CLR Exception 0xE0434F4D和0xE0434352的区别
《根据《CLR Exception---E0434352》和《CLR Exception---E0434F4D》这两篇随笔,我们会发现,这两个异常太相似了,除了代码值不一样,其他几乎都一样。在windbg里调试dmp时,也会看到都叫它们CLR Exception。那他们有什么区别呢?这个问题值得研究研究。
我查了很多资料都没查明白。但是黄天不负有心人。在我搞其他问题时,让我窥得一线道道儿来。
首先上个实际的例子,在VS2013里新建一个c#控制台工程ConsoleApplication1,代码如下:
static void Main(string[] args)
{throw newSystem.Exception();return;
}
如何跟踪高CPU在用户模式应用程序-现场调试!
我想谈谈我们经常处理的一个常见问题。我们的任务通常是在用户模式进程/应用程序中查找哪些函数正在使用CPU。通常,用户会发现一个应用程序使用的CPU比他们预期的要多,这可能会影响整个系统的性能和响应能力。
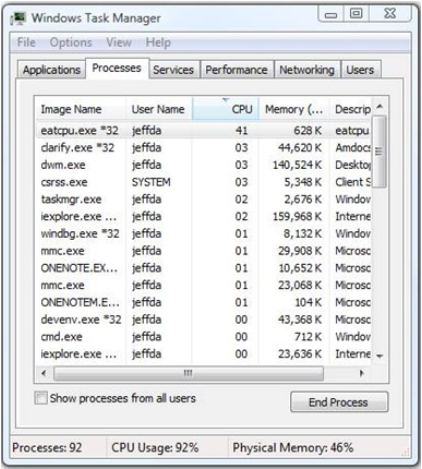
对于这个练习,我编写了一些人为的示例代码,称为EATCPU。它包含在博客文章的底部。任务管理器的下图显示EATCPU消耗41%的CPU时间。客户或用户可能会告诉您,这种情况“通常”不会发生。问“正常”是什么总是好的。在这种情况下,我们认为正常值为~10%。
最好的情况是对运行在高CPU级别的进程进行实时调试。如果您有幸拥有一个客户/用户,该客户/用户允许您进行远程调试,并且问题在需要时重现,那么您可以采取以下操作。
您需要安装Windows调试工具,并设置符号路径。如果有可能,请获取正在调试的应用程序的符号。我们假设你是支持上述计划的专家。如果是内部编写的,从开发者那里获取符号。如果是来自第三方的,供应商可能愿意为您提供他们产品的符号。
下一件事是附用windbg.exe加进程。
在debuggers目录中,输入TLIST,这将列出您的进程。获取进程id,然后运行WinDBG.EXE –p PROCESSID,或者如果您调试的是eatcup之类的程序,则可以运行WINDBG C:\program\EATCPU.EXE.
附加调试器或在调试器中启动进程后,重现问题。
Microsoft (R) Windows Debugger Version 6.8.0001.0Copyright (c) Microsoft Corporation. All rights reserved.***** WARNING: Your debugger is probably out-of-date.***** Check http://dbg for updates. CommandLine: eatcpu.exe
Symbol search path is: srv*C:\symbols*\\symbols\symbols
Executable search path is:
ModLoad:004000000041a000 eatcpu.exe
ModLoad: 779b0000 77b00000 ntdll.dll
ModLoad:76780000 76890000C:\Windows\syswow64\kernel32.dll
ModLoad: 62bb0000 62cd1000 C:\Windows\WinSxS\x86_microsoft.vc80.debugcrt_1fc8b3b9a1e18e3b_8.0.50727.762_none_24c8a196583ff03b\MSVCR80D.dll
ModLoad: 75cb0000 75d5a000 C:\Windows\syswow64\msvcrt.dll
(1090.164): Break instruction exception - code 80000003(first chance)
eax=00000000 ebx=00000000 ecx=712b0000 edx=00000000 esi=fffffffe edi=77a90094
eip=779c0004 esp=0017faf8 ebp=0017fb28 iopl=0nv up ei pl zr na pe nc
cs=0023 ss=002b ds=002b es=002b fs=0053 gs=002b efl=00000246ntdll!DbgBreakPoint:
779c0004cc int 3 0:000>g
(1090.11d4): Break instruction exception - code 80000003(first chance)
eax=7efa3000 ebx=00000000 ecx=00000000 edx=77a1d894 esi=00000000 edi=00000000eip=779c0004 esp=0109ff74 ebp=0109ffa0 iopl=0nv up ei pl zr na pe nc
cs=0023 ss=002b ds=002b es=002b fs=0053 gs=002b efl=00000246ntdll!DbgBreakPoint:
779c0004cc int 3 0:007> .sympath SRV*c:\websymbols*http://msdl.microsoft.com/download/symbols Symbol search path is: SRV*c:\websymbols*http://msdl.microsoft.com/download/symbols 0:007>g
(1090.17d4): Break instruction exception - code 80000003(first chance)
eax=7efa3000 ebx=00000000 ecx=00000000 edx=77a1d894 esi=00000000 edi=00000000eip=779c0004 esp=0109ff74 ebp=0109ffa0 iopl=0nv up ei pl zr na pe nc
cs=0023 ss=002b ds=002b es=002b fs=0053 gs=002b efl=00000246ntdll!DbgBreakPoint:
779c0004cc int 3
Rotor里的异常处理
我看到了一些关于Rotor(和CLR)中使用的异常处理机制的问题。下面是关于Rotor异常处理的另一个注意事项列表。目的是帮助Rotor开发人员调试和理解CLR中的异常。
异常生成和抛出
此步骤在很大程度上取决于异常的类型以及从何处引发异常:
jitted代码中的软件异常---使用C#中throw new MyException(…)引发的异常
- 异常对象的创建方式与任何其他托管对象的创建方式相同
- vm\jitiface.cpp中调用JIT_Throw
- HelperFrame被推送以标记从jitted到EE代码的转换。这是可靠的stack walk工作所必需的——安全性和垃圾收集是可靠stackwalk的主要用户。
- vm\excep.cpp中调用了RaiseTheException
- 异常对象存储在当前线程对象中
- EXCEPTION_COMPLUS异常是使用Win32的RaiseException API引发的
执行引擎代码中的软件异常---在clr\src\vm目录中使用COMPlusThrow(…)引发异常
- 如果尚未提供给调用,则异常对象的创建方式与任何其他托管对象的创建方式相同
- vm\excep.cpp:RaiseTheException被调用,故事的其余部分与第一个案例相同。
- 注意:不需要推送任何转换框架
- 注意:在托管异常堆栈跟踪中不包含C++ stacttrace。
jitted代码中的硬件异常-如访问空对象、除以零等。
- 将调用jitted代码的异常处理程序。大多数时候它是vm\i386\excepx86.cpp:COMPlusFrameHandler。
- 异常被标识为直接来自vm\i386\excepx86.cpp:CPFH_HandleManagedFault中的jitted代码。
- 推送FaultingExceptionFrame以标记从jitted到EE代码的特殊转换。
- 使用vm\i386\excepx86.cpp:LinkFrameAndRow和关联的asm帮助程序重新引发异常。
对于Win32/i386 SEH,通过将IP修改为指向NakedThrowHelper的异常过滤器返回EXCEPTION_CONTINUE_EXECUTION来完成重新触发。
对于PAL_PORTABLE_SEH,通过简单调用LaunchNakedThrowHelper来完成重新触发。 - 第二次在异常过滤器中,为硬件异常创建正确类型的异常对象。硬件异常到BCL异常类型的映射在vm\excep.cpp:MapWin32FaultToCOMPlusException中完成。
- 注意:硬件异常重试是一个实现细节,它应该允许可继续的异常(异常继续执行)无缝工作。CLI目前不支持可延续的异常,但将来可能会有所改变。此外,可能存在一些互操作场景,其中异常继续执行非常重要。
- 注意:对于PAL_PORTABLE_SEH,硬件异常的重新触发是不同的,因为PAL不支持异常继续执行。稍后为调试器支持添加了异常继续执行。
执行引擎代码中的硬件异常
执行引擎代码中的硬件异常通常不应该发生。如果他们这样做了,通常意味着事情真的出了问题,需要大量的运气才能从这种情况中恢复过来。不过,这条规则有几个例外:
- 写入屏障帮助程序(vm\i386\jithelp.asm:JIT_write barrier and friends)中的访问冲突被转换为调用程序中的访问冲突。转换在vm\i386\excepx86.cpp:CPFH_AdjustContextForWriteBarrier中完成。这允许JIT在调用写回载波时优化空检查。FJIT当前不使用此功能。
- 尽管存在一些防止堆栈溢出异常(vm\stackprobe.h)的屏蔽,但它们可能发生在执行引擎代码中,这通常非常糟糕。这是为.NET v1设计的,CLR团队正在为Whidbey开发更好的解决方案。便携式堆栈溢出处理不在转子-我们只是死时堆栈溢出发生。可移植堆栈溢出处理的设计和实现留给读者练习
- 元数据代码用于访问监视(#define ZAP_MONITOR),以允许按配置文件引导的元数据布局优化。检测是通过使所有元数据访问A/V、记录它们并通过异常继续执行从它们恢复来完成的。(是的,这个解决方案的性能很差。)元数据工具不是作为Rotor的一部分提供的,但是必须记住它以避免代码损坏。
FCalls中的软件异常--使用FCThrow(…)及其类似调用引发的异常
Fcall闻起来像jitted代码,但实际上不是,因此Fcall中的异常处理是特殊的。
- 如果未推送helper框架,则使用FCThrow helpers从fcall抛出异常。(如果推送helperframe,则它是使用complushrow在执行引擎代码中抛出软件异常的简单方法)
- FCThrow helper使用特殊帧ATTR_CAPTURE_DEPTH_2推动辅助帧。因此,只能直接从FCALL调用FCThrow。不能从从FCALL调用的函数调用它。
- 一旦helper框架被推送,complushrow就会像执行引擎代码中的任何其他软件异常一样实际抛出异常。
- 注意:FCThrow只是HELPER_METHOD_FRAME_BEGIN(…);complusthrow(…);HELPER_METHOD_FRAME_END()的快捷方式。如果您看到了长代码模式,那么在尝试使用FCThrow对其进行优化时要小心—它可能是有原因的。fcall依赖于一个非常脆弱的x86解释器。这个翻译有时需要帮助.
可以看到,所有异常都转换为一个看起来像常规托管异常的统一案例。从托管代码引发的每个异常(无论是硬件异常还是软件异常)都会下放到Win32 RaiseException层。这样做是为了保持一致性。它被认为可以简化互操作性的实现。
处理异常
异常的处理遵循两次机会的Win32模型。
第一次,stackwalker为堆栈上的每个方法调用回调。一旦某个过滤器返回它处理异常,异常展开的第二次传递就开始了。
第二次,堆栈已展开。展开代码的结构在本机Win32 i386异常处理和PAL可移植异常处理之间有所不同。
异常和垃圾收集器
请注意,对RaiseException的调用是由EE代码发出的,并且此代码以协作模式运行。因此,在异常分派期间不会阻止垃圾收集。
异常和帧
帧的链接列表(Frame-vm\frames.h类的后代)与每个线程对象关联。这些是可靠的堆栈遍历基础设施的关键部分。执行引擎代码正在使用一种特殊的机制来释放异常时的链。COMPLUS-TRY/COMPLUS-CATCH宏(vm\exceptmacros.h)通过在异常时调用unwind frame chain(vm\excepp.cpp)来展开帧链。此外,这些宏还释放嵌套的异常信息(vm\excep.cpp:UnwindExInfo)并还原GC模式,这非常方便。
请注意,UnwindFrameChain正在访问已展开的堆栈空间。这是可行的,但它取决于堆栈展开的微妙的低级实现细节。由于Win32/i386 SEH和PAL_PORTABLE_SEH之间堆栈展开的低级实现细节不同,因此COMPLUS_TRY/COMPLUS_CATCH宏对于这两个宏是不同的。它还解释了为什么有必要在执行引擎中使用COMPLUS-TRY/COMPLUS-catch捕获异常,而不使用常规的PAL-TRY/PAL-catch除外。
CLR开发人员没有选择通过为类框架创建C++析构函数来解开帧链,这将是一个非常简单的解决方案。这可能是一个纯粹的历史遗留物;它们可能有一些性能童话;或者对象析构函数与结构化异常处理的混合,而MSC不支持的结构异常处理会在编写代码时造成太多的不适。
异常与C++对象展开
在异常解除时,PAL_PORTABLE_SEH 不调用堆栈上的对象的C++析构函数。这是可以的,因为执行引擎代码似乎没有利用当前的C++特性。嗯,我们还没有找到它依赖于被调用的C++的地方。这可能会因Whidbey而改变
异常和安全
由于存在安全隐患,因此从异常处理中正确执行堆栈遍历非常重要。对于过滤器来说,这是特别棘手的,因为在调用过滤器时,真正的堆栈是不展开的。在抛出异常到最后调用异常之间,可以调用来自堆栈上源代码的任意用户代码。
Rotor
如何与转储文件建立丰富多彩的关系
我每天都看很多转储文件。在这种情况下,我喜欢充分利用windbg可定制的外观和感觉。实际上,我在DMP文件和CMD文件之间有一个关联设置,每当我双击一个转储文件时,这个文件就会加载我自定义的颜色工作区。我喜欢有彩色源代码和调试命令窗口输出的黑色背景。
下面是我典型的调试会话的快照。

下面告诉你的设置方法。
- 创建以下CMD文件并将其放入您的路径中。在我的系统里叫D.CMD
echooff
Title kd.exe-z %1C:
CD\debuggers
start C:\Debuggers\windbg.exe-z %1 -W color用!htrace调试句柄泄漏的一般步骤
Windbg调试器的!htrace扩展对于调试泄漏处理非常方便。
该过程基本上可归结为以下简单步骤:- 启用跟踪
- 拍张快照
- 情景分析
- 显示差异
在第四步!htrace将在最后一个快照之后显示所有额外打开的句柄,以及调用堆栈(如果可用)。这大大有助于调试哪些句柄是泄漏的,以及由谁来处理。与其他任何资源泄漏检测工具一样,也会有误报。您需要了解什么是真正的泄漏,什么只是暂时的分配。