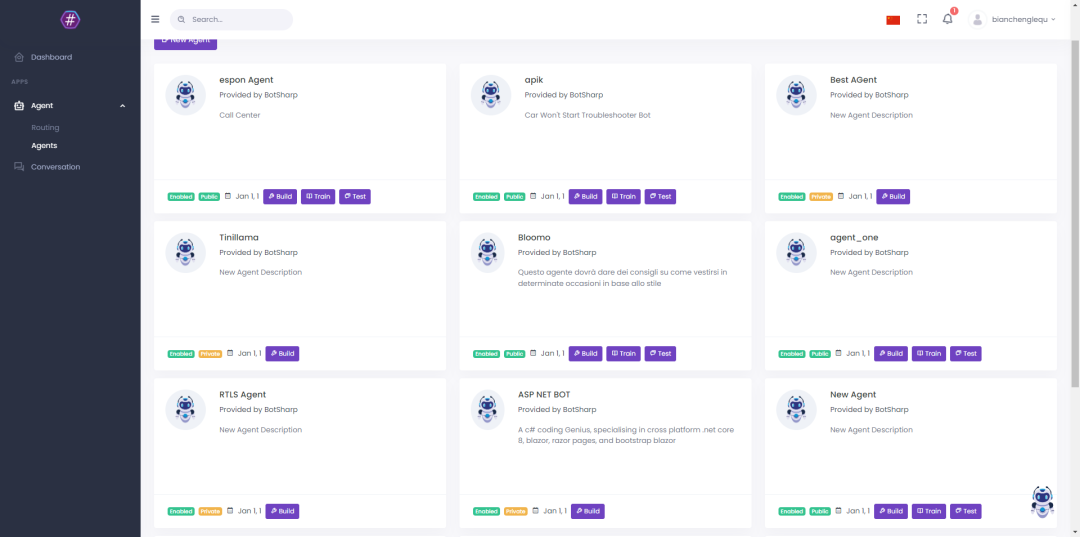
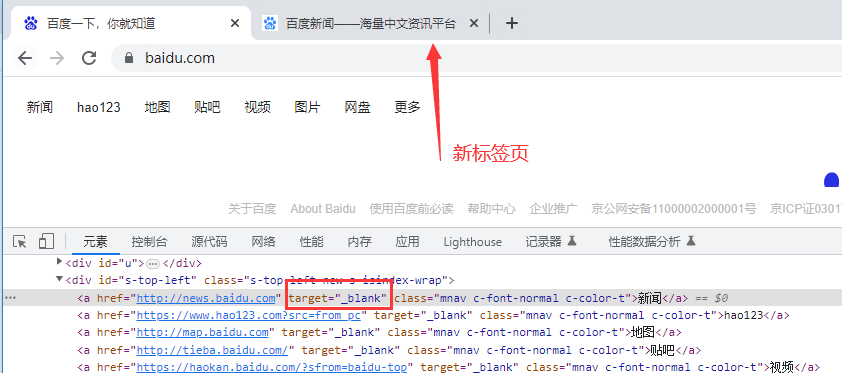
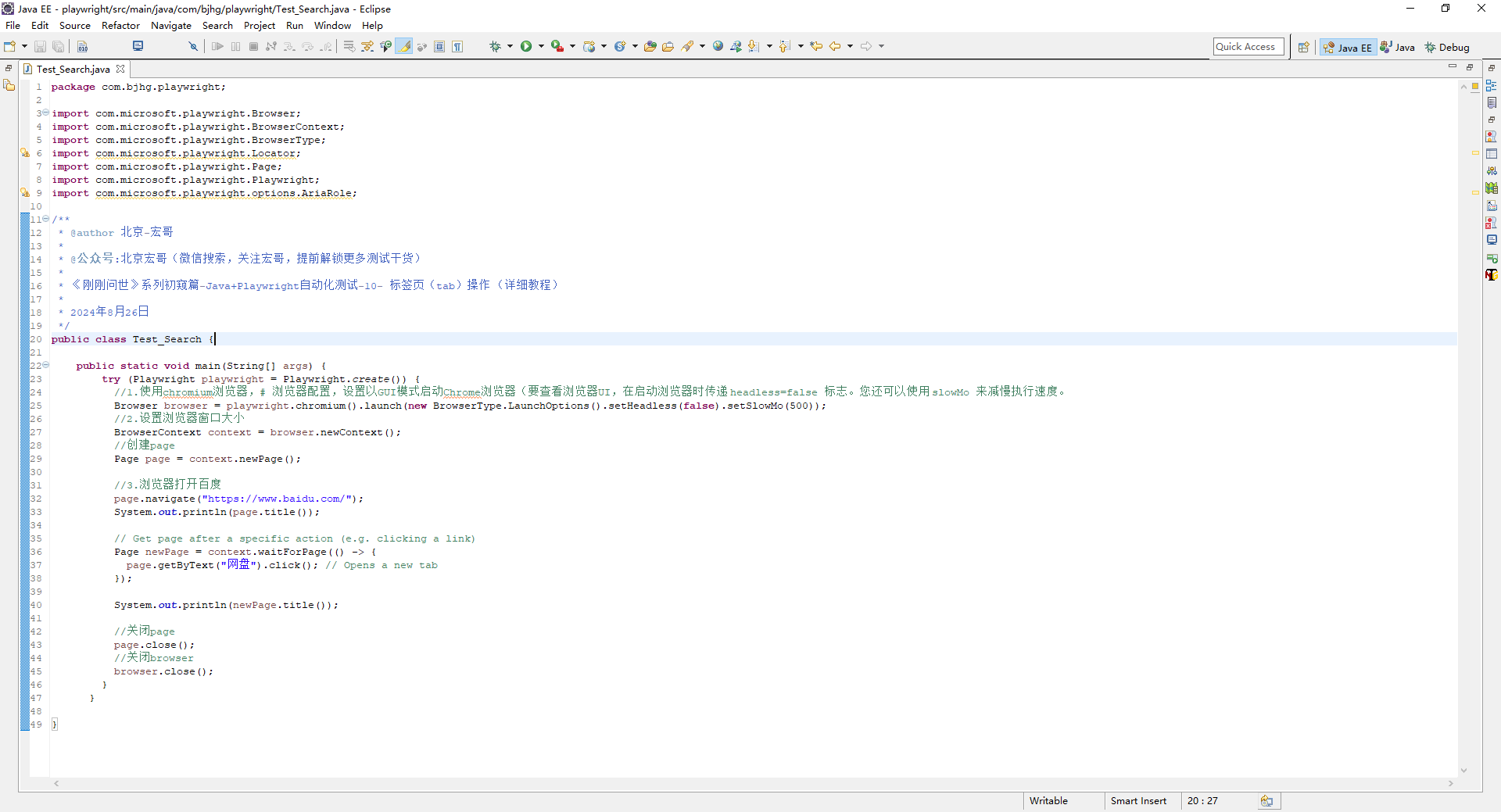
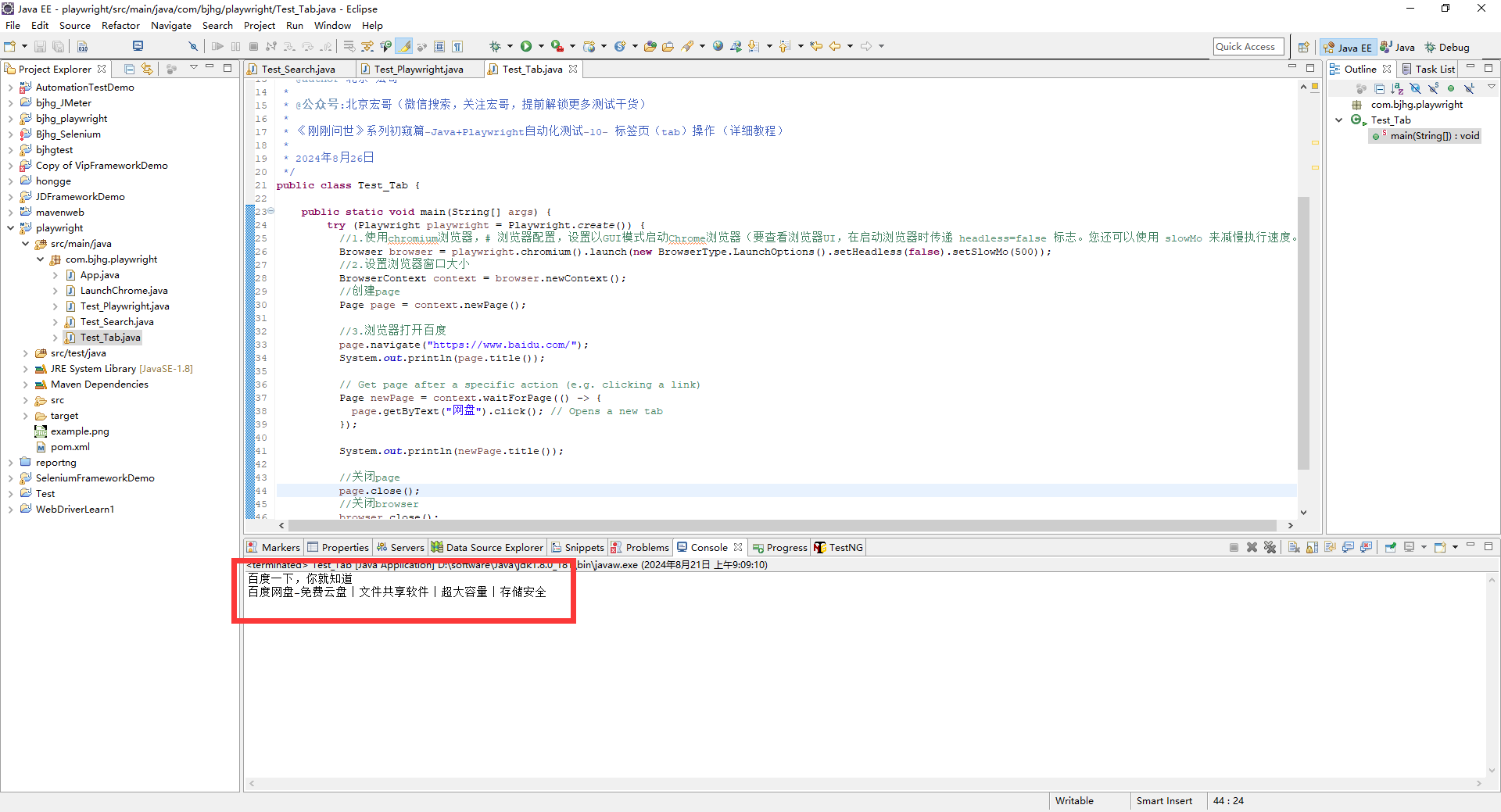
推陈出新的2024年
今年的关键字包括看书学习、业务研发、产品思维、交互设计、兴趣爱好等,已浏览相关书籍或专栏 30 篇,平均每周阅读 10~20 篇技术博文。
这些资料的内容我不可能全部消化记住,但可以让我在解决实际问题时,会有个印象,便于给出不同的方案。
维护着的技术仓库
daily
也在继续补充着 2024 年的
面试资料
、
性能优化
、
技术工具
等信息。
在公司方面,自从去年裁员之后,团队人员就稳定在 3 人,全年基本都扑在业务研发上,基建工作也只是做些优化迭代,没有大动作。
尽管如此,全年下来在工作上还是有些亮点,团队技术也一直在革新,例如首次进行了 Electron 研发、首次使用 Taro 框架、首次引入 Ant Design Pro 等等。
而自己在完成本职工作后,会腾出更多的精力去涉足更上层的产品、交互等工作,让自己的技能更加复合,也为了能更好的协作与服务。
平时有空也会去数据分析平台看些用户指标变化,或者去浏览下其他组的 OKR,以及了解下各个组的核心指标。
也会去 Wiki 上看看品牌、运营、产品等各个小组记录的各类文档,想了解下他们的工作内容,还有我们服务的是一群什么样的用户。
让自己知道他们都在关心什么,也能更好的理解他们为什么提出这个需求,想要的结果是什么,我除了完成技术支撑,还能为他们提供哪些帮助或建议。
公司去年提出了 4 项企业价值观,我觉得挺好的,蛮正向的,我们团队和个人也是遵循该价值观在慢慢的成长。
- 用户导向:以用户的需求和体验为中心,交付让用户满意的产品和服务。
- 乐于创造:思考问题本质,打破惯性思维,用创造性方案去解决本质问题。
- 积极分享:积极真诚分享用户洞察、工作信息等让团队共同成长。
- 使命必达:以结果为导向,全力推进问题解决,促进目标达成。
下面的思维图列举出了今年做的一些比较重要的事情。

一、项目经历
今年总共完成了 7 个版本迭代,大大小小 90 多个需求,这里就列举其中 3 个比较重要的项目,包括杀猪盘、PC 直播助手和社群小程序。
1)杀猪盘
杀猪盘是一个保护用户安全,识别诈骗用户的需求,涉及到多端联调,此项目从 2023 年 6 月份开始,至 2024 年 8 月份才上线,研发周期长达 1 年多。
这里面有客观资源问题,也有人的问题,技术方案改了好几版,计算方式从一端改到另一端,每次的改变都几乎是重写,所以说出现了很大的技术规划问题。
产品组也是奔溃了,不断的投诉另外两个组,我们组维护的部分比较轻量,所以时刻配合的变化。
这个项目暴露了太多的问题,从我的视角看,还是前期的技术准备不够充分,不够重视,把需求也想简单了。
在写代码时,写到某个位置,才发现这里有问题,然后拉上产品,讨论一通,这种情况发生了好几次,换谁都会不爽。
不断的在调整方案,最后将计算的逻辑从一个组调整到另一个组,直接重写,这么拖拖拉拉的,周期肯定会被拉长。
项目上线后,还是有效果的,杀猪盘相关的举报变少了,虽然杀猪盘没变少,但是每天都能封禁很多相关账号,避免发生杀猪盘。
这个项目对我们组也是一个警示,是一个反面教材,让我们在应对复杂需求时要做好万全的准备。
2)PC 直播助手
由于主播反映模拟器操作麻烦、输出效果打折且经常出各类问题,因此就需要一款稳定的 PC 客户端的直播助手软件。
公司直播使用的是声网的服务,声网说有 Electron 的 SDK,于是我们就基于 Electron 来开发这个直播助手,从 2 月份开始,到 4 月份上线第一版。
首次基于 Electron 开发,还是有些陌生的,简单理解地话,这是一个可以改造的浏览器环境,我们的业务开发其实并不需要改造环境。
声网的 SDK 会集成到 Electron 中,然后他们打包给我们,在此基础上开发业务。
直播间的通信基于腾讯 IM,以上麦为例,在上麦时客户端会向 IM 服务器发送上麦消息,服务端在完成上麦处理后,让 IM 服务端发送响应消息给客户端。
核心业务其实就是根据通信收到的 Code 码,完成不同的操作。
但是在业务中会涉及到大量的 Code 码,没有文档,没有统一结构,我们这边等于是边开发,边与客户端核对,非常费时间。
还有些问题是由于客户端和 Electron 环境的差异导致的,例如客户端的主播先以观众身份进入直播间的,但是在 PC 助手中没有这个身份,那样对应的处理逻辑就会不同。
第三方服务商的接口文档不清晰不完整,也会给我们的开发造成些阻碍,有的时候还需要让他们去修改源码。
打包的时候发现公司都是 Mac,而主播大部分是 Windows,还要去找相应的电脑,打包出的客户端还有点问题,都花了时间排查。
总之,这个项目完成下来不容易,但是上线后的反馈也并不好,主要还是功能太少,还无法满足主播的日常使用。
但是现有的资源还不足以完成一套完整的直播服务,因此,这个项目上线第一版后,就被搁置了,非常遗憾。
3)社群小程序
公司开展了一项新业务,就是购买公司的一个商品,可以获得积分,然后用积分可以在社群小程序中兑换徒步活动或者礼品。
小程序就是当前业务中缺失的一环,于是就投入了 1 个产品、1 个UI、7 名技术人员来实现这个需求。
项目周期从 6 月 5 号到 9 月 13 号正式上线,期间也经历了资源问题,导致项目不断的延期。
在这个项目中,首次使用 Ant Design Pro 和 Taro 框架,首次与 Go 的新框架对接,首次部署新框架,首次参与电商需求等。
产品文档更新过 3 版,总共产出 11 份独立文档,12612 个字,总大小 53.34 M。总共 58 个接口,630 条测试用例,测出 268 个 BUG,60 个高等级 BUG。
UI 验收时提出 19 个界面优化,产品验收提出 40 个功能优化点。总之,大家对这个项目都很重视。
在上线后,也陆陆续续迭代了多个版本,运营的意思是两周一个迭代,不过当然,没那么多的资源支持,大家都得妥协。
这个项目让我们体验了好多个新技术,其中 Ant Design Pro 让后台的研发更加的简单化,自己之前也封装过多个后台组件。
我发现我那些组件与成熟的库有着异曲同工之妙,只是开源库的功能更加的完善,可以适应更多的场景。
虽然现在小程序的用户量只有几百人,但是可以参与到一个从 0 到 1 的项目,还是可以学习到很多。
二、工作优化
虽然人员减少了,但是工作上的优化没有停下,都是小步迭代。
其中比较有代表性的就是根据飞书告警优化业务逻辑,完善前端监控系统的功能,各类营收和体验优化等。
1)飞书告警
大部分的飞书告警都不会让页面白屏,但有可能影响页面的性能,今年总共处理了将近 1700 多条的告警(每日新增数)。
例如有些页面每天有 140 多条白屏记录,分析后发现是因为接口响应超过 1 秒导致,主要的时间消耗在传输,因为传输的内容要 1.5M,当网络不好时,就会拉大通信时间。
于是将图被转化成 base64 存储在数据库中,将页面请求转换成 URL 方式,大大降低了页面尺寸,提升了传输速度。
在 7 月份,发现图像告警数量异常,经过排查,确认问题来源于某个特定地区的访问异常。
我将这一结论传达给运维,推动问题得到解决。几天后,另一个业务组也上报了该地区 CDN 异常的问题,进一步验证了我分析的准确性。
在 11 月中旬,通过每日发送的监控记录数量,发现突然暴增将近 68W 条,经过分析是因为打印记录的增多导致的,于是就注释掉几处通用代码中的打印,总量马上就下来了。
2)基建迭代
基建的工作也趋于稳定,榜单活动配置化在今年已经发布了 12 个活动,降本提效的典型案例,并且今年也修复了几个小问题。
静态页面配置是另一个后台可配的网页,是组员在使用中发现问题,而主动做了功能上完善和优化。
前端监控增加了两个监控项目:PC 直播助手和社群小程序,日志搜索增加了操作系统的查询条件,性能监控堆叠面积图和指标增加颜色标识。
自己也去买了几本书、看了几篇专栏去研究可观测性的概念,对于监控有了更深刻的理解。
都是些比较细节的优化,社群小程序是个新项目,包括发布都是新部署的,依照之前的文档,还增加了飞书指令发布的功能。
就是在 IM 界面输入关键字,就能直接发布,省去了进入云效后台界面的步骤。
除了系统优化之外,今年还推动将几个老旧无人维护的 Node 服务接口迁移到了 Go 服务,例如直播状态、赠送物品等。
今年维护和新建了近百份文档,其中包括多份技术分享、Code Review 记录、项目介绍等,组内也紧跟时髦学习了些 AI 技术资料。
3)成本优化
作为支撑部门,我们一般都是消耗公司资源,但有时候也能做些成本优化,最直接是就算减少数据库的存储。
5 月份清理了 MongoDB 中 5 张表,共减少 276G 的容量,删除了 4 张冗余表,定期清理 1 张表。
让整个 MongoDB 维持在 11G,每个月的存储费用可减少 150 不到点。
10 月份每天凌晨 3 点会有数据库的 CPU 告警,分析后发现是一条删除语句造成,在删除语句时增加 limit 限制。
然后分析发现,删除的那张表会将数据迁移到另一个数据库中,但是数据组已经做了同步。
也就是说,我们这边的同步是冗余的,于是就将另一个数据库中的 2 张表直接清空,还有 1 张表做定期清理。
总共减少1TB的数据量,每个月至少节约 1600 元,这比之前的 MongoDB 给力多了。
公司发展了这么多年,肯定有很多地方的技术费用是多付的,就看各个维护人员平时会不会关心这事儿了。
4)体验优化
我们组的用户包括自己、公司同事以及会员,我们要把所有的用户都伺候好了才行。
管理后台暗黑模式是我在浏览开源库的时候,突发奇想,也要给我们的后台整一套。
翻阅 Ant Design 4.X 的文档后,找到了改造流程,修改了代码后,就上线了,然后再慢慢的给个别组件或页面进行适配。
运营看到后台的暗黑模式后,马上去催促产品,给客户端也去整一套,产品一脸无奈,囧。
5 月份为两个对外的项目开启了强缓存,从 3 个小时慢慢加到 3 天,1 秒内白屏占比从 92.04% 提升至 95.32%,1 秒内首屏占比从 79.71% 提升至 88.03%
还有个比较顽疾的匹配问题,一开始也没重视,隔几天会报上来几个,也修复过几次,但还是有问题,最后决定彻底大改下,改完后。
让测试走了遍主流程,就上线了,14点左右上的,观察了一个下午,没啥问题,后面也没人上报了。
管理后台陆陆续续做了些优化,例如完善提示、增加限制、显示有用的数据等。虽然都是小小的改动,但能大大帮助了同事们的日常工作。
伺候好了其他人,也要伺候好我们自己组,Android 6 以后,就不能抓包 HTTPS 的请求,客户端调试很不方便,于是自己去研究了些
WebView的调试方法
。
iOS 的调试比较简单,可以借助 Safari 浏览器实现;Android 配置调试的过程比较波折,可以借助 Chrome 浏览器实现。
5)绩效考核
年底的时候制订了明年的绩效考核,包括业务指标和重要项目。
业务指标包括交付质量、双月用户满意度、业务支撑;重要项目包括基础建设和社群小程序。
交付质量就是线上急高等级的 BUG 数、SLA 和慢响应占比这些指标需要在一个好的范围内。
双月用户满意度就是我们自己做的一张问卷,每个双月推给各个协作方,让他们打分,满分 5 分。
业务支撑就是完成率和延期率不能超过某一个值。
基础建设就是完成团队和项目的迭代,包括组员能力成长、数据库优化、活动标准化、前端监控平台等。
虽然这一项比较难以量化,但是可以作为一个指导方向,让我们团队可以时刻关注着这块,到年底也能说道说道。
社群小程序是我们所维护的一个持续迭代的重要项目,考核标准是按期上线以及线上急高 BUG 数。
三、日常生活
现在下班后让我再去学技术,已经很难了,回家不是躺着刷手机,就是带小孩去这边那边的玩。
基本都是碎片时间,很少有大段的时间留给自己,一般也就晚上才会有点空闲时间。
小孩幼儿园正式毕业,9 月份入学,成为一年级大朋友了。
学校读书的原因,也在年中搬了次家,正式入住到新装修的房子中,去地铁站的距离加倍了。
1)旅行
今年总共去了 6 个地方旅行,都是带着小孩的,休闲为主,最远的是去了青岛,高铁单程 5 个小时,不远。
7 月中旬去的青岛,4 天 3 夜,天气一点都不热,环境很舒服,吃了点海鲜,有 3 天时间去了沙滩,小孩要挖泥沙。
景点附近容易堵车,不过地铁也很方便,景点都能到。吃的方面,崂山可乐有点喝不惯。
其余的地方就是江浙沪区域,包括常州恐龙园、无锡、同里古镇、西塘古镇、森泊,有的自驾有的高铁,现在去哪都方便。
高中的时候去过一次常州恐龙园,当时觉得是个公园而已,这次去了另一块游乐场区域,颠覆了我之前的认知。
2)兴趣
今年 3 月份看到鸟山明去世的消息后,就萌发了买套龙珠漫画的想法,但是我要买的版本得是童年时候内蒙古出版社的那套。
在闲鱼上看到套买的话比之前贵了几倍,就去散配,但其实也便宜不了,最终搞了一套,放书架。
还买了圣斗士的三套书籍,幽游白书正好看到有正版授权在卖,就也搞了一套,不过目前就 6 本。
5 月份又对手办产生了兴趣,又开始买些眼镜厂、一番赏等系列的手办,买了一堆,都摆到了书架中。
就摆在视野最好的那两层,也留了几个放在公司办公桌上当摆件,后面觉得占地方,收手了。
7 月份在青岛玩的时候,买了本介绍水浒卡的电子书,水浒卡就是 1999 年的时候流行的小浣熊水浒卡。
看了书之后,才了解到原来水浒卡版本有那么多,还分普卡、碎闪、闪卡等等。
从青岛回来后,就开始慢慢的在闲鱼上买卡,套买、散配都有,还自己的童年债。
我玩的比较花,打算把 34 号解珍这个人物的各个版本都搜集到。
如果每个版本都搜集 108 张,既费钱也费精力,几乎很难完成,并且卡太多了,都会来不及欣赏。
水浒闪卡还分软闪、硬面、奖闪,这部分比较费钱,花的大头都是在这块,其价格从当初翻了几十倍。
今年是怀旧的一年,买了很多以前就喜欢的东西,把私房钱挥霍的也差不多了。