软件调试的概念
软件调试是泛指重现软件缺陷问题,定位和 查找问题根源,最终解决问题的过程。 软件调试通常有如下两种不同的定义:
- 定义1:软件调试是为了发现并排除软件程序中 的错误,可以通过某种方法控制被调试程序的执行过 程,以便随时查看和修改被调试程序执行状态的方法。 在该定义中,软件测试属于软件调试的一部分,与 牛津词典中的调试定义类似。 在牛津词典中调试定义 为:“识别和排除计算机硬件或软件中错误的过程。”
- 定义2:调试是执行一次成功的测试之后所要进 行的工作。 所谓成功的测试,是指它可以证明程序没 有实现预期的功能。 调试包含两个步骤,从执行了一个成功测试用例,发现问题后开始;第一步,确定程序 中可疑错误的准确性质和位置;第二步,修改错误。 在该定义中软件测试从调试工作中分离出来。
软件调试的内涵
软件调试是将编制的程序投入实际运行前,用手工或编译程序等方法进行测试,修正语法错误和逻辑错误的过程。这是保证计算机信息系统正确性的必不可少的步骤。编完计算机程序,必须送入计算机中测试。根据测试时所发现的错误,进一步诊断,找出原因和具体的位置进行修正。
调试这个术语可能意味着很多不同的事情,但最字面的意思是,它意味着从代码中删除错误、异常和bug。现在,有很多方法可以做到这一点。例如,可以通过扫描代码以查找输入错误或使用代码分析器进行调试。您可以使用性能分析器调试代码。或者,可以使用调试器进行调试。
软件调试的基本过程
按照定义1,软件系统调试的基本过程如下:
- 用编辑程序把编制的源程序按照一定的书写格式送到计算机中,编辑程序会根据使用人员的意图对源程序进行增、删或修改。
- 把送入的源程序翻译成机器语言,即用编译程序对源程序进行语法检查并将符合语法规则的源程序语句翻译成计算机能识别的“语言”。如果经编译程序检查,发现有语法错误,那就必须用编辑程序来修改源程序中的语法错误,然后再编译,直至没有语法错误为止。
- 使用计算机中的连接程序,把翻译好的计算机语言程序连接起来,并扶植成一个计算机能真正运行的程序。在连接过程中,一般不会出现连接错误,如果出现了连接错误,说明源程序中存在子程序的调用混乱或参数传递错误等问题。这时又要用编辑程序对源程序进行修改,再进行编译和连接,如此反复进行,直至没有连接错误为止。
- 将修改后的程序进行试算,这时可以假设几个模拟数据去试运行,并把输出结果与手工处理的正确结果相比较。如有差异,就表明计算机的程序存在有逻辑错误。如果程序不大,可以用人工方法去模拟计算机对源程序的这几个数据进行修改处理;如果程序比较大,人工模拟显然行不通,这时只能将计算机设置成单步执行的方式,一步步跟踪程序的运行。一旦找到问题所在,仍然要用编辑程序来修改源程序,接着仍要编译、连接和执行,直至无逻辑错误为止。也可以在完成后再进行编译。
按照定义2,软件系统调试的基本过程如下:
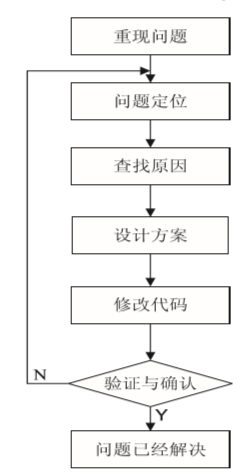
- 重现问题:重现软件测试发现的问题;
- 问题定位:确定可能发生问题的程序段位置;
- 查找原因:分析相关代码,确定导致缺陷问题 的内在原因;
- 设计方案:提出软件缺陷问题解决方案;
- 修改代码:根据设计方案修改程序代码;
- 验证和确认:采用审查、分析和测试等技术来 确定错误是否被排除,是否引入了新的错误。
上述6个步骤不断迭代进行,直至问题解决。 软件调试基本过程如图1所示:
在这些步骤中,问题定位和查找原因是软件调试 的关键环节,其工作量约占总工作量的90%以上。 软 件调试是一项既耗时又费力,同时又富有技巧性的工 作。 目前软件调试中的问题定位研究的比较多。
可以看到,定义一的流程更贴合我们的日常开发测试工作;而定义二的流程更贴合我们测试特别是软件发布或上线后发现问题的处理相关工作。
软件调试基本特征
- 广泛的关联性
需要调试人员有着雄厚的计算机基础知识(包括操作系统、开发语言、工具等)以及精通面向的业务问题域知识。
- 难度大
从"广泛的关联性"就可以知道难度大不大了。当然也看面临的具体问题和调试人员的素质
- 难以预估完成时间
这个时间真的是没法预估,除非某个问题的领域专家和对软件整体架构及代码的理解熟悉程度。
软件调试分类
- 按调试目标的系统环境分类:Windows下的软件调试、Linux下的软件调试、Dos下的软件调试等
- 按目标代码的执行方式分:
脚本程序 – 脚本调试器
执行编译的程序:
先编译为中间代码,在运行时再动态编译为当前CPU能够执行的目标代码(比如C#开发的.NET程序) – 托管调试
直接编译和链接成目标代码的程序(C/C++) – 本地调试
兼具以上两种的 – 混合调试
- 按目标代码的执行模式分:用户态调试(User Mode Debugging)、内核态调试(Kernel Mode Debugging);
在Windows这样的多任务操作系统中,作为保证安全和秩序的一个根本措施,系统定义了两种执行模式,即低特权等级的用户模式(User Mode)和高特权等级的内核模式(Kernel Mode)。
应用程序代码是运行在用户模式下的,操作系统的内核、执行体和大多数设备驱动程序是运行在内核模式的。
- 按软件所处的阶段分:开发期调试、产品期调试(分界线是产品的正式发布)
- 按调试器和调试目标的相对位置分:本机提哦啊哈斯、远程调试
- 按调试目标的活动性分:活动目标调试、转储文件调试



 )。 此菜单包含以下命令:
)。 此菜单包含以下命令:



 键入。
键入。 按钮来滚动查看命令列表,
按钮来滚动查看命令列表,