详细说说在Vistual studio IDE里使用SOS.dll扩展调试程序
通常,我写的问题只在生产环境中表现出来,每次执行某个操作时,您不能在受控开发环境中真实再现这些问题。在这些情况下,您需要使用windbg之类的工具来收集转储并进行事后调试。Windbg对于这些类型的问题非常有效,但它有其缺点,因为它不是真正的托管调试器,所以在.NET代码中设置断点或单步执行代码,甚至像在visual Studio这样的托管调试器中那样以可视方式检查对象都要困难得多。
另一方面,Visual Studio不允许您像windbg那样进行事后调试,而且没有简单的方法可以查看进程中加载的域的信息或查看.net堆上的对象的信息。
我的同事遇到了一个很容易重现的问题,但他需要两个世界,即从代码到一个特定的点,可视化地查看堆栈上的对象,同时他需要查看堆上的内容,因此他求助于附加两个调试程序,管理visual studio调试和windbg调试与sos一起原生以查看托管堆。这是相当恶劣的,有一个更容易的方法来结合这两个世界。。。在Visual Studio中使用sos进行调试。
有很多网友看了我的《VisualStudio中集成扩展调试SOS》,说不够细,确实那篇随笔只是大致讲了主要的步骤,很多的朋友是在卡在第二步,也就是对立即窗口的使用。
下面我将使用Visual Studio来向您展示如何在其中加载sos并运行sos命令。
步骤一:为项目启用本机调试
为了加载类似于SOS.dll文件您必须在本机模式下进行调试,因此在启动调试器之前,请进入项目上下文菜单上的Project/Properties/Debug,并选中“启用非托管代码调试”复选框。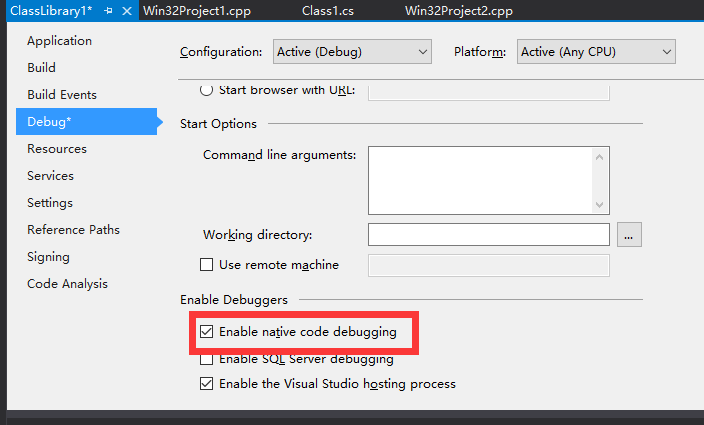
步骤二:调试并中断
像在Visual Studio中一样调试问题,直到重现问题为止。
中断进程(调试菜单/全部中断)
步骤三:加载SOS.dll扩展
为了装载sos.dll文件你必须打开“立即”窗口(Debug/Windows/Immediate or Ctrl+D, I),并输入如下命令:
.load C:\WINDOWS\Microsoft.NET\Framework\v4.0.30319\sos.dll
若执行成功,会输出:
extension C:\WINDOWS\Microsoft.NET\Framework\v4.0.30319\sos.dll loaded
个人试验,VS2013里,加载2.0版本成功率高,4.0版本多半失败
步骤四:用sos扩展命令开始调试你的问题
NET PDB文件到底包含多少秘密?
虽然我希望.NET PDB文件与本地PDB文件处理方式相同,但我们在这件事上没有任何选择,因为事情就是这样。我相信微软的调试器团队多年来听到过很多类似帕特里克的评论。也许我们会在未来的Visual Studio版本中看到所有问题都得到解决。
帕特里克非常幸运能够通过VPN远程调试到客户机器中。我相信你们大多数读者都会喜欢这样的场景!对于我们大多数人来说,只要让用户/管理员打开日志并将输出发送给我们,就和登月旅行一样困难。
本机二进制PDB文件非常敏感。正如我在关于PDB文件的原始文章中指出的,本机PDB文件包含以下数据(如果它们没有被剥离):
- 公共、私有和静态函数地址
- 全局变量名称和地址
- 参数和局部变量的名称和偏移在堆栈上的位置
- 由类、结构和数据定义组成的类型数据
- 帧指针省略(FPO)数据,这是在x86上进行本机堆栈遍历的关键
- 源文件名及其行
如果你把这些文件交给一个客户,你已经给了他们所有缺少源文件的东西。事实上,使用完整的本地PDB文件,使用公共DBGHELP符号API编写一个工具来编写一个重新创建头文件的工具并不难。如果你重视你的工作,你永远不想让你的本地PDB文件泄漏相关信息。
另一方面,.NET PDB文件只包含以下信息:
- 源文件名及其行
- 局部变量名
那么调试器如何知道所有关于.NET类型的信息呢?从二进制文件中的元数据来看,不需要在.NET PDB文件中复制元数据。.NET的优点是“自描述对象”,因此您需要更多有关二进制文件中类型的信息。元数据是如何使用反射加载以前从未见过的二进制文件并开始实例化其类型。正如您可以想象的,这意味着由于相同的元数据,将.NET二进制文件直接反编译回您选择的首选语言并不太难。选择.NET的易用性意味着你必须放弃一些东西,因为没有免费的午餐。
因为.NET PDB文件不包含任何敏感的内容,我说给他们自由!在Patrick的例子中,我将把.NET PDB文件给客户,这样他就可以对本机和.NET进行远程调试。所有源文件都加载在运行Visual Studio UI的本地计算机上,因此您不会放弃这些文件。
先发制人的评论攻击:是的,如果你做了一些疯狂的蠢事,比如在你的构建路径中嵌入域名和登录密码,这将显示在你给客户的.NET PDB文件中。我说的是正常的情况<big smile!>
实际上,我建议您为.NET PDB文件创建一个安装程序,以便可以将它们安装到与二进制文件相同的目录中。调试器(本地或远程)总是首先在加载二进制文件的目录中查找匹配的.NET PDB文件。要求您的客户手动将每个.NET PDB文件复制到适当的目录是一个灾难的秘诀。安装程序是好事,尽管Windows安装程序API有点麻烦。
让我将创建.NET PDB文件安装程序的“推荐”改为“强烈推荐”。您是否注意到开发机器上未处理的异常与测试或客户机器上的异常之间有一个有趣的区别?当您查看开发机器上未处理的异常时,您会看到调用堆栈以及一些非常有用的信息:调用堆栈中每个项的源和行。在开发计算机上,本地生成PDB文件与二进制文件位于同一目录中,异常类中的.NET StackTrace字段会自动读取它们以获取源和行信息。当你有一个写300行方法的同事时,准确的行在调用堆栈中有很大的帮助。
通过.NET PDB文件安装程序,您可以让复制未处理异常的客户安装符号,这样当您将异常转储到日志时,您就得到了源代码和行代码。这就是我所说的快速调试!
请记住,抛出的每个异常都使用StackTrace类,因此在计算调用堆栈时,由于符号查找,性能会受到一些影响。正如您可以猜到的,有许多变量会影响性能,所以我不能给您一个确切的数字,但事实上,您将在堆栈中拥有确切的源代码和代码行,这意味着您将更快地调试问题,这最终是性能的最终改进。
简单聊下c#异常处理
在 .NET 中异常处理是一个庞大的模块,专门用来处理程序中的已知可捕获异常,这篇文章我将详细讲解异常处理的细节性的东西,其中包含了异常处理类型、自定义异常处理、多 catch 的异常处理以及异常处理的依赖。
一、异常处理类型
C# 允许我们编写的代码抛出从System.Exception派生的任何异常类型(这其中包括了间接派生和直接派生)。例如下面的代码段:
public class Demo{publicint StringToNumber(string para){string[] numberArray={"零","一","二","三"};int number = Array.IndexOf(numberArray,(para??throw new ArgumentNullException(nameof(para))));if (number <0){throw new ArgumentException("参数值无法转换为数字",nameof(para));}return number;}}
上述代码使用了throw关键字抛出了异常,并且使用了特定的异常类型说明了发生异常的背景。在代码中我们只用到了 C# 7.0 的新特性throw 表达式,在 para 为 null 时会抛出ArgumentNullException异常,当 number 的值小于 0 的时候我们并没有抛出Exception类型的异常,而是抛出了更能明确告知异常原因的ArgumentException类型的异常。我们从代码中可以看到,当 para 参数为 null 时抛出的是 ArgumentNullException 类型的异常而不是 NullReferenceException 类型的异常。
对于这两个类型的异常好多开发人员其实并不清楚它俩的区别。其实它俩的区别还是很简单的, ArgumentNullException 是在错误的传递了空值时抛出的,如果传递的是非空的无效参数则必须使用 ArgumentException 或者 ArgumentOutOfRangeException 。如果是底层运行时发现对象的值为空的时候才会抛出 NullReferenceException 类型的异常,这个异常一般来说开发人员不能随意抛出,我们应该先判断参数是否为空之后再使用参数,如果为空就抛出 ArgumentNullException 异常。
除了 NullReferenceException 异常外,还有五种派生自System.SystemException的异常不能自己抛出,只能有运行时抛出,它们分别是System.StackOverflowException、System.OutOfMemoryException、System.Runtime.InteropServices.COMException、System.ExecutionEngineException和System.Runtime.InteropServices.SEHException。
同样,开发人员尽量不在程序代码中抛出Exception和ApplicationException异常,因为它们所反映出来的异常过于笼统,没法为异常提供明确的信息。
在实际项目开发中有可能会遇到代码执行到一定程度就会出现不安全或者无法恢复的状态,这时代码大多数情况下不会出现异常,因此我们在这种情况下就必须调用System.Environemnt.FailFast方法终止程序,这个方法会向实践日志写入一条消息之后马上终止程序进程。前面的代码中我们还使用了nameof操作符,使用这个操作符首先是因为我们可以利用重构工具方便的自动更改标识符,另外如果参数名发生了变化我们能及时收到编译错误。
针对这一节的内容我来做一个简单的总结:
成员接收到错误的参数时应当抛出 ArgumentException 异常或者它的子类型异常;在抛出 ArgumentException 异常或者子类型异常时必须设置 ParamName 属性,也就是 nameof;抛出的异常必须能明确表示异常的问题;避免在意外获得空值时抛出 NullReferenceException 异常;不要抛出 System.SystemException 及其派生的异常;不要抛出 Exception 和 ApplicationException 异常;如果程序出现不安全因素时必须调用 System.Environemnt.FailFast 方法来终止程序的运行;要向传给参数异常类型的 ParamName 使用 nameof 操作符Tip:参数异常类型包括 ArgumentNullException 、ArgumentNullException 、ArgumentOutOfRangeException
二、捕获异常处理
捕获异常处理这一节比较简单,主要需要了解并掌握的是多 catch 块和异常类型的顺序问题以及 when 子句。
多 catch 块多个 catch 块在 C# 中是比较常见的,我们前面一节说过抛出的异常必须能明确表示异常的问题,因此我们可以利用多 catch 块解决一个代码段中有可能出现的多种异常的情况,每个 catch 块针对一种异常情况进行处理。我们来看一个简单的代码段:上述代码中我们一共定义了 5 个 catch 块,当发生异常时会被对应的 catch 块拦截并处理。这一小节就这么简单,主要是多 catch 块的使用,下一小节我将讲解 catch 块最重要的内容。void OpenFile(string filePath){try{//more code}catch(ArgumentNullException ex){//more code}catch(DirectoryNotFoundException ex){//more code}catch(FileNotFoundException ex){//more code}catch(IOException ex){//more code}catch(Exception ex){//more code}}异常类型的顺序异常类型的顺序是很多初学者甚至是部分多年的老程序员会犯的问题,我们从前面的代码中也可以看到 Exception 异常位于最后的位置, IOException 位于倒数第二的位置,这是因为 Exception 异常是所有异常的父类,所有的异常都是直接或间接派生自它,而 IOException 又是 DirectoryNotFoundException 和 FileNotFoundException 的父类。根据异常匹配的顺序,C# 会始终匹配第一个符合要求的异常,如果将父类异常放在子类异常的前面,那么再代码出现异常的时候回直接匹配父类异常的 catch ,不再去匹配后面的子类异常 catch 。Tip:不管在什么情况下都必须把 Exception 异常作为最后的 catch ,当程序中出现的异常没有匹配任何 catch 块时可以被 Exception catch 块拦截并处理when 子句从 C# 6.0 开始, catch 块支持条件表达式,这样我们可以不根据异常类型来匹配程序中出现的异常。When 子句返回的时一个布尔值,当返回 true 时 catch 块才会执行。我们来看一个使用 when 子句的例子:不过我们也可以在 catch 块中使用 if 语句执行上面的条件检查,但是这样做的话整个 catch 块的逻辑就变为先成为异常处理程序,再进行条件判断,进而造成了在不满足条件的情况下无法去执行别的符合要求的 catch 块。如果使用了 when 子句程序就可以先检查条件,在决定是否执行 catch 块。但是 when 自己也有需要注意的地方,如果 when 子句中抛出了异常,那么这新的异常就会被忽略并且整个 when 子句返回值将变为 false 。try{//more code}catch(Win32Exception ex) when (ex.NativeErrorCode==42){//more code}重新抛出异常这里在简单说一下异常的重新抛出,有些开发人员喜欢在 catch 块中写这段语句throw ex。这段语句存在一个致命的问题,在 catch 块中这么写将会抛出一个新的异常,那么将会造成所有的栈信息被更新进而丢失最初的栈信息造成难以定位问题。因此 C# 开发团队设计出了可以不指定具体异常的方法,就是在 catch 块中直接使用 throw 语句。这样我们就可以判断当前 catch 块是否可以处理这个异常,如果不能就讲原始栈信息抛出去。三、常规 catch
C# 要求代码抛出的任何对象都必须从 Exception 派生,从 C#2.0 开始,不管是不是从 Exception 派生的所有异常在进入程序集之后,都会被打包成从 Exception 派生的。结果是捕捉 Exception 的 catch 块现在可捕捉前面的块不能捕捉的所有异常。
简述C# 还支持常规 catch 块,即 catch{} ,它的行为和 catch(Exception ex) 块的行为一样,唯一不同的是它不具备类型名和变量名。同样它也必须位于所有 catch 块的末尾。在代码中如果同时存在常规 catch 块和 catch(Exception ex) 块编译器就会显示警告,因为程序会永远匹配 catch(Exception ex) 块而不去匹配常规 catch 块。之所以 C# 中出现常规 catch 块的原因是因为如果程序中存在调用的别的语言开发的程序集,并且该程序集在使用过程中抛出了异常,那么这个异常是不会被 catch(Exception ex) 块所拦截,而是进入到未处理状态,为了避免这个问题 c# 就推出了常规 catch 块。Tip:虽然常规 catch 块具有强大的功能,但是它依然存在一个问题。它不具备一个可供访问的异常实例,所以无法确定异常是无害的还是有害于程序的。
原理常规 catch 所生成的 CIL 代码是 catch(object),这就说明不管抛出什么类型它都可以捕获得到。虽然生成的 CIL 代码是 catch(object),但是我们不能在代码中直接这么写。常规 catch 块无法捕获不是派生自 Exception 的异常,因此 C# 在设计的时候将所有来自其他语言的异常都统一设置为System.Runtime.InteropServices.SEHException异常,因此常规 catch 块既能捕获继承自 Exception 的异常,又能捕获非托管代码的异常。四、规范
异常处理规范不是由微软所规定的,而是开发人员在千千万万的项目中总结出来的,下面我们来看一下。
只捕获可以处理的异常通常我们只处理当前代码可以处理的异常,而不能处理的异常将会抛出去,让栈中层级高的调用者去处理。不隐藏无法处理的异常这个问题会发生在刚刚从事开发的人员身上,他们会捕获所有异常即不处理也不抛出。这种情况下如果系统出现问题那么将逃过检测。少用 Exception 和常规 catch 块所有的异常都是继承自 Exception ,因此使用 Exception 来处理异常并不是一个最优方法,而且某些异常需要马上关闭程序进程。避免在调用栈较低的位置报告或记录异常大部分调用栈较低的位置无法完整处理异常,所以只能抛出异常,并且如果在这些位置记录异常并且再抛出异常会造成异常的重复记录。无法处理异常时,因使用 throw 而不是 throw ex抛出一个新的异常会造成栈追踪重置为重新抛出的位置,而不是重用原始抛出位置。因此如果不需要重新抛出不同的异常类型或者不是想故意隐藏原始调用栈,就应使用 throw ,允许相同的异常在调用栈中向上传播。避免在 catch 块中重新抛出异常如果在开发中发现捕获的异常不能完整或恰当的处理,并且需要抛出异常那么我们就需要重新优化捕获异常的条件。避免在 when 子句中抛出异常when 子句抛出异常会造成表达式的结果变为 false,进而不能运行 catch 块。避免以后 when 子句条件改变这种情况常见于异常会因本地化而改变,那么这是我们将不得不改变 when 子句的条件。五、自定义异常处理
一般来说抛出异常时我们应该使用 c# 为我们提供的异常类型。但是某些情况下我们还需自定义异常,例如我们编写的 API 是由其他语言开发人员调用的,这时我们就不能抛出自己所使用的语言的异常,应该自定义异常让调用者清晰明了的知道发什么么错误。
自定义异常一般都是从 Exception 或者其他异常类派生出来,这是唯一的要求。自定义异常还必须遵循如下三点要求:
异常名称以 Exception 结尾;必须包含无参构造函数、包含唯一一个参数类型为 string 的构造函数和同时获取一个字符串以及一个内部异常作为参数的构造函数;集成层次不能大于 5 层。部分程序要求异常可以序列化,这时我们可以使用可序列化异常。我们只需要在自定义异常类型上加上 System.SerializableAttribute特性或实现ISerializable,然后添加一个构造函数来获取 SerializationInfo 和 StreamingContext 。这里需要注意的是如果你使用的是 .NET Core 2.0 以下版本那么将无法使用可序列化异常。
六、总结
本篇文章讲解了一下 C# 中的异常处理,这里我需要提醒各位的是抛出异常会影响程序的性能,它加载和处理大量额外的运行时栈信息,整个过程会花费可观的时间,因此我们在编写程序时应尽量避免大量使用抛出异常。
关于System.ArgumentNullException异常
什么是ArgumentNullException
当将 null 引用(Visual Basic 中为 Nothing)传递到不接受其作为有效参数的方法时引发的异常。
- 继承
Object错误模型(二)
Bug是不可恢复的错误
我们早期所做的一个重要区别是可恢复错误和错误之间的区别:
- 可恢复的错误通常是编程数据验证的结果。一些法典审查了世界状况,认为这种情况不可接受,无法取得进展。可能是一些正在解析的标记文本、来自网站的用户输入,或者是暂时的网络连接失败。在这些情况下,程序有望恢复。编写这段代码的开发人员必须考虑在失败时应该做什么,因为无论您做什么,它都会发生在构造良好的程序中。响应可能是将情况告知最终用户、重试或完全放弃操作,但是这是一种可预测的、经常是计划好的情况,尽管被称为“错误”
- Bug是一种程序员没想到的错误。输入没有正确验证,逻辑写错了,或者出现了许多问题。这样的问题通常都不会被及时发现;需要一段时间才能间接观察到“二次效应”,这时可能会对程序的状态造成重大损害。因为开发商没想到会发生这种事,所以所有的赌注都没有了。此代码可以访问的所有数据结构现在都是可疑的。因为这些问题不一定能及时发现,事实上,更多的问题值得怀疑。依赖于语言的隔离保证,也许整个过程都被污染了。
这种区别是最重要的。令人惊讶的是,大多数系统并不能产生一个,至少在原则上不是这样的!如上所述,Java、C#和动态语言只对所有内容使用异常;C和Go使用返回代码。C++使用的是一个取决于观众的混合,但通常的故事是一个项目选择一个单独的并且到处使用它。但是,您通常听不到语言建议使用两种不同的错误处理技术。
考虑到bug本质上是不可恢复的,我们没有尝试。在运行时检测到的所有错误都会导致所谓的终止,也就是所谓的“快速失败”。
上述每个系统都提供了类似于放弃的机制。C#有环境.FailFast,C++有std::terminate;等等。每一个都突然而迅速地撕开周围的背景。这个上下文的范围取决于系统——例如,C和C++终止进程。尽管我们确实以一种比普通人更规范、更普遍的方式使用放弃,但我们肯定不是第一个认识到这种模式的人。哈斯克尔的这篇文章很好地阐明了这一区别:
我参与了一个用C++编写的图书馆的开发。一位开发人员告诉我,开发人员分为喜欢异常的和喜欢返回代码的两类。在我看来,返回码的朋友赢了。然而,我得到的印象是,他们争论了错误的一点:异常和返回代码同样具有表现力,但是它们不应该用来描述错误。实际上,返回代码包含数组索引超出范围等定义。但是我想知道:当我的函数从一个子例程获取这个返回代码时,它应该如何反应?它要给它的程序员发一封信吗?它可以依次将此代码返回给调用方,但也不知道如何处理它。更糟糕的是,由于我无法对函数的实现进行假设,我不得不期望每个子例程都有一个超出范围的数组索引。我的结论是数组索引超出范围是一个(编程)错误。它不能在运行时处理或修复,只能由开发人员修复。因此不应该有相应的返回代码,而是应该有断言。放弃细粒度的可变共享内存作用域是可疑的,比如Goroutines或threads之类的,除非您的系统以某种方式保证所造成的潜在损害的作用域。不过,这些机制是伟大的,我们有使用!这意味着在这些语言中使用废弃规则确实是可能的。
然而,这种方法要在规模上取得成功,有一些架构元素是必要的。我敢肯定你在想“如果我每次在我的C#程序中出现空引用时都抛出整个过程,我会有一些非常恼火的客户”;同样地,“那根本就不可靠!”!“事实证明,可靠性可能不是你想的那样。可靠性、容错性和隔离性
在我们进一步讨论之前,我们需要陈述一个中心信念:史无前例。
建立一个可靠的系统
普遍的看法是,你通过系统地保证失败永远不会发生来建立一个可靠的系统。直觉上,这很有道理。有一个问题:在极限,这是不可能的。如果你能像许多任务关键型实时系统一样,仅在这处房产上就花费数百万美元,那么你就可以取得重大进展。或许可以使用SPARK这样的语言(Ada的一组基于契约的扩展)来正式证明所写每一行的正确性。然而,经验表明,即使是这种方法也不是万无一失的。
我们没有反抗生活的现实,而是拥抱它。显然,你会尽可能地消除失败。错误模型必须使它们透明且易于处理。但更重要的是,你设计你的系统,这样即使个别部分出现故障,整个系统仍能正常工作,然后教你的系统优雅地恢复那些故障部分。这在分布式系统中是众所周知的。那为什么是小说呢?
最重要的是,操作系统只是一个由协作进程组成的分布式网络,就像一个由微服务或互联网本身组成的分布式集群。主要的区别包括延迟、可以建立的信任级别和容易程度,以及关于位置、标识等的各种假设,但是在高度异步、分布式和I/O密集型系统中,失败是必然发生的。我的印象是,在很大程度上,由于单片内核的持续成功,整个世界还没有实现“操作系统作为分布式系统”的飞跃。然而,一旦你这样做了,很多设计原则就会变得显而易见。
与大多数分布式系统一样,我们的体系结构假定过程失败是不可避免的。我们花了大量的时间来防止层叠故障,定期记录日志,并实现程序和服务的可重启性。
当你假设这一点的时候,你会以不同的方式构建事物。
特别是,隔离是至关重要的。系统的流程模型鼓励轻量级细粒度隔离。因此,程序和现代操作系统中通常的“线程”是独立的独立实体。防止一个这样的连接失败比在地址空间中共享可变状态要容易得多。孤立也鼓励简单。巴特勒·兰普森(Butler Lampson)的《计算机系统设计经典提示》(Hinks on Computer System Design)探讨了这个话题。我一直很喜欢霍尔的这句话: