从托管调试器的角度看模块与程序集
常见WinDbg问题及解决方案
Win32 Error Code COM Error Code NTSTATUS的区别、转换
这三种码其实都是Windows系统错误码,只是对应不同API和使用场景。它们既有区别,又相互有联系。
一、区别和联系
- 都是32位值
- Win32 Error Code和NTSTATUS位域组成相同,但Win32 Error Code的取值范围只能在0x00000000---0x0000FFFF
- Win32 Error Code和COM Error Code,在高2位定义不同,设备来源值可能一样,但代表的设备不一样,设备来源值位数也不一样,但它们又可以互相转换。它们实际上的定义都是LONG型的,都是通过相关的API函数返回值返回来的,小于0时都代表着失败了。
- 具有相同格式的ntstatus和win32错误代码可能会使用相同的设施代码。然而,情况并非如此——相反,win32错误代码(根据winerrror.h)使用的是hresults的功能值!因此,交换ntstatus和win32错误代码在语法上是正常的,但由于设施代码不匹配而改变了它们的语义。
二、相互转换
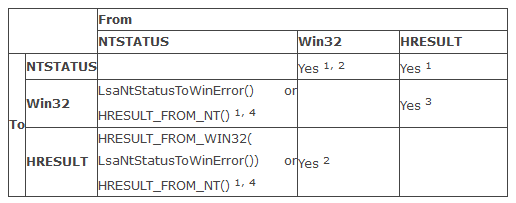
1 Facility may need to be adapted
2 Holds for ‘real’ Win32 error codes. For compatibility error codes, use HRESULT_FROM_WIN32
3 As long as you have a ‘real’ HRESULT (i.e. not one from
HRESULT_FROM_WIN32) and want to get a ‘real’ Win32 error code (i.e. not a
compaitibility one) — otherwise it can get tricky
4 Note that HRESULT_FROM_NT does not take the NT Status to Win32 Error Code conversion table
into account, thus the result may not be what one would expect. Using
LsaNtStatusToWinError takes this table into account, but yields
‘compatibility’ Win32 error code.
参考:
https://jpassing.com/2007/08/20/error-codes-win32-vs-hresult-vs-ntstatus/?like=1&_wpnonce=9495153bae
为什么托管调试API不公开终结器线程?
这是个公平的问题。部分原因是我们不相信人们能正确地使用它。我们发现人们问的主要原因是:
1) 用户好奇心:
用户只想在调试时知道这些琐事。当调试你认为是单线程应用程序时,你会在VSThreads窗口中看到6个线程,你想知道原因。请参阅Steve关于为调试器命名线程的帖子。不幸的是,CLR没有命名终结器线程。。我认为正确的解决方法是让终结器线程的命名和其他线程命名一样工作(并修复之前出现的任何perf问题);而不是添加一个特殊的调试器API来识别它。
2) 解决错误:
人们碰到了由终结器线程暴露的线程错误,然后希望能够识别终结器线程,以识别特殊情况下该错误的某些行为。终结器使用与其他线程相同的规则,因此线程错误(无论是在调试器中还是在常规托管应用程序中),发生在终结器线程上的线程错误也很可能发生在其他线程中。
现在根据经验,终结器的行为与主线程不同。在运行终结器之前,终结器实际上不会出现在托管代码中,这可能在任何随机时间发生。这是因为托管调试器在实际运行托管代码之前不会看到线程。由于主线程立即运行托管main()函数,因此这不是问题。
但是,其他线程的行为可能与终结器相同。通常,本机线程可以随时进入托管代码。在MC++中,线程可以在应用程序的本地部分启动,然后调用C++编译到IL,然后再进行管理。
在崩溃转储中查找所有可能的上下文记录
如果您调试了一段时间的崩溃转储,那么您可能遇到了这样的情况:调试器提供的初始转储上下文对应于在处理初始异常时发生的第二个异常,该异常可能更接近您正在调查的问题中的原始基础问题。
这可能很烦人,因为“.ecxr”命令将指向次要故障异常的位置,而不是原始异常上下文本身。然而,在大多数情况下,原始的、主要的异常上下文仍然在堆栈上;人们只需要知道如何找到它。
有两种方法可以解决这个问题:
- 对于硬件生成的异常(如访问冲突),可以查找堆栈上的ntdll!KiUserExceptionDispatcher,它以PCONTEXT和PEXCEPTION_RECORD作为参数。
- 对于软件生成的异常(如C++异常),情况会变得更糟。你可以找在堆栈上调用ntdll!RtlDispatchException,然后从那里获取PCONTEXT参数
如果堆栈展开失败,或者您正在处理其中一个转储,其中多个线程同时出现异常,这可能会有点乏味,这通常是由于崩溃转储写入失控。如果调试器能稍微自动化一下这个过程就好了。幸运的是,用一点蛮力的方法来做到这一点其实并不难。具体地说,只是一个普通的老“哑”内存扫描,以查找大多数上下文记录所共有的内容。这并不完全是一种巧妙的方法,但通常比手动在堆栈中查找要快得多,尤其是在涉及多个线程或多个嵌套异常的情况下。虽然可能会有误报,但通常很明显的一点是,涉及到一个活动异常有什么意义。然而,有时,快速而肮脏的暴力类型解决方案最终真的做到了这一点。
但是,为了基于内存搜索查找上下文记录,我们需要一些公共数据点,这些数据点通常对于所有上下文结构都是相同的,并且最好是连续的(为了便于使用“s”命令,调试器的内存搜索支持)。幸运的是,它以上下文结构的段寄存器的形式存在:
0:000> dt ntdll!_CONTEXT
+0x000 ContextFlags : Uint4B
[…]
+0x08c SegGs : Uint4B
+0x090 SegFs : Uint4B
+0x094 SegEs : Uint4B
+0x098 SegDs : Uint4B
[…]
现在,事实证明,对于给定进程中的所有线程,几乎总是具有相同的段选择器值,不包括异常的和非常不寻常的情况,如VDM进程。(x64上的段选择器值也是如此。)四个非零的32位值(实际上,零填充到32位的16位值)足以在不被误报的情况下合理地完成搜索。下面介绍如何使用臭名昭著的WinDbg调试器脚本(也适用于其他启用DbgEng的程序,如kd):
.foreach ( CxrPtr { s -[w1]d 0 l?ffffffff @gs @fs @es @ds } ) { .cxr CxrPtr – 8c }
这是一个有点冗长的命令,所以让我们把它分解成各个组件。首先,我们有一个“.foreach”构造,根据调试器文档,它遵循以下约定:
.foreach [Options] ( Variable { InCommands } ) { OutCommands }