SAP如何查询表名及字段
1 、根据事务代码或菜单打开窗口,在某个字段上按“F1"键,在弹出的帮助窗口中,点”技术信息“按钮
如:VA01打开销售订单创建窗口,在售达方上按F1键。
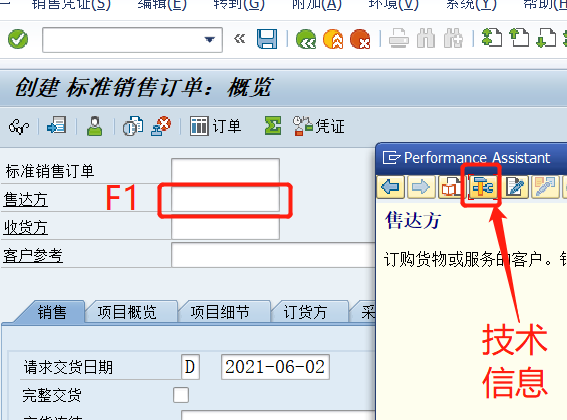
2、技术信息窗口

3、输入SE11
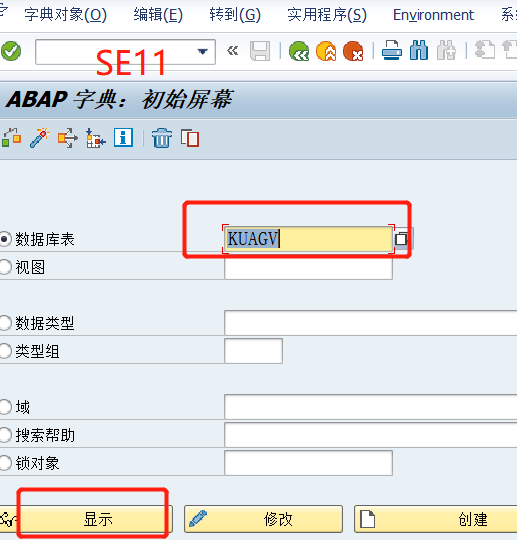
4、点击显示
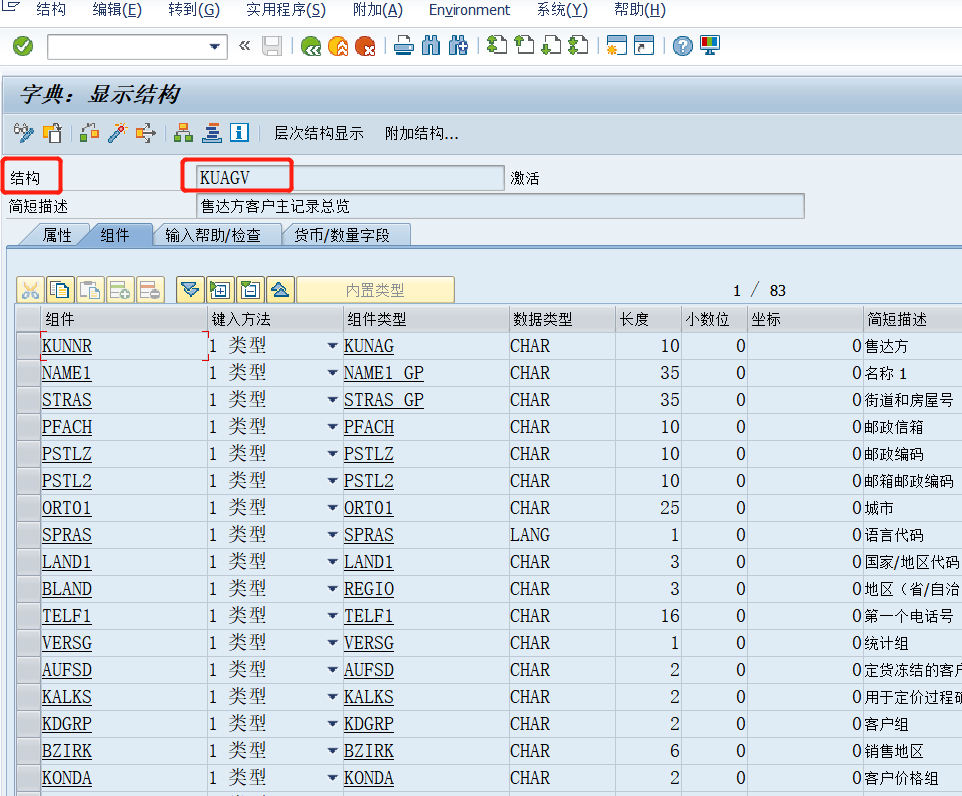
1 、根据事务代码或菜单打开窗口,在某个字段上按“F1"键,在弹出的帮助窗口中,点”技术信息“按钮
如:VA01打开销售订单创建窗口,在售达方上按F1键。
2、技术信息窗口
3、输入SE11
4、点击显示
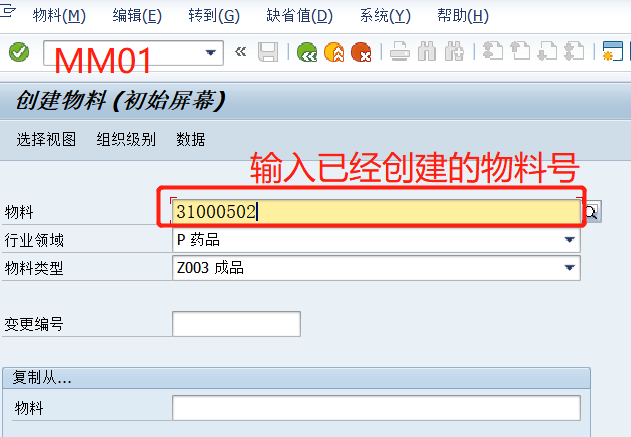
今天学习新建了一个物料,结果创建订单时只能在一个工厂用,想将其加到其它工厂中,试了N遍不得其解,请教内部专家后找到原因;
SAP中维护物料主数据到多个工厂,使用MM01代码,输入物料号,选择新的工厂,重新创建一次,有N个工厂要用就要维护N次;
前几日早上打开邮箱收到一封监控报警邮件:某某 ip 服务器 CPU 负载较高,请研发尽快排查解决,发送时间正好是凌晨。
其实早在去年我也处理过类似的问题,并记录下来:《一次生产 CPU 100% 排查优化实践》
不过本次问题产生的原因却和上次不太一样,大家可以接着往下看。
收到邮件后我马上登陆那台服务器,看了下案发现场还在(负载依然很高)。
于是我便利用这类问题的排查套路定位一遍。
首先利用 top -c 将系统资源使用情况实时显示出来 (-c 参数可以完整显示命令)。
接着输入大写 P 将应用按照 CPU 使用率排序,第一个就是使用率最高的程序。
果不其然就是我们的一个 Java 应用。
这个应用简单来说就是定时跑一些报表使的,每天凌晨会触发任务调度,正常情况下几个小时就会运行完毕。
常规操作第二步自然是得知道这个应用中最耗 CPU 的线程到底再干嘛。
利用 top -Hp pid 然后输入 P 依然可以按照 CPU 使用率将线程排序。
这时我们只需要记住线程的 ID 将其转换为 16 进制存储起来,通过 jstack pid >pid.log 生成日志文件,利用刚才保存的 16 进制进程 ID 去这个线程快照中搜索即可知道消耗 CPU 的线程在干啥了。
如果你嫌麻烦,我也强烈推荐阿里开源的问题定位神器 arthas 来定位问题。
比如上述操作便可精简为一个命令 thread -n 3 即可将最忙碌的三个线程快照打印出来,非常高效。
更多关于 arthas 使用教程请参考官方文档。
由于之前忘记截图了,这里我直接得出结论吧:
最忙绿的线程是一个 GC 线程,也就意味着它在忙着做垃圾回收。
排查到这里,有经验的老司机一定会想到:多半是应用内存使用有问题导致的。
于是我通过 jstat -gcutil pid 200 50 将内存使用、gc 回收状况打印出来(每隔 200ms 打印 50次)。
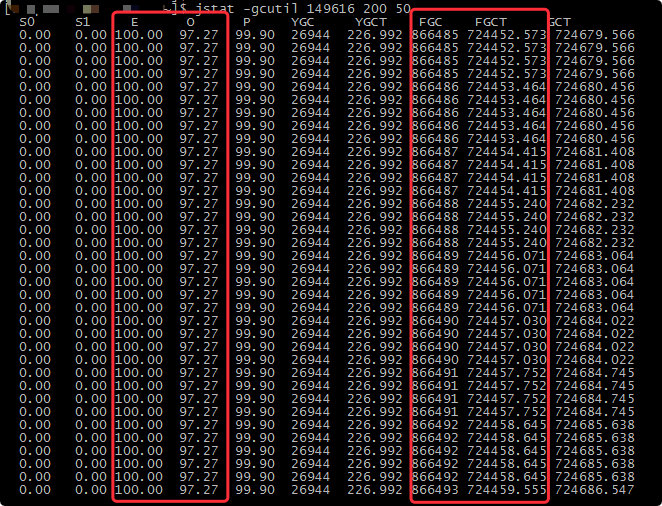
从图中可以得到以下几个信息:
Eden 区和 old 区都快占满了,可见内存回收是有问题的。
fgc 回收频次很高,10s 之内发生了 8 次回收((866493-866485)/ (200 *5))。
持续的时间较长,fgc 已经发生了 8W 多次。
既然是初步定位是内存问题,所以还是得拿一份内存快照分析才能最终定位到问题。
通过命令 jmap -dump:live,format=b,file=dump.hprof pid 可以导出一份快照文件。
这时就得借助 MAT 这类的分析工具出马了。
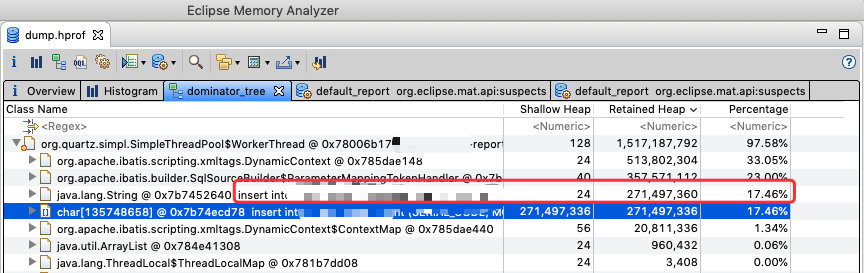
通过这张图其实很明显可以看出,在内存中存在一个非常大的字符串,而这个字符串正好是被这个定时任务的线程引用着。

大概算了一下这个字符串所占的内存为 258m 左右,就一个字符串来说已经是非常大的对象了。
那这个字符串是咋产生的呢?
其实看上图中的引用关系及字符串的内容不难看出这是一个 insert 的 SQL 语句。
这时不得不赞叹 MAT 这个工具,他还能帮你预测出这个内存快照可能出现问题地方同时给出线程快照。

最终通过这个线程快照找到了具体的业务代码:
他调用一个写入数据库的方法,而这个方法会拼接一个 insert 语句,其中的 values 是循环拼接生成,大概如下:
<insert id="insert" parameterType="java.util.List"> insert into xx (files) values <foreach collection="list" item="item" separator=","> xxx </foreach> </insert>
所以一旦这个 list 非常大时,这个拼接的 SQL 语句也会很长。
通过刚才的内存分析其实可以看出这个 List 也是非常大的,也就导致了最终的这个 insert 语句占用的内存巨大。
既然找到问题原因那就好解决了,有两个方向:
控制源头 List 的大小,这个 List 也是从某张表中获取的数据,可以分页获取;这样后续的 insert 语句就会减小。
控制批量写入数据的大小,其实本质还是要把这个拼接的 SQL 长度降下来。
整个的写入效率需要重新评估。
本次问题从分析到解决花的时间并不长,也还比较典型,其中的过程再总结一下:
首先定位消耗 CPU 进程。
再定位消耗 CPU 的具体线程。
内存问题 dump 出快照进行分析。
得出结论,调整代码,测试结果。
最后愿大家都别接到生产告警。
scrapy 是一个为了爬取网站数据,提取结构性数据而编写的应用框架。关于框架使用的更多详情可浏览官方文档,本篇文章展示的是爬取漫画图片的大体实现过程。
首先是 scrapy 的安装,博主用的是Mac系统,直接运行命令行:
pip install Scrapy
对于html节点信息的提取使用了 Beautiful Soup 库,大概的用法可见之前的一篇文章,直接通过命令安装:
pip install beautifulsoup4
对于目标网页的 Beautiful Soup 对象初始化需要用到 html5lib 解释器,安装的命令:
pip install html5lib
安装完成后,直接在命令行运行命令:
scrapy
可以看到如下输出结果,这时候证明scrapy安装完成了。
Scrapy 1.2.1 - no active projectUsage: scrapy <command> [options] [args]Available commands: bench Run quick benchmark test commands fetch Fetch a URL using the Scrapy downloader genspider Generate new spider using pre-defined templates runspider Run a self-contained spider (without creating a project) settings Get settings values ...
scrapy startproject Comics
Comics文件结构为:|____Comics| |______init__.py| |______pycache__| |____items.py| |____pipelines.py| |____settings.py| |____spiders| | |______init__.py| | |______pycache__|____scrapy.cfg
find . -print | sed -e 's;[^/]*/;|____;g;s;____|; |;g'
scrapy.Spider 的子类。Comics/spiders 文件路径下创建 comics.py 文件。comics.py 的具体实现:#coding:utf-8import scrapyclass Comics(scrapy.Spider): name = "comics" def start_requests(self): urls = ['http://www.xeall.com/shenshi'] for url in urls: yield scrapy.Request(url=url, callback=self.parse) def parse(self, response): self.log(response.body);scrapy.Spider的子类,其中的name属性为该爬虫的唯一标识,作为scrapy爬取命令的参数。其他方法的属性后续再解释。Comics路径下,运行命令,启动爬虫任务开始爬取网页。scrapy crawl comics
2016-11-26 22:04:35 [scrapy] INFO: Scrapy 1.2.1 started (bot: Comics)2016-11-26 22:04:35 [scrapy] INFO: Overridden settings: {'ROBOTSTXT_OBEY': True, 'BOT_NAME': 'Comics', 'NEWSPIDER_MODULE': 'Comics.spiders', 'SPIDER_MODULES': ['Comics.spiders']}2016-11-26 22:04:35 [scrapy] INFO: Enabled extensions:['scrapy.extensions.corestats.CoreStats', 'scrapy.extensions.telnet.TelnetConsole', 'scrapy.extensions.logstats.LogStats'] ...
http://www.xeall.com/shenshi
url我们放在了start_requests函数的urls数组中。其中start_requests是重载了父类的方法,爬虫任务开始时会执行到这个方法。start_requests方法中主要的执行在这一行代码:请求指定的url,请求完成后调用对应的回调函数self.parsescrapy.Request(url=url, callback=self.parse)
#coding:utf-8import scrapyclass Comics(scrapy.Spider): name = "comics" start_urls = ['http://www.xeall.com/shenshi'] def parse(self, response): self.log(response.body);start_urls是框架中提供的属性,为一个包含目标网页url的数组,设置了start_urls的值后,不需要重载start_requests方法,爬虫也会依次爬取start_urls中的地址,并在请求完成后自动调用parse作为回调方法。
parse方法。BeautifulSoup库from bs4 import BeautifulSoup
BeautifulSoup初始化。def parse(self, response): content = response.body; soup = BeautifulSoup(content, "html5lib")
html5lib解释器,若没安装这里会报错。lxml,此时解析出的结果会有问题,而导致无法进行接下来的数据提取。所以当发现有时候提取结果又问题时,打印soup看看是否正确。listcon的ul标签,通过listcon类能唯一确认对应的标签listcon_tag = soup.find('ul', class_='listcon')find方法意为寻找class为listcon的ul标签,返回的是对应标签的所有内容。href属性的a标签,这些a标签即为每部漫画对应的信息。com_a_list = listcon_tag.find_all('a', attrs={'href': True})href属性合成完整能访问的url地址,保存在一个数组中。comics_url_list = []base = 'http://www.xeall.com' for tag_a in com_a_list: url = base + tag_a['href'] comics_url_list.append(url)
comics_url_list数组即包含当前页每部漫画的url。
href属性的a标签page_tag = soup.find('ul', class_='pagelist')page_a_list = page_tag.find_all('a', attrs={'href': True})a标签中,倒数第一个代表末页的url,倒数第二个代表下一页的url,因此,我们可以通过取page_a_list数组中倒数第二个元素来获取到下一页的url。select控件来判断。通过源码可以判断,当前页对应的option标签会具有selected属性,下图为当前页为第一页select_tag = soup.find('select', attrs={'name': 'sldd'})option_list = select_tag.find_all('option')last_option = option_list[-1]current_option = select_tag.find('option' ,attrs={'selected': True})is_last = (last_option.string == current_option.string)parse方法做处理if not is_last: next_page = 'http://www.xeall.com/shenshi/' + page_a_list[-2]['href'] if next_page is not None: print('\n------ parse next page --------') print(next_page) yield scrapy.Request(next_page, callback=self.parse)
parse方法中提取到当前页的所有漫画url时,就可以开始对每部漫画进行处理。comics_url_list数组的下方加上下面代码:for url in comics_url_list: yield scrapy.Request(url=url, callback=self.comics_parse)
self.comics_parse,comics_parse方法用来处理每部漫画,下面为具体实现。
BeautifulSoup,和前面基本一致def comics_parse(self, response): content = response.body; soup = BeautifulSoup(content, "html5lib")
class为pagelist的ul标签page_list_tag = soup.find('ul', class_='pagelist')li标签的class属性thisclass,以此获取到当前页页数current_li = page_list_tag.find('li', class_='thisclass')page_num = current_li.a.stringli_tag = soup.find('li', id='imgshow')img_tag = li_tag.find('img')img_url = img_tag['src']title = img_tag['alt']self.save_img(page_num, title, img_url)
save_img,具体完整实现如下# 先导入库import osimport urllibimport zlibdef save_img(self, img_mun, title, img_url): # 将图片保存到本地 self.log('saving pic: ' + img_url) # 保存漫画的文件夹 document = '/Users/moshuqi/Desktop/cartoon' # 每部漫画的文件名以标题命名 comics_path = document + '/' + title exists = os.path.exists(comics_path) if not exists: self.log('create document: ' + title) os.makedirs(comics_path) # 每张图片以页数命名 pic_name = comics_path + '/' + img_mun + '.jpg' # 检查图片是否已经下载到本地,若存在则不再重新下载 exists = os.path.exists(pic_name) if exists: self.log('pic exists: ' + pic_name) return try: user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)' headers = { 'User-Agent' : user_agent } req = urllib.request.Request(img_url, headers=headers) response = urllib.request.urlopen(req, timeout=30) # 请求返回到的数据 data = response.read() # 若返回数据为压缩数据需要先进行解压 if response.info().get('Content-Encoding') == 'gzip': data = zlib.decompress(data, 16 + zlib.MAX_WBITS) # 图片保存到本地 fp = open(pic_name, "wb") fp.write(data) fp.close self.log('save image finished:' + pic_name) except Exception as e: self.log('save image error.') self.log(e)document为本地指定的文件夹,可自定义。页数.jpg的格式命名,若本地已存在同名图片则不再进行重新下载,一般用在反复开始任务的情况下进行判断以避免对已存在图片进行重复请求。response.info().get('Content-Encoding')的类型来进行判断。压缩过的图片要先经过zlib.decompress解压再保存到本地,否则图片打不开。
href属性为#时为漫画的最后一页a_tag_list = page_list_tag.find_all('a')next_page = a_tag_list[-1]['href']if next_page == '#': self.log('parse comics:' + title + 'finished.')else: next_page = 'http://www.xeall.com/shenshi/' + next_page yield scrapy.Request(next_page, callback=self.comics_parse)yield scrapy.Request(next_page, callback=self.comics_parse)
FilesPipeline、ImagesPipeline来保存下载的文件或者图片。XPath类用来对网页信息进行提取,这个的效率要比BeautifulSoup高,也可以通过专门的item类将爬取的数据结果保存作为一个类返回。具体请查阅官网。
C++程序设计中使用堆内存是非常频繁的操作,堆内存的申请和释放都由程序员自己管理。程序员自己管理堆内存可以提高了程序的效率,但是整体来说堆内存的管理是麻烦的,C++11中引入了智能指针的概念,方便管理堆内存。使用普通指针,容易造成堆内存泄露(忘记释放),二次释放,程序发生异常时内存泄露等问题等,使用智能指针能更好的管理堆内存。
理解智能指针需要从下面三个层次:
1、从较浅的层面看,智能指针是利用了一种叫做RAII(资源获取即初始化)的技术对普通的指针进行封装,这使得智能指针实质是一个对象,行为表现的却像一个指针。
2、智能指针的作用是防止忘记调用delete释放内存和程序异常的进入catch块忘记释放内存。另外指针的释放时机也是非常有考究的,多次释放同一个指针会造成程序崩溃,这些都可以通过智能指针来解决。
3、智能指针还有一个作用是把值语义转换成引用语义。C++和Java有一处最大的区别在于语义不同,在Java里面下列代码:
Animal a = new Animal();
Animal b = a;
你当然知道,这里其实只生成了一个对象,a和b仅仅是把持对象的引用而已。但在C++中不是这样,
Animal a;
Animal b = a;
这里却是就是生成了两个对象。
关于值语言参考这篇文章http://www.cnblogs.com/Solstice/archive/2011/08/16/2141515.html
智能指针在C++11版本之后提供,包含在头文件中,shared_ptr、unique_ptr、weak_ptr
shared_ptr多个指针指向相同的对象。shared_ptr使用引用计数,每一个shared_ptr的拷贝都指向相同的内存。每使用他一次,内部的引用计数加1,每析构一次,内部的引用计数减1,减为0时,自动删除所指向的堆内存。shared_ptr内部的引用计数是线程安全的,但是对象的读取需要加锁。
初始化。智能指针是个模板类,可以指定类型,传入指针通过构造函数初始化。也可以使用make_shared函数初始化。不能将指针直接赋值给一个智能指针,一个是类,一个是指针。例如std::shared_ptr p4 = new int(1);的写法是错误的
拷贝和赋值。拷贝使得对象的引用计数增加1,赋值使得原对象引用计数减1,当计数为0时,自动释放内存。后来指向的对象引用计数加1,指向后来的对象
get函数获取原始指针
注意不要用一个原始指针初始化多个shared_ptr,否则会造成二次释放同一内存
注意避免循环引用,shared_ptr的一个最大的陷阱是循环引用,循环,循环引用会导致堆内存无法正确释放,导致内存泄漏。循环引用在weak_ptr中介绍。
#include <iostream>
#include <memory>
int main() {
{
int a = 10;
std::shared_ptr<int> ptra = std::make_shared<int>(a);
std::shared_ptr<int> ptra2(ptra); //copy
std::cout << ptra.use_count() << std::endl;
int b = 20;
int *pb = &a;
//std::shared_ptr<int> ptrb = pb; //error
std::shared_ptr<int> ptrb = std::make_shared<int>(b);
ptra2 = ptrb; //assign
pb = ptrb.get(); //获取原始指针
std::cout << ptra.use_count() << std::endl;
std::cout << ptrb.use_count() << std::endl;
}
}
unique_ptr“唯一”拥有其所指对象,同一时刻只能有一个unique_ptr指向给定对象(通过禁止拷贝语义、只有移动语义来实现)。相比与原始指针unique_ptr用于其RAII的特性,使得在出现异常的情况下,动态资源能得到释放。unique_ptr指针本身的生命周期:从unique_ptr指针创建时开始,直到离开作用域。离开作用域时,若其指向对象,则将其所指对象销毁(默认使用delete操作符,用户可指定其他操作)。unique_ptr指针与其所指对象的关系:在智能指针生命周期内,可以改变智能指针所指对象,如创建智能指针时通过构造函数指定、通过reset方法重新指定、通过release方法释放所有权、通过移动语义转移所有权。
#include <iostream>
#include <memory>
int main() {
{
std::unique_ptr<int> uptr(new int(10)); //绑定动态对象
//std::unique_ptr<int> uptr2 = uptr; //不能賦值
//std::unique_ptr<int> uptr2(uptr); //不能拷貝
std::unique_ptr<int> uptr2 = std::move(uptr); //轉換所有權
uptr2.release(); //释放所有权
}
//超過uptr的作用域,內存釋放
}
weak_ptr是为了配合shared_ptr而引入的一种智能指针,因为它不具有普通指针的行为,没有重载operator*和->,它的最大作用在于协助shared_ptr工作,像旁观者那样观测资源的使用情况。weak_ptr可以从一个shared_ptr或者另一个weak_ptr对象构造,获得资源的观测权。但weak_ptr没有共享资源,它的构造不会引起指针引用计数的增加。使用weak_ptr的成员函数use_count()可以观测资源的引用计数,另一个成员函数expired()的功能等价于use_count()==0,但更快,表示被观测的资源(也就是shared_ptr的管理的资源)已经不复存在。weak_ptr可以使用一个非常重要的成员函数lock()从被观测的shared_ptr获得一个可用的shared_ptr对象, 从而操作资源。但当expired()==true的时候,lock()函数将返回一个存储空指针的shared_ptr。
#include <iostream>
#include <memory>
int main() {
{
std::shared_ptr<int> sh_ptr = std::make_shared<int>(10);
std::cout << sh_ptr.use_count() << std::endl;
std::weak_ptr<int> wp(sh_ptr);
std::cout << wp.use_count() << std::endl;
if(!wp.expired()){
std::shared_ptr<int> sh_ptr2 = wp.lock(); //get another shared_ptr
*sh_ptr = 100;
std::cout << wp.use_count() << std::endl;
}
}
//delete memory
}
考虑一个简单的对象建模——家长与子女:a Parent has a Child, a Child knowshis/her Parent。在Java 里边很好写,不用担心内存泄漏,也不用担心空悬指针,只要正确初始化myChild 和myParent,那么Java 程序员就不用担心出现访问错误。一个handle 是否有效,只需要判断其是否non null。
public class Parent
{
private Child myChild;
}
public class Child
{
private Parent myParent;
}
在C++里边就要为资源管理费一番脑筋。如果使用原始指针作为成员,Child和Parent由谁释放?那么如何保证指针的有效性?如何防止出现空悬指针?这些问题是C++面向对象编程麻烦的问题,现在可以借助smart pointer把对象语义(pointer)转变为值(value)语义,shared_ptr轻松解决生命周期的问题,不必担心空悬指针。但是这个模型存在循环引用的问题,注意其中一个指针应该为weak_ptr。
原始指针的做法,容易出错
#include <iostream>
#include <memory>
class Child;
class Parent;
class Parent {
private:
Child* myChild;
public:
void setChild(Child* ch) {
this->myChild = ch;
}
void doSomething() {
if (this->myChild) {
}
}
~Parent() {
delete myChild;
}
};
class Child {
private:
Parent* myParent;
public:
void setPartent(Parent* p) {
this->myParent = p;
}
void doSomething() {
if (this->myParent) {
}
}
~Child() {
delete myParent;
}
};
int main() {
{
Parent* p = new Parent;
Child* c = new Child;
p->setChild(c);
c->setPartent(p);
delete c; //only delete one
}
return 0;
}
循环引用内存泄露的问题
#include <iostream>
#include <memory>
class Child;
class Parent;
class Parent {
private:
std::shared_ptr<Child> ChildPtr;
public:
void setChild(std::shared_ptr<Child> child) {
this->ChildPtr = child;
}
void doSomething() {
if (this->ChildPtr.use_count()) {
}
}
~Parent() {
}
};
class Child {
private:
std::shared_ptr<Parent> ParentPtr;
public:
void setPartent(std::shared_ptr<Parent> parent) {
this->ParentPtr = parent;
}
void doSomething() {
if (this->ParentPtr.use_count()) {
}
}
~Child() {
}
};
int main() {
std::weak_ptr<Parent> wpp;
std::weak_ptr<Child> wpc;
{
std::shared_ptr<Parent> p(new Parent);
std::shared_ptr<Child> c(new Child);
p->setChild(c);
c->setPartent(p);
wpp = p;
wpc = c;
std::cout << p.use_count() << std::endl; // 2
std::cout << c.use_count() << std::endl; // 2
}
std::cout << wpp.use_count() << std::endl; // 1
std::cout << wpc.use_count() << std::endl; // 1
return 0;
}
正确的做法
#include <iostream>
#include <memory>
class Child;
class Parent;
class Parent {
private:
//std::shared_ptr<Child> ChildPtr;
std::weak_ptr<Child> ChildPtr;
public:
void setChild(std::shared_ptr<Child> child) {
this->ChildPtr = child;
}
void doSomething() {
//new shared_ptr
if (this->ChildPtr.lock()) {
}
}
~Parent() {
}
};
class Child {
private:
std::shared_ptr<Parent> ParentPtr;
public:
void setPartent(std::shared_ptr<Parent> parent) {
this->ParentPtr = parent;
}
void doSomething() {
if (this->ParentPtr.use_count()) {
}
}
~Child() {
}
};
int main() {
std::weak_ptr<Parent> wpp;
std::weak_ptr<Child> wpc;
{
std::shared_ptr<Parent> p(new Parent);
std::shared_ptr<Child> c(new Child);
p->setChild(c);
c->setPartent(p);
wpp = p;
wpc = c;
std::cout << p.use_count() << std::endl; // 2
std::cout << c.use_count() << std::endl; // 1
}
std::cout << wpp.use_count() << std::endl; // 0
std::cout << wpc.use_count() << std::endl; // 0
return 0;
}
下面是一个简单智能指针的demo。智能指针类将一个计数器与类指向的对象相关联,引用计数跟踪该类有多少个对象共享同一指针。每次创建类的新对象时,初始化指针并将引用计数置为1;当对象作为另一对象的副本而创建时,拷贝构造函数拷贝指针并增加与之相应的引用计数;对一个对象进行赋值时,赋值操作符减少左操作数所指对象的引用计数(如果引用计数为减至0,则删除对象),并增加右操作数所指对象的引用计数;调用析构函数时,构造函数减少引用计数(如果引用计数减至0,则删除基础对象)。智能指针就是模拟指针动作的类。所有的智能指针都会重载 -> 和 * 操作符。智能指针还有许多其他功能,比较有用的是自动销毁。这主要是利用栈对象的有限作用域以及临时对象(有限作用域实现)析构函数释放内存。
1 #include <iostream>
2 #include <memory>
3
4 template<typename T>
5 class SmartPointer {
6 private:
7 T* _ptr;
8 size_t* _count;
9 public:
10 SmartPointer(T* ptr = nullptr) :
11 _ptr(ptr) {
12 if (_ptr) {
13 _count = new size_t(1);
14 } else {
15 _count = new size_t(0);
16 }
17 }
18
19 SmartPointer(const SmartPointer& ptr) {
20 if (this != &ptr) {
21 this->_ptr = ptr._ptr;
22 this->_count = ptr._count;
23 (*this->_count)++;
24 }
25 }
26
27 SmartPointer& operator=(const SmartPointer& ptr) {
28 if (this->_ptr == ptr._ptr) {
29 return *this;
30 }
31
32 if (this->_ptr) {
33 (*this->_count)--;
34 if (this->_count == 0) {
35 delete this->_ptr;
36 delete this->_count;
37 }
38 }
39
40 this->_ptr = ptr._ptr;
41 this->_count = ptr._count;
42 (*this->_count)++;
43 return *this;
44 }
45
46 T& operator*() {
47 assert(this->_ptr == nullptr);
48 return *(this->_ptr);
49
50 }
51
52 T* operator->() {
53 assert(this->_ptr == nullptr);
54 return this->_ptr;
55 }
56
57 ~SmartPointer() {
58 (*this->_count)--;
59 if (*this->_count == 0) {
60 delete this->_ptr;
61 delete this->_count;
62 }
63 }
64
65 size_t use_count(){
66 return *this->_count;
67 }
68 };
69
70 int main() {
71 {
72 SmartPointer<int> sp(new int(10));
73 SmartPointer<int> sp2(sp);
74 SmartPointer<int> sp3(new int(20));
75 sp2 = sp3;
76 std::cout << sp.use_count() << std::endl;
77 std::cout << sp3.use_count() << std::endl;
78 }
79 //delete operator
80 }