软件调试和应用软件开发模式
根据软件代码规模,应用软件的开发大致分为三 种模式。
程序员个人开发的小软件
用例图
这种模式和早期的软件开发模式类似。 小软件开发用例图如图所示。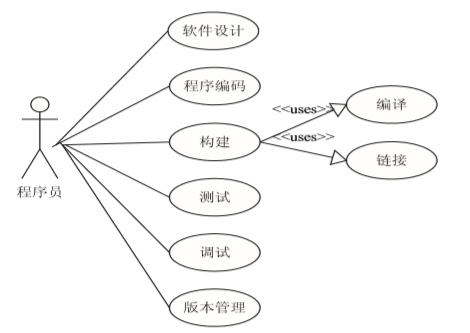
软件调试的特点
发现问题(测试)、定位问题和提出解决问题方 案、修改程序代码、验证全部由程序员负责。
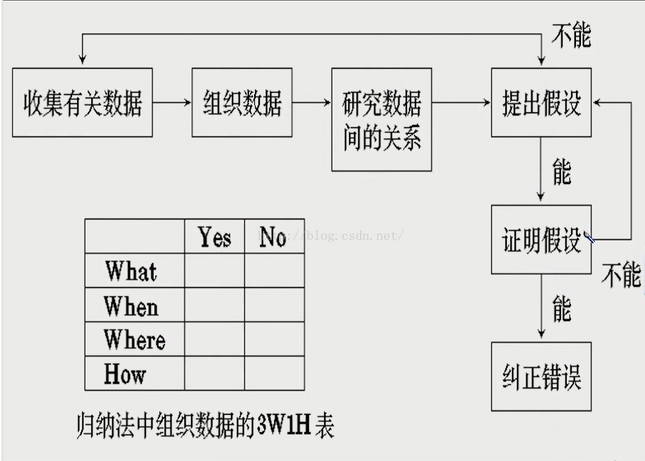
软件调试 可以分为静态调试与动态调试。
1、静态调试。 源程序代码编译时同时对源代码进行静态检查, 编译器提供了源代码各种编程错误和错误所在的位 置。 静态调试就是程序员逐条修改编译器提示的错 误,通过代码编译这一关。
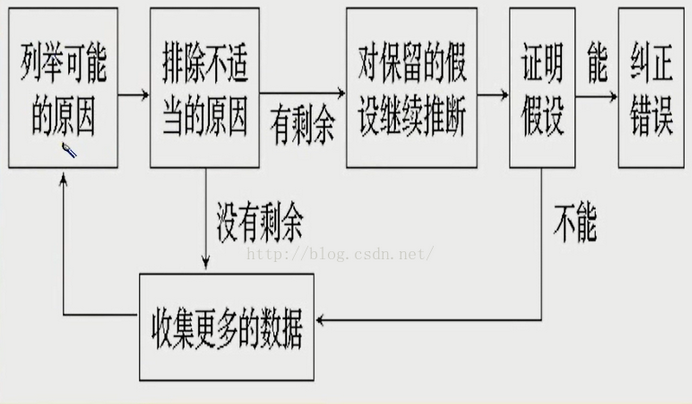
2、动态调试。 动态调试分为查错和纠错。 查错就是对程序进行 功能性能测试,查找各种不符合设计要求的各种问题; 纠错就是根据发现的问题,查找原因,修改程序源代 码。 这里的软件调试工作包括软件测试。 动态调试通 常采用以下两种方式:
- 仔细分析发现的问题,通过推理来查找发生 问题的原因。 程序员对程序的架构设计、编码实现十 分熟悉,往往能比较快地定位和处理问题。 这种方式 通常具有全局观念,可以避免解决问题过程中诱导出 现其他问题。
- 通过调试工具采用人机交互方式调试代码。 这种方式是逐条执行和跟踪程序代码,观察各种状态 和变量的变化,检查是否符合程序设计的要求来定位 问题。 这种方式有助于查找程序代码的微观错误,要 求程序员对程序代码的实现十分熟悉。 这两种方式是互补的,综合应用调试程序代码。
3、版本管理。 版本管理通常采用小型软件配置管理工具VSS, 也可采用文件存储的方式
程序组软件开发
这种模式与软件开发中期的开发模式类似。 通常 软件分为多个软件模块,每个程序员仅负责自己开发 的软件模块。 这种开发模式通常用于中、小型软件的 开发。
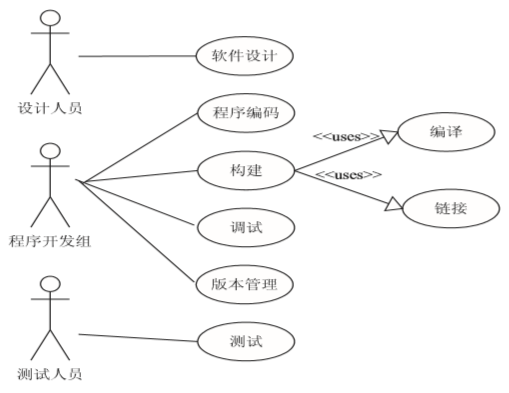
角色和用例图
软件设计人员:负责软件设计,提供设计规格 文档。
程序开发组:程序代码编写和程序调试,负责软件 的版本管理和集成构建。
测试人员:负责软件功能、性能测试。 程序组开发的软件用例图如图所示
软件调试的特点
1、软件的设计工作和大部分测试工作从程序组 工作中分离出去。 设计人员负责软件设计,程序员负 责程序代码的实现,定位问题和提出解决问题方案往 往由设计人员和程序组共同合作处理,程序员负责软 件纠错(程序代码修改),测试人员负责测试工作。
2、调试分为两个阶段:
(1)、开发组自己测试软件。 程序员完成程序源代码的编写,程序代码的静态 检查,使用调试工具对程序代码进行功能点的调试。 所有的功能点都调试完成后,通过组内代码评审之后, 将源代码合入版本库。 开发组组长指定某个程序员负责程序代码的集成 构建,编译过程中发现的问题,反馈给相关的程序员进 行处理。 源代码完成集成构建之后,打包提交给测试 人员测试。
(2)、测试人员测试软件。 测试人员根据设计规格文档设计测试用例,测试 提交过来的软件包。 测试人员发现的各种问题反馈给 程序开发组进行软件调试处理。 程序开发组和设计人 员确定发生问题的原因,确定修改方案,分配给相关的 程序员进行代码纠错处理。 对于比较复杂的问题,软 件设计人员需要提供实现编码的设计文档。 程序代码修改后,进行验证和确认。
3、版本管理通常采用软件配置管理工具 SVN。 通过版本管理工具对程序员提交的代码进行冲突检 查,通过调试处理保证代码的兼容性和一致性。
项目组开发的软件
软件通常由多个模块组成,每个模块由若干开发 单元组成。 开发单元分配给程序员编写程序代码。 这 种开发模式通常用于大型软件的开发。
角色和用例图
1、软件设计组:提供总体和各模块的设计规格 文档。
2、软件开发组:按模块分为开发小组,开发小组 将开发单元分配给程序员进行程序编码。
3、软件配置管理员:负责基线和版本库的管理。
4、持续集成工程师:负责软件的持续集成工作,搭建的集成构建工程,通过制定定时任务来自动 完成从版本库更新代码、静态检查、编译、出包、冒烟测 试等任务。 冒烟测试也称为预测试,对集成构建成功 的软件包的主要功能进行快速自动化测试。 构建成 功,可以获得最新Build版本,建立新的编码基线。 持 续集成工程师进行全量构建生成内部转测试版本,提 交测试组进行的测试工作。
5、软件测试组:对软件转测试版本进行功能、性 能测试,通过后产生测试(Tested)基线。 为持续集成 工作提供进行冒烟测试的自动化测试用例脚本包,搭 建相应的测试环境。 项目组开发软件(通常为大型软件)用例图如图 所示。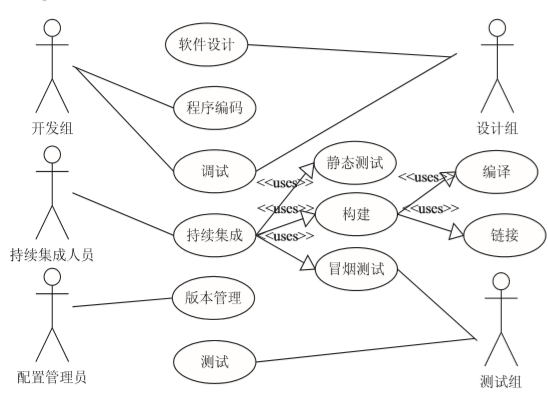
软件调试的特点
1、软件设计人员和软件测试人员增加了,有的软 件项目测试人员比开发人员还要多。 软件测试不仅要 发现程序编码中的问题,而且测试软件设计中的问题。 设计中的问题自然由设计人员处理,程序编码中的问 题由设计人员和开发人员共同处理。
2、软件的版本管理和集成构建工作由专人负责,实行基线和版本库的管理。 基线管理[13-14]为全体开 发人员提供统一的开发基点,统一的程序接口。 通过 控制集成构建的频率,有助于及时发现程序代码问题。
3、软件调试分为三个阶段:
(1)、开发人员调试自己开发软件单元。 程序开发人员每天从版本库检出需要的文件,放 在本地作为工作副本开始工作。 在工作副本上进行查 看、修改、编译、运行、调试等操作。 为了提供高质量的 代码,需要对编写好的代码进行单元测试,静态走码检 查,冲突处理和本地构建工作,处理发现的各种问题。 最后将评审过的代码提交到版本库。 开发人员向版本 库提交时,要添加注释、说明、CR单号、修改原因等,以 保证可追溯。
(2)、处理持续集成工程师发现的问题。 通常持续集成工作包括静态测试、编译、链接和冒 烟测试,每一步发现问题都要反馈给相关开发人员处 理,直到通过集成构建。
(3)、处理测试组发现的问题。 测试组测试转测试版本,将测试结果反馈给相关 人员,对存在的问题逐一定位,查找原因,修改程序,对 每个软件缺陷问题进行跟踪管理,直到问题解决为止。
4、设计人员和程序员共同处理反馈的各种问题, 定位问题和提出解决问题方案。 程序员负责程序代码 修改,测试人员负责验证和确认工作。
5、版本管理可以选择SVN、ClearCase、Git等软件 配置管理工具。 通过版本管理工具进行软件的版本管 理、基线管理和代码冲突检查。
6、软件开发过程中采用持续集成和基线管理技 术,可以更有效地进行开发和调试工作。