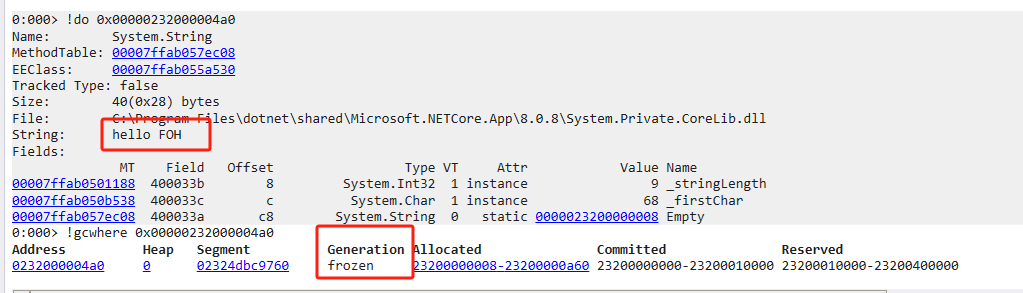
全面解读TaurusDB透明压缩特性,降低数据库使用成本
本文分享自华为云社区
《【华为云MySQL技术专栏】TaurusDB透明压缩》
,作者: GaussDB 数据库。

背景介绍
某一部分特定比例的客户群体,对数据库的读写性能要求并不高。相比之下,他们反而更关注数据写入磁盘时的压缩能力,通过减小存储空间,来降低数据库的使用成本。
TaurusDB透明压缩特性就是通过在存储过程中引入轻微延迟,换取更小的存储空间,进而满足客户降低存储成本的需求。
本文主要从透明压缩特性的使用开启方法、实现原理、性能优化以及性能影响评估等这几个方面来进行介绍。
使用方法
新实例的来源分为两种:一种是通过主界面上的“创建实例”生成新实例,另一种是通过已有实例的备份恢复来创建一个新实例。
第一种创建新实例的方式,如图1所示,需要通过选择“存储压缩”选项开启。

新实例开启透明压缩
图1中,压缩实例的开启选项包括高压缩比和高压缩速度两种模式。高压缩比和高压缩速度分别指使用ZSTD压缩算法和LZ4压缩算法两种不同方式进行压缩。其中,高压缩比采用ZSTD压缩算法,能实现约2.1倍的压缩效率;而高压缩速度则运用LZ4压缩算法,其压缩比约为1.35倍。相较于ZSTD算法,LZ4算法对系统性能的影响较小。对于性能要求不高的用户而言,选择高压缩比模式能更有效地节省存储空间。
在备份恢复到新实例的场景中,如图2所示,压缩特性支持两种恢复方式: 一种是将非压缩存量实例,恢复到非压缩已有实例中;另一种是将压缩存量实例,恢复到压缩已有实例中。

压缩实例的备份恢复限制
在未来的透明压缩增强计划中,会提供支持将非压缩存量实例,恢复为压缩实例的功能。
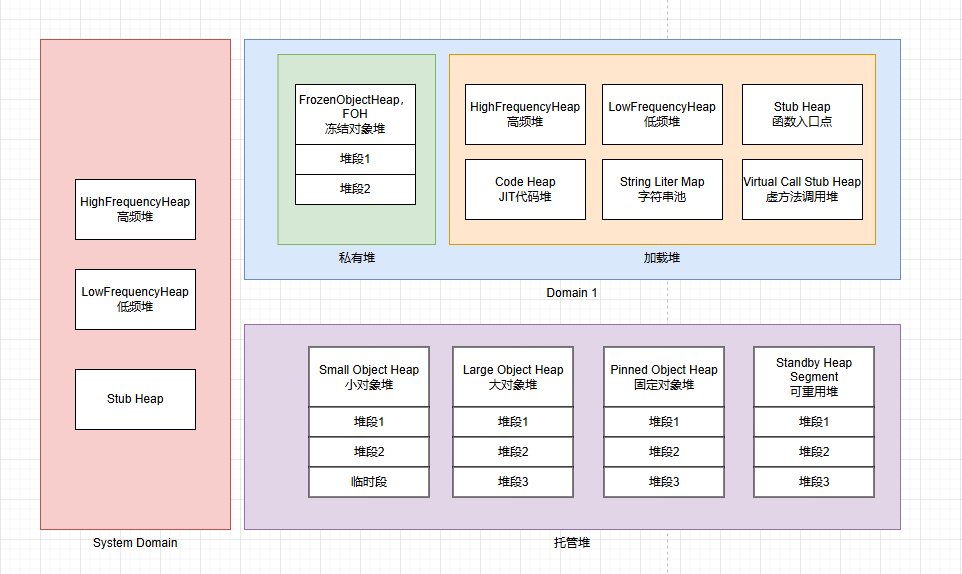
原理介绍
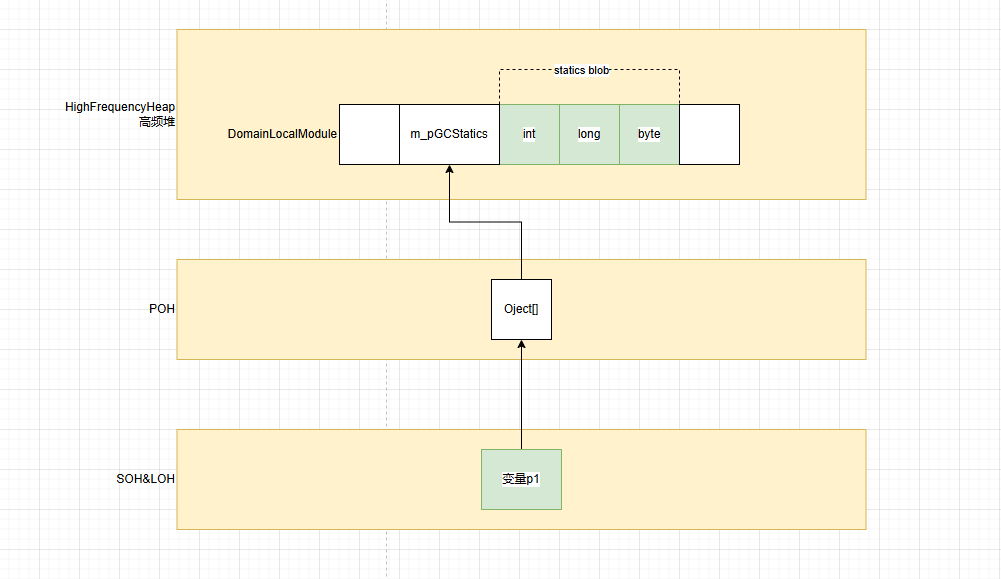
透明压缩是一种通过页级别的粒度进行压缩和解压的技术。下面将分别介绍写入和读取页的对应流程。图3展示了压缩特性是如何与写入页的操作相适配的。

压缩实例与写入页的适配
在数据需要刷新到页上时,系统会调用flushByPageFlusher函数。该函数的底层实现是通过Ulog对secondary stream进行append操作,同时对页进行压缩处理,从而实现页级别的压缩能力。Ulog是TaurusDB存储底层提供的IO模型,它构成了数据库的数据存储单元。而secondary stream实际上是由Ulog组成的,它存储着数据库页面基本结构的信息。通过解析Ulog后的压缩字段,可以判断页面是否已被压缩,以及具体采用了哪种压缩方式。
与此相对对应的读取页面,也是类似,其流程如图4所示:

压缩实例与读取页的适配
在读取页面时,调用了slice侧的readPages函数,实际上是触发了Ulog的readInternalSync功能。在解析plog(构成ulog的基本存储单元)时,会存在两种场景:
1)如果plog header中的压缩字段为0,则表示该页面未经压缩,因此无需处理。
2)如果plog header中的压缩字段标记为LZ4/ZSTD,则说明该页已经过压缩,需要使用相应的LZ4/ZSTD算法进行解压缩。解压缩后即可获取所需的未压缩页面,其数据的读取结果与未压缩的页面相同。
然而,上述压缩特性存在一个明显问题,即在slice侧环境压力较大的情况下,压缩或解压缩都会占用一定的系统资源。特别是在高并发情况下,这可能会对slice侧造成严重的资源占用问题。
资源限制
为了解决可能因压缩和解压缩过程导致的资源问题,透明压缩特性采用线程队列和线程池来限制压缩操作对资源的占用。这样,即使在存储池压力极大的极端情况下,压缩操作也不会过多消耗资源。其中,页持久化压缩操作的处理方法,如图5所示。

页持久化时进行压缩处理
具体流程如下:
1)在初始化LRU线程队列LRUList时,压缩实例会生成一个压缩线程池。
2)当LRU页面需要被置换并且需要落盘时,会调用addPage方法,将需要压缩的页面放入压缩线程池队列compressDirty2Queue中,并有序地进行压缩操作。
3)当LRU队列出队时,我们进行真正的落盘操作,是通过调用flushByPageFlusher接口来实现最终的落盘。
从功能的角度来看,通过使用线程池有效地控制了压缩页操作的资源,从而实现了对刷盘性能的可控管理。
同样地,读取数据的流程也遵循了类似的资源限制设计原则,如图6所示:

读取压缩页进行解压缩处理
在初始化阶段,我们创建了ulog线程池,并同步创建了压缩处理线程池。当系统需要读取压缩页时,会利用在初始化阶段通过readCallback回调函数申请的压缩线程来执行读取操作。通过利用线程池的约束机制,我们成功地在资源受限的环境下实现了压缩页面的读取功能。
通过上述所述的方法,结合图5和图6所展示的流程,在确保资源消耗可控的前提下,成功实现了页面级别的读写透明压缩能力。
性能分析
使用sysbench工具来模拟真实业务大压力场景,以此评估压缩对业务TPS(交易处理速度)/QPS(查询处理速度)的影响。
场景一:测试LZ4高压缩速度算法,对业务TPS/QPS的影响
在硬件配置相同的8核32G内存机器上,对压缩和非压缩实例进行了sysbench测试。测试采用了64个表,每个表包含1000万条数据,来模拟大数据量的实际业务场景。测试过程中,分别在1到512个线程下,使用LZ4压缩算法,并记录不同模式下的QPS/TPS数值变化。结果如图7所示:

8U32G机器上采用高压缩速度(LZ4)性能影响
可以观察到,在最坏的情况下,根据TPS/QPS指标来衡量,性能下降不超过5%。
场景二:测试ZSTD高压缩比算法,对业务TPS/QPS的影响
同样,使用相同配置的8核32G内存的机器,在该机器上对压缩和非压缩实例进行了sysbench测试。测试采用了64个表,每个表包含1000万条数据,来模拟一个大数据量的sysbench测试模型。
通过进行压力测试实验,在1到512个线程的不同情况下,使用ZSTD压缩算法,记录QPS/TPS数值变化,如图8所示:

8U32G机器上采用高压缩比(ZSTD)性能影响
根据实验结果可以明确地观察到,相较于LZ4算法,ZSTD算法对性能的影响更为显著。从QPS/TPS的角度来看,在最糟糕的情况下,性能影响控制在10%以内。高压缩比意味着该算法具备更强的空间压缩能力,但同时也会给性能带来较大的影响。
总结
本文全面介绍了TaurusDB透明压缩特性。首先,介绍了用户如何通过界面开启压缩实例,并说明了如何实现页面级别的压缩能力。同时,针对压缩特性可能带来的资源占用问题,我们讨论了利用线程池进行优化的方法。
最后,通过一系类性能测试结果,展示了在高压缩速度和高压缩比两种场景下的压缩特性表现。具体而言,在使用高压缩速度的LZ4压缩模式时,其性能劣化控制在5%以内,对性能较敏感的用户,提供了一种既能节约空间又不显著影响性能的解决方案。而高压缩比的ZSTD模式则在空间上更加节省,性能劣化控制亦可控制在10%以内,更适用于对性能不敏感但希望大幅节约空间成本的客户群体。
华为开发者空间,汇聚鸿蒙、昇腾、鲲鹏、GaussDB、欧拉等各项根技术的开发资源及工具,致力于为每位开发者提供一台云主机、一套开发工具及云上存储空间,让开发者基于华为根生态创新。
点击链接
,免费领取您的专属云主机