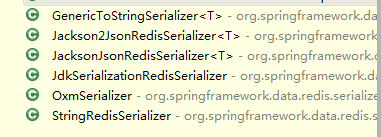
Spring Data Redis 为我们提供了下面的Serializer:GenericToStringSerializer、Jackson2JsonRedisSerializer、JacksonJsonRedisSerializer、JdkSerializationRedisSerializer、OxmSerializer、StringRedisSerializer。
序列化方式对比:
- JdkSerializationRedisSerializer: 使用JDK提供的序列化功能。 优点是反序列化时不需要提供类型信息(class),但缺点是需要实现Serializable接口,还有序列化后的结果非常庞大,是JSON格式的5倍左右,这样就会消耗redis服务器的大量内存。
- Jackson2JsonRedisSerializer: 使用Jackson库将对象序列化为JSON字符串。优点是速度快,序列化后的字符串短小精悍,不需要实现Serializable接口。但缺点也非常致命,那就是此类的构造函数中有一个类型参数,必须提供要序列化对象的类型信息(.class对象)。 通过查看源代码,发现其只在反序列化过程中用到了类型信息。
使用 FastJson2 来做。重写一些序列化器,并实现RedisSerializer接口。源码如下:
<dependency>
<groupId>com.alibaba.fastjson2</groupId>
<artifactId>fastjson2</artifactId>
<version>2.0.50</version>
</dependency>
Fastjson2 序列化
FastJson2JsonRedisSerializer
package com.vipsoft.base.util;
import com.alibaba.fastjson2.JSON;
import com.alibaba.fastjson2.JSONReader;
import com.alibaba.fastjson2.JSONWriter;
import com.alibaba.fastjson2.filter.Filter;
import org.springframework.data.redis.serializer.RedisSerializer;
import org.springframework.data.redis.serializer.SerializationException;
import java.nio.charset.Charset;
/**
* Redis使用FastJson序列化
*
* @author ruoyi
*/
public class FastJson2JsonRedisSerializer<T> implements RedisSerializer<T>
{
/**
* 自动识别json对象白名单配置(仅允许解析的包名,范围越小越安全)
*/
public static final String[] JSON_WHITELIST_STR = { "org.springframework", "com.vipsoft" };
public static final Charset DEFAULT_CHARSET = Charset.forName("UTF-8");
static final Filter AUTO_TYPE_FILTER = JSONReader.autoTypeFilter(JSON_WHITELIST_STR);
private Class<T> clazz;
public FastJson2JsonRedisSerializer(Class<T> clazz)
{
super();
this.clazz = clazz;
}
@Override
public byte[] serialize(T t) throws SerializationException
{
if (t == null)
{
return new byte[0];
}
return JSON.toJSONString(t, JSONWriter.Feature.WriteClassName).getBytes(DEFAULT_CHARSET);
}
@Override
public T deserialize(byte[] bytes) throws SerializationException
{
if (bytes == null || bytes.length <= 0)
{
return null;
}
String str = new String(bytes, DEFAULT_CHARSET);
return (T)JSON.parseObject(str, clazz, AUTO_TYPE_FILTER);
}
}
Redis.config
package com.vipsoft.base.config;
import com.cuwor.base.util.FastJson2JsonRedisSerializer;
import org.springframework.cache.annotation.EnableCaching;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.StringRedisSerializer;
@EnableCaching //开启缓存功能,作用于缓存配置类上或者作用于springboot启动类上
@Configuration
public class RedisConfig {
/**
* 创建一个RedisTemplate实例,用于操作Redis数据库。
* 其中,redisTemplate是一个泛型为<String, Object>的模板对象,可以存储键值对数据;
* @param factory factory是一个Redis连接工厂对象,用于建立与Redis服务器的连接
* @return
*/
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory factory) {
RedisTemplate<String, Object> template = new RedisTemplate<>();
template.setConnectionFactory(factory);
FastJson2JsonRedisSerializer serializer = new FastJson2JsonRedisSerializer(Object.class);
// 使用StringRedisSerializer来序列化和反序列化redis的key值
template.setKeySerializer(new StringRedisSerializer());
template.setValueSerializer(serializer);
// Hash的key也采用StringRedisSerializer的序列化方式
template.setHashKeySerializer(new StringRedisSerializer());
template.setHashValueSerializer(serializer);
template.afterPropertiesSet();
return template;
}
}
RedisUtil.java
package com.vipsoft.base.util;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.HashOperations;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.core.ValueOperations;
import org.springframework.stereotype.Component;
import java.util.*;
import java.util.concurrent.TimeUnit;
@Component
public class RedisUtil {
@Autowired
private RedisTemplate redisTemplate;
/**
* 判断key是否存在
*
* @param key 键
* @return true 存在 false不存在
*/
public boolean hasKey(String key) {
return redisTemplate.hasKey(key);
}
/**
* 指定缓存失效时间
*
* @param key 键
* @param time 时间(秒)
*/
public boolean expire(String key, long time) {
try {
redisTemplate.expire(key, time, TimeUnit.MINUTES);
return true;
} catch (Exception ex) {
ex.printStackTrace();
}
return false;
}
/**
* 获取 Keys
*
* @param key 键
*/
public Set<String> keys(String key) {
Set<String> result = new HashSet();
try {
result = redisTemplate.keys(key);
} catch (Exception ex) {
ex.printStackTrace();
}
return result;
}
/**
* 删除缓存
*/
public boolean del(String key) {
try {
redisTemplate.delete(key);
return true;
} catch (Exception ex) {
ex.printStackTrace();
}
return false;
}
/**
* 删除缓存
*/
public boolean del(Collection<String> keys) {
try {
redisTemplate.delete(keys);
return true;
} catch (Exception ex) {
ex.printStackTrace();
}
return false;
}
//region String
public <T> T get(String key) {
ValueOperations<String, T> operation = redisTemplate.opsForValue();
return operation.get(key);
}
public <T> boolean set(String key, T value) {
try {
redisTemplate.opsForValue().set(key, value);
return true;
} catch (Exception ex) {
ex.printStackTrace();
}
return false;
}
/**
* 普通缓存放入并设置时间
*
* @param key 键
* @param value 值
* @param time 时间(分种) time要大于0 如果time小于等于0 将设置无限期
* @return true成功 false 失败
*/
public boolean set(String key, Object value, long time) {
try {
redisTemplate.opsForValue().set(key, value, time, TimeUnit.MINUTES);
return true;
} catch (Exception ex) {
ex.printStackTrace();
}
return false;
}
//endregion
//region Hash
public <T> T hget(String key, String hashKey) {
HashOperations<String, String, T> hash = redisTemplate.opsForHash();
return hash.get(key, hashKey);
}
public <T> Map<String, T> hmget(String key) {
return redisTemplate.opsForHash().entries(key);
}
/**
* 向一张hash表中放入数据,如果不存在将创建
*
* @param key 键
* @param hashKey 项
* @param value 值
* @return true 成功 false失败
*/
public boolean hset(String key, String hashKey, Object value) {
redisTemplate.opsForHash().put(key, hashKey, value);
return true;
}
/**
* 向一张hash表中放入数据,如果不存在将创建
*
* @param key 键
* @param hashKey 项
* @param value 值
* @param time 时间(分钟) 注意:如果已存在的hash表有时间,这里将会替换原有的时间
* @return true 成功 false失败
*/
public boolean hset(String key, String hashKey, Object value, long time) {
redisTemplate.opsForHash().put(key, hashKey, value);
if (time > 0) {
redisTemplate.expire(key, time, TimeUnit.MINUTES);
}
return true;
}
/**
* HashSet
*
* @param key 键
* @param map 对应多个键值
* @return true 成功 false 失败
*/
public boolean hmset(String key, Map<String, Object> map) {
redisTemplate.opsForHash().putAll(key, map);
return true;
}
/**
* HashSet 并设置时间
*
* @param key 键
* @param map 对应多个键值
* @param time 时间(秒)
* @return true成功 false失败
*/
public boolean hmset(String key, Map<String, Object> map, long time) {
redisTemplate.opsForHash().putAll(key, map);
if (time > 0) {
redisTemplate.expire(key, time, TimeUnit.MINUTES);
}
return true;
}
/**
* 删除hash表中的值
*
* @param key 键 不能为null
* @param hashKey 项 可以使多个 不能为null
*/
public void hdel(String key, Object... hashKey) {
redisTemplate.opsForHash().delete(key, hashKey);
}
/**
* 判断hash表中是否有该项的值
*
* @param key 键 不能为null
* @param hashKey 项 不能为null
* @return true 存在 false不存在
*/
public boolean hHasKey(String key, String hashKey) {
return redisTemplate.opsForHash().hasKey(key, hashKey);
}
/**
* hash递增 如果不存在,就会创建一个 并把新增后的值返回
*
* @param key 键
* @param hashKey 项
* @param by 要增加几(大于0)
* @return
*/
public double hincr(String key, String hashKey, double by) {
return redisTemplate.opsForHash().increment(key, hashKey, by);
}
/**
* hash递减
*
* @param key 键
* @param hashKey 项
* @param by 要减少记(小于0)
* @return
*/
public double hdecr(String key, String hashKey, double by) {
return redisTemplate.opsForHash().increment(key, hashKey, -by);
}
//endregion
//region List
/**
* 获取list缓存的内容
* @param key 键
* @param start 开始
* @param end 结束 0 到 -1代表所有值
* @return
*/
public <T> List<T> lrange(String key, long start, long end) {
return redisTemplate.opsForList().range(key, start, end);
}
/**
* 获取list缓存的长度
* @param key 键
* @return
*/
public long llen(String key) {
return redisTemplate.opsForList().size(key);
}
/**
* 通过索引 获取list中的值
* @param key 键
* @param index 索引 index>=0时, 0 表头,1 第二个元素,依次类推;index<0时,-1,表尾,-2倒数第二个元素,依次类推
* @return
*/
public Object lindex(String key, long index) {
return redisTemplate.opsForList().index(key, index);
}
/**
* 将一个或多个值插入到列表的尾部(最右边)。
* @param key 键
* @param value 值
* @return
*/
public boolean lrpush(String key, Object value) {
redisTemplate.opsForList().rightPush(key, value);
return true;
}
/**
* 将一个或多个值插入到列表的尾部(最右边)。
* @param key 键
* @param value 值
* @param time 时间(秒)
* @return
*/
public boolean lrpush(String key, Object value, long time) {
redisTemplate.opsForList().rightPush(key, value);
if (time > 0) {
expire(key, time);
}
return true;
}
/**
* 将一个或多个值插入到列表的尾部(最右边)。
* @param key 键
* @param value 值
* @return
*/
public boolean lrpush(String key, List<Object> value) {
redisTemplate.opsForList().rightPushAll(key, value);
return true;
}
/**
* 将list放入缓存
* @param key 键
* @param value 值
* @param time 时间(秒)
* @return
*/
public boolean lrpush(String key, List<Object> value, long time) {
redisTemplate.opsForList().rightPushAll(key, value);
if (time > 0) {
expire(key, time);
}
return true;
}
/**
* 通过索引来设置元素的值
* @param key 键
* @param index 索引
* @param value 值
* @return /
*/
public boolean lset(String key, long index, Object value) {
redisTemplate.opsForList().set(key, index, value);
return true;
}
/**
* 删除指定key集合中值等于value的元素(count=0, 删除所有值等于value的元素; count>0, 从头部开始删除第一个值等于value的元素; count<0, 从尾部开始删除第一个值等于value的元素)
* @param key 键
* @param count count>0, 从头部开始删除第一个值等于value的元素; count<0, 从尾部开始删除第一个值等于value的元素
* @param value 值
* @return 移除的个数
*/
public long lremove(String key, long count, Object value) {
return redisTemplate.opsForList().remove(key, count, value);
}
//endregion
}
fastjson和fastjson2的区别
FastJSON是一种广泛使用的JSON解析库,其高性能和简单易用的特点受到开发者的喜爱。然而,随着应用场景的复杂化和安全要求的提高,FastJSON逐渐暴露出一些问题。为了解决这些问题并进一步提升性能和安全性,阿里巴巴推出了FastJSON2。以下是FastJSON和FastJSON2的详细对比:
一、性能
FastJSON:
以其快速高效著称,可以快速地将Java对象转换为JSON字符串,也可以将JSON字符串转换为Java对象。
FastJSON2:
在性能上进行了多方面的优化,通过优化序列化算法和数据结构,提高了序列化的效率,减少了不必要的对象创建和复制操作,从而降低了CPU和内存的开销。同时,对解析器进行了重构,使其能够更快速地处理大规模JSON数据。根据官方提供的性能测试数据,FastJSON2的性能远超其他流行的JSON库,如Jackson、Gson和org.json。
二、安全性
FastJSON:
在安全性方面存在一些漏洞,特别是其AutoType功能的安全性问题较为突出。该功能在序列化的JSON字符串中带上类型信息,在反序列化时不需要传入类型,实现自动类型识别,但这也为恶意攻击提供了可能。
FastJSON2:
在安全性方面做了显著改进,针对之前版本中暴露的一些安全漏洞进行了修复。为了防止反序列化漏洞,FastJSON2引入了更严格的黑名单机制,默认禁止了某些危险类型的反序列化操作。同时,增强了类型检测机制,可以更好地防止恶意数据的注入,确保数据解析的安全性。此外,FastJSON2的AutoType功能必须显式打开才能使用,且没有任何白名单,也不包括任何Exception类的白名单,这进一步提高了其安全性。
三、功能特性
FastJSON:
支持复杂对象的处理,包括嵌套对象、集合、Map等;支持注解来指定Java对象与JSON字符串之间的映射关系;允许用户自定义实现对象的序列化和反序列化过程;提供了流式的API,可以在处理大量JSON数据时提供更好的性能。
FastJSON2:
在FastJSON的基础上增加了一系列新的功能特性。例如,对JSONPath的支持更加全面和高效,允许开发者使用JSONPath表达式方便地访问和操作JSON数据;改进了对日期和时间的处理,提供了更多的配置选项和更好的性能,支持多种日期格式和时区处理;提供了对JSON Schema的支持,增强了数据验证的能力;新增加对二进制格式JSONB的支持,进一步提升了数据处理的效率和灵活性。
四、兼容性
FastJSON:
作为早期版本的JSON处理库,已经被广泛应用于各种Java项目中。
FastJSON2:
在保持与FastJSON兼容性的同时,也进行了一些必要的改进和优化。例如,FastJSON2支持最新的JDK特性,包括JDK 11和JDK 17等;同时提供了对Kotlin语言的优化支持,使得Kotlin开发者能够更加便捷地使用FastJSON2。此外,FastJSON2还支持跨平台兼容性,包括Android 8+等平台。
五、易用性
FastJSON:
提供了简单明了的API,使用起来非常方便。
FastJSON2:
对部分API进行了调整和优化,使其更加直观和易用。同时提供了更详细和友好的错误提示信息,帮助开发者更快地定位和解决问题。
综上所述,FastJSON2在性能、安全性、功能特性、兼容性和易用性等方面相比FastJSON都有显著的提升。对于需要高性能JSON解析和序列化的应用场景,特别是在安全性要求较高的情况下,FastJSON2是一个更好的选择。