary> ///基于WebAPI方式的Facade接口实现类/// </summary> public class UserCaller : BaseApiService<UserInfo>, IUserService
对于直接连接方式,实现类的代码如下所示。
/// <summary> ///基于传统Winform方式,直接访问本地数据库的Facade接口实现类/// </summary> public class UserCaller : BaseLocalService<UserInfo>, IUserService
这样我们整理下它们关系如下图所示。

对于不同的业务模块,我们基于对应不同的Facade层接口实现不同的Caller层,这样即使有很多项目模块,我们单独维护起来也方便很多,在Winform客户端或者Web端调用Caller层的时候,需要引入对应的Caller层项目,以及业务核心层Core。
例如我们需要在使用的时候,同时引入Core层和Caller层,如下是项目中的部分引用关系。
5)对于Web 界面层
这个Web界面层,主要就是消费Facade层接口实现,用来获取数据展示在界面上的,我们界面上通过HTML + JS Ajax的方式,实现从MVC控制器接口获取数据,那么我们为了方便,依旧在控制器层进行抽象,以便对常规的方法抽到基类里面,这样子类代码就不用重复了。
这样的改变,对于我们已有的MVC项目来说,视图处理代码不需要任何改变,只需要控制器对数据访问的处理调整即可,从而实现MVC普通方式获取数据的界面层,顺利转换到基于Web API +直接访问数据库两者合一的混合式方式上。
原先直接访问数据库的MVC视图控制器的设计,基本上类似于Web API 中控制器的设计过程,如下所示。
而对于MVC的Web界面层,以混合式方式来访问数据,我们需要引入一个新的控制器来实现适配处理。
这样构建出来的继承关系图,和上面Web的MVC控制器类似。

不同的是,里面调用的任何访问数据的方法,从原来BLLFactory<T>到CallerFactorry<T>的转换了,这样就实现了从简单的直接访问数据库方式,切换到混合式访问数据的方式,在Web框架里面,可以配置为直接访问数据库,也可以配置为通过Web API方式访问数据,非常方便。
例如继承关系类的代码如下所示。
/// <summary> ///基于混合访问方式的用户信息控制器类/// </summary> public class UserController : ApiBusinessController<IUserService, UserInfo>
其中对于Web 界面端的控制器,使用混合式访问方式的后台控制器代码如下所示。
/// <summary> ///根据角色获取对应的用户/// </summary> /// <param name="roleid">角色ID</param> /// <returns></returns> public ActionResult GetUsersByRole(stringroleid)
{
ActionResult result= Content("");if (!string.IsNullOrEmpty(roleid) &&ValidateUtil.IsValidInt(roleid))
{
List<UserInfo> roleList = CallerFactory<IUserService>.Instance.GetUsersByRole(Convert.ToInt32(roleid));
result=ToJsonContent(roleList);
}returnresult;
}
也就是从传统的BLLFactory<User>转换为了CallerFactory<IUserService>,整体性的接口变化很小,很容易过渡到混合式方式的访问。
在Web界面端的视图里面,我们基本上就是根据HTML + Ajax的Javascript方式实现数据的交互处理的,包括显示数据,提交修改等等操作。
同样我们可以通过JS的函数进行抽象,把基本的处理函数,放到一个类库里面,方便界面层使用,然后引入JS文件即可。
@*脚本引用放在此处可以实现自定义函数自动提示*@<scriptsrc="~/Scripts/CommonUtil.js"></script>
如下面所示,是调用JS自定义函数实现列表数据的绑定操作。
$("#Dept_ID").on("change", function(e) {var deptid = $("#Dept_ID").val();
BindSelect("PID", "/User/GetUserDictJson?deptId="+deptid);
});或者删除的JS代码如下所示
var postData ={ ids: ids };
$.post("/User/ConfirmDeleteByIds", postData, function(json) {var data =$.parseJSON(json);if(data.Success) {
showTips("删除选定的记录成功");
Refresh();//刷新页面数据 }else{
showTips(data.ErrorMessage);
}
});
以及对一些JS列表树,以及下拉列表,都可以采用JS函数实现快速的处理,如下所示。
var treeUrl = '/Function/GetFunctionJsTreeJsonByUser?userId=' +info.ID;
bindJsTree("jstree_function", treeUrl);
$('#lbxRoles').empty();
$.getJSON("/Role/GetRolesByUser?r=" + Math.random() + "&userid=" + info.ID, function(json) {
$.each(json,function(i, item) {
$('#lbxRoles').append('<option value="' + item.ID + '">' + item.Name + '</option>');
});
});
以上就是我从整个基于混合式访问的Web项目进行讲解介绍,贯穿了整个数据传输的路线和调用路线,当然其中还有很多细节方面有待细讲,以及需要一些比较巧妙的整合封装处理,整个目的就是希望借助混合式的访问思路,实现多种数据接入方式的适配整合,以及最大程度简化子类代码的编写,并且通过利用代码生成工具对整体框架的各个层代码的生成,我们关心的重点转移到如何实现不同业务的接口上来,从而使得我们能够快速开发复杂的应用,而且又能合理维护好各个项目的代码。
一句话总结整个开发:简单、统一、高效。