!eeheap -gc 和 !address输出的关联性
!address是一个非常强大的调试器命令。它向您显示了您的虚拟地址空间的确切分布。
如果你已经从!sos.eeheap -gc命令得到了输出,例如:
0:003> !eeheap -gc
Number of GC Heaps:1generation0 starts at 0x01245078generation1 starts at 0x0124100cgeneration2 starts at 0x01241000ephemeral segment allocation context: (0x0125a900, 0x0125b39c)
segment begin allocated size
001908c0 793fe120 7941d8a80x0001f788(128904)01240000 01241000 0125b39c 0x0001a39c(107420)
Largeobject heap starts at 0x02241000segment begin allocated size02240000 02241000 02243250 0x00002250(8784)
Total Size0x3bd74(245108)
——————————
GC Heap Size0x3bd74(245108)
在VMMap中跟踪不可用的虚拟内存
VMMap是一个很好的系统内部工具,它可以可视化特定进程的虚拟内存,并帮助理解内存的用途。它有线程堆栈、映像、Win32堆和GC堆的特定报告。有时,VMMap会报告不可用的虚拟内存,这与可用内存不同。下面是32位进程(总共有2GB虚拟内存)的VMMap报告示例:

这种“不可用”的内存从何而来,为什么不能使用?Windows虚拟内存管理器具有64KB的分配粒度。当直接用VirtualAlloc分配内存并要求小于64KB(比如16KB)时,VirtualAlloc返回64KB边界上的地址。然后分配前四页(16KB),其余48KB标记为未使用。无法通过执行另一个分配来获取此内存,因为VirtualAlloc将始终返回驻留在64KB边界上的地址。那么,这个内存是不可用的。
VMMap中的fragmentation视图使问题更加明显。在下面的屏幕截图中,黄点是4KB区域,可以分配和使用,而灰色矩形是60KB区域,不能使用。当整个地址空间都是这些不可用的区域时,你得到的虚拟内存就没有你想象的那么多了。
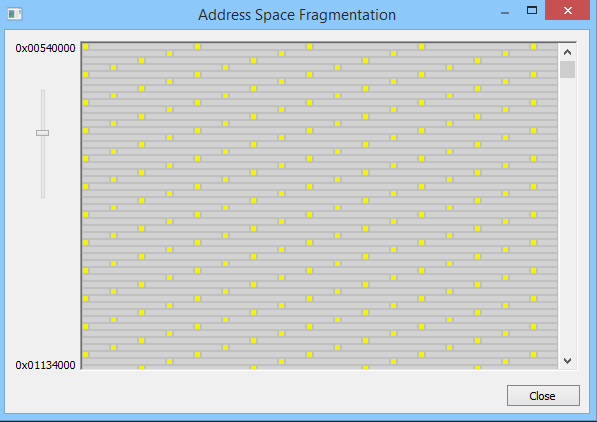
幸运的是,很容易找到违规分配的来源。本质上,我们正在寻找分配大小小于64KB(或者更好:不能被64KB平均整除)的VirtualAlloc调用。您可以使用VMMap本身(它具有跟踪模式)跟踪这些分配,也可以附加WinDbg并设置断点:
0:000> bm kernelbase!VirtualAlloc* "r $t0 = poi(@esp+8); .if (@$t0 % 0x10000 != 0) { .printf \"Unusable memory will emerge after allocating %d bytes\", @$t0; kb 4 } .else { gc }"
1: 76c03e8a @!"KERNELBASE!VirtualAllocExNuma"
2: 76bcd532 @!"KERNELBASE!VirtualAlloc"
3: 76c03e66 @!"KERNELBASE!VirtualAllocEx"
0:000> g
Unusable memory will emerge after allocating 4096 bytes
ChildEBP RetAddr Args to Child
00defd48 010a4e34 00000000 00001000 00003000 KERNELBASE!VirtualAlloc
00defe2c 010a5f25 00000000 00000000 7eaa7000 FourKBLeak!allocate_small+0x34
00deff18 010a6989 00000001 012ba870 012bae98 FourKBLeak!main+0x35
00deff68 010a6b7d 00deff7c 7529919f 7eaa7000 FourKBLeak!__tmainCRTStartup+0x199此断点确保传递给VirtualAlloc的分配大小可被64KB整除。否则,断点将停止并打印出有问题的分配和调用堆栈;否则,它将继续执行。这将使捕获小分配的源变得非常容易,并有望修复它们。
我的应用似乎卡死了。我该怎么办?
定义“卡死”是一个很好的起点。有时又叫"挂起",英文叫"hang"。
当人们说“卡死”时,他们可能意味着各种各样的事情。当我说“卡死”时,我的意思是进程没有进展——进程中的线程要么被阻塞(例如死锁,要么因为来自其他进程的线程而没有被调度),要么正在执行代码(疯狂地)但没有做有用的工作(例如无限循环,或者长时间忙于旋转而没有做有用的工作)。前者不使用CPU,后者使用100%CPU。当UI开发人员说“卡死”时,他可能意味着“UI没有被绘制”,所以本质上它们意味着UI线程不工作——它们进程中的其他线程可能正在做大量的工作,但由于UI没有更新,它看起来是“卡死”。因此,澄清你说“卡死”的意思是第一步,这需要你查看你的进程及其线程。
如果启动任务管理器,它显示每个进程当前使用的CPU数量。如果没有看到CPU列,可以通过单击View\Select Columns并选中“CPU Usage”复选框来添加它。
请注意,如果有多个CPU,则CPU使用率最多为100。假设您有4个CPU,并且您的进程有一个线程正在运行并占用了它所能使用的所有CPU,您将看到进程CPU列是25%—因为您的进程在任何给定时间只能使用一个CPU。
进程的CPU使用率计算为属于该进程的所有线程使用的CPU使用率。线程是在CPU上运行的东西。它们由操作系统调度器调度,后者决定何时在哪个处理器上运行哪个线程。
第一个场景
如果你看到你的进程占用了0个CPU,这就可以解释为什么它挂起(在CPU保持为0的时间段内)–没有线程可以在你的进程中运行!接下来要看的是其他进程的CPU使用情况。如果您看到一个或多个其他进程占用了所有CPU,这意味着您的进程中的线程根本没有机会运行—这是因为其他进程中的线程比您进程中的线程具有更高的优先级(或由于优先级提升而暂时具有更高的优先级)。可能的原因是:
1) 有些线程被标记为低优先级,它们获取了进程中其他线程运行所需的锁。低优先级线程被其他(正常或高)优先级线程从其他进程抢占。当人们错误地使用低优先级线程执行“不重要的工作”或“不需要及时完成的工作”时,就会发生这种情况,而没有意识到几乎不可能避免对这些线程进行锁定。我听说过很多人说“但我没有锁定低优先级线程”,这不是一个有效的论据,因为你调用的API或你使用的操作系统服务可以通过锁来运行你的代码——在本机NT堆上分配可以获得锁;即使触发页面错误也会导致锁(这不是应用程序开发人员可以在代码中控制的东西)。
2) 您的进程中的线程具有正常的优先级,但其他进程具有高优先级线程-这应该相对容易诊断(除非某些进程只是坏人,否则这种情况很少发生)–您可以查看这些进程正在做什么(再次查看其线程的调用堆栈是一个很好的开始)。
第二个场景
上面挂起的场景是您的进程占用了0个CPU,而CPU被同一台机器上的其他进程占用。下一个场景是您的进程占用了0个CPU,而这个CPU几乎不被其他进程使用。
正如一位同事正确地指出的,这很可能是因为您有一个死锁。通常,调试死锁是相对简单的——您可以查看线程在等待什么,并找出其他线程持有锁。如果您使用Windows调试器包,则会有内置的调试器扩展DLL来帮助您这样做,像!locks等命令。如果您正在调试托管应用程序,SoS调试器扩展有一些命令可以帮助您–!SyncBlk,向您显示托管锁(对于clr2.0和以后的版本,还有 !Dumpheap –thinlock用于使用ThinLocks而不是SyncBlk锁定的对象)。
另一种可能是进程没有执行任何与CPU相关的活动。一个常见的活动是IO—例如,如果进程大量分页,则CPU使用率几乎为0,但它似乎挂起,因为它所需的内存从磁盘加载,速度非常慢。进程监视器是一个非常有用的工具,它可以显示进程正在做什么。昨天我机器上的一个程序周期性地暂停——非常烦人。所以我使用了进程监视器,它告诉我这个程序会定期检查我是否在另一个程序中登录到我的帐户,因为我没有,它会让我登录,做一些事情然后注销我。挂起是因为等待网络IO。所以为了让它高兴,我自己登录,然后恼人的周期性挂起消失了。
第三个场景
现在,如果你的进程确实占用了CPU,那么它也可能会挂起——正如我上次提到的,这意味着不同的人有不同的事情。如果你有一个用户界面应用程序,这可能意味着用户界面没有被绘制;如果你有一个服务器应用程序,这可能意味着你的应用程序没有处理请求。所以你必须定义挂起对你意味着什么。我将以服务器应用程序不处理请求为例。通常服务器应用程序运行在专用计算机上。因此,让我们假设这里是这样的——在一台机器上运行一台服务器,服务器可能由多个进程组成。您可以通过吞吐量来衡量服务器性能。一种情况是CPU使用率很高(甚至比平时更高),但吞吐量比平时低。
最简单的情况是无限循环,非常容易调试。你用调试器中断几次,发现一个线程占用了所有的CPU,而这个线程无法退出某个函数——于是你的无限循环就出现了。如果这个进程很明显的使用了你的CPU。如果您有多个cpu,而其他进程也在使用cpu,则会变得更加复杂。但由于它是一个无限循环,所以如果你不干涉它,它就会一直在执行,所以一旦发生,你就可以随时进行调查。
异常STATUS_FATAL_APP_EXIT(0x40000015)
简介
STATUS_FATAL_APP_EXIT,值为0x40000015。代表的意思是"致命错误,应用退出"。它定义在 ntstatus.h头文件里,如下:
//
// MessageId: STATUS_FATAL_APP_EXIT
//
// MessageText:
//
// {Fatal Application Exit}
// %hs
//
#define STATUS_FATAL_APP_EXIT ((NTSTATUS)0x40000015L) // winnt
触发条件
应用关闭期间,应用程序产生了未处理的运行时异常。如果您自己不处理这些运行时异常,则实际上某些运行时异常会被默认处理,而这些默认处理程序中的有一些会调用abort()。默认情况下,就是中止调用:
_call_reportfault(_CRT_DEBUGGER_ABORT, STATUS_FATAL_APP_EXIT, EXCEPTION_NONCONTINUABLE);abort是一个通用的终止-它不知道是什么特定的异常促使它被调用,因此出现了通用的“未知软件异常”消息。常见的情况是是通过pure call异常-调用未实现的纯虚拟调用。
异常结构填充
ExceptionAddress: 0x0f3db2b2{msvcr120.dll!abort(void),Line90}
ExceptionCode: 40000015//错误代码
ExceptionFlags: 00000001
NumberParameters: 0//附加参数个数,根据经验来看,abort函数里引发的一般都是0
使用正确的工具进行调试
当你需要调试/调查问题时,我想指出的一个非常强大的工具是你的调试器(如果你的调试器也是windbg/cdb,那就是对了,因为这就是我要用的,这也是我在本文中将要讨论的)。
对于那些对研究内存相关问题感兴趣的人来说,无论是因为你不喜欢当前应用程序的内存使用情况,还是只是想提高,学习使用调试器都是非常宝贵的。如果您还没有开始使用windbg/cdb,我强烈建议您–我保证您不会后悔的。
我以前说过使用SoS,在V4.0中添加了更多的SoS命令,其中一些与GC相关,像!AnalyzeOOM,!GCWhere 和 !FindRoots。你可以在MSDN页面上看到它们。但我想谈谈一些从阅读参考资料中看不到的技巧。
当你的程序是GC时,你想知道什么是最常见的两件事吗?
1) 为什么触发GCs?
2) 为什么GCs要花这么多时间?
答案分别是:
1) GC前后堆的差异
2) 那个GC的幸存者
让我详细解释一下。每一次都有自己的分配预算,我在这里解释了这一点。这是一个我们设置的值,当超过这个值时,我们想要触发一个GC。如果我们做了一个收集,发现有很多内存存留下来,我们会把这个分配预算设置得非常大,这意味着您需要为该代分配更多的内存,这样我们才能触发GC。其基本原理是,这样我们下次进行GC时就有机会回收一些相当大的空间。否则,我们将为GC做所有这些工作,而不能找到太多的死内存。
所以在GC之前,如果你运行!dumpheap,你可以看到你有什么对象;然后在GC之后你在运行!dumpheap,你会看到其中一些对象消失了。正是这些对象触发了这个GC。为什么?因为如果我们没有任何物体消失,我们就不会做GC(因为我们不会得到死内存)。
到目前为止,CLR-GC还没有压缩LOH。因此,如果你想看看LOH,你可以确切地看到内存的哪些部分消失了。下面是gen2gc前后堆范围的示例输出。在gen2gc之前(我格式化了!dumpheap,将methodtable指针替换为可读名称的)
Address MethodTable Size
————————————————–
00000007f7ffe1e0 System.Byte[]2,080,00000000007f81f9ee0 System.String100,00000000007f8212580 System.Byte[]140,000After this gen2 GCforthe same heap range:
Address MethodTable Size
————————————————–
00000007f7ffe1e0 Free2,320,000