WxPython跨平台开发框架之列表数据的通用打印处理
在WxPython跨平台开发框架中,我们大多数情况下,数据记录通过wx.Grid的数据表格进行展示,其中表格的数据记录的显示和相关处理,通过在基类窗体 BaseListFrame 进行统一的处理,因此对于常规的数据记录打印,我们也可以在其中集成相关的打印处理,本篇随笔介绍如何利用WxPython内置的打印数据组件实现列表数据的自定义打印处理,以及对记录进行分页等常规操作。
1、WxPython内置的打印数据组件
wx.PrintPreview
、
wx.Printer
和
wx.Printout
是 wxPython 提供的用于打印功能的核心类。它们帮助开发者在程序中实现打印和打印预览功能。下面是关于这三个类的详细介绍及其使用方法。
1)
wx.Printout
wx.Printout
是一个抽象类,通常需要被子类化以便在打印时自定义页面内容。你可以通过继承
wx.Printout
类来实现自定义打印内容,重写
OnPrintPage
方法来决定每一页的打印内容。
常用方法:
OnPrintPage(page)
: 该方法是打印过程中每一页的核心方法。你需要在这里绘制要打印的内容,例如文本、图片、图形等。每次页面需要绘制时,该方法会被调用。GetDC()
: 获取一个打印设备上下文(
wx.DC
对象),用于在页面上绘制内容。HasPage(page)
: 该方法用于检查是否有足够的内容来填充打印页面,返回
True
或
False
。
简单的wx.PrintOut的子类继承处理如下所示。
importwxclassMyPrintout(wx.Printout):def __init__(self):
super().__init__()defOnPrintPage(self, page):
dc=self.GetDC()
dc.SetFont(wx.Font(10, wx.FONTFAMILY_SWISS, wx.FONTSTYLE_NORMAL, wx.FONTWEIGHT_NORMAL))
dc.DrawText("Hello, this is a print test!", 100, 100)return True
一般情况下,我们肯定会添加很多相关的绘制逻辑处理,这里只是简单的介绍。
2)
wx.Printer
wx.Printer
是用来执行实际打印操作的类。它用于与打印机进行交互,发送页面内容到打印机。你可以使用
wx.Printer
来选择打印机、启动打印作业并发送打印内容。
常用方法:
Print(printout)
: 用于启动打印操作,将
printout
对象中的内容发送到打印机。GetCurrentPrinterName()
: 获取当前选定的打印机名称。SetPageSize(width, height)
: 设置打印页面的大小。SetPrintData(print_data)
: 设置打印的数据,控制打印的纸张大小、打印质量等
3)
wx.PrintPreview
wx.PrintPreview
用于实现打印预览功能,它允许你查看打印内容的预览,而不是直接将内容发送到打印机。通过打印预览,你可以看到打印文档的外观,并进行调整(如分页、内容布局等)。
常用方法:
IsOk()
: 检查打印预览是否成功创建。Show()
: 显示打印预览窗口。SetPagesPerPreview(pages)
: 设置每个预览页面显示的页面数。
通常,
wx.PrintPreview
是在打印机选择之前使用的,它会展示打印内容的预览。预览确认后,用户可以选择继续打印,程序则使用
wx.Printer
实际执行打印操作。
绘制二维表的打印预览可以通过在
wx.Printout
类的
OnPrintPage
方法中逐行逐列绘制表格内容。为了实现更复杂的表格布局,通常需要计算每一行和每一列的位置,确保文本不会超出页面边界,并在必要时分页。
如果需要在 wxPython 中实现打印预览,可以使用
wx.PrintPreview
类来生成打印预览。这个类允许你在显示打印预览时,不直接打印内容,而是显示一个打印的“模拟”视图,用户可以在此视图中查看打印效果,决定是否继续打印。
高级功能:表格样式
如果你需要更复杂的表格样式(例如,添加边框、背景色或其他格式化功能),你可以通过
dc.SetPen()
、
dc.SetBrush()
等方法来实现。
示例:给表格添加边框
defdraw_table_border(dc, x_pos, y_pos, width, height):
dc.SetPen(wx.Pen(wx.Colour(0, 0, 0)))#设置边框颜色 dc.SetBrush(wx.Brush(wx.Colour(255, 255, 255))) #设置背景颜色 dc.DrawRectangle(x_pos, y_pos, width, height)
你可以在
OnPrintPage
方法中调用此函数,为每个单元格添加边框。
2、在框架的基类窗体中实现自定义打印及分页处理
在我的WxPython跨平台开发框架中,我们对于常规窗体列表界面做了抽象处理,一般绝大多数的逻辑封装在基类上,基类提供一些可重写的函数给子类实现弹性化的处理。
如下是基类窗体和其他窗体之间的集成关系。

一般列表界面,如下所示。
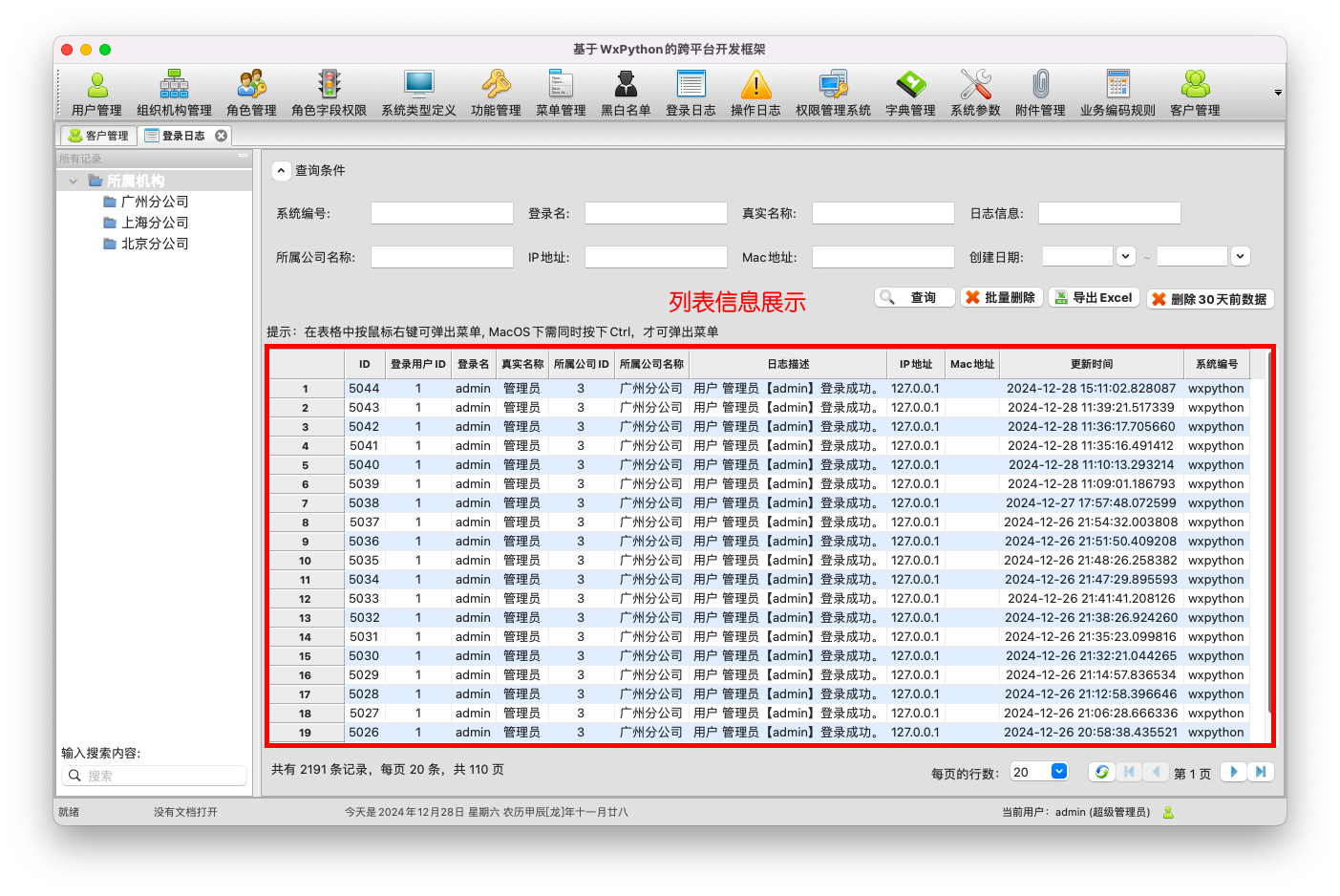
我们打印模块的处理,需要把这些列表的记录显示在打印预览界面上,并决定是否继续打印即可。
前面介绍了wx.PrintOut的子类处理,只是简单的输出一些文本信息,一般对于更复杂的打印需求(例如表格或多页文档),你可以在
OnPrintPage
中使用更复杂的绘制逻辑。例如,绘制多个表格行或根据页数拆分内容等等。
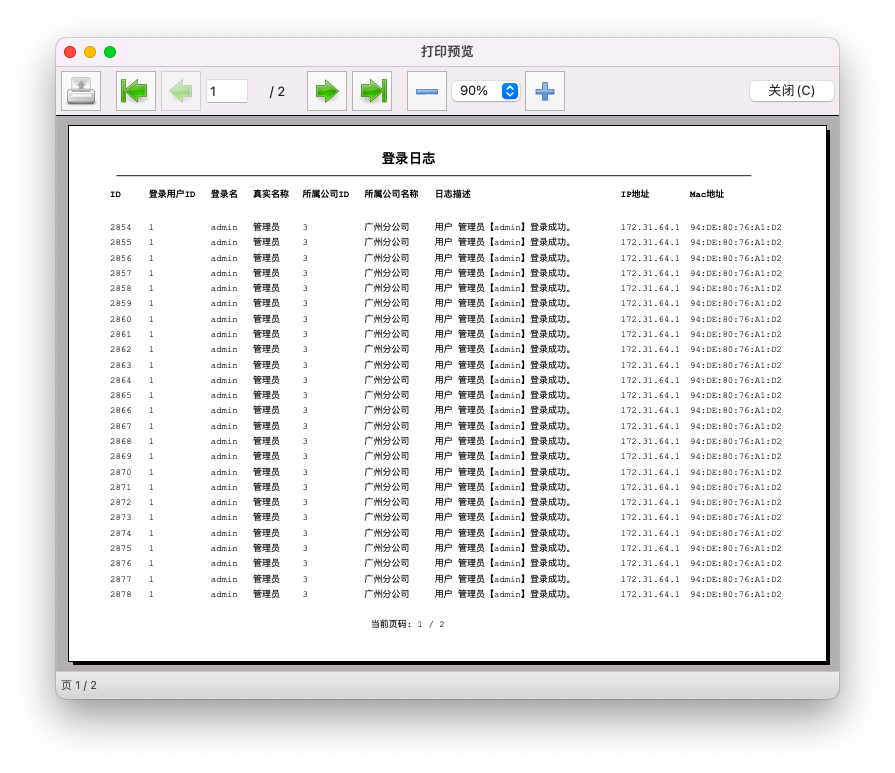
我们先来看看实现后的打印预览界面效果,有一个感官认识后再继续探寻它的实现机制。
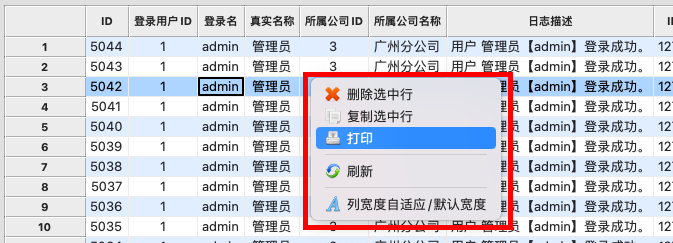
打印预览入口,在列表界面上右键,弹出打印菜单,如下界面所示。
打印预览界面如下所示。
我们来看看,对于列表数据,我们是如何一步步通过自定义的方式实现打印的内容绘制的。
打印有几个注意的地方,由于不同的操作系统或者不同的设置可能会导致打印面板的尺寸有所差异,因此最好统一转换为一个逻辑的尺寸处理;另外分页的处理是关键,需要根据字体文字计算出你绘制一行所需要的高度,然后根据操作的页面高度计算可以绘制的行数,然后在表格行记录中循环处理,判断达到每页的行数就换行即可。
在我们的WxPython跨平台框架中列表入口菜单的实现如下代码所示,主要就是调用MyPrintOut的自定义对象,然后调用PrintPreview进行打印预览窗体的显示即可,如下代码所示。
def OnPrint(self, event: wx.Event) ->None:"""打印表格""" #创建打印数据对象 pageData =wx.PrintData()
pageData.SetPaperId(wx.PAPER_A4)#设置纸张类型为 A4 pageData.SetOrientation(wx.LANDSCAPE) #设置纸张方向为纵向 #将打印数据设置到打印机对象 data =wx.PrintDialogData(pageData)#窗口标题 page_title =self.GetTitle()#创建打印输出对象 printout =ctrl.MyPrintout(self.grid, page_title)
printout2=ctrl.MyPrintout(self.grid, page_title)#创建打印机对象,并将打印数据传递给打印机 #printer = wx.Printer(data) preview = wx.PrintPreview(printout, printout2, data=data)ifpreview.IsOk():
preview.SetZoom(100)
frame=wx.PreviewFrame(
preview, self,"打印预览", pos=self.GetPosition(), size=self.GetSize()
)
frame.Initialize()
frame.Show(True)
wx.PrintPreview需要接受两个PrintOut对象,如代码:printout, printout2
wx.PrintData 主要就是指定页面尺寸及布局等相关信息,具体的逻辑还是在自定义的 MyPrintout 类里面,它接受当前的wx.Grid对象和当前页面的标题。
而ctrl.MyPrintOut是我们根据需要打印的二维表内容进行的逻辑封装,它们的类初始化代码如下。
classMyPrintout(wx.Printout):"""创建一个自定义的 wx.Printout 类,在其中定义如何打印 wx.Grid 的内容。""" def __init__(
self,
grid: gridlib.Grid,
title: str= "打印标题",
margins=(wx.Point(10, 10), wx.Point(10, 10)),
):
super().__init__()
self.grid=grid
self.title=title
self.margins=margins#获取网格的行列数 self.row_count =self.grid.GetNumberRows()
self.col_count=self.grid.GetNumberCols()
self.current_row= 0 #记录当前打印的行数
我们记录表格对象,以及表格的行数和列数,以及当前打印的行数,默认从0开始,在每次计算分页的时候,需要知道当前的记录才能接着绘制剩余的记录。
我们通过转换逻辑单位,获得绘制设备的页面高度和宽度,然后每行记录的高度,我们根据内容的实际高度+一定的空白间距,如下代码
font =wx.Font(
FONTSIZE, wx.FONTFAMILY_TELETYPE, wx.FONTSTYLE_NORMAL, wx.FONTWEIGHT_NORMAL
)
dc.SetFont(font)#计算每行的高度 self.lineHeight = dc.GetCharHeight() + 5 #加上5像素的间距
计算每页可以绘制多少行,需要记录摒除标题内容、表格标题行以及相关空白,剩下的页面高度除以一行的高度,进行计算获得即可。如下代码所示。
#标题高度 + 标题底部空白行高度 + 表头高度 y_offset = 20 + 20 + 20 #计算每页可以显示的行数 self.linesPerPage = int((self.pageHeight - y_offset) // self.lineHeight)
然后,我们在PrintOut的子类实现中重写 OnPreparePrinting(self) 函数,这个函数在绘制页面前执行一次,我们需要在其中计算出页面的数量。
#计算页面数 self.numPages = self.row_count //self.linesPerPageif self.row_count % self.linesPerPage !=0:
self.numPages+= 1
然后在重写两个函数,决定是否存在下一页,以及页码信息,如下所示的函数实现。
defHasPage(self, page):return page <=self.numPagesdefGetPageInfo(self):return (1, self.numPages, 1, self.numPages)
剩下的就是实现
这个函数就是主要控制绘制内容和分页标识的处理的。
绘制的内容,主要根据起始位置,并设置相关的字体大小实现绘制即可,我们简单介绍一下,如下是在页面顶部的中间绘制标题。
#绘制标题,居中显示 text_width, text_height =dc.GetTextExtent(self.title)
title_x= (width - text_width) // 2 #计算居中的X位置 dc.DrawText(self.title, int(title_x), int(y_offset))
线条的绘制也是类似,确定位置和颜色等,画线绘制即可。
#设置线条颜色 dc.SetPen(wx.Pen(wx.Colour(0, 0, 0))) #黑色线条 #将所有的坐标转换为整数 dc.DrawLine(line_x, line_y, line_x + line_width, line_y)
绘制表头的时候,我们切换会正常的字体大小,然后遍历绘制
#绘制表头 font.SetPointSize(FONTSIZE)
dc.SetFont(font)for col inrange(self.col_count):
dc.DrawText(
self.grid.GetColLabelValue(col),
int(x_offset+sum(col_widths[:col])),
int(y_offset),
)
其中的 col_widths 是我们前面根据表格的列数量进行计算的宽度集合
col_widths = [self.grid.GetColSize(col) for col in range(self.col_count)]
以上内容是我们每页都需要绘制的常规信息,因此先绘制报表表头、线条、表格标题行这些。
下面我们需要根据当前page的页码来计算当前开始的行记录,page为1的时候,那么当前的开始行号是0,否则就是根据页码计算数值。
self.current_row = (page - 1) * self.linesPerPage #计算当前页面的起始行数
下面就是对数据进行分页的处理了,如果需要分页,在OnPrintPage函数中返回False,否则返回True,如下代码所示。
#绘制表格的内容 lines_on_page = 0 #记录当前页面的行数 for row inrange(self.current_row, self.row_count):
y_offset+= self.lineHeight #增加行的高度 for col inrange(self.col_count):
cell_value=self.grid.GetCellValue(row, col)
dc.DrawText(
cell_value,
x_offset+sum(col_widths[:col]),
y_offset,
)
lines_on_page+= 1 #如果当前页面的行数已经达到最大值,则绘制页脚,并返回False,继续打印下一页 if lines_on_page >=self.linesPerPage:
self.draw_footer(dc, page)#绘制页脚,底部的页码 return False #打印完一页后返回False,继续打印下一页 self.draw_footer(dc, page)return True
而底部的页码信息,我们简单绘制当前页面和页面总数即可,如下函数。
defdraw_footer(self, dc: wx.DC, page: int):#绘制当前页码 page_num_text = f"当前页码: {page} / {self.numPages}"page_num_width, page_num_height=dc.GetTextExtent(page_num_text)
dc.DrawText(
page_num_text,
int((self.pageWidth- page_num_width) // 2),
int(self.y2),
)
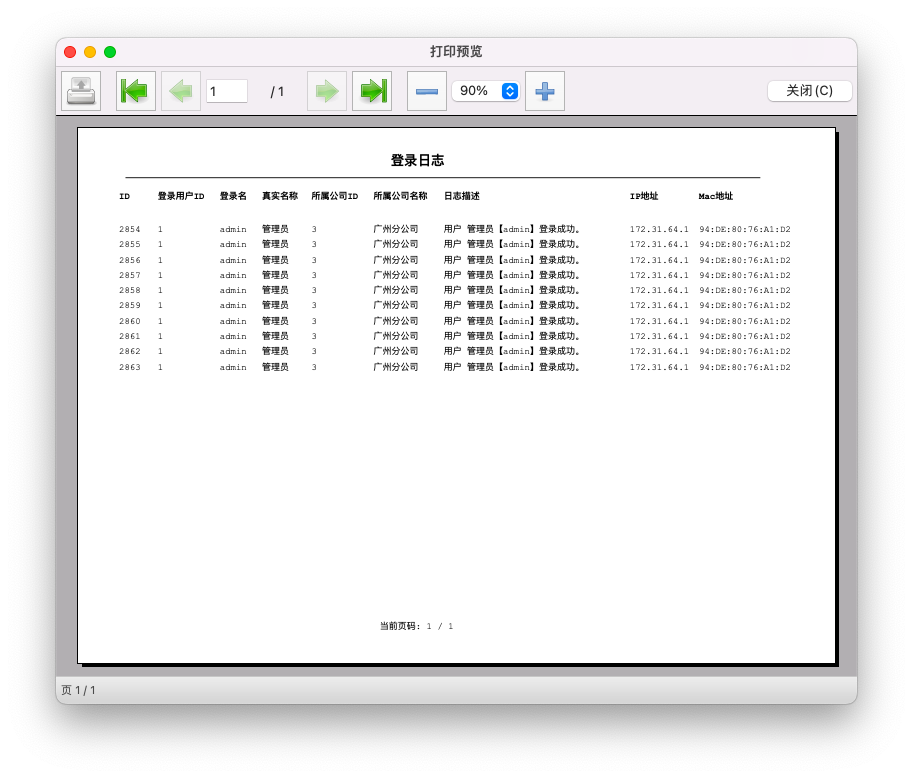
最后获得随笔开始前介绍的效果。
如果没有分页信息,那么底部空白一些,还是会绘制页码信息,如下是没有更多记录的时候打印预览的界面效果
以上就是整个实现的过程,我们在WxPython开发框架中自定义PrintOut对象,实现WxPython跨平台开发框架之列表数据的通用打印处理过程。








