Dump文件数据存储格式(九)
十一、系统内存信息流(SystemMemoryInfoStream)
SystemMemoryInfoStream包含系统内存管理的一些信息,它紧随在UnloadedModuleListStream流的后面。UnloadedModuleListStream的信息如下:

0x91f8+0n324=0x933c
而SystemMemoryInfoStream的相关信息如下:

可知SystemMemoryInfoStream的RVA 为0x933C,大小为492字节,数据如下:
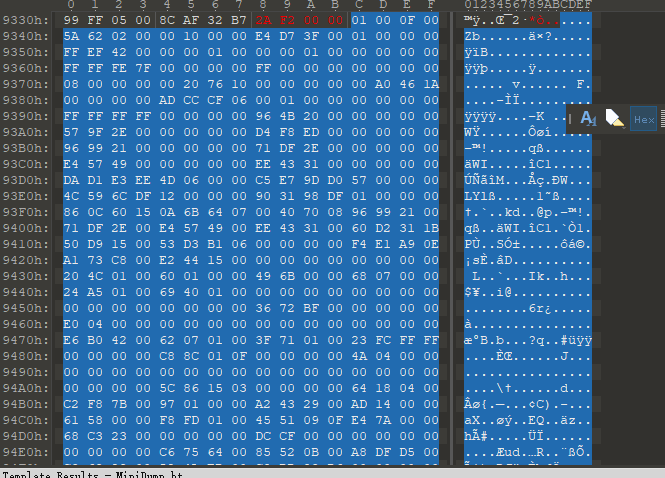
对应的数据结构目前我还没找到,但我们可以通过Minidump Browser工具大概了解一下:
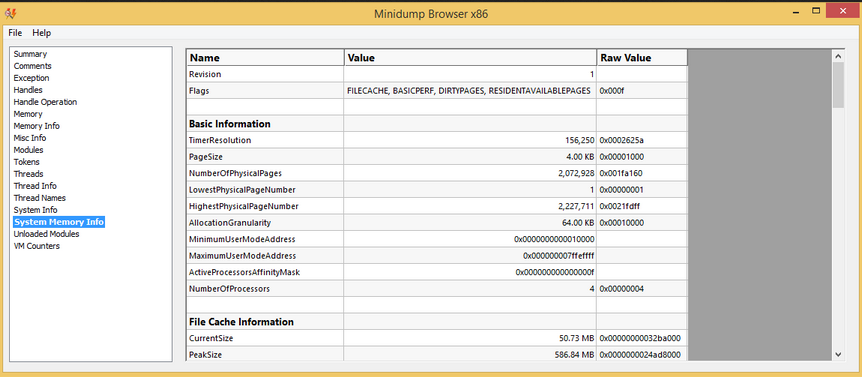
对照上面的图,感觉这些数据对应的是SYSTEM_INFO结构,如下:
typedef struct_SYSTEM_INFO {
union {
DWORD dwOemId;struct{
WORD wProcessorArchitecture;
WORD wReserved;
} DUMMYSTRUCTNAME;
} DUMMYUNIONNAME;
DWORD dwPageSize;
LPVOID lpMinimumApplicationAddress;
LPVOID lpMaximumApplicationAddress;
DWORD_PTR dwActiveProcessorMask;
DWORD dwNumberOfProcessors;
DWORD dwProcessorType;
DWORD dwAllocationGranularity;
WORD wProcessorLevel;
WORD wProcessorRevision;
} SYSTEM_INFO,*LPSYSTEM_INFO;
符号文件如何让断点发挥作用的?
调试符号文件(pdb)是一种很复杂的文件,由于这种文件格式微软并不公开,所以至今为止,并没有一篇文章或资料敢说自己对pdb文件进行了深入剖析。更重要的原因是,我们为了研究调试技术,需要知道一些系统(操作系统,编译器,连接器,调试器等)调试支持,仅仅知道即可,没必要深究微软为了实现调试而做出的每一个细节。
首先,我先问几个问题:
- 我们经常用的调试方法,下断点,是如何实现的呢?
- 我们可以在程序还没有执行起来的时候就可以下断点,等调试启动的时候,就可以命中这个断点。这个是怎么实现的?
- 当断点命中时,我们可以观察一个变量的值,这是怎么实现的?
先简单讲解本文中用到的两个概念:
- OFFSET,文件中的偏移。
- VA,程序加载到内存后的一个虚拟地址。
假设在一个EXE文件中,有一个全局变量a,距离文件起始的偏移为0x10,此时文件的起始位置为0x00000000,那么该全局变量a的OFFSET就是0x00000010。当这个exe执行起来,加载到内存后,这个exe本身所加载到的内存位置称为基地址。假设基地址为0x00400000,那么这个全局变量a的VA便是0x00400010。可见,exe本身所加载到的基地址不一样的话,那么a的VA就不能确定。
依然使用最简单的例子,来阐述原理,代码如下:
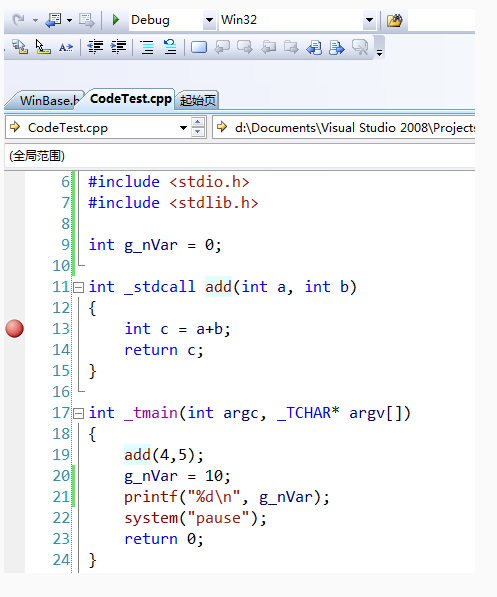
可以观察到,此时,笔者并未调试启动程序,而这个断点,就已经打上了。接下来我们调试启动程序,如下图:
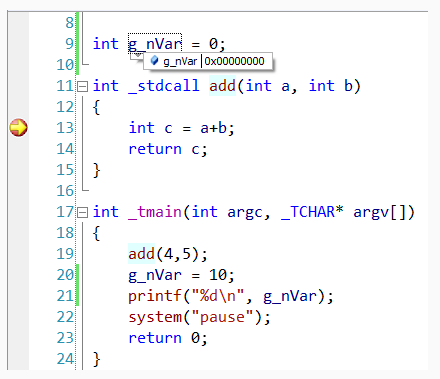
此时,我们已经进入断点,并中断下来,我们可以观察到全局变量g_nVar的值。想必这个过程,有过VC++开发经验的开发者,再熟悉不过了。下面,详细分析一下这个过程。
当我们鼠标点击下断点的时候,我们的程序还没有启动,VS是不可能知道这个断点应该打在内存中的哪一条指令的地址处的(此时,VS顶多知道断点所在的OFFSET,但是无法知道断点所在的VA),但是VS可以记录到一条重要的信息,就是当前断点在哪个源文件的哪个行号上。
接下来,我们调试启动程序,exe的镜像加载到内存后,所有代码段的指令的VA便是真实可用的了。但此时调试器是如何根据断点所在源文件和行号,来找到断点所在的VA的呢?现在,你应该想到本文在讲什么,哈哈,就是pdb啦。那么pdb文件中到底存了什么,才让调试器可以根据源文件及行号来找到对应的VA呢?
默认情况下,在pdb文件中,保存了可执行文件中所有的符号(函数名、变量名等)所在源文件、行号、OFFSET等信息。但是这些信息,是在什么时间得到的呢?很明显是编译阶段,编译器在编译每个cpp的过程中,就可以把这些符号的相关信息收集起来,存放在各个cpp所生成的obj文件中,然后在链接的时候,提取每个obj中的这些信息,生成一个单独的pdb文件。这样,以后调试程序的时候,调试器只要找得到这个pdb,就可以知道可执行文件中,所有符号所在的源文件、行号和OFFSET了。反过来说,当给出一个源文件和行号,就可以拿到对应的OFFSET了,所以在还没有启动调试的时候,我们下的断点,实际上调试器是知道这个断点应该在哪个OFFSET上了,等启动调试的时候,用这个OFFSET加上这个模块所加载到的基地址值,就可以得到这个断点所在的VA了,然后在这个VA处强行写上int
3指令,并继续执行,当执行到这里,便中断下来给我们一个调试机会了。想想,如果没有pdb,这个断点还能用么?
当我们鼠标放在某个变量上时,调试器可以拿到这个变量的名称,根据我们前面说的,用这个名称去pdb中查找,自然就可以找到pdb文件中保存的OFFSET了,加上这个模块的基地址,就找到了这个变量所在内存的VA,剩下的就是读一下这个VA内存中的内容了。这样也就实现了观察变量值得功能。
下面证实一下,pdb文件中确实存储了源文件、行号、OFFSET等信息。将上面例子代码放到VC6中编译,然后到debug目录中使用dumpbin来查看CodeTest.obj文件中的符号信息,如图:
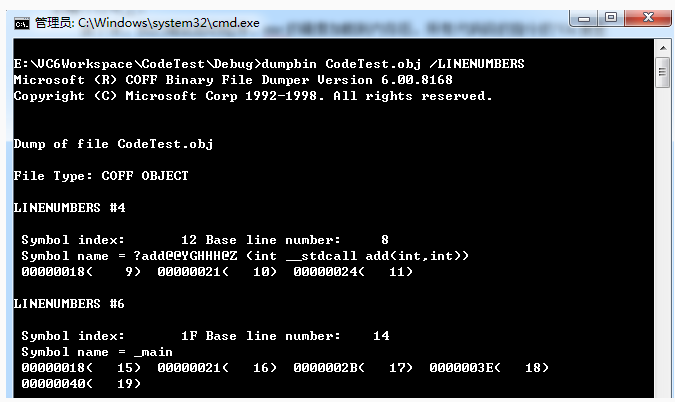
可见,add函数和main函数所在行号和起始行号和结束行号都是有记录的,那源文件是哪个呢?哈哈,当然是CodeTest.cpp了,我们查看的是CodeTest.obj文件嘛。。。
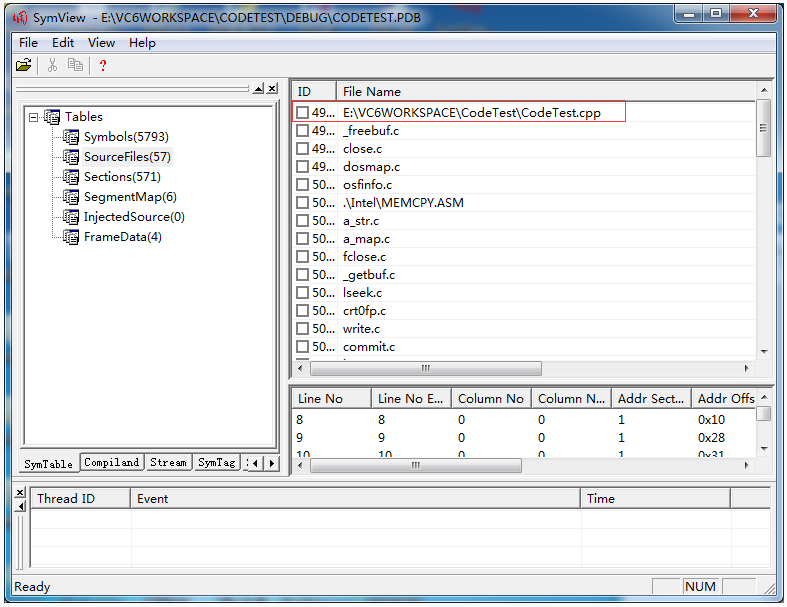
但是这里并没有add或者main函数的OFFSET啊,为什么呢?想想,此时只有一堆obj,真正的可执行模块还没有生成出来呢,何来的可执行模块的OFFSET呢。。。由此可以知道,这个OFFSET要在链接过程中,才可以确定。经过了链接之后,这些本来在obj里的调试信息,也就被收集到pdb文件中了,下面我们来找找add函数的OFFSET到底在哪里?使用SymView工具打开CodeTest.pdb文件,如下图:

可见,pdb中存储了add函数相关信息,不仅仅只有offset,而且此处并未直接记载add函数在哪个cpp里,这些关系都是通过索引来查找的,其实pdb文件的内部结构是很复杂的,要想解释清楚,其实很不容易,大家如果想知道pdb内部到底都有什么东西,可以参考一下《软件调试》第25章,但也是讲了个大概。
在我们观察的过程中,我们可以发现两个很主要的特征:
- 可执行模块中,保存了当前模块的调试符号文件的路径,而且是绝对路径,如下图:

- Pdb文件中保存了每个cpp文件的路径,而且也是用的绝对路径。如下图:
这样,我们可以得出一个结论:
- 在同一台开发者的机器上,如果被调试的exe放在了其他目录里,而pdb依然在原来生成时所在的位置,那么调试exe时,依然可以找到对应的pdb文件。
- 如果exe和pdb都换了路径,只要调试的时候,我们手动指定了pdb所在的位置,如果源码文件还在原来的路径,那么调试时,依然可以找得到源码文件。
Windbg命令系列---!cpuid(CPU信息)
!cpuid扩展命令显示有关系统上处理器的信息。
语法
!cpuid[Processor]
参数
- Processor
指定将显示其信息的处理器。如果忽略此参数,则显示所有处理器。
DLL
Windows 2000 |
Ext.dll |
Windows XP and later |
Ext.dll |
备注
!cpuid扩展在实时用户模式或内核模式调试、本地内核调试和转储文件调试期间工作。但是,用户模式的小型转储文件仅包含有关活动处理器的信息。如果在用户模式下调试,则!cpuid扩展描述目标应用程序正在运行的计算机。在内核模式下,它描述目标计算机。
下面的示例显示了这个扩展。
0:000> !cpuid
CP F/M/S Manufacturer MHz
0 6,158,10 GenuineIntel 3192
1 6,158,10 GenuineIntel 3192
2 6,158,10 GenuineIntel 3192
3 6,158,10 GenuineIntel 3192
4 6,158,10 GenuineIntel 3192
5 6,158,10 GenuineIntel 3192
6 6,158,10 GenuineIntel 3192
7 6,158,10 GenuineIntel 3192
8 6,158,10 GenuineIntel 3192
9 6,158,10 GenuineIntel 3192
10 6,158,10 GenuineIntel 3192
11 6,158,10 GenuineIntel 3192
CP列给出处理器编号。(这些数字总是连续的,从零开始)。制造商列指定处理器制造商。MHz列指定处理器速度(如果可用)。对于基于x86或基于x64的处理器,F列显示处理器系列号,M列显示处理器型号,S列显示步进大小。对于基于安腾的处理器,M列显示处理器型号,R列显示处理器修订号,F列显示处理器系列号,A列显示体系结构修订号。
软件调试的九个规则
这就个规则来自于书籍《调试九法:软硬件错误的排查之道》,记录下来:
规则1:理解系统
你必须掌握系统的工作原理以及它是如何设计的,在某些情况下还要知道为什么这样设计。如果你没有理解系统中的某个部分,那么这通常是出问题的地方。(这不仅仅是墨菲定律的问题,如果你不能理解你所设计的系统,你的工作可能会变得一团糟)。
如何理解系统呢?
- 阅读手册
- 逐字逐句阅读手册,仔细理解每个细节
- 知道什么是正常的,知道什么是正常的可以帮助你注意到什么是不正常的
- 知道工作流程,要理解业务,要讲系统的工作过程对应到具体要解决的现实问题
- 选择合适的工具,选择合适的辅助(监控、插桩)工具可以帮你理解系统
- 查阅细节,经验有时候会骗人,记忆有时候会出错
规则2:制造失败
这一点比较容易理解,就是问题复现,在日常工作中,你在排查一个问题的过程中,最重要的一步就是复现问题——能复现的问题都能解决。
这里有几个要点需要注意:
- 引发失败,而不要模拟失败,不要尝试用不同的方式去模拟问题,而要模拟和构建引发bug发生的条件
- debug的动作,不要影响错误的发生方式,可以影响错误的发生频率
- 从头开始,需要有一个正常的状态到不正常的状态的过程,从开始正常的状态开始观察,直到问题发生;
- 终极方案,控制变量法,将可能引发错误的因素依次排除;排除所有可能的原因后,剩下那个答案,无论多么不可思议,都是事实。
规则3:不要想,而要看
亲眼看到底层的失败是非常重要的,如果你猜测失败是如何发生的,那常常会修复一些根本不是bug的问题。
在软件世界里,观察意味着设置断点、添加调试语句、监视程序值以及检查内存;在医学领域,需要测试血样和进行X光透视。
对细节的观察应该到什么程度合适呢?简单的答案是:一直观察,直到把问题的原因锁定在几种可能之内。
在系统设计的时候,就要考虑到将来调试、排查问题的情况,将日志视为系统设计的一部分—打印一些关键日志,或者设计一些打开日志的开关,以便在生产环境针对某个case进行调试。
日常生活中有很多插桩的case:
- 体温计测量体温
- 自行车轮胎漏气时,都是将轮胎打满气,然后放在水里检查哪里漏气
- 天然气中加入了臭鸡蛋的气味
规则4:分而治之
反复将问题分成好的一半和坏的一半,然后缩小搜索范围,然后进一步研究有问题的那一半链路。
规则5:一次只改一个地方
初中就学过的控制变量法。 在修改bug时候,如果某个改动没有修复bug,就应该立即把它改回来。
规则6: 保持审计跟踪
记下你的每步操作、顺序和结果; 魔鬼藏在细节中; 将一些事情关联起来思考; 好记性不如烂笔头;
规则7:检查插头
一些显而易见的假设可能是错误的;是不是运行了正确的代码?是不是打了正确的包?插头是不是掉了?从一些最基本的问题开始确认,很多时候问题就出在这里。对自己使用的工具进行测试,因为工具也是一种软件,难保不会出问题。
规则8:获得全新观点
向别人解释问题的过程,会让你对问题进行重新的梳理和理解,这时候可能发现之前没有发现的问题。
bug发生了,以除掉bug为自豪,而不是非得以自己除掉bug才自豪。
不管你是跟什么人求助,或者需要别人什么样的帮助(征求意见、获取专业知识、听取经验),在向别人描述问题的时候,一定要记住一件事——报告症状、而不是讲你的理论;另外,有些症状你可能不是十分确定,也可以描述出来。
规则9:如果你不修复bug,它将依然存在
如果你不修复bug,它不会自动消失。按照前面的规则解决问题后,要进行一次回归验证,确保已经修复问题,并且没有引入新的问题。
《调试九法:软硬件错误的排查之道》
Windbg命令系列---!chkimg
!chkimg扩展命令通过将可执行文件的映像与符号存储库或其他文件存储库上的副本进行比较来检测可执行文件映像中的损坏。
语法
!chkimg[Options][-mmw LogFile LogOptions] [Module]
参数
- Options
以下选项的任意组合:
- -pSearchPath
在访问符号服务器之前,递归地搜索SearchPath路径。
- -f
修复Image中的错误。每当扫描检测到符号存储中的文件与内存中的图像之间存在差异时,符号存储中的文件内容将复制到Image上。如果正在执行实时调试,则可以在执行!chkimg-f扩展之前创建一个转储文件。
- -nar
- 防止移动符号服务器上文件的映射。默认情况下,当文件副本位于符号服务器上并映射到内存时!chkimg移动符号服务器上文件的Image。但是,如果使用-nar选项,则不会移动服务器上的文件映像。已在内存中的可执行映像(即正在扫描的映像)将被移动,因为调试器总是重新定位它加载的映像。仅当操作系统已移动原始映像时,此开关才有用。如果Image没有被移动!chkimg和调试器将移动Image。很少使用这个开关。
- -ssSectionName
将扫描限制为名称包含字符串SectionName的节。扫描将包括名称中包含此字符串的任何不可丢弃部分。SectionName区分大小写,不能超过8个字符。
- -as
使扫描包括除可丢弃部分以外的Image的所有部分。默认情况下,(如果不使用-as或-ss),扫描将跳过可写的部分、不可执行的部分、名称中有“PAGE”的部分以及可丢弃的部分。
- -rStartAddressEndAddress
将扫描限制为以StartAddress开始、以EndAddress结束的内存范围。在此范围内,将扫描通常要扫描的任何部分。如果部分与此范围重叠,则只扫描与此范围重叠的部分。即使您也使用-as或-ss开关,扫描也限制在该范围内。
- -nospec
使扫描包括的保留部分Hal.dll 和 Ntoskrnl.exe. 默认情况下!chkimg不检查这些文件的某些部分。
- -noplock
显示字节值0x90(nop指令)和字节值0xF0(锁定指令)不匹配的区域。默认情况下,不显示这些不匹配项。
- -np
使修补的指令被识别。
- -d
扫描时显示所有不匹配区域的摘要。
- -db
以类似于db debugger命令的格式显示不匹配的区域。因此,每个显示行显示该行中第一个字节的地址,后跟最多16个十六进制字节值。字节值后面紧跟着相应的ASCII值。所有不可打印的字符,如回车符和换行符,都显示为句点(.)。不匹配的字节用星号(*)标记。
- -lolines
将-d或-db显示的输出行数限制为行数。
- -v
显示详细信息。
- -mmw
创建日志文件并记录!chkimg在这个文件里的活动。日志文件的每一行都表示一个不匹配项。
- LogFile
指定日志文件的完整路径。如果指定相对路径,则该路径相对于当前路径。
- LogOptions
指定日志文件的内容。LogOptions是一个由多个字母串联而成的字符串。日志文件中的每一行包含多个用逗号分隔的列。这些列包括以下选项字母指定的项,顺序是字母在LogOptions字符串中的出现顺序。可以多次包含以下选项。必须至少包含一个选项。
Log option Information included in the log file v
The virtual address of the mismatch
r
The offset (relative address) of the mismatch within the module
s
The symbol that corresponds to the address of the mismatch
S
The name of the section that contains the mismatch
e
The correct value that was expected at the mismatch location
w
The incorrect value that was at the mismatch location
LogOptions还可以包括以下附加选项中的一些,或者不包括。
Log option Effect o
If a file that has the name LogFile already exists, the existing file is overwritten. By default, the debugger appends new information to the end of any existing file.
tString
Adds an extra column to the log file. Each entry in this column contains String. The tString option is useful if you are appending new information to an existing log file and you have to distinguish the new records from the old. You cannot add space between t and String. If you use the tIString option, it must be the final option in LogOptions, because String is taken to include all of the characters that are present before the next space.
例如,如果LogOptions是rSewo,则日志文件的每一行都包含不匹配位置的相对地址和节名以及该位置的预期值和实际值。此选项还会导致覆盖以前的任何文件。如果要创建多个具有不同选项的日志文件,可以多次使用-mmw开关。最多可以同时创建10个日志文件。
- Module
指定要检查的模块。Module可以是模块的名称、模块的起始地址或模块中包含的任何地址。如果省略模块,调试器将使用包含当前指令指针的模块。
DLL
Windows 2000 |
Ext.dll |
Windows XP and later |
Ext.dll |
备注
当你使用!它将内存中可执行文件的映像与驻留在符号存储中的文件副本进行比较。比较文件的所有部分,除了可丢弃、可写、不可执行、名称中有“PAGE”或来自INITKDBG的节除外。可以通过使用-ss、-as或-r开关来更改此行为。!chkimg将映像和文件之间的任何不匹配显示为映像错误,但以下情况除外:
- 不检查由导入地址表(IAT)占用的地址。
- 某些特定地址哈尔.dll以及Ntoskrnl.exe文件未选中,因为加载这些节时会发生某些更改。要检查这些地址,请包含-nospec选项。
- 如果文件中存在字节值0x90,并且如果值0xF0出现在图像的相应字节中(反之亦然),则将这种情况视为匹配。通常,符号服务器保存单处理器和多处理器版本中都存在的二进制文件的一个版本。在基于x86的处理器上,锁指令是0xF0,而该指令对应于单处理器版本中的nop(0x90)指令。如果你愿意的话!chkimg要将此对显示为不匹配,请设置-noplock选项。
注意,如果您使用-f选项来修复Image不匹配!chkimg只修复那些它认为是错误的不匹配。例如!除非包含-noplock,否则chkimg不会将0x90字节更改为0xF0字节。
当您包含-d选项时!当扫描发生时,chkimg显示所有不匹配区域的摘要。每个不匹配显示在两行上。第一行包括范围的开始、范围的结束、范围的大小、与范围开始相对应的符号名称和偏移量,以及自上一个错误以来的字节数(在括号中)。第二行的十六进制值中包含了一个十六进制值。如果范围大于8个字节,则只有前8个字节显示在冒号之前和冒号之后。下面的示例显示了这种情况。
be000015-be000016 2 bytes - win32k!VeryUsefulFunction+15 (0x8)
[ 85 dd:95 23 ]有时,驱动程序会使用钩子、重定向或其他方法来更改Microsoft Windows内核的一部分。即使是不再在堆栈中的驱动程序也可能改变了内核的一部分。你可以用!chkimgextension是一个文件比较工具,用于确定驱动程序正在更改Windows内核(或任何其他映像)的哪些部分,以及这些部分是如何更改的。这种比较对完全转储文件最有效。
你也可以用!chkimg和!for_each_module他在一起用于检查每个加载模块的映像。下面的示例显示了这种情况。
!for_each_module !chkimg @#ModuleName 例如,假设您遇到了一个bug检查,并使用 !analyze.
kd> !analyze
....
BugCheck 1000008E, {c0000005, bf920e48, baf75b38, 0}
Probably caused by : memory_corruption
CHKIMG_EXTENSION: !chkimg !win32k
....在这个例子中,这个!analyze 输出表明内存已损坏,并包含一个CHKIMG_EXTENSION,表明Win32k.sys可能是损坏的模块。(即使这行不存在,您也可以考虑堆栈顶部的模块可能损坏。)开始使用没有任何开关的!chkimg,如下例所示。
kd> !chkimg win32k
Number of different bytes for win32k: 31下面的示例显示确实存在内存损坏。使用!chkimg-d显示Win32 K模块的所有错误。
kd> !chkimg win32k -d
bf920e40-bf920e46 7 bytes - win32k!HFDBASIS32::vSteadyState+1f
[ 78 08 d3 78 0c c2 04:00 00 00 00 00 01 00 ]
bf920e48-bf920e5f 24 bytes - win32k!HFDBASIS32::vHalveStepSize (+0x08)
[ 8b 51 0c 8b 41 08 56 8b:00 00 00 00 00 00 00 00 ]
Number of different bytes for win32k: 31尝试反汇编列出的第二部分的损坏映像时,可能会出现以下输出。
kd> u win32k!HFDBASIS32::vHalveStepSize
win32k!HFDBASIS32::vHalveStepSize:
bf920e48 0000 add [eax],al
bf920e4a 0000 add [eax],al
bf920e4c 0000 add [eax],al
bf920e4e 0000 add [eax],al
bf920e50 7808 js win32k!HFDBASIS32::vHalveStepSize+0x12 (bf920e5a)
bf920e52 d3780c sar dword ptr [eax+0xc],cl
bf920e55 c20400 ret 0x4
bf920e58 8b510c mov edx,[ecx+0xc]那就用 !chkimg -fto修复内存。
kd> !chkimg win32k -f
Warning: Any detected errors will be fixed to what we expect!
Number of different bytes for win32k: 31 (fixed)现在可以反汇编已更正的视图并查看所做的更改
kd> u win32k!HFDBASIS32::vHalveStepSize
win32k!HFDBASIS32::vHalveStepSize:
bf920e48 8b510c mov edx,[ecx+0xc]
bf920e4b 8b4108 mov eax,[ecx+0x8]
bf920e4e 56 push esi
bf920e4f 8b7104 mov esi,[ecx+0x4]
bf920e52 03c2 add eax,edx
bf920e54 c1f803 sar eax,0x3
bf920e57 2bf0 sub esi,eax
bf920e59 d1fe sar esi,1