【高清视频方案分享】12G-SDI与CameraLink输入输出,基于RK3588J+FPGA工业平台
CameraLink协议介绍
CameraLink是一种用于机器视觉和工业成像应用的标准化数字接口协议。它由自动化成像协会(Automated Imaging Association)开发,旨在解决传统模拟视频接口的局限性,提供一种高效、可靠且易于使用的数字解决方案,以实现相机与图像处理系统之间的高速数据传输。
CameraLink优势
高清视频:
CameraLink协议支持高分辨率、高帧率视频传输,能够满足捕捉快速运动或进行高速图像采集等应用场景。
稳定可靠:
CameraLink采用低压差分信号(LVDS)传输技术,能够有效抵抗电磁干扰和噪音,确保了信号在传输过程中的稳定性和抗干扰能力。
灵活配置:
CameraLink协议提供了Base、Medium、Full等多种配置选项,以适应不同带宽需求的应用场景。

12G-SDI介绍
SDI(Serial Digital Interface,串行数字接口)是一种用于传输未经压缩的数字视频信号的标准,主要应用于远程监控、工业检测等领域。12G-SDI是SDI接口的其中一种,支持高达12Gbps的数据传输速率,专为支持4K超高清视频而设计。
12G-SDI优势
支持单链路传输:
12G-SDI能够在单根电缆上传输,简化安装与维护,减少布线复杂性。
支持长距离传输:
12G-SDI支持长距离传输,能够实现远距离的高质量视频信号传输。
支持4K高清视频:
12G-SDI支持4K分辨率,帧率高达60fps,能够流畅地播放动态视频。

RK3588J+FPGA国产平台
瑞芯微RK3588J/RK3588处理器集成了四核2.4GHz ARM Cortex-A76与四核1.8GHz ARM Cortex-A55。创龙科技基于瑞芯微RK3588J/RK3588 + 紫光同创Titan-2 PG2T390H(兼容Xilinx Kintex-7 XC7K325T)FPGA,推出了SOM-TL3588F工业核心板和TL3588F-EVM评估板。
创龙的SOM-TL3588F核心板的ARM、FPGA、ROM、RAM、电源、晶振、连接器等所有元器件均采用国产工业级方案,国产化率100%。此外,RK3588J + FPGA评估板具备丰富的接口资源,包括Ethernet、RS422/RS485、USB 3.1、CAN、SFP+等通信接口,以及MIPI CSI、CameraLink Base、HDMI、12G-SDI等音视频接口,满足客户的项目评估需求!
RK3588J+FPGA核心板优势
接口拓展灵活便捷
2路CameraLink Base,支持Full模式
12G-SDI IN/OUT接口,支持4K@60fps高清视频,由高速串行收发器HSST引出
强大编解码能力
8K@60fps H.265、8K@30fps H.264视频解码
8K@30fps H.265/H.264视频编码
6T超强算力NPU
支持INT4/INT8/INT16/FP16/BF16/TF32
支持TensorFlow/PyTorch/Caffe/MXNet深度学习框架

RK3588J+FPGA核心板典型应用领域

12G-SDI与CameraLink输入输出方案演示
本文主要介绍基于瑞芯微RK3588J + FPGA的高清视频输入案例,适用开发环境如下。
Windows开发环境:Windows 7 64bit、Windows 10 64bit
FPGA端开发环境:Xilinx Vivado 2017.4、Xilinx SDK 2017.4
硬件平台:TL3588F-EVM(基于RK3588J + Kintex-7)
为了简化描述,本文仅摘录部分方案功能描述与测试结果。
cameralink_display案例
案例说明
案例通过TL3588F-EVM评估板的CameraLink接口进行分辨率为1280x1024、最高帧率为289.41fps的视频采集,并通过TLCameraLinkF模块的HDMI接口输出采集到的视频,分辨率为1920X1080、帧率为60fps。
案例演示
请将TLCameraLinkF模块、CameraLink相机、HDMI显示屏、评估板等对应连接,硬件连接如下图所示。

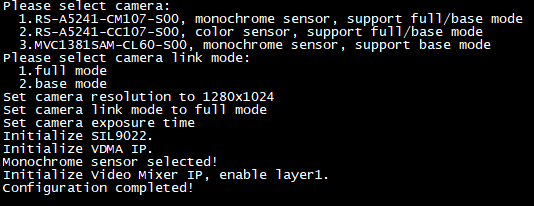
运行Full模式程序,即可看到串口终端打印如下信息。输入"1"选择相机型号为RS-A5241-CM107-S00,再输入"1"选择为Full模式。配置完成后,即可看到HDMI显示屏输出黑白图像。

gtx_sdi_cap_dis案例
案例说明
TL3588F-EVM评估板通过12G-SDI IN接口进行1080P@60fps的视频采集,并通过评估板的12G-SDI OUT接口将采集到的视频进行输出。
案例演示
将PC机HDMI OUT接口、HDMI转SDI模块、HDMI转SDI模块、HDMI显示屏、评估板等对应连接,硬件连接如下图所示。

运行程序,即可看到串口终端打印如下信息,然后在PC机的显卡设置(或图形属性)中,按照下图设置HDMI分辨率为1920x1080、刷新率为60p Hz。
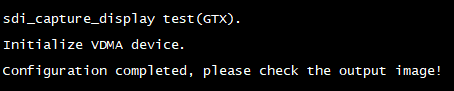
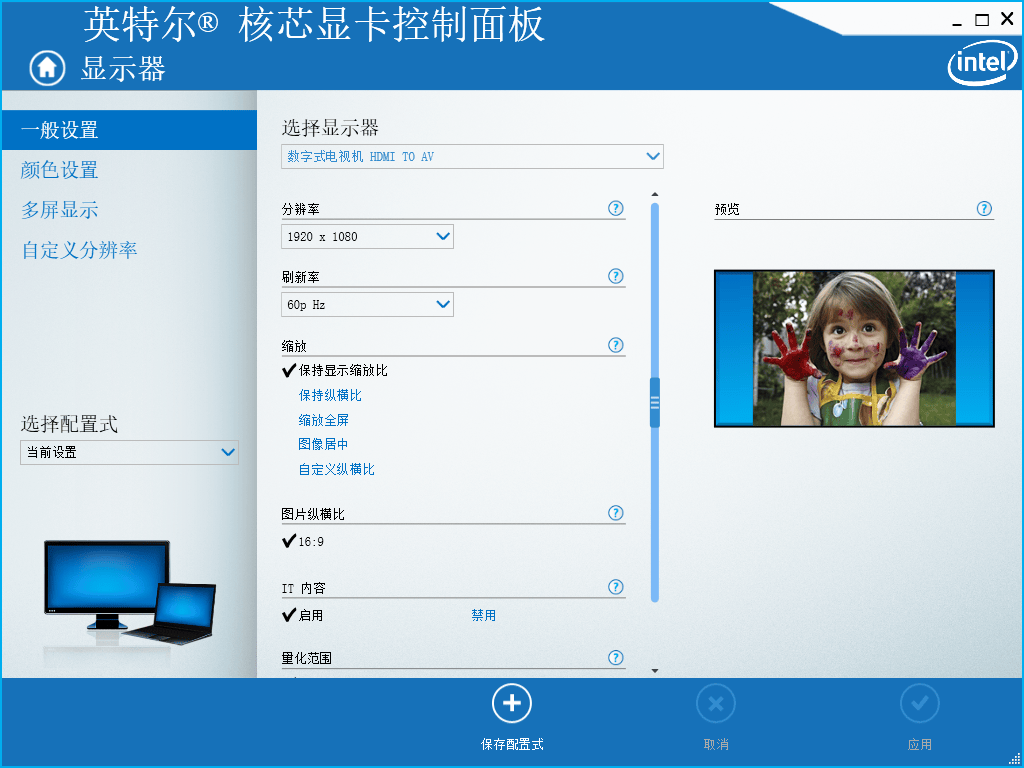
此时,HDMI显示屏将显示PC机HDMI OUT接口输出的图像。

到这里,我们的演示步骤结束。想要查看更多瑞芯微RK3588J + FPGA国产平台更多相关的案例演示,欢迎各位工程师通过公众号(Tronlong创龙科技)查看,快来试试吧!