调试器工作流程
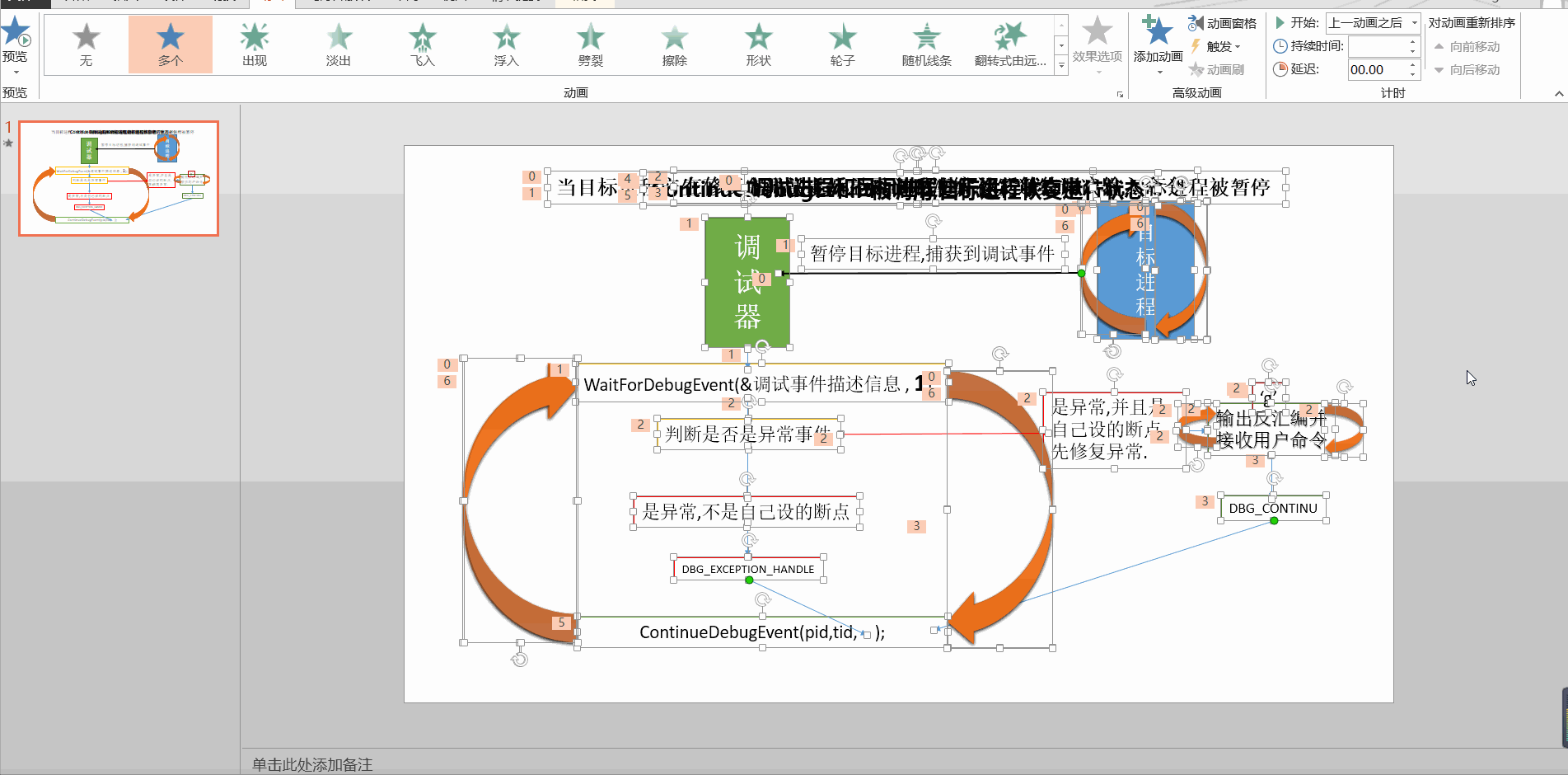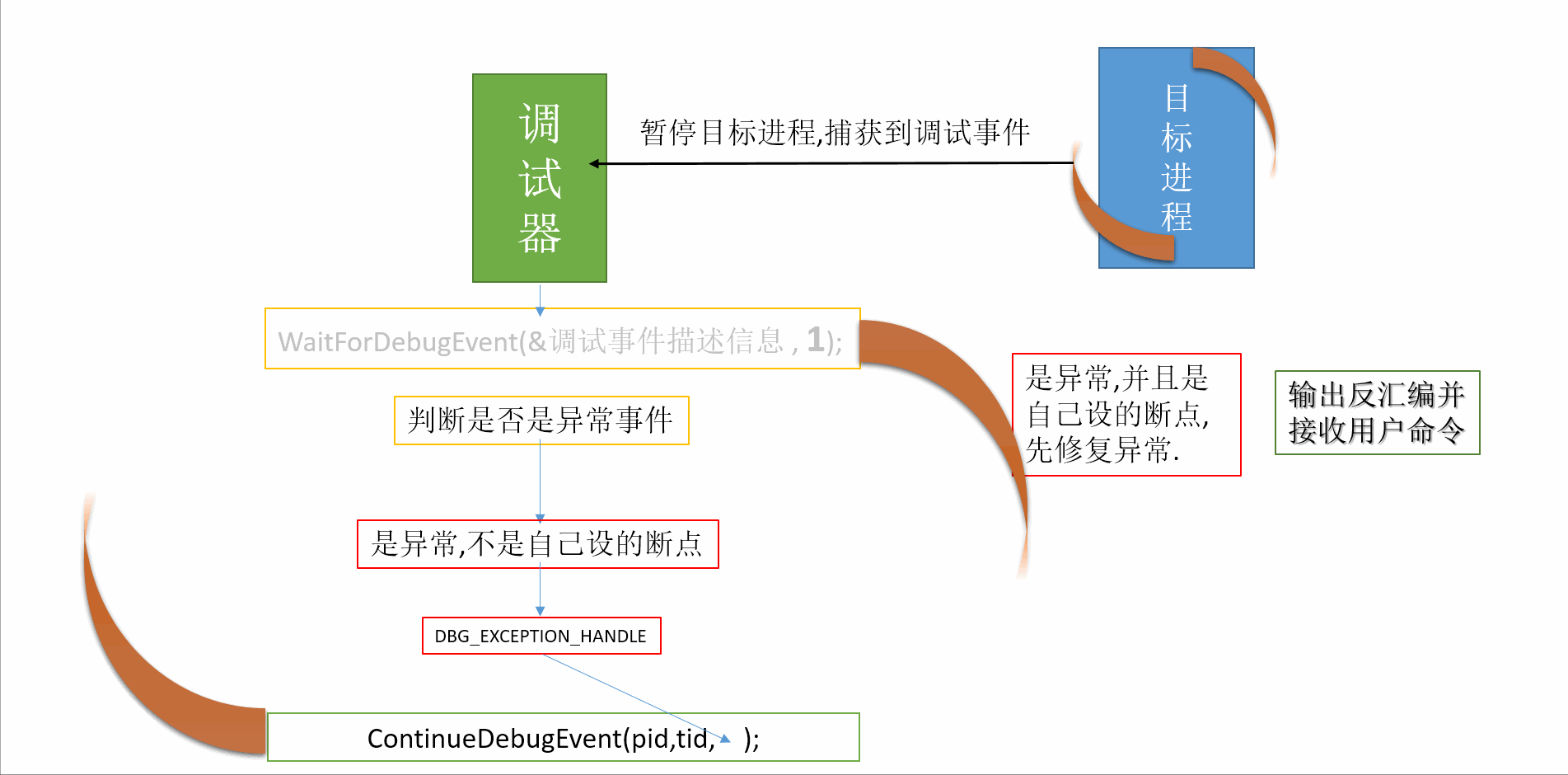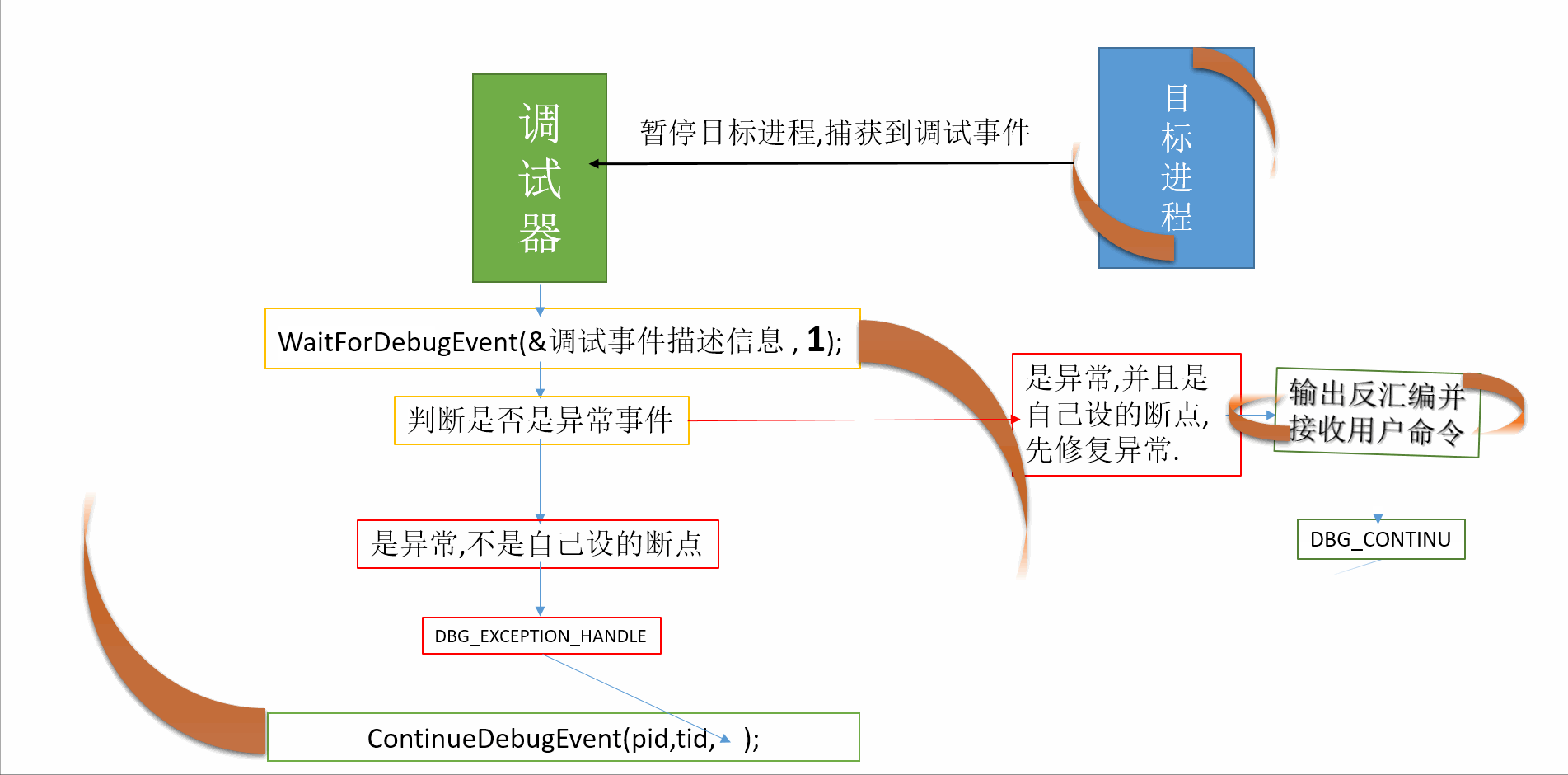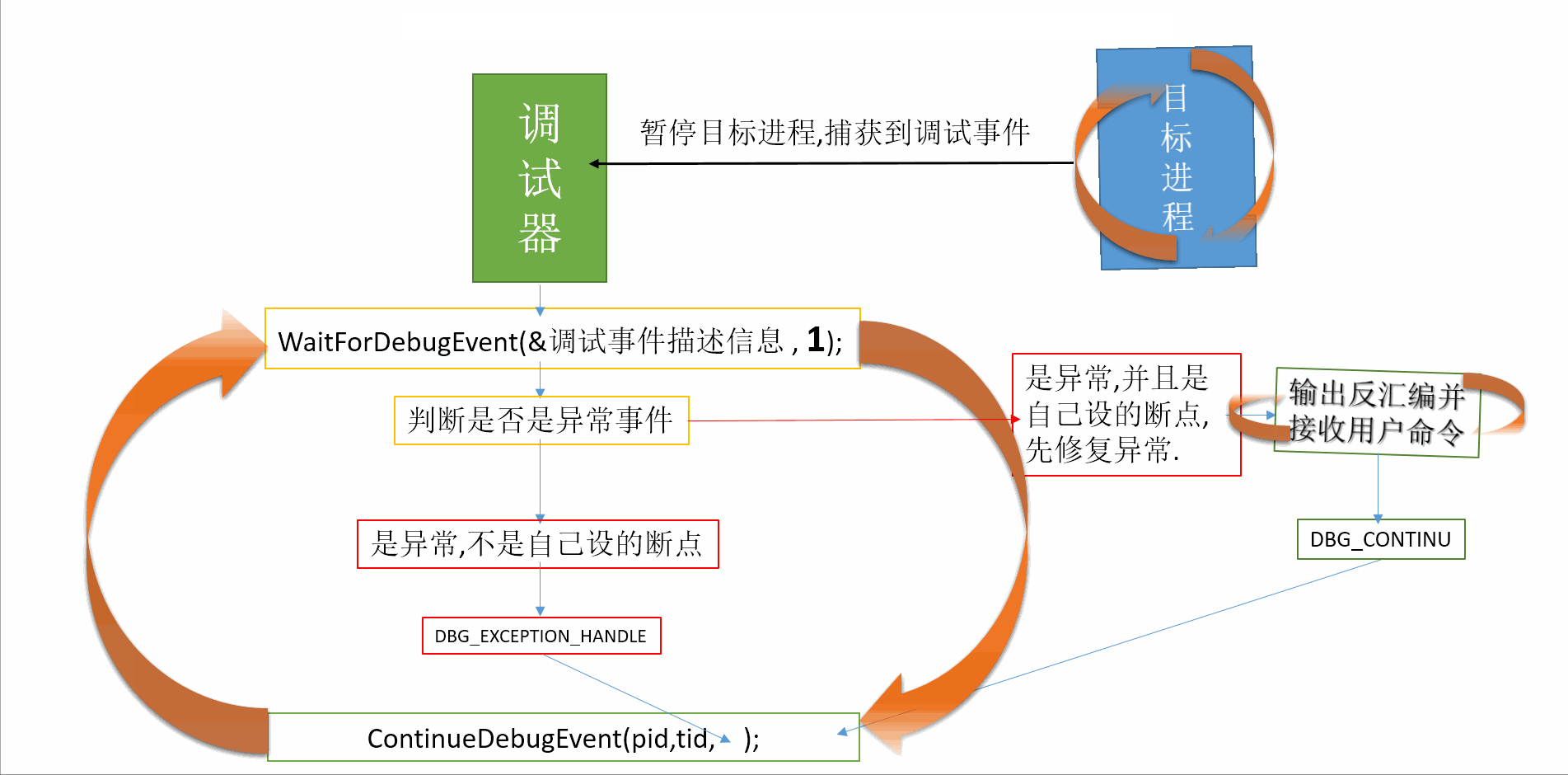
转自:https://blog.csdn.net/sinat_35360663/article/details/80176269
转自:https://blog.csdn.net/sinat_35360663/article/details/80176269
这就个规则来自于书籍《调试九法:软硬件错误的排查之道》,记录下来:
你必须掌握系统的工作原理以及它是如何设计的,在某些情况下还要知道为什么这样设计。如果你没有理解系统中的某个部分,那么这通常是出问题的地方。(这不仅仅是墨菲定律的问题,如果你不能理解你所设计的系统,你的工作可能会变得一团糟)。
如何理解系统呢?
这一点比较容易理解,就是问题复现,在日常工作中,你在排查一个问题的过程中,最重要的一步就是复现问题——能复现的问题都能解决。
这里有几个要点需要注意:
亲眼看到底层的失败是非常重要的,如果你猜测失败是如何发生的,那常常会修复一些根本不是bug的问题。
在软件世界里,观察意味着设置断点、添加调试语句、监视程序值以及检查内存;在医学领域,需要测试血样和进行X光透视。
对细节的观察应该到什么程度合适呢?简单的答案是:一直观察,直到把问题的原因锁定在几种可能之内。
在系统设计的时候,就要考虑到将来调试、排查问题的情况,将日志视为系统设计的一部分—打印一些关键日志,或者设计一些打开日志的开关,以便在生产环境针对某个case进行调试。
日常生活中有很多插桩的case:
反复将问题分成好的一半和坏的一半,然后缩小搜索范围,然后进一步研究有问题的那一半链路。
初中就学过的控制变量法。 在修改bug时候,如果某个改动没有修复bug,就应该立即把它改回来。
记下你的每步操作、顺序和结果; 魔鬼藏在细节中; 将一些事情关联起来思考; 好记性不如烂笔头;
一些显而易见的假设可能是错误的;是不是运行了正确的代码?是不是打了正确的包?插头是不是掉了?从一些最基本的问题开始确认,很多时候问题就出在这里。对自己使用的工具进行测试,因为工具也是一种软件,难保不会出问题。
向别人解释问题的过程,会让你对问题进行重新的梳理和理解,这时候可能发现之前没有发现的问题。
bug发生了,以除掉bug为自豪,而不是非得以自己除掉bug才自豪。
不管你是跟什么人求助,或者需要别人什么样的帮助(征求意见、获取专业知识、听取经验),在向别人描述问题的时候,一定要记住一件事——报告症状、而不是讲你的理论;另外,有些症状你可能不是十分确定,也可以描述出来。
如果你不修复bug,它不会自动消失。按照前面的规则解决问题后,要进行一次回归验证,确保已经修复问题,并且没有引入新的问题。
《调试九法:软硬件错误的排查之道》
调试符号文件(pdb)是一种很复杂的文件,由于这种文件格式微软并不公开,所以至今为止,并没有一篇文章或资料敢说自己对pdb文件进行了深入剖析。更重要的原因是,我们为了研究调试技术,需要知道一些系统(操作系统,编译器,连接器,调试器等)调试支持,仅仅知道即可,没必要深究微软为了实现调试而做出的每一个细节。
首先,我先问几个问题:
先简单讲解本文中用到的两个概念:
假设在一个EXE文件中,有一个全局变量a,距离文件起始的偏移为0x10,此时文件的起始位置为0x00000000,那么该全局变量a的OFFSET就是0x00000010。当这个exe执行起来,加载到内存后,这个exe本身所加载到的内存位置称为基地址。假设基地址为0x00400000,那么这个全局变量a的VA便是0x00400010。可见,exe本身所加载到的基地址不一样的话,那么a的VA就不能确定。
依然使用最简单的例子,来阐述原理,代码如下:
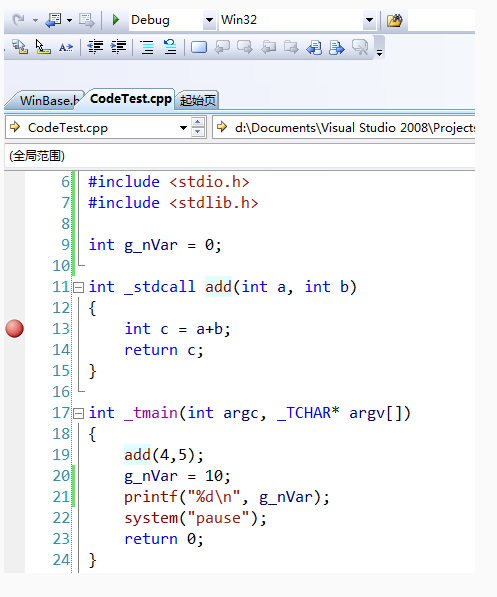
可以观察到,此时,笔者并未调试启动程序,而这个断点,就已经打上了。接下来我们调试启动程序,如下图:
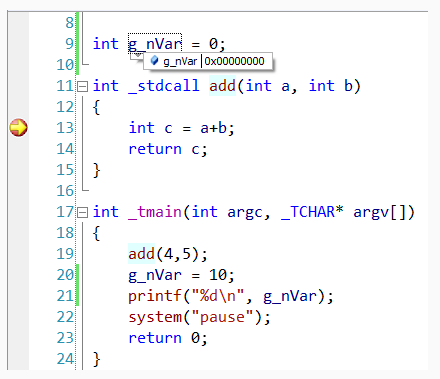
此时,我们已经进入断点,并中断下来,我们可以观察到全局变量g_nVar的值。想必这个过程,有过VC++开发经验的开发者,再熟悉不过了。下面,详细分析一下这个过程。
当我们鼠标点击下断点的时候,我们的程序还没有启动,VS是不可能知道这个断点应该打在内存中的哪一条指令的地址处的(此时,VS顶多知道断点所在的OFFSET,但是无法知道断点所在的VA),但是VS可以记录到一条重要的信息,就是当前断点在哪个源文件的哪个行号上。
接下来,我们调试启动程序,exe的镜像加载到内存后,所有代码段的指令的VA便是真实可用的了。但此时调试器是如何根据断点所在源文件和行号,来找到断点所在的VA的呢?现在,你应该想到本文在讲什么,哈哈,就是pdb啦。那么pdb文件中到底存了什么,才让调试器可以根据源文件及行号来找到对应的VA呢?
默认情况下,在pdb文件中,保存了可执行文件中所有的符号(函数名、变量名等)所在源文件、行号、OFFSET等信息。但是这些信息,是在什么时间得到的呢?很明显是编译阶段,编译器在编译每个cpp的过程中,就可以把这些符号的相关信息收集起来,存放在各个cpp所生成的obj文件中,然后在链接的时候,提取每个obj中的这些信息,生成一个单独的pdb文件。这样,以后调试程序的时候,调试器只要找得到这个pdb,就可以知道可执行文件中,所有符号所在的源文件、行号和OFFSET了。反过来说,当给出一个源文件和行号,就可以拿到对应的OFFSET了,所以在还没有启动调试的时候,我们下的断点,实际上调试器是知道这个断点应该在哪个OFFSET上了,等启动调试的时候,用这个OFFSET加上这个模块所加载到的基地址值,就可以得到这个断点所在的VA了,然后在这个VA处强行写上int
3指令,并继续执行,当执行到这里,便中断下来给我们一个调试机会了。想想,如果没有pdb,这个断点还能用么?
当我们鼠标放在某个变量上时,调试器可以拿到这个变量的名称,根据我们前面说的,用这个名称去pdb中查找,自然就可以找到pdb文件中保存的OFFSET了,加上这个模块的基地址,就找到了这个变量所在内存的VA,剩下的就是读一下这个VA内存中的内容了。这样也就实现了观察变量值得功能。
下面证实一下,pdb文件中确实存储了源文件、行号、OFFSET等信息。将上面例子代码放到VC6中编译,然后到debug目录中使用dumpbin来查看CodeTest.obj文件中的符号信息,如图:
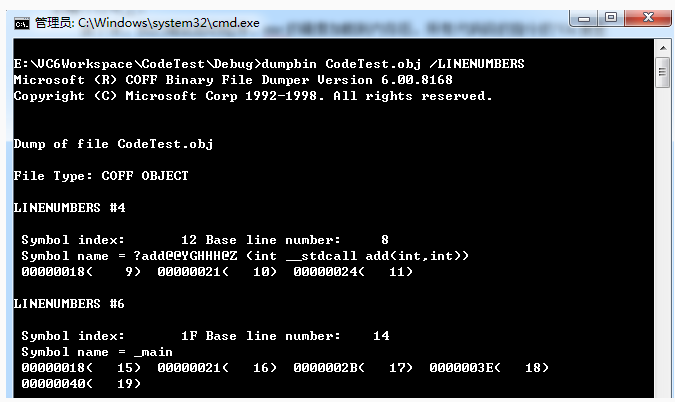
可见,add函数和main函数所在行号和起始行号和结束行号都是有记录的,那源文件是哪个呢?哈哈,当然是CodeTest.cpp了,我们查看的是CodeTest.obj文件嘛。。。
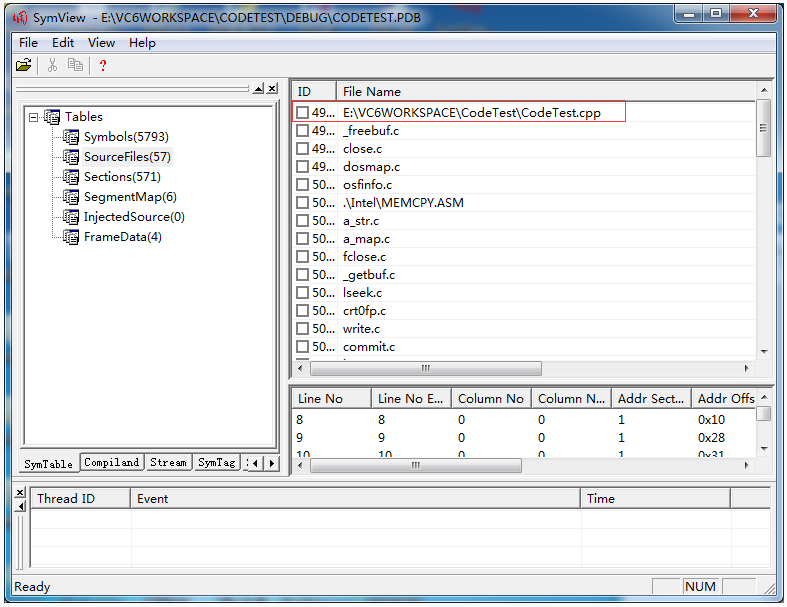
但是这里并没有add或者main函数的OFFSET啊,为什么呢?想想,此时只有一堆obj,真正的可执行模块还没有生成出来呢,何来的可执行模块的OFFSET呢。。。由此可以知道,这个OFFSET要在链接过程中,才可以确定。经过了链接之后,这些本来在obj里的调试信息,也就被收集到pdb文件中了,下面我们来找找add函数的OFFSET到底在哪里?使用SymView工具打开CodeTest.pdb文件,如下图:

可见,pdb中存储了add函数相关信息,不仅仅只有offset,而且此处并未直接记载add函数在哪个cpp里,这些关系都是通过索引来查找的,其实pdb文件的内部结构是很复杂的,要想解释清楚,其实很不容易,大家如果想知道pdb内部到底都有什么东西,可以参考一下《软件调试》第25章,但也是讲了个大概。
在我们观察的过程中,我们可以发现两个很主要的特征:

这样,我们可以得出一个结论:
Diomidis Spinellis是《代码阅读与代码质量》一书的作者。在GOTO阿姆斯特丹2016大会上,他就如何有效地调试软件和预防错误做了演讲。InfoQ采访了Spinellis,内容涉及发现和修复软件中的错误、软件调试的原则、如何提高调试效率、如何编写出不怎么需要调试的代码以及管理人员如何为错误预防和处理提供支持。
InfoQ:是什么让软件错误的发现和修复如此困难?
Diomidis Spinellis:如果你认为编写代码困难,那就尝试下代码调试吧。你编写了一个新的函数或方法,并加上一些语句形成某个只是貌似正确的东西。当你调试一个程序的时候,你要面对数千或数百万行貌似正确的代码,并设法找出其中的错误。这必定要困难许多。然后,你还要应对各种系统和层次之间的复杂交互、每秒执行数十亿次的CPU指令、难以再现的Bug以及来自生产环境系统的压力。
而且,课堂上很少教调试;从一切可能出错的东西辛苦得来的经验很难压缩到一次演讲中。此外,由于系统失败的方式各不相同,你必须不断地改进和调整你所用的工具和方法。你可以从观察开始,继之以数据分析,然后做一些试验,最后推断出Bug的原因。没有什么标准的初学者技能。
InfoQ:软件调试有什么一般原则吗?
Spinellis:很遗憾,由于软件会出现各种难以想象的错误情况,我不认为有什么可以在软件调试过程中遵循的一般原则。退而求其次,我归纳出了三大类方法:
高级策略,比如由故障特征推断出原因,或者确保某些代码满足了其前提条件;
方法和实践,比如确保Bug可以有效地再现,或者着重突出故障的影响;
通用工具,比如Unix命令行工具、跟踪(考虑下strace、dtrace和systemtap)工具和版本控制系统。
InfoQ:程序员做什么能够提高调试效率?
Spinellis:首先要为调试成功做好准备。让自己相信问题将会得到解决,留出足够的时间用于调试,不要分心,要坚持不懈,必要的时候,留待第二天解决。重要的是,要不断地在环境、工具和知识上投入。购买高效工作所需的软件和硬件。例如,如果软件生成大量的调试日志文件,你就应该有足够的磁盘空间、CPU处理能力和带宽,以便可以高效地处理它们。在调试的过程中,你很容易遇到千奇百怪的问题,因此,花些精力管理和优化自己的环境和工具配置。这包括按键绑定、别名、辅助脚本、快捷方式和工具配置;所有这些都可以显著地提高调试生产力。
InfoQ:有什么技术或方法可以编写出不怎么需要调试的代码吗?
Spinellis:当然!编写可维护的代码——可读、稳定、易于分析和修改的代码——带来的Bug也比较少。此外,像单元测试、代码审查这样的方法以及使用断言都有助于最小化进入生产环境的错误。
在设计时使用高级抽象(例如使用一个框架的算法或容器数据结构,而不是选择自己开发一种方案)可以减少代码和错误。另外,让程序易于调试也很重要。这包括为详细地记录日志提供便利,当出现内部错误时报告丰富的上下文信息,并将问题及崩溃的详细信息发送到一个中央存储库。
InfoQ:管理人员如何为组织里的错误预防和处理提供支持?
Spinellis:设定基本的过程有助于确保软件错误不会失控。部署并采用一个问题跟踪系统,用它把要处理的问题分类并排定优先级。将软件变更恰当地记录在进一个运作良好的版本管理系统里,并将它与问题跟踪系统联系起来;我经常仅仅通过仔细研究一个文件的历史和变更就修复了Bug。在软件建设方面,推广单元测试的应用,把软件的构建性能分析、静态分析和动态分析包含进来,并维护一个快速、精益、均衡的构建-测试周期。这有助于帮助开发人员尽早捕获Bug,并迅速修复。最后,在运维方面,逐步部署软件,允许新旧版本对比,努力确保所使用的工具和所部署的环境的多样性,并有组织地升级工具和库。
转自:http://lf.lnu.edu.cn/detail.jsp?id=55243
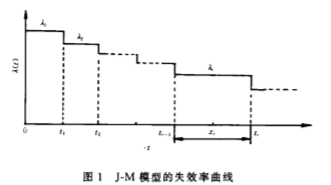
在硬 件可靠性 理 论 中 , 典 型 的失效 率 又( t ) 函 数是 一条 形 似“ 浴 盆” 的曲线 。 浴 盆 曲线 由三 段 构成 : 早 期故 障期 、 偶 然故 障期 、 耗损 故 障期 。 这种 曲线描 述 了事物 生命期 的 整个过 程 , 而 且具 有普遍 性 。 对 软件来 说 , 在调 试排错 阶 段 , 故 障易 被发现 , 也 易于 纠正 , 而且 在纠 正 中引 人新 故 障的概率 较小 , 因此 , 在 此 阶段 , 软件 失效率 是递 减 的 ; 当软件 中存在 的残 留错误 数减 少 到一 定数 目后 , 由于 故 障发 现率 较 低 , 故 障机 理 较复 杂 , 再 发现 的错 误 一 般就 难 以 得 到 纠 正 , 甚至 在纠正 过 程 中又 引人新 的错误 , 从 而使 得 软件 在运 行 阶 段失 效 率基 本保 持 不变 ; 在 软件 生存 的后期 , 由于 软件 应用 范 围 的扩 大 , 或 用 户对 软件 功 能 提 出更 新 的要求 , 从 而 导致 软件故 障增多 , 而 对其 纠 正越来 越 困 难 , 很 易引入新故 障 , 这样 使 得软件 失效 率呈 递增趋 势 , 直到软件寿命 期结 束 。 因 此 , 人 们把 浴盆 曲线 理论运 用到 软件 可 靠性领 域来 , 结合 软件 固 有 特性 , 提 出了许 多评 估软 件 可 靠性 的模 型 , 并 在实 践 中 得到 了广 泛 应用 , 取 得 了 良好 效 果 。
J一M 模型 就是 其 中 的一 种 , 它对 应 于浴 盆 曲 线 的第一 段 , 适 用 于软 件 调 试排 错 阶 段 , 这类 模 型 统称 为软件 出生 模型 ( Born-In模型)。
J 一M 模型 是 由 2 . Je lin s ki 和 P . B . M o r a n d a 于 19 7 2 年提 出的一种 确定 性模 型 , 简 称 J一 M 模型 , 用来描述 软件 错误 的检 测过 程 。 根据软件 特性 , 在 B o r n 一 n I 模 型 中规 定 了 四 条基本 假设 :
J一M 模 型 除 上述 四 条基 本假 设外 , 还增 加两 条假设 :
由上 述假设 可 得到 J一M 模 型 的失 效率 曲线 如 图 所示 :
失 效率 和 可靠 度 函 数 可 表示 为 :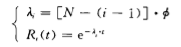
式 中 , N 表 示 开始 时 软 件 存 在 的 错 误 总 数 ; ∮表 示错 误 尺 寸 , 由假设 6 知∮是 个 常数 ; λ表示第( i一 1 ) 次 失 效 至 第 i 次 失 效 为止 , 这 段时 间 的失效 率 ; Ri ( t )表 示第( i 一 l ) 次失 效 至第 i 次失 效 为止 , 这段 时 间的软 件可靠性 函 数 。
式 中的 N 、 ∮必两参 数可 由极 大 似然法 估计 出来 。 如果 以 X i ( i=1 , 2 , … , n ) 表示被 观察 到 的一 系 列失 效 间 隔时 间 , 则 可 求 得第 n 次失 效后 的软件 可 靠性 函 数 估 计 , 以 及到 第 n + 1 次 失效 发生 的平均 间隔 时间 的估 计 。
J一M 模 型 的准确性 主要 取 决于 假设 的有效 性 。 在 软件 的调试排 错 阶段 , B o r n 一玩 模 型 的 四 个基 本假 设 是 比 较 合理 的 , 而 对于 J一M 模 型 所 附 加 的 两条 假设 , 在 软 件 工 程实 践 中具 有 一 定的缺 陷 。 首先 , 软件 的失效 率不 仅仅 取决 于 当前残 留错 误数 。 例如 , 一个 仅含 有 两个不 常碰到 的 错 误 ( 即错 误 尺 寸非 常小 , 如 0 5 死锁 等 ) 的 软件 5 1 , 另 一个 仅 含有 一个 经 常 出现 的错 误 ( 即 错误尺 寸较大 , 如 下标动 态超 界等 ) 的软件 5 2 。 显而 易见 S , 比 S : 可靠性 高 。 这样 , 假 设 5 就 不 成 立 。 其次 , 根 据 定义 , 错 误尺 寸是 某一 错误 导致 软件 失效 的概率 , 即对 软件 失效 率 的贡 献率 。 很 明显 , 错误 尺 寸越大 , 就越 容易 造成 软件 运行 失效 , 就越 容易被 发现 ; 反 之 , 错 误尺 寸越小 , 就越难 被发现 。 从 另一 角度说 , 越 先 发现 的错误 , 其错 误尺 寸越大 ; 而越 是 后发 现的错 误 , 其 错 误尺 寸越小 。 也 就是说 , 不 同的 软件 错误 , 其错 误尺 寸是 不相等 的 , 而是 随着被 发现 的顺 序 呈 递减 序列 。 这样 , 假设 6 也 不成 立 。 综 上 所述 , J一 M 模型 所 附加 的 两 条 假 设 , 对于 某 些 软 件 工程不 适 用 , 不 能很 好地 反映 软 件 的客观状 况 。 此外 , 适 用于 软 件 调试 阶段 的其它 出生模 型 , 如 B a y e S 模 型 、 Sh o o m a n 模 型 、 非 出错计数 模 型 等 , 也都存 在 类似 的 问题 , 为此 , 应 予改 进 。
软件 的失效 率不 仅与其 残 留错误 数 有关 , 而 且与每 个错 误 的错 误尺 寸有 关 。 如 果软件 残设 : 开始 时软件 的残 留错误 数 为 N , 其 相 应 的错 误尺 寸 为 ∮j( j= 1, 2 , … , N ) , 则 失 效 率与可靠性 函 数 由下 式表 示 :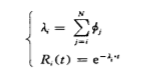
由于 错误 尺 寸随 着发现 的先后 次 序呈 递减 序列 , 因此 : ∮j>∮j+1; 。 如果 直接 用 ( 2 ) 式 进行分 析计算 , 比较 困难 。 为减化计算 , 根据 ( 3 ) 式 引人假 设 7;
假设 7 : 第 i ( + l ) 个 错 误 与 第 i 个 错 误 的 错 误 尺 寸 之 比 为 常 数 。 即 : ∮j+1=K*∮j( 0 < K < 1 )。
令 笋 ∮j=∮1 ,则,∮j=kj-1* ∮这样 ( 2 ) 式变 为 :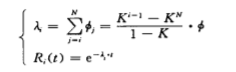

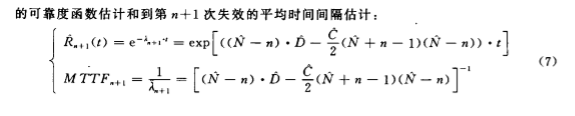
软件 测试 数据 是 软件 可靠性 评估 的基础 , 在软 件调 试排错 阶段 , 开 发人 员应详细记 录每 次 软件故 障 间隔 时间 , 保证 数据 的客 观性 和 准确性 。 对 收集 的数据 在用 于评估 前 , 应进 行初 步处 理 。 对重 复 出现 的故 障 , 应将 前 几 次故 障数据 剔除 , 保 留最后一 次真 正 消除软 件故 障的 那个数 据 , 即如 果第 i 次 出现 的故 障剔 除 不成 功 , 应将 x ` 删 除 , 同时 将 x 、 ,数 据 赋 予 x 、 , 即 : x 、 一` + , 一 t、 , 以 此 类 推 。 另外 , 如果 有 多个 程 序模 块 , 则 各模 块 的故 障数 据应 分别 记 录 , 不 要 混 淆 , 同一程 序模 块 的不 同版本 的软 件故 障数 据也 不要混 淆 。 收集到 一定 数量 的数 据后 , 就 可 以 进行 数据 分析 , 代 入评估模型 进 行评估 。
5 结束语
过 去 由于缺 少切 合 软件 开发 实际 的 软件 可靠 性评估 模 型 , 在 系统 工程 产 品 的可 靠性 分 析 和评估 中 , 只 对 硬件进 行 , 而将软 件 可靠 度视 为 1 , 即不 考虑软件 可靠 性 问题 。 事 实上 随着 硬件 可靠性 的不断 提高 , 软件 可靠性 显 得 日益突 出 。 而 且一 个软件 模块 , 开发 人员 调试到 什 么 程 度就 可结 束调 试排错 , 也 就是 如何 确定 软件 调试周 期也 是个 棘手 的问题 。 本文 正是基 于 这 种 情况 , 结 合 系统 工程 实 际 , 对 软件 调试 排错 阶段 的可 靠性 评估 模 型 进 行探 索 , 使 得软 件 开发 人员在 软件 调试 阶段 收集 n 个 数据 后 , 经 过 预处理 , 运 用本 文提供 的评估 模型 计算得 到 该 软件 残 留错 误总数 及下 一个 软件故 障出现 的平 均时 间 。 排除第 n 个软 件错 误后 , 也可 以估 计 出该软件 的平 均无 故障 时 间及 排 除剩 余软件 错 误还需 工作 的时 间 。 这 对于 开展 软件可 靠 性 增 长试验 , 合理 确定 调试 周期 , 调整 软件 开发 计划等有 较大 作用 。