介绍
IoC(Inversion of Control:控制反转) 是一种设计思想,而不是一个具体的技术实现。IoC 的思想就是将原本在程序中手动创建对象的控制权,交由 Spring 框架来管理,由Spring容器管理bean的整个生命周期。通俗来说就是
IoC是设计思想,DI是实现方式。
通过反射实现对其他对象的控制,包括初始化、创建、销毁等,解放手动创建对象的过程,同时降低类之间的耦合度。
在 Spring 中,
IoC container
是 Spring 用来实现 IoC 的载体,
IoC 容器实际上就是个 Map(key,value),Map 中存放的是各种对象,根据BeanName或者Type获取对象
。
为何是反转,哪些方面反转了?
有反转就有正转,传统应用程序是由我们自己在对象中主动控制去直接获取依赖对象,也就是正转;而反转则是由容器来帮忙创建及注入依赖对象;
控制
:指的是对象创建(实例化、管理)的权力
反转
:控制权交给外部环境(Spring 框架、IoC 容器)
IOC的好处
ioc的思想最核心的地方在于,资源不由使用资源者管理,而由不使用资源的第三方管理,这可以带来很多好处。
- 资源集中管理,实现资源的可配置和易管理。
- 降低类之间的耦合度。
比如在实际项目中一个 Service 类可能依赖了很多其他的类,假如我们需要实例化这个 Service,可能要每次都要搞清这个 Service 所有底层类的构造函数,这就变得复杂了。而如果使用 IoC 的话,只需要配置好,然后在需要的地方引用就行了,这大大增加了项目的可维护性且降低了开发难度。
IOC配置的四种方式
在
Spring - 概述
一文中已经给出了三种配置方式,这里再总结下;总体上目前的主流方式是
注解 + Java 配置
。
xml 配置
顾名思义,就是将bean的信息配置.xml文件里,通过Spring加载文件来创建bean。这种方式出现很多早前的SSM项目中,将第三方类库或者一些配置工具类都以这种方式进行配置,主要原因是由于第三方类不支持Spring注解。
- 优点
: 可以使用于任何场景,结构清晰,通俗易懂
- 缺点
: 配置繁琐,不易维护,枯燥无味,扩展性差
举例
:
- 配置xx.xml文件
- 声明命名空间和配置bean
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd">
<!-- services -->
<bean id="userService" class="com.seven.springframework.service.UserServiceImpl">
<property name="userDao" ref="userDao"/>
<!-- additional collaborators and configuration for this bean go here -->
</bean>
<!-- more bean definitions for services go here -->
</beans>
Java 配置
将类的创建交给我们配置的JavcConfig类来完成,Spring只负责维护和管理,采用纯Java创建方式。其本质上就是把在XML上的配置声明转移到Java配置类中
- 优点
:适用于任何场景,配置方便,因为是纯Java代码,扩展性高,十分灵活
- 缺点
:由于是采用Java类的方式,声明不明显,如果大量配置,可读性比较差
举例
:
- 创建一个配置类, 添加@Configuration注解声明为配置类
- 创建方法,方法上加上@bean,该方法用于创建实例并返回,该实例创建后会交给spring管理,方法名建议与实例名相同(首字母小写)。注:实例类不需要加任何注解
@Configuration
public class BeansConfig {
@Bean("userDao")
public UserDaoImpl userDao() {
return new UserDaoImpl();
}
@Bean("userService")
public UserServiceImpl userService() {
UserServiceImpl userService = new UserServiceImpl();
userService.setUserDao(userDao());
return userService;
}
}
注解配置
通过在类上加注解的方式,来声明一个类交给Spring管理,Spring会自动扫描带有@Component,@Controller,@Service,@Repository这四个注解的类,然后帮我们创建并管理,前提是需要先配置Spring的注解扫描器。
- 优点
:开发便捷,通俗易懂,方便维护。
- 缺点
:具有局限性,对于一些第三方资源,无法添加注解。只能采用XML或JavaConfig的方式配置
举例
:
- 对类添加@Component相关的注解,比如@Controller,@Service,@Repository
- 设置ComponentScan的basePackage, 比如在xml文件里设置
<context:component-scan base-package='com.seven.springframework'>
, 或者在配置类中设置
@ComponentScan("com.seven.springframework")
注解,或者 直接在APP类中
new AnnotationConfigApplicationContext("com.seven.springframework")
指定扫描的basePackage.
@Service
public class UserServiceImpl {
@Autowired
private UserDaoImpl userDao;
public List<User> findUserList() {
return userDao.findUserList();
}
}
依赖注入DI的方式
其原理是将对象的依赖关系由外部容器来管理和注入。这样,对象只需要关注自身的核心功能,而不需要关心如何获取依赖对象。它的目的是解耦组件之间的依赖关系,提高代码的灵活性、可维护性和可测试性。
在Spring创建对象的过程中,把对象依赖的属性注入到对象中。
依赖注入主要有三种方式:构造器注入,Setter方式注入(属性注入)、基于字段的依赖注入
其中基于字段的依赖注入被广泛使用,但是 idea 或者其他静态代码分析工具会给出提示信息,不推荐使用。
Setter方式注入
在基于 setter 的依赖注入中,setter 方法被标注为 @Autowired。一旦使用无参数构造函数或无参数静态工厂方法实例化 Bean,为了注入 Bean 的依赖项,Spring 容器将调用这些 setter 方法。
- 在XML配置方式中
,property都是setter方式注入,比如下面的xml:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd">
<!-- services -->
<bean id="userService" class="com.seven.springframework.service.UserServiceImpl">
<property name="userDao" ref="userDao"/>
<!-- additional collaborators and configuration for this bean go here -->
</bean>
<!-- more bean definitions for services go here -->
</beans>
本质上包含两步:
- 第一步,需要new UserServiceImpl()创建对象, 所以需要默认构造函数
- 第二步,调用setUserDao()函数注入userDao的值, 所以需要setUserDao()函数
@Component
public class UserServiceImpl {
private UserDao userDao;
@Autowired //这个 @Autowired可以省略
public void setUserDao(UserDao userDao) {
this.userDao = userDao;
}
}
将@Autowired写在被注入的成员变量上,setter或者构造器上,就不用再xml文件中配置了。
基于属性的依赖注入
在基于属性的依赖注入中,以@Autowired(自动注入)注解注入为例,修饰符有三个属性:Constructor,byType,byName。默认按照byType注入。一旦类被实例化,Spring 容器将设置这些字段。
- constructor
:通过构造方法进行自动注入,spring会匹配与构造方法参数类型一致的bean进行注入,如果有一个多参数的构造方法,一个只有一个参数的构造方法,在容器中查找到多个匹配多参数构造方法的bean,那么spring会优先将bean注入到多参数的构造方法中。
- byName
:被注入bean的id名必须与set方法后半截匹配,并且id名称的第一个单词首字母必须小写,这一点与手动set注入有点不同。
- byType
:查找所有的set方法,将符合符合参数类型的bean注入。
@Component
public class FieldBasedInjection {
@Autowired
private InjectedBean injectedBean;
}
可能存在的缺点
正如所看到的,这是依赖注入最干净的方法,因为它避免了添加样板代码,并且不需要声明类的构造函数。代码看起来很干净简洁,但是正如代码检查器已经向我们暗示的那样,这种方法有一些缺点:
- 不允许声明不可变域
:基于字段的依赖注入在声明为 final/immutable 的字段上不起作用,因为这些字段必须在类实例化时实例化。声明不可变依赖项的唯一方法是使用基于构造器的依赖注入。
- 容易违反单一职责设计原则
:使用基于字段的依赖注入,高频使用的类随着时间的推移,会在类中逐渐添加越来越多的依赖项,用着很爽,但很容易忽略类中的依赖已经太多了。但是如果使用基于构造函数的依赖注入,随着越来越多的依赖项被添加到类中,构造函数会变得越来越大,一眼就可以察觉到哪里不对劲。
有一个有超过10个参数的构造函数是一个明显的信号,表明类已经转变一个大而全的功能合集,需要将类分割成更小、更容易维护的块。
因此,尽管属性注入并不是破坏单一责任原则的直接原因,但它隐藏了信号,使我们很容易忽略这些信号。
- 与依赖注入容器紧密耦合
:
使用基于字段的依赖注入的主要原因是为了避免 getter 和 setter 的样板代码或为类创建构造函数。最后,这意味着设置这些字段的唯一方法是通过Spring容器实例化类并使用反射注入它们,否则字段将保持 null。
依赖注入设计模式将类依赖项的创建与类本身分离开来,并将此责任转移到类注入容器,从而允许程序设计解耦,并遵循单一职责和依赖项倒置原则(同样可靠)。因此,通过自动装配(autowiring)字段来实现的类的解耦,最终会因为再次与类注入容器(在本例中是 Spring)耦合而丢失,从而使类在Spring容器之外变得无用。
这意味着,如果想在应用程序容器之外使用您的类,例如用于单元测试,将被迫使用 Spring 容器来实例化您的类,因为没有其他可能的方法(除了反射)来设置自动装配字段。
- 隐藏依赖关系
:在使用依赖注入时,受影响的类应该使用公共接口清楚地公开这些依赖项,方法是在构造函数中公开所需的依赖项,或者使用方法(setter)公开可选的依赖项。当使用基于字段的依赖注入时,实质上是将这些依赖对外隐藏了。
@Autowired和@Resource以及@Inject等注解注的区别
@Autowired
在Spring 2.5 引入了 @Autowired 注解
@Target({ElementType.CONSTRUCTOR, ElementType.METHOD, ElementType.PARAMETER, ElementType.FIELD, ElementType.ANNOTATION_TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface Autowired {
boolean required() default true;//默认是true
}
从Autowired注解源码上看,可以使用在下面这些地方:
@Target(ElementType.CONSTRUCTOR) #构造函数
@Target(ElementType.METHOD) #方法
@Target(ElementType.PARAMETER) #方法参数
@Target(ElementType.FIELD) #字段、枚举的常量
@Target(ElementType.ANNOTATION_TYPE) #注解
- @Autowired是Spring自带的注解,通过AutowiredAnnotationBeanPostProcessor 类实现的依赖注入
- @Autowired可以作用在CONSTRUCTOR、METHOD、PARAMETER、FIELD、ANNOTATION_TYPE
- @Autowired默认是根据类型(byType )进行自动装配的
- 如果有多个类型一样的Bean候选者,需要指定按照名称(byName )进行装配,则需要配合 @Qualifier。
指定名称后,如果Spring IOC容器中没有对应的组件bean抛出NoSuchBeanDefinitionException。也可以将@Autowired中required配置为false,如果配置为false之后,当没有找到相应bean的时候,系统不会抛异常
在SpringBoot中也可以使用@Bean + @Autowired进行组件注入,将@Autowired加到参数上,其实也可以省略。
@Bean
public Person getPerson(@Autowired Car car){
return new Person();
}
// @Autowired 其实也可以省略
@Resource
Resource注解源码:
@Target({TYPE, FIELD, METHOD})
@Retention(RUNTIME)
public @interface Resource {
String name() default "";//指定注入指定名称的组件,name 的作用类似 @Qualifier
// 其他省略
}
从Resource注解源码上看,可以使用在下面这些地方:
@Target(ElementType.TYPE) #接口、类、枚举、注解
@Target(ElementType.FIELD) #字段、枚举的常量
@Target(ElementType.METHOD) #方法
- @Resource是JSR250规范的实现,在javax.annotation包下
- @Resource可以作用TYPE、FIELD、METHOD上
- @Resource是默认根据属性名称进行自动装配的,如果有多个类型一样的Bean候选者,则可以通过name进行指定进行注入
@Inject
@Target({ METHOD, CONSTRUCTOR, FIELD })
@Retention(RUNTIME)
@Documented
public @interface Inject {}
从Inject注解源码上看,可以使用在下面这些地方:
@Target(ElementType.CONSTRUCTOR) #构造函数
@Target(ElementType.METHOD) #方法
@Target(ElementType.FIELD) #字段、枚举的常量
- @Inject是JSR330 (Dependency Injection for Java)中的规范,需要导入javax.inject.Inject jar包 ,才能实现注入
- @Inject可以作用CONSTRUCTOR、METHOD、FIELD上
- @Inject是根据类型进行自动装配的,如果需要按名称进行装配,则需要配合@Named;@Named 的作用类似 @Qualifier!
构造器注入
- 在XML配置方式中
,
<constructor-arg>
是通过构造函数参数注入,比如下面的xml:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd">
<!-- services -->
<bean id="userService" class="com.seven.springframework.service.UserServiceImpl">
<constructor-arg name="userDao" ref="userDao"/>
<!-- additional collaborators and configuration for this bean go here -->
</bean>
<!-- more bean definitions for services go here -->
</beans>
在基于构造函数的依赖注入中,类构造函数被标注为 @Autowired,并包含了许多与要注入的对象相关的参数。
@Component
public class ConstructorBasedInjection {
private final InjectedBean injectedBean;
@Autowired //当然,这个@Autowired可以省略
public ConstructorBasedInjection(InjectedBean injectedBean) {
this.injectedBean = injectedBean;
}
}
将@Autowired写在被注入的成员变量上,setter或者构造器上,就不用再xml文件中配置了。
注意
:不能提供无参构造方法,否则Springboot默认会加载无参的构造方法,Bean实例对象会为null。并且构造器的权限需要为public
为什么建议使用构造器注入
一般推荐构造器注入,为什么?Spring文档里的解释如下:
The Spring team generally advocates constructor injection as it enables one to implement application components as immutable objects and to ensure that required dependencies are not null. Furthermore constructor-injected components are always returned to client (calling) code in a fully initialized state.
翻译一下就是:这个构造器注入的方式能够保证注入的组件不可变,并且确保需要的依赖不为空。此外,构造器注入的依赖总是能够在返回客户端(组件)代码的时候保证完全初始化的状态。
依赖不可变
:其实说的就是final关键字。
依赖不为空
:(省去了我们对其检查):当要实例化UserServiceImpl的时候,由于自己实现了有参数的构造函数,所以不会调用默认构造函数,那么就需要Spring容器传入所需要的参数,所以就两种情况:1、有该类型的参数->传入,OK 。2:无该类型的参数->报错。
完全初始化的状态
:这个可以跟上面的依赖不为空结合起来,向构造器传参之前,要确保注入的内容不为空,那么肯定要调用依赖组件的构造方法完成实例化。而在Java类加载实例化的过程中,构造方法是最后一步(之前如果有父类先初始化父类,然后自己的成员变量,最后才是构造方法),所以返回来的都是初始化之后的状态。
如果使用setter注入,缺点显而易见,对于IOC容器以外的环境,除了使用反射来提供它需要的依赖之外,无法复用该实现类。而且将一直是个潜在的隐患,因为你不调用将一直无法发现NPE的存在
// 这里只是模拟一下,正常来说我们只会暴露接口给客户端,不会暴露实现。
UserServiceImpl userService = newUserServiceImpl();
userService.findUserList();// -> NullPointerException, 潜在的隐患
总结
:对于必需的依赖,建议使用基于构造函数的注入,设置它们为不可变的,并防止它们为 null。对于可选的依赖项,建议使用基于 setter 的注入。
借助lombok简化
然而,手动编写构造函数可能会使代码
显得冗长不美观
。Lombok 是一个非常好的工具,它能够通过注解自动生成构造函数,从而使代码更加简洁和优雅。
Lombok提供的
@AllArgsConstructor
注解可以帮助我们自动生成包含所有字段的构造函数。此外,
@RequiredArgsConstructor
注解可以生成包含所有
final
字段和带有
@NonNull
注解字段的构造函数,这通常是我们在依赖注入中需要的。
@Component
@RequiredArgsConstructor // 自动生成包含final字段的构造函数
public class ConstructorBasedInjection {
private final InjectedBean injectedBean;
}
Bean注入的七种方式
使用xml方式来声明Bean的定义,Spring容器在启动会加载并解析这个xml,把bean装载到IOC容器中
使用@CompontScan注解来扫描声明了@Controller、@Service、@Repository、@Component注解的类
使用@Configuration注解声明配置类,并使用@Bean注解实现Bean的定义,这种方式其实是xml配置方式的一种演变,是Spring迈入到无xml 时代的里程碑
使用@Import注解,导入配置类或者普通的Bean
使用FactoryBean工厂bean, 动态构建一个Bean实例,Spring Cloud OpenFeign 里面的动态代理实例就是使用FactoryBean来实现的
实现ImportBeanDefinitionRegistrar接口,可以动态注入Bean实例。这个在Spring Boot里面的启动注解有用到
实现ImportSelector接口,动态批量注入配置类或者Bean对象,这个在Spring Boot里面的自动装配机制里面有用到
Bean的作用域
- singleton
:单例,Spring中的bean默认都是单例的。
- prototype
:每次请求都会创建一个新的bean实例。
- request
:每一次HTTP请求都会产生一个新的bean,该bean仅在当前HTTP request内有效。
- session
:每一次HTTP请求都会产生一个新的bean,该bean仅在当前HTTP session内有效。
- global-session
:全局session作用域。
- websocket
(仅 Web 应用可用):每一次 WebSocket 会话产生一个新的 bean。
如何配置 bean 的作用域呢?
xml 方式:
<bean id="..." class="..." scope="singleton"></bean>
注解方式:
@Bean
@Scope(value = ConfigurableBeanFactory.SCOPE_PROTOTYPE)
public Person personPrototype() {
return new Person();
}
Bean 是线程安全的吗
Spring 框架中的 Bean 是否线程安全,取决于其作用域和状态。
这里以最常用的两种作用域 prototype 和 singleton 为例介绍。几乎所有场景的 Bean 作用域都是使用默认的 singleton ,重点关注 singleton 作用域即可。
prototype 作用域
下,每次获取都会创建一个新的 bean 实例,不存在资源竞争问题,所以不存在线程安全问题。
singleton 作用域
下,IoC 容器中只有唯一的 bean 实例,可能会存在资源竞争问题(取决于 Bean 是否有状态)。如果这个 bean 是有状态的话,那就存在线程安全问题(有状态 Bean 是指包含可变的成员变量的对象)。
不过,大部分 Bean 实际都是无状态(没有定义可变的成员变量)的(比如 Dao、Service),这种情况下, Bean 是线程安全的。
对于有状态单例 Bean 的线程安全问题,常见的有两种解决办法:
- 在 Bean 中尽量避免定义可变的成员变量。
- 在类中定义一个
ThreadLocal
成员变量,将需要的可变成员变量保存在
ThreadLocal
中(推荐的一种方式)。
IOC的结构设计
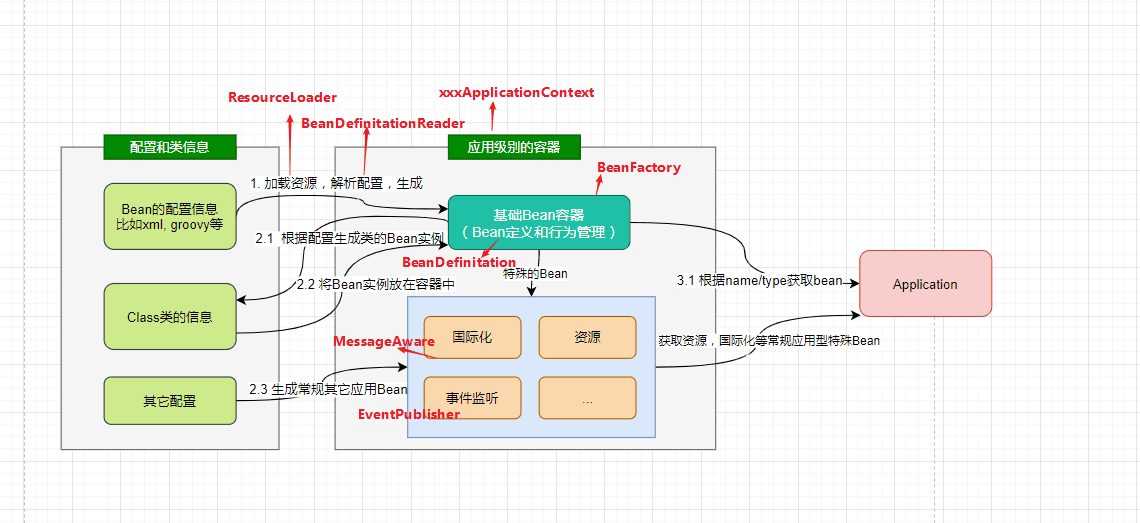
Spring Bean的创建是典型的
工厂模式
,这一系列的Bean工厂,也即IOC容器为开发者管理对象间的依赖关系提供了很多便利和基础服务,在Spring中有许多的IOC容器的实现供用户选择和使用,这是IOC容器的基础;在顶层的结构设计主要围绕着BeanFactory和xxxRegistry进行:
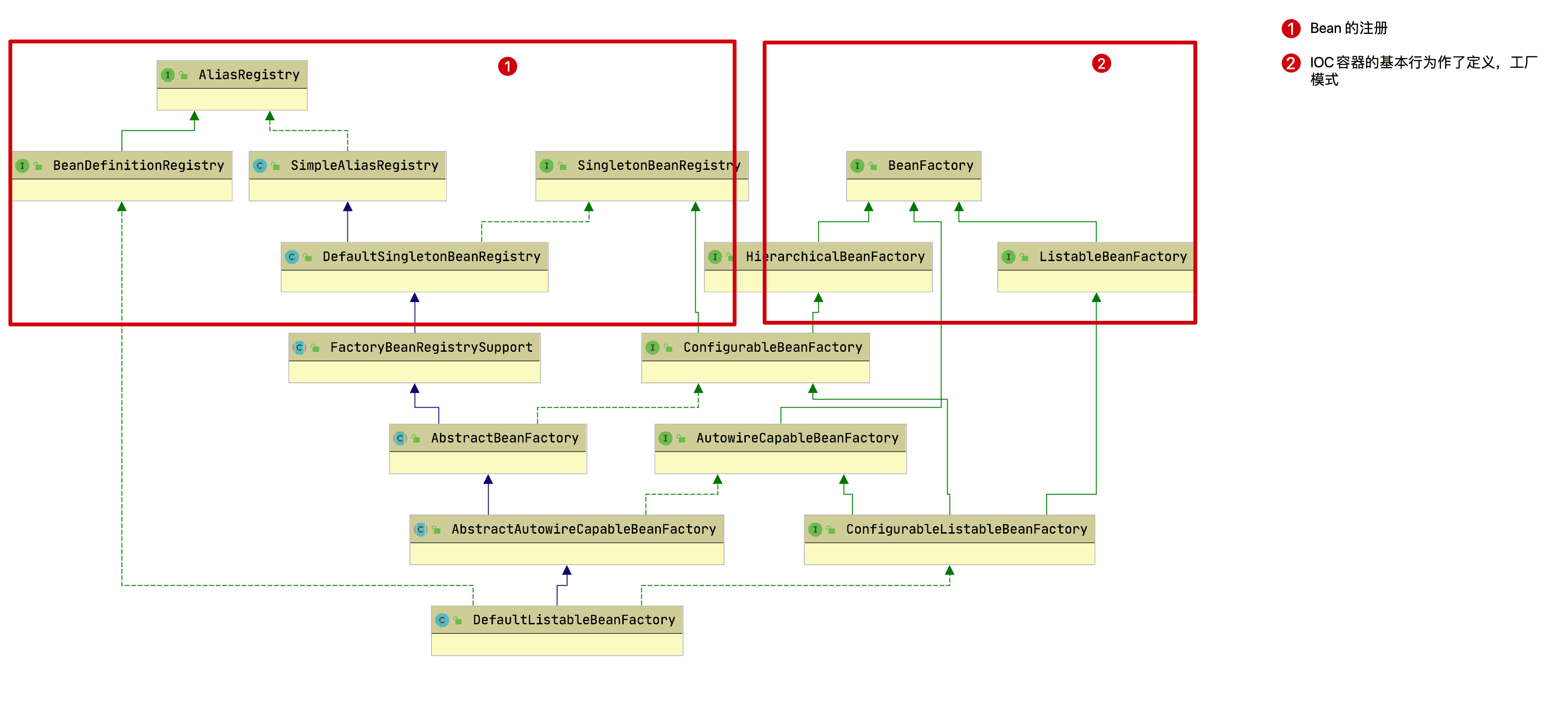
BeanFactory
- BeanFactory: 工厂模式定义了IOC容器的基本功能规范
BeanFactory作为最顶层的一个接口类,它定义了IOC容器的基本功能规范
,BeanFactory 有三个子类:ListableBeanFactory、HierarchicalBeanFactory 和AutowireCapableBeanFactory。先看下BeanFactory接口:
public interface BeanFactory {
//用于取消引用实例并将其与FactoryBean创建的bean区分开来。例如,如果命名的bean是FactoryBean,则获取将返回Factory,而不是Factory返回的实例。
String FACTORY_BEAN_PREFIX = "&";
//根据bean的名字和Class类型等来得到bean实例
Object getBean(String name) throws BeansException;
Object getBean(String name, Class requiredType) throws BeansException;
Object getBean(String name, Object... args) throws BeansException;
<T> T getBean(Class<T> requiredType) throws BeansException;
<T> T getBean(Class<T> requiredType, Object... args) throws BeansException;
//返回指定bean的Provider
<T> ObjectProvider<T> getBeanProvider(Class<T> requiredType);
<T> ObjectProvider<T> getBeanProvider(ResolvableType requiredType);
//检查工厂中是否包含给定name的bean,或者外部注册的bean
boolean containsBean(String name);
//检查所给定name的bean是否为单例/原型
boolean isSingleton(String name) throws NoSuchBeanDefinitionException;
boolean isPrototype(String name) throws NoSuchBeanDefinitionException;
//判断所给name的类型与type是否匹配
boolean isTypeMatch(String name, ResolvableType typeToMatch) throws NoSuchBeanDefinitionException;
boolean isTypeMatch(String name, Class<?> typeToMatch) throws NoSuchBeanDefinitionException;
//获取给定name的bean的类型
@Nullable
Class<?> getType(String name) throws NoSuchBeanDefinitionException;
//返回给定name的bean的别名
String[] getAliases(String name);
}
BeanFactory的其他接口主要是为了区分在 Spring 内部在操作过程中对象的传递和转化过程中,对对象的数据访问所做的限制。
- ListableBeanFactory:该接口定义了访问容器中 Bean 基本信息的若干方法,如查看Bean 的个数、获取某一类型 Bean 的配置名、查看容器中是否包括某一 Bean 等方法;
- HierarchicalBeanFactory:父子级联 IoC 容器的接口,子容器可以通过接口方法访问父容器; 通过 HierarchicalBeanFactory 接口, Spring 的 IoC 容器可以建立父子层级关联的容器体系,子容器可以访问父容器中的 Bean,但父容器不能访问子容器的 Bean。Spring 使用父子容器实现了很多功能,比如在 Spring MVC 中,展现层 Bean 位于一个子容器中,而业务层和持久层的 Bean 位于父容器中。这样,展现层 Bean 就可以引用业务层和持久层的 Bean,而业务层和持久层的 Bean 则看不到展现层的 Bean。
- ConfigurableBeanFactory:是一个重要的接口,增强了 IoC 容器的可定制性,它定义了设置类装载器、属性编辑器、容器初始化后置处理器等方法;
- ConfigurableListableBeanFactory: ListableBeanFactory 和 ConfigurableBeanFactory的融合;AutowireCapableBeanFactory:定义了将容器中的 Bean 按某种规则(如按名字匹配、按类型匹配等)进行自动装配的方法;
BeanRegistry
- BeanRegistry: 向IOC容器手工注册 BeanDefinition 对象的方法
Spring 配置文件中每一个节点元素在 Spring 容器里都通过一个 BeanDefinition 对象表示,它描述了 Bean 的配置信息。而 BeanDefinitionRegistry 接口提供了向容器手工注册 BeanDefinition 对象的方法。
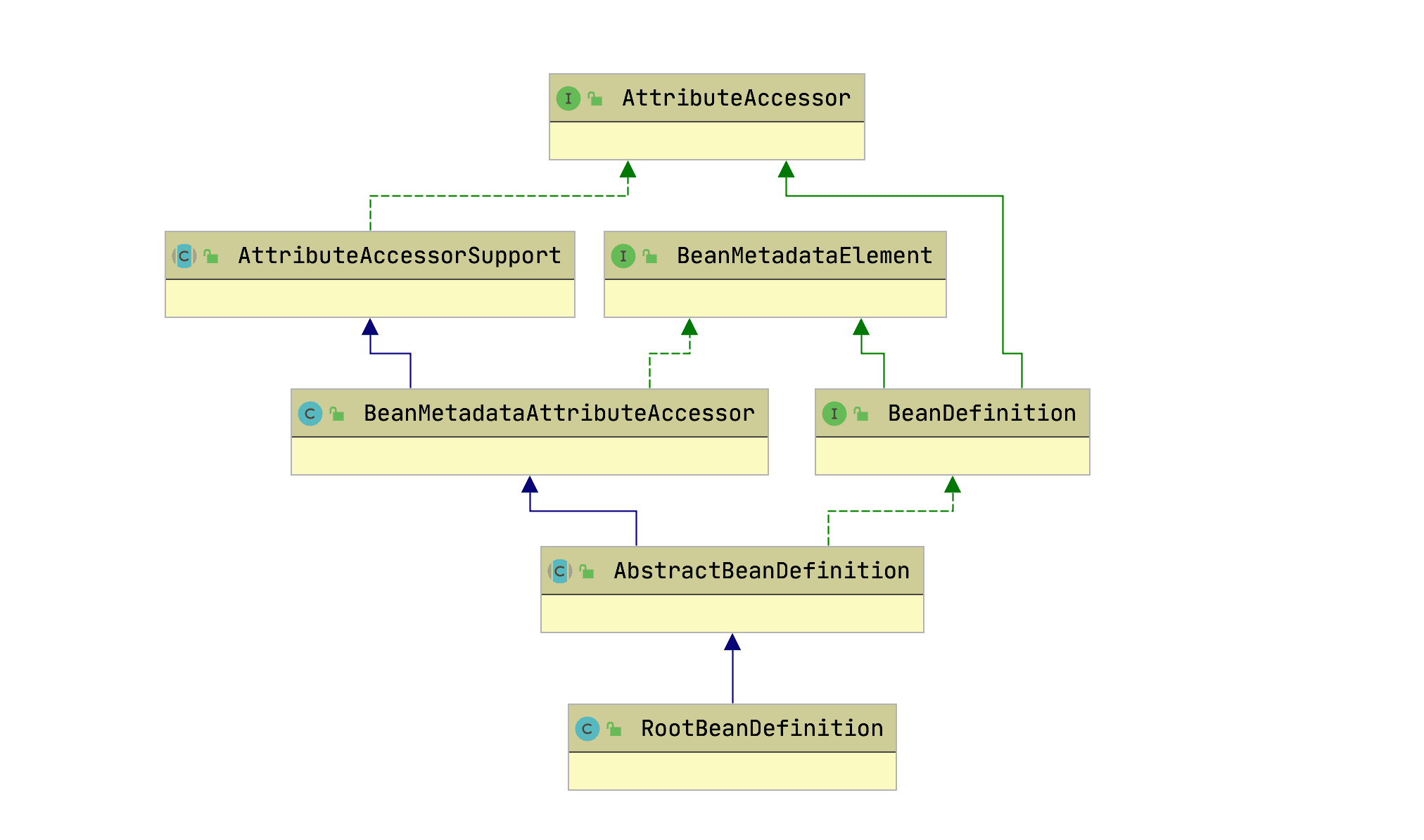
BeanDefinition
各种Bean对象及其相互的关系
BeanDefinition 定义了各种Bean对象及其相互的关系
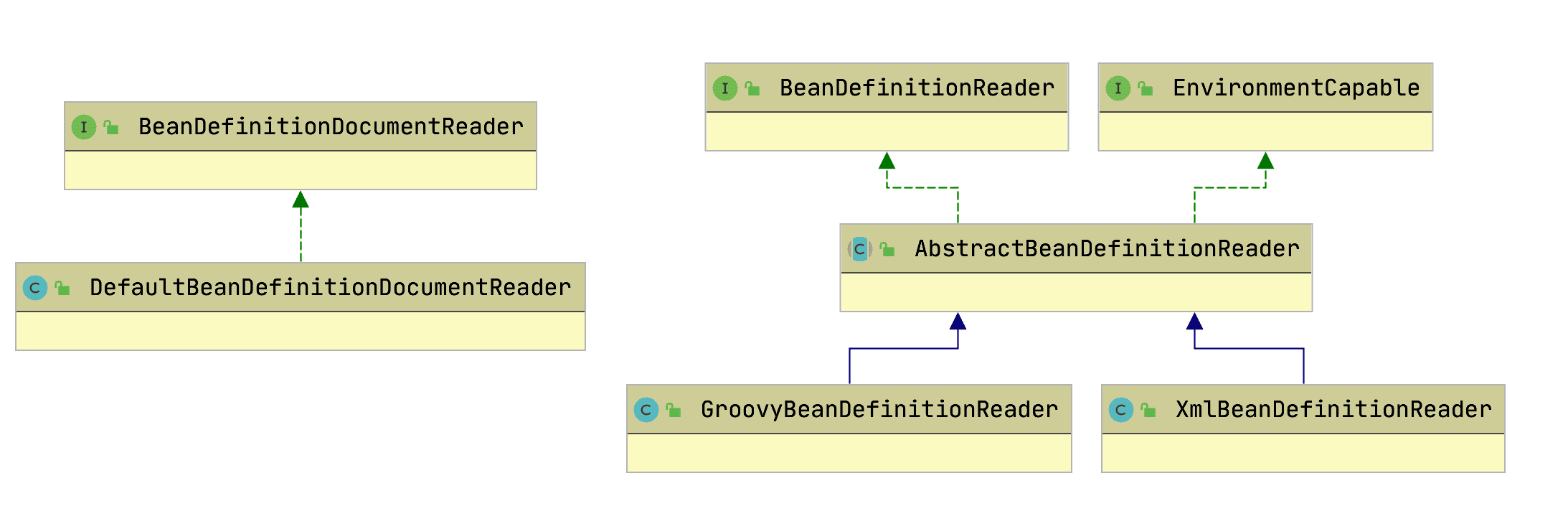
BeanDefinitionReader 这是BeanDefinition的解析器
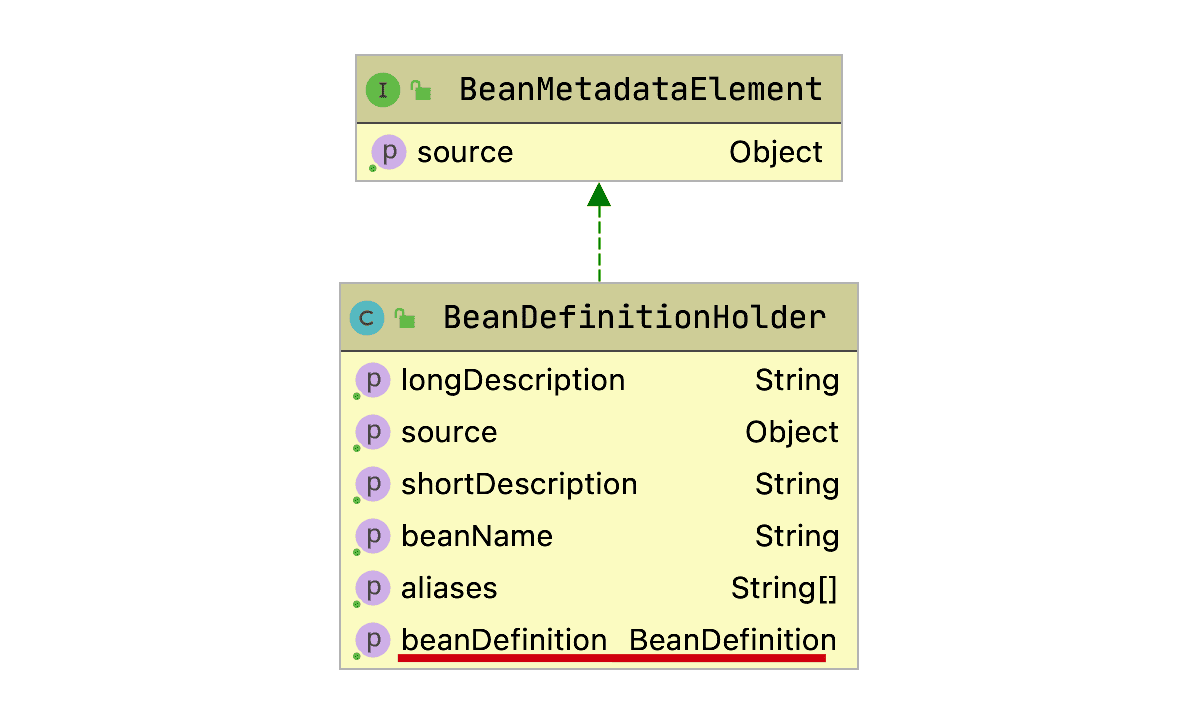
BeanDefinitionHolder 这是BeanDefination的包装类,用来存储BeanDefinition,name以及aliases等。
BeanDefinition
SpringIOC容器管理了定义的各种Bean对象及其相互的关系,Bean对象在Spring实现中是以BeanDefinition来描述的,其继承体系如下
BeanDefinitionReader
Bean 的解析过程非常复杂,功能被分的很细,因为这里需要被扩展的地方很多,必须保证有足够的灵活性,以应对可能的变化。Bean 的解析主要就是对 Spring 配置文件的解析。这个解析过程主要通过下图中的类完成:
BeanDefinitionHolder
BeanDefinitionHolder 是BeanDefination的包装类,用来存储BeanDefinition,name以及aliases等
ApplicationContext
IoC容器的接口类是ApplicationContext,很显然它必然继承BeanFactory对Bean规范(最基本的ioc容器的实现)进行定义。而ApplicationContext表示的是应用的上下文,除了对Bean的管理外,还至少应该包含了
访问资源: 对不同方式的Bean配置(即资源)进行加载。(实现ResourcePatternResolver接口)
国际化: 支持信息源,可以实现国际化。(实现MessageSource接口)
应用事件: 支持应用事件。(实现ApplicationEventPublisher接口)
接口设计
ApplicationContext整体结构:
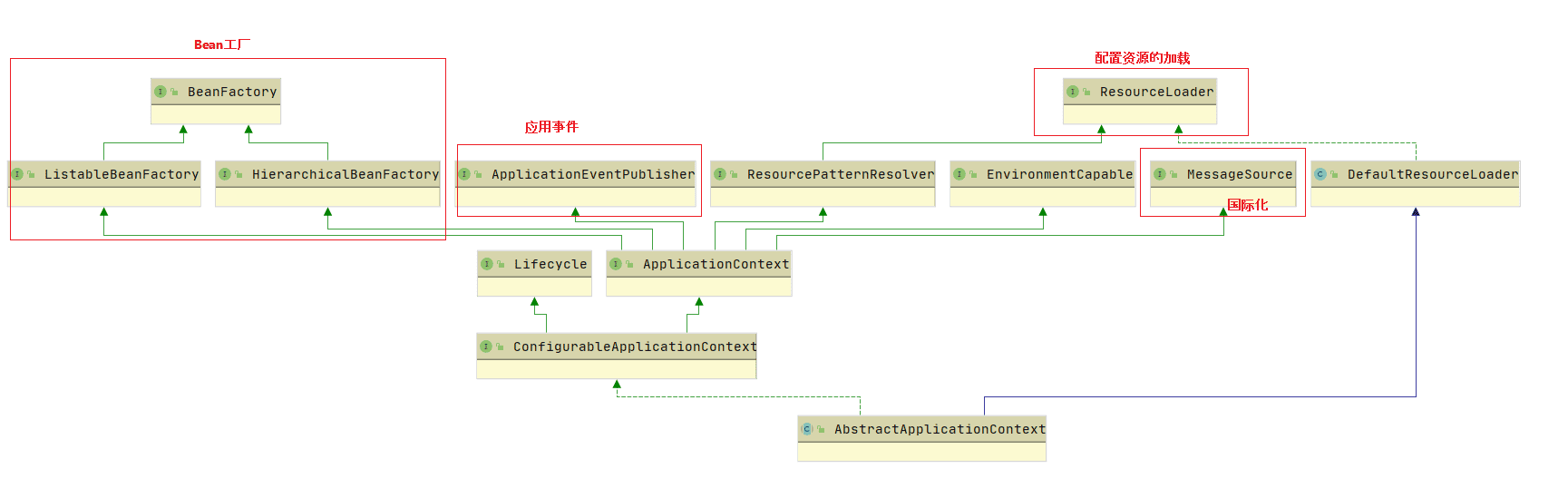
- HierarchicalBeanFactory 和 ListableBeanFactory: ApplicationContext 继承了 HierarchicalBeanFactory 和 ListableBeanFactory 接口,在此基础上,还通过多个其他的接口扩展了BeanFactory的功能
- ApplicationEventPublisher:让容器拥有发布应用上下文事件的功能,包括容器启动事件、关闭事件等。实现了 ApplicationListener 事件监听接口的 Bean 可以接收到容器事件 , 并对事件进行响应处理 。 在 ApplicationContext 抽象实现类AbstractApplicationContext 中,我们可以发现存在一个 ApplicationEventMulticaster,它负责保存所有监听器,以便在容器产生上下文事件时通知这些事件监听者。
- MessageSource:为应用提供 i18n 国际化消息访问的功能;
- ResourcePatternResolver : 所 有 ApplicationContext 实现类都实现了类似于PathMatchingResourcePatternResolver 的功能,可以通过带前缀的 Ant 风格的资源文件路径装载 Spring 的配置文件。
- LifeCycle:该接口是 Spring 2.0 加入的,该接口提供了 start()和 stop()两个方法,主要用于控制异步处理过程。在具体使用时,该接口同时被 ApplicationContext 实现及具体 Bean 实现, ApplicationContext 会将 start/stop 的信息传递给容器中所有实现了该接口的 Bean,以达到管理和控制 JMX、任务调度等目的
接口的实现
ApplicationContext接口的实现,关键的点在于,不同Bean的配置方式(比如xml,groovy,annotation等)有着不同的资源加载方式,这便衍生除了众多ApplicationContext的实现类。

第一,从类结构设计上看, 围绕着是否需要Refresh容器衍生出两个抽象类:
GenericApplicationContext: 是初始化的时候就创建容器,往后的每次refresh都不会更改
AbstractRefreshableApplicationContext: AbstractRefreshableApplicationContext及子类的每次refresh都是先清除已有(如果不存在就创建)的容器,然后再重新创建;AbstractRefreshableApplicationContext及子类无法做到GenericApplicationContext混合搭配从不同源头获取bean的定义信息
第二, 从加载的源来看(比如xml,groovy,annotation等), 衍生出众多类型的ApplicationContext, 典型比如:
FileSystemXmlApplicationContext: 从文件系统下的一个或多个xml配置文件中加载上下文定义,也就是说系统盘符中加载xml配置文件。
ClassPathXmlApplicationContext: 从类路径下的一个或多个xml配置文件中加载上下文定义,适用于xml配置的方式。
AnnotationConfigApplicationContext: 从一个或多个基于java的配置类中加载上下文定义,适用于java注解的方式。
ConfigurableApplicationContext: 扩展于 ApplicationContext,它新增加了两个主要的方法: refresh()和 close(),让 ApplicationContext 具有启动、刷新和关闭应用上下文的能力。在应用上下文关闭的情况下调用 refresh()即可启动应用上下文,在已经启动的状态下,调用 refresh()则清除缓存并重新装载配置信息,而调用close()则可关闭应用上下文。这些接口方法为容器的控制管理带来了便利,但作为开发者,我们并不需要过多关心这些方法。
第三, 更进一步理解:
设计者在设计时AnnotationConfigApplicationContext为什么是继承GenericApplicationContext? 因为基于注解的配置,是不太会被运行时修改的,这意味着不需要进行动态Bean配置和刷新容器,所以只需要GenericApplicationContext。
而基于XML这种配置文件,这种文件是容易修改的,需要动态性刷新Bean的支持,所以XML相关的配置必然继承AbstractRefreshableApplicationContext; 且存在多种xml的加载方式(位置不同的设计),所以必然会设计出AbstractXmlApplicationContext, 其中包含对XML配置解析成BeanDefination的过程。
面试题专栏
Java面试题专栏
已上线,欢迎访问。
- 如果你不知道简历怎么写,简历项目不知道怎么包装;
- 如果简历中有些内容你不知道该不该写上去;
- 如果有些综合性问题你不知道怎么答;
那么可以私信我,我会尽我所能帮助你。