鸿蒙NEXT开发案例:随机数生成
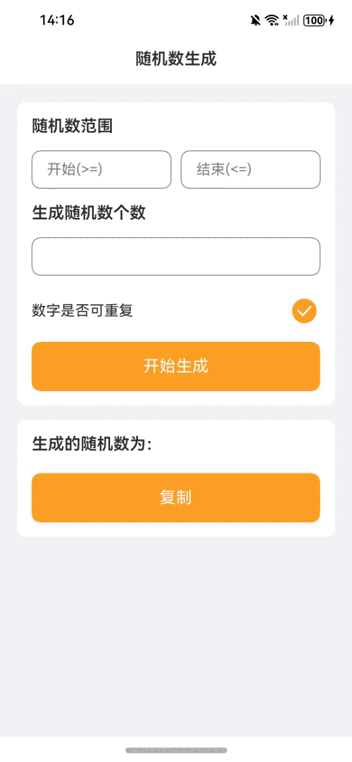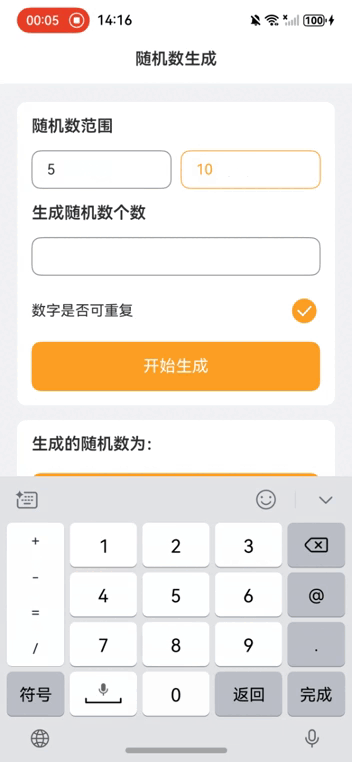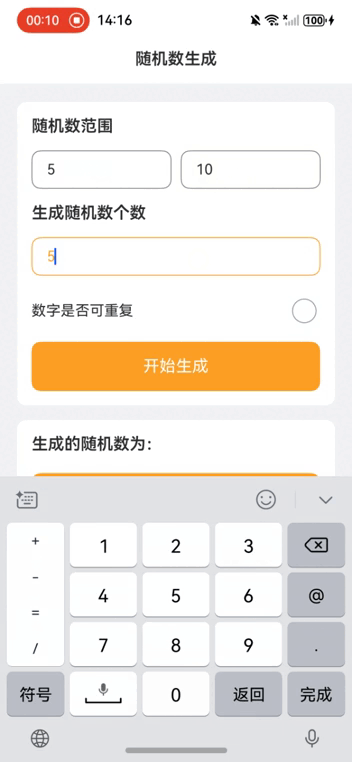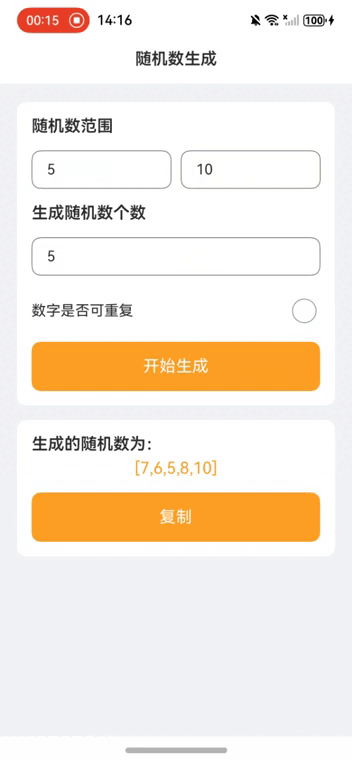
【引言】
本项目是一个简单的随机数生成器应用,用户可以通过设置随机数的范围和个数,并选择是否允许生成重复的随机数,来生成所需的随机数列表。生成的结果可以通过点击“复制”按钮复制到剪贴板。
【环境准备】
• 操作系统:Windows 10
• 开发工具:DevEco Studio NEXT Beta1 Build Version: 5.0.3.806
• 目标设备:华为Mate60 Pro
• 开发语言:ArkTS
• 框架:ArkUI
• API版本:API 12
【关键技术点】
1. 用户界面设计
用户界面主要包括以下几个部分:
• 标题栏:显示应用名称。
• 输入框:用户可以输入随机数的起始值、结束值和生成个数。
• 开关:用户可以选择生成的随机数是否允许重复。
• 生成按钮:点击后生成随机数。
• 结果显示区:显示生成的随机数,并提供复制功能。
2. 随机数生成算法
随机数生成是本项目的重点。根据用户是否允许生成重复的随机数,算法分为两种情况:
2.1 不允许重复
当用户选择不允许生成重复的随机数时,程序使用一个 Set 来存储生成的随机数,利用 Set 的特性自动去重。具体步骤如下:
1)计算范围:计算用户指定的随机数范围 range = endValue - startValue + 1。
2)生成随机数:使用一个临时数组 tempArray 来辅助生成不重复的随机数。每次生成一个随机索引 randomIndex,从 tempArray 中取出或计算一个新的随机数 randomNum,并将其添加到 Set 中。
3)更新临时数组:将 tempArray 中末尾的元素移动到随机位置,以确保下次生成的随机数仍然是唯一的。
if (!this.isUnique) {
if (countValue > range) {
// 显示错误提示
this.getUIContext().showAlertDialog({
title: '错误提示',
message: `请求的随机数数量超过了范围内的总数`,
confirm: {
defaultFocus: true,
value: '我知道了',
fontColor: Color.White,
backgroundColor: this.primaryColor,
action: () => {}
},
onWillDismiss: () => {},
alignment: DialogAlignment.Center,
});
return;
}
for (let i = 0; i < countValue; i++) {
let randomIndex = Math.floor(Math.random() * (range - i));
let randomNum = 0;
if (tempArray[randomIndex] !== undefined) {
randomNum = tempArray[randomIndex];
} else {
randomNum = startValue + randomIndex;
}
generatedNumbers.add(randomNum);
if (tempArray[range - 1 - i] === undefined) {
tempArray[range - 1 - i] = startValue + range - 1 - i;
}
tempArray[randomIndex] = tempArray[range - 1 - i];
}
this.generatedNumbers = JSON.stringify(Array.from(generatedNumbers));
}
3. 剪贴板功能
为了方便用户使用,程序提供了将生成的随机数复制到剪贴板的功能。具体实现如下:
private copyToClipboard(text: string): void {
const pasteboardData = pasteboard.createData(pasteboard.MIMETYPE_TEXT_PLAIN, text);
const systemPasteboard = pasteboard.getSystemPasteboard();
systemPasteboard.setData(pasteboardData);
promptAction.showToast({ message: '已复制' });
}
【完整代码】
// 导入剪贴板服务模块,用于后续实现复制功能
import { pasteboard } from '@kit.BasicServicesKit';
// 导入用于显示提示信息的服务
import { promptAction } from '@kit.ArkUI';
// 使用装饰器定义一个入口组件,这是应用的主界面
@Entry
@Component
struct RandomNumberGenerator {
// 定义基础间距,用于布局中的间距设置
@State private baseSpacing: number = 30;
// 存储生成的随机数字符串
@State private generatedNumbers: string = '';
// 应用的主题色
@State private primaryColor: string = '#fea024';
// 文本的颜色
@State private fontColor: string = "#2e2e2e";
// 输入框是否获取焦点的状态变量
@State private isFocusStart: boolean = false;
@State private isFocusEnd: boolean = false;
@State private isFocusCount: boolean = false;
// 是否允许生成的随机数重复
@State private isUnique: boolean = true;
// 随机数生成的起始值
@State private startValue: number = 0;
// 随机数生成的结束值
@State private endValue: number = 0;
// 要生成的随机数个数
@State private countValue: number = 0;
// 生成随机数的方法
private generateRandomNumbers(): void {
const startValue = this.startValue; // 获取当前设定的起始值
const endValue = this.endValue; // 获取当前设定的结束值
const countValue = this.countValue; // 获取当前设定的生成个数
const range: number = endValue - startValue + 1; // 计算生成范围
// 用于存储生成的随机数
const generatedNumbers = new Set<number>(); // 使用Set来自动去重
const tempArray: number[] = []; // 临时数组,用于辅助生成不重复的随机数
// 如果不允许重复,则使用去重算法生成随机数
if (!this.isUnique) {
// 如果请求的随机数数量超过了范围内的总数,则显示错误提示
if (countValue > range) {
this.getUIContext().showAlertDialog({
title: '错误提示',
message: `请求的随机数数量超过了范围内的总数`,
confirm: {
defaultFocus: true,
value: '我知道了',
fontColor: Color.White,
backgroundColor: this.primaryColor,
action: () => {} // 点击确认后的回调
},
onWillDismiss: () => {}, // 对话框即将关闭时的回调
alignment: DialogAlignment.Center, // 对话框的对齐方式
});
return;
}
for (let i = 0; i < countValue; i++) {
let randomIndex = Math.floor(Math.random() * (range - i)); // 在剩余范围内选择一个随机索引
let randomNum = 0;
if (tempArray[randomIndex] !== undefined) { // 如果索引位置已有值,则使用该值
randomNum = tempArray[randomIndex];
} else {
randomNum = startValue + randomIndex; // 否则计算新的随机数
}
generatedNumbers.add(randomNum); // 添加到Set中,自动去重
if (tempArray[range - 1 - i] === undefined) { // 更新末尾元素的位置
tempArray[range - 1 - i] = startValue + range - 1 - i;
}
tempArray[randomIndex] = tempArray[range - 1 - i]; // 将末尾元素移到随机位置
}
// 将生成的随机数转换成JSON格式的字符串
this.generatedNumbers = JSON.stringify(Array.from(generatedNumbers));
} else {
// 如果允许重复,则直接生成随机数
for (let i = 0; i < this.countValue; i++) {
let randomNumber = this.startValue + Math.floor(Math.random() * (this.endValue - this.startValue));
tempArray.push(randomNumber);
}
// 将生成的随机数转换成JSON格式的字符串
this.generatedNumbers = JSON.stringify(tempArray);
}
}
// 将生成的随机数复制到剪贴板的方法
private copyToClipboard(text: string): void {
const pasteboardData = pasteboard.createData(pasteboard.MIMETYPE_TEXT_PLAIN, text); // 创建剪贴板数据
const systemPasteboard = pasteboard.getSystemPasteboard(); // 获取系统剪贴板
systemPasteboard.setData(pasteboardData); // 设置剪贴板数据
// 显示复制成功的提示信息
promptAction.showToast({ message: '已复制' });
}
// 构建页面布局的方法
build() {
Column() {
// 标题栏,展示应用名
Text("随机数生成")
.width('100%') // 设置宽度为100%
.height(54) // 设置高度为54
.fontSize(18) // 设置字体大小为18
.fontWeight(600) // 设置字体粗细为600
.backgroundColor(Color.White) // 设置背景颜色为白色
.textAlign(TextAlign.Center) // 设置文本居中对齐
.fontColor(this.fontColor); // 设置文本颜色
// 随机数范围设置区域
Column() {
Row() {
Text(`随机数范围`)
.fontWeight(600) // 设置字体粗细为600
.fontSize(18) // 设置字体大小为18
.fontColor(this.fontColor); // 设置文本颜色
}
.margin({ top: `${this.baseSpacing}lpx`, left: `${this.baseSpacing}lpx` }); // 设置边距
// 输入随机数范围的两个值
Row() {
TextInput({ placeholder: '开始(>=)' }) // 输入框,显示占位符
.layoutWeight(1) // 设置布局权重为1
.type(InputType.Number) // 设置输入类型为数字
.placeholderColor(this.isFocusStart ? this.primaryColor : Color.Gray) // 设置占位符颜色
.fontColor(this.isFocusStart ? this.primaryColor : this.fontColor) // 设置文本颜色
.borderColor(this.isFocusStart ? this.primaryColor : Color.Gray) // 设置边框颜色
.borderWidth(1) // 设置边框宽度
.borderRadius(10) // 设置圆角半径
.backgroundColor(Color.White) // 设置背景颜色
.showUnderline(false) // 不显示下划线
.onBlur(() => this.isFocusStart = false) // 输入框失去焦点时的处理
.onFocus(() => this.isFocusStart = true) // 输入框获得焦点时的处理
.onChange((value: string) => this.startValue = Number(value)); // 输入值变化时的处理
// 分隔符
Line().width(10) // 设置分隔符宽度
TextInput({ placeholder: '结束(<=)' }) // 输入框,显示占位符
.layoutWeight(1) // 设置布局权重为1
.type(InputType.Number) // 设置输入类型为数字
.placeholderColor(this.isFocusEnd ? this.primaryColor : Color.Gray) // 设置占位符颜色
.fontColor(this.isFocusEnd ? this.primaryColor : this.fontColor) // 设置文本颜色
.borderColor(this.isFocusEnd ? this.primaryColor : Color.Gray) // 设置边框颜色
.borderWidth(1) // 设置边框宽度
.borderRadius(10) // 设置圆角半径
.backgroundColor(Color.White) // 设置背景颜色
.showUnderline(false) // 不显示下划线
.onBlur(() => this.isFocusEnd = false) // 输入框失去焦点时的处理
.onFocus(() => this.isFocusEnd = true) // 输入框获得焦点时的处理
.onChange((value: string) => this.endValue = Number(value)); // 输入值变化时的处理
}
.margin({
left: `${this.baseSpacing}lpx`, // 左边距
right: `${this.baseSpacing}lpx`, // 右边距
top: `${this.baseSpacing}lpx`, // 上边距
});
// 输入生成随机数的个数
Text('生成随机数个数')
.fontWeight(600) // 设置字体粗细为600
.fontSize(18) // 设置字体大小为18
.fontColor(this.fontColor) // 设置文本颜色
.margin({ left: `${this.baseSpacing}lpx`, top: `${this.baseSpacing}lpx` }); // 设置边距
Row() {
TextInput({ placeholder: '' }) // 输入框,显示占位符
.layoutWeight(1) // 设置布局权重为1
.type(InputType.Number) // 设置输入类型为数字
.placeholderColor(this.isFocusCount ? this.primaryColor : Color.Gray) // 设置占位符颜色
.fontColor(this.isFocusCount ? this.primaryColor : this.fontColor) // 设置文本颜色
.borderColor(this.isFocusCount ? this.primaryColor : Color.Gray) // 设置边框颜色
.borderWidth(1) // 设置边框宽度
.borderRadius(10) // 设置圆角半径
.backgroundColor(Color.White) // 设置背景颜色
.showUnderline(false) // 不显示下划线
.onBlur(() => this.isFocusCount = false) // 输入框失去焦点时的处理
.onFocus(() => this.isFocusCount = true) // 输入框获得焦点时的处理
.onChange((value: string) => this.countValue = Number(value)); // 输入值变化时的处理
}
.margin({
left: `${this.baseSpacing}lpx`, // 左边距
right: `${this.baseSpacing}lpx`, // 右边距
top: `${this.baseSpacing}lpx`, // 上边距
});
// 设置数字是否可重复的开关
Row() {
Text('数字是否可重复')
.fontWeight(400) // 设置字体粗细为400
.fontSize(16) // 设置字体大小为16
.fontColor(this.fontColor) // 设置文本颜色
.layoutWeight(1); // 设置布局权重为1
Toggle({ type: ToggleType.Checkbox, isOn: this.isUnique }) // 切换按钮
.width('100lpx') // 设置宽度
.height('50lpx') // 设置高度
.borderColor(Color.Gray) // 设置边框颜色
.selectedColor(this.primaryColor) // 设置选中时的颜色
.onChange((isOn: boolean) => this.isUnique = isOn) // 切换状态变化时的处理
.align(Alignment.End); // 设置对齐方式为右对齐
}
.margin({
top: `${this.baseSpacing}lpx`, // 上边距
})
.width('100%') // 设置宽度为100%
.padding({
left: `${this.baseSpacing}lpx`, // 左内边距
right: `${this.baseSpacing}lpx`, // 右内边距
top: `${this.baseSpacing / 3}lpx`, // 上内边距
})
.hitTestBehavior(HitTestMode.Block) // 设置点击测试行为
.onClick(() => this.isUnique = !this.isUnique); // 点击时切换状态
// 生成随机数的按钮
Text('开始生成')
.fontColor(Color.White) // 设置文本颜色为白色
.backgroundColor(this.primaryColor) // 设置背景颜色为主题色
.height(54) // 设置高度为54
.textAlign(TextAlign.Center) // 设置文本居中对齐
.borderRadius(10) // 设置圆角半径
.fontSize(18) // 设置字体大小为18
.width(`${650 - this.baseSpacing * 2}lpx`) // 设置宽度
.margin({
top: `${this.baseSpacing}lpx`, // 上边距
left: `${this.baseSpacing}lpx`, // 左边距
right: `${this.baseSpacing}lpx`, // 右边距
bottom: `${this.baseSpacing}lpx` // 下边距
})
.clickEffect({ level: ClickEffectLevel.HEAVY, scale: 0.8 }) // 设置点击效果
.onClick(() => this.generateRandomNumbers()); // 点击时生成随机数
}
.width('650lpx') // 设置宽度
.margin({ top: 20 }) // 设置上边距
.backgroundColor(Color.White) // 设置背景颜色为白色
.borderRadius(10) // 设置圆角半径
.alignItems(HorizontalAlign.Start); // 设置水平对齐方式为左对齐
// 显示生成的随机数
Column() {
Text(`生成的随机数为:`)
.fontWeight(600) // 设置字体粗细为600
.fontSize(18) // 设置字体大小为18
.fontColor(this.fontColor) // 设置文本颜色
.margin({
top: `${this.baseSpacing}lpx`, // 上边距
left: `${this.baseSpacing}lpx`, // 左边距
});
Text(`${this.generatedNumbers}`) // 显示生成的随机数
.width('650lpx') // 设置宽度
.fontColor(this.primaryColor) // 设置文本颜色为主题色
.fontSize(18) // 设置字体大小为18
.textAlign(TextAlign.Center) // 设置文本居中对齐
.padding({ left: 5, right: 5 }) // 设置内边距
.margin({
top: `${this.baseSpacing / 3}lpx` // 上边距
});
// 复制生成的随机数到剪贴板的按钮
Text('复制')
.enabled(this.generatedNumbers ? true : false) // 按钮是否可用
.fontColor(Color.White) // 设置文本颜色为白色
.backgroundColor(this.primaryColor) // 设置背景颜色为主题色
.height(54) // 设置高度为54
.textAlign(TextAlign.Center) // 设置文本居中对齐
.borderRadius(10) // 设置圆角半径
.fontSize(18) // 设置字体大小为18
.width(`${650 - this.baseSpacing * 2}lpx`) // 设置宽度
.margin({
top: `${this.baseSpacing}lpx`, // 上边距
left: `${this.baseSpacing}lpx`, // 左边距
right: `${this.baseSpacing}lpx`, // 右边距
bottom: `${this.baseSpacing}lpx` // 下边距
})
.clickEffect({ level: ClickEffectLevel.HEAVY, scale: 0.8 }) // 设置点击效果
.onClick(() => this.copyToClipboard(this.generatedNumbers)); // 点击时复制随机数
}
.width('650lpx') // 设置宽度
.backgroundColor(Color.White) // 设置背景颜色为白色
.borderRadius(10) // 设置圆角半径
.margin({ top: `${this.baseSpacing}lpx` }) // 设置上边距
.alignItems(HorizontalAlign.Start); // 设置水平对齐方式为左对齐
}
.height('100%') // 设置高度为100%
.width('100%') // 设置宽度为100%
.backgroundColor("#f2f3f5"); // 设置背景颜色
}
}