SAP中的ALE, IDOC
ALE技术:应用链接支持(Application Link Enabling 简称ALE),是一项用于创建和运行分布式应用的技术。ALE是SAP的专有技术。
ALE对象——ALE包含了可控的数据消息交换,可以确保松散耦合的应用程序之间的数据一致性。ALE由三层组成,应用服务、分发服务和通信服务。ALE的基本原理是提供一个分布式的并且完全整合的R/3系统。每一个应用都是自适应的。每一个自适应系统使用一种特定的方法实现数据冗余。因此数据必须是分布的、且同步的。
ALE通信图
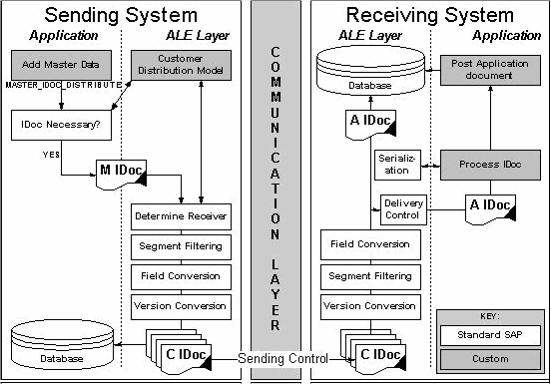
1,IDOC类型和消息类型的区别是什么?如何联系IDOC类型和消息类型?
消息类型把意义赋予了IDOC,IDOC类型则将结构给予了IDOC。消息会在包含着不同消息类型的系统之间交换。消息类型依赖于包含的数据和涉及的处理过程,它决定了消息的技术结构和IDOC类型。IDOC类型标识了SAP用于解释一个busness transaction的格式。
2,IDOC信息存储在哪里?
表 |
描述 |
EDID4 |
存储数据记录 (version 4.6) |
EDIDC |
存储IDOC的控制记录信息 |
EDIDD |
数据段 (EDI中间文档) |
EDIDS |
存储IDOC的状态 |
3,处理代码是什么?处理代码的类型是什么?
处理代码是指一个可以帮助从/向IDOC读写数据的workflow或者是function module。处理代码应用在ALE和EDI中,用以标识需要被调用以进行后续处理过程的function module或者API。进站和出站接口也使用处理代码,但是用于不同的目的。出站处理代码保存在表TEDE1中,而进站处理代码保存在TEDE2中。
以下是处理代码类型。
处理代码 |
描述 |
Inbound Process Code |
This will Idoc and create corresponding application data |
Outbound Process Code |
读取应用数据并放置到IDOC中 |
Status Proces Code |
处理IDOC被发送到其它系统时出现的错误 |
System Process Code |
创建工作条目,如果在IDOC/应用文档处理中发生某些错误的情况下 |
4,如何处理IDOC?
你可以使用以下程序来处理IDOC:
- RBDMANI2 : 手动重新处理IDOC
- RBDMANIN : 发送状态51的IDOC
- RBDMOIND : 状态03->12的出站IDOC
- RSEOUT00 : 处理状态30的IDOC
- RBDAPP01 : 处理状态64的IDOC
- RBDAGAIN : 重新处理不正确的出站IDOC
- RBDAGAI2 : 重新处理ALE输入错误的IDOC
5,如何从发送系统追踪接收系统的IDOC?
- 运行事务代码BD87
- 在IDOC编号字段填入出站IDOC,然后运行。或者当你运行主数据事务比如说BD10的时候,记住开始时间和结束时间并且填到BD87的相应字段里面,并且给出消息类型和接收系统的名字,然后运行
- 选择相应的消息类型,然后点击追踪IDOC按钮

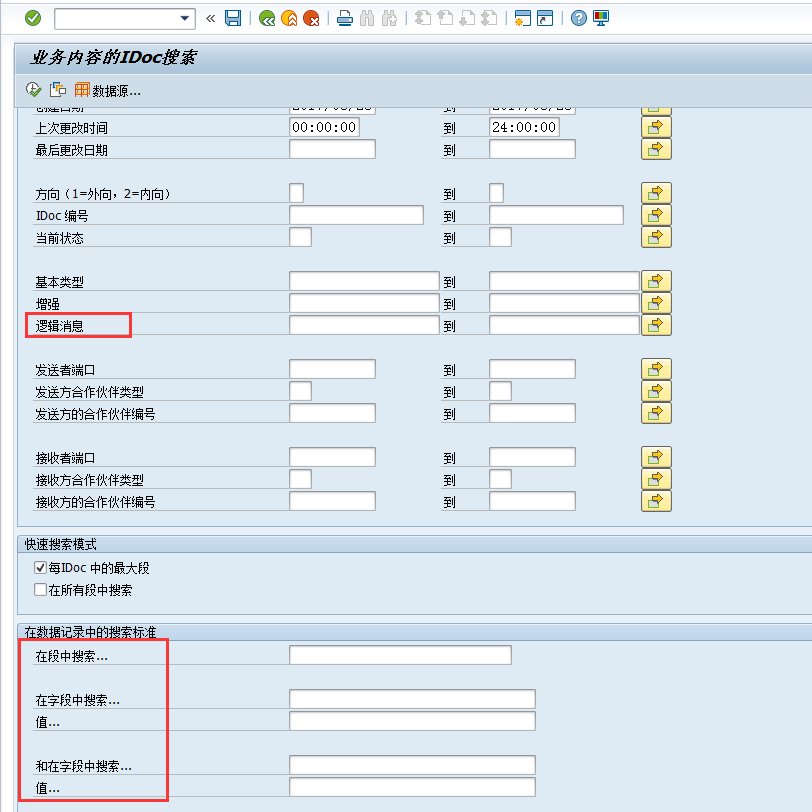
6,如何基于数据追踪IDOC?
步骤:
- 运行事务代码WE09
- 把消息类型名填入字段“逻辑消息”,比如,填上“DEBMAS”
- 现在我们要移动到“在数据记录中的搜索标准”部分
- 在这部分我们要填入段的名字,即我们想要搜索的数据的段名,填入到“在段中搜索”中。比如,填上“EX - E1KNA1M”
- 在“在字段中搜索”字段中,我们要填入想要搜索的数据段的字段名,比如用“KUNNR”来搜索特定的客户编码对应的IDOC。
- 现在在字段“值”中我们要填入搜索值。比如,客户编码“100”。
- 我们现在要运行事务。
- 结果可以是单个IDOC或者多个IDOC的列表,这取决于输入的搜索条件。
7,如何在同一个系统里面发送和接受IDOC?
- 创建一个虚拟的逻辑系统
- 新条目。前往事务代码 SALE->基本设置->逻辑系统->新条目,输入SYSID_CLNT,但是这个是虚拟的,所以使用SYSID的前两个字符和前缀“D”,接着加上下划线和客户端号。(注:原文是SALE-> sending and Receiving Systems -> Logical Systems ,疑有误)。

例如,如果ERP_100是R/3的逻辑系统,创建的虚拟系统名应该是ERD_100.
- 为源系统创建端口(ERP_100)
- 前往WE21并且选择“事务性RFC”然后点击创建按钮。将端口命名为“SAP”并且把它和SYSID结合到一起,在我们的例子里应该是SAPERP。选择合适的版本,输入当前系统的RFC连接,在这个例子里是“ERP”。
- 在合作伙伴类型LS里创建合作伙伴配置:
- 接收端 ( Outbound to ) : 在合作伙伴类型LS,编号ERD_100中创建出站参数,给出消息类型,接收端名(即我们在第二步中创建的)。输入基本类型。
- 发送端( Inbound From ): 在合作伙伴类型LS,编号ERD_100中创建入站参数,给出合适的消息类型和处理代码。
- 现在创建单独的程序来发送IDOC:
- 程序需要在某个点调用FM: MASTER_IDOC_DISTRIBUTE,这时需要传递如下的EDIDC结构:
i_edidc-mestyp = 消息类型.
i_edidc-idoctp = 基本类型.
i_edidc-rcvprt = 'LS'.
Concatenate 'SAP' sy-sysid into l_port.
i_edidc-rcvpor = l_port.
i_edidc-rcvprn = 'ERD_000'.
CONCATENATE sy-sysid '_' sy-mandt
INTO l_sndprn.
i_edidc-sndprn = l_sndprn.
i_edidc-sndprt = 'LS'.
i_edidc-sndpor = l_port. - 观察发送端口和接收端口,这是关键所在。出站IDOC通过名为ERP_100的发送者被发往端口SAPERP,接收者为ERD_100,接着入站IDOC也通过发送者ERP_100被发往相同的端口SAPERP,接收者仍是ERD_100.
- 程序需要在某个点调用FM: MASTER_IDOC_DISTRIBUTE,这时需要传递如下的EDIDC结构:
8. 消息控制是什么?什么时候使用它?
消息控制是一种根据选择条件和需求来输出文档的机制。该原理并非只应用在EDI和ALE中,也在其它的输出媒介(比如:打印,传真)中使用。消息控制会判断文档类型、时间、数量和媒介。NAST表存储了输出记录。用于创建输出消息的条件(选择条件和需求)存储在条件表里。搜索机制用于访问队列、输出结果以及判断应用文档是否有资格被输出。
一些有关消息控制的T-CODE:
事务代码 |
描述 |
NACE |
条件记录维护 |
VOK2 |
SD消息控制组件 |
VOK3 |
采购消息控制组件 |
VOFM |
关于需求、公式的配置 |
V/86 |
条件表字段目录 |
WE15 |
IDOC测试:从消息控制出站测试 |
9,如何重新处理失败的传输条目?
你可以使用程序RSARFCEX重处理失败的传输条目。
10,可以在用哪个事务代码在统一额地方找到出站和入站处理代码?
WE64
本文链接:http://www.cnblogs.com/hhelibeb/p/6625534.html
英文原文:ALE, IDOC





