事务管理在系统开发中是不可缺少的一部分,Spring提供了很好事务管理机制
分类
主要分为编程式事务和声明式事务两种。
编程式事务
是指在代码中手动的管理事务的提交、回滚等操作,代码侵入性比较强,如下示例:
try {
//TODO something
transactionManager.commit(status);
} catch (Exception e) {
transactionManager.rollback(status);
throw new InvoiceApplyException("异常失败");
}
声明式事务
基于AOP面向切面的,它将具体业务与事务处理部分解耦,代码侵入性很低,所以在实际开发中声明式事务用的比较多。声明式事务也有两种实现方式,一是基于TX和AOP的xml配置文件方式,第二种就是基于@Transactional注解了。
@Transactional
@GetMapping("/test")
public String test() {
int insert = cityInfoDictMapper.insert(cityInfoDict);
}
事务传播方式propagation
Spring的传播特性(行为)指的是:当一个事务方法调用另一个事务方法时,事务该如何进行。Spring的传播行为有七种,可以分为三大类类型。
场景:以下都会使用这个例子,方便理解;有A类内部有个a方法、B类内部有个b方法
支持当前事务
REQUIRED:如果当前方法存在一个事务,则加入这个事务。若当前方法不存在事务,则新建一个事务。
例:b方法的传播特性是REQUIRED,当a方法调用到b方法时,若a方法存在事务,则b方法加入这个事务,与a共用一个事务。若a方法不存在事务,则b方法新建一个事务。回滚怎么判断:前者两个方法使用同一个事务,当a或者b任意一个方法出现异常,a和b都会回滚;后者a没有事务不会回滚,b方法有事务,会回滚。
SUPPORTS:如果当前方法存在事务,则加入事务。反之,则以非事务方式运行。
例:b方法的传播特性是SUPPORTS,当a方法调用到b方法时,若a方法存在事务,则b方法加入这个事务。若a方法不存在事务,则b方法以非事务进行。
MANDATORY:如果当前方法存在事务则加入事务,若不存在则抛出异常。
例:b方法的传播特性是MANDATORY,当a方法调用到b方法时,若a方法存在事务,则b方法加入这个事务。若a方法不存在事务,则抛出异常。
不支持当前事务
REQUIRES_NEW:新建一个事务,如果当前方法存在事务,则把当前事务挂起。
例:b方法的传播特性是REQUIRES_NEW,当a方法调用到b方法时,b方法新建一个事务,如果a方法存在事务,则把a方法事务挂起。回滚怎么判断:要明白一点就是a和b的事务没有关系。当a没有事务时,只有b有事务,a方法不会回滚,b方法会回滚。后者a和b有不同事务,当b方法出现异常时b会回滚。而a方法会不会回滚需要分为两种情况:若b中的异常自己捕获则a不会回滚,若b中是是抛出异常,则a也会回滚。
NOT_SUPPORTED:以非事务方式执行,若存在当前事务,则把当前事务挂起。
例:b方法的传播特性是NOT_SUPPORTED,当a方法调用到b方法时,b方法以非事务方式执行,若a方法存在事务,则挂起a方法事务。
NEVER:以非事务方式执行,若存在当前事务,则会抛出异常。
例:b方法的传播特性是NEVER,当a方法调用到b方法时,b方法以非事务方式执行,若a方法存在事务,则抛出异常。
嵌套事务
NESTED:如果当前存在事务,则在嵌套事务内执行。如果当前没有事务,则执行与REQUIRED类似的操作。
例:b方法的传播特性是NESTED,当a方法内调用到b方法时。若a方法存在事务,则在a方法内嵌套b方法的事务,两者是有联系的,b事务相当于a事务的子事务。若a方法不存在事务,则b方法新建一个事务。回滚怎么判断:前者a和b都有事务,并且是相关联的事务(a的事务相当于父事务、b的事务相当于子事务),当a方法出现异常时,a和b都会回滚。当b方法出现异常时则要分两种情况分析:若b中的异常自己捕获则a不会回滚,若b中是是抛出异常,则a也会回滚。
其他属性
isolation 属性:隔离级别
isolation :事务的隔离级别,默认值为 Isolation.DEFAULT。开发中基本都是 default 级别
Isolation.DEFAULT:使用底层数据库默认的隔离级别
Isolation.READ_COMMITTED:读已提交
Isolation.READ_UNCOMMITTED:读未提交
Isolation.REPEATABLE_READ:可重复读
Isolation.SERIALIZABLE:串行化
timeout 属性
timeout :事务的超时时间,。如果超过该时间限制但事务还没有完成,则自动回滚事务。默认值为 -1,默认不限制时间
readOnly 属性
readOnly :指定事务是否为只读事务,默认值为 false;为了忽略那些不需要事务的方法,比如读取数据,可以设置 read-only 为 true。
rollbackFor 属性
rollbackFor :用于指定能够触发事务回滚的异常类型,可以指定多个异常类型。
noRollbackFor属性
noRollbackFor:抛出指定的异常类型,不回滚事务,也可以指定多个异常类型。
@Transactional
作用范围
@Transactional 可以作用在接口、类、类方法。
作用于类:当把@Transactional 注解放在类上时,表示所有该类的public方法都配置相同的事务属性信息。
作用于方法:当类配置了@Transactional,方法也配置了@Transactional,方法的事务会覆盖类的事务配置信息。
作用于接口:不推荐这种使用方法,因为一旦标注在Interface上并且配置了Spring AOP 使用CGLib动态代理,将会导致@Transactional注解失效
错误使用场景
无需事务的业务
在没有事务操作的业务方法上使用 @Transactional 注解;
例如,在只有查询的操作上,或者在只操作单表的情况下 使用 @Transactional 注解。
- 虽然对业务功能无影响,但从编码角度看是不规范的。其他开发者可能会认为该方法实际需要事务支持,从而增加理解代码的复杂性。
- @Transactional是通过动态代理实现的,每次调用带有
@Transactional
注解的方法时,事务管理器都会检查是否需要启动一个新事务,造成性能开销。虽然事务管理的开销在大多数现代数据库和应用服务器中相对较小,但仍然存在。
@Transactional
public String testQuery() {
standardBak2Service.getById(1L);
return "testB";
}
事务范围过大
有些同学为了省事直接将 @Transactional 注解加在了类上或者抽象类上,这样做导致的问题就是
类内的方法或抽象类的实现类中所有方法全部都被事务管理
。增加了不必要的性能开销或复杂性,建议按需使用,只在有事务逻辑的方法上加@Transactional。
以下是事务范围过大可能引发的问题及其相关处理建议:
- 锁竞争:事务范围过大可能会导致较长时间持有数据库锁,从而增加锁竞争的可能性。其他事务在等待锁释放期间,可能会导致响应时间变长或出现超时。
- 死锁
:长时间持有锁的事务增加了死锁的风险。当多个事务相互持有对方需要的资源时,可能会陷入死锁状态。
失效场景
应用在非 public 修饰的方法上
之所以会失效是因为@Transactional 注解依赖于Spring AOP切面来增强事务行为,这个 AOP 是通过代理来实现的
而无论是JDK动态代理还是CGLIB代理,Spring AOP的默认行为都是只代理
public
方法。
被用 final 、static 修饰方法
和上边的原因类似,被用
final
、
static
修饰的方法上加 @Transactional 也不会生效。
- static 静态方法属于类本身的而非实例,因此代理机制是无法对静态方法进行代理或拦截的
- final 修饰的方法不能被子类重写,事务相关的逻辑无法插入到 final 方法中,代理机制无法对 final 方法进行拦截或增强。
同类中非事务方法调用事务方法
比如有一个类Test,它的一个方法A,A再调用本类的方法B(不论方法B是用public还是private修饰),但方法A没有声明注解事务,而B方法有。则外部调用方法A之后,方法B的事务是不会起作用的。但是如果是A声明了事务,A的事务是会生效的。
失效原因:事务是基于动态代理实现的,但本类中调用另一个方法默认是this调用关系,并非动态代理,故失效
解决方案:要么将操作移动到事务中,要么调用另一个Service中的事务方法
Bean 未被 spring 管理
上边我们知道 @Transactional 注解通过 AOP 来管理事务,而 AOP 依赖于代理机制。因此,
Bean 必须由Spring管理实例!
要确保为类加上如
@Controller
、
@Service
或
@Component
注解,让其被Spring所管理,这很容易忽视。
异步线程调用
如果我们在 testMerge() 方法中使用异步线程执行事务操作,通常也是无法成功回滚的,来个具体的例子。
假设testMerge() 方法在事务中调用了 testA(),testA() 方法中开启了事务。接着,在 testMerge() 方法中,我们通过一个新线程调用了 testB(),testB() 中也开启了事务,并且在 testB() 中抛出了异常。此时,testA() 不会回滚 和 testB() 回滚。
testA() 无法回滚是因为没有捕获到新线程中 testB()抛出的异常;testB()方法正常回滚。
在多线程环境下,Spring 的事务管理器不会跨线程传播事务,事务的状态(如事务是否已开启)是存储在线程本地的
ThreadLocal
来存储和管理事务上下文信息。这意味着每个线程都有一个独立的事务上下文,事务信息在不同线程之间不会共享。
@Transactional
public void transactionalMethod() {
new Thread(() ->{
Valuation v = new Valuation();
v.setUserName("张三");
valuationMapper.insert(v);
}).start();
}
Spring的事务是通过数据库连接来实现不同线程使用不同的数据库连接,且放在ThreadLocal中,基于同一个数据库连接的事务才能同时提交或回滚,多线程场景下,拿到的数据库连接不是同一个
解决方案:
- 采用分布式事务保证
- 自己实现事务回滚
数据库引擎不支持事务
事务能否生效数据库引擎是否支持事务是关键。常用的MySQL数据库默认使用支持事务的innodb引擎。一旦数据库引擎切换成不支持事务的myisam,那事务就从根本上失效了。
propagation 设置错误
若是错误的配置以下三种 propagation,事务将不会发生回滚。
TransactionDefinition.PROPAGATION_SUPPORTS:如果当前存在事务,则加入该事务;如果当前没有事务,则以非事务的方式继续运行。
TransactionDefinition.PROPAGATION_NOT_SUPPORTED:以非事务方式运行,如果当前存在事务,则把当前事务挂起。
TransactionDefinition.PROPAGATION_NEVER:以非事务方式运行,如果当前存在事务,则抛出异常。
rollbackFor 设置错误
rollbackFor 可以指定能够触发事务回滚的异常类型。Spring 默认抛出了未检查unchecked异常(继承自 RuntimeException 的异常)或者 Error才回滚事务;其他异常(如IOException)不会触发回滚事务。如果在事务中抛出其他类型的异常,例如
checked exceptions
(检查型异常),但却期望 Spring 能够回滚事务,就需要指定 rollbackFor属性。
失效原因:@Transactional 注解默认处理RuntimeException,即只有抛出运行时异常,才会触发事务回滚
解决方案:@Transactional 设置为 @Transactional(rollbackFor =Exception.class) 或者直接抛出运行时异常
异常被 catch了
spring的事务是在调用业务方法之前开始的,业务方法执行完毕之后才执行commit or rollback,事务是否执行取决于是否抛出runtime异常。如果抛出runtime exception 并在你的业务方法中没有catch到的话,事务会回滚。
在业务方法中一般不需要catch异常,如果非要catch一定要抛出throw new RuntimeException(),或者注解中指定抛异常类型@Transactional(rollbackFor=Exception.class),否则会导致事务失效,数据commit造成数据不一致,所以有些时候try catch反倒会画蛇添足。
嵌套事务问题
还有一种场景就是嵌套事务问题,比如,我们在 testMerge() 方法中调用了事务方法 testA() 和事务方法 testB(),此时不希望 testB() 抛出异常让整个 testMerge() 都跟着回滚;这就需要单独 try catch 处理 testB() 的异常,不让异常在向上抛。
@RequiredArgsConstructor
@Slf4j
@Service
public class TestMergeService {
private final TestBService testBService;
private final TestAService testAService;
@Transactional
public String testMerge() {
testAService.testA();
try {
testBService.testB();
} catch (Exception e) {
log.error("testMerge error:{}", e);
}
return "ok";
}
}
@Service
public class TestAService {
@Transactional
public String testA() {
standardBakService.save(entity);
return "ok";
}
}
@Service
public class TestBService {
@Transactional
public String testB() {
standardBakService.save(entity2);
throw new RuntimeException("test2");
}
}
源码分析
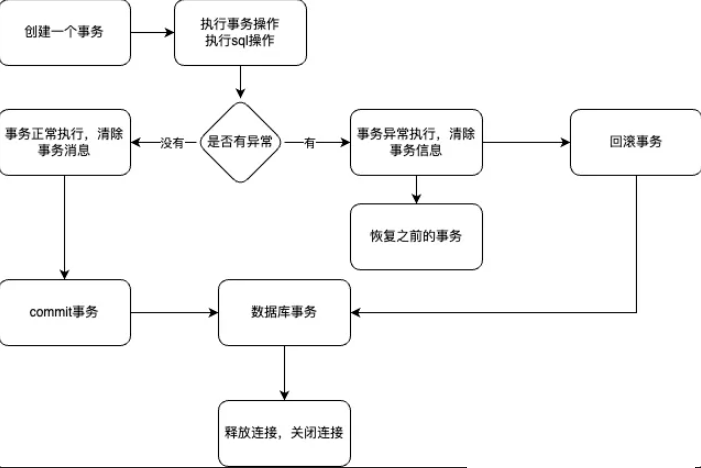
以下源码均基于Spring4.3.12版本。主要从 创建事务、开启事务、提交事务、事务回滚 的维度来详细分析声明式事务。
事务简易流程图
代理类生成
在Spring框架中,当配置了事务管理器并声明了@Transactional注解时,Spring会在实例化bean时生成事务增强的代理类。创建代理类参考源码路径如下:
AbstractAutowireCapableBeanFactory.createBean=>
doCreateBean()=>
initializeBean()=>
applyBeanPostProcessorsAfterInitialization()=>
postProcessAfterInitialization()(BeanPostProcessor内接口)=>
AbstractAutoProxyCreator.postProcessAfterInitialization()=>
wrapIfNecessary()=>
createProxy() 中 proxyFactory.setProxyTargetClass(true); //是否对类进行代理的设置,true为cglib代理
代理类中方法执行入口
从
TransactionInterceptor.invoke()
方法开始分析 (获取代理类,调用父类
TransactionAspectSupport.invokeWithinTransaction()
方法,该方法会将代理类的方法纳入事务中)。
public class TransactionInterceptor extends TransactionAspectSupport implements MethodInterceptor, Serializable {
public Object invoke(final MethodInvocation invocation) throws Throwable {
// 返回代理类的目标类
Class<?> targetClass = invocation.getThis() != null ? AopUtils.getTargetClass(invocation.getThis()) : null;
//事务中执行被代理的方法
return this.invokeWithinTransaction(invocation.getMethod(), targetClass, new InvocationCallback() {
public Object proceedWithInvocation() throws Throwable {
return invocation.proceed();
}
});
}
}
主要核心逻辑
TransactionAspectSupport.invokeWithinTransaction()
方法负责获取事务属性和事务管理器,然后针对声明式事务和编程式事务区分处理流程(此处源码忽略编程式事务)。
protected Object invokeWithinTransaction(Method method, Class<?> targetClass, final TransactionAspectSupport.InvocationCallback invocation) throws Throwable {
// 获取事务属性 TransactionDefinition对象(回顾规则,隔离级别,只读等)
final TransactionAttribute txAttr = this.getTransactionAttributeSource().getTransactionAttribute(method, targetClass);
// 根据事务属性和方法,获取对应的事务管理器,(后续用于做事务的提交,回滚等操作),数据库的一些信息,
final PlatformTransactionManager tm = this.determineTransactionManager(txAttr);
// 获取事务方法全路径,
final String joinpointIdentification = this.methodIdentification(method, targetClass, txAttr);
//响应式编程事务,大多数情况下都会执行到 else中的语句;
// CallbackPreferringPlatformTransactionManager 可以通过回掉函数来处理事务的提交和回滚操作, 此处不考虑,此处源码可以忽略
if (txAttr != null && tm instanceof CallbackPreferringPlatformTransactionManager) {
// 此处省略,此处为编程式事务 处理逻辑
} else {
//创建事务,事务属性等信息会被保存进 TransactionInfo,便于后续流程中的提交和回滚操作,详情见下文
TransactionAspectSupport.TransactionInfo txInfo = this.createTransactionIfNecessary(tm, txAttr, joinpointIdentification);
Object retVal = null;
try {
// 执行目标的方法 (执行具体的业务逻辑)
retVal = invocation.proceedWithInvocation();
} catch (Throwable var15) {
//异常处理
this.completeTransactionAfterThrowing(txInfo, var15);
throw var15;
} finally {
//清除当前节点的事务消息,将旧事务节点消息通过ThreadLoacl更新到当前线程(事务的挂起操作就是在这执行)
this.cleanupTransactionInfo(txInfo);
}
//提交事务
this.commitTransactionAfterReturning(txInfo);
return retVal;
}
}
开启事务
TransactionAspectSupport.createTransactionIfNecessary()
方法作用是检查当前是否存在事务,如果存在,则根据一定的规则创建一个新的事务。
protected TransactionAspectSupport.TransactionInfo createTransactionIfNecessary(PlatformTransactionManager tm, TransactionAttribute txAttr, final String joinpointIdentification) {
//如果事务名称不为空,则使用方法唯一标识。并使用 DelegatingTransactionAttribute 封装 txAttr
if (txAttr != null && ((TransactionAttributerollbackOn)txAttr).getName() == null) {
txAttr = new DelegatingTransactionAttribute((TransactionAttribute)txAttr) {
public String getName() {
return joinpointIdentification;
}
};
}
TransactionStatus status = null;
if (txAttr != null) {
if (tm != null) {
// 获取事务状态。内部判断是否开启事务绑定线程与数据库连接。详情见下文
status = tm.getTransaction((TransactionDefinition)txAttr);
} else if (this.logger.isDebugEnabled()) {
this.logger.debug("Skipping transactional joinpoint [" + joinpointIdentification + "] because no transaction manager has been configured");
}
}
//构建事务消息,根据指定的属性与状态status 构建一个 TransactionInfo。将已经建立连接的事务所有信息,都记录在ThreadLocal下的TransactionInfo 实例中,包括目标方法的所有状态信息,如果事务执行失败,spring会根据TransactionInfo中的信息来进行回滚等后续操作
return this.prepareTransactionInfo(tm, (TransactionAttribute)txAttr, joinpointIdentification, status);
}
获取当前事务对象
AbstractPlatformTransactionManager.getTransaction()
获取当前事务对象。通过这个方法,可以获取到关于事务的详细信息,如事务的状态、相关属性等。
public final TransactionStatus getTransaction(@Nullable TransactionDefinition definition)
throws TransactionException {
//definition 中存储的事务的注解信息,超时时间和隔离级别等
TransactionDefinition def = (definition != null ? definition : TransactionDefinition.withDefaults());
// 获取当前事务
Object transaction = doGetTransaction();
boolean debugEnabled = logger.isDebugEnabled();
// 判断当前线程是否存在事务
if (isExistingTransaction(transaction)) {
// 处理已经存在的事务
return handleExistingTransaction(def, transaction, debugEnabled);
}
// 事务超时设置验证,超时时间小于-1 抛异常
if (def.getTimeout() < TransactionDefinition.TIMEOUT_DEFAULT) {
throw new InvalidTimeoutException("Invalid transaction timeout", def.getTimeout());
}
// 如果当前线程不存在事务且 事务传播行为是 MANDATORY(用当前事务,如果当前没有事务,则抛出异常) 抛异常
if (def.getPropagationBehavior() == TransactionDefinition.PROPAGATION_MANDATORY) {
throw new IllegalTransactionStateException(
"No existing transaction found for transaction marked with propagation 'mandatory'");
}
//以下三种事务传播行为 需要开启新事务
else if (def.getPropagationBehavior() == TransactionDefinition.propagation_required ||
def.getPropagationBehavior() == TransactionDefinition.propagation_requires_new ||
def.getPropagationBehavior() == TransactionDefinition.propagation_nested) {
//挂起原事务,因为这里不存在原事务 故设置为null。
//当一个事务方法内部调用了另一个事务方法时,如果第二个事务方法需要独立于第一个事务方法,那么可以使用 suspend 方法来挂起当前事务,然后再开始一个新的事务
AbstractPlatformTransactionManager.SuspendedResourcesHolder suspendedResources = this.suspend((Object)null);
try {
boolean newSynchronization = this.getTransactionSynchronization() != 2;
DefaultTransactionStatus status = this.newTransactionStatus((TransactionDefinition)definition, transaction, true, newSynchronization, debugEnabled, suspendedResources);
//开启事务
this.doBegin(transaction, (TransactionDefinition)definition);
//同步事务状态及书屋属性
this.prepareSynchronization(status, (TransactionDefinition)definition);
return status;
} catch (RuntimeException var7) {
this.resume((Object)null, suspendedResources);
throw var7;
}
}
else {
boolean newSynchronization = (getTransactionSynchronization() == SYNCHRONIZATION_ALWAYS);//0
//创建默认状态 详情见 下文
return prepareTransactionStatus(def, null, true, newSynchronization, debugEnabled, null);
}
}
执行获取事务的具体操作
AbstractPlatformTransactionManager.doGetTransaction()
方法用于执行获取事务的具体操作。它可能会根据一些条件或规则,去查找和获取当前的事务对象,并进行相应的处理。
protected Object doGetTransaction() {
DataSourceTransactionManager.DataSourceTransactionObject txObject = new DataSourceTransactionManager.DataSourceTransactionObject();
//是否允许在一个事务内部开启另一个事务。
txObject.setSavepointAllowed(this.isNestedTransactionAllowed());
// this.dataSource数据源 配置
//判断当前线程如果已经记录数据库连接则使用原连接
ConnectionHolder conHolder = (ConnectionHolder)TransactionSynchronizationManager.getResource(this.dataSource);
//false 表示不是新创建连接
txObject.setConnectionHolder(conHolder, false);
return txObject;
}
this.dataSource()
是我们配置DataSourceTransactionManager时传入的。
<bean id="valuationTransactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="valuationDataSource"/>
</bean>
TransactionSynchronizationManager.getResource()
方法的作用主要是获取与当前事务相关联的资源。TransactionSynchronizationManager 持有一个ThreadLocal的实例,存在一个key为dataSource ,value为ConnectionHolder 的Map信息。
//ThreadLocal 存放 ConnectionHolder 信息,ConnectionHolder 可以理解为Connection(数据库连接)的包装类,其中最主要属性为 Connection
private static final ThreadLocal<Map<Object, Object>> resources = new NamedThreadLocal("Transactional resources");
// 获取ConnectionHolder
public static Object getResource(Object key) {
Object actualKey = TransactionSynchronizationUtils.unwrapResourceIfNecessary(key);
//获取连接信息
Object value = doGetResource(actualKey);
return value;
}
//具体执行获取连接信息操作
private static Object doGetResource(Object actualKey) {
//从 ThreadLoacl中获取
Map<Object, Object> map = (Map)resources.get();
if (map == null) {
return null;
} else {
Object value = map.get(actualKey);
if (value instanceof ResourceHolder && ((ResourceHolder)value).isVoid()) {
map.remove(actualKey);
if (map.isEmpty()) {
resources.remove();
}
value = null;
}
return value;
}
}
判断是否存在正在进行的事务
AbstractPlatformTransactionManager.isExistingTransaction()
方法用于判断是否存在正在进行的事务。它可以帮助我们确定当前的执行环境是否处于事务中,以便进行相应的处理。
protected boolean isExistingTransaction(Object transaction) {
DataSourceTransactionManager.DataSourceTransactionObject txObject = (DataSourceTransactionManager.DataSourceTransactionObject)transaction;
return txObject.getConnectionHolder() != null && txObject.getConnectionHolder().isTransactionActive();
}
挂起事务
AbstractPlatformTransactionManager.suspend()
挂起事务,对有无同步的事务采取不同方案,
doSuspend()
执行挂起具体操作。
protected final AbstractPlatformTransactionManager.SuspendedResourcesHolder suspend(Object transaction) throws TransactionException {
//如果有同步的事务,则优先挂起同步事务
if (TransactionSynchronizationManager.isSynchronizationActive()) {
List suspendedSynchronizations = this.doSuspendSynchronization();
try {
Object suspendedResources = null;
if (transaction != null) {
//执行挂起操作
suspendedResources = this.doSuspend(transaction);
}
//重置事务名称
String name = TransactionSynchronizationManager.getCurrentTransactionName();
TransactionSynchronizationManager.setCurrentTransactionName((String)null);
//重置只读状态
boolean readOnly = TransactionSynchronizationManager.isCurrentTransactionReadOnly();
TransactionSynchronizationManager.setCurrentTransactionReadOnly(false);
//重置隔离级别
Integer isolationLevel = TransactionSynchronizationManager.getCurrentTransactionIsolationLevel();
TransactionSynchronizationManager.setCurrentTransactionIsolationLevel((Integer)null);
//重置事务激活状态
boolean wasActive = TransactionSynchronizationManager.isActualTransactionActive();
TransactionSynchronizationManager.setActualTransactionActive(false);
//返回挂起的事务
return new AbstractPlatformTransactionManager.SuspendedResourcesHolder(suspendedResources, suspendedSynchronizations, name, readOnly, isolationLevel, wasActive);
} catch (RuntimeException var8) {
this.doResumeSynchronization(suspendedSynchronizations);
throw var8;
}
} else if (transaction != null) {
Object suspendedResources = this.doSuspend(transaction);
return new AbstractPlatformTransactionManager.SuspendedResourcesHolder(suspendedResources);
} else {
return null;
}
}
AbstractPlatformTransactionManager.doSuspend()
执行挂起操作只是将当前ConnectionHolder设置为null,返回原有事务消息,方便后续恢复原有事务消息,并将当前正在进行的事务信息进行重置。
protected Object doSuspend(Object transaction) {
DataSourceTransactionManager.DataSourceTransactionObject txObject = (DataSourceTransactionManager.DataSourceTransactionObject)transaction;
txObject.setConnectionHolder((ConnectionHolder)null);
//接触绑定
return TransactionSynchronizationManager.unbindResource(this.dataSource);
}
//解除绑定操作,将现有的事务消息remove并返回上一级
public static Object unbindResource(Object key) throws IllegalStateException {
Object actualKey = TransactionSynchronizationUtils.unwrapResourceIfNecessary(key);
//解绑操作,移除资源
Object value = doUnbindResource(actualKey);
if (value == null) {
throw new IllegalStateException("No value for key [" + actualKey + "] bound to thread [" + Thread.currentThread().getName() + "]");
} else {
return value;
}
}
AbstractPlatformTransactionManager.doBegin()
数据库连接获取,当新事务时,则获取新的数据库连接,并为其设置隔离级别,是否只读等属性。
protected void doBegin(Object transaction, TransactionDefinition definition) {
DataSourceTransactionManager.DataSourceTransactionObject txObject = (DataSourceTransactionManager.DataSourceTransactionObject)transaction;
Connection con = null;
try {
//新事务开启时将 ConnectionHolder 设置为null
if (txObject.getConnectionHolder() == null || txObject.getConnectionHolder().isSynchronizedWithTransaction()) {
//获取新的数据库连接
Connection newCon = this.dataSource.getConnection();
txObject.setConnectionHolder(new ConnectionHolder(newCon), true);
}
txObject.getConnectionHolder().setSynchronizedWithTransaction(true);
con = txObject.getConnectionHolder().getConnection();
//设置事务隔离级别 和readOnly属性
Integer previousIsolationLevel = DataSourceUtils.prepareConnectionForTransaction(con, definition);
txObject.setPreviousIsolationLevel(previousIsolationLevel);
if (con.getAutoCommit()) {
txObject.setMustRestoreAutoCommit(true);
// 交给Spring控制事务提交
con.setAutoCommit(false);
}
this.prepareTransactionalConnection(con, definition);
//设置当前线程的事务激活状态
txObject.getConnectionHolder().setTransactionActive(true);
int timeout = this.determineTimeout(definition);
if (timeout != -1) {
// 设置超时时间
txObject.getConnectionHolder().setTimeoutInSeconds(timeout);
}
if (txObject.isNewConnectionHolder()) {
TransactionSynchronizationManager.bindResource(this.getDataSource(), txObject.getConnectionHolder());
}
} catch (Throwable var7) {
if (txObject.isNewConnectionHolder()) {
DataSourceUtils.releaseConnection(con, this.dataSource);
txObject.setConnectionHolder((ConnectionHolder)null, false);
}
throw new CannotCreateTransactionException("Could not open JDBC Connection for transaction", var7);
}
}
AbstractPlatformTransactionManager.prepareTransactionStatus()
创建默认Status,如果不需要开始事务 (比如SUPPORTS),则返回一个默认的状态。
protected final DefaultTransactionStatus prepareTransactionStatus(TransactionDefinition definition, Object transaction, boolean newTransaction, boolean newSynchronization, boolean debug, Object suspendedResources) {
DefaultTransactionStatus status = this.newTransactionStatus(definition, transaction, newTransaction, newSynchronization, debug, suspendedResources);
this.prepareSynchronization(status, definition);
return status;
}
protected DefaultTransactionStatus newTransactionStatus(TransactionDefinition definition, Object transaction, boolean newTransaction, boolean newSynchronization, boolean debug, Object suspendedResources) {
boolean actualNewSynchronization = newSynchronization && !TransactionSynchronizationManager.isSynchronizationActive();
//创建 DefaultTransactionStatus 对象
return new DefaultTransactionStatus(transaction, newTransaction, actualNewSynchronization, definition.isReadOnly(), debug, suspendedResources);
}
AbstractPlatformTransactionManager.handleExistingTransaction()
针对不同的传播行为做不同的处理方法,比如挂起原事务开启新事务等等。
private TransactionStatus handleExistingTransaction(TransactionDefinition definition, Object transaction, boolean debugEnabled) throws TransactionException {
//当传播行为是 NEVER 时抛出异常
if (definition.getPropagationBehavior() == 5) {
throw new IllegalTransactionStateException("Existing transaction found for transaction marked with propagation 'never'");
} else {
AbstractPlatformTransactionManager.SuspendedResourcesHolder suspendedResources;
boolean newSynchronization;
//当传播方式为NOT_SUPPORTED 时挂起当前事务,然后在无事务的状态下运行
if (definition.getPropagationBehavior() == 4) {
//挂起事务
suspendedResources = this.suspend(transaction);
newSynchronization = this.getTransactionSynchronization() == 0;
//返回默认status
return this.prepareTransactionStatus(definition, (Object)null, false, newSynchronization, debugEnabled, suspendedResources);
//当传播方式为REQUIRES_NEW时,挂起当前事务,然后启动新事务
} else if (definition.getPropagationBehavior() == 3) {
//挂起原事务
suspendedResources = this.suspend(transaction);
try {
newSynchronization = this.getTransactionSynchronization() != 2;
DefaultTransactionStatus status = this.newTransactionStatus(definition, transaction, true, newSynchronization, debugEnabled, suspendedResources);
//启动新的事务
this.doBegin(transaction, definition);
this.prepareSynchronization(status, definition);
return status;
} catch (Error|RuntimeException var7) {
this.resumeAfterBeginException(transaction, suspendedResources, var7);
throw var7;
}
} else {
boolean newSynchronization;
//当传播方式为NESTED时,设置事务的保存点
//存在事务,将该事务标注保存点,形成嵌套事务
//嵌套事务中的子事务出现异常不会影响到父事务保存点之前的操作
if (definition.getPropagationBehavior() == 6) {
if (!this.isNestedTransactionAllowed()) {
throw new NestedTransactionNotSupportedException("Transaction manager does not allow nested transactions by default - specify 'nestedTransactionAllowed' property with value 'true'");
} else {
if (this.useSavepointForNestedTransaction()) {
DefaultTransactionStatus status = this.prepareTransactionStatus(definition, transaction, false, false, debugEnabled, (Object)null);
//创建保存点,回滚时,只回滚到该保存点
status.createAndHoldSavepoint();
return status;
} else {
newSynchronization = this.getTransactionSynchronization() != 2;
DefaultTransactionStatus status = this.newTransactionStatus(definition, transaction, true, newSynchronization, debugEnabled, (Object)null);
//如果不支持保存点,就启动新的事务
this.doBegin(transaction, definition);
this.prepareSynchronization(status, definition);
return status;
}
}
} else {
newSynchronization = this.getTransactionSynchronization() != 2;
return this.prepareTransactionStatus(definition, transaction, false, newSynchronization, debugEnabled, (Object)null);
}
}
}
}
回滚事务
TransactionAspectSupport.completeTransactionAfterThrowing()
判断事务是否存在,如不存在就不需要回滚,如果存在则在判断是否满足回滚条件。
protected void completeTransactionAfterThrowing(TransactionAspectSupport.TransactionInfo txInfo, Throwable ex) {
//判断是否存在事务
if (txInfo != null && txInfo.hasTransaction()) {
// 判断是否满足回滚条件。抛出的异常类型,和定义的回滚规则进行匹配
if (txInfo.transactionAttribute.rollbackOn(ex)) {
try {
// 回滚处理
txInfo.getTransactionManager().rollback(txInfo.getTransactionStatus());
}
//省略代码
} else {
try {
//不满足回滚条件 出现异常
txInfo.getTransactionManager().commit(txInfo.getTransactionStatus());
}
//省略代码
}
}
}
AbstractPlatformTransactionManager.rollback()
当在事务执行过程中出现异常或其他需要回滚的情况时,就会调用这个方法,将事务进行回滚操作,撤销之前所做的数据库操作,以保证数据的一致性。
public final void rollback(TransactionStatus status) throws TransactionException {
//判断事务是否已经完成,回滚时抛出异常
if (status.isCompleted()) {
throw new IllegalTransactionStateException("Transaction is already completed - do not call commit or rollback more than once per transaction");
} else {
DefaultTransactionStatus defStatus = (DefaultTransactionStatus)status;
// 执行回滚操作。
this.processRollback(defStatus);
}
}
AbstractPlatformTransactionManager.processRollback()
方法主要用于处理事务的回滚操作。通过这个方法,可以确保事务在需要回滚时能够正确地执行回滚操作,保持数据的完整性。
private void processRollback(DefaultTransactionStatus status) {
try {
try {
//解绑线程和会话绑定关系
this.triggerBeforeCompletion(status);
if (status.hasSavepoint()) {
//如果有保存点(当前事务为单独的线程则会退到保存点)
status.rollbackToHeldSavepoint();
} else if (status.isNewTransaction()) {
//如果是新事务直接回滚。调用数据库连接并调用rollback方法进行回滚。使用底层数据库连接提供的API
this.doRollback(status);
} else if (status.hasTransaction()) {
if (status.isLocalRollbackOnly() || !this.isGlobalRollbackOnParticipationFailure()) {
//如果当前事务不是独立的事务,则只能等待事务链执行完成后再做回滚操作
this.doSetRollbackOnly(status);
}
}
}
//catch 等代码
// 关闭会话,重置属性
this.triggerAfterCompletion(status, 1);
} finally {
//清理并恢复挂起的事务
this.cleanupAfterCompletion(status);
}
}
提交事务
TransactionAspectSupport.commitTransactionAfterReturning()
基本上和回滚一样,都是先判断是否有事务,在操作提交。
protected void commitTransactionAfterReturning(TransactionAspectSupport.TransactionInfo txInfo) {
if (txInfo != null && txInfo.hasTransaction()) {
//提交事务
txInfo.getTransactionManager().commit(txInfo.getTransactionStatus());
}
}
AbstractPlatformTransactionManager.commit()
创建默认Status prepareTransactionStatu,发现是否有回滚标记,然后进行回滚。如果判断无需回滚就可以直接提交。
public final void commit(TransactionStatus status) throws TransactionException {
// 事务状态已完成则抛异常
if (status.isCompleted()) {
throw new IllegalTransactionStateException("Transaction is already completed - do not call commit or rollback more than once per transaction");
} else {
DefaultTransactionStatus defStatus = (DefaultTransactionStatus)status;
//发现回滚标记
if (defStatus.isLocalRollbackOnly()) {
//回滚
this.processRollback(defStatus);
} else if (!this.shouldCommitOnGlobalRollbackOnly() && defStatus.isGlobalRollbackOnly()) {
//回滚
this.processRollback(defStatus);
if (status.isNewTransaction() || this.isFailEarlyOnGlobalRollbackOnly()) {
throw new UnexpectedRollbackException("Transaction rolled back because it has been marked as rollback-only");
}
} else {
// 提交操作
this.processCommit(defStatus);
}
}
}
AbstractPlatformTransactionManager.processCommit()
处理事务的提交操作
private void processCommit(DefaultTransactionStatus status) throws TransactionException {
try {
boolean beforeCompletionInvoked = false;
try {
this.prepareForCommit(status);
this.triggerBeforeCommit(status);
this.triggerBeforeCompletion(status);
beforeCompletionInvoked = true;
boolean globalRollbackOnly = false;
if (status.isNewTransaction() || this.isFailEarlyOnGlobalRollbackOnly()) {
globalRollbackOnly = status.isGlobalRollbackOnly();
}
if (status.hasSavepoint()) {
//释放保存点信息
status.releaseHeldSavepoint();
} else if (status.isNewTransaction()) {
// 是一个新的事务 则提交。 获取数据库连接后使用数据库API进行提交事务
this.doCommit(status);
}
if (globalRollbackOnly) {
throw new UnexpectedRollbackException("Transaction silently rolled back because it has been marked as rollback-only");
}
} catch (TransactionException var20) {
if (this.isRollbackOnCommitFailure()) {
//提交异常回滚
this.doRollbackOnCommitException(status, var20);
} else {
this.triggerAfterCompletion(status, 2);
}
throw var20;
}
//省略其它异常拦截
try {
this.triggerAfterCommit(status);
} finally {
this.triggerAfterCompletion(status, 0);
}
} finally {
// 清理事务消息
this.cleanupAfterCompletion(status);
}
}
清除事务信息
AbstractPlatformTransactionManager.cleanupAfterCompletion()
这个方法主要用于在事务完成后进行清理工作。它会负责释放资源、清理临时数据等,以确保系统处于良好的状态。
private void cleanupAfterCompletion(DefaultTransactionStatus status) {
//将当前事务设置为完成状态
status.setCompleted();
if (status.isNewSynchronization()) {
// 清空当前事务消息
TransactionSynchronizationManager.clear();
}
if (status.isNewTransaction()) {
//如果是新事务 则在事务完成之后做清理操作
this.doCleanupAfterCompletion(status.getTransaction());
}
if (status.getSuspendedResources() != null) {
// 将原事务从挂起状态恢复
this.resume(status.getTransaction(), (AbstractPlatformTransactionManager.SuspendedResourcesHolder)status.getSuspendedResources());
}
}
AbstractPlatformTransactionManager.doCleanupAfterCompletion()
在新事务完成后会调用resetConnectionAfterTransaction方法重置数据库连接信息,并判断如果是新的数据库连接则将其放回连接池。
protected void doCleanupAfterCompletion(Object transaction) {
DataSourceTransactionObject txObject = (DataSourceTransactionObject) transaction;
if (txObject.isNewConnectionHolder()) {
// 将数据库连接从当前线程中解除绑定
TransactionSynchronizationManager.unbindResource(this.dataSource);
}
Connection con = txObject.getConnectionHolder().getConnection();
try {
// 恢复数据库连接的autoCommit状态
if (txObject.isMustRestoreAutoCommit()) {
con.setAutoCommit(true);
}
// 负责重置数据库连接信息,包括隔离级别、readOnly属性等
DataSourceUtils.resetConnectionAfterTransaction(con, txObject.getPreviousIsolationLevel());
}
catch (Throwable ex) {
logger.debug("Could not reset JDBC Connection after transaction", ex);
}
if (txObject.isNewConnectionHolder()) {
// 如果是新的数据库连接则将数据库连接放回连接池
DataSourceUtils.releaseConnection(con, this.dataSource);
}
txObject.getConnectionHolder().clear();
}
AbstractPlatformTransactionManager.resume()
如果事务执行前有事务挂起,那么当前事务执行结束后需要将挂起的事务恢复,挂起事务时保存了原事务信息,重置了当前事务信息,所以恢复操作就是将当前的事务信息设置为之前保存的原事务信息。
protected final void resume(Object transaction, AbstractPlatformTransactionManager.SuspendedResourcesHolder resourcesHolder) throws TransactionException {
if (resourcesHolder != null) {
Object suspendedResources = resourcesHolder.suspendedResources;
if (suspendedResources != null) {
// 执行 恢复挂起事务 ,绑定资源bindResource
this.doResume(transaction, suspendedResources);
}
List<TransactionSynchronization> suspendedSynchronizations = resourcesHolder.suspendedSynchronizations;
if (suspendedSynchronizations != null) {
TransactionSynchronizationManager.setActualTransactionActive(resourcesHolder.wasActive);
TransactionSynchronizationManager.setCurrentTransactionIsolationLevel(resourcesHolder.isolationLevel);
TransactionSynchronizationManager.setCurrentTransactionReadOnly(resourcesHolder.readOnly);
TransactionSynchronizationManager.setCurrentTransactionName(resourcesHolder.name);
this.doResumeSynchronization(suspendedSynchronizations);
}
}
}
TransactionAspectSupport.cleanupTransactionInfo()
清除当前节点的事务消息,将旧事务节点信息通过thradLoacl更新到当前线程。
protected void cleanupTransactionInfo(TransactionAspectSupport.TransactionInfo txInfo) {
if (txInfo != null) {
//从当前线程的 ThreadLocal 获取上层的事务信息,将当前事务出栈,继续执行上层事务
txInfo.restoreThreadLocalStatus();
}
}
private void restoreThreadLocalStatus() {
//当前事务处理完之后,恢复上层事务上下文
TransactionAspectSupport.transactionInfoHolder.set(this.oldTransactionInfo);
}
小结
如果方法正常执行完成且没有异常,调用
commitTransactionAfterReturning()
方法。如果执行中出现异常,调用
completeTransactionAfterThrowing()
方法。
两个方法内部都会判断是否存在事务以及是否满足回滚条件来决定最终执行提交操作还是回滚操作。
面试题专栏
Java面试题专栏
已上线,欢迎访问。
- 如果你不知道简历怎么写,简历项目不知道怎么包装;
- 如果简历中有些内容你不知道该不该写上去;
- 如果有些综合性问题你不知道怎么答;
那么可以私信我,我会尽我所能帮助你。