重磅推出 Sdcb Chats:一个全新的开源大语言模型前端
重磅推出 Sdcb Chats:一个全新的开源大语言模型前端
在当前大语言模型(LLM)蓬勃发展的时代,各类 LLM 前端层出不穷。那么,
为什么我们还需要另一个 LLM 前端呢?
最初的原因在于
质感的追求
。市面上已有的开源或不开源的大语言模型前端在用户体验上都缺少了一些类似 ChatGPT 那样的质感。因此,我们打造了
Sdcb Chats
——一个基于 Apache 2.0 协议开源的项目,旨在为用户提供更优质的交互体验。
另一个原因是市场上几乎没有基于 .NET 实现的 LLM 前端,这让我个人感到非常遗憾和不满。
Sdcb Chats 旨在填补这个空白
,不仅为 .NET 社区带来一个功能强大的大语言模型前端,同时也展示 .NET 在现代 AI 应用中的潜力和优势。
消息内容即是一棵树
在与大语言模型交互时,传统的对话形式可能会导致用户与模型“争吵”。
Sdcb Chats 引入了树状消息结构
,即在同一位置,用户消息可以有多个回复,LLM 的响应也可以有多个。
这种设计的优势在于:
- 当您认为 LLM 的回复不正确时,您可以修改提示词(Prompt)或请求 LLM 重新回复,而不是继续争论。
- 提供了更灵活的对话路径,方便回溯和比较不同的回答。
(
动图1:Sdcb Chats 的主界面展示
)
如图,与其在聊完之后再与LLM争吵,不如修改Prompt。
遗憾的是,在我开发Chats之前,并没有一个开源的LLM前端支持这个功能,这也是促成我要重新再做一个的根本原因。
大语言模型功能篇
多语言支持

(
动图2:通过修改浏览器语言,Chats 支持多语言显示
)
Sdcb Chats 支持多语言界面
。您只需修改浏览器的语言设置,Chats 就会自动适配您的语言偏好,为全球用户提供便捷。
聊天性能统计
(
动图3:详细的聊天性能统计
)
每次与 LLM 的对话,
Chats 都会进行详尽的统计
,包括:
- Token 数量
- 延迟时间
- 返回次数
- 客户端 IP
- 用户代理(User Agent)
- 用户相关信息
这些数据有助于您日后进行分析和优化。
多种大语言模型支持

(
动图4:支持多种模型提供商,内置超过 100 款模型
)
Sdcb Chats 内置了对 9 种模型提供商的支持
,包括 OpenAI 兼容协议在内。此外,还预置了超过 100 款模型的信息,方便您快速使用。
支持配置新的大语言模型

(
动图5:演示如何新增 DeepSeek 和零一万物模型
)
如果预置的模型不能满足您的需求,您可以
自行添加新的模型配置
。在上述动图中,我们演示了如何添加 DeepSeek 和零一万物模型。
视觉模型支持

(
动图6:支持多模态视觉模型与图床功能
)
为了增强用户体验,
Chats 支持视觉模型
。我们为 Chats 添加了一层图床,方便上传和管理图片。支持的图床形式包括:
- 本地文件
- AWS S3
- Minio
- Azure Blob Storage
- 阿里云 OSS
API 网关功能
(
动图7:强大的 API 网关功能
)
很多开源项目声称兼容 OpenAI API 协议的 API 网关功能,但可能仅仅是 HTTP 协议的转发。
Chats 的 API 网关不仅支持按用户权限配置模型、限制模型量,还支持目的地为非 OpenAI 协议的模型提供商,进行透明代理
。
API 网关支持参数

(
动图8:全面支持 OpenAI API 的参数和功能
)
Chats 的 API 网关全面支持 OpenAI API 的所有参数
,包括最新的
max_response_tokens
(适用于最新的 OpenAI o1 模型)和
response_format=json_schema
等功能。此外,响应的结束原因等信息也会忠实于源 API 的响应,确保兼容性和准确性。
部署与兼容性
简单部署:Docker 支持
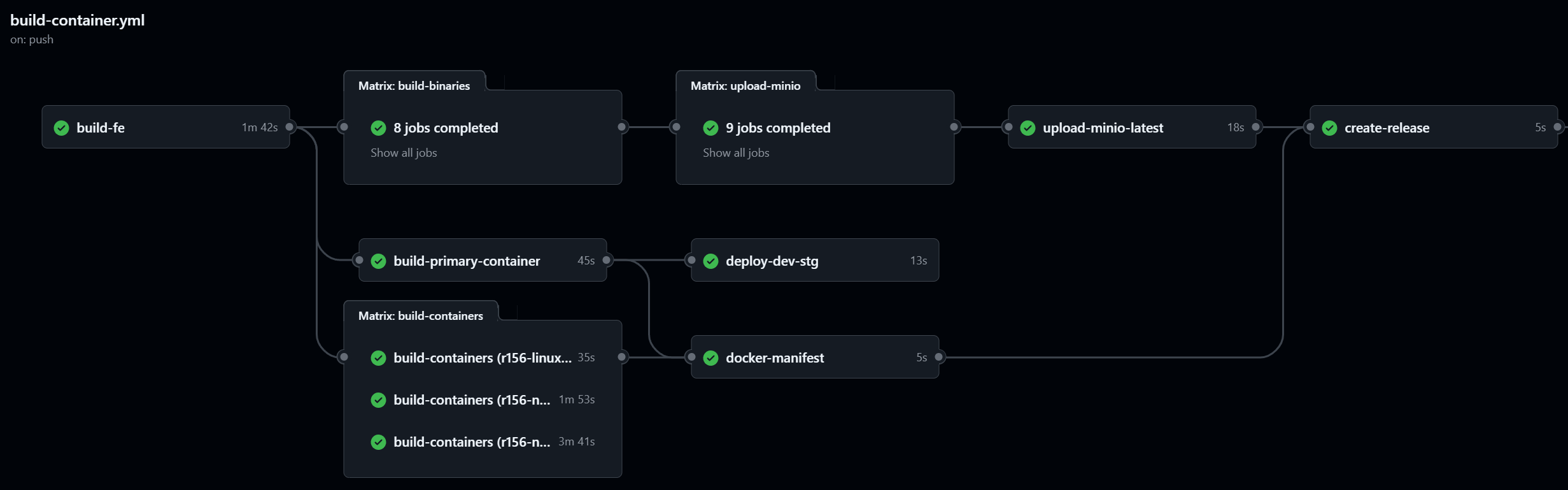
(
图片9:复杂的 GitHub Actions CICD 流程
)
Sdcb Chats 提供了便捷的 Docker 部署方式
。我们在 GitHub Actions 中编写了复杂的 CICD 流程,会自动编译包括 Windows、Linux 等 4 种不同操作系统的原生支持 Docker 镜像。
动态选择合适的 Docker 镜像
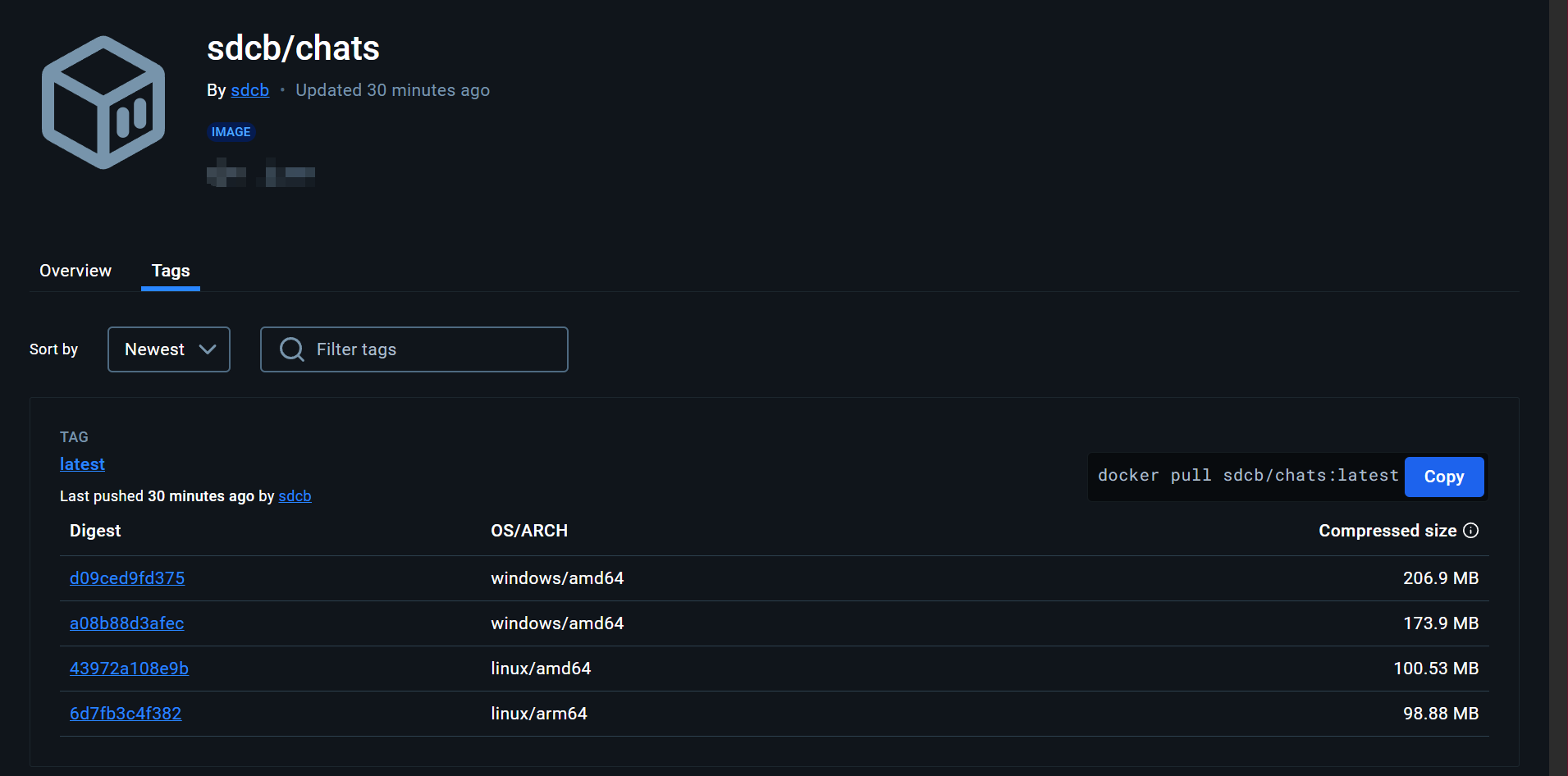
(
图片10:通过 manifest 部署的 Docker 标签
)
通过使用
docker.io/sdcb/chats:latest
这样的 Docker 标签,
Docker 会根据您的操作系统和平台架构(如 amd64、arm64 等)动态选择合适的 Docker 镜像下载
,这大大简化了部署流程。Chats 提供了以下几个镜像:
| 描述 | Docker 镜像 |
|---|---|
| Latest | docker.io/sdcb/chats:latest |
| r | docker.io/sdcb/chats:r |
| Linux x64 | docker.io/sdcb/chats:r{version}-linux-x64 |
| Linux ARM64 | docker.io/sdcb/chats:r{version}-linux-arm64 |
| Windows Nano Server 1809 | docker.io/sdcb/chats:r{version}-nanoserver-1809 |
| Windows Nano Server LTSC 2022 | docker.io/sdcb/chats:r{version}-nanoserver-ltsc2022 |
说明:
Latest
和
r{version}
镜像中已经包含了以下四个操作系统版本的支持:
- Linux x64
- Linux ARM64
- Windows Nano Server 1809(适用于 Windows Server 2019)
- Windows Nano Server LTSC 2022(适用于 Windows Server 2022)
因此,用户在使用
docker pull
时,无需指定具体的操作系统版本,Docker 的 manifest 功能会自动选择适合您系统的正确版本。这确保了用户能够轻松获取与其环境兼容的镜像,避免了选择错误镜像的风险。
请注意,
r{version}
中的
{version}
表示具体的版本号,例如
r141
(在编写文档时的最新版本号)。通过这种方式,您可以始终获取到最新或指定版本的最优匹配版本,确保部署的快速和可靠。
简单部署——Linux 容器演示
(
动图11:在 Linux 上部署 Chats,虽然图片是在Windows pwsh中演示,但我Docker Desktop启用的是Linux容器
)
在 Linux 上,您可以按照以下步骤轻松部署 Chats:
创建
AppData
文件夹并设置权限:mkdir ./AppData && chmod 777 ./AppData运行 Docker 命令:
docker run --restart unless-stopped --name sdcb-chats -v ./AppData:/app/AppData -p 8080:8080 sdcb/chats:latest
创建之后,默认的用户名为
chats
,默认密码为:
RESET!!!
,请注意,为了您的安全,请登录之后立即修改您的默认密码。
简单部署——Windows 容器演示

(
动图12:在 Windows 上部署 Chats
)
许多朋友可能不知道,
Windows 也有原生的 Docker
。Chats 支持在 Windows 上以进程隔离的方式部署 Docker,这与 Linux 的部署方式类似,但映射的目录变为了
C:\app\AppData
。
简单部署——可运行文件安装
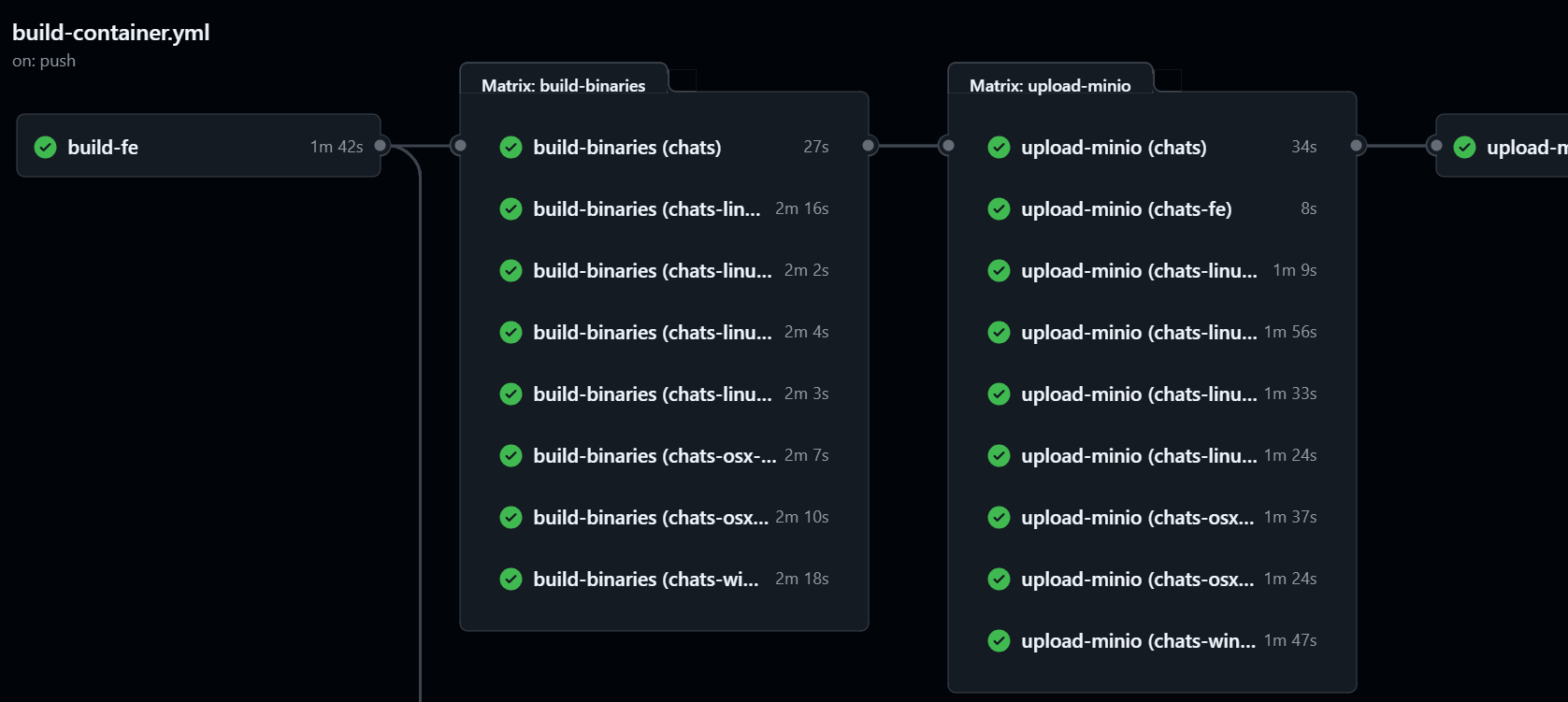
(
图片13:GitHub Actions 的 Summary 页面
)
对于不方便使用 Docker 的用户,
Sdcb Chats 提供了可直接运行的二进制文件
。我们通过 GitHub Actions 的 Matrix strategy,自动编译了
8 种不同操作系统或平台的 Native AOT 编译版本
。对于不便使用 Docker 部署的环境,Chats 提供了 8 种操作系统或架构的直接部署选项,您可以从以下链接获取相应的编译包:
| 平台 | Github下载链接 | 替代下载链接 |
|---|---|---|
| Windows 64位 | chats-win-x64.zip | chats-win-x64.zip |
| Linux 64位 | chats-linux-x64.zip | chats-linux-x64.zip |
| Linux ARM64 | chats-linux-arm64.zip | chats-linux-arm64.zip |
| Linux musl x64 | chats-linux-musl-x64.zip | chats-linux-musl-x64.zip |
| Linux musl ARM64 | chats-linux-musl-arm64.zip | chats-linux-musl-arm64.zip |
| macOS ARM64 | chats-osx-arm64.zip | chats-osx-arm64.zip |
| macOS x64 | chats-osx-x64.zip | chats-osx-x64.zip |
| 依赖.NET的通用包 | chats.zip | chats.zip |
| 纯前端文件 | chats-fe.zip | chats-fe.zip |

(
图片14:上传到 GitHub Release 和个人 Minio 服务器的编译文件
)
考虑到国内用户访问 GitHub 速度较慢,我们将编译文件同时上传到了个人的 Minio 服务器,方便快速下载。
(
动图15:演示如何下载和部署 Windows 版 Chats
)
直接下载适合您操作系统的压缩包,解压后双击
Chats.BE.exe
即可运行(对于 Linux 也同样,直接运行里面的
Chats.BE
即可),无需安装 .NET SDK 或 Runtime。
版本和下载说明
- 指定版本下载地址
:
- 若需下载特定版本的 Chats,将链接中的
release/latest/download
替换为
releases/download/r-{version}
。例如,版本
141
的 Linux ARM64 文件链接为:
https://github.com/sdcb/chats/releases/download/r-141/chats-linux-arm64.zip
- 若需下载特定版本的 Chats,将链接中的
执行文件目录结构和运行说明
解压AOT可执行文件后的目录结构如下:
C:\Users\ZhouJie\Downloads\chats-win-x64>dir
2024/12/06 16:35 <DIR> .
2024/12/06 16:35 <DIR> ..
2024/12/06 16:35 119 appsettings.Development.json
2024/12/06 16:35 417 appsettings.json
2024/12/06 16:35 367,144 aspnetcorev2_inprocess.dll
2024/12/06 16:35 84,012,075 Chats.BE.exe
2024/12/06 16:35 200,296 Chats.BE.pdb
2024/12/06 16:35 1,759,232 e_sqlite3.dll
2024/12/06 16:35 504,872 Microsoft.Data.SqlClient.SNI.dll
2024/12/06 16:35 465 web.config
2024/12/06 16:35 <DIR> wwwroot
- 启动应用
:运行
Chats.BE.exe
即可启动 Chats 应用,该文件名虽指“后端”,但实际同时包含前端和后端组件。 - 数据库配置
:默认情况下,应用将在当前目录创建名为
AppData
的目录,并以 SQLite 作为数据库。命令行参数可用于指定不同的数据库类型:
.\Chats.BE.exe --DBType=mssql --ConnectionStrings:ChatsDB="Data Source=(localdb)\mssqllocaldb; Initial Catalog=ChatsDB; Integrated Security=True"
- 参数
DBType
:可选
sqlite
、
mssql
或
pgsql
。 - 参数
--ConnectionStrings:ChatsDB
:用于指定数据库的ADO.NET连接字符串。
- 参数
特殊说明
- 对于下载的
chats.zip
,将需要.NET SDK支持。安装 .NET 运行时后,使用
dotnet Chats.BE.dll
启动程序。
多数据库支持(感谢 EF Core)

(
图片16:支持多种数据库类型
)
Chats 的后端使用 Entity Framework Core 访问数据库
,支持:
- SQLite:
DBType=sqlite - SQL Server:
DBType=mssql - PostgreSQL:
DBType=pgsql
在程序首次运行且数据库不存在时,Chats 会尝试自动创建数据库、相关表并插入基础数据。
多文件服务支持
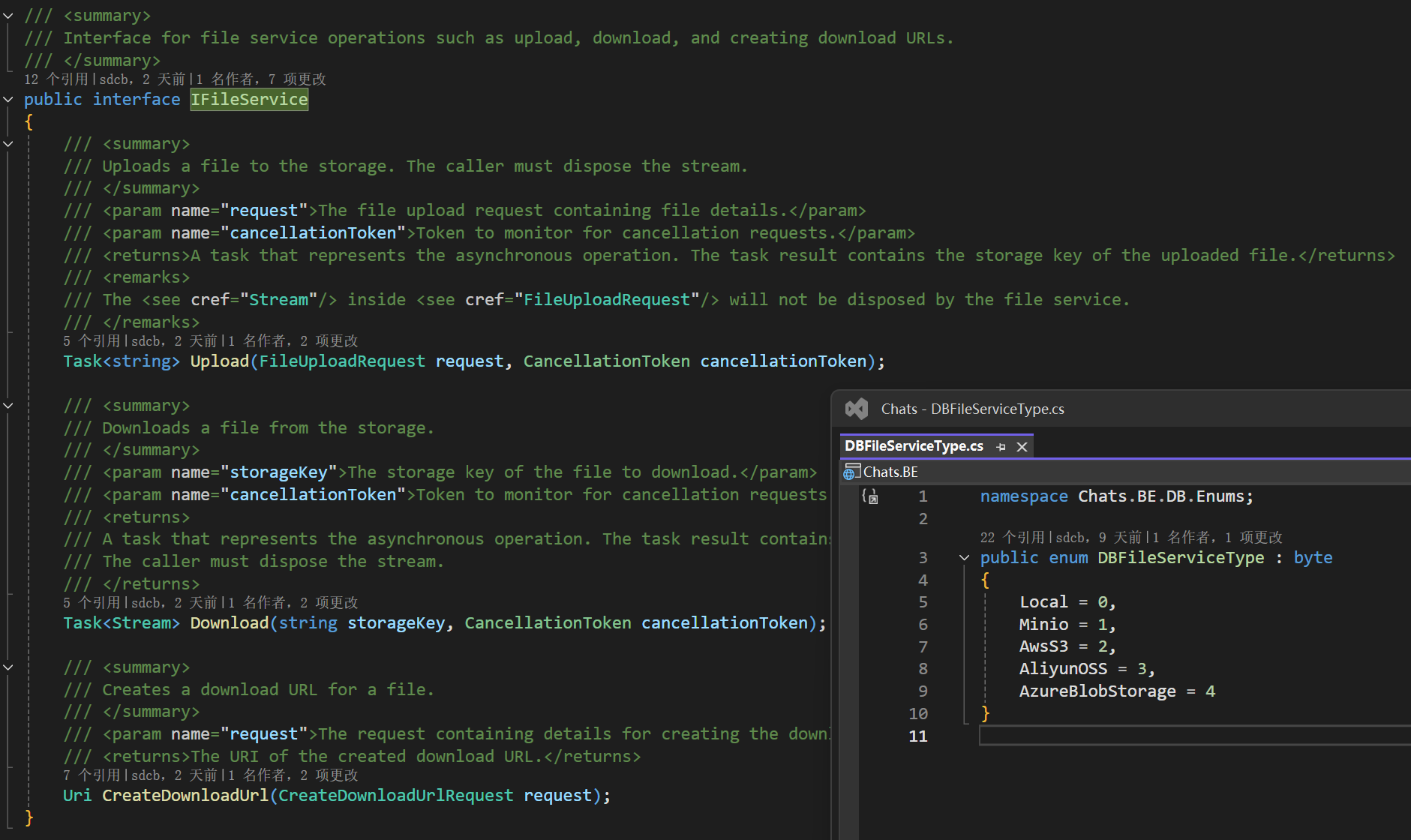
(
图片17:支持多种图床形式
)
Chats 支持本地文件、Minio/AWS S3、阿里云 OSS 和 Azure Blob Storage 五种图床形式
,您可以根据需要进行配置。
我们创新性地使用了云服务厂商提供的
Presigned URL 或 SAS URL
,这样可以节省 Chats 服务器的带宽,并提高图片的访问速度,增强用户体验,比如:
- 对于本地图片,地址可能是这样:
https://chats.starworks.cc:88/api/file/AFwoyuCjK9zVmPj_yMMKFWM?validBefore=1733724000259&hash=r6wvYSM6ElmsccUWWBZP_YvGYAhf1k553UHJsHvC3oQ - 对于Minio图片,地址可能是这样:
https://io.starworks.cc:88/gpt-v/2024/12/09/c1-tmwOTI02Vv8BJQk0DPg-image.png?AWSAccessKeyId=dmTDrNYIu8gzBeUc&Expires=1733724092&Signature=OlXqBgCxQvr8CJlfnemU1VG3ezQ%3D - 对于Azure Blob Storage,地址可能是这样:
https://richsgp.blob.core.windows.net/test/2024/12/09/Pm5IuJRuq02cXh6PX0VRtQ-image.png?sv=2025-01-05&se=2024-12-09T06%3A02%3A43Z&sr=b&sp=r&sig=Rm9X6%2FiqP1%2B41Jwms%2B75Jb3X9wPUxE4%2FxhwIEwJuL6c%3D
(链接仅供参考,因为所有链接仅提供2小时的有效期,防止流量被偷跑)
此外,我们引入了
PartialBufferedStream
,在读取用户上传图片的元信息(如宽高)时,不需要完全读入整个文件,节省内存。实际运行中,
Chats 的内存占用仅约 200MB
,具体代码可以从这个链接中参考:
https://github.com/sdcb/chats/blob/main/src/BE/Services/ImageInfo/PartialBufferedStream.cs
用户管理与安全
完善的用户管理功能
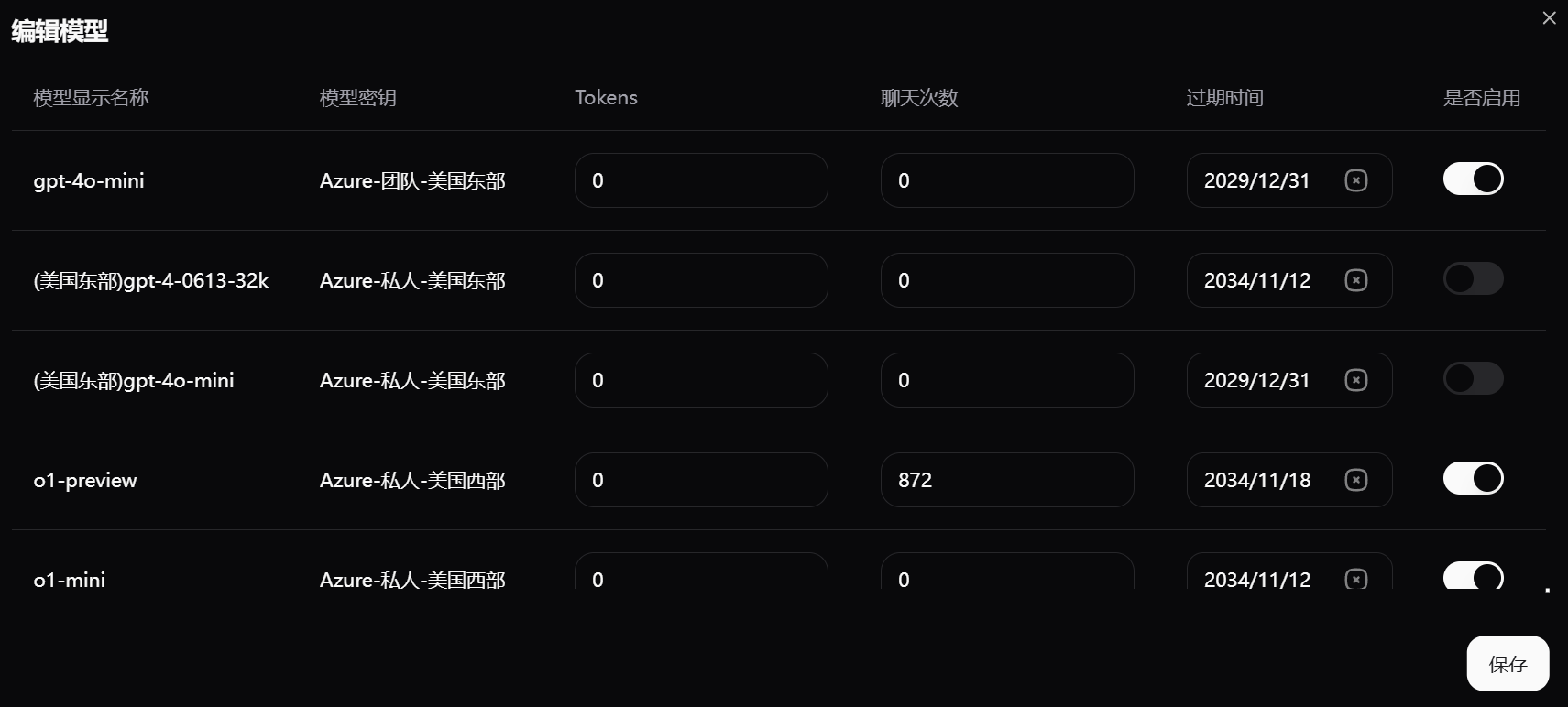
(
图片19:管理员的用户管理界面
)
作为一款面向企业应用的软件,
Sdcb Chats 提供了强大的用户管理功能
。管理员可以:
- 限制用户能使用的模型
- 限制 token 数量
- 限制聊天次数
- 设置模型过期时间
用户有余额概念,模型的价格可配置。余额通过
记账表
实现,每一笔开销或收入都会记录,账户余额通过记账表统计,确保并发请求下余额计算的准确性。
支持 Keycloak SSO 登录
(
动图20:使用 Keycloak SSO 登录
)
企业通常有自己的身份认证系统
,如 Keycloak SSO。Chats 支持集成这些系统,登录时如果用户不存在,会自动创建。只需配置相应的
well-known URL
、
client ID
和
client secret
。
手机号码验证码登录
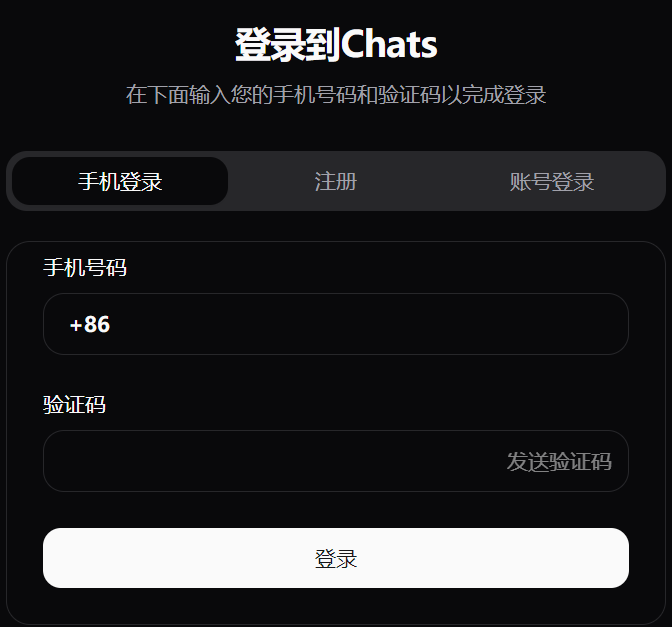
(
图片21:手机验证码登录界面
)
为方便国内用户,
Chats 支持手机号码验证码登录
,提升用户体验和安全性。
邀请码与注册

(
图片22:邀请码配置界面
)
如果您不想开放注册,
可以使用邀请码机制
。邀请码可以限制邀请次数,初始赠送金额,以及模型、token 数、使用次数和过期时间等。
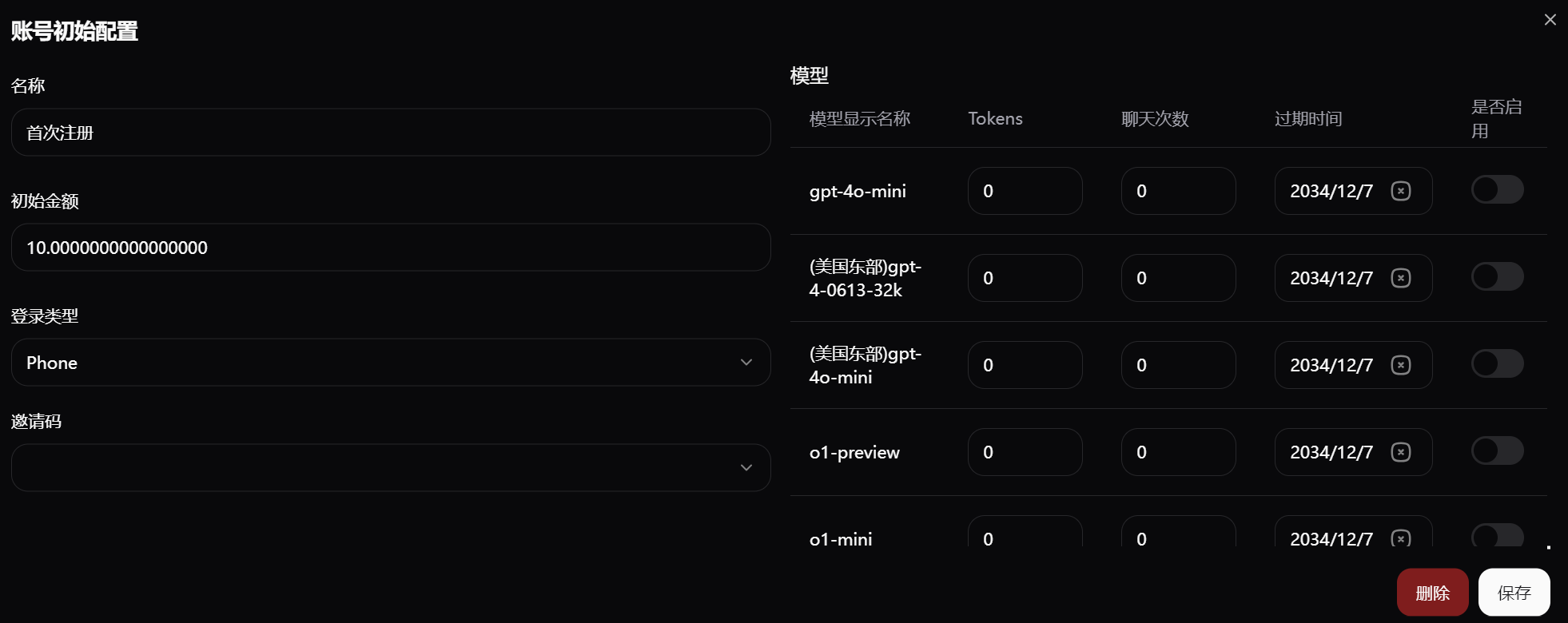
(
图片23:通过邀请码注册的新用户初始权限设置
)
当 token 数和聊天次数都为 0 时,将使用余额,按照模型配置的价格扣费。
Sdcb Chats 现已开源!
项目地址:
https://github.com/sdcb/chats
- 项目最初由我的好朋友文旺发起
- 历经超过 1000 次签入打磨
- 我们公司同事已经内部使用(dog food)一年
Sdcb 的含义
Sdcb:Serving dotNet, Constructing Brilliance(服务 .NET,构建卓越)
我们致力于为 .NET 社区和广大开发者提供高质量的开源项目。
开源协议
Apache 2.0 开源协议(可免费商用)
您可以自由地使用、修改和分发 Sdcb Chats,无需商用授权。
欢迎 Star ⭐
如果您觉得这个项目对您有帮助,
请在 GitHub 上给我们一个 Star
!您的支持是我们前进的最大动力。
感谢您的阅读和支持!让我们一起用 Sdcb Chats 探索大语言模型的无限可能!




