KTL 用C++14写公式的K线工具 - 0.9.3版
K,K线,Candle蜡烛图。
T,技术分析,工具平台
L,公式Language语言使用c++14,Lite小巧简易。
项目仓库:
https://github.com/bbqz007/KTL
国内仓库:
https://gitee.com/bbqz007/KTL
当前0.9.3。修正代码编辑器不能调整窗口大小的问题。
新功能以
patch.cpprest.7z
方式提供,包含源代码。需要手动解压。
关键字:pplx, cpprest, sina finance, baidu gushitong.
新功能如下:
这个版本,加入pplx,cpprest编程模块。使用者可以在本工具使用pplx更简单地写异步代码, 使用cpprest更方便地写异步http,包括http请求数据还有http服务提供数据。
cpprest使用boost178,包含最小的asio头文件依赖。
然后提供应用工具,请求新浪财经数据,使用百度股市通opendata的api请求数据。
先来简单介绍pplx。是一个简化的
PPL
,相似地为java或javascript的Promise。用于简单方便地写异步应用。
将一个完整流程逻辑,拆分成一段一段的contination。每个contination借助pplx;:task投放到线程池。你可以wait()在当前控制的线程手动同步,或者then()让它在线程池事件循环异步等待结果。
auto task = create_task([]{
return 1;
})
.then([](int){
return 1.;
})
.then([](double){
return std::string("end");
}); 这里面安排了三个task,它们构成一个简单的filter-pipeline,前者的输出结果作为后者的输入参数。并且三个task在线程池自动完成分派。
下面是map-reduce形式
std::vector<task<int> > maps = {
create_task([]{
return 1;
}),
create_task([]{
return 12;
}),
create_task([]{
return 13;
}),
create_task([]{
return 14;
}),
};
auto reduce = when_all(maps.begin(), maps.end())
.then([=](auto){
int sum = 0;
for_each(maps.begin(), maps.end(),
[&](auto& task){
sum += task.get();
});
return sum;
});
reduce.get();
产生4个map任务并发, 然后reduce所有结果,一共5个task在线程池自动完成。
为了有更好的控制,这里有一个可等待事件,task_completion_event。我们可以用它作为一个事件源,借助一个task用它作为参数就可以进行同步或异步等待了,类似于future。
我们可以将这个future用作输入源,让安排好异步任务链等待输入才开始执行。
task_completion_event<int> future;
task<int> start(future);
auto pipeline = start.then([](int i){
return i;
})
.then([](int i){
return i;
})
.then([](double){
return std::string("end");
});
start.set(0);
pipeline.wait();
或者利用这个future,让pplx线程池外的线程也参与到pplx异步任务链。让pplx异步任务等待外部线程的结果。
再次指出,then()异步等待,并不阻塞任何线程,它是由线程池的事件循环完成异步等待的。
本工具提供的pplx,其底层基于asio。所有可以用asio的timer进行async_wait。结合task_completion_event,可以实现delay。
pplx::task<void> delay_post(std::chrono::milliseconds delay) {
boost::asio::io_service& io_service = pplx::threadpool::shared_instance().io_service();
pplx::task_completion_event<void> tce;
auto timer = std::make_shared<boost::asio::steady_timer>(io_service);
timer->expires_after(delay);
timer->async_wait([tce, timer](const boost::system::error_code& ec) mutable {
if (!ec) {
tce.set();
} else {
tce.set_exception(std::make_exception_ptr(std::runtime_error("Timer error: " + ec.message())));
}
});
return pplx::create_task(tce);
}了了解更多pplx,我写了另一篇《
浅析pplx库的设计与实现。
》
再来介绍cpprest。
cpprest就是cpp实现的rest开发库。线程模型使用pplx,http使用asio的实现。全程支持异步。
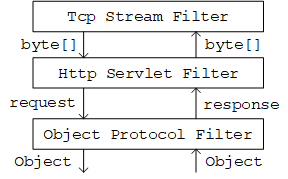
对于http client。主要两步,异步等待response,然后异步读取content。当http_client接收读取出status跟header fields后,response完成等待,然后就可以对streambuf进行异步读取content数据。
对于http server。借助于pplx异步模型,灵活性大。一个request不再由一个线程从开头处理到结束。而是把处理逻辑拆分成异步片段。在线程池进行异步任务链处理。这样就可以将http请求实现成poll。
下面就用BlackJack例子说明。
客户端状态机如下:
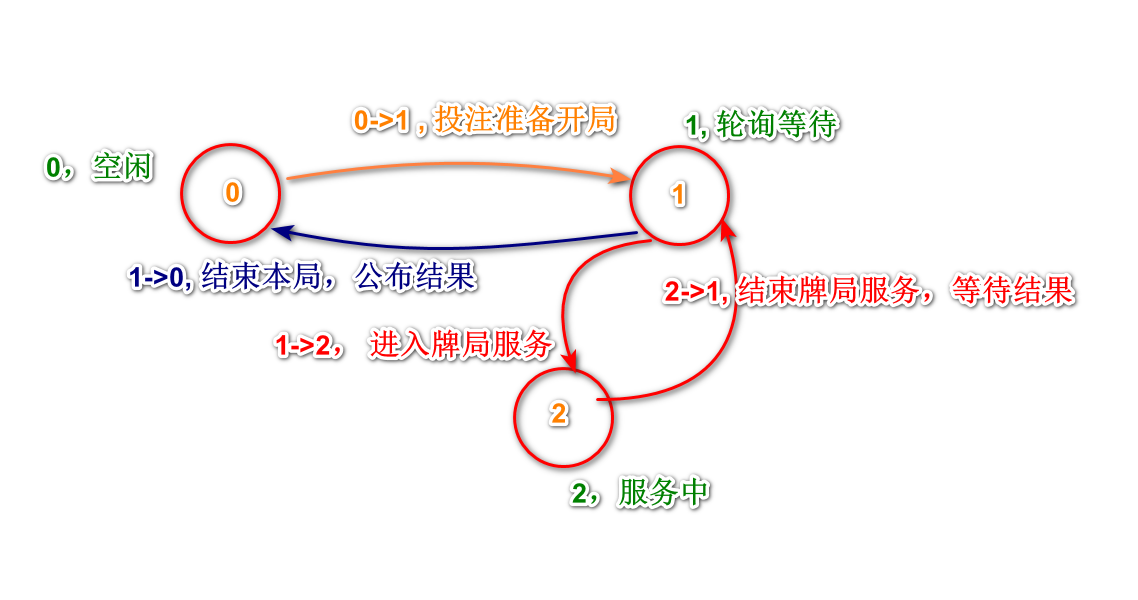
0,准备开局,接受投注。
>0, 开局中。
1, 需要轮询,等待下一步。
2, 进行处理环节,可以操作。
0, 结束,得出结果。
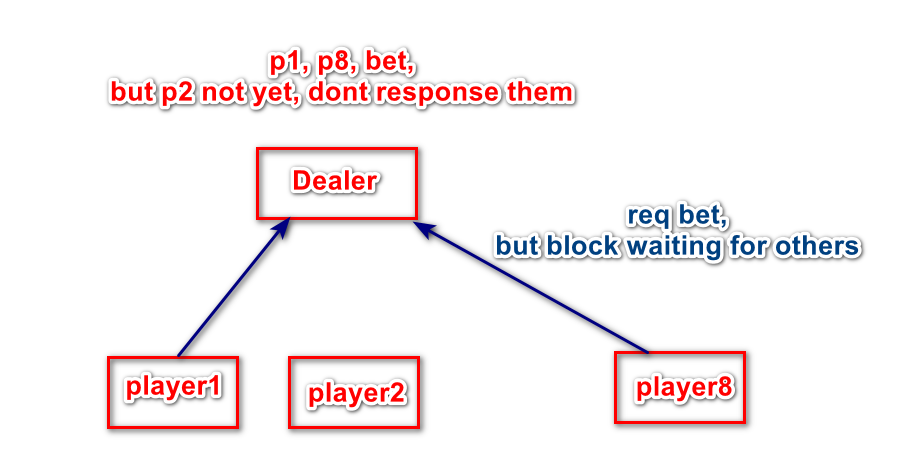
开始时,大家都在状态0,并进行投注,服务器原子等待所有人都投注后才能开局。
服务器会阻塞所有投注请求,直到人齐数了,才会开局并发出response。
服务器不会将线程阻塞来等待其它投注进来,而是将request作为异步上下文缓存起来。当人数齐后,进行开局逻辑处理,并发出response通知开局信息,包含状态切换。
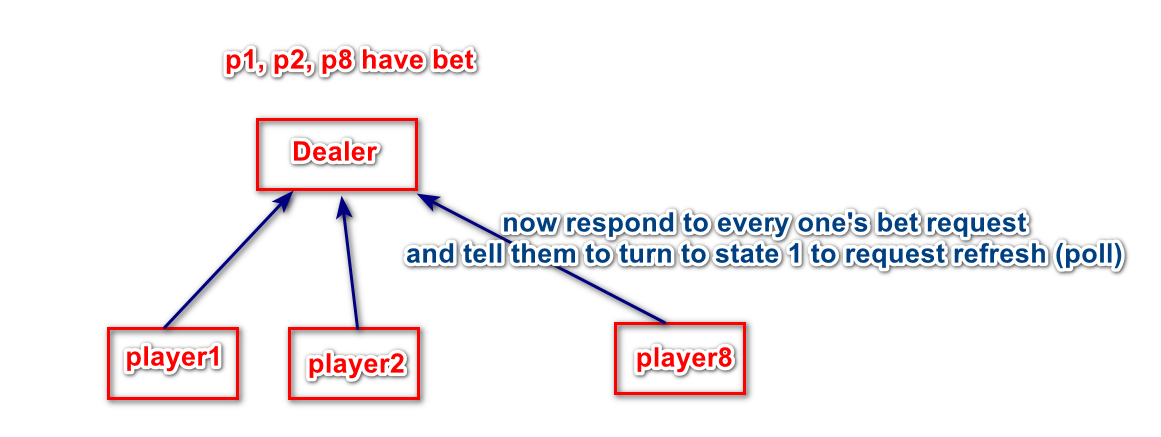
收到1的玩家,必须调用接口refresh阻塞轮询。收到2的玩家进入服务状态,进行牌局交互操作。结束后,服务器通知其切换状态1进入轮询等待。并选出一下玩家通知它的轮询切换状态2。
服务器通过缓存起全部轮询请求,以确保一桌人数同时在线。
全部玩家相继完成服务环节后,服务器向每人的轮询请求发出结果。并知会状态切换0。
BlackJack例子的实现就是利用pplx的异步优势。
本工具提供的BlackJack例子完全使用cpprest的BlackJack例程,逻辑没有任何修改。原例程应用于控制台标准输入输出,为了让其应用在界面,我只是将标准输入替换成QTextStream再指向pipe,标准输出替换成stringstream。
这样一来,原例程就可以原原本本地作为台后部分运行,界面作为前台部分运行。前后台之间用两条流进行数据交互。
要将cpprest线程池的数据更新到ui线程,我们需要将数据投递到ui线程执行。在win32界面我们可以PostMessage到线程队列,虽然qt没有线程队列,但是基于qt事件循环的线程,每个qt对象都可充当线程队列角色,我说的是signal队列。为方便,我们只需要借用任意一个qt对象的signal就可以了,不必新写一个qt对象只为了定义一个signal。在此,我就借用QFutureWatcher的signal finished(),用作投递方法。


struct MyQFutureWatcher : public QFutureWatcher<int>{~MyQFutureWatcher()
{
OutputDebugStringA("~MyQFutureWatcher");
}
QMutex mtx;
QList<std::function<void()> >queue;
MyQFutureWatcher(QObject*parent =nullptr)
: QFutureWatcher(parent)
{
QObject::connect(this, &QFutureWatcher<int>::finished, [=](){
_sched();
});
}void sched(std::function<void()>&functor)
{
mtx.lock();
queue.push_back(functor);
mtx.unlock();///Z#20241210, bug, Q_EMIT dispatch in caller's thread //Q_EMIT finished();//to sched QMetaObject::invokeMethod(this, "finished", Qt::QueuedConnection);
}private:void_sched()
{
QList<std::function<void()> >coll;
mtx.lock();
coll=std::move(queue);
mtx.unlock();while (!coll.empty())
{
coll.front()();
coll.pop_front();
}
}
};
MyUIExecutor
于是有界面例程:
编写服务器也简单方便,虚函数handle_XXX对应于http请求方法的入口,只要override这些虚函数,再根据uri进行不同服务接口处理。
然后就是本工具的新增的
主要功能
。
通过两个例子,介绍如何使用cpprest写代码,请求新浪财经的数据,使用百度股市通的opendata接口请求数据。
对于新浪财务数据,就是页面的表格。我们可以用QTextEdit转换成MarkDown。
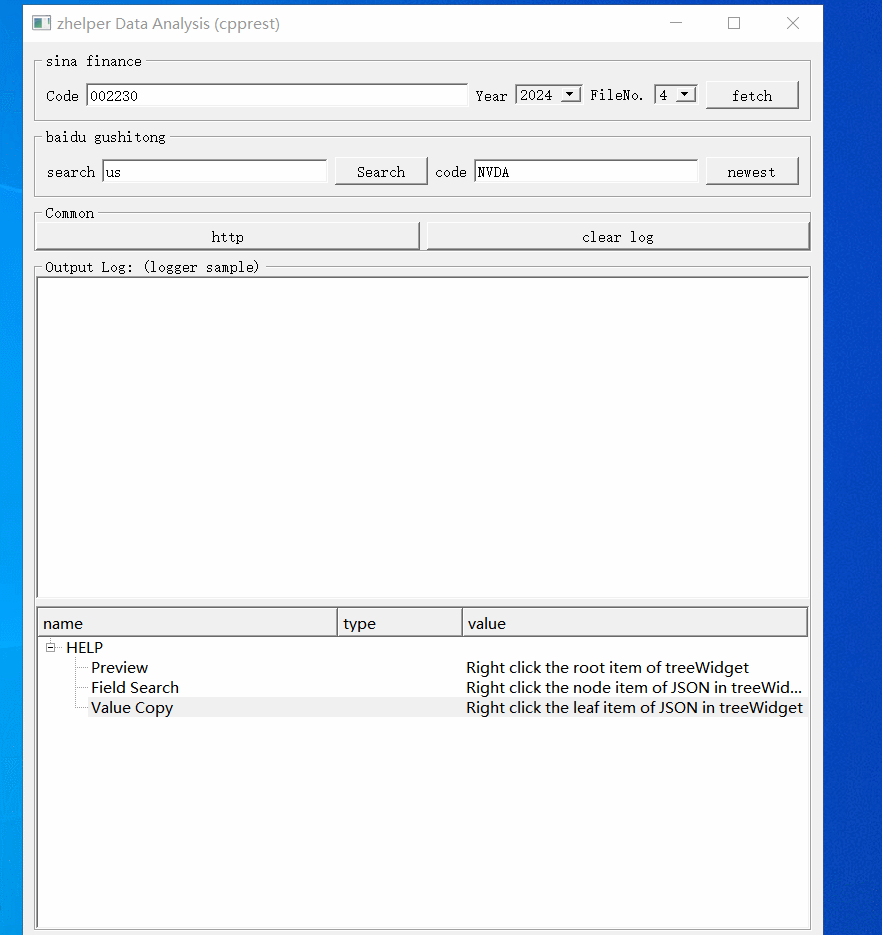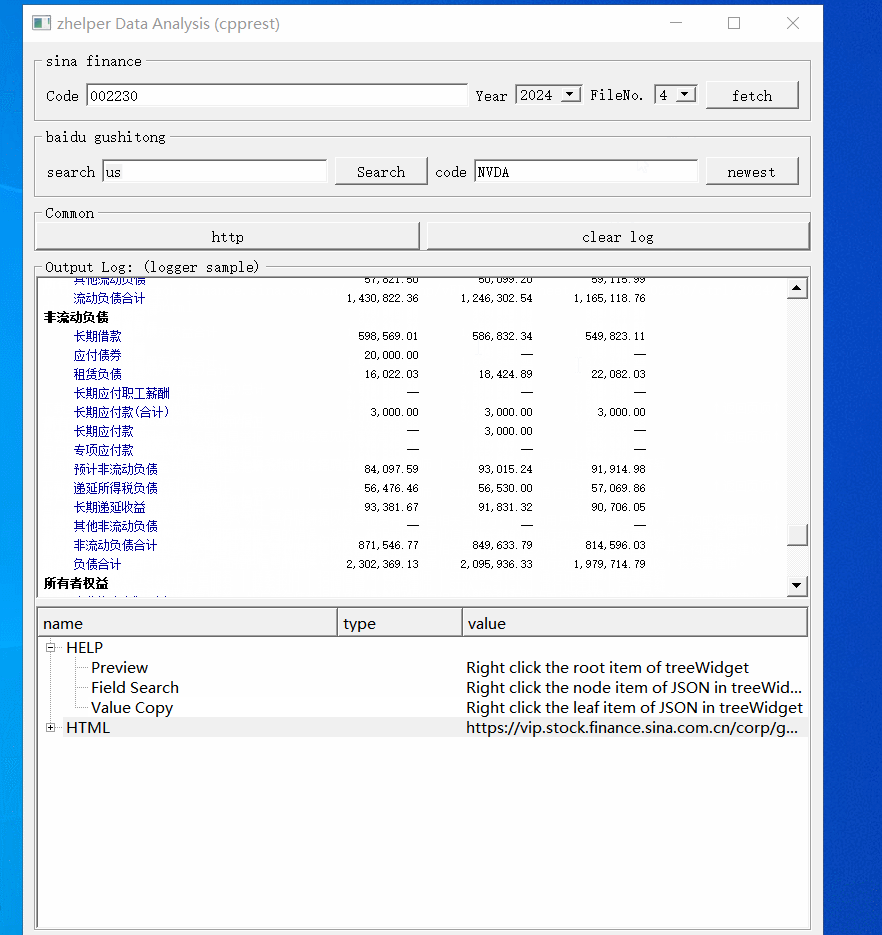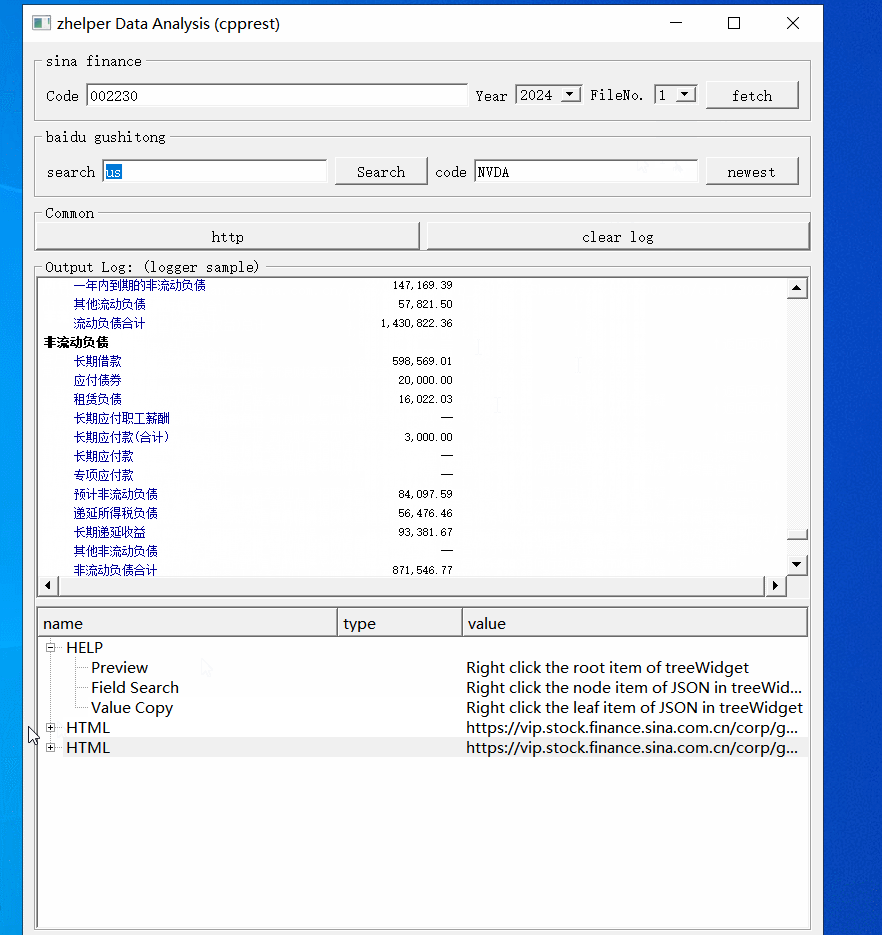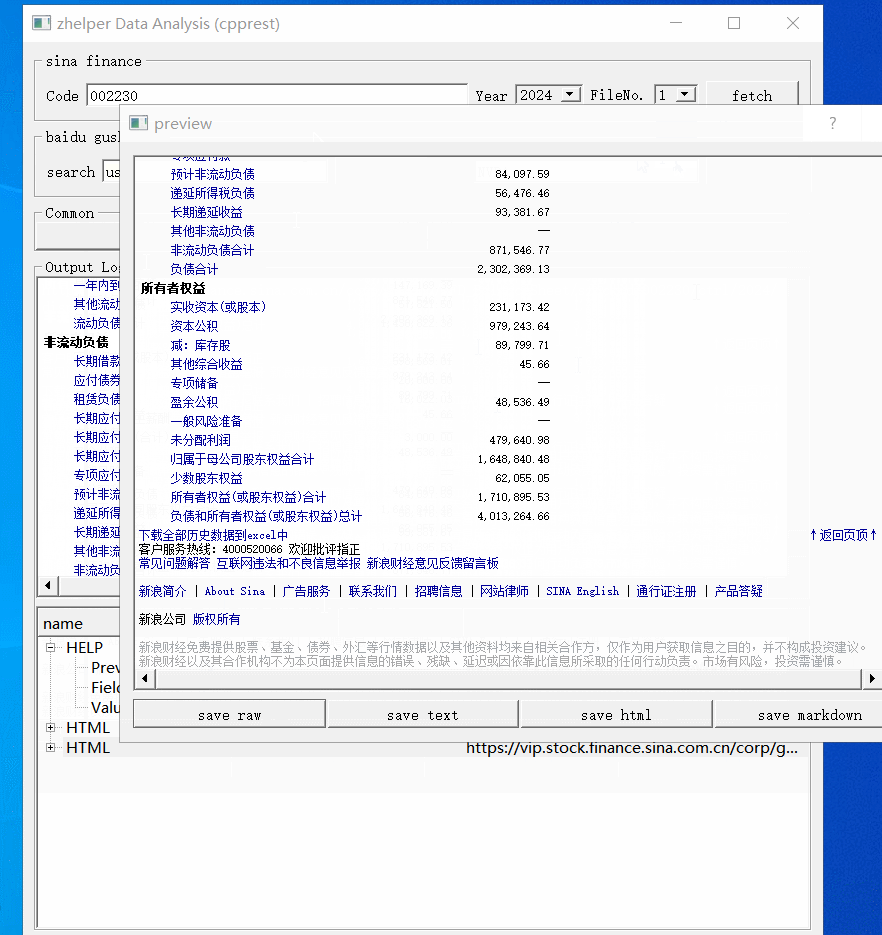
下面就是百度的opendata数据接口,它们在webpack://finance-pc/src/api/路径下api_prefix.js跟detail.js,有详细的注释说明。数据涵盖多个市场,A股,港股,美股,货币,有色金属等。
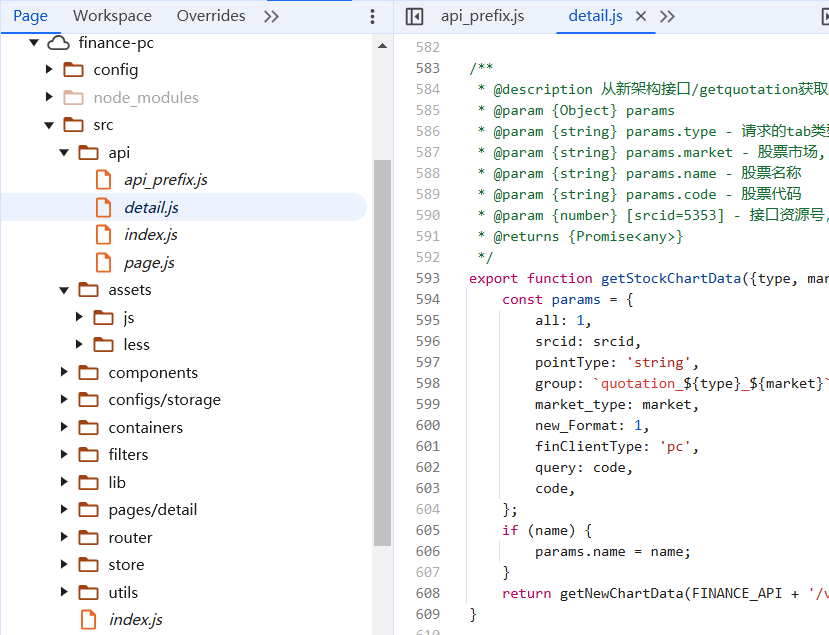
本功能使用了两个接口,第一个是码表搜索。第二个是基本行情。所有接口皆用JSON承载数据。
本功能帮助大家调试分析这些接口的数据。每次请求结果会在下方树型表缓冲。右键树型节点打开不同功能。根节点预览并转换格式保存文件。对于JSON的对象节点,右键打开属性路径搜索。叶子节点则是复制值。
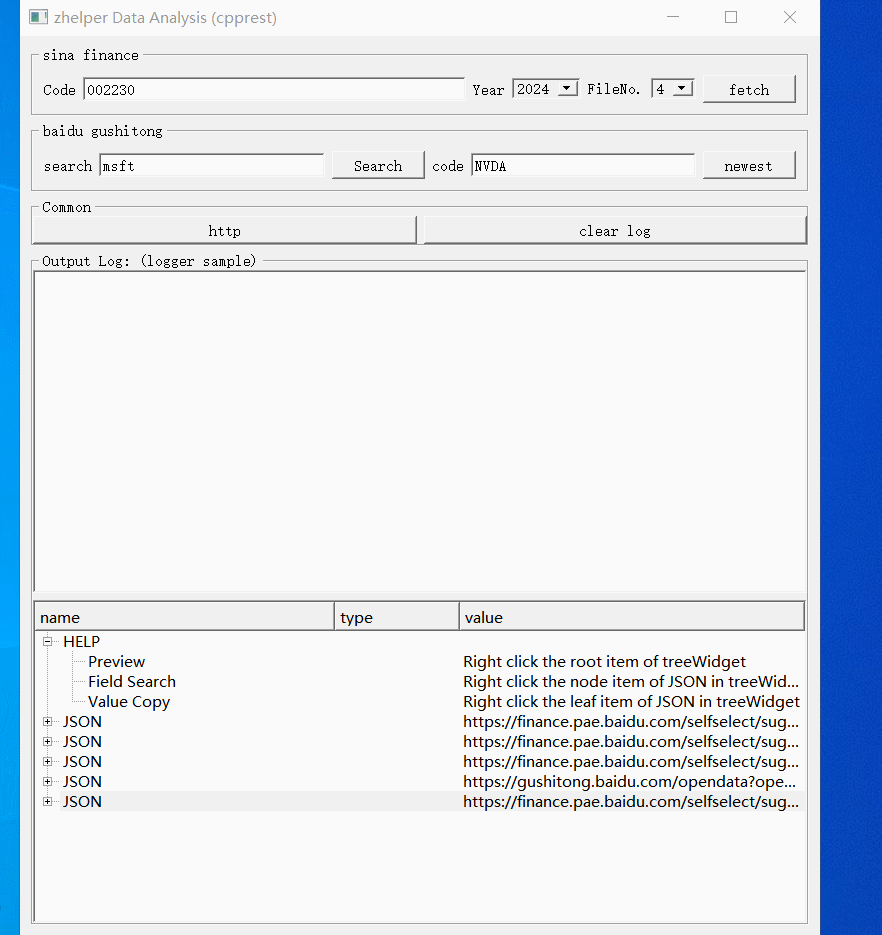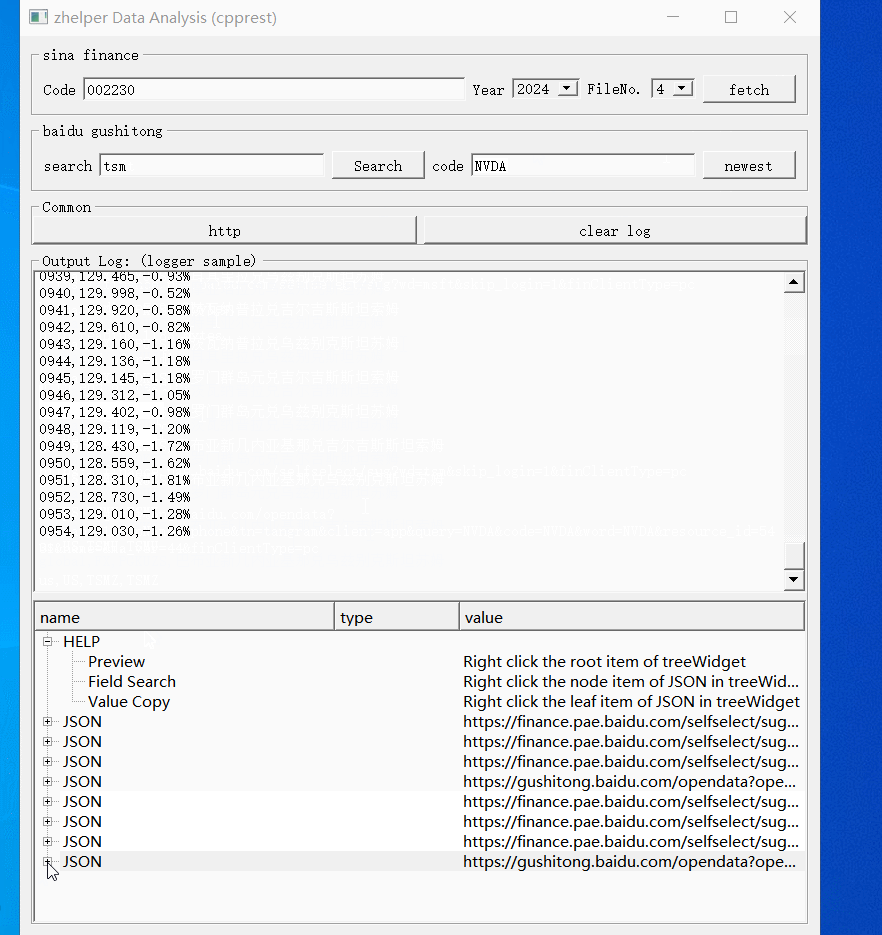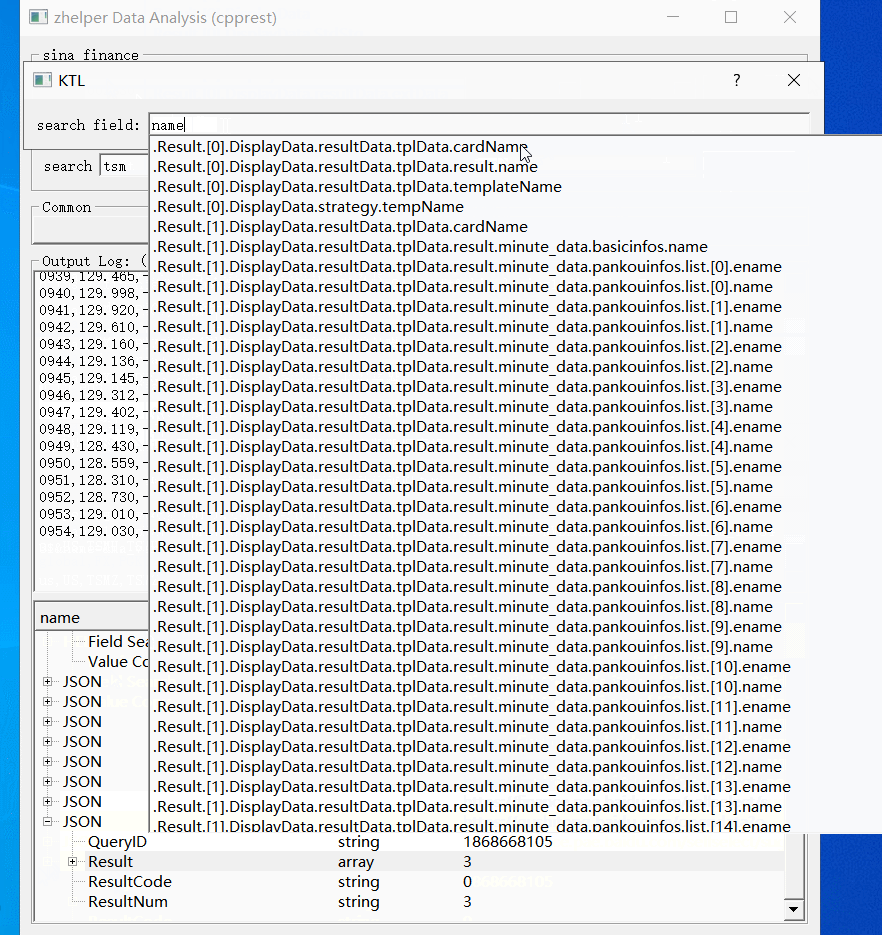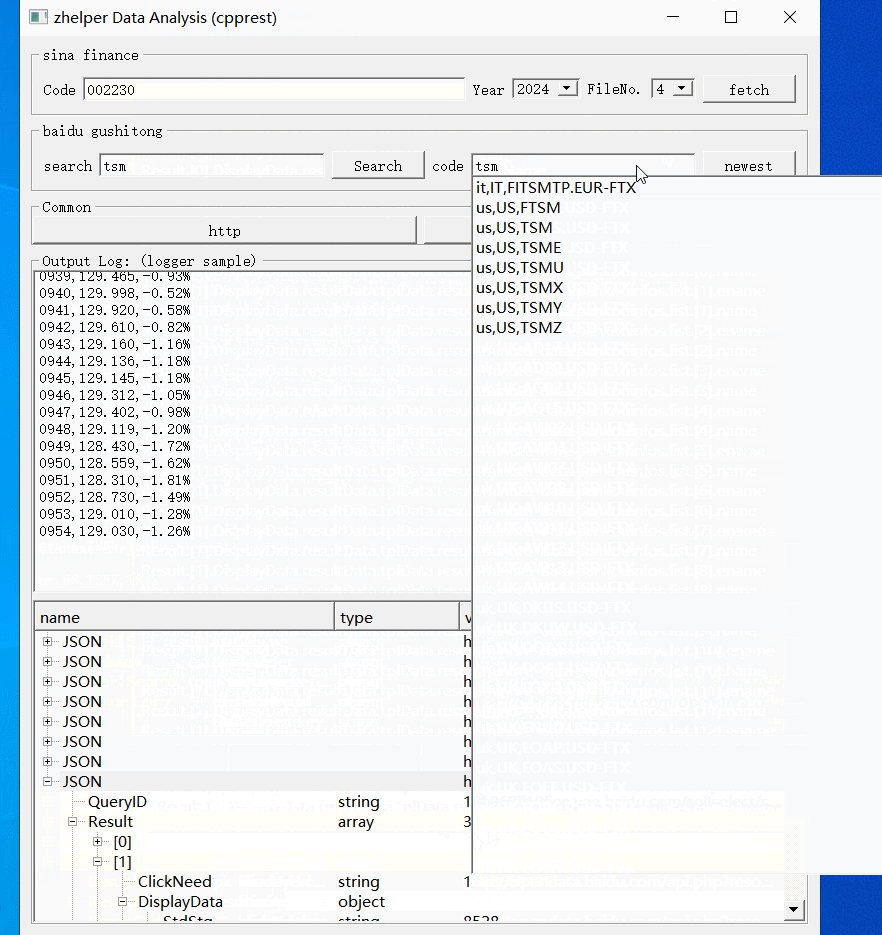
除了上面两个固定网站的接口应用例子,还可以使用通用请求。
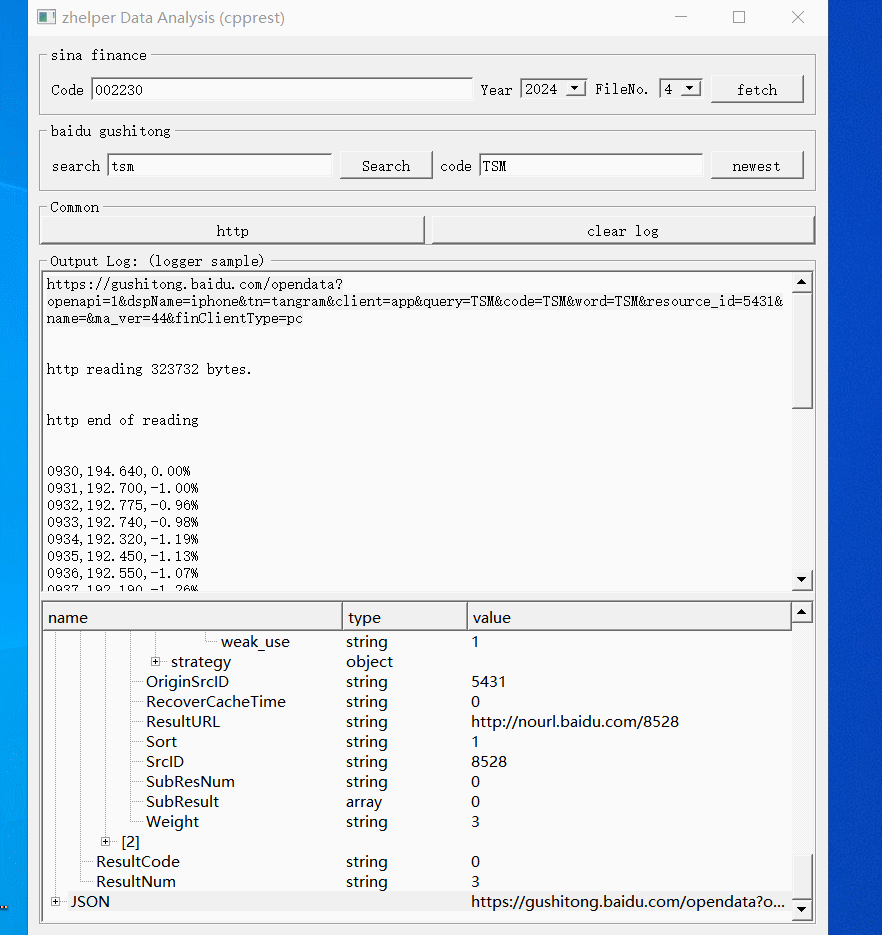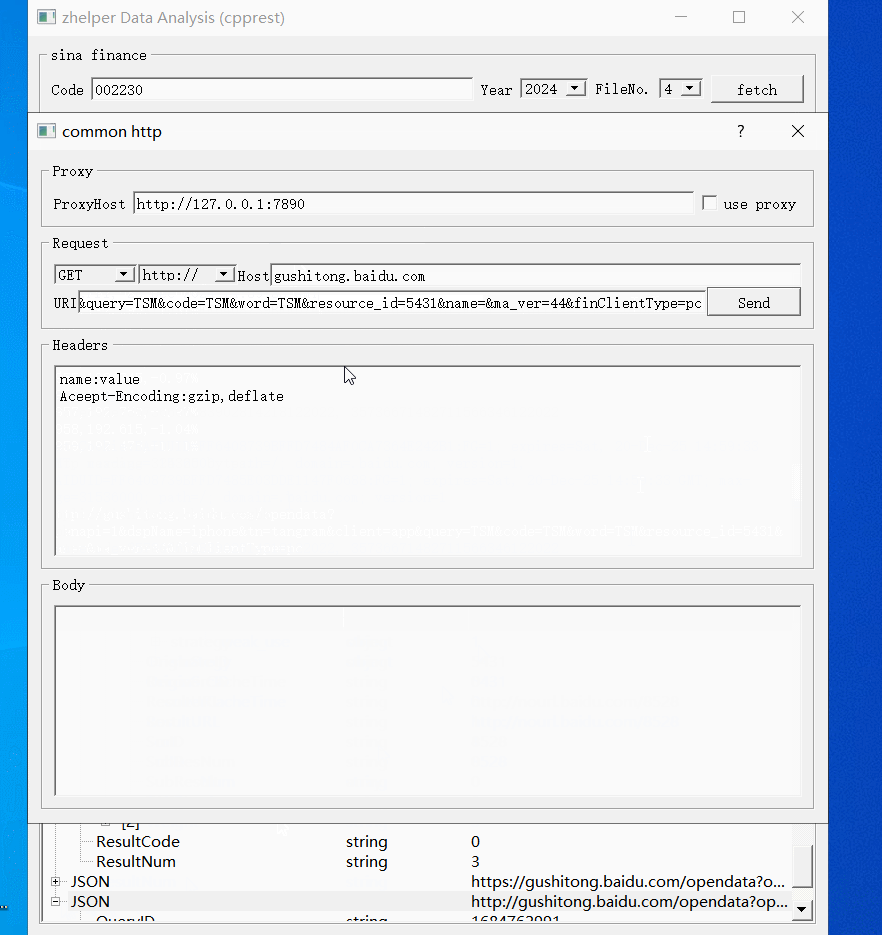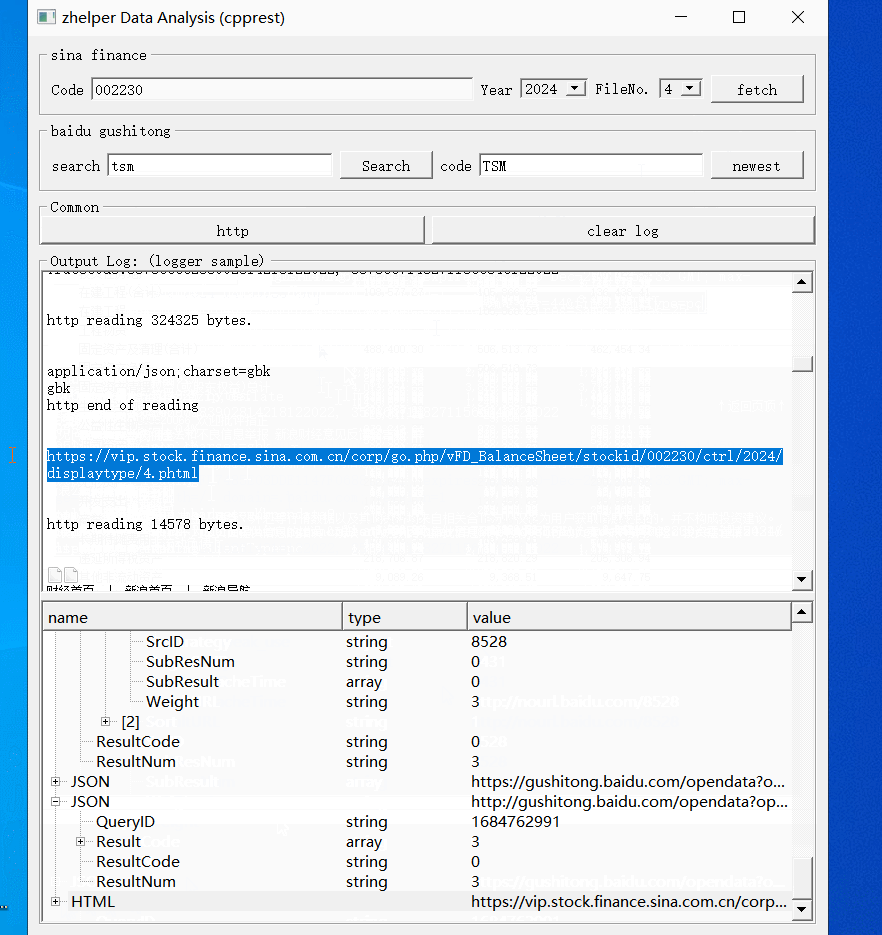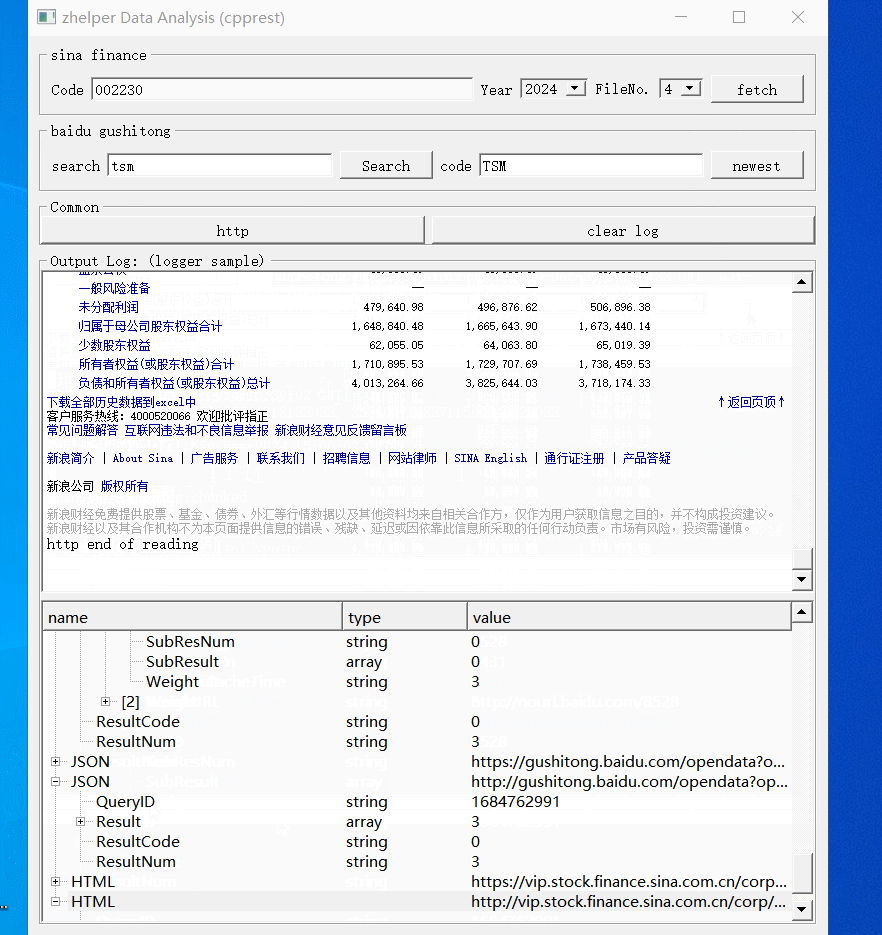
现就用通用请求跟BlackJack例子一同测试一下。
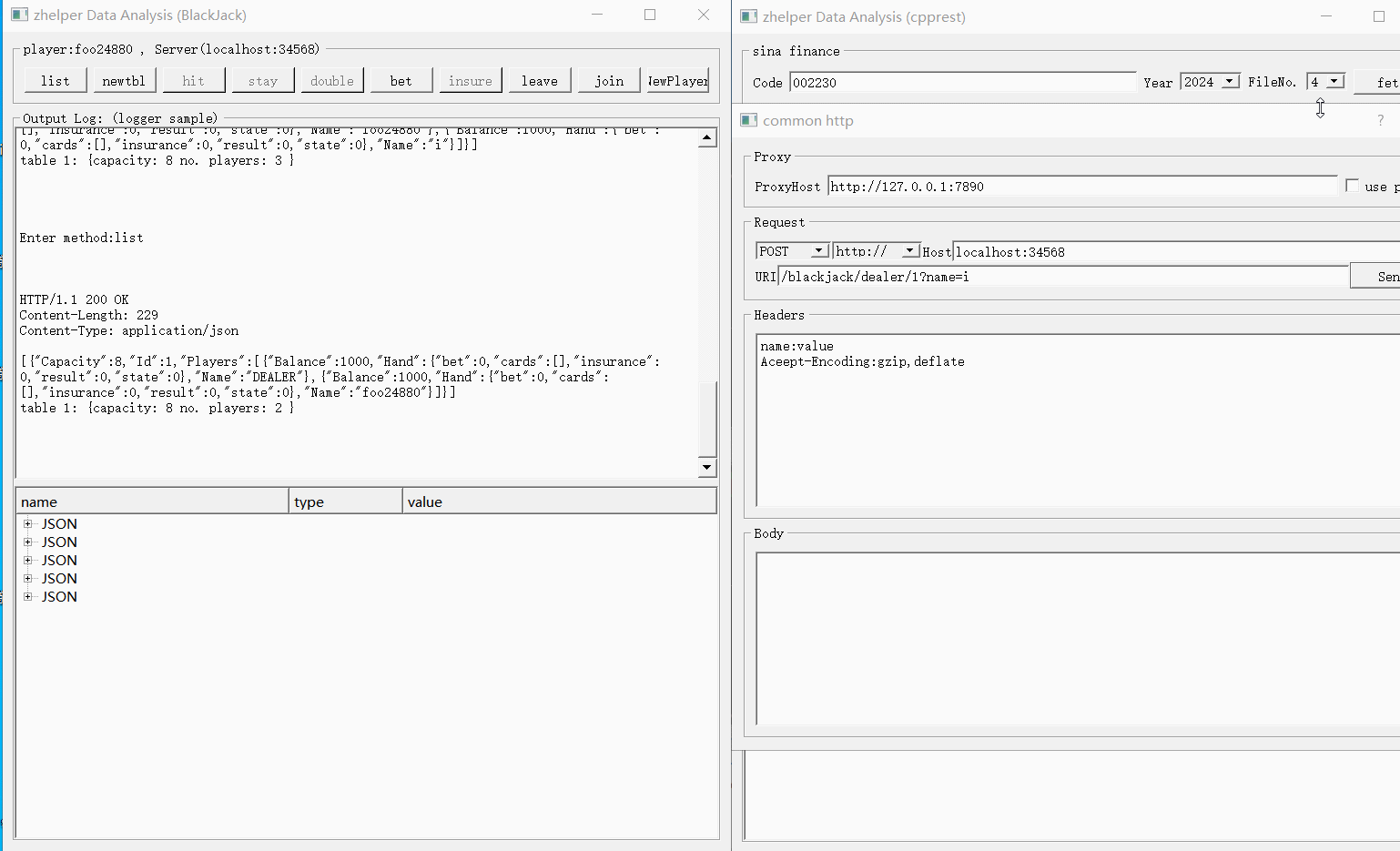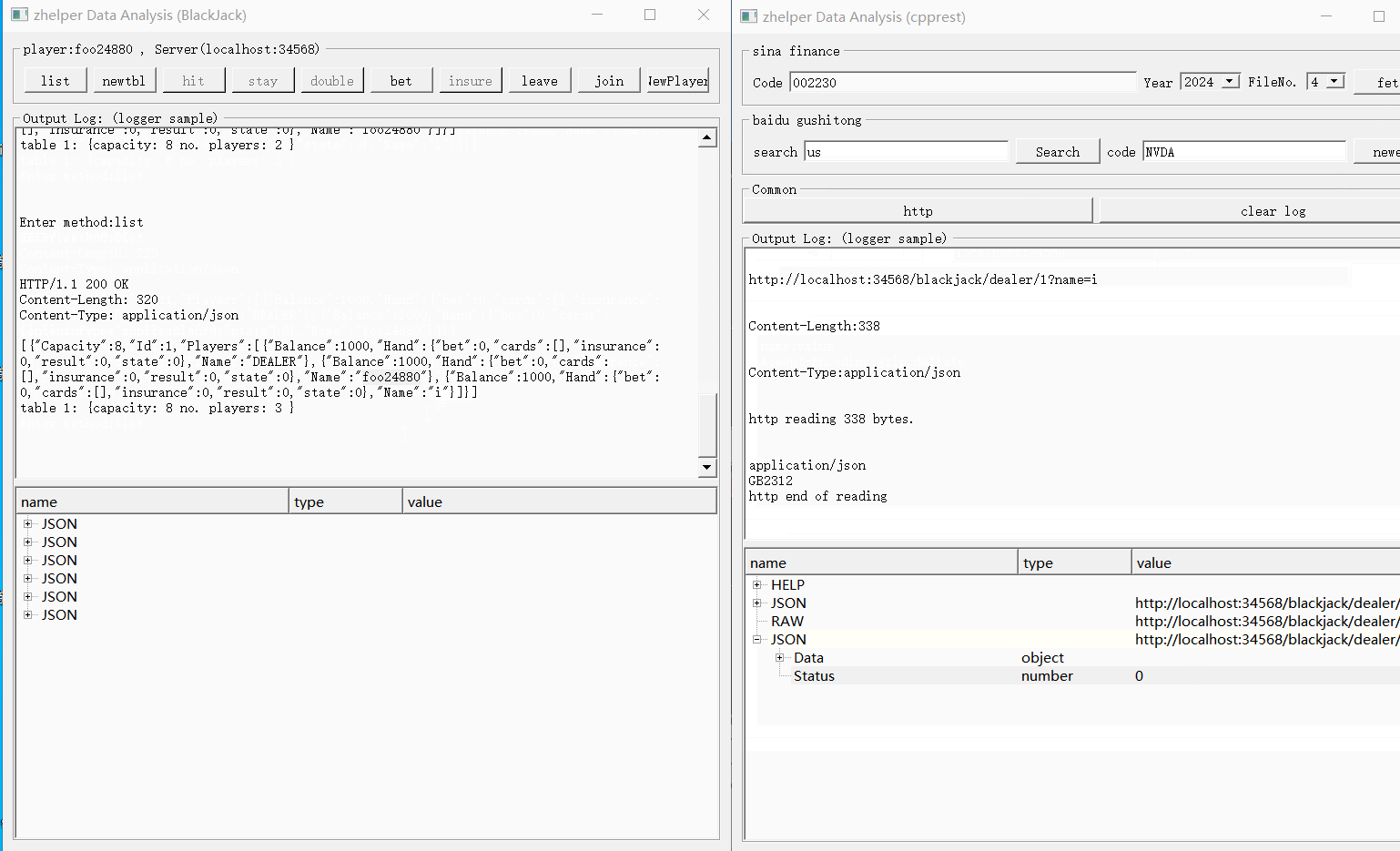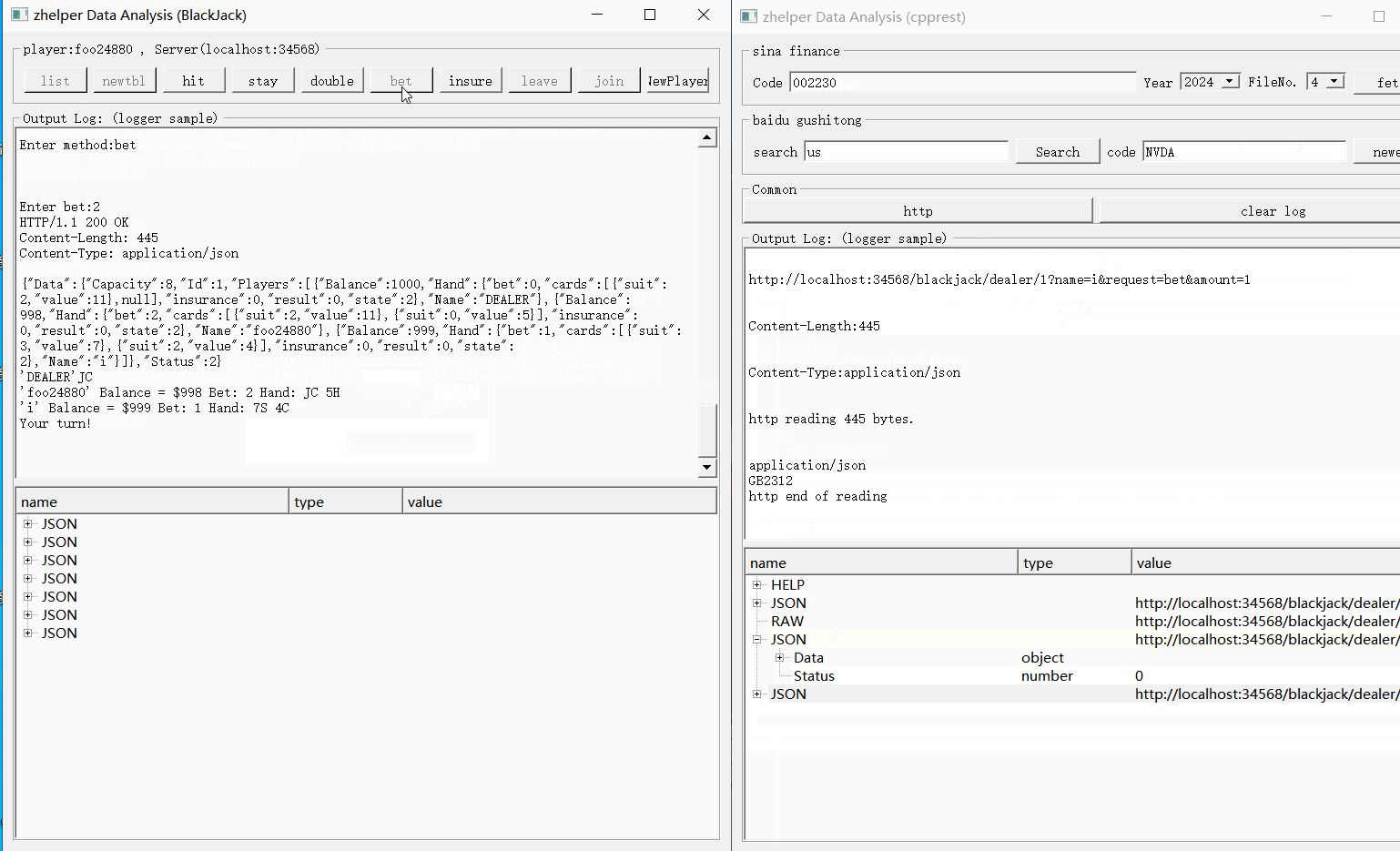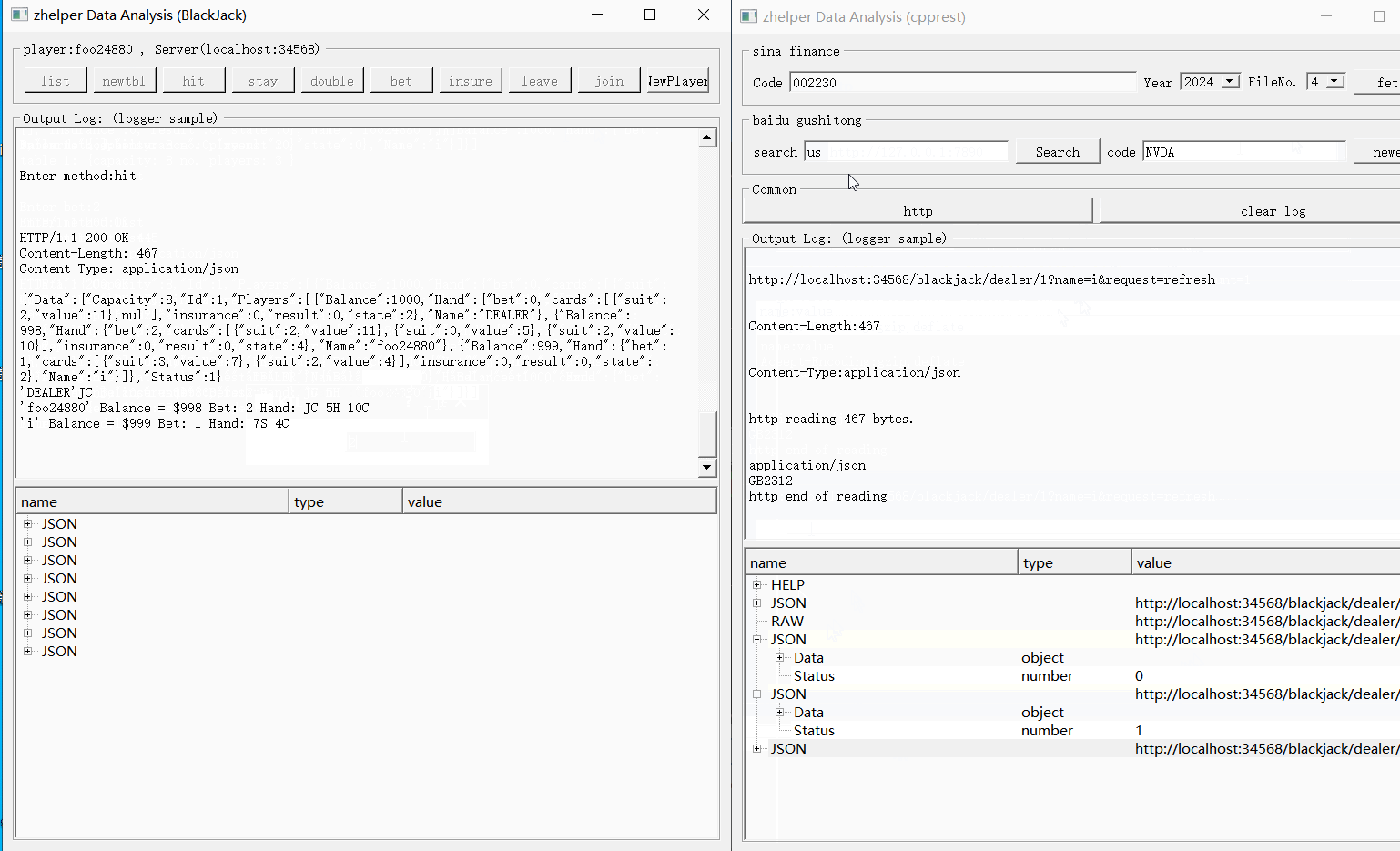
本功能的源代码, 已经完整展示了如何使用cpprest调用opendata接口,如何使用cpprest写界面交互。使用者可以根据需要修改裁剪扩展,满足自己需要的功能。 使用cpprest从其它股票相关网站获取数据也是十分方便。有cpprest借助pplx加承,不必费心多线程跟io并发,轻轻松松写异步http请求。
还有一点注意, cpprest默认使用unicode,qt字符串底层也是使用unicode。其它json11,pugihtml需要utf8。
本篇结束。