RAG七十二式:2024年度RAG清单

回顾2024,大模型日新月异,智能体百家争鸣。作为AI应用的重要组成部分,RAG也是“群雄逐鹿,诸侯并起”。年初ModularRAG持续升温、GraphRAG大放异彩,年中开源工具如火如荼、知识图谱再创新机,年末图表理解、多模态RAG又启新征程,简直“你方唱罢我登场”,奇技叠出,不胜枚举!
我在这里遴选了2024年度典型的RAG系统和论文(含AI注解、来源、摘要信息),并于文末附上RAG综述和测试基准材料,望执此一文,计一万六千言,助大家速通RAG。
全文共72篇,逐月为纲,强谓之“RAG七十二式”,以献诸位。
2024.01
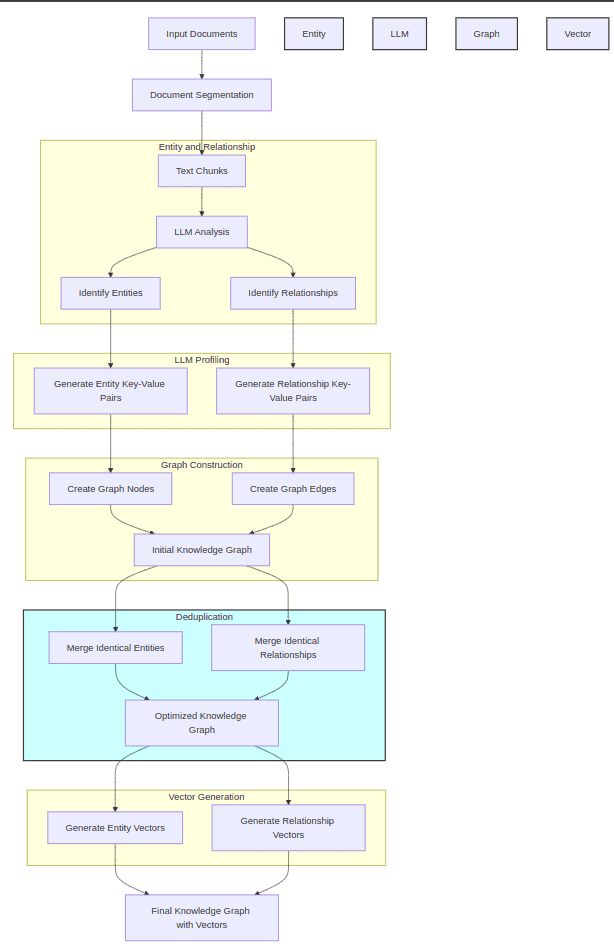
(01) GraphReader【图解专家】
图解专家
:像个善于制作思维导图的导师,将冗长的文本转化为清晰的知识网络,让AI能够像沿着地图探索一样,轻松找到答案需要的各个关键点,有效克服了处理长文本时的"迷路"问题。
- 时间:01.20
- 论文:
GraphReader: Building Graph-based Agent to Enhance Long-Context Abilities of Large Language Models - 参考:
https://mp.weixin.qq.com/s/eg3zIZ_3yhiJK83aTvQE2g
GraphReader是一种基于图的智能体系统,旨在通过将长文本构建成图并使用智能体自主探索该图来处理长文本。在接收到问题后,智能体首先进行逐步分析并制定合理的计划。然后,它调用一组预定义的函数来读取节点内容和邻居,促进对图进行从粗到细的探索。在整个探索过程中,智能体不断记录新的见解并反思当前情况以优化过程,直到它收集到足够的信息来生成答案。
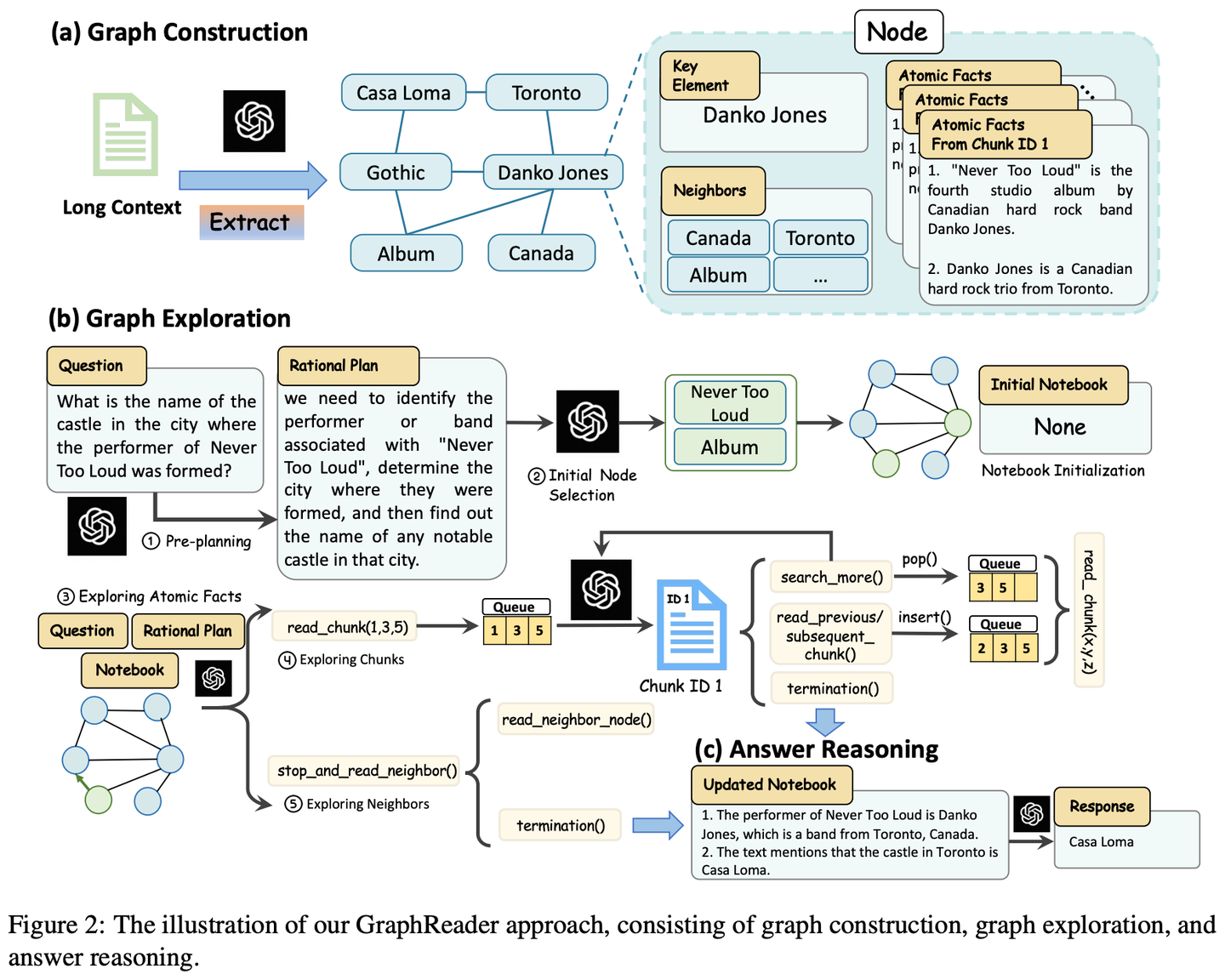
(02) MM-RAG【多面手】
多面手
:就像一个能同时精通视觉、听觉和语言的全能选手,不仅能理解不同形式的信息,还能在它们之间自如切换和关联。通过对各种信息的综合理解,它能在推荐、助手、媒体等多个领域提供更智能、更自然的服务。
- 时间:01.22
- 参考:
https://mp.weixin.qq.com/s/wGar-qBfvjdi5juO1c0YxQ
介绍了多模态机器学习的发展,包括对比学习、多模态嵌入实现的任意模态搜索、多模态检索增强生成(MM-RAG)以及如何使用向量数据库构建多模态生产系统等。同时还探讨了多模态人工智能的未来发展趋势,强调了其在推荐系统、虚拟助手、媒体和电子商务等领域的应用前景。
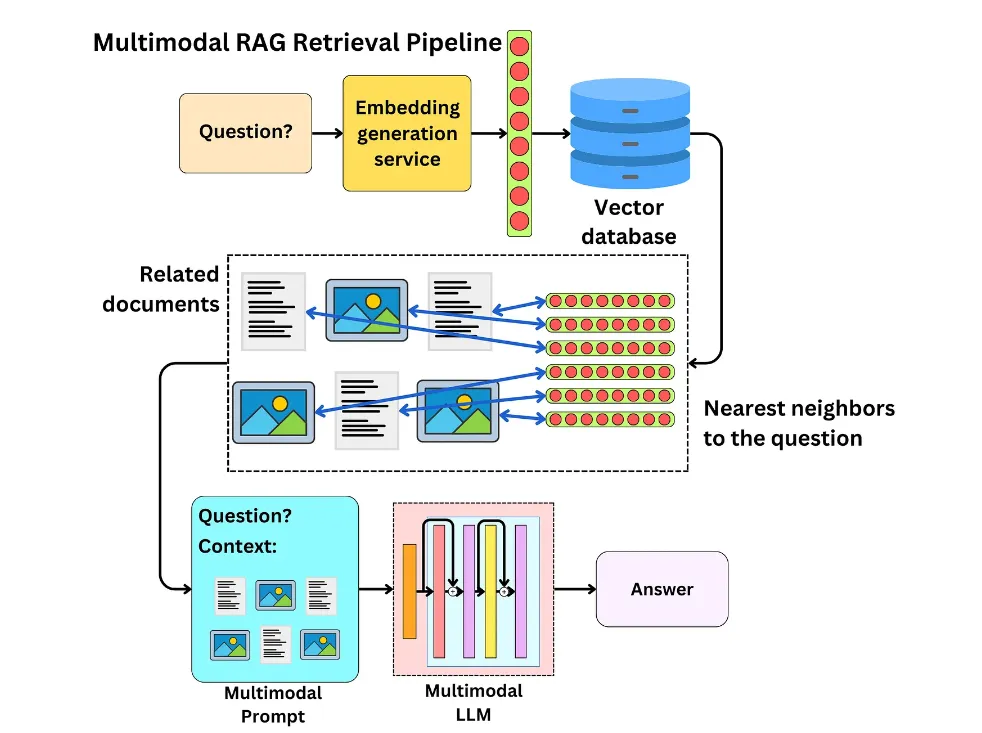
(03) CRAG【自我校正】
自我校正
:像个经验丰富的编辑,先用简单快速的方式筛选初步资料,再通过网络搜索扩充信息,最后通过拆解重组的方式,确保最终呈现的内容既准确又可靠。就像是给RAG装上了一个质量控制系统,让它产出的内容更值得信赖。
- 时间:01.29
- 论文:
Corrective Retrieval Augmented Generation - 项目:
https://github.com/HuskyInSalt/CRAG - 参考:
https://mp.weixin.qq.com/s/HTN66ca6OTF_2YcW0Mmsbw
CRAG通过设计轻量级的检索评估器和引入大规模网络搜索,来改进检索文档的质量,并通过分解再重组算法进一步提炼检索到的信息,从而提升生成文本的准确性和可靠性。CRAG是对现有RAG技术的有益补充和改进,它通过自我校正检索结果,增强了生成文本的鲁棒性。
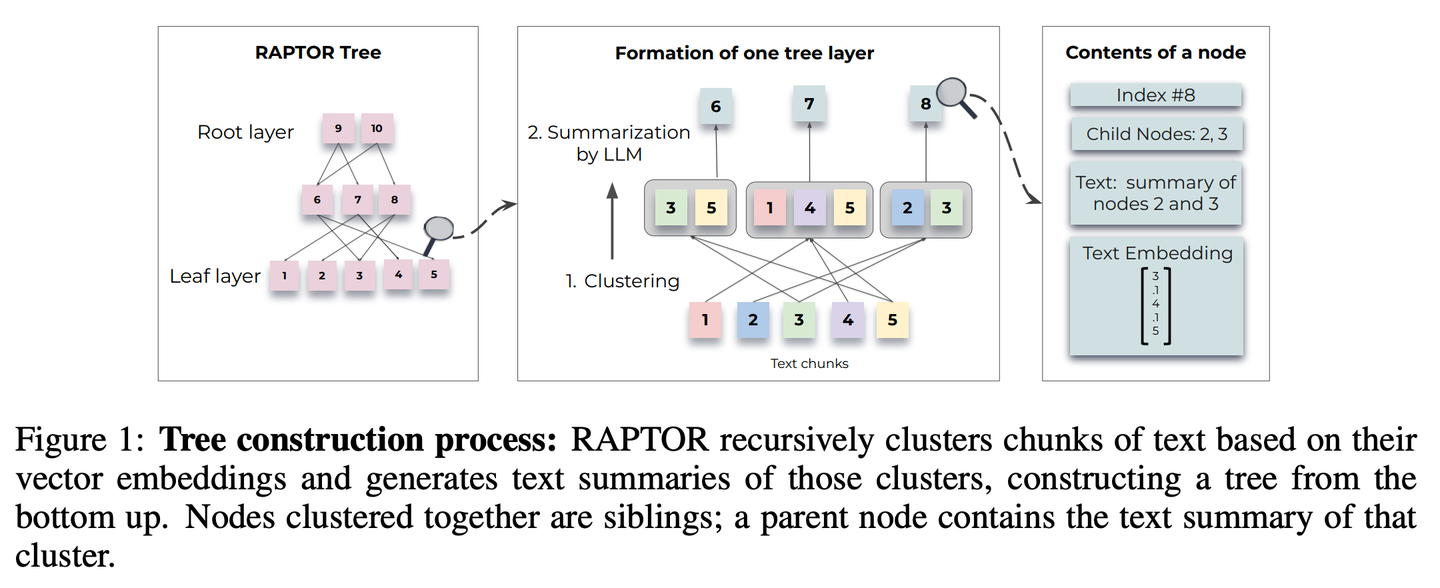
(04) RAPTOR【分层归纳】
分层归纳
:像个善于组织的图书管理员,将文档内容自下而上地整理成树状结构,让信息检索能在不同层级间灵活穿梭,既能看到整体概要,又能深入细节。
- 时间:01.31
- 论文:
RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval - 项目:
https://github.com/parthsarthi03/raptor - 参考:
https://mp.weixin.qq.com/s/8kt5qbHeTP1_ELY_YKwonA
RAPTOR(Recursive Abstractive Processing for Tree-Organized Retrieval)引入了一种新方法,即递归嵌入、聚类和总结文本块,从下往上构建具有不同总结级别的树。在推理时,RAPTOR 模型从这棵树中检索,整合不同抽象级别的长文档中的信息。
2024.02
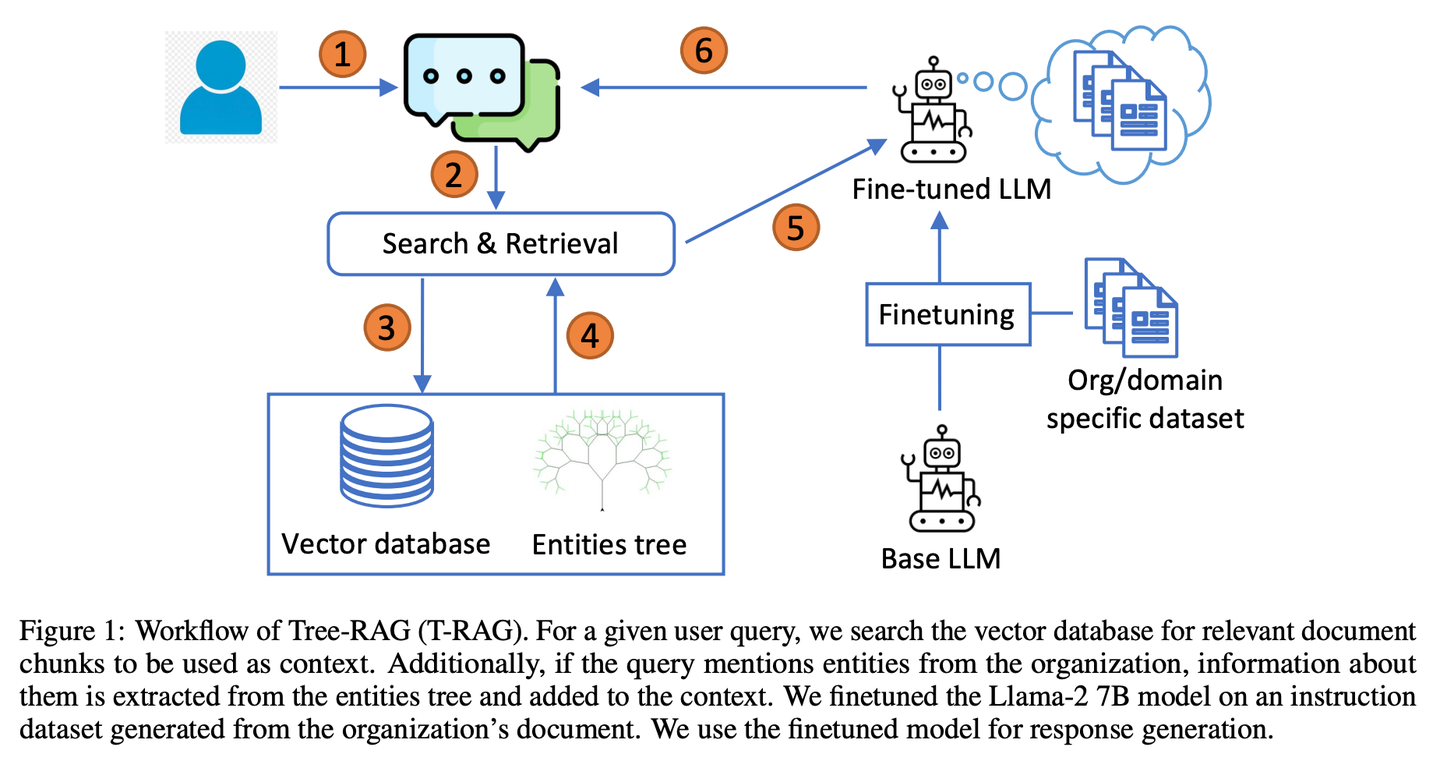
(05) T-RAG【私人顾问】
私人顾问
:像个熟悉组织架构的内部顾问,善于利用树状结构组织信息,在保护隐私的同时,高效且经济地提供本地化服务。
- 时间:02.12
- 论文:
T-RAG: Lessons from the LLM Trenches - 参考:
https://mp.weixin.qq.com/s/ytEkDAuxK1tLecbFxa6vfA
T-RAG(树状检索增强生成)结合RAG与微调的开源LLM,使用树结构来表示组织内的实体层次结构增强上下文,利用本地托管的开源模型来解决数据隐私问题,同时解决推理延迟、令牌使用成本以及区域和地理可用性问题。
2024.03
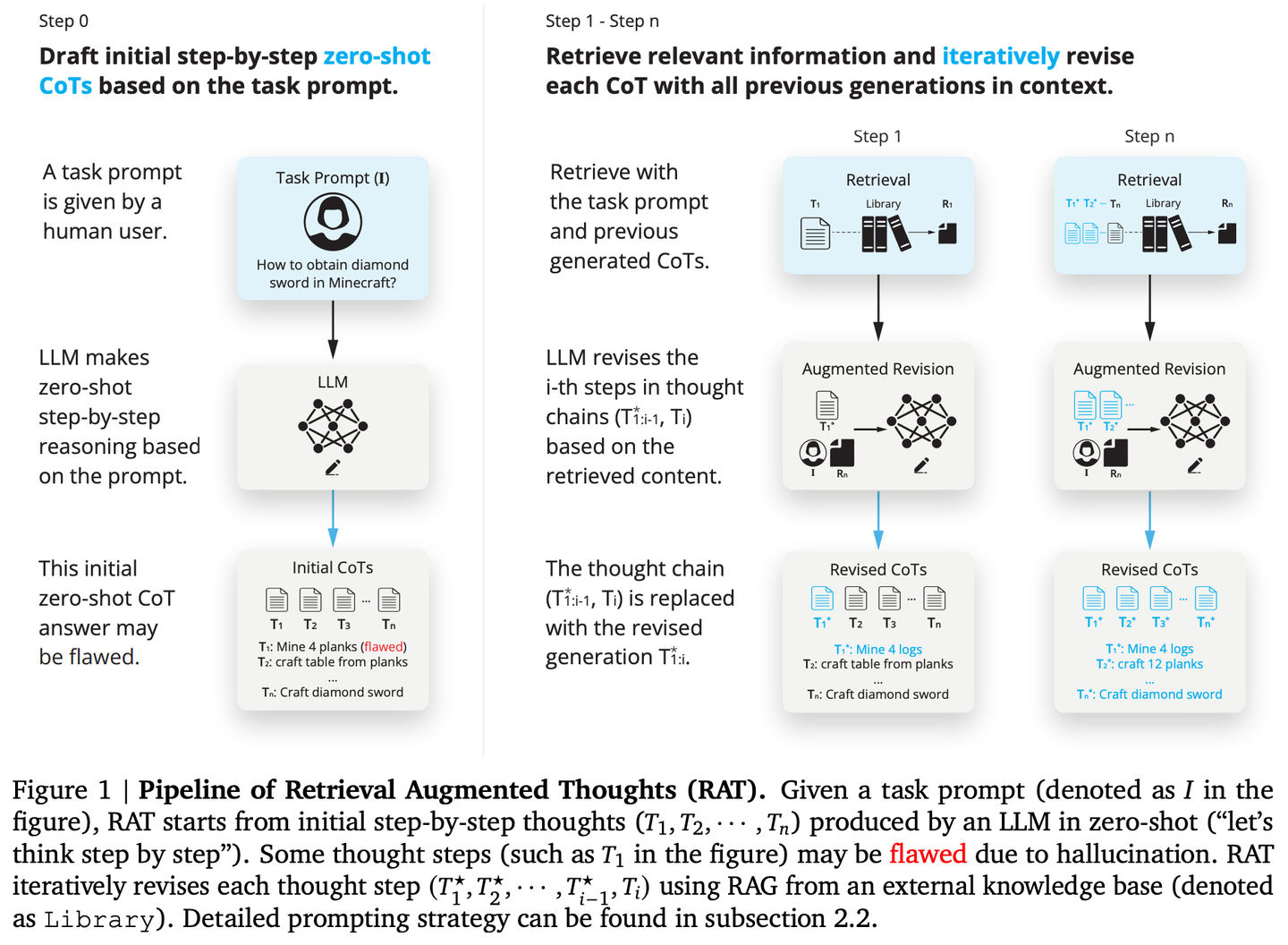
(06) RAT【思考者】
思考者
:像个善于反思的导师,不是一次性得出结论,而是先有初步想法,然后利用检索到的相关信息,不断审视和完善每一步推理过程,让思维链条更加严密可靠。
- 时间:03.08
- 论文:
RAT: Retrieval Augmented Thoughts Elicit Context-Aware Reasoning in Long-Horizon Generation - 项目:
https://github.com/CraftJarvis/RAT - 参考:
https://mp.weixin.qq.com/s/TqmY4ouDuloE2v-iSJB_-Q
RAT(检索增强思维)在生成初始零样本思维链(CoT)后,利用与任务查询、当前和过去思维步骤相关的检索信息逐个修订每个思维步骤,RAT可显著提高各种长时生成任务上的性能。
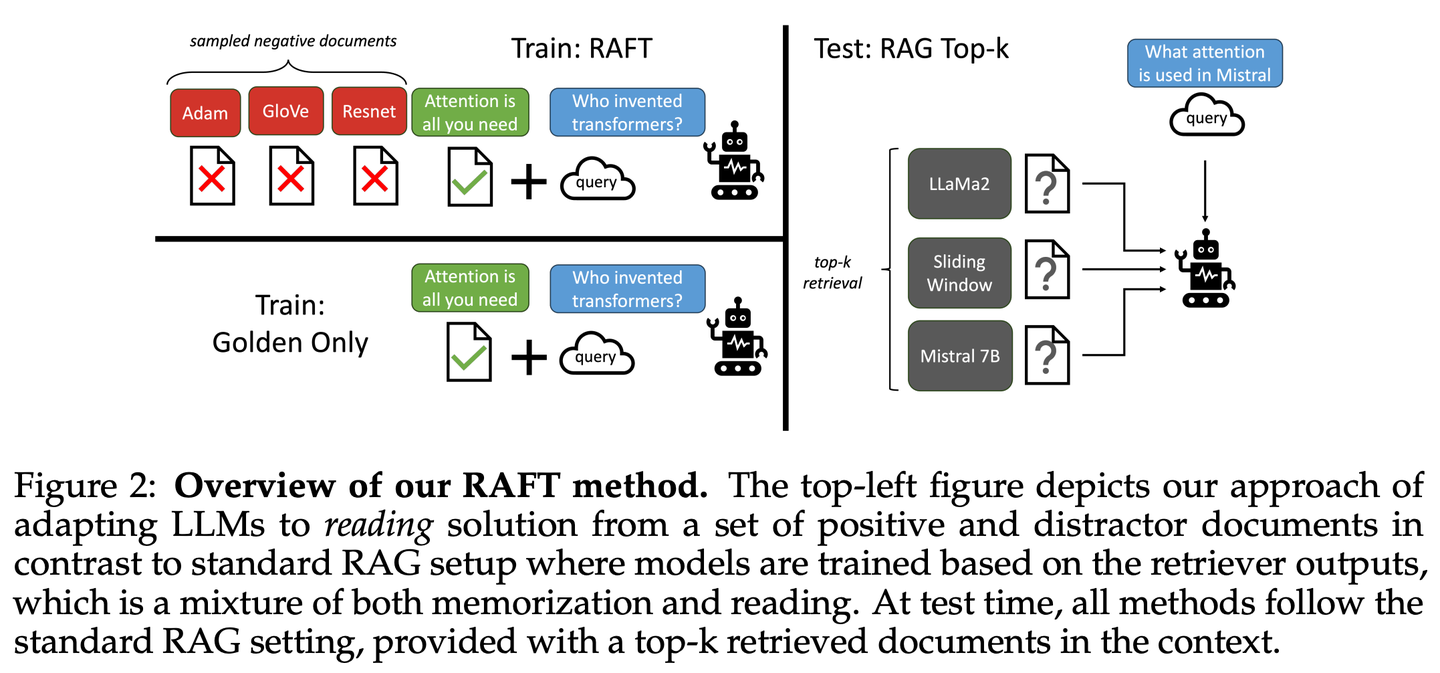
(07) RAFT【开卷高手】
开卷高手
:像个优秀的考生,不仅会找对参考资料,还能准确引用关键内容,并清晰地解释推理过程,让答案既有据可循又合情合理。
- 时间:03.15
- 论文:
RAFT: Adapting Language Model to Domain Specific RAG - 参考:
https://mp.weixin.qq.com/s/PPaviBpF8hdviqml3kPGIQ
RAFT旨在提高模型在特定领域内的“开卷”环境中回答问题的能力,通过训练模型忽略无关文档,并逐字引用相关文档中的正确序列来回答问题,结合思维链式响应,显著提升了模型的推理能力。
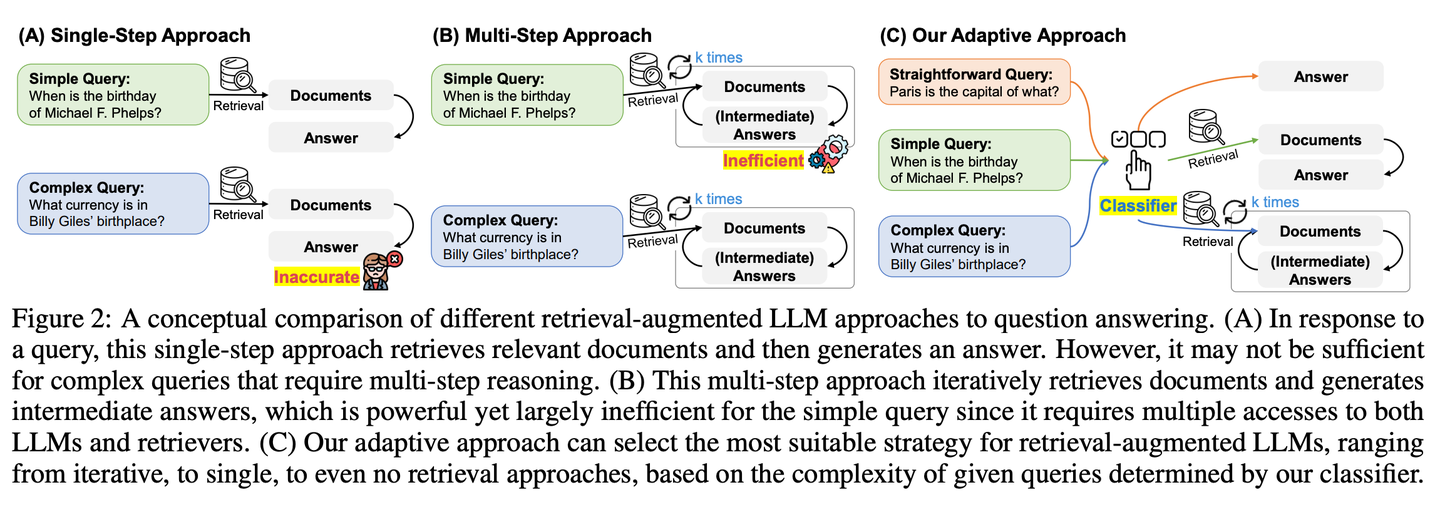
(08) Adaptive-RAG【因材施教】
因材施教
:面对不同难度的问题,它会智能地选择最合适的解答方式。简单问题直接回答,复杂问题则会查阅更多资料或分步骤推理,就像一个经验丰富的老师,懂得根据学生的具体问题调整教学方法。
- 时间:03.21
- 论文:
Adaptive-RAG: Learning to Adapt Retrieval-Augmented Large Language Models through Question Complexity - 项目:
https://github.com/starsuzi/Adaptive-RAG - 参考:
https://mp.weixin.qq.com/s/sxAu8xahY-GthS--nfgmjg
Adaptive-RAG根据查询的复杂程度动态选择最适合的检索增强策略,从最简单到最复杂的策略中动态地为LLM选择最合适的策略。这个选择过程通过一个小语言模型分类器来实现,预测查询的复杂性并自动收集标签以优化选择过程。这种方法提供了一种平衡的策略,能够在迭代式和单步检索增强型 LLMs 以及无检索方法之间无缝适应,以应对一系列查询复杂度。
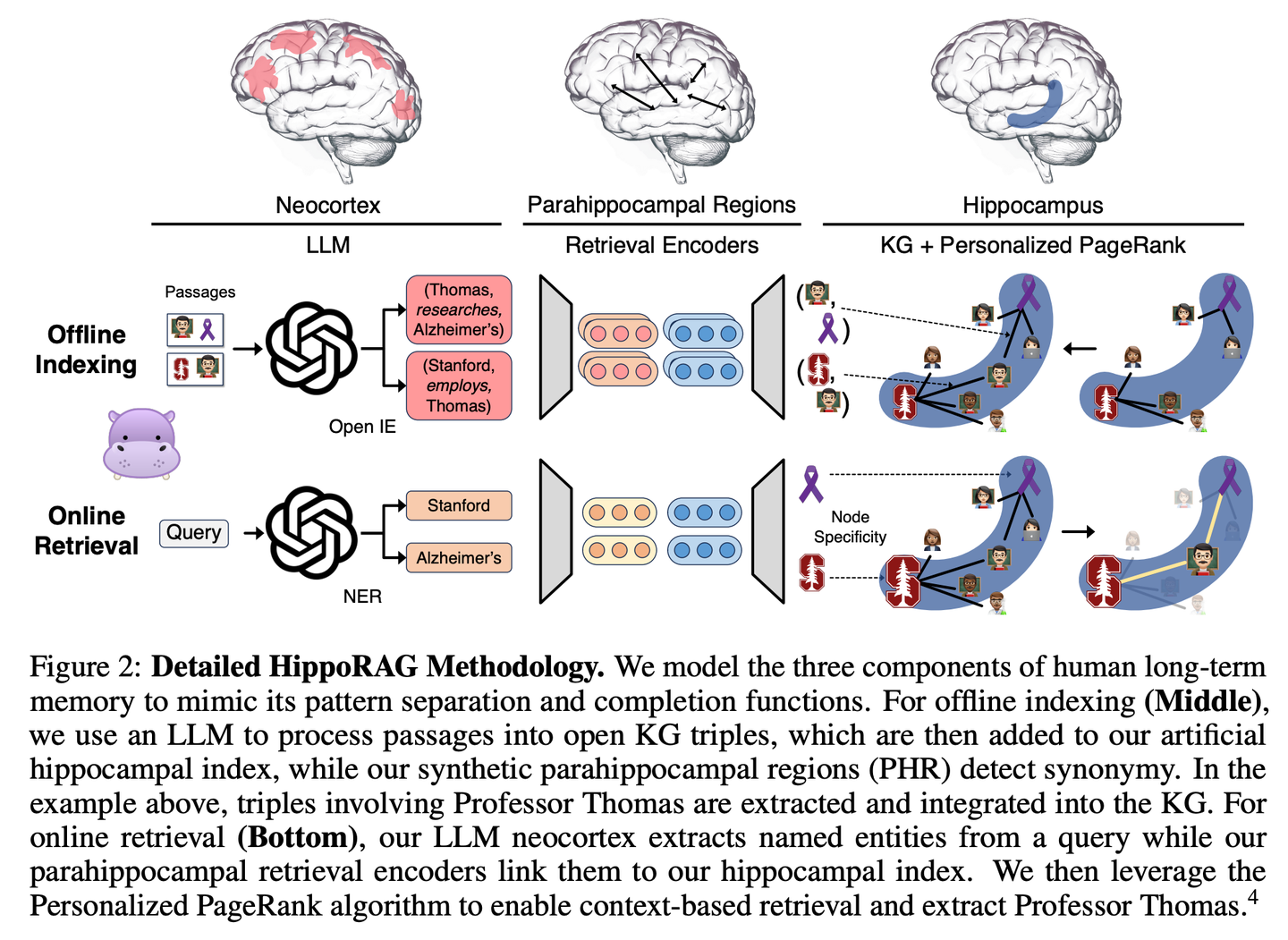
(09) HippoRAG【海马体】
海马体
:像人脑海马体一样,把新旧知识巧妙编织成网。不是简单地堆积信息,而是让每条新知识都找到最恰当的归属。
- 时间:03.23
- 论文:
HippoRAG: Neurobiologically Inspired Long-Term Memory for Large Language Models - 项目:
https://github.com/OSU-NLP-Group/HippoRAG - 参考:
https://mp.weixin.qq.com/s/zhDw4SxX1UpnczEC3XyHGA
HippoRAG是一种新颖的检索框架,其灵感来源于人类长期记忆的海马体索引理论,旨在实现对新经验更深入、更高效的知识整合。HippoRAG协同编排 LLMs、知识图谱和个性化PageRank算法,以模拟新皮层和海马体在人类记忆中的不同角色。
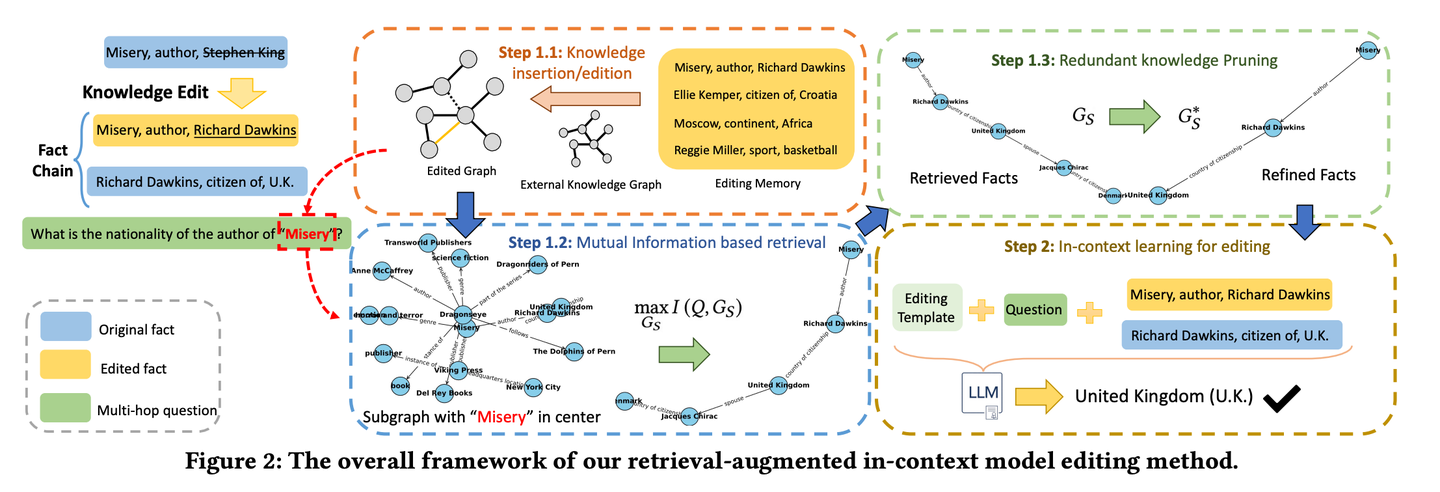
(10) RAE【智能编辑】
智能编辑
:像个细心的新闻编辑,不仅会深入挖掘相关事实,还能通过连环推理找出容易被忽略的关键信息,同时懂得删减冗余内容,确保最终呈现的信息既准确又精炼,避免"说得天花乱坠却不靠谱"的问题。
- 时间:03.28
- 论文:
Retrieval-enhanced Knowledge Editing in Language Models for Multi-Hop Question Answering - 项目:
https://github.com/sycny/RAE - 参考:
https://mp.weixin.qq.com/s/R0N8yexAlXetFyCS-W2dvg
RAE(多跳问答检索增强模型编辑框架)首先检索经过编辑的事实,然后通过上下文学习来优化语言模型。基于互信息最大化的检索方法利用大型语言模型的推理能力来识别传统基于相似性的搜索可能会错过的链式事实。此外框架包括一种修剪策略,以从检索到的事实中消除冗余信息,这提高了编辑准确性并减轻了幻觉问题。
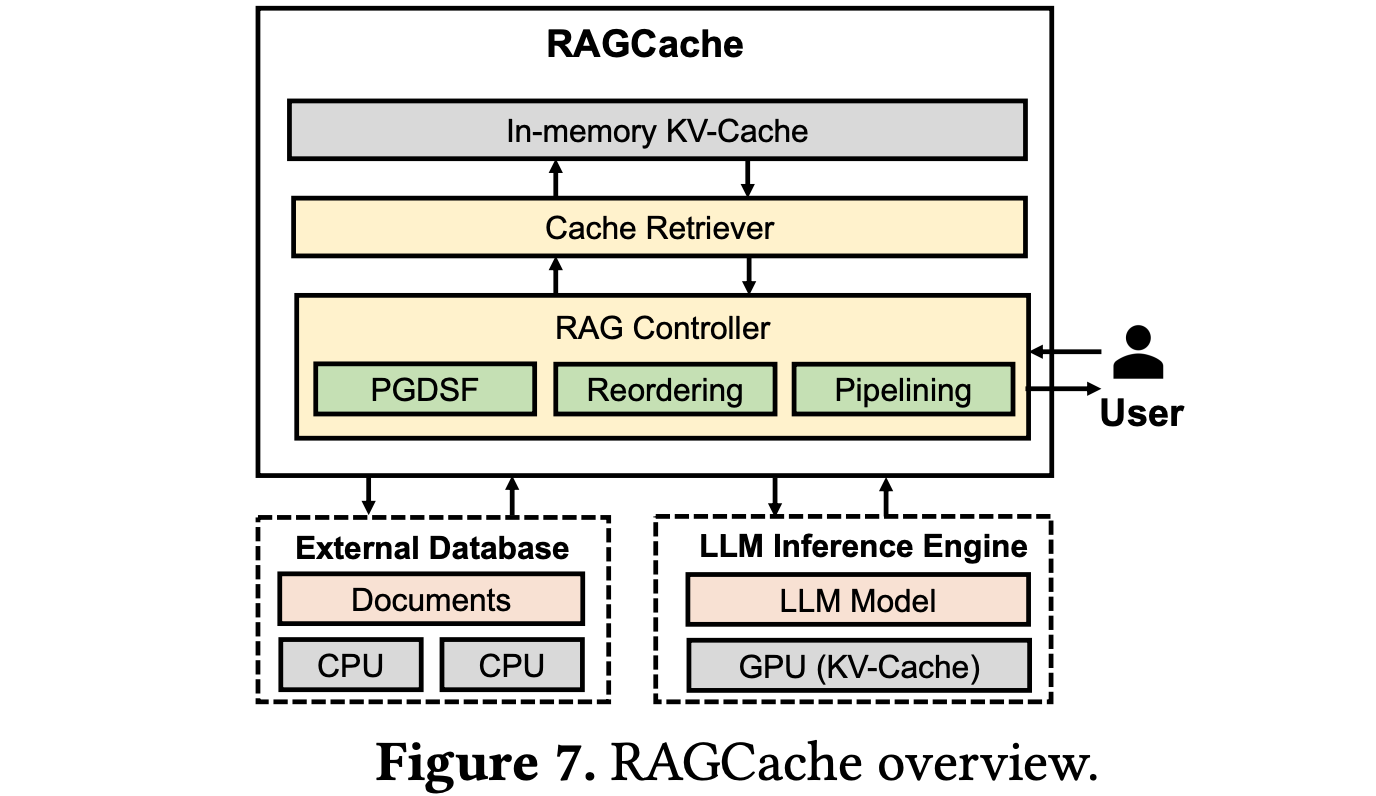
2024.04
(11) RAGCache【仓储员】
仓储员
:像大型物流中心一样,把常用知识放在最容易取的货架上。懂得把经常用的包裹放在门口,把不常用的放在后仓,让取货效率最大化。
- 时间:04.18
- 论文:
RAGCache: Efficient Knowledge Caching for Retrieval-Augmented Generation - 参考:
https://mp.weixin.qq.com/s/EOf51zoycmUCKkIo8rPsZw
RAGCache是一种为RAG量身定制的新型多级动态缓存系统,它将检索到的知识的中间状态组织在知识树中,并在GPU和主机内存层次结构中进行缓存。RAGCache提出了一种考虑到LLM推理特征和RAG检索模式的替换策略。它还动态地重叠检索和推理步骤,以最小化端到端延迟。
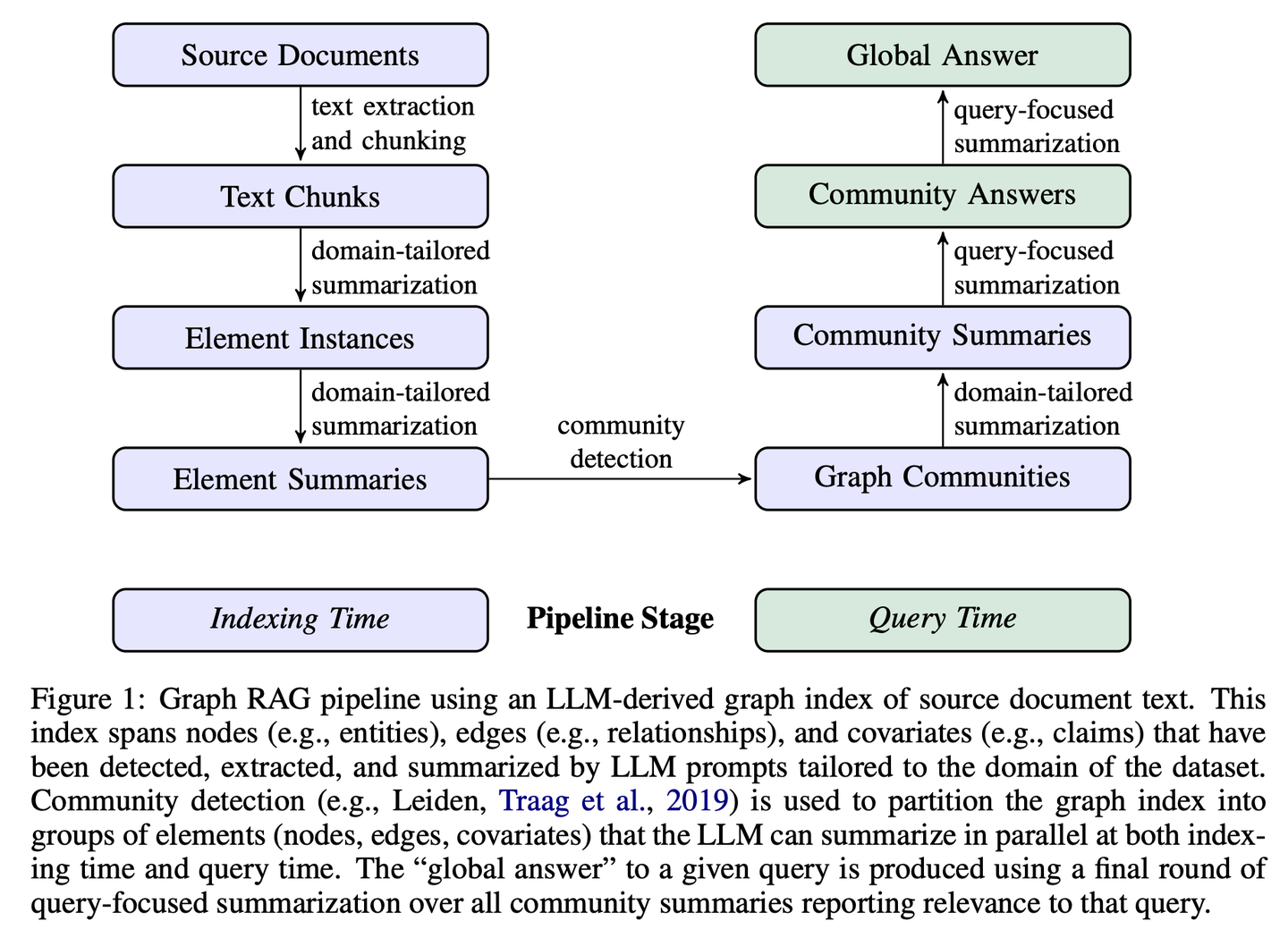
(12) GraphRAG【社区摘要】
社区摘要
:先把小区居民的关系网理清楚,再给每个邻里圈做个简介。有人问路时,各个邻里圈提供线索,最后整合成最完整的答案。
- 时间:04.24
- 论文:
From Local to Global: A Graph RAG Approach to Query-Focused Summarization - 项目:
https://github.com/microsoft/graphrag - 参考:
https://mp.weixin.qq.com/s/I_-rpMNVoQz-KvUlgQH-2w
GraphRAG分两个阶段构建基于图的文本索引:首先从源文档中推导出实体知识图,然后为所有紧密相关实体的组预生成社区摘要。给定一个问题,每个社区摘要用于生成部分响应,然后在向用户的最终响应中再次总结所有部分响应。
2024.05
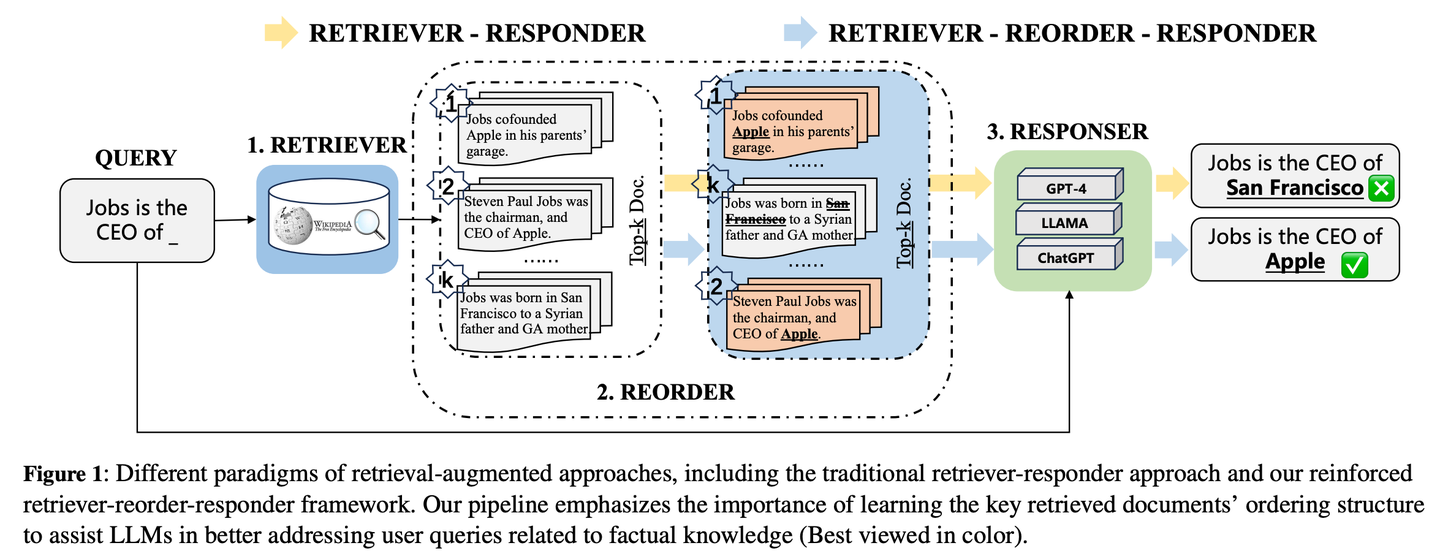
(13) R4【编排大师】
编排大师
:像个排版高手,通过优化材料的顺序和呈现方式来提升输出质量,无需改动核心模型就能让内容更有条理,重点更突出。
- 时间:05.04
- 论文:
R4: Reinforced Retriever-Reorder-Responder for Retrieval-Augmented Large Language Models - 参考:
https://mp.weixin.qq.com/s/Lsom93jtIr4Pv7DjpQuiDQ
R4 (Reinforced Retriever-Reorder-Responder)用于为检索增强型大语言模型学习文档排序,从而在大语言模型的大量参数保持冻结的情况下进一步增强其生成能力。重排序学习过程根据生成响应的质量分为两个步骤:文档顺序调整和文档表示增强。具体来说,文档顺序调整旨在基于图注意力学习将检索到的文档排序组织到开头、中间和结尾位置,以最大化响应质量的强化奖励。文档表示增强通过文档级梯度对抗学习进一步细化质量较差的响应的检索文档表示。
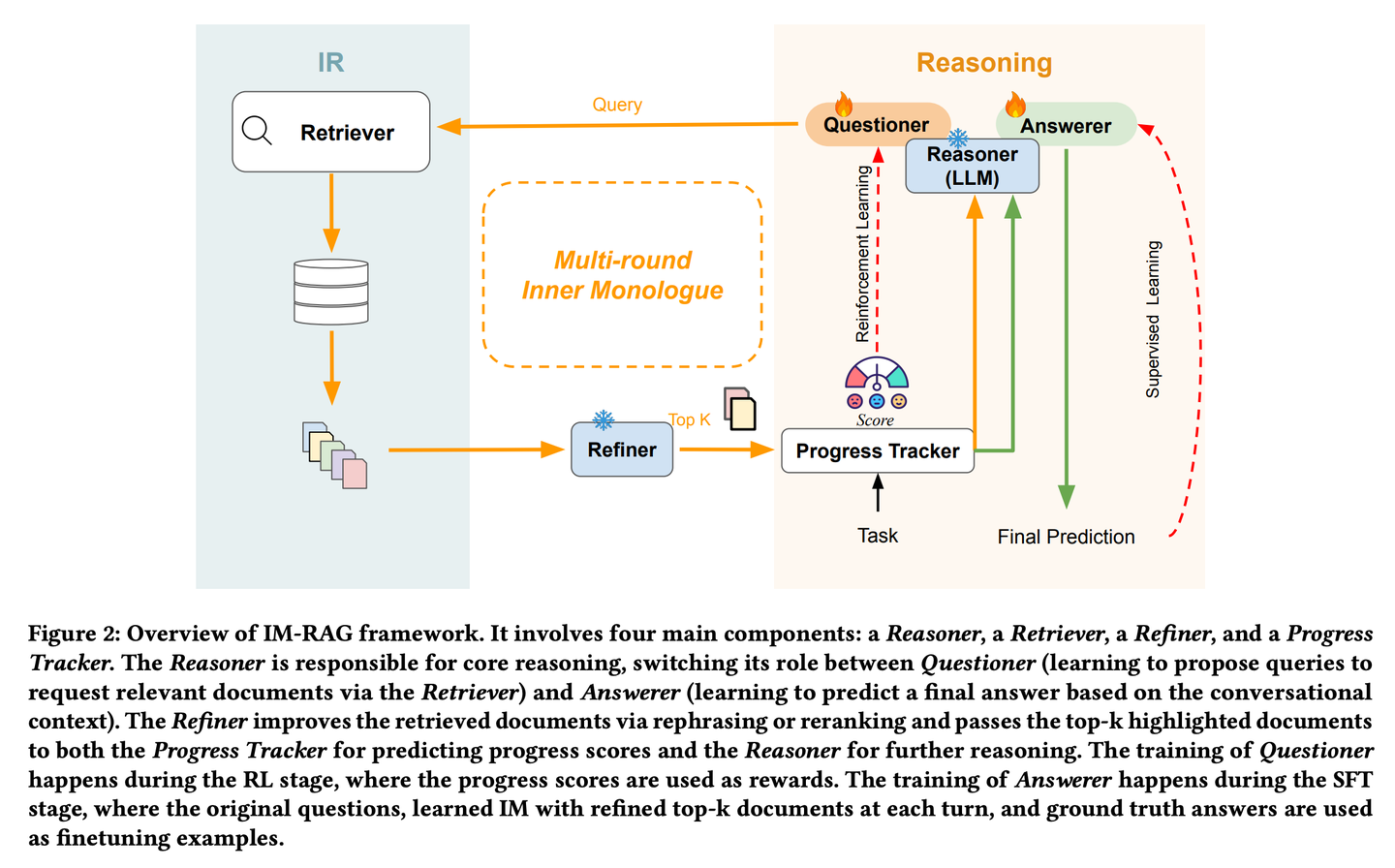
(14) IM-RAG【自言自语】
自言自语
:遇到问题时会在心里盘算"我需要查什么资料"、"这个信息够不够",通过不断的内心对话来完善答案,这种"独白"能力像人类专家一样,能够逐步深入思考并解决复杂问题。
- 时间:05.15
- 论文:
IM-RAG: Multi-Round Retrieval-Augmented Generation Through Learning Inner Monologues - 参考:
https://mp.weixin.qq.com/s/O6cNeBAT5f_nQM5hRaQUnw
IM-RAG通过学习内部独白(Inner Monologues)来连接IR系统与LLMs,从而支持多轮检索增强生成。该方法将信息检索系统与大型语言模型相整合,通过学习内心独白来支持多轮检索增强生成。在内心独白过程中,大型语言模型充当核心推理模型,它既可以通过检索器提出查询以收集更多信息,也可以基于对话上下文提供最终答案。我们还引入了一个优化器,它能对检索器的输出进行改进,有效地弥合推理器与能力各异的信息检索模块之间的差距,并促进多轮通信。整个内心独白过程通过强化学习(RL)进行优化,在此过程中还引入了一个进展跟踪器来提供中间步骤奖励,并且答案预测会通过监督微调(SFT)进一步单独优化。
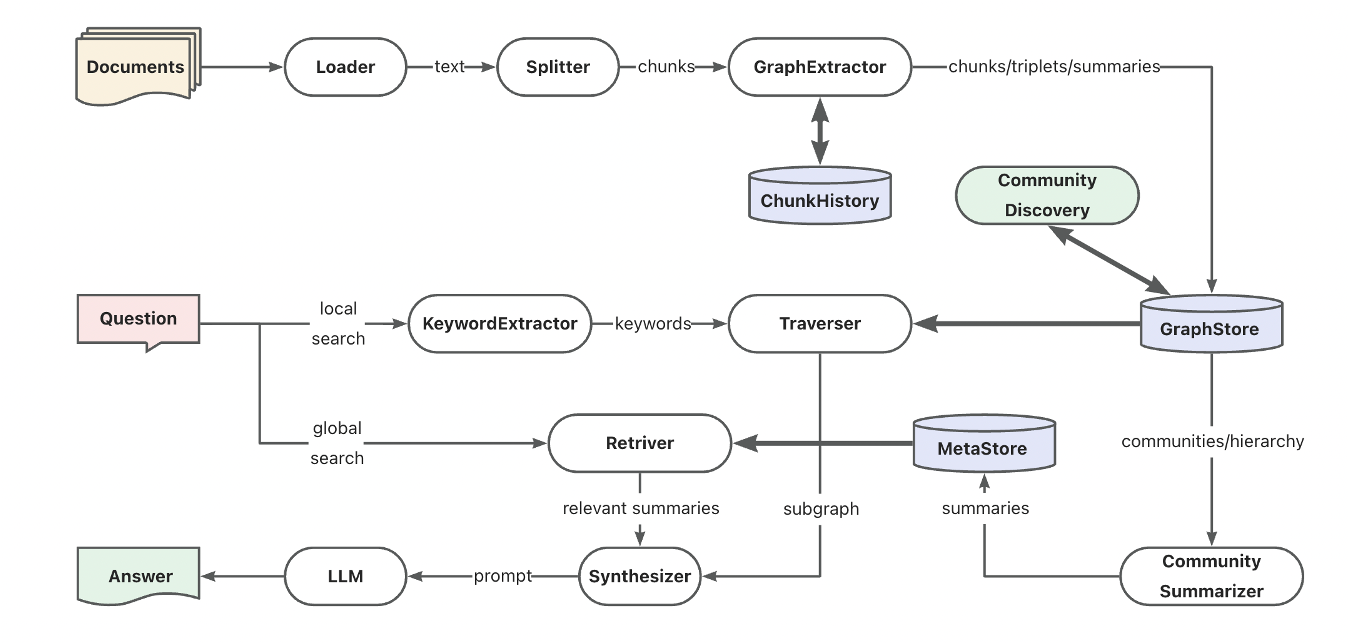
(15) AntGroup-GraphRAG【百家之长】
百家之长
:汇集行业百家之长,擅用多种方式快速定位信息,既能提供精准检索,又能理解自然语言查询,让复杂的知识检索变得既经济又高效。
- 时间:05.16
- 项目:
https://github.com/eosphoros-ai/DB-GPT - 参考:
https://mp.weixin.qq.com/s/LfhAY91JejRm_A6sY6akNA
蚂蚁TuGraph团队基于DB-GPT构建的开源GraphRAG框架,兼容了向量、图谱、全文等多种知识库索引底座,支持低成本的知识抽取、文档结构图谱、图社区摘要与混合检索以解决QFS问答问题。另外也提供了关键词、向量和自然语言等多样化的检索能力支持。
(16) Kotaemon【乐高】
乐高
:一套现成的问答积木套装,既能直接拿来用,又能自由拆装改造。用户要用就用,开发要改就改,随心所欲不失章法。
- 时间:05.15
- 项目:
https://github.com/Cinnamon/kotaemon - 参考:
https://mp.weixin.qq.com/s/SzoE2Hb82a6yUU7EcfF5Hg
一个开源的干净且可定制的RAG UI,用于构建和定制自己的文档问答系统。既考虑了最终用户的需求,也考虑了开发者的需求。

(17) FlashRAG【百宝箱】
百宝箱
:把各路RAG神器打包成一个工具包,让研究者像挑选积木一样,随心所欲地搭建自己的检索模型。
- 时间:05.22
- 论文:
FlashRAG: A Modular Toolkit for Efficient Retrieval-Augmented Generation Research - 项目:
https://github.com/RUC-NLPIR/FlashRAG - 参考:
https://mp.weixin.qq.com/s/vvOdcARaU1LD6KgcdShhoA
FlashRAG是一个高效且模块化的开源工具包,旨在帮助研究人员在统一框架内重现现有的RAG方法并开发他们自己的RAG算法。我们的工具包实现了12种先进的RAG方法,并收集和整理了32个基准数据集。
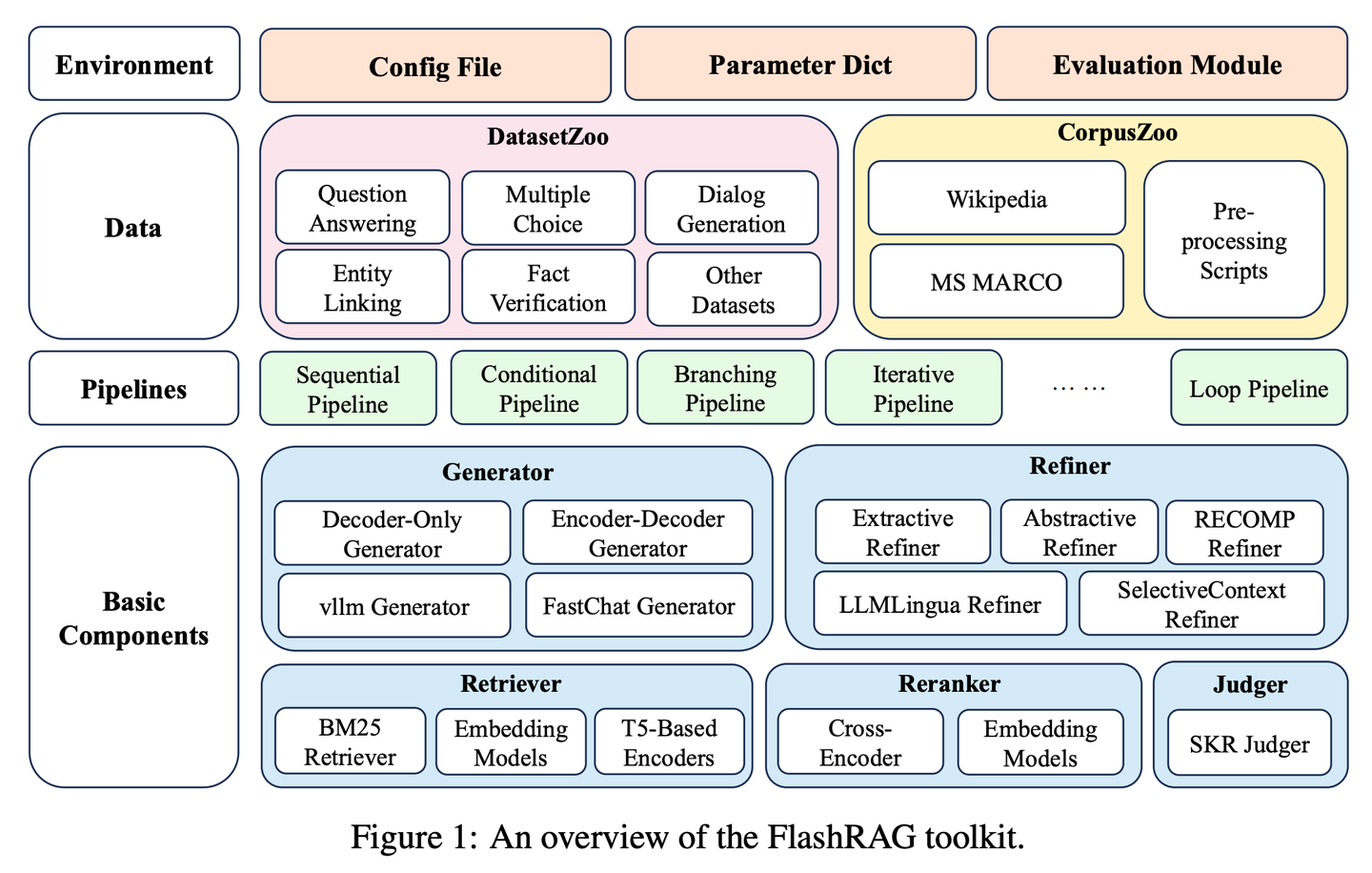
(18) GRAG【侦探】
侦探
:不满足于表面线索,深入挖掘文本之间的关联网络,像破案一样追踪每条信息背后的真相,让答案更准确。
- 时间:05.26
- 论文:
GRAG: Graph Retrieval-Augmented Generation - 项目:
https://github.com/HuieL/GRAG - 参考:
https://mp.weixin.qq.com/s/xLVaFVr7rnYJq0WZLsFVMw
传统RAG模型在处理复杂的图结构数据时忽视了文本之间的联系和数据库的拓扑信息,从而导致了性能瓶颈。GRAG通过强调子图结构的重要性,显著提升了检索和生成过程的性能并降低幻觉。
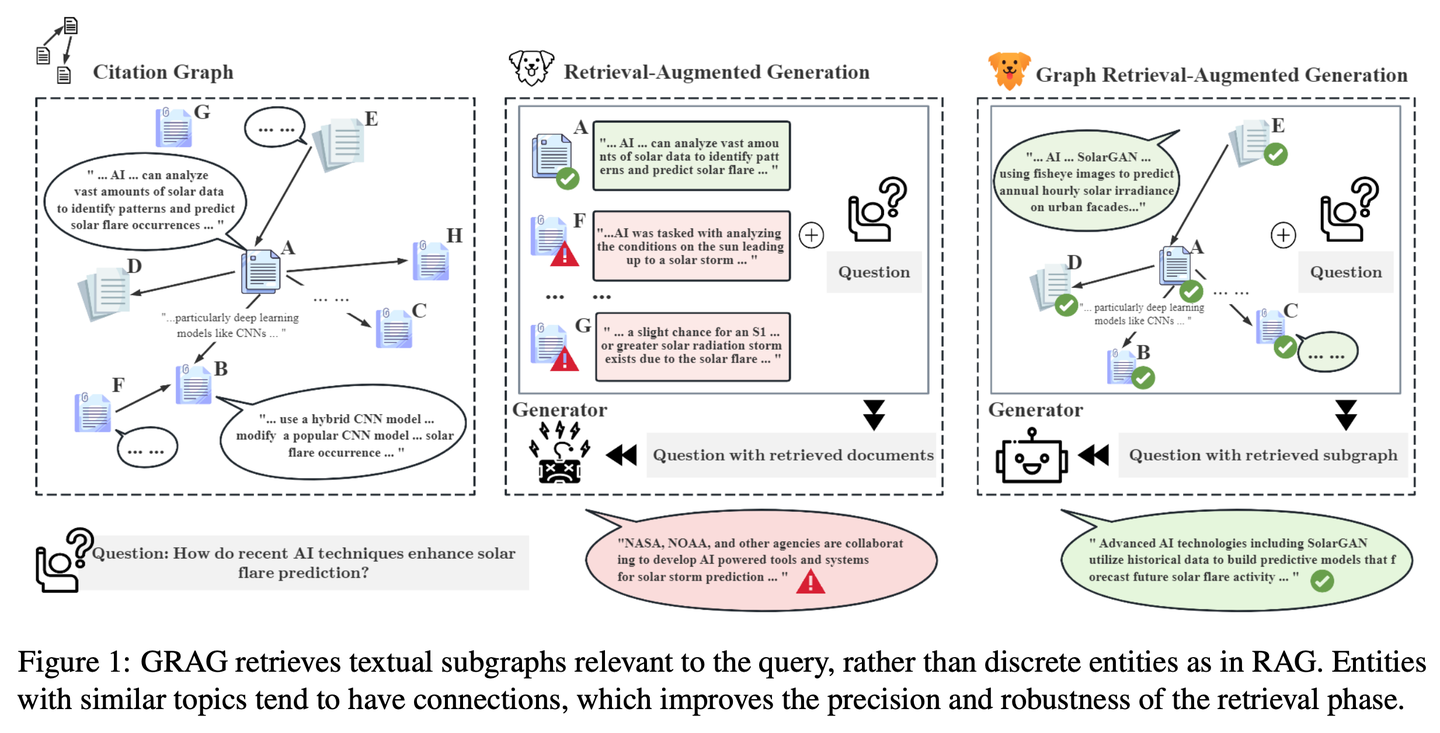
(19) Camel-GraphRAG【左右开弓】
左右开弓
:一只眼睛用Mistral扫描文本提取情报,另只眼睛用Neo4j编织关系网。查找时左右眼配合,既能找相似的,又能顺着线索图追踪,让搜索更全面精准。
- 时间:05.27
- 项目:
https://github.com/camel-ai/camel - 参考:
https://mp.weixin.qq.com/s/DhnAd-k-CtdGFVrwGat90w
Camel-GraphRAG依托Mistral模型提供支持,从给定的内容中提取知识并构建知识结构,然后将这些信息存储在 Neo4j图数据库中。随后采用一种混合方法,将向量检索与知识图谱检索相结合,来查询和探索所存储的知识。
(20) G-RAG【串门神器】
串门神器
:不再是单打独斗地查资料,而是给每个知识点都建立人际关系网。像个社交达人,不仅知道每个朋友的特长,还清楚谁和谁是酒肉朋友,找答案时直接顺藤摸瓜。
- 时间:05.28
- 论文:
Don't Forget to Connect! Improving RAG with Graph-based Reranking - 参考:
https://mp.weixin.qq.com/s/e6sRpYFDTQ7w7ituIjyovQ
RAG 在处理文档与问题上下文的关系时仍存在挑战,当文档与问题的关联性不明显或仅包含部分信息时,模型可能无法有效利用这些文档。此外,如何合理推断文档之间的关联也是一个重要问题。 G-RAG实现了RAG检索器和阅读器之间基于图神经网络(GNN)的重排器。该方法结合了文档之间的连接信息和语义信息(通过抽象语义表示图),为 RAG 提供了基于上下文的排序器。
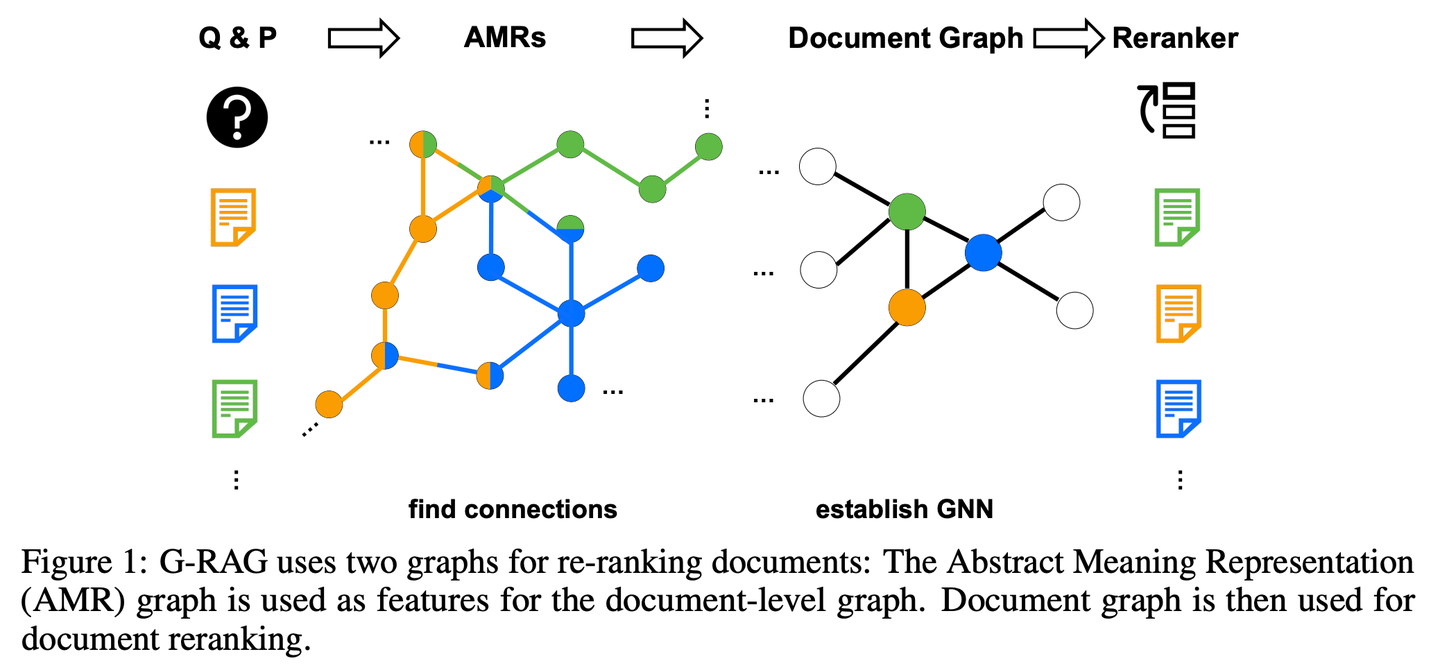
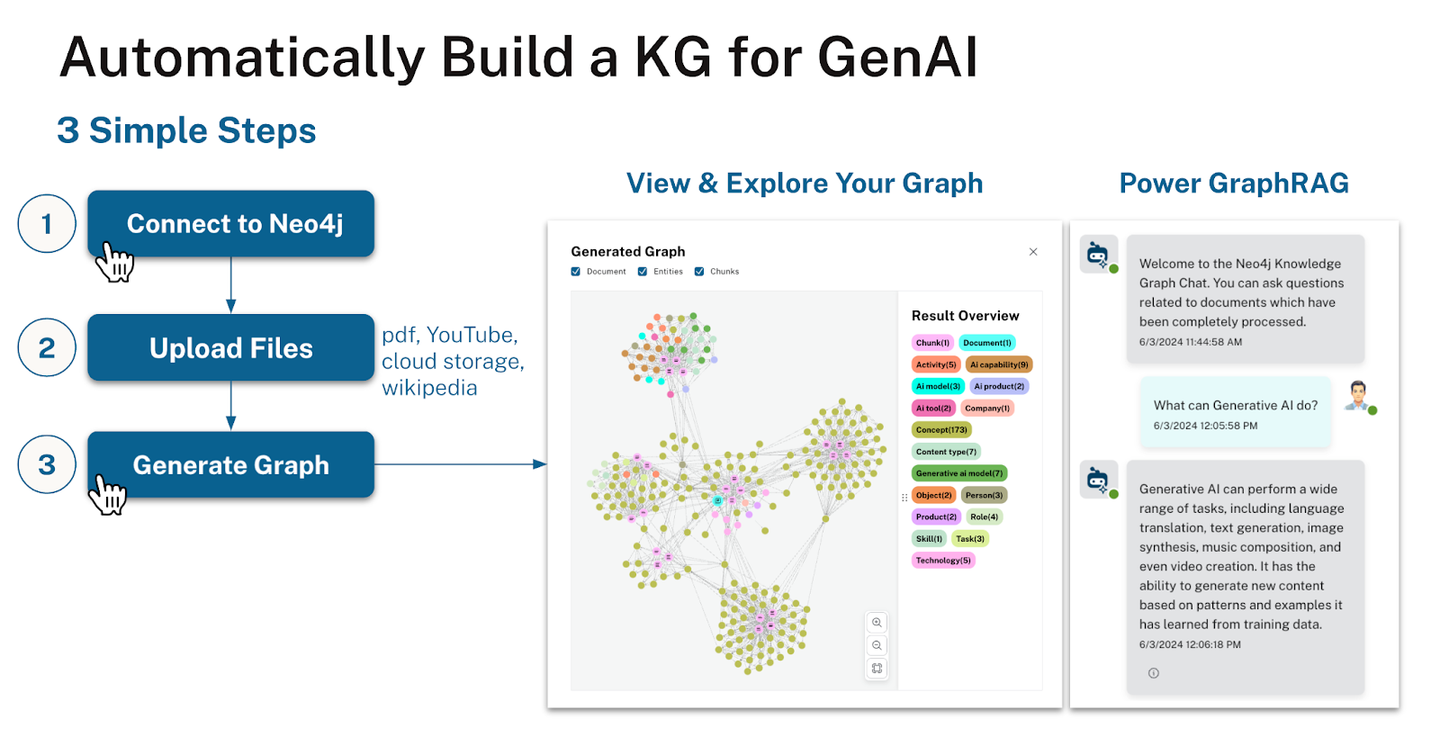
(21) LLM-Graph-Builder【搬运工】
搬运工
:给混乱的文字安个明白的家。不是简单地搬运,而是像个强迫症患者,把每个知识点都贴上标签,画上关系线,最后在Neo4j的数据库里盖起一座井井有序的知识大厦。
- 时间:05.29
- 项目:
https://github.com/neo4j-labs/llm-graph-builder - 参考:
https://mp.weixin.qq.com/s/9Jy11WH7UgrW37281XopiA
Neo4j开源的基于LLM提取知识图谱的生成器,可以把非结构化数据转换成Neo4j中的知识图谱。利用大模型从非结构化数据中提取节点、关系及其属性。
2024.06
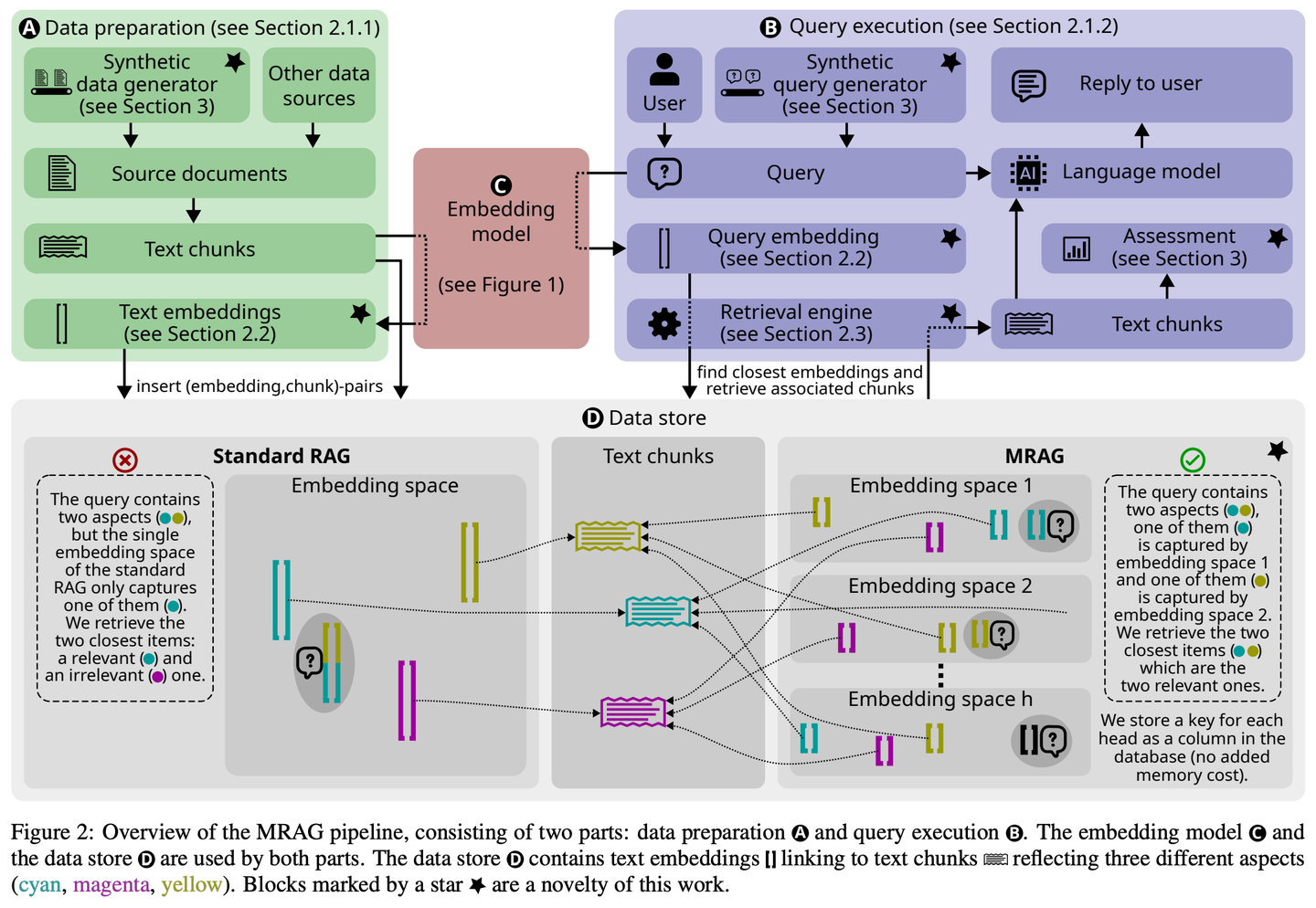
(22) MRAG【八爪鱼】
八爪鱼
:不是只长一个脑袋死磕问题,而是像章鱼一样长出多个触角,每个触角负责抓取一个角度。简单说,这就是AI版的"一心多用"。
- 时间:06.07
- 论文:
Multi-Head RAG: Solving Multi-Aspect Problems with LLMs - 项目:
https://github.com/spcl/MRAG - 参考:
https://mp.weixin.qq.com/s/WFYnF5UDlmwYsWz_BMtIYA
现有的 RAG 解决方案并未专注于可能需要获取内容差异显著的多个文档的查询。此类查询经常出现,但具有挑战性,因为这些文档的嵌入在嵌入空间中可能相距较远,使得难以全部检索到它们。本文介绍了多头 RAG(MRAG),这是一种新颖的方案,旨在通过一个简单而强大的想法来填补这一空白:利用 Transformer 多头注意力层的激活,而非解码器层,作为获取多方面文档的键。其驱动动机是不同的注意力头可以学习捕获不同的数据方面。利用相应的激活会产生代表数据项和查询各个层面的嵌入,从而提高复杂查询的检索准确性。
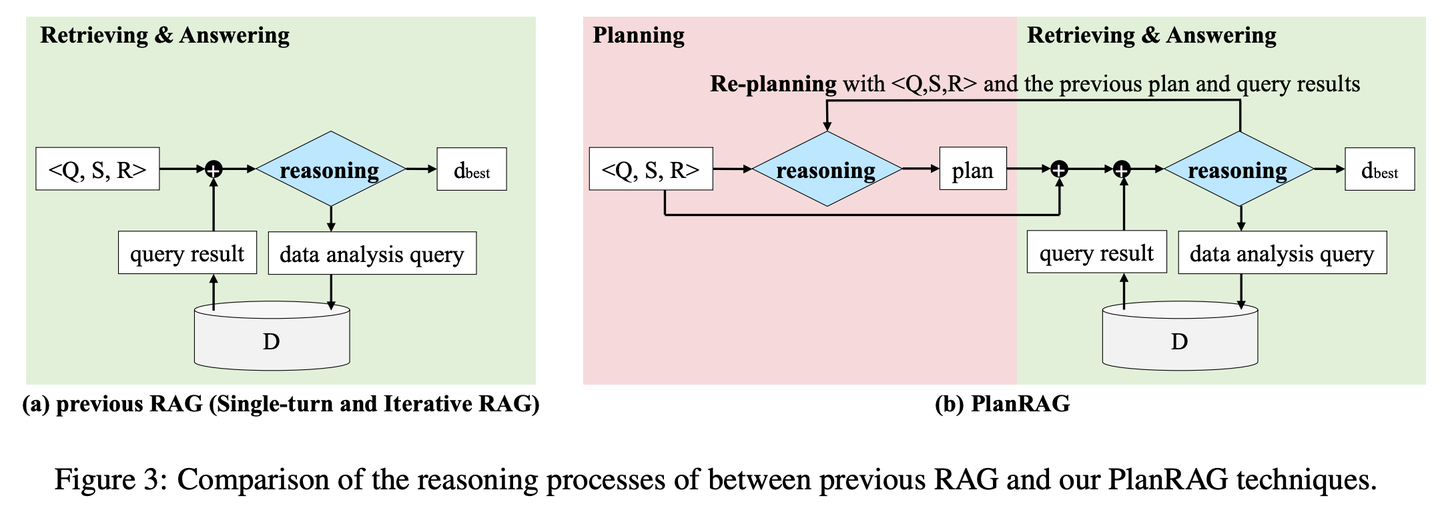
(23) PlanRAG【战略家】
战略家
:先制定完整作战计划,再根据规则和数据分析局势,最后做出最佳战术决策。
- 时间:06.18
- 论文:
PlanRAG: A Plan-then-Retrieval Augmented Generation for Generative Large Language Models as Decision Makers - 项目:
https://github.com/myeon9h/PlanRAG - 参考:
https://mp.weixin.qq.com/s/q3x2jOFFibyMXHA57sGx3w
PlanRAG研究如何利用大型语言模型解决复杂数据分析决策问题的方案,通过定义决策问答(Decision QA)任务,即根据决策问题Q、业务规则R和数据库D,确定最佳决策d。PlanRAG首先生成决策计划,然后检索器生成数据分析的查询。
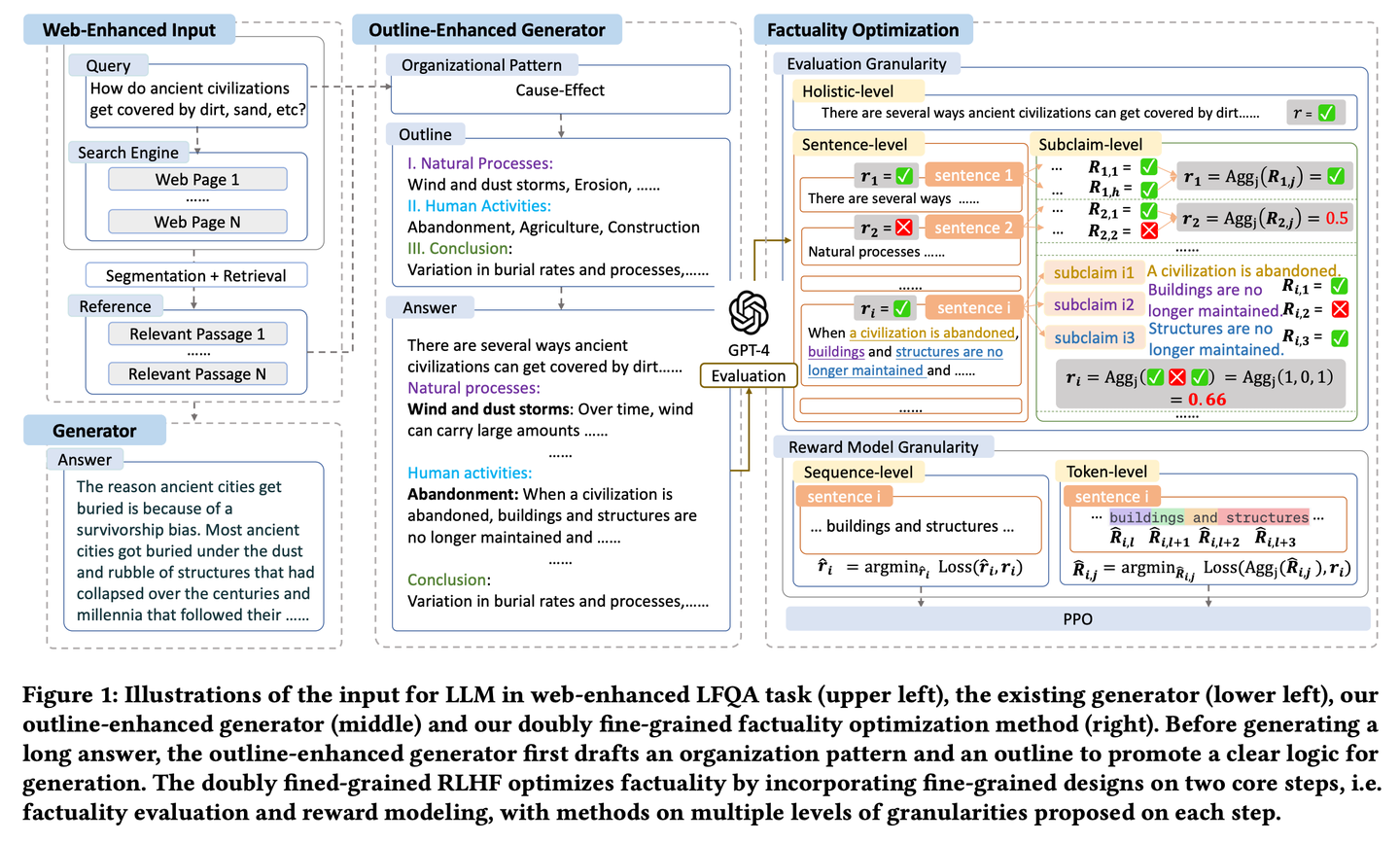
(24) FoRAG【作家】
作家
:先列写作大纲构思文章框架,再逐段扩充完善内容。同时还配备了一个"编辑",通过仔细的事实核查和修改建议,帮助完善每个细节,确保作品的质量。
- 时间:06.19
- 论文:
FoRAG: Factuality-optimized Retrieval Augmented Generation for Web-enhanced Long-form Question Answering - 参考:
https://mp.weixin.qq.com/s/7uqZ5U10Ec2Pa7akCLCJEA
FoRAG提出了一种新颖的大纲增强生成器,在第一阶段生成器使用大纲模板,根据用户查询和上下文草拟答案大纲,第二阶段基于生成的大纲扩展每个观点,构建最终答案。同时提出一种基于精心设计的双精细粒度RLHF框架的事实性优化方法,通过在事实性评估和奖励建模两个核心步骤中引入细粒度设计,提供了更密集的奖励信号。
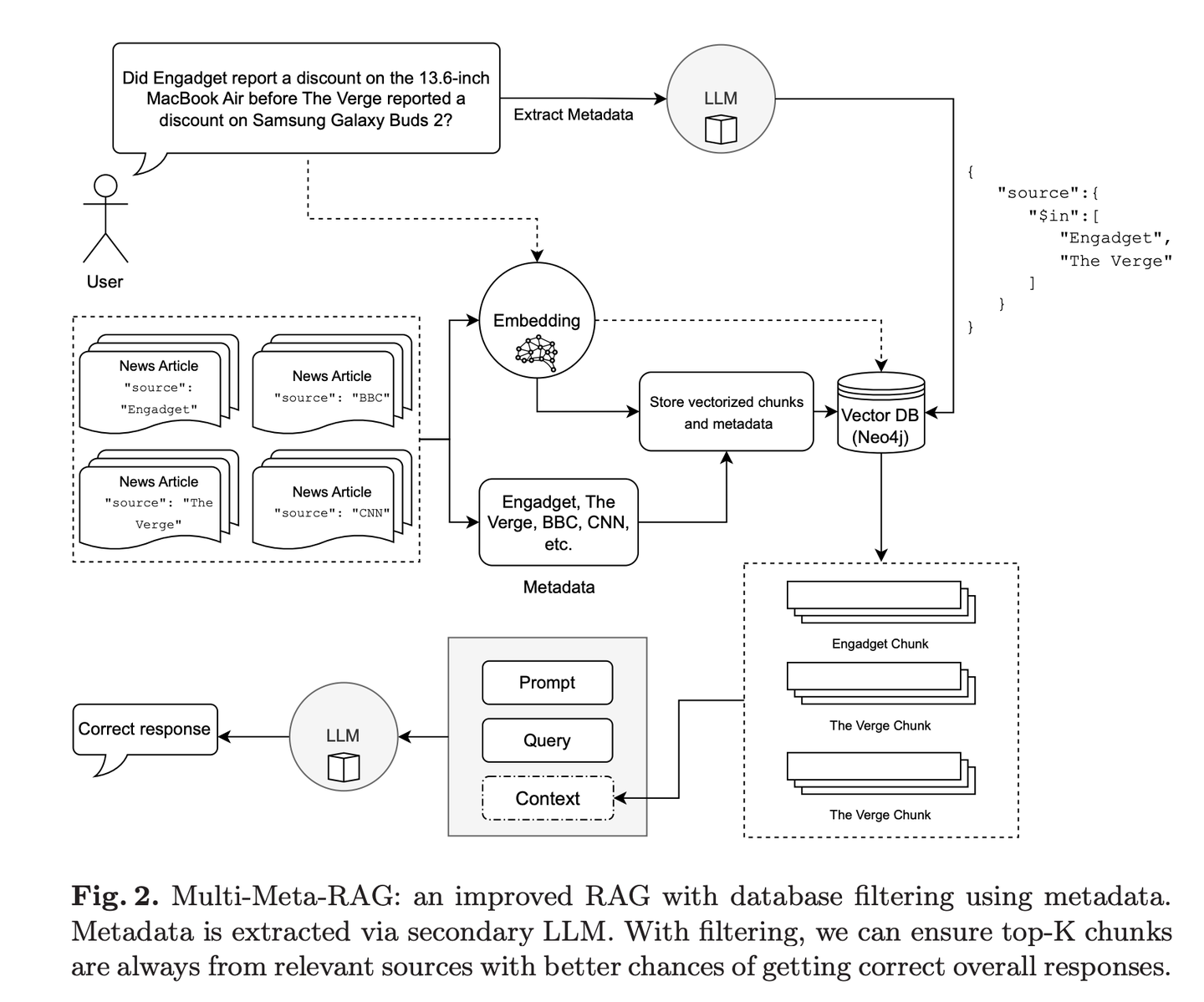
(25) Multi-Meta-RAG【元筛选器】
元筛选器
:像个经验丰富的资料管理员,通过多重筛选机制,从海量信息中精准定位最相关的内容。它不只看表面,还会深入分析文档的"身份标签"(元数据),确保找到的每份资料都真正对题。
- 时间:06.19
- 论文:
Multi-Meta-RAG: Improving RAG for Multi-Hop Queries using Database Filtering with LLM-Extracted Metadata - 项目:
https://github.com/mxpoliakov/multi-meta-rag - 参考:
https://mp.weixin.qq.com/s/Jf3qdFR-o_A4FXwmOOZ3pg
Multi-Meta-RAG使用数据库过滤和LLM提取的元数据来改进RAG从各种来源中选择与问题相关的相关文档。
2024.07
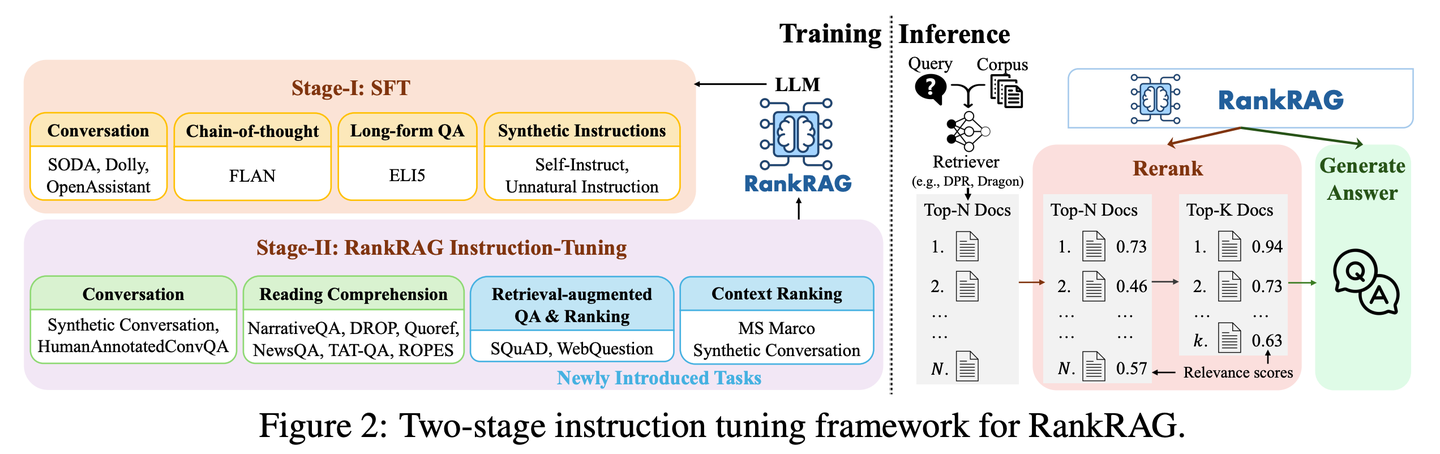
(26) RankRAG【全能选手】
全能选手
:通过一点特训就能当好"评委"和"选手"双重角色。像个天赋异禀的运动员,只需要少量指导就能在多个项目上超越专业选手,还能把看家本领都融会贯通。
- 时间:07.02
- 论文:
RankRAG: Unifying Context Ranking with Retrieval-Augmented Generation in LLMs - 参考:
https://mp.weixin.qq.com/s/BZDXCTKSKLOwDv1j8_75_Q
RankRAG的通过指令微调单一的LLM,使其同时具备上下文排名和答案生成的双重功能。通过在训练数据中加入少量排序数据,经过指令微调的大语言模型效果出奇地好,甚至超过了现有的专家排序模型,包括在大量排序数据上专门微调的相同大语言模型。这种设计不仅简化了传统RAG系统中多模型的复杂性,还通过共享模型参数增强了上下文的相关性判断和信息的利用效率。
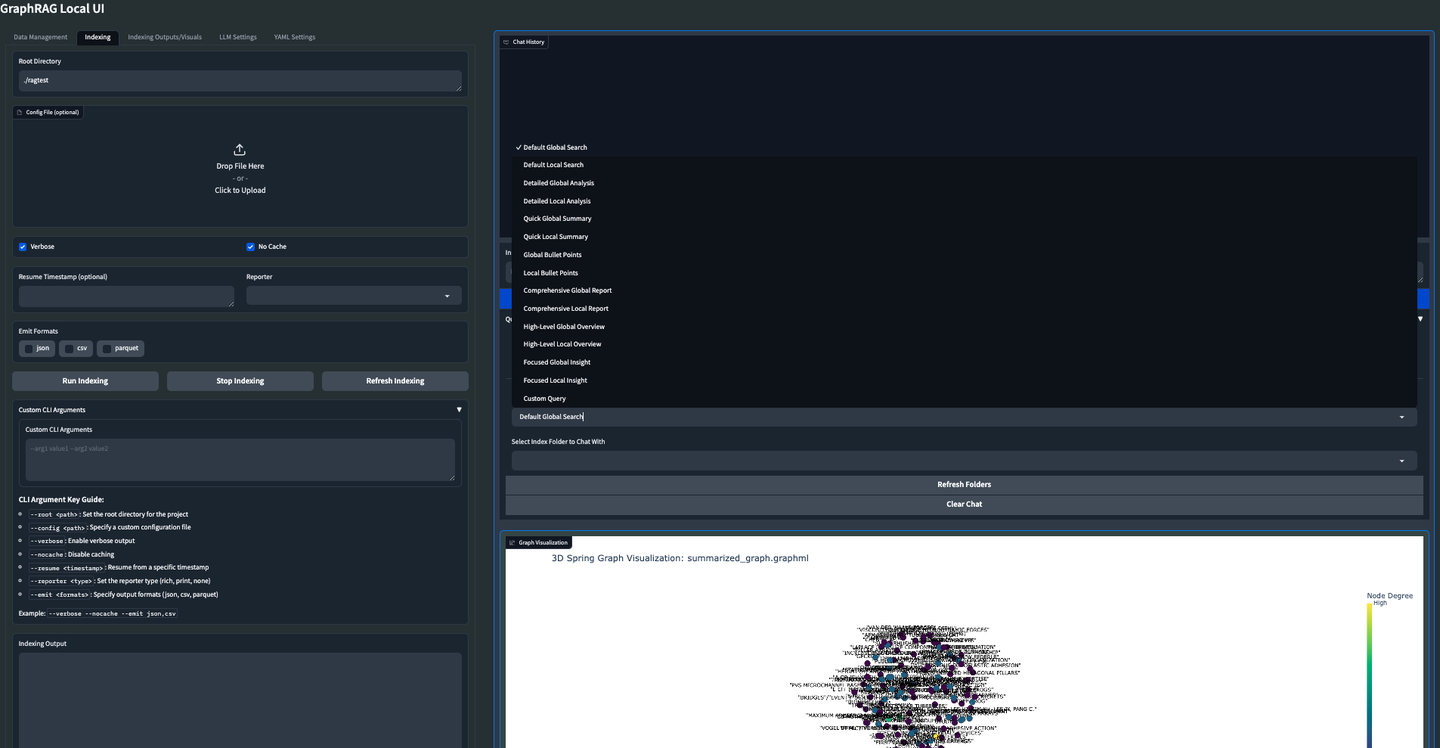
(27) GraphRAG-Local-UI【改装师】
改装师
:把跑车改装成适合本地道路的实用车,加装了友好的仪表盘,让人人都能轻松驾驶。
- 时间:07.14
- 项目:
https://github.com/severian42/GraphRAG-Local-UI - 参考:
https://mp.weixin.qq.com/s/DLvF7YpU3IfWvnu9ZyiBIA
GraphRAG-Local-UI是基于Microsoft的GraphRAG的本地模型适配版本,具有丰富的交互式用户界面生态系统。
(28) ThinkRAG【小秘书】
小秘书
:把庞大的知识体系浓缩成口袋版,像个随身携带的小秘书,不用大型设备就能随时帮你查找解答。
- 时间:07.15
- 项目:
https://github.com/wzdavid/ThinkRAG - 参考:
https://mp.weixin.qq.com/s/VmnVwDyi0i6qkBEzLZlERQ
ThinkRAG大模型检索增强生成系统,可以轻松部署在笔记本电脑上,实现本地知识库智能问答。
(29) Nano-GraphRAG【轻装上阵】
轻装上阵
:像个轻装上阵的运动员,把繁复的装备都简化了,但保留了核心能力。
- 时间:07.25
- 项目:
https://github.com/gusye1234/nano-graphrag - 参考:
https://mp.weixin.qq.com/s/pnyhz0jA4jgLndMUM9IU1g
Nano-GraphRAG是一个更小、更快、更简洁的 GraphRAG,同时保留了核心功能。
2024.08
(30) RAGFlow-GraphRAG【导航员】
导航员
:在问答的迷宫里开辟捷径,先画张地图把知识点都标好,重复的路标合并掉,还特地给地图瘦身,让问路的人不会绕远路。
- 时间:08.02
- 项目:
https://github.com/infiniflow/ragflow - 参考:
https://mp.weixin.qq.com/s/c5-0dCWI0bIa2zHagM1w0w
RAGFlow借鉴了GraphRAG的实现,在文档预处理阶段,引入知识图谱构建作为可选项,服务于QFS问答场景,并引入了实体去重、Token优化等改进。
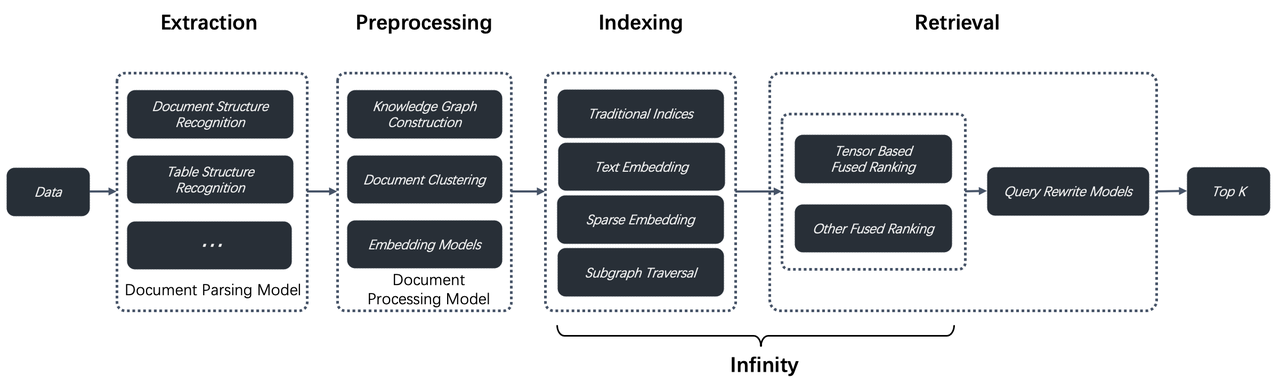
(31) Tiny-GraphRAG【入门版】
入门版
:像个初学者友好的教学版本,保留了所有基础功能,让你能完整体验从收纳文档到查询问答的全过程,是GraphRAG家族的"新手套装"。
- 时间:08.05
- 项目:
https://github.com/limafang/tiny-graphrag - 参考:
https://mp.weixin.qq.com/s/pnyhz0jA4jgLndMUM9IU1g
Tiny-GraphRAG是一个简洁版本的GraphRAG实现,旨在提供一个最简单的GraphRAG系统,包含所有必要的功能。我们实现了添加文档的全部流程,以及本地查询和全局查询的功能。
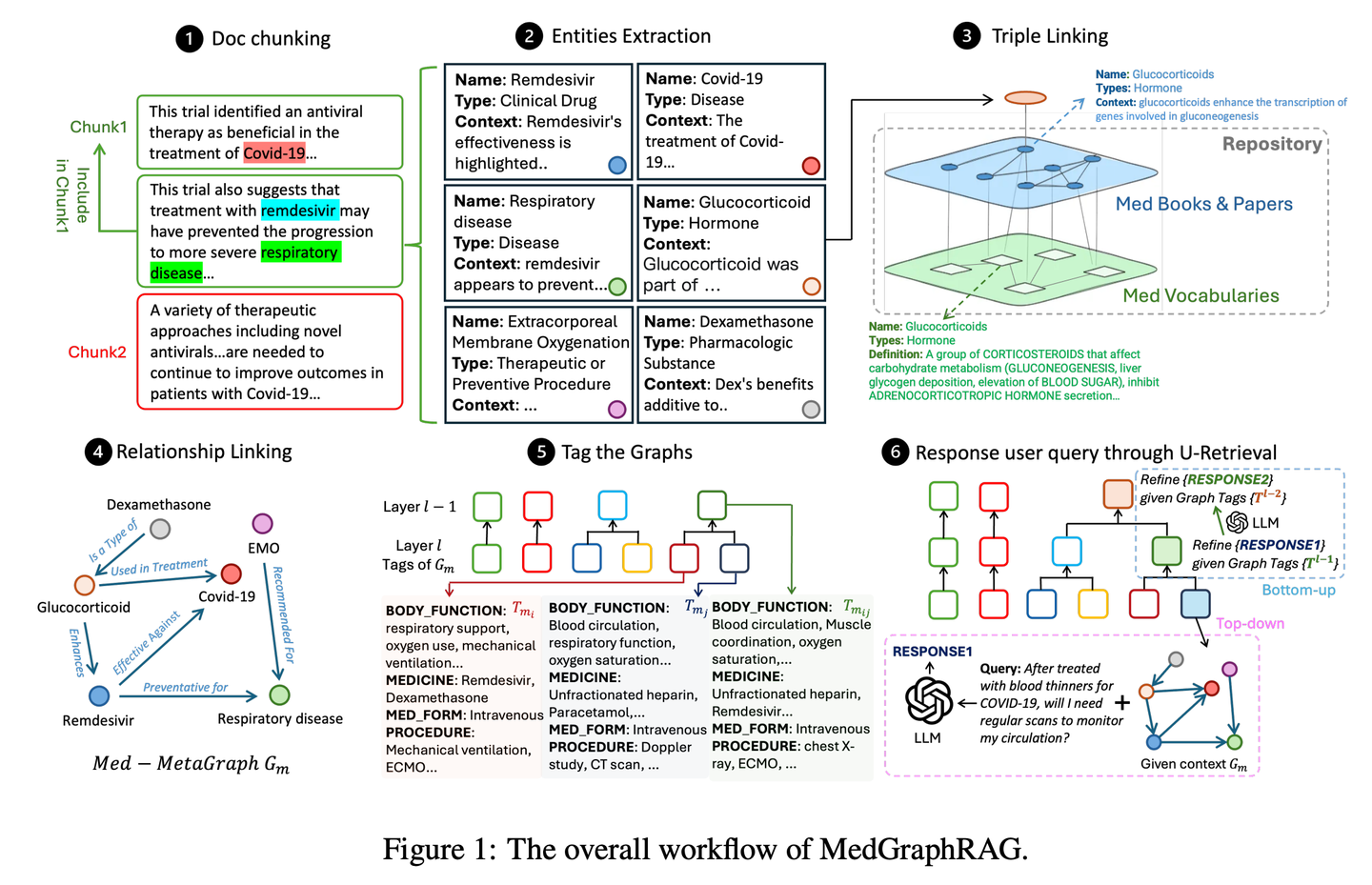
(32) Medical-Graph-RAG【数字医生】
数字医生
:像个经验丰富的医学顾问,用图谱把复杂的医疗知识整理得清清楚楚,诊断建议不是凭空想象,而是有理有据,让医生和患者都能看明白每个诊断背后的依据。
- 时间:08.08
- 论文:
Medical Graph RAG: Towards Safe Medical Large Language Model via Graph Retrieval-Augmented Generation - 项目:
https://github.com/SuperMedIntel/Medical-Graph-RAG - 参考:
https://mp.weixin.qq.com/s/5mX-hCyFdve98H01x153Eg
MedGraphRAG 是一个框架,旨在解决在医学中应用 LLM 的挑战。它使用基于图谱的方法来提高诊断准确性、透明度并集成到临床工作流程中。该系统通过生成由可靠来源支持的响应来提高诊断准确性,解决了在大量医疗数据中维护上下文的困难。
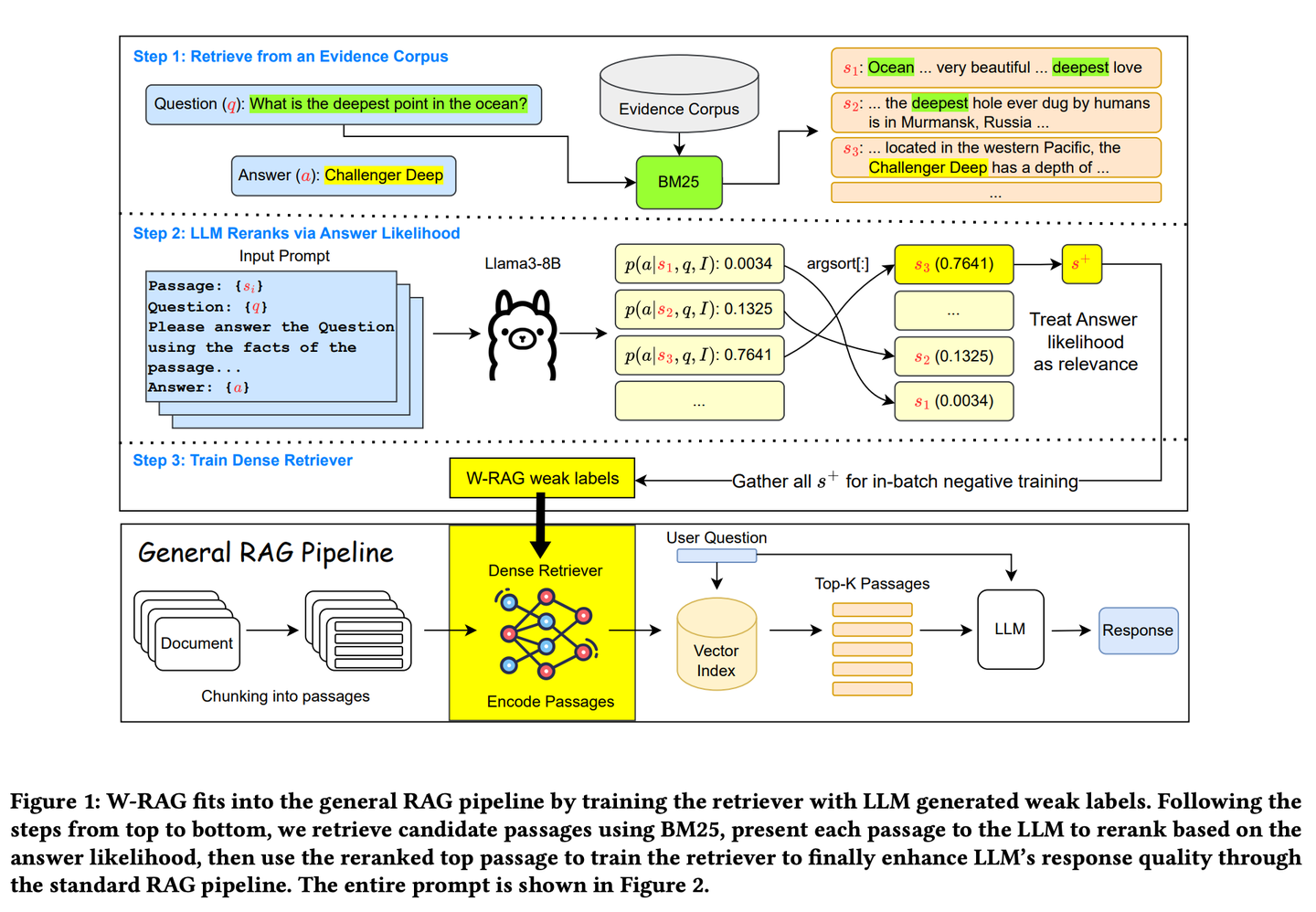
(33) W-RAG【进化搜索】
进化搜索
:像个善于自我进化的搜索引擎,通过大模型对文章段落的评分来学习什么是好答案,逐步提升自己找到关键信息的能力。
- 时间:08.15
- 论文:
W-RAG: Weakly Supervised Dense Retrieval in RAG for Open-domain Question Answering - 项目:
https://github.com/jmnian/weak_label_for_rag - 参考:
https://mp.weixin.qq.com/s/JqT1wteHC43h2cPlXmPOFg
开放域问答中的弱监督密集检索技术,利用大型语言模型的排序能力为训练密集检索器创建弱标注数据。通过评估大型语言模型基于问题和每个段落生成正确答案的概率,对通过 BM25 检索到的前 K 个段落进行重新排序。排名最高的段落随后被用作密集检索的正训练示例。
(34) RAGChecker【质检员】
质检员
:不只简单地判断答案对错,而是会深入检查整个回答过程中的每个环节,从资料查找到最终答案生成,就像一个严格的考官,既给出详细的评分报告,还会指出具体哪里需要改进。
- 时间:08.15
- 论文:
RAGChecker: A Fine-grained Framework for Diagnosing Retrieval-Augmented Generation - 项目:
https://github.com/amazon-science/RAGChecker - 参考:
https://mp.weixin.qq.com/s/x4o7BinnwvTsOa2_hegcrQ
RAGChecker 的诊断工具为 RAG 系统提供细粒度、全面、可靠的诊断报告,并为进一步提升性能,提供可操作的方向。它不仅能评估系统的整体表现,还能深入分析检索和生成两大核心模块的性能。
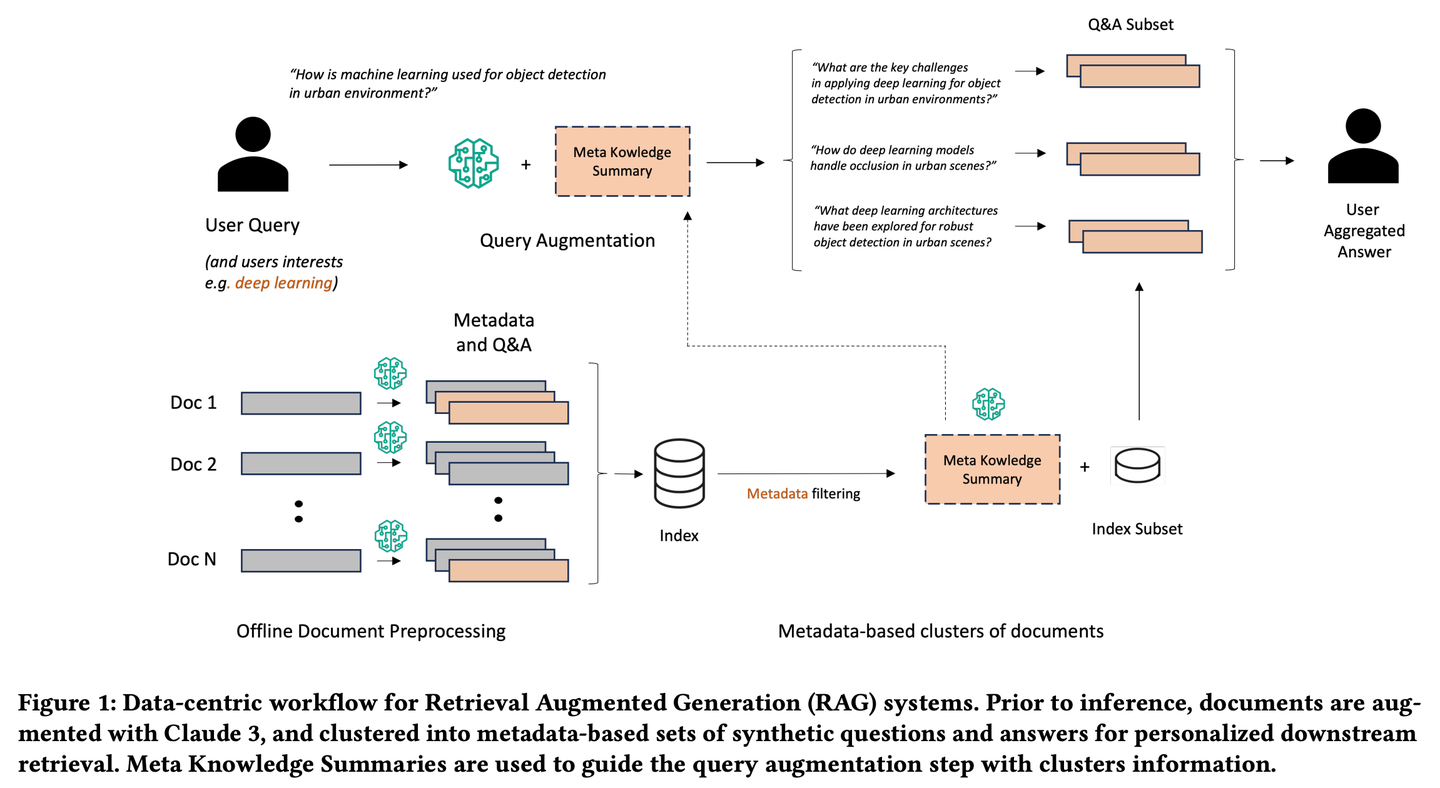
(35) Meta-Knowledge-RAG【学者】
学者
:像个学术界的资深研究员,不仅收集资料,还会主动思考问题,为每份文档做批注和总结,甚至预先设想可能的问题。它会把相关的知识点串联起来,形成知识网络,让查询变得更有深度和广度,就像有一个学者在帮你做研究综述。
- 时间:08.16
- 论文:
Meta Knowledge for Retrieval Augmented Large Language Models - 参考:
https://mp.weixin.qq.com/s/twFVKQDTRZTGvDeYA8-c0A
Meta-Knowledge-RAG(MK Summary)引入了一种新颖的以数据为中心的 RAG 工作流程,将传统的 “检索-读取” 系统转变为更先进的 “准备-重写-检索-读取” 框架,以实现对知识库的更高领域专家级理解。我们的方法依赖于为每个文档生成元数据和合成的问题与答案以及为基于元数据的文档集群引入元知识摘要的新概念。所提出的创新实现了个性化的用户查询增强和跨知识库的深度信息检索。
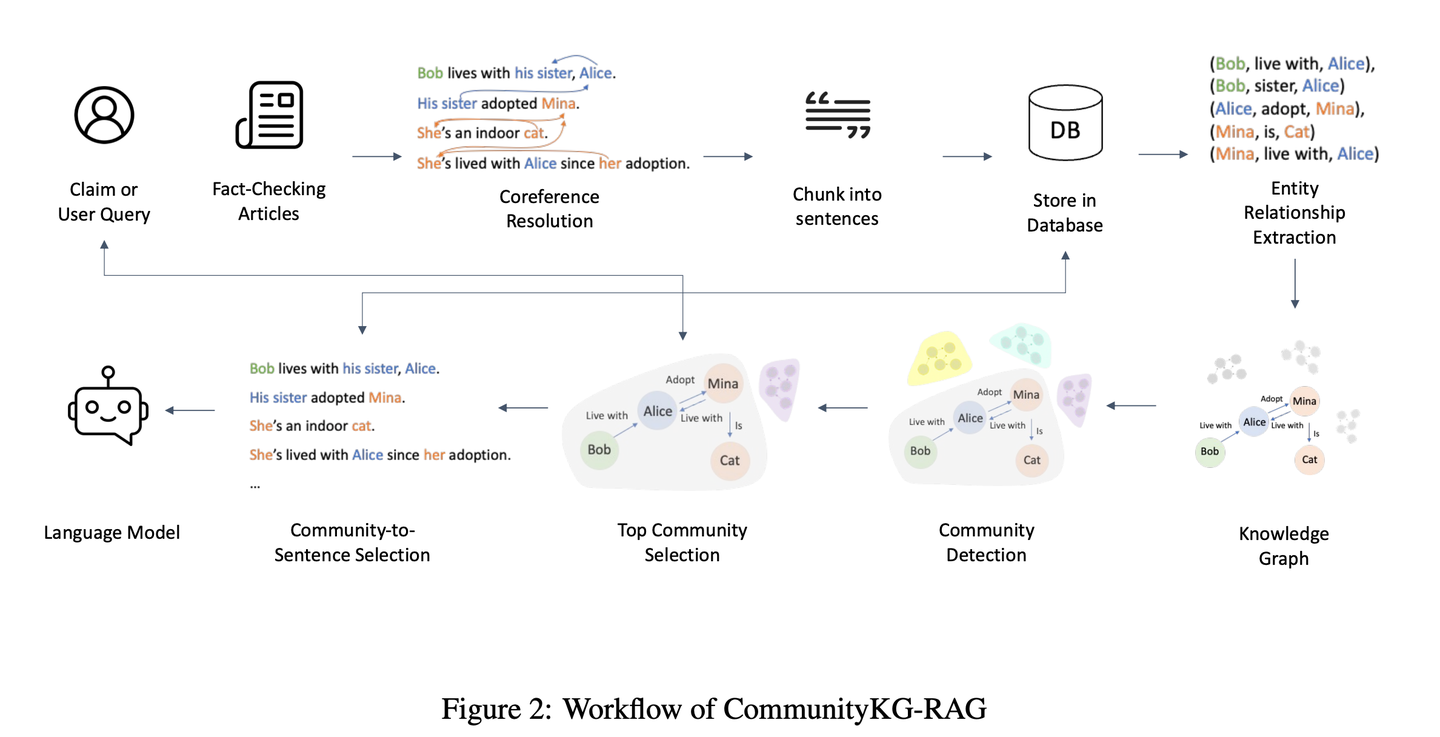
(36) CommunityKG-RAG【社群探索】
社群探索
:像个熟悉社区关系网络的向导,善于利用知识间的关联和群组特征,在不需要特别学习的情况下,就能准确地找到相关信息,并验证其可靠性。
- 时间:08.16
- 论文:
CommunityKG-RAG: Leveraging Community Structures in Knowledge Graphs for Advanced Retrieval-Augmented Generation in Fact-Checking - 参考:
https://mp.weixin.qq.com/s/ixKV-PKf8ohqZDCTN9jLZQ
CommunityKG-RAG是一种新颖的零样本框架,它将知识图谱中的社区结构与RAG系统相结合,以增强事实核查过程。CommunityKG-RAG能够在无需额外训练的情况下适应新的领域和查询,它利用知识图谱中社区结构的多跳性质,显著提高信息检索的准确性和相关性。
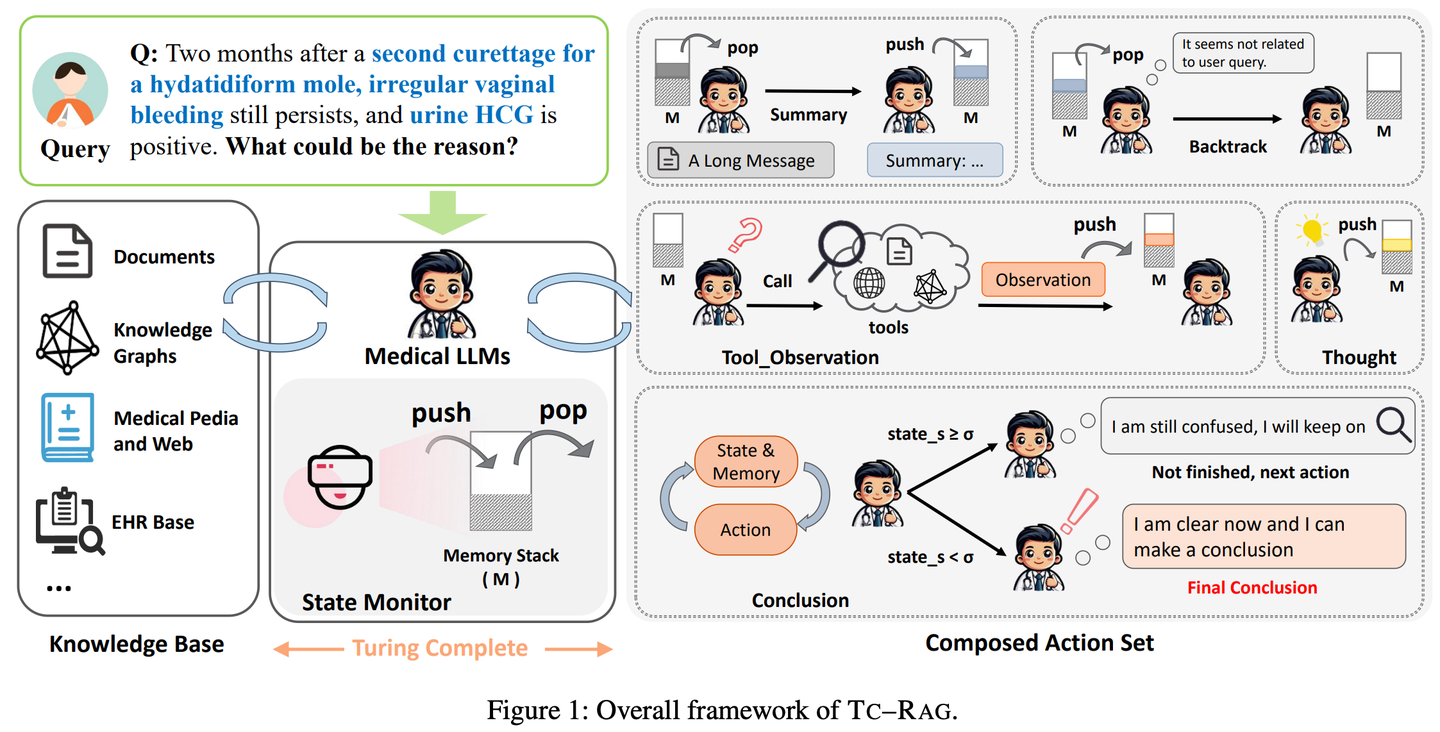
(37) TC-RAG【记忆术士】
记忆术士
:给LLM装了个带自动清理功能的大脑。就像我们解题,会把重要步骤写在草稿纸上,做完就划掉。它不是死记硬背,该记的记住,该忘的及时清空,像个会收拾房间的学霸。
- 时间:08.17
- 论文:
TC-RAG: Turing-Complete RAG's Case study on Medical LLM Systems - 项目:
https://github.com/Artessay/TC-RAG - 参考:
https://mp.weixin.qq.com/s/9VhIC5sJP_6nh_Ppfsb6UQ
通过引入图灵完备的系统来管理状态变量,从而实现更高效、准确的知识检索。通过利用具有自适应检索、推理和规划能力的记忆堆栈系统,TC-RAG不仅确保了检索过程的受控停止,还通过Push和Pop操作减轻了错误知识的积累。
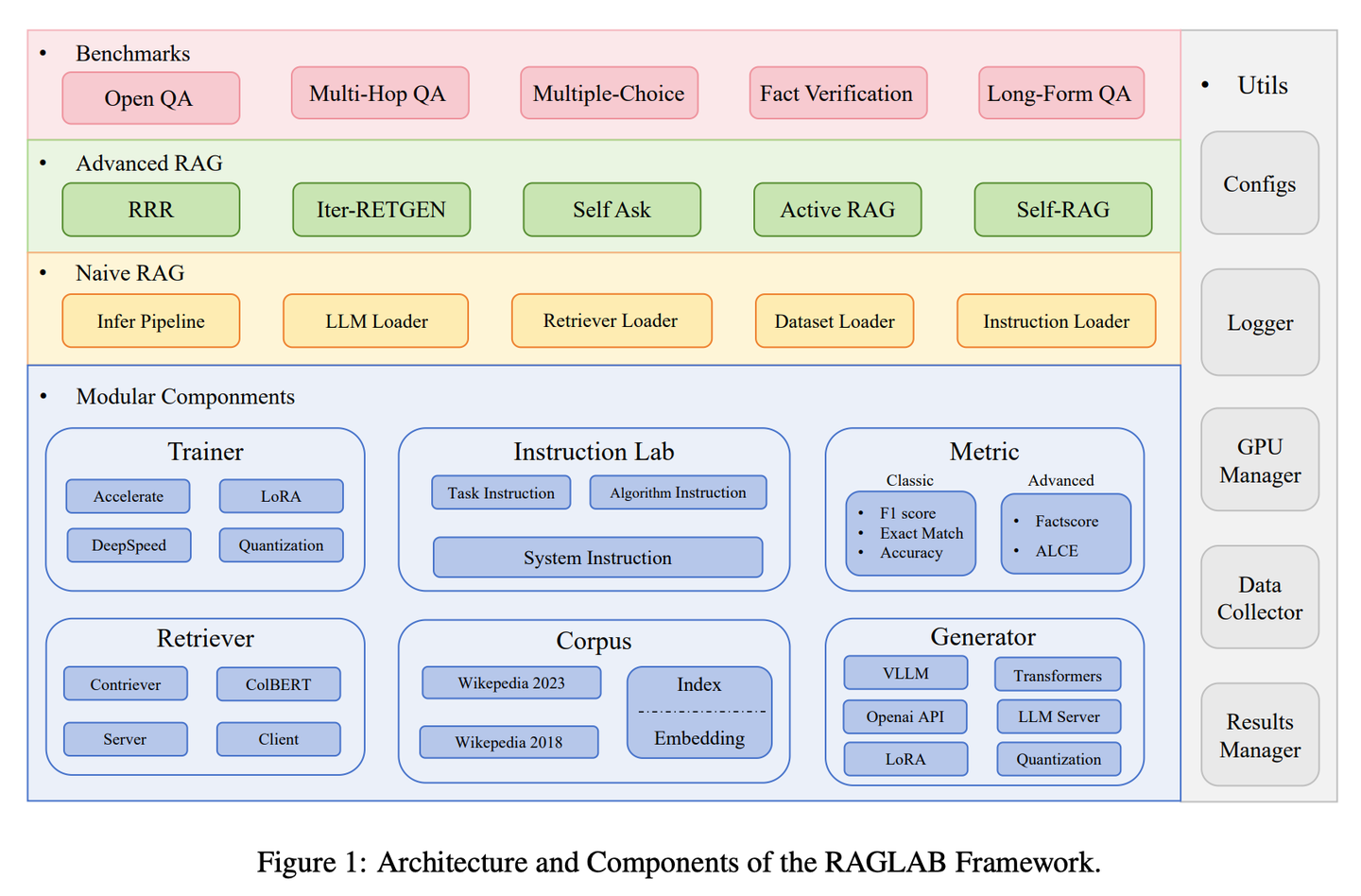
(38) RAGLAB【竞技场】
竞技场
:让各种算法可以在相同的规则下进行公平竞争和比较,就像科学实验室里的标准化测试流程,确保每个新方法都能得到客观透明的评估。
- 时间:08.21
- 论文:
RAGLAB: A Modular and Research-Oriented Unified Framework for Retrieval-Augmented
Generation - 项目:
https://github.com/fate-ubw/RAGLab - 参考:
https://mp.weixin.qq.com/s/WSk0zdWZRXMVvm4-_HiFRw
新型RAG算法之间越来越缺乏全面和公平的比较,开源工具的高级抽象导致缺乏透明度,并限制了开发新算法和评估指标的能力。RAGLAB是一个模块化、研究导向的开源库,重现6种算法并构建全面研究生态。借助RAGLAB,我们在10个基准上公平对比6种算法,助力研究人员高效评估和创新算法。
2024.09
(39) MemoRAG【过目不忘】
过目不忘
:它不只是按需查找资料,而是已经把整个知识库都深入理解并记在心里。当你问问题时,它能快速从这个"超级大脑"中调取相关记忆,给出既准确又富有见地的答案,就像一个博学多识的专家。
- 时间:09.01
- 项目:
https://github.com/qhjqhj00/MemoRAG - 参考:
https://mp.weixin.qq.com/s/88FTElcYf5PIgHN0J8R7DA
MemoRAG是一个创新的检索增强生成(RAG)框架,构建在一个高效的超长记忆模型之上。与主要处理具有明确信息需求查询的标准RAG不同,MemoRAG利用其记忆模型实现对整个数据库的全局理解。通过从记忆中召回特定于查询的线索,MemoRAG增强了证据检索,从而产生更准确且具有丰富上下文的响应生成。
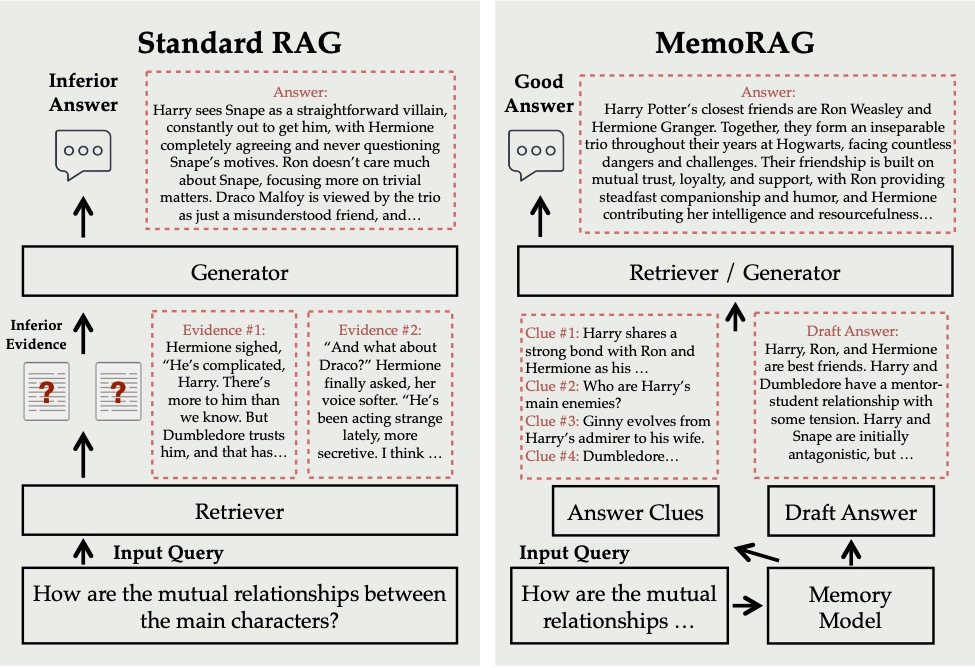
(40) OP-RAG【注意力管理】
注意力管理
:就像看一本特别厚的书,你不可能把每个细节都记住,但懂得在关键章节做好标记的人才是高手。它不是漫无目的地看,而是像个资深读书人,边读边在重点处画下重点,需要的时候直接翻到标记页。
- 时间:09.03
- 论文:
In Defense of RAG in the Era of Long-Context Language Models - 参考:
https://mp.weixin.qq.com/s/WLaaniD7RRgN0h2OCztDcQ
LLM中的极长语境会导致对相关信息的关注度降低,并导致答案质量的潜在下降。重新审视长上下文答案生成中的RAG。我们提出了一种顺序保留检索增强生成机制OP-RAG,显著提高了RAG在长上下文问答应用中的性能。
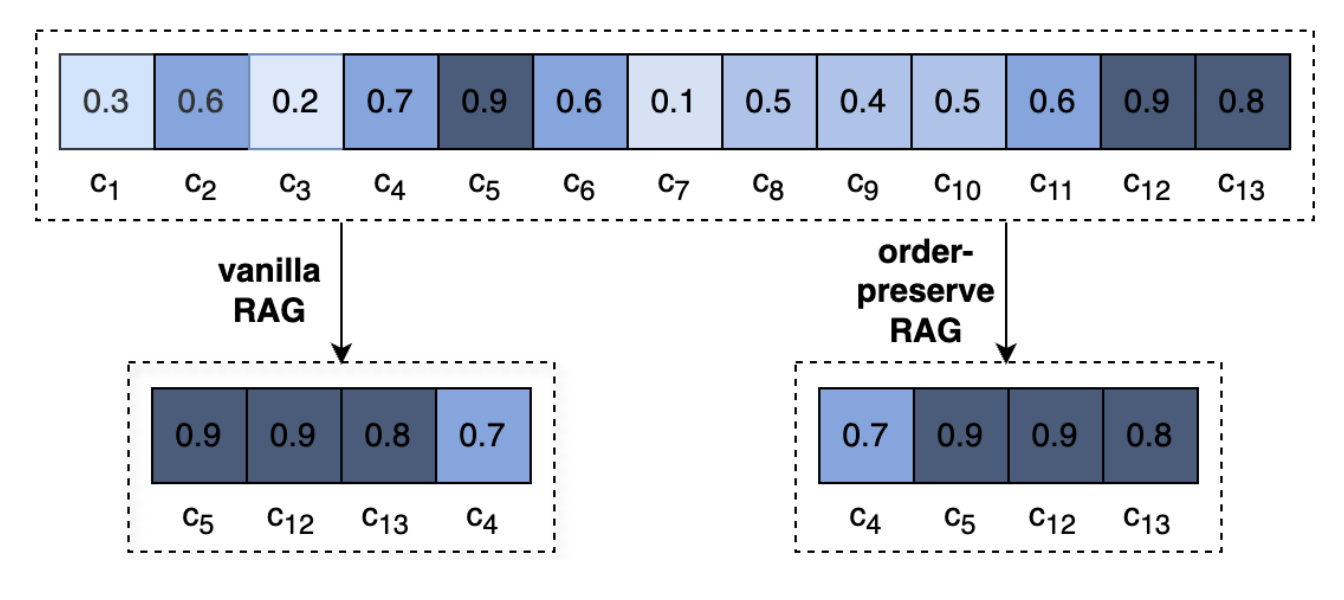
(41) AgentRE【智能抽取】
智能抽取
:像个善于观察人际关系的社会学家,不仅能记住关键信息,还会主动查证并深入思考,从而准确理解复杂的关系网络。即使面对错综复杂的关系,也能通过多角度分析,理清其中的脉络,避免望文生义。
- 时间:09.03
- 论文:
AgentRE: An Agent-Based Framework for Navigating Complex Information Landscapes in Relation Extraction - 项目:
https://github.com/Lightblues/AgentRE - 参考:
https://mp.weixin.qq.com/s/_P_3H3uyIWjgaCF_FczsDg
AgentRE通过整合大型语言模型的记忆、检索和反思能力,有效应对复杂场景关系抽取中关系类型多样以及单个句子中实体之间关系模糊的挑战。AgentRE 包含三大模块,助力代理高效获取并处理信息,显著提升 RE 性能。
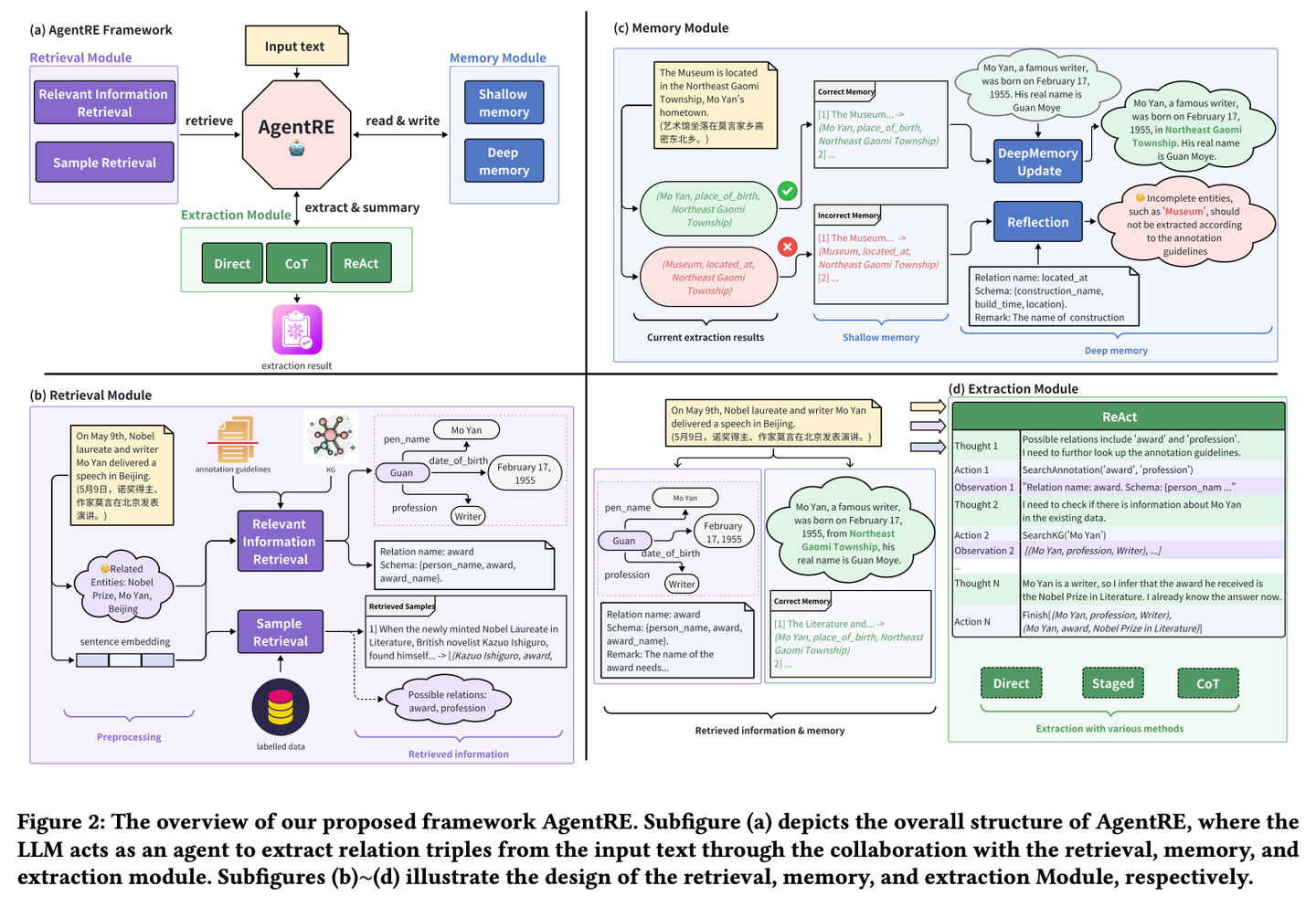
(42) iText2KG【建筑师】
建筑师
:像个有条理的工程师,通过分步骤提炼、提取和整合信息,逐步将零散文档转化为系统的知识网络,而且不需要事先准备详细的建筑图纸,可以根据需要灵活地扩建和完善。
- 时间:09.05
- 论文:
iText2KG: Incremental Knowledge Graphs Construction Using Large Language Models - 项目:
https://github.com/AuvaLab/itext2kg - 参考:
https://mp.weixin.qq.com/s/oiDffH1_0JiGpVGw83-guQ
iText2KG(增量式知识图谱构建)利用大型语言模型 (LLM) 从原始文档中构建知识图谱,并通过四个模块(文档提炼器、增量实体提取器、增量关系提取器和图谱集成器)实现增量式知识图谱构建,无需事先定义本体或进行大量的监督训练。
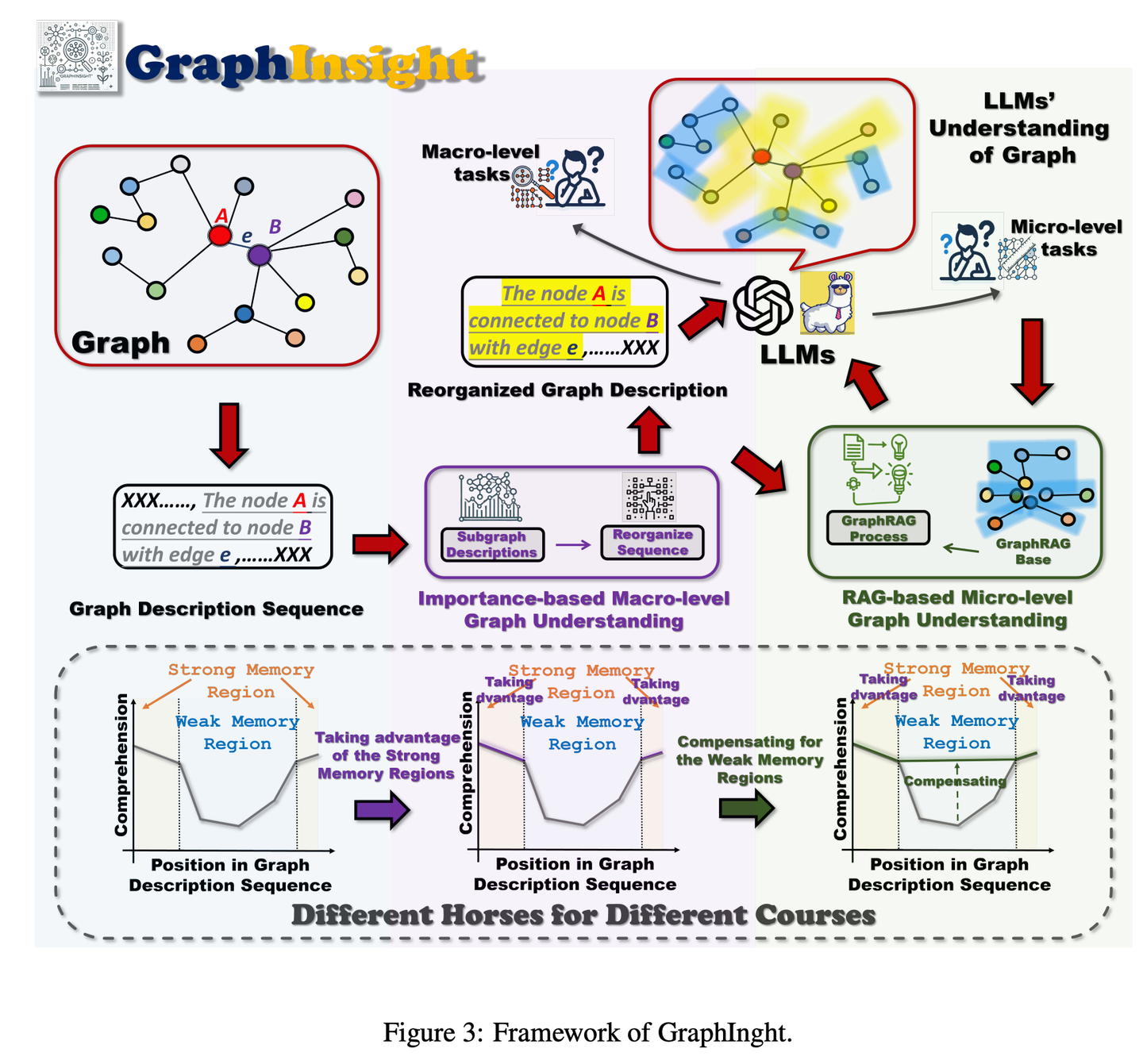
(43) GraphInsight【图谱解读】
图谱解读
:像个擅长信息图表分析的专家,知道把重要信息放在最显眼的位置,同时在需要时查阅参考资料来补充细节,并能step by step地推理复杂图表,让AI既能把握全局又不遗漏细节。
- 时间:09.05
- 论文:
GraphInsight: Unlocking Insights in Large Language Models for Graph Structure Understanding - 参考:
https://mp.weixin.qq.com/s/xDKTBtso3ONCGyskvmfAcg
GraphInsight旨在提升LLMs对宏观和微观层面图形信息理解的新框架。GraphInsight基于两大关键策略:1)将关键图形信息置于LLMs记忆性能较强的位置;2)借鉴检索增强生成(RAG)的思想,对记忆性能较弱的区域引入轻量级外部知识库。此外,GraphInsight探索将这两种策略整合到LLM代理过程中,以应对需要多步推理的复合图任务。
(44) LA-RAG【方言通】
方言通
:像个精通各地方言的语言专家,通过细致的语音分析和上下文理解,不仅能准确识别标准普通话,还能听懂带有地方特色的口音,让AI与不同地区的人都能无障碍交流。
- 时间:09.13
- 论文:
LA-RAG:Enhancing LLM-based ASR Accuracy with Retrieval-Augmented Generation - 参考:
https://mp.weixin.qq.com/s/yrmtBqP4bmQ2wYZM7F24Yg
LA-RAG,是一种基于LLM的ASR的新型检索增强生成(RAG)范例。LA-RAG 利用细粒度标记级语音数据存储和语音到语音检索机制,通过 LLM 上下文学习 (ICL) 功能提高 ASR 准确性。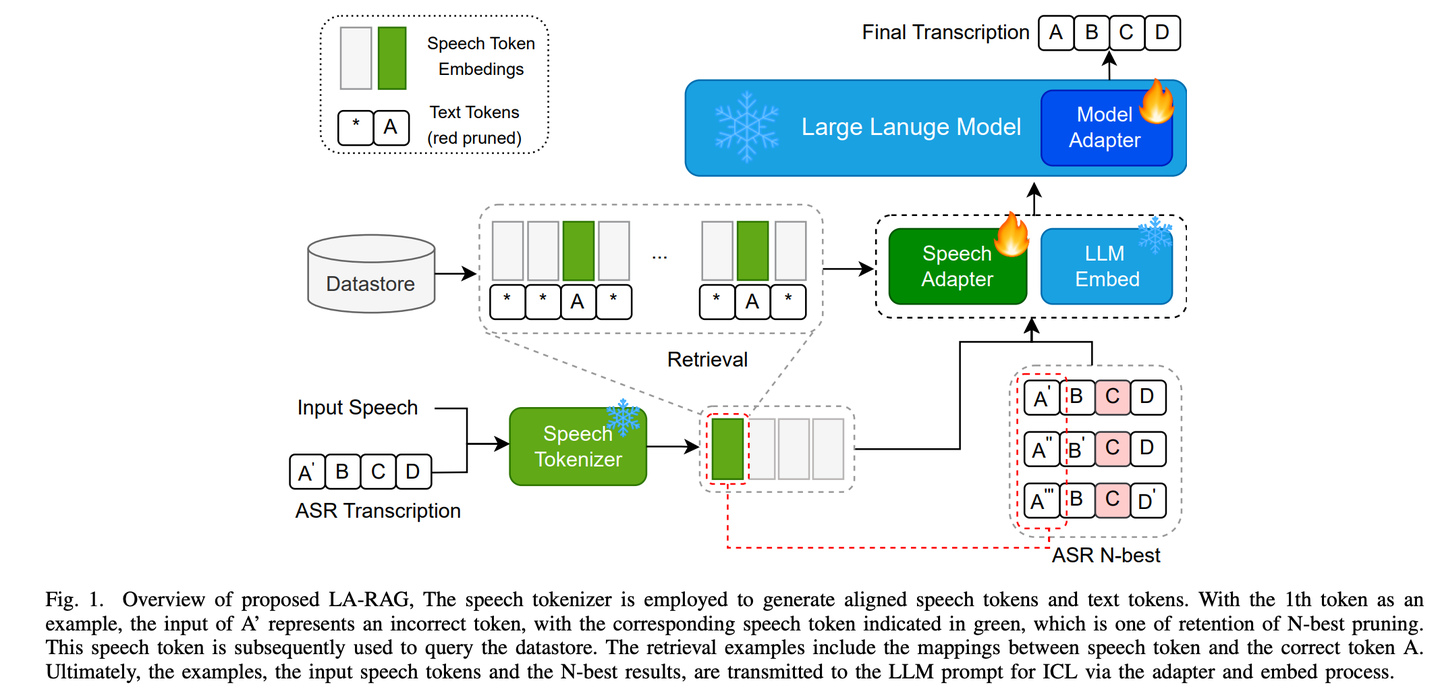
(45) SFR-RAG【精简检索】
精简检索
:像个精练的参考顾问,体积虽小但功能精准,既能理解需求又懂得寻求外部帮助,保证回答既准确又高效。
- 时间:09.16
- 论文:
SFR-RAG: Towards Contextually Faithful LLMs - 参考:
https://mp.weixin.qq.com/s/rArOICbHpkmFPR5UoBIi5A
SFR-RAG是一个经过指令微调的小型语言模型,重点是基于上下文的生成和最小化幻觉。通过专注于在保持高性能的同时减少参数数量,SFR-RAG模型包含函数调用功能,使其能够与外部工具动态交互以检索高质量的上下文信息。

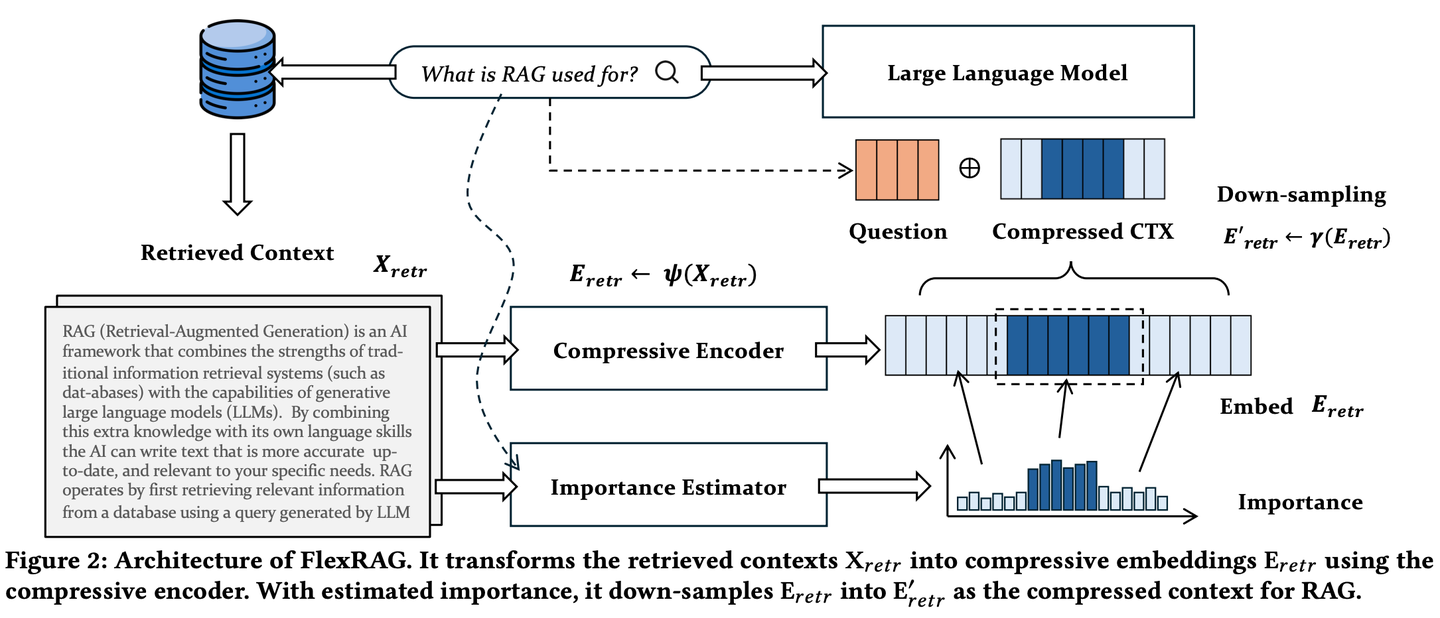
(46) FlexRAG【压缩专家】
压缩专家
:把长篇大论浓缩成精华摘要,而且压缩比例可以根据需要灵活调整,既不丢失关键信息,又能节省存储和处理成本。就像把一本厚书精炼成一份简明扼要的读书笔记。
- 时间:09.24
- 论文:
Lighter And Better: Towards Flexible Context Adaptation For Retrieval Augmented Generation - 参考:
https://mp.weixin.qq.com/s/heYbLVQHeykD1EbqH8PSZw
FlexRAG检索到的上下文在被LLMs编码之前被压缩为紧凑的嵌入。同时这些压缩后的嵌入经过优化以提升下游RAG的性能。FlexRAG的一个关键特性是其灵活性,它能够有效支持不同的压缩比,并选择性地保留重要上下文。得益于这些技术设计,FlexRAG在显著降低运行成本的同时实现了卓越的生成质量。在各种问答数据集上进行的全面实验验证了我们的方法是RAG系统的一种具有成本效益且灵活的解决方案。
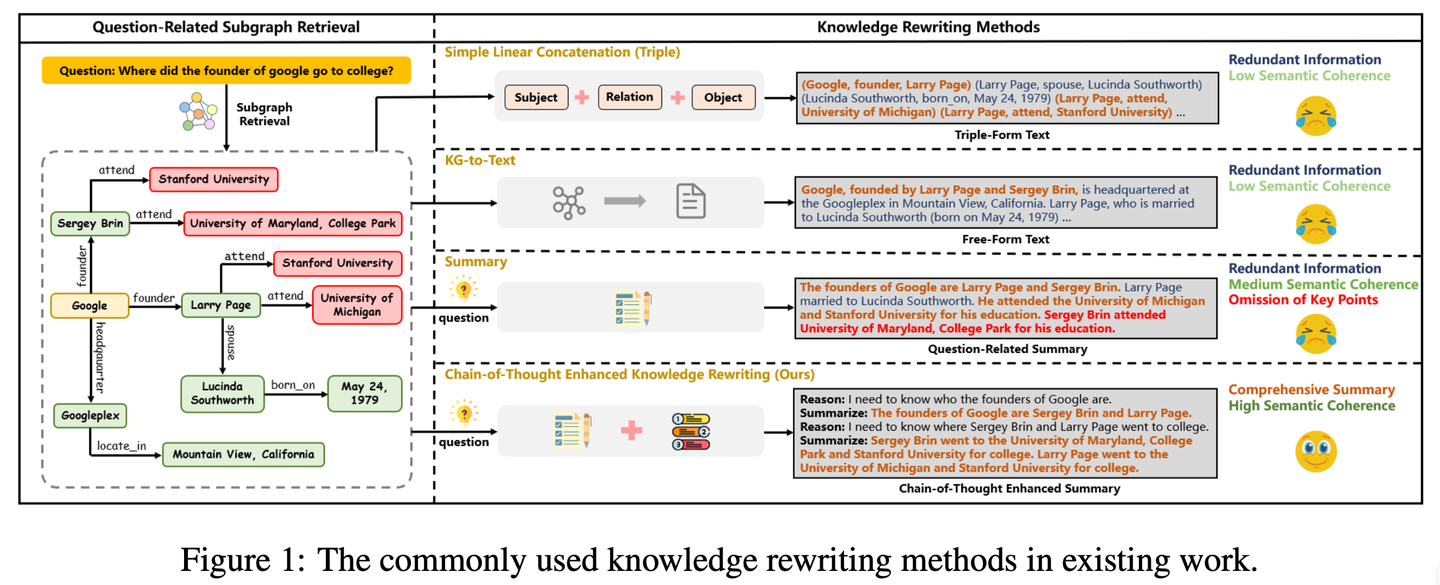
(47) CoTKR【图谱翻译】
图谱翻译
:像个耐心的老师,先理解知识的来龙去脉,再一步步讲解,不是简单复述而是深入浅出地转述。同时通过不断收集"学生"的反馈来改进自己的讲解方式,让知识传递更加清晰有效。
- 时间:09.29
- 论文:
CoTKR: Chain-of-Thought Enhanced Knowledge Rewriting for Complex Knowledge Graph Question Answering - 项目:
https://github.com/wuyike2000/CoTKR - 参考:
https://mp.weixin.qq.com/s/lCHxLxRP96Y3mofDVjKY9w
CoTKR(Chain-of-Thought Enhanced Knowledge Rewriting)方法交替生成推理路径和相应知识,从而克服了单步知识改写的限制。此外,为了弥合知识改写器和问答模型之间的偏好差异,我们提出了一种训练策略,即从问答反馈中对齐偏好通过利用QA模型的反馈进一步优化知识改写器。
2024.10
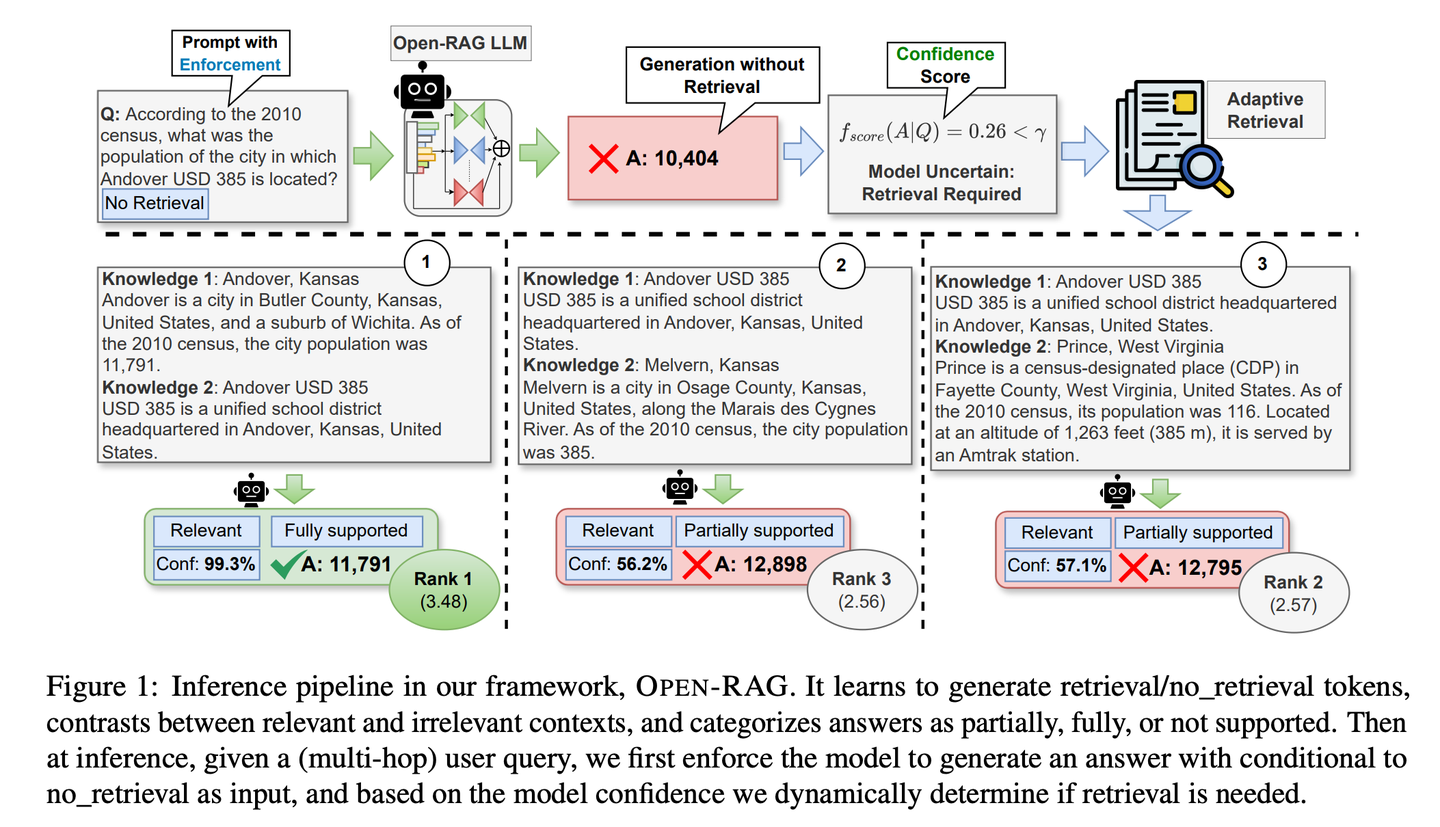
(48) Open-RAG【智囊团】
智囊团
:把庞大的语言模型分解成专家小组,让它们既能独立思考又能协同工作,还特别会分辨真假信息,关键时刻知道该不该查资料,像个经验丰富的智囊团。
- 时间:10.02
- 论文:
Open-RAG: Enhanced Retrieval-Augmented Reasoning with Open-Source Large Language Models - 项目:
https://github.com/ShayekhBinIslam/openrag - 参考:
https://mp.weixin.qq.com/s/H0_THczQ3UWCkSnnk-vveQ
Open-RAG通过开源大语言模型提高RAG中的推理能力,将任意密集的大语言模型转换为参数高效的稀疏专家混合(MoE)模型,该模型能够处理复杂的推理任务,包括单跳和多跳查询。OPEN-RAG独特地训练模型以应对那些看似相关但具有误导性的挑战性干扰项。
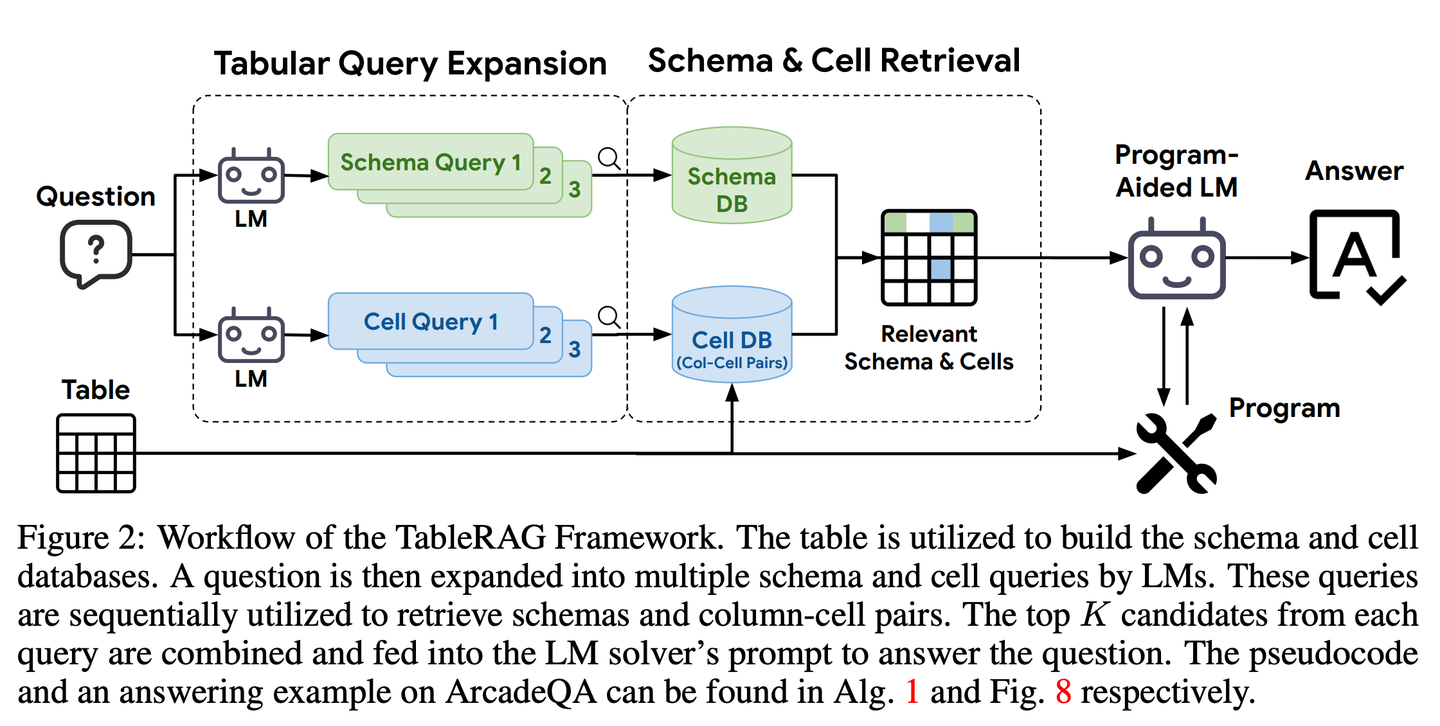
(49) TableRAG【Excel专家】
Excel专家
:不只简单地查看表格数据,而是懂得从表头和单元格两个维度去理解和检索数据,就像熟练使用数据透视表一样,能快速定位和提取所需的关键信息。
- 时间:10.07
- 论文:
TableRAG: Million-Token Table Understanding with Language Models - 参考:
https://mp.weixin.qq.com/s/n0iu6qOufc1izlzuRjQO6g
TableRAG专为表格理解设计了检索增强生成框架,通过查询扩展结合Schema和单元格检索,能够在提供信息给语言模型之前精准定位关键数据,从而实现更高效的数据编码和精确检索,大幅缩短提示长度并减少信息丢失。
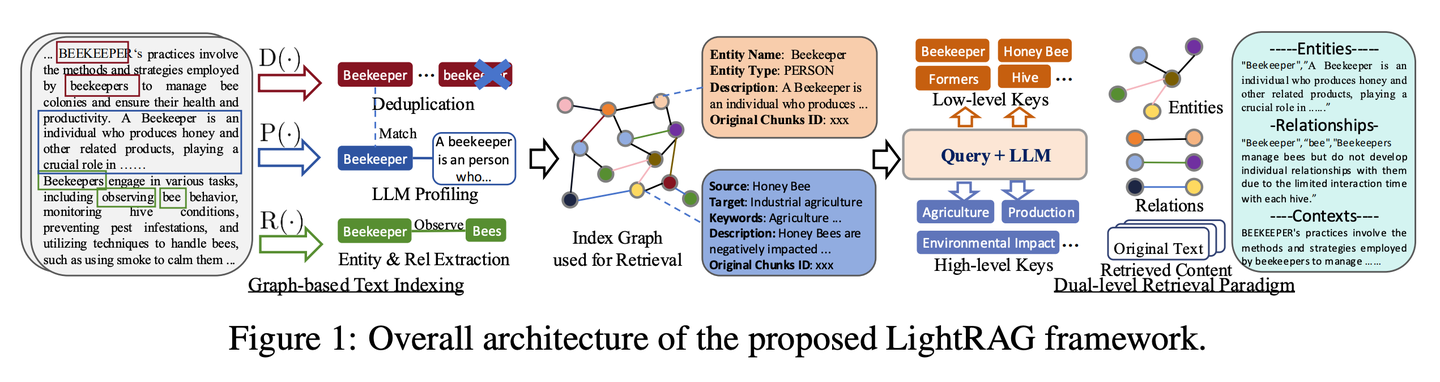
(50) LightRAG【蜘蛛侠】
蜘蛛侠
:在知识的网中灵活穿梭,既能抓住知识点之间的丝,又能借网顺藤摸瓜。像个长了千里眼的图书管理员,不仅知道每本书在哪,还知道哪些书该一起看。
- 时间:10.08
- 论文:
LightRAG: Simple and Fast Retrieval-Augmented Generation - 项目:
https://github.com/HKUDS/LightRAG - 参考:
https://mp.weixin.qq.com/s/1QKdgZMN55zD6X6xWSiTJw
该框架将图结构融入文本索引和检索过程中。这一创新框架采用了一个双层检索系统,从低级和高级知识发现中增强全面的信息检索。此外,将图结构与向量表示相结合,便于高效检索相关实体及其关系,显著提高了响应时间,同时保持了上下文相关性。这一能力通过增量更新算法得到了进一步增强,该算法确保了新数据的及时整合,使系统能够在快速变化的数据环境中保持有效性和响应性。
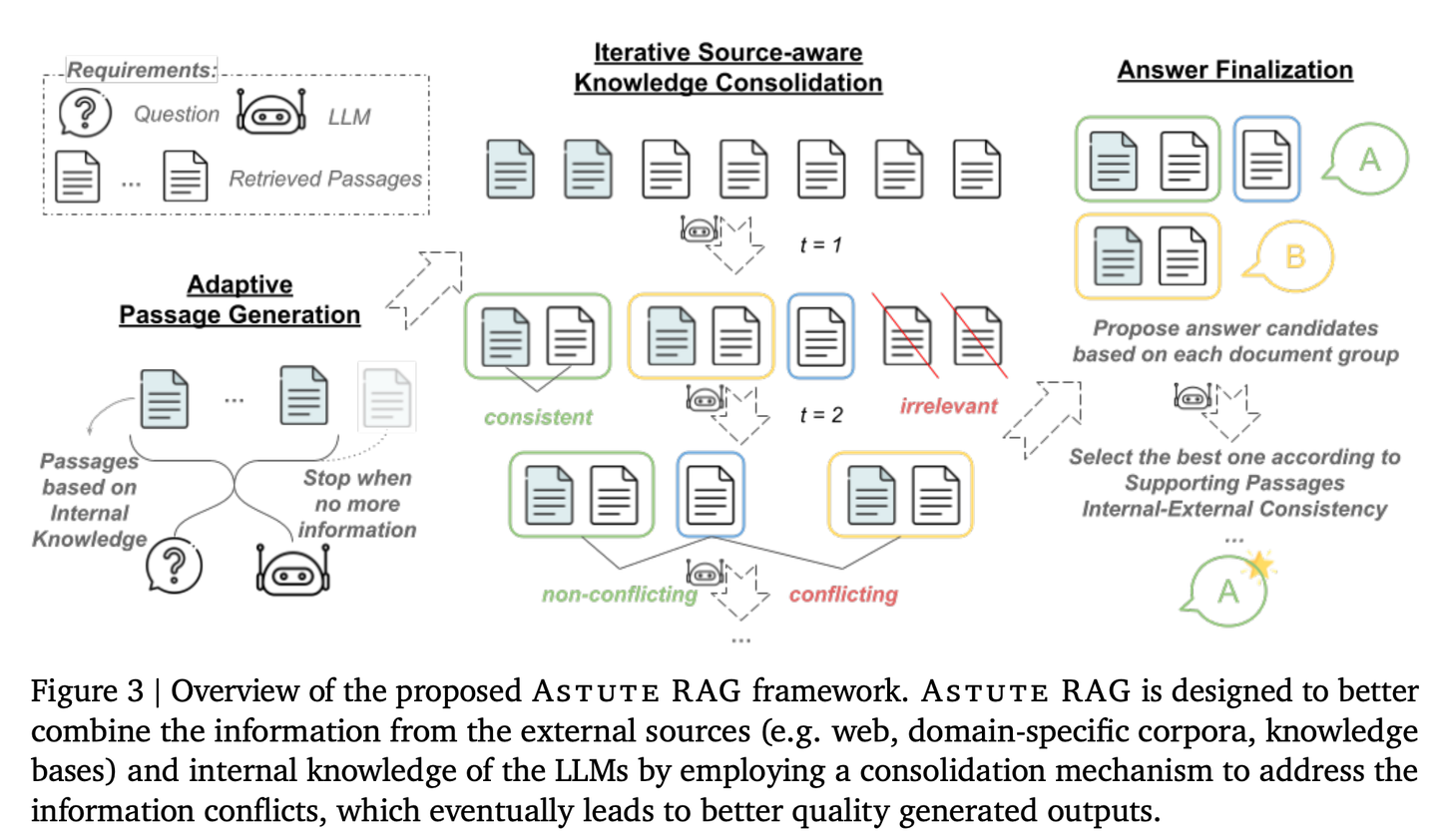
(51) AstuteRAG【明智判官】
明智判官
:对外部信息保持警惕,不轻信检索结果,善用自身积累的知识,甄别信息真伪,像资深法官一样,权衡多方证据定论。
- 时间:10.09
- 论文:
Astute RAG: Overcoming Imperfect Retrieval Augmentation and Knowledge Conflicts for Large Language Models - 参考:
https://mp.weixin.qq.com/s/Y8ozl3eH1osJTNOSuu4v1w
通过适应性地从LLMs内部知识中提取信息,结合外部检索结果,并根据信息的可靠性来最终确定答案,从而提高系统的鲁棒性和可信度。
(52) TurboRAG【速记高手】
速记高手
:提前把功课做好,把答案都记在小本本里。像个考前突击的学霸,不是临场抱佛脚,而是把常考题提前整理成错题本。需要的时候直接翻出来用,省得每次都要现场推导一遍。
- 时间:10.10
- 论文:
TurboRAG: Accelerating Retrieval-Augmented Generation with Precomputed KV Caches for Chunked Text - 项目:
https://github.com/MooreThreads/TurboRAG - 参考:
https://mp.weixin.qq.com/s/lanZ8cIEnIt12tFt4d-xzw
TurboRAG通过离线预计算和存储文档的KV缓存来优化RAG系统的推理范式。与传统方法不同,TurboRAG在每次推理时不再计算这些KV缓存,而是检索预先计算的缓存以进行高效的预填充,从而消除了重复在线计算的需要。这种方法显著减少了计算开销,加快了响应时间,同时保持了准确性。
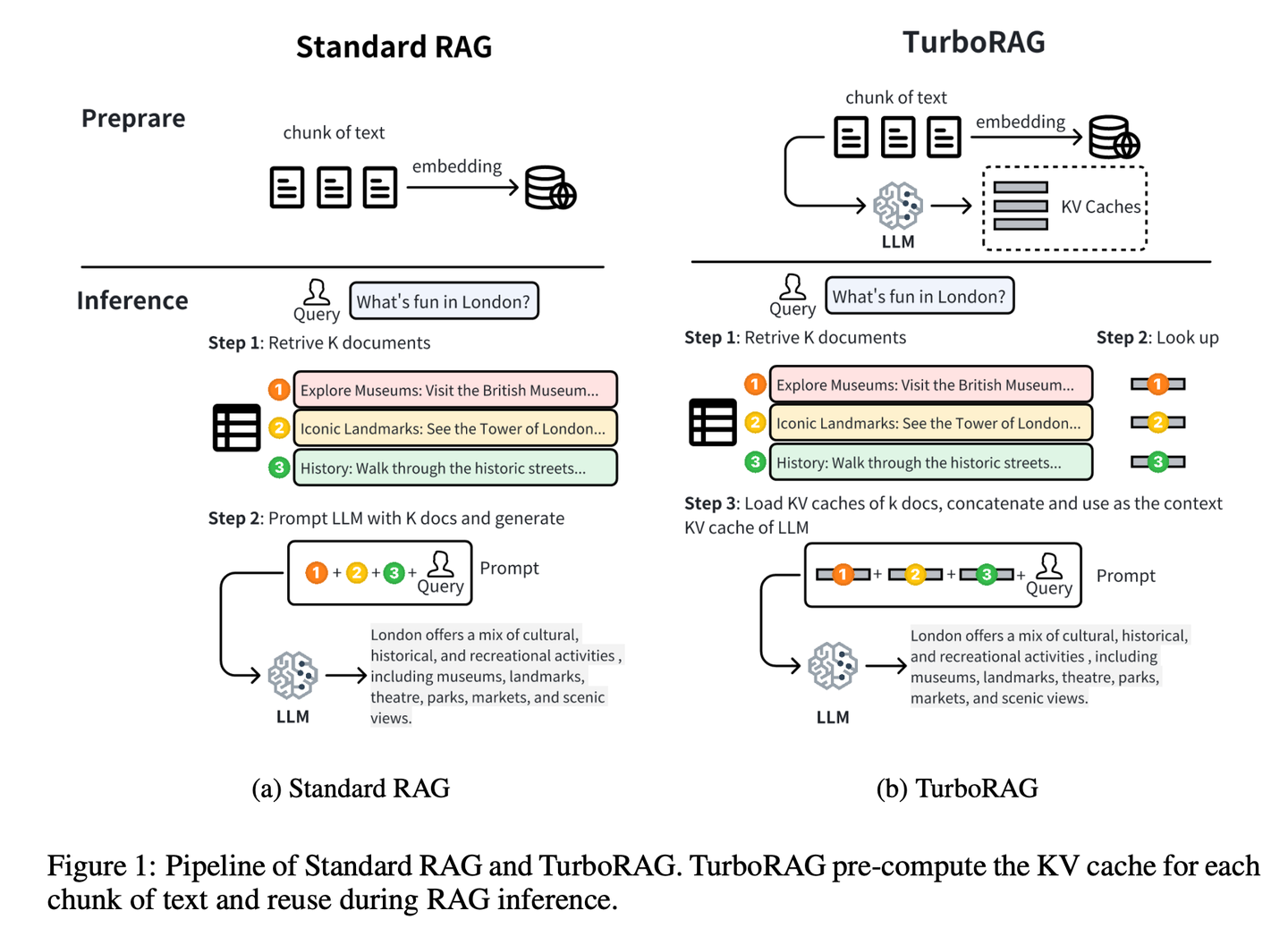
(53) StructRAG【收纳师】
收纳师
:把杂乱无章的信息像收纳衣柜一样分门别类地整理好。像个模仿人类思维的学霸,不是死记硬背,而是先画个思维导图。
- 时间:10.11
- 论文:
StructRAG: Boosting Knowledge Intensive Reasoning of LLMs via Inference-time Hybrid Information Structurization - 项目:
https://github.com/Li-Z-Q/StructRAG - 参考:
https://mp.weixin.qq.com/s/9UQOozHNHDRade5b6Onr6w
受人类在处理知识密集型推理时将原始信息转换为结构化知识的认知理论启发,该框架引入了一种混合信息结构化机制,该机制根据手头任务的特定要求以最合适的格式构建和利用结构化知识。通过模仿类人的思维过程,提高了LLM在知识密集型推理任务上的表现。

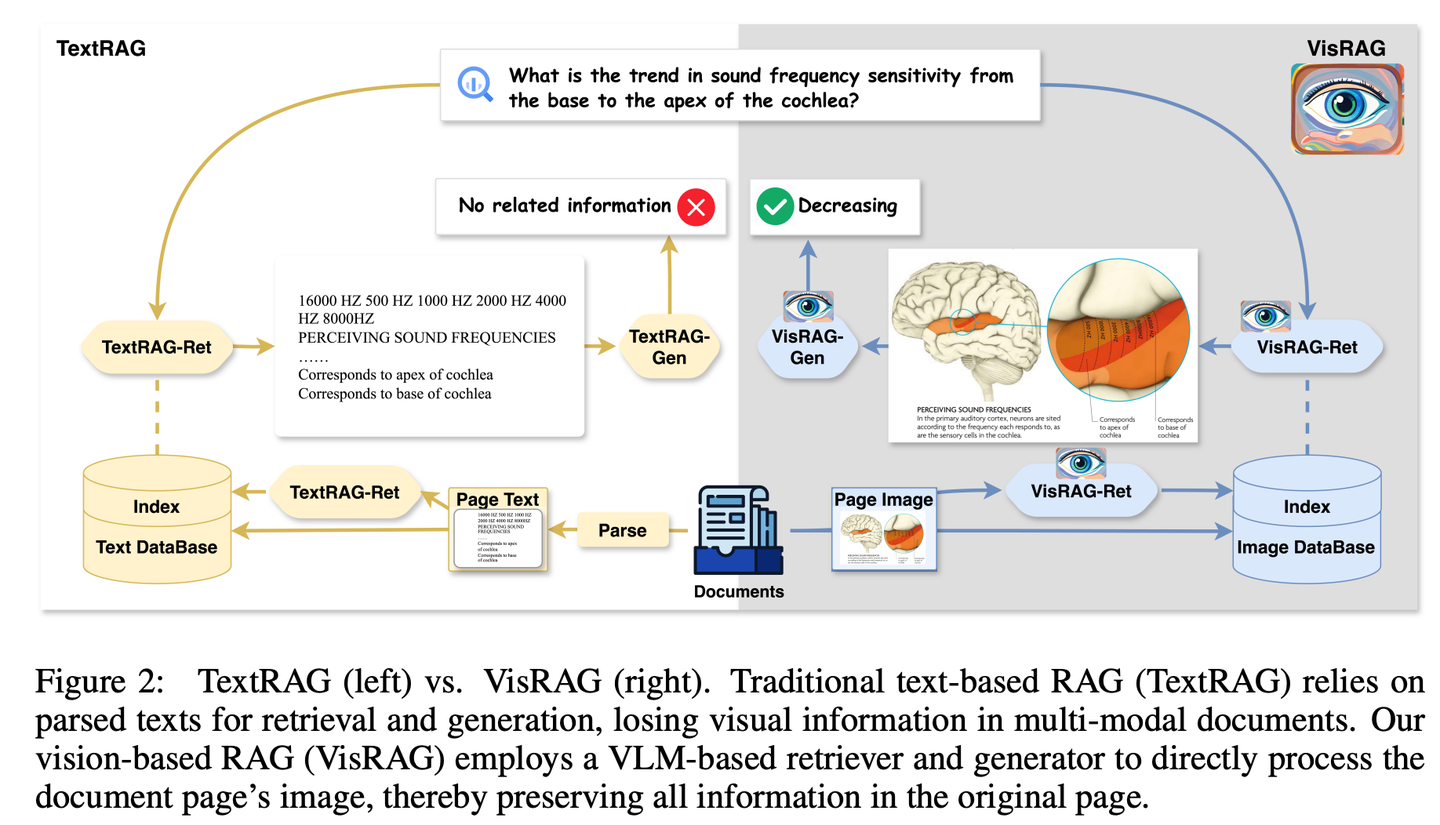
(54) VisRAG【火眼金睛】
火眼金睛
:终于悟出文字不过是图像的一种特殊表现形式。像个开了天眼的阅读者,不再执着于逐字解析,而是直接"看"透全局。用照相机代替了OCR,懂得了"一图胜千言"的精髓。
- 时间:10.14
- 论文:
VisRAG: Vision-based Retrieval-augmented Generation on Multi-modality Documents - 项目:
https://github.com/openbmb/visrag - 参考:
https://mp.weixin.qq.com/s/WB23pwJD-JV95ZlpB3bUew
通过构建基于视觉-语言模型 (VLM) 的RAG流程,直接将文档作为图像嵌入并检索,从而增强生成效果。相比传统文本RAG,VisRAG避免了解析过程中的信息损失,更全面地保留了原始文档的信息。实验显示,VisRAG在检索和生成阶段均超越传统RAG,端到端性能提升达25-39%。VisRAG不仅有效利用训练数据,还展现出强大的泛化能力,成为多模态文档RAG的理想选择。
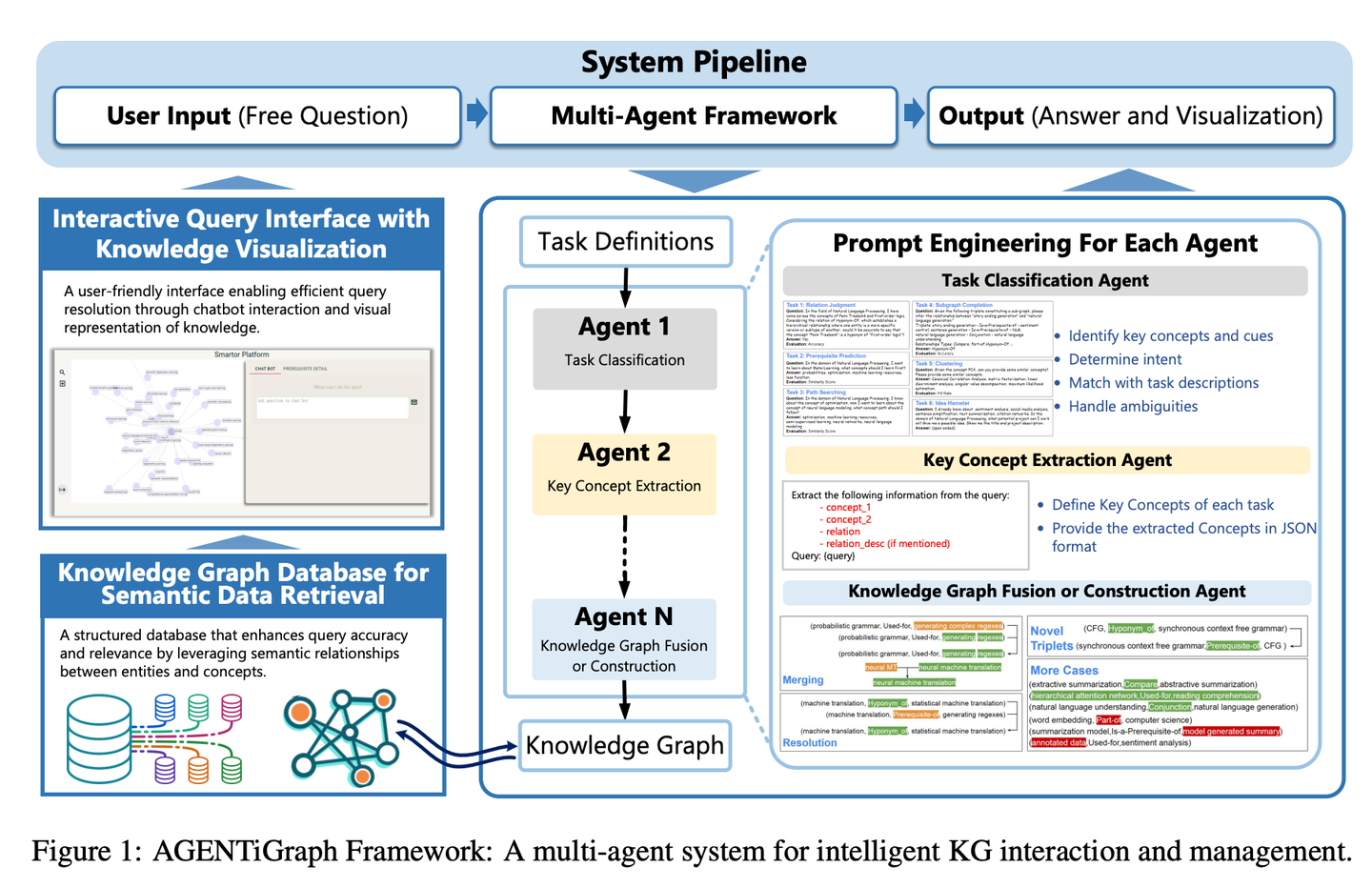
(55) AGENTiGraph【知识管家】
知识管家
:像个善于对话的图书管理员,通过日常交流帮你整理和展示知识,带着一队助手随时准备解答问题、更新资料,让知识管理变得简单自然。
- 时间:10.15
- 论文:
AGENTiGraph: An Interactive Knowledge Graph Platform for LLM-based Chatbots Utilizing Private Data - 参考:
https://mp.weixin.qq.com/s/iAlcxjXHlz7xfwVd4lpQ-g
AGENTiGraph通过自然语言交互进行知识管理的平台。它集成了知识提取、集成和实时可视化。AGENTiGraph 采用多智能体架构来动态解释用户意图、管理任务和集成新知识,确保能够适应不断变化的用户需求和数据上下文。
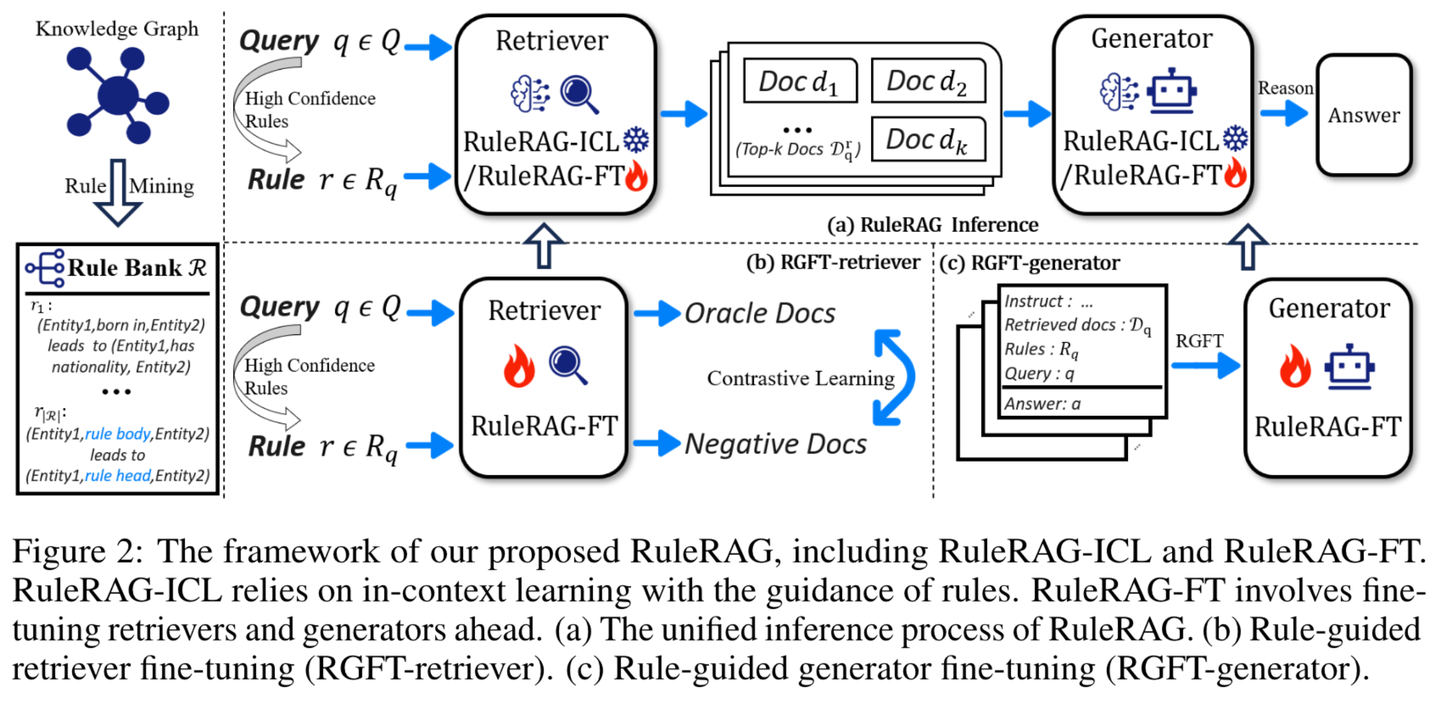
(56) RuleRAG【循规蹈矩】
循规蹈矩
:用规矩来教AI做事,就像带新人入职,先给本员工手册。不是漫无目的地学,而是像个严格的老师,先把规矩和范例都讲明白,然后再让学生自己动手。做多了,这些规矩就变成了肌肉记忆,下次遇到类似问题自然知道怎么处理。
- 时间:10.15
- 论文:
RuleRAG: Rule-guided retrieval-augmented generation with language models for question answering - 项目:
https://github.com/chenzhongwu20/RuleRAG_ICL_FT - 参考:
https://mp.weixin.qq.com/s/GNLvKG8ZgJzzNsWyVbSSig
RuleRAG提出了基于语言模型的规则引导检索增强生成方法,该方法明确引入符号规则作为上下文学习(RuleRAG - ICL)的示例,以引导检索器按照规则方向检索逻辑相关的文档,并统一引导生成器在同一组规则的指导下生成有依据的答案。此外,查询和规则的组合可进一步用作有监督的微调数据,用以更新检索器和生成器(RuleRAG - FT),从而实现更好的基于规则的指令遵循能力,进而检索到更具支持性的结果并生成更可接受的答案。
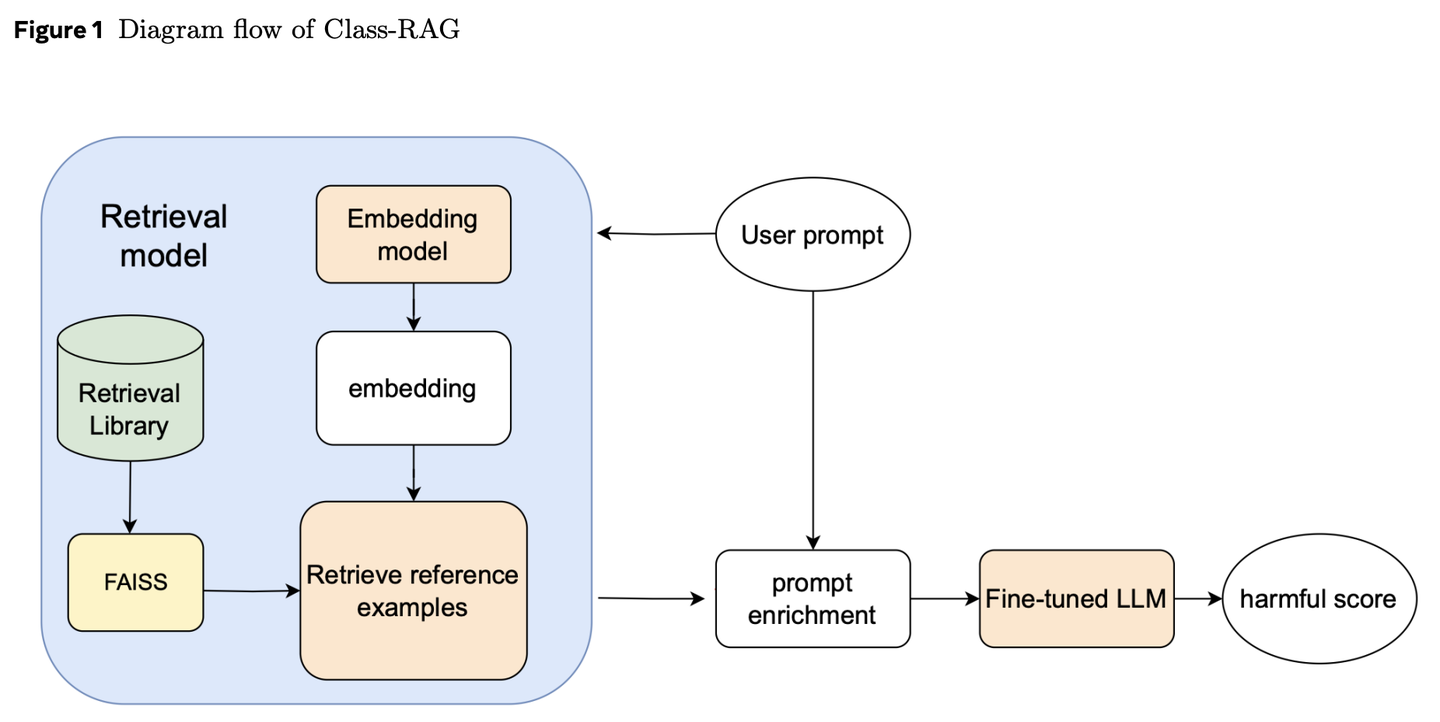
(57) Class-RAG【法官】
法官
:不是靠死板的条文判案,而是通过不断扩充的判例库来研判。像个经验老到的法官,手握活页法典,随时翻阅最新案例,让判决既有温度又有尺度。
- 时间:10.18
- 论文:
Class-RAG: Content Moderation with Retrieval Augmented Generation - 参考:
https://mp.weixin.qq.com/s/4AfZodMGJ5JQ2NUCFt3eqQ
内容审核分类器对生成式 AI 的安全性至关重要。然而,安全与不安全内容间的细微差别常令人难以区分。随着技术广泛应用,持续微调模型以应对风险变得愈发困难且昂贵。为此,我们提出 Class-RAG 方法,通过动态更新检索库,实现即时风险缓解。与传统微调模型相比,Class-RAG 更具灵活性与透明度,且在分类与抗攻击方面表现更佳。研究还表明,扩大检索库能有效提升审核性能,成本低廉。
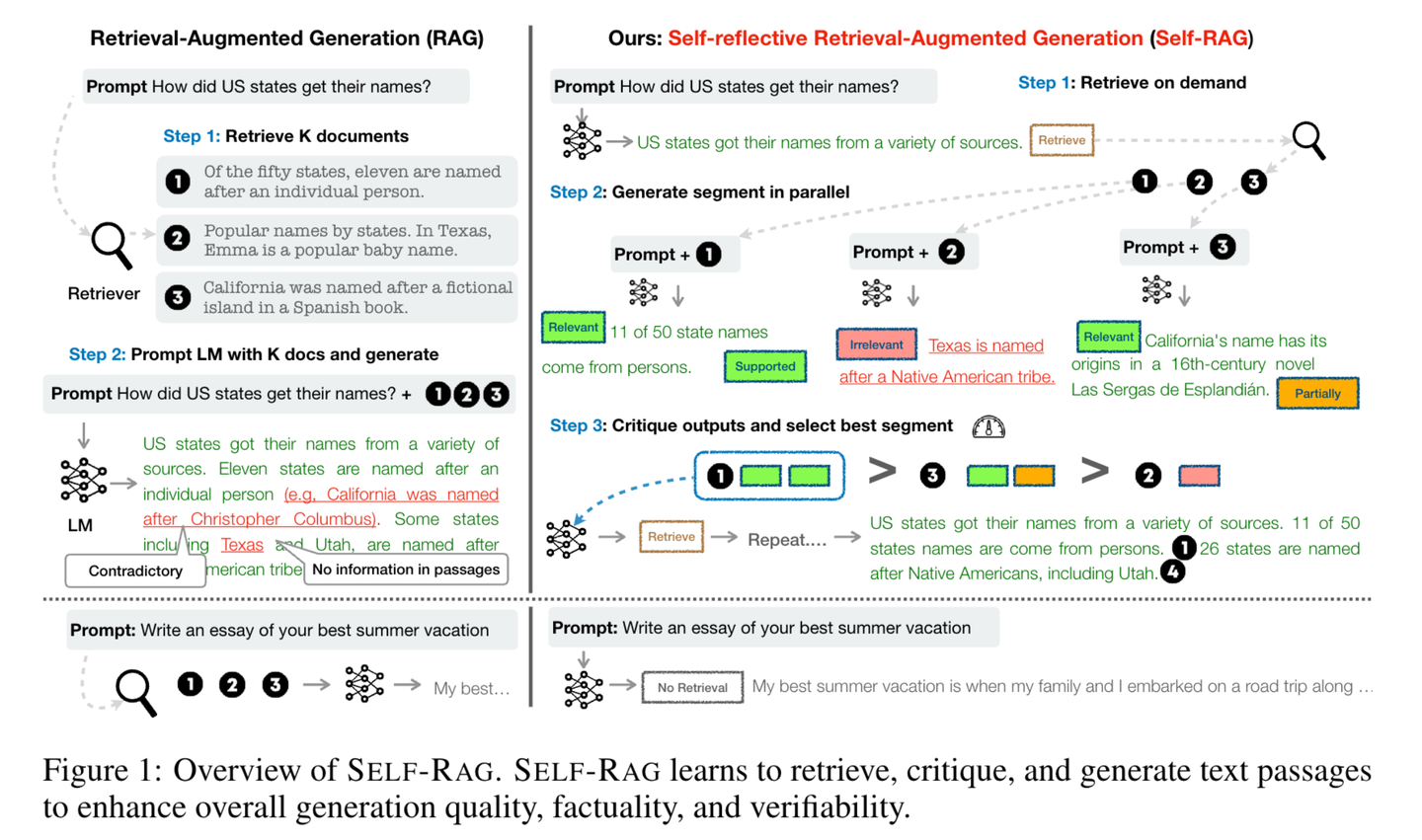
(58) Self-RAG【反思者】
反思者
:在回答问题时,不仅会查阅资料,还会不断思考和检查自己的答案是否准确完整。通过"边说边想"的方式,像一个谨慎的学者一样,确保每个观点都有可靠的依据支持。
- 时间:10.23
- 论文:
Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection - 项目:
https://github.com/AkariAsai/self-rag - 参考:
https://mp.weixin.qq.com/s/y-hN17xFyODxzTIfEfm1Vg
Self-RAG通过检索和自我反思来提升语言模型的质量和准确性。框架训练一个单一的任意语言模型,该模型能按需自适应地检索文段,并使用被称为反思标记的特殊标记来对检索到的文段及其自身生成的内容进行生成和反思。生成反思标记使得语言模型在推理阶段具备可控性,使其能够根据不同的任务要求调整自身行为。
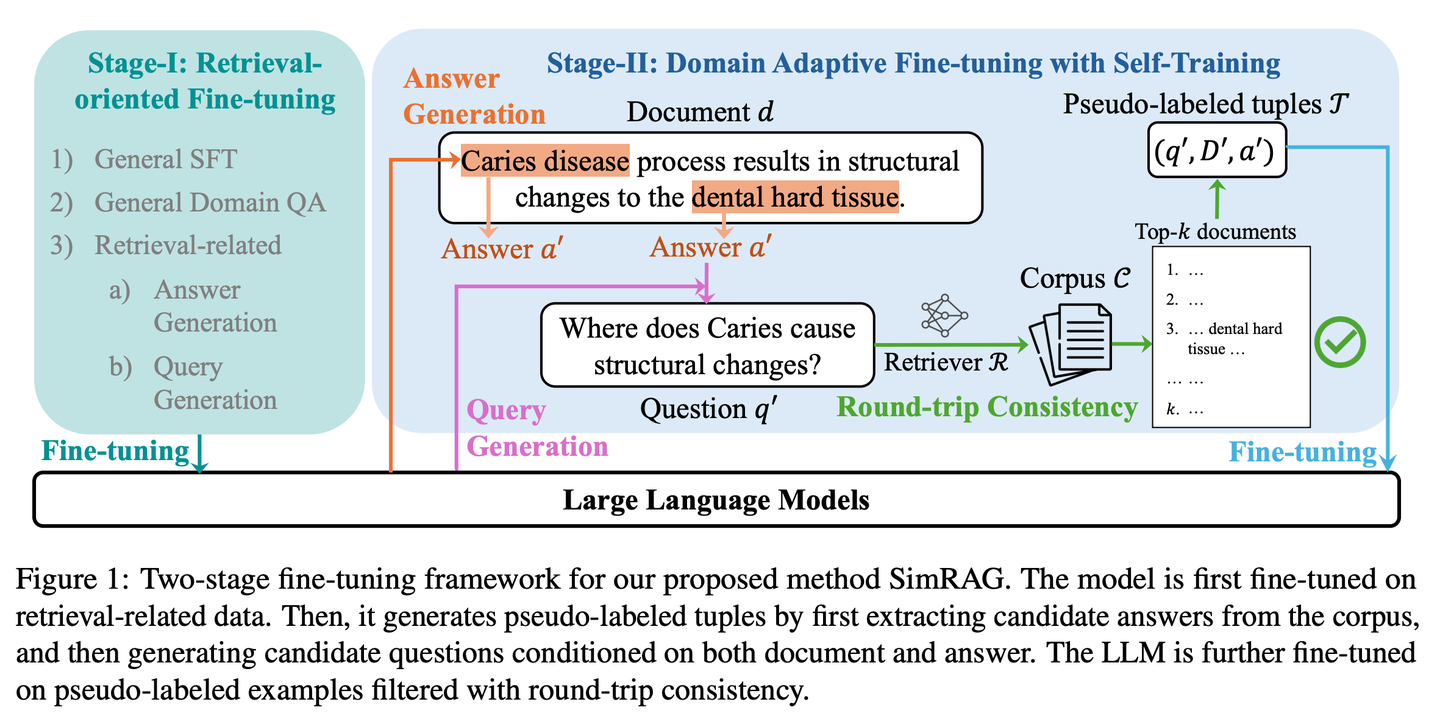
(59) SimRAG【自学成才】
自学成才
:面对专业领域时,先自己提问再自己回答,通过不断练习来提升专业知识储备,就像学生通过反复做习题来熟悉专业知识一样。
- 时间:10.23
- 论文:
SimRAG: Self-Improving Retrieval-Augmented Generation for Adapting Large Language Models to Specialized Domains - 参考:
https://mp.weixin.qq.com/s/pR-W_bQEA4nM86YsVTThtA
SimRAG是一种自训练方法,使LLM具备问答和问题生成的联合能力以适应特定领域。只有真正理解了知识,才能提出好的问题。这两个能力相辅相成,可以帮助模型更好地理解专业知识。首先在指令遵循、问答和搜索相关数据上对LLM进行微调。然后,它促使同一LLM从无标签语料库中生成各种与领域相关的问题,并采用额外的过滤策略来保留高质量的合成示例。通过利用这些合成示例,LLM可以提高其在特定领域RAG任务上的性能。
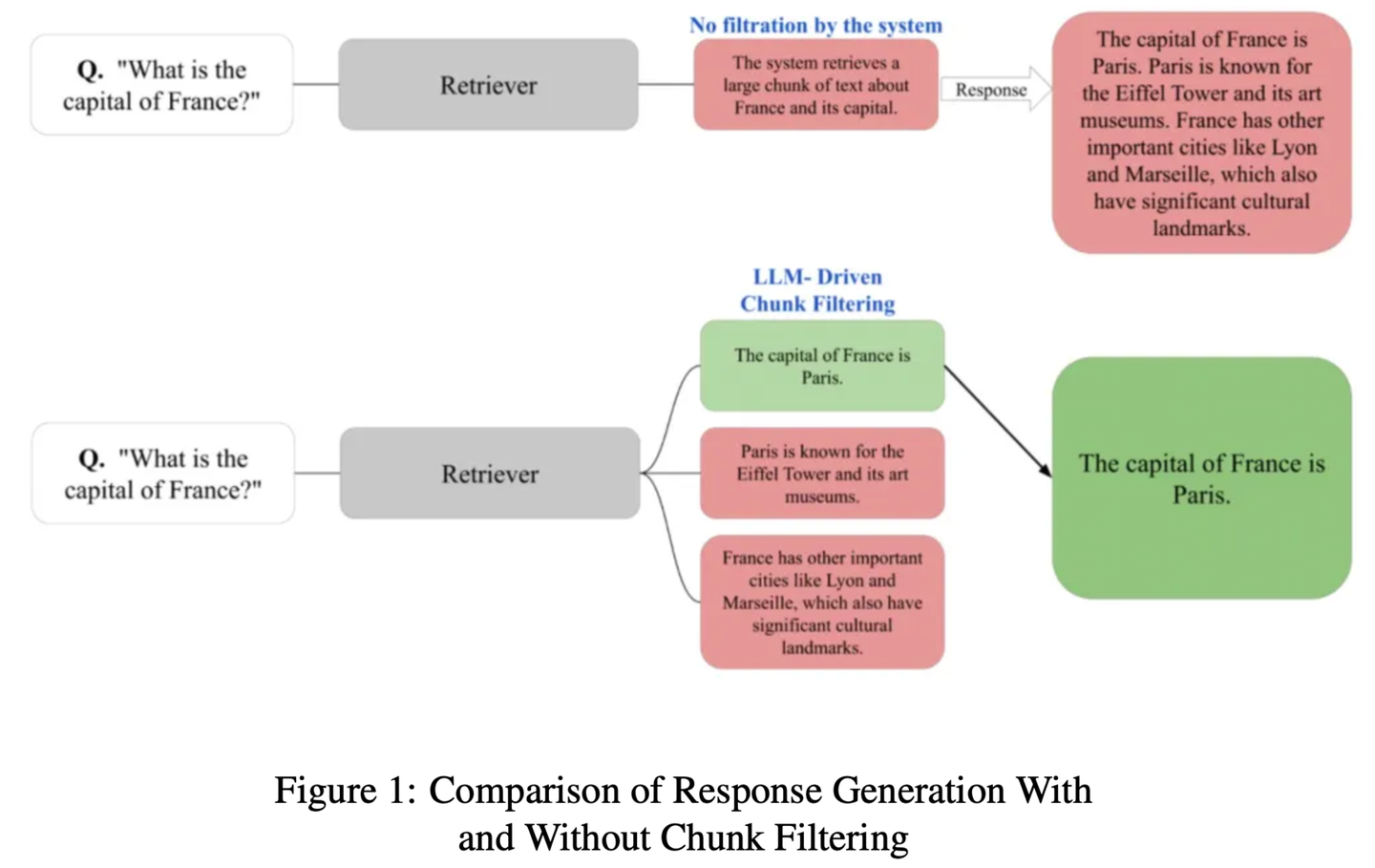
(60) ChunkRAG【摘抄达人】
摘抄达人
:先把长文章分成小段落,再用专业眼光挑出最相关的片段,既不遗漏重点,又不被无关内容干扰。
- 时间:10.23
- 论文:
ChunkRAG: Novel LLM-Chunk Filtering Method for RAG Systems - 参考:
https://mp.weixin.qq.com/s/Pw7_vQ9bhdDFTmoVwxGCyg
ChunkRAG提出LLM驱动的块过滤方法,通过在块级别评估和过滤检索到的信息来增强RAG系统的框架,其中 “块” 代表文档中较小的连贯部分。我们的方法采用语义分块将文档划分为连贯的部分,并利用基于大语言模型的相关性评分来评估每个块与用户查询的匹配程度。通过在生成阶段之前过滤掉不太相关的块,我们显著减少了幻觉并提高了事实准确性。
(61) FastGraphRAG【雷达】
雷达
:像谷歌网页排名一样,给知识点也排出个热度榜。就好比社交网络中的意见领袖,越多人关注就越容易被看见。它不是漫无目的地搜索,而是像个带着雷达的侦察兵,哪里的信号强就往哪里看。
- 时间:10.23
- 项目:
https://github.com/circlemind-ai/fast-graphrag - 参考:
https://mp.weixin.qq.com/s/uBcYaO5drTUabcCXh3bzjA
FastGraphRAG提供了一个高效、可解释且精度高的快速图检索增强生成(FastGraphRAG)框架。它将PageRank算法应用于知识图谱的遍历过程,快速定位最相关的知识节点。通过计算节点的重要性得分,PageRank使GraphRAG能够更智能地筛选和排序知识图谱中的信息。这就像是为GraphRAG装上了一个"重要性雷达",能够在浩如烟海的数据中快速定位关键信息。
(62) AutoRAG【调音师】
调音师
:一位经验丰富的调音师,不是靠猜测调音,而是通过科学测试找到最佳音效。它会自动尝试各种RAG组合,就像调音师测试不同的音响设备搭配,最终找到最和谐的"演奏方案"。
- 时间:10.28
- 论文:
AutoRAG: Automated Framework for optimization of Retrieval Augmented Generation Pipeline - 项目:
https://github.com/Marker-Inc-Korea/AutoRAG_ARAGOG_Paper - 参考:
https://mp.weixin.qq.com/s/96r6y3cNmLRL2Z0W78X1OQ
AutoRAG框架能够自动为给定数据集识别合适的RAG模块,并探索和逼近该数据集的RAG模块的最优组合。通过系统评估不同的RAG设置来优化技术选择,该框架类似于传统机器学习中的AutoML实践,通过广泛实验来优化RAG技术的选择,提高RAG系统的效率和可扩展性。
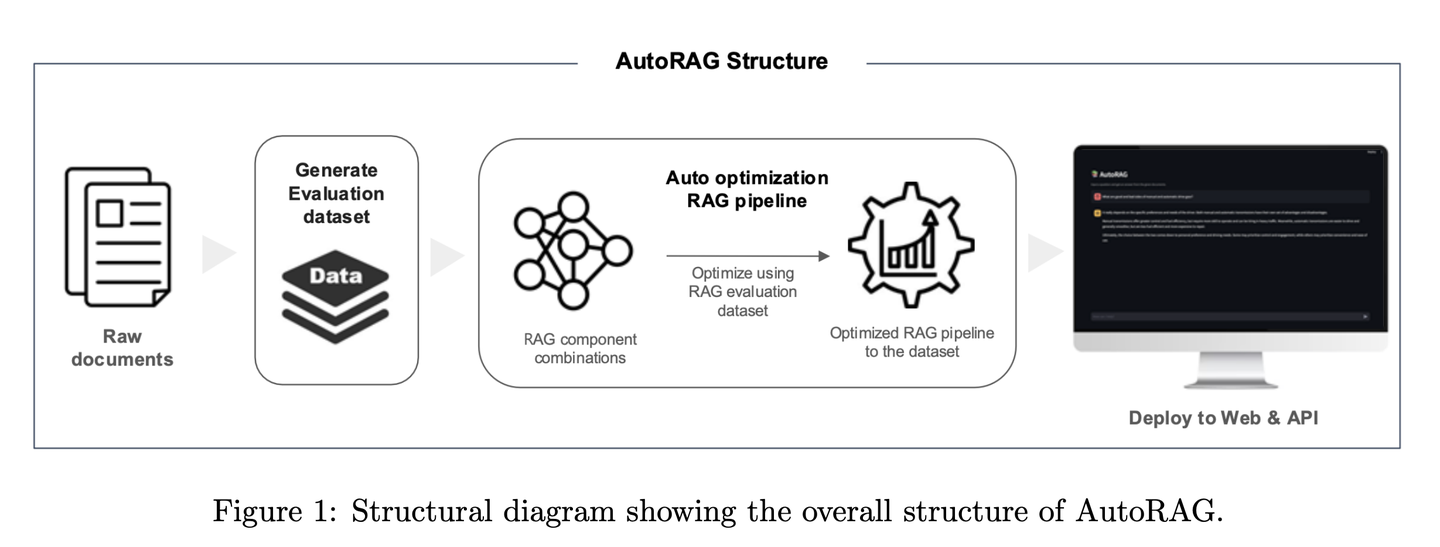
(63) Plan×RAG【项目经理】
项目经理
:先规划后行动,把大任务分解成小任务,安排多个"专家"并行工作。每个专家负责自己的领域,最后由项目经理统筹汇总结果。这种方式不仅更快、更准,还能清楚交代每个结论的来源。
- 时间:10.28
- 论文:
Plan×RAG: Planning-guided Retrieval Augmented Generation - 参考:
https://mp.weixin.qq.com/s/I_-NDGzd7d8l4zjRfCsvDQ
Plan×RAG是一个新颖的框架,它将现有RAG框架的 “检索 - 推理” 范式扩充为 “计划 - 检索”范式。Plan×RAG 将推理计划制定为有向无环图(DAG),将查询分解为相互关联的原子子查询。答案生成遵循 DAG 结构,通过并行检索和生成显著提高效率。虽然最先进的RAG解决方案需要大量的数据生成和语言模型(LMs)的微调,但Plan×RAG纳入了冻结的LMs作为即插即用的专家来生成高质量的答案。
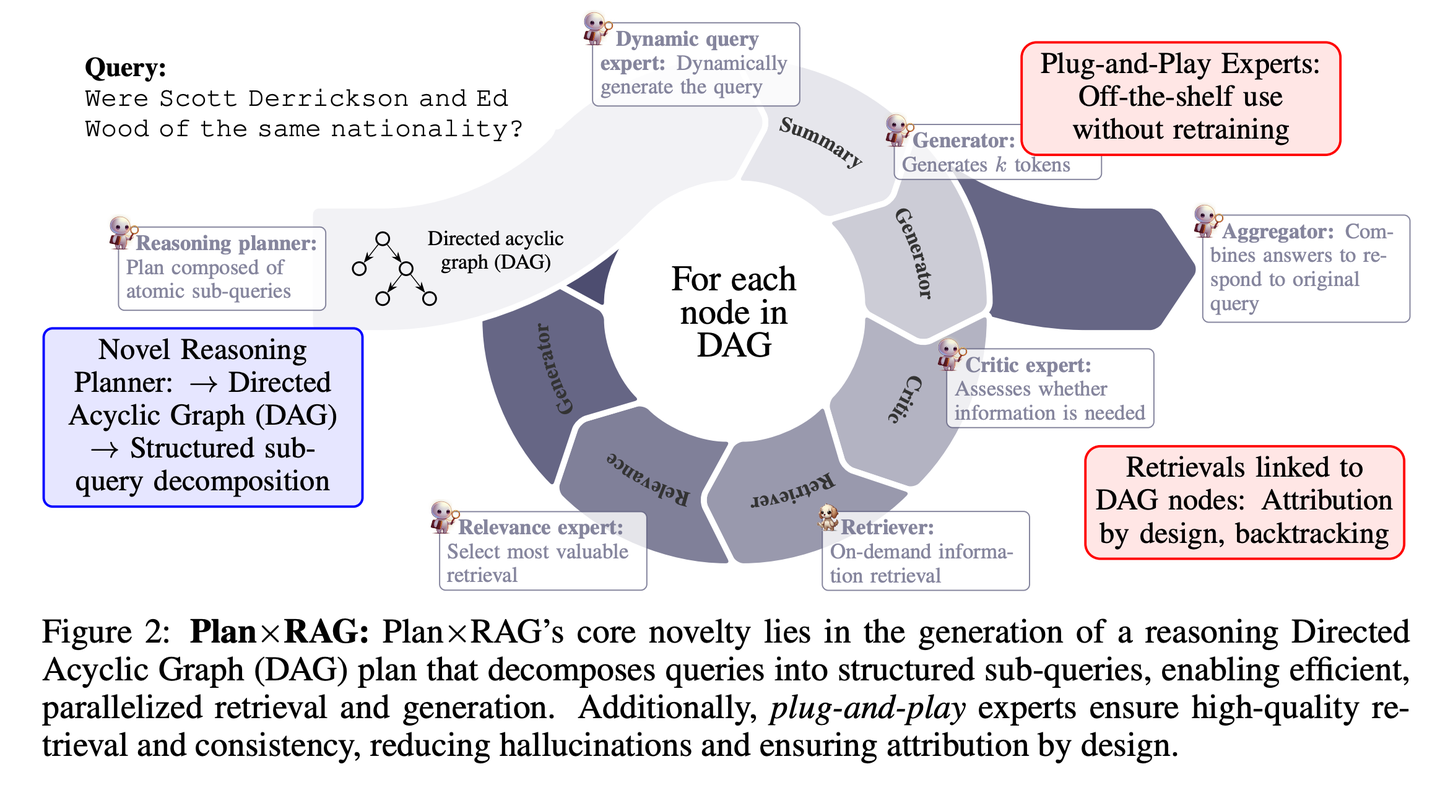
(64) SubgraphRAG【定位仪】
定位仪
:不是漫无目的地大海捞针,而是精准绘制一张小型知识地图,让 AI 能快速找到答案。
- 时间:10.28
- 论文:
Simple is Effective: The Roles of Graphs and Large Language Models in Knowledge-Graph-Based Retrieval-Augmented Generation - 项目:
https://github.com/Graph-COM/SubgraphRAG - 参考:
https://mp.weixin.qq.com/s/ns22XLKsABly7RjpSjQ_Fw
SubgraphRAG扩展了基于KG的RAG框架,通过检索子图并利用LLM进行推理和答案预测。将轻量级多层感知器与并行三元组评分机制相结合,以实现高效灵活的子图检索,同时编码有向结构距离以提高检索有效性。检索到的子图大小可以灵活调整,以匹配查询需求和下游LLM的能力。这种设计在模型复杂性和推理能力之间取得了平衡,实现了可扩展且通用的检索过程。
2024.11
(65) RuRAG【炼金术士】
炼金术士
:像个炼金术士,能将海量数据提炼成清晰的逻辑规则,并用通俗易懂的语言表达出来,让AI在实际应用中更有智慧。
- 时间:11.04
- 论文:
RuAG: Learned-rule-augmented Generation for Large Language Models - 参考:
https://mp.weixin.qq.com/s/A4vjN1eJr7hJd75UH0kuXA
旨在通过将大量离线数据自动蒸馏成可解释的一阶逻辑规则,并注入大型语言模型(LLM)中,以提升其推理能力。该框架使用蒙特卡洛树搜索(MCTS)来发现逻辑规则,并将这些规则转化为自然语言,实现针对LLM下游任务的知识注入和无缝集成。该论文在公共和私有工业任务上评估了该框架的有效性,证明了其在多样化任务中增强LLM能力的潜力。
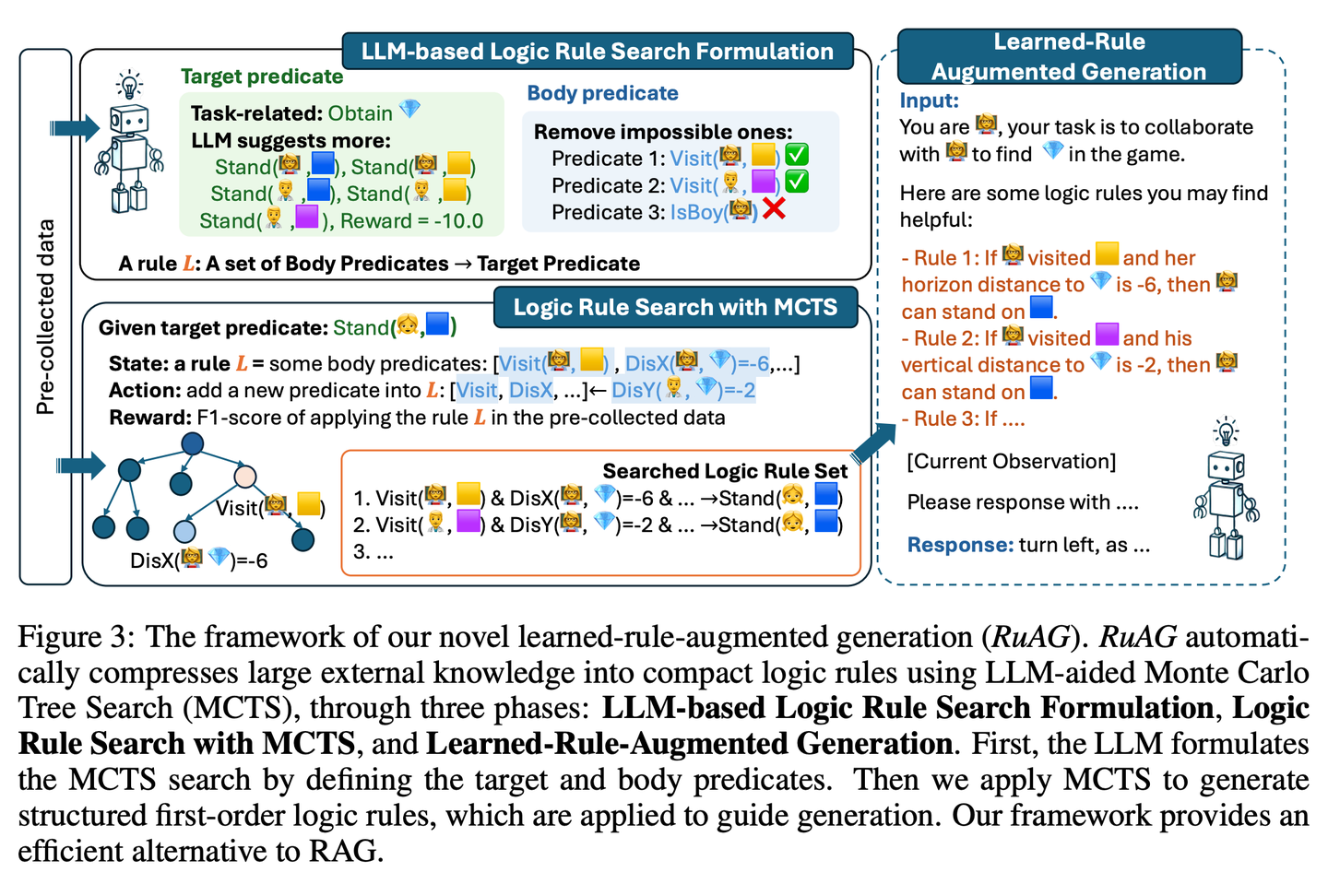
(66) RAGViz【透视眼】
透视眼
:让RAG系统变透明,看得见模型在读哪句话,像医生看X光片一样,哪里不对一目了然。
- 时间:11.04
- 论文:
RAGViz: Diagnose and Visualize Retrieval-Augmented Generation - 项目:
https://github.com/cxcscmu/RAGViz - 参考:
https://mp.weixin.qq.com/s/ZXvAWDhqKRPq1u9NTfYFnQ
RAGViz提供了对检索文档和模型注意力的可视化,帮助用户理解生成的标记与检索文档之间的交互,可用于诊断和可视化RAG系统。

(67) AgenticRAG【智能助手】
智能助手
:不再是简单的查找复制,而是配了个能当机要秘书的助手。像个得力的行政官,不光会查资料,还知道什么时候该打电话,什么时候该开会,什么时候该请示领导。
- 时间:11.05
- 参考:
https://mp.weixin.qq.com/s/Sa6vtb1pDKo1we1cSMn9oQ
AgenticRAG描述了基于AI智能体实现的RAG。具体来说,它将AI智能体纳入RAG流程中,以协调其组件并执行超出简单信息检索和生成的额外行动,以克服非智能体流程的局限性。
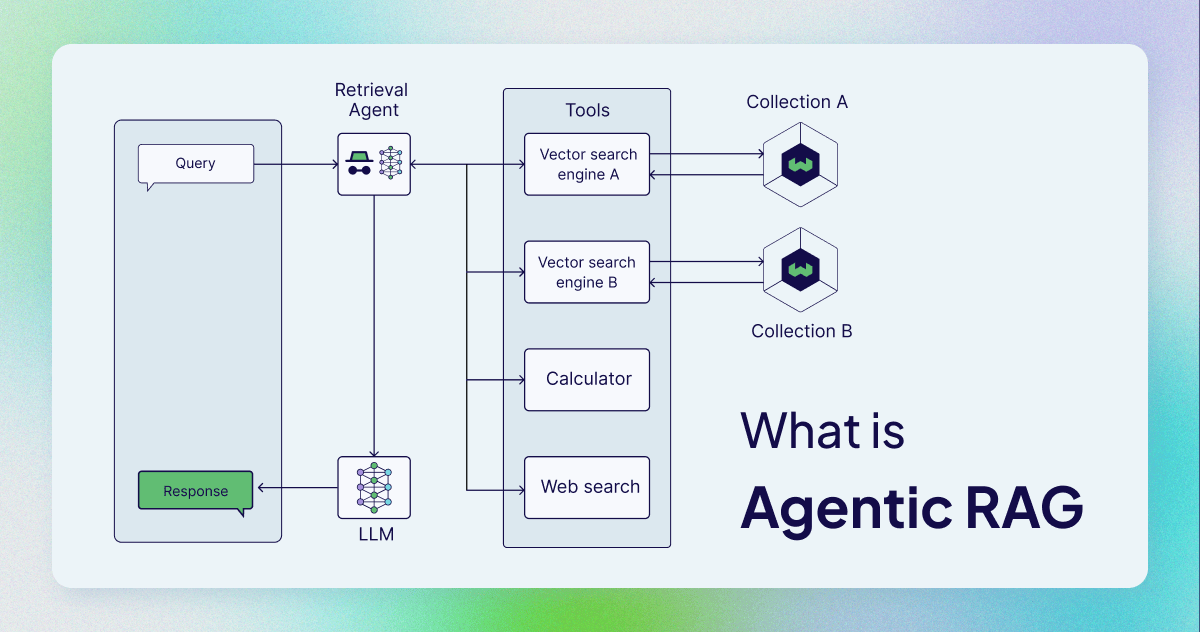
(68) HtmlRAG【排版师】
排版师
:把知识不是当作流水账来记,而是像排版杂志一样,该加粗的加粗,该标红的标红。就像一个挑剔的美编,觉得光有内容不够,还得讲究排版,这样重点才能一目了然。
- 时间:11.05
- 论文:
HtmlRAG: HTML is Better Than Plain Text for Modeling Retrieved Knowledge in RAG Systems - 项目:
https://github.com/plageon/HtmlRAG - 参考:
https://mp.weixin.qq.com/s/1X6k9QI71BIyQ4IELQxOlA
HtmlRAG在RAG中使用HTML而不是纯文本作为检索知识的格式,在对外部文档中的知识进行建模时,HTML比纯文本更好,并且大多数LLM具有强大的理解HTML的能力。HtmlRAG提出了HTML清理、压缩和修剪策略,以缩短HTML同时最小化信息损失。
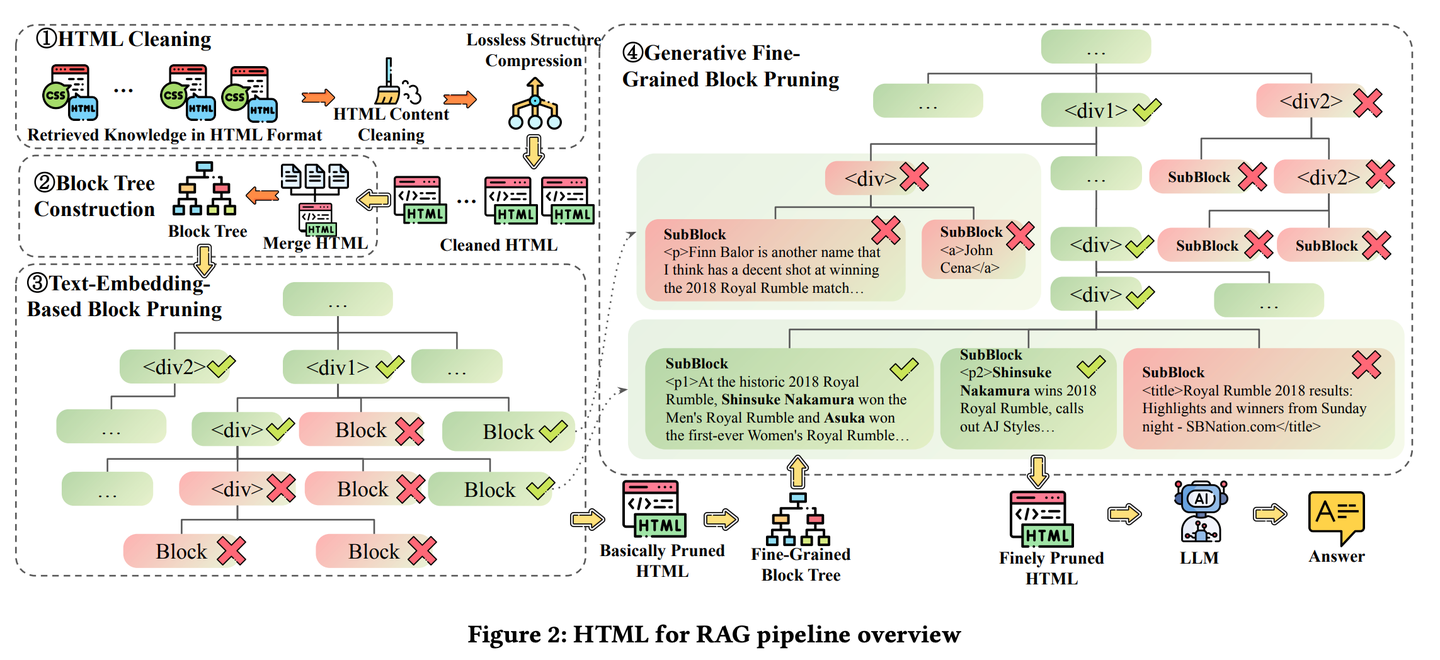
(69) M3DocRAG【感官达人】
感官达人
:不是只会读书,还能看图识图,听声辨位。像个综艺节目里的全能选手,图片能看懂,文字能理解,该跳跃思维时就跳跃,该专注细节时就专注,各种挑战都难不倒。
- 时间:11.07
- 论文:
M3DocRAG: Multi-modal Retrieval is What You Need for Multi-page Multi-document Understanding - 参考:
https://mp.weixin.qq.com/s/a9tDj6BmIZHs2vTFXKSPcA
M3DocRAG是一种新颖的多模态RAG框架,能够灵活适应各种文档上下文(封闭域和开放域)、问题跳转(单跳和多跳)和证据模式(文本、图表、图形等)。M3DocRAG使用多模态检索器和MLM查找相关文档并回答问题,因此它可以有效地处理单个或多个文档,同时保留视觉信息。
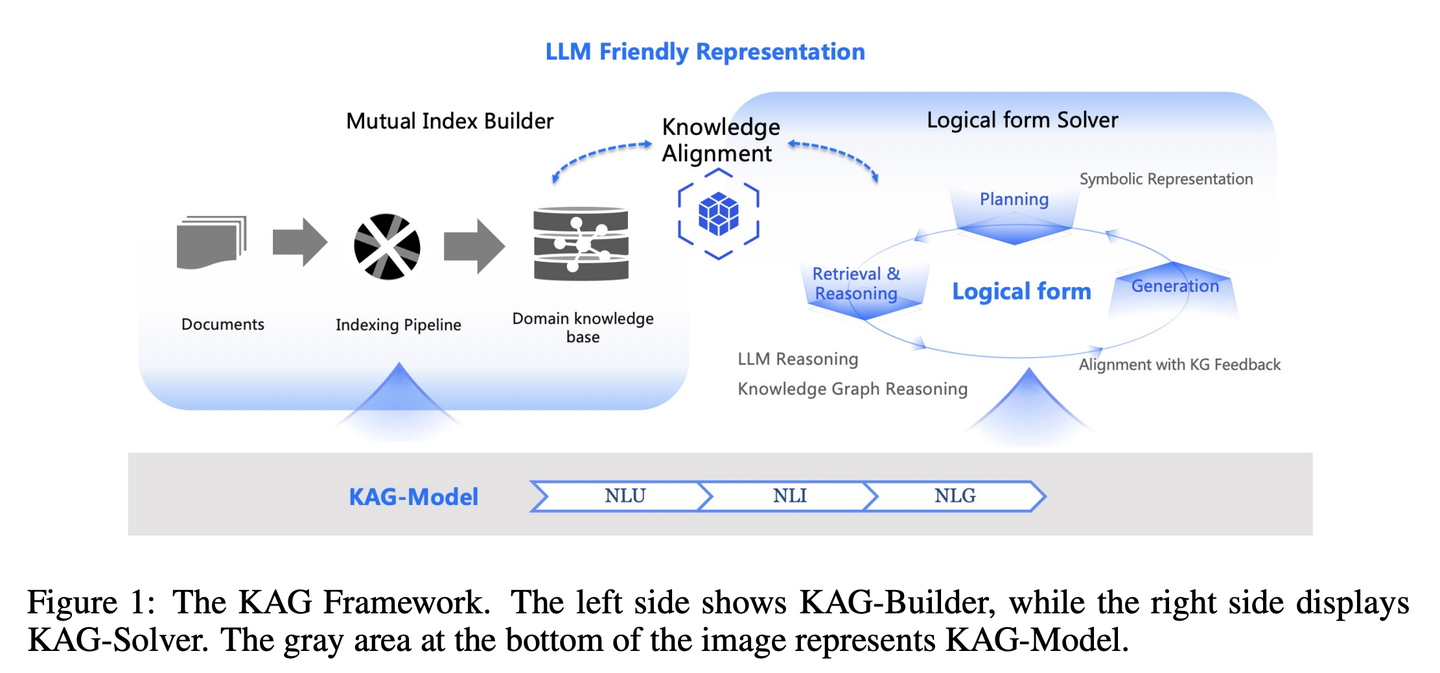
(70) KAG【逻辑大师】
逻辑大师
:不光靠感觉找相似的答案,还得讲究知识间的因果关系。像个严谨的数学老师,不仅要知道答案是什么,还得解释清楚这答案是怎么一步步推导出来的。
- 时间:11.10
- 论文:
KAG: Boosting LLMs in Professional Domains via Knowledge Augmented Generation - 项目:
https://github.com/OpenSPG/KAG - 参考:
https://mp.weixin.qq.com/s/oOzFBHS_B7FST6YKynD1GA
RAG中向量相似性与知识推理的相关性之间的差距,以及对知识逻辑(如数值、时间关系、专家规则等)不敏感阻碍了专业知识服务的有效性。KAG的设计目的是充分利用知识图谱(KG)和向量检索的优势来应对上述挑战,并通过五个关键方面双向增强大型语言模型(LLM)和知识图谱来提高生成和推理性能:(1)对LLM友好的知识表示,(2)知识图谱与原始块之间的相互索引,(3)逻辑形式引导的混合推理引擎,(4)与语义推理的知识对齐,(5)KAG的模型能力增强。
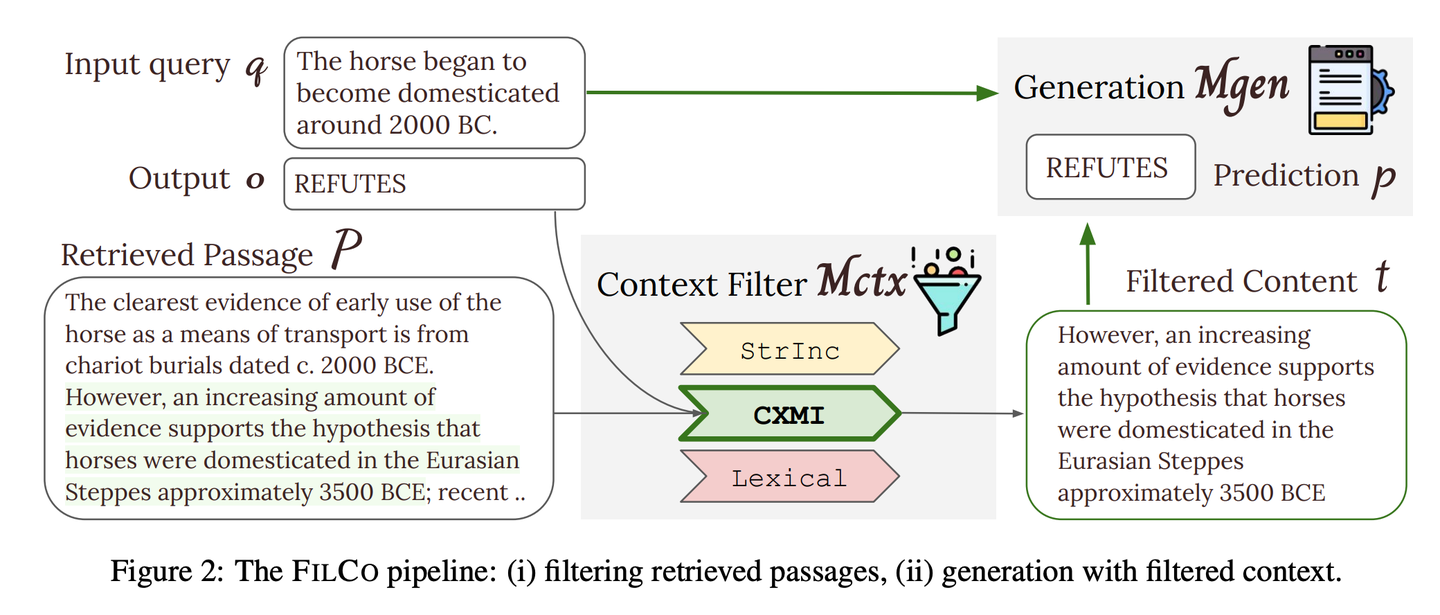
(71) FILCO【筛选师】
筛选师
:像个严谨的编辑,善于从大量文本中识别并保留最有价值的信息,确保传递给AI的每段内容都精准且相关。
- 时间:11.14
- 论文:
Learning to Filter Context for Retrieval-Augmented Generation - 项目:
https://github.com/zorazrw/filco - 参考:
https://mp.weixin.qq.com/s/93CdvD8FLZjaA7E724bf7g
FILCO通过基于词法和信息论方法识别有用的上下文,以及训练上下文过滤模型,以过滤检索到的上下文,来提高提供给生成器的上下文质量。
(72) LazyGraphRAG【精算师】
精算师
:能省一步是一步,把贵的大模型用在刀刃上。就像个会过日子的主妇,不是看到超市打折就买,而是货比三家后才决定在哪里花钱最值。
- 时间:11.25
- 项目:
https://github.com/microsoft/graphrag - 参考:
https://mp.weixin.qq.com/s/kDUcg5CzRcL7lTGllv-GKA
一种新型的图谱增强生成增强检索(RAG)方法。这种方法显著降低了索引和查询成本,同时在回答质量上保持或超越竞争对手,使其在多种用例中具有高度的可扩展性和高效性。LazyGraphRAG推迟了对LLM的使用。在索引阶段,LazyGraphRAG仅使用轻量级的NLP技术来处理文本,将LLM的调用延迟到实际查询时。这种“懒惰”的策略避免了前期高昂的索引成本,实现了高效的资源利用。
| 传统GraphRAG | LazyGraphRAG | |
|---|---|---|
| 索引阶段 | - 使用LLM提取并描述实体和关系 - 为每个实体和关系生成摘要 - 利用LLM总结社区内容 - 生成嵌入向量 - 生成Parquet文件 |
- 使用NLP技术提取概念和共现关系 - 构建概念图 - 提取社区结构 - 索引阶段不使用LLM |
| 查询阶段 | - 直接使用社区摘要回答查询 - 缺乏对查询的细化和对相关信息的聚焦 |
- 使用LLM细化查询并生成子查询 - 根据相关性选择文本片段和社区 - 使用LLM提取和生成答案 - 更加聚集于相关内容,回答更精确 |
| LLM调用 | - 在索引阶段和查询阶段都大量使用 | - 在索引阶段不使用LLM - 仅在查询阶段调用LLM - LLM的使用更加高效 |
| 成本效率 | - 索引成本高,耗时长 - 查询性能受限于索引质量 |
- 索引成本仅为传统GraphRAG的0.1% - 查询效率高,答案质量好 |
| 数据存储 | - 索引数据生成 Parquet 文件,适合大规模数据的存储和处理 | - 索引数据存储为轻量级格式(如 JSON、CSV),更适合快速开发和小规模数据 |
| 使用场景 | - 适用于对计算资源和时间不敏感的场景 - 需要提前构建完整的知识图谱,并存储为Parquet文件,方便后续导入数据库进行复杂分析 |
- 适用于需要快速索引和响应的场景 - 适合一次性查询、探索性分析和流式数据处理 |
RAG Survey
- A Survey on Retrieval-Augmented Text Generation
- Retrieving Multimodal Information for Augmented Generation: A Survey
- Retrieval-Augmented Generation for Large Language Models: A Survey
- Retrieval-Augmented Generation for AI-Generated Content: A Survey
- A Survey on Retrieval-Augmented Text Generation for Large Language Models
- RAG and RAU: A Survey on Retrieval-Augmented Language Model in Natural Language Processing
- A Survey on RAG Meeting LLMs: Towards Retrieval-Augmented Large Language Models
- Evaluation of Retrieval-Augmented Generation: A Survey
- Retrieval-Augmented Generation for Natural Language Processing: A Survey
- Graph Retrieval-Augmented Generation: A Survey
- A Comprehensive Survey of Retrieval-Augmented Generation (RAG): Evolution, Current Landscape and Future Directions
- Retrieval Augmented Generation (RAG) and Beyond: A Comprehensive Survey on How to Make your LLMs use External Data More Wisely
RAG Benchmark
- Benchmarking Large Language Models in Retrieval-Augmented Generation
- RECALL: A Benchmark for LLMs Robustness against External Counterfactual Knowledge
- ARES: An Automated Evaluation Framework for Retrieval-Augmented Generation Systems
- RAGAS: Automated Evaluation of Retrieval Augmented Generation
- CRUD-RAG: A Comprehensive Chinese Benchmark for Retrieval-Augmented Generation of Large Language Models
- FeB4RAG: Evaluating Federated Search in the Context of Retrieval Augmented Generation
- CodeRAG-Bench: Can Retrieval Augment Code Generation?
- Long
2
RAG: Evaluating Long-Context & Long-Form Retrieval-Augmented Generation with Key Point Recall