基于SqlSugar的开发框架循序渐进介绍(10)-- 利用axios组件的封装,实现对后端API数据的访问和基类的统一封装处理
在SqlSugar的开发框架的后端,我们基于Web API的封装了统一的返回结果,使得WebAPI的接口返回值更加简洁,而在前端,我们也需要统一对返回的结果进行解析,并获取和Web API接口对应的数据进行展示即可,本篇随笔介绍在Vue3+TypeScript+Vite的项目中,使用基于TypeScript的基类继承的方式,实现对后端接口数据的统一解析处理的封装操作。
1、SqlSugar的开发框架后端Web API的封装
前面介绍到,在SqlSugar的开发框架的后端,我们需要对Web API统一封装返回结果,如对于授权登录的接口,我们的接口定义如下所示。
/// <summary> ///登录授权处理/// </summary> /// <returns></returns> [AllowAnonymous]
[HttpPost]
[Route("authenticate")]public async Task<AuthenticateResultDto> Authenticate(LoginDto dto)
其中的Web API的返回结果定义如下所示。
/// <summary> ///授权结果对象/// </summary> public classAuthenticateResultDto
{/// <summary> ///令牌信息/// </summary> public string? AccessToken { get; set; }/// <summary> ///失效秒数/// </summary> public int Expires { get; set; }/// <summary> ///处理是否成功/// </summary> public bool Succes { get; set; }/// <summary> ///错误信息/// </summary> public string? Error { get; set; }
}
我们注意到 Authenticate 的Web API方法返回的结果是一些简单的业务信息,一般我们返回结果需要在进行统一的封装处理,以便达到统一的外部处理需要。
关于接口数据格式的统一封装,我们定义一个WrapResultFilter,以及需要一个不封装的属性标识DontWrapResultAttribute,默认是统一封装返回的结果。
而对于结果的统一封装,我们只需要在Web API服务启动的时候,加入相关的过滤器处理即可。
//控制器添加自定义过滤器 builder.Services.AddControllers(options=>{
options.Filters.Add<WrapResultFilter>(); //统一结果封装处理 options.Filters.Add<GlobalExceptionFilter>();//自定义异常处理 });//所有控制器启动身份验证 builder.Services.AddMvc(options =>{
options.Filters.Add(new AuthorizeFilter());//所有MVC服务默认添加授权标签 });
如下是Web API统一封装后返回的结果对象。
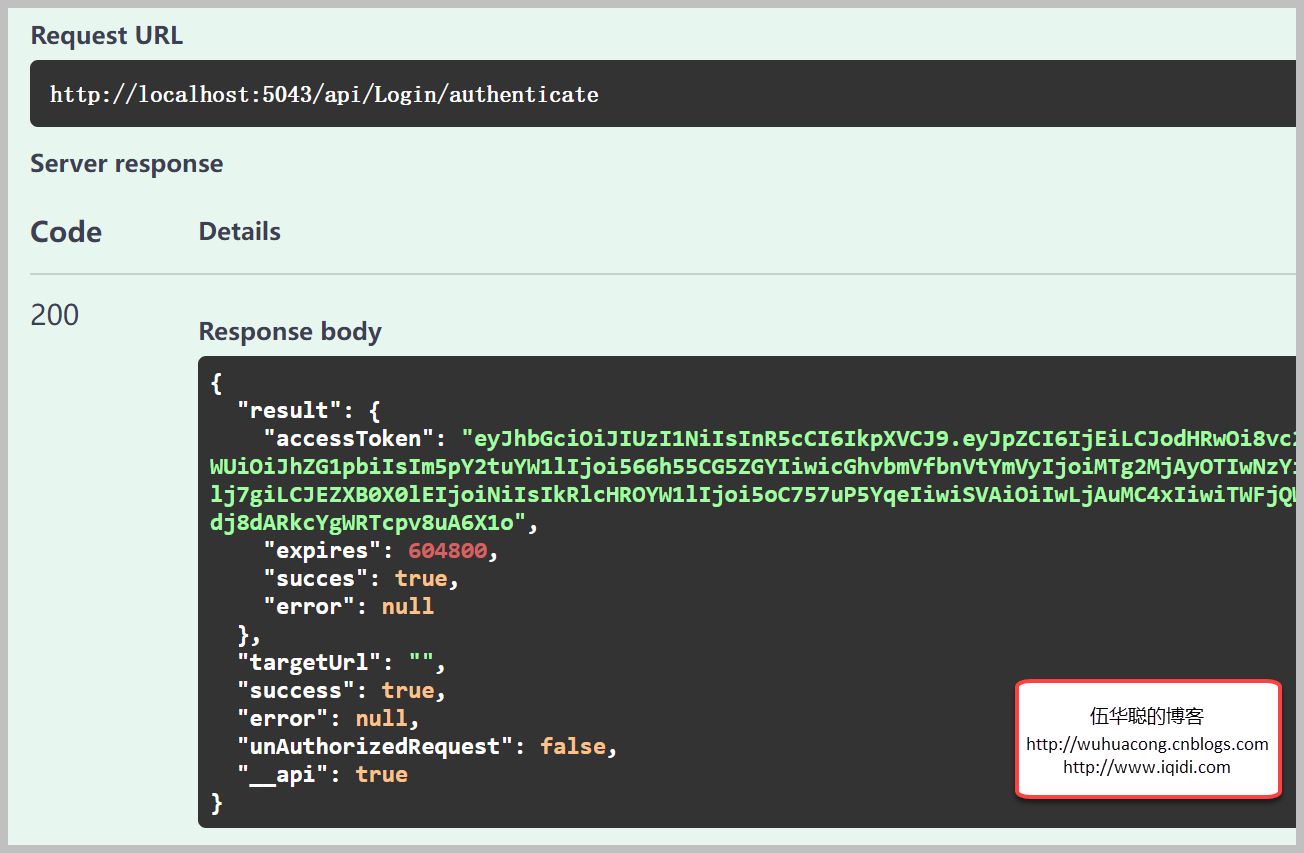
而对于列表记录的返回,同样是进行了外围的封装。
/// <summary> ///获取所有记录/// </summary> [HttpGet]
[Route("all")]
[HttpGet]public virtual async Task<ListResultDto<TEntity>> GetAllAsync()

2、利用axios组件对后端API数据的访问和基类的统一封装处理
利用axios组件对后端Web API的调用,基本上是前端开发的标准做法了。
一般来说,我们为了方便,会对原生的axios组件进行一定的封装处理,以便支持更好的调用处理,一般场景的操作就是POST、GET、PUT、DELETE,以及对文件流的上传处理操作,axios的github地址是
https://github.com/axios/axios
,如果需要可以参考它来做封装处理即可。
本篇随笔基于
https://github.com/vbenjs/vue-vben-admin
项目上的axios组件封装进行使用,它对于axios组件的封装比项目
https://github.com/xiaoxian521/vue-pure-admin
上的封装更加丰富一些,因此采用它。
利用axios组件,一般是为了方便,采用Typescript对它进行一定的封装,并利于统一对Request和Response的对象统一拦截处理,如Request请求接口调用的时候,根据当前用户的token进行头部信息的注入,获取到接口后,可以对结果内容进行拆解,获得简化后的结果。
例如对于常规的POST、GET、PUT、DELETE的处理,统一进行了调用,根据配置参数进行处理
get<T = any>(
config: AxiosRequestConfig,
options?: RequestOptions
): Promise<T>{return this.request({ ...config, method: "GET"}, options);
}
post<T = any>(
config: AxiosRequestConfig,
options?: RequestOptions
): Promise<T>{return this.request({ ...config, method: "POST"}, options);
}
put<T = any>(
config: AxiosRequestConfig,
options?: RequestOptions
): Promise<T>{return this.request({ ...config, method: "PUT"}, options);
}delete<T = any>(
config: AxiosRequestConfig,
options?: RequestOptions
): Promise<T>{return this.request({ ...config, method: "DELETE"}, options);
}
如对于HTTP请求拦截,我们需要在配置信息中加入token令牌信息,如下代码所示。
/**
* @description: 请求拦截器处理*/requestInterceptors: (config, options)=>{//请求之前处理config const tokenString =getToken();//console.log(tokenString); if(tokenString) {
const data=JSON.parse(tokenString) as AuthenticateDto;
const now= newDate().getTime();
const expired= parseInt(data.expires) - now <= 0;//console.log(data, now, expired); if(expired) {//token过期刷新 }
const token=data.accessToken;if(
token&&(config as Recordable)?.requestOptions?.withToken !== false) {//jwt token (config as Recordable).headers.Authorization =options.authenticationScheme?`${options.authenticationScheme} ${token}`
: token;
}
}returnconfig;
},
这些我们进行一定的微调即可,大多数情况下,不需要进行太多的设置。
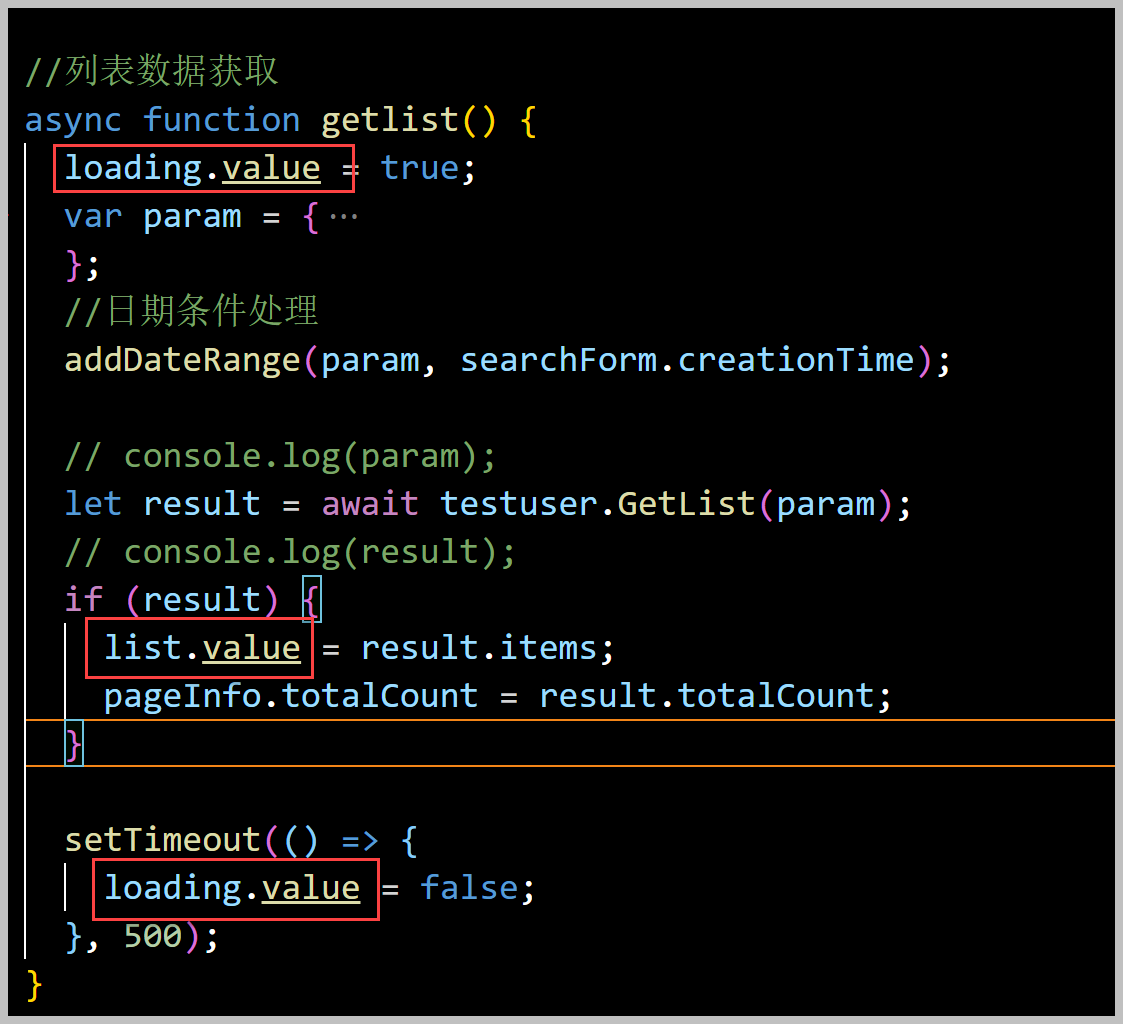
对于统一返回的结果,我们为了方便,统一进行了处理。在前端定义好几个数据类型,最后返回结果result即可。

在以前写过的关于前端Web API的处理文章中,有《
循序渐进VUE+Element 前端应用开发(19)--- 后端查询接口和Vue前端的整合
》 、《
在Bootstrap开发框架基础上增加WebApi+Vue&Element的前端
》,都是对相关业务类进行接口的抽象封装,以便于重用服务器的逻辑调用。
Vue&Element的前端的架构设计如下所示。

一般来说,我们页面模块可能会涉及到Store模块,用来存储对应的状态信息,也可能是直接访问API模块,实现数据的调用并展示。在页面开发过程中,多数情况下,不需要Store模块进行交互,一般只需要存储对应页面数据为全局数据状态的情况下,才可能启用Store模块的处理。
通过WebProxy代理的处理,我们可以很容易在前端中实现跨域的处理,不同的路径调用不同的域名地址API都可以,最终转换为本地的API调用,这就是跨域的处理操作。

3、访问后端接口的ES6 基类的封装处理
前端根据框架后端的接口进行前端JS端的类的封装处理,引入了ES6类的概念实现业务基类接口的统一封装,简化代码。
权限模块我们涉及到的用户管理、机构管理、角色管理、菜单管理、功能管理、操作日志、登录日志等业务类,那么这些类继承BaseApi,就会具有相关的接口了,如下所示继承关系。

按照这个思路,我们在BaseApi的ES6类里面定义了对应Web API基类里面的操作方法,如下所示。
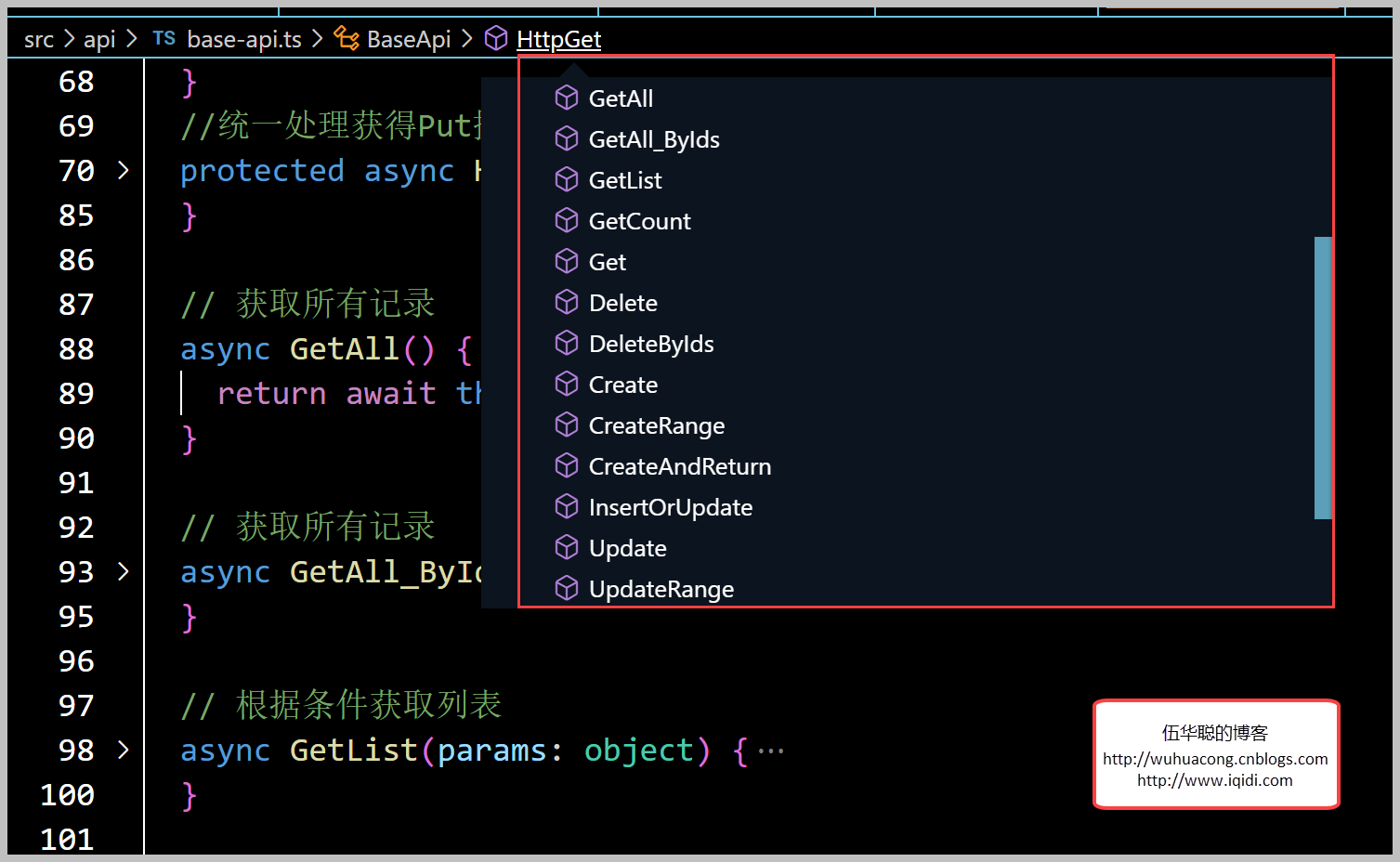
这样,我们在创建一个业务类的时候,如果没有特殊的自定义接口,只需要继承基类BaseApi即可具有所有的常规基类方法了。
//导入API基类对象,默认具有Get/GetAll/Create/Update/Delete/BatchDelete/SaveImport/Count等接口 import BaseApi from "./base-api";//业务类自定义接口实现, 通用的接口已经在BaseApi中定义 class Api extends BaseApi {//参考下面案例,增加自定义函数 //GET 方法例子 //根据条件计算记录数量 //async GetCount(params: object) { //return await this.HttpGet<number>(this.baseurl + "count", params); //} //POST 方法例子 //创建对象 //async Create(data: object) { //return await this.HttpPost<boolean>(this.baseurl + `create`, data); //} //PUT 方法例子 //更新对象 //async Update(data: object) { //return await this.HttpPut<boolean>(this.baseurl + `update`, data); //} //DELETE 方法例子 //删除指定ID的对象 //async Delete(id: number | string) { //return await this.HttpDelete<boolean>(this.baseurl + `${id}`); //} }//构造客户信息 Api实例,并传递业务类接口地址 export default new Api("/api/customer/");
如果需要一些定制的方法,我们则根据注释的提示和Web API的路径声明进行编写即可,如下是一个自定义接口的处理。
//根据字典类型获取对应的TreeNodeItem集合(包括id, label属性) async GetTreeItemByDictType(dictTypeName: string) {return await this.HttpGet<TreeNodeItem[]>(this.baseurl + `treeitem-by-typename/${dictTypeName}` );
}
由于是基于TypeScript,我们在具体的位置中定义了TreeNodeItem类型,对应服务器返回的WebAPI类型即可。
//树节点类型 export interface TreeNodeItem {
id: string;
label: string;
key?: string;
children?: TreeNodeItem[];
}
然后在自定义的ES6类的顶部引入类型定义就可以了
import {
PagedResult,
ListResult,
TreeNodeItem,
CListItem,
CommonResult
} from"./types";我们定义了接口后,就可以在Vue的JS里面进行调用了。
//使用字典类型,从服务器请求数据 await dictdata.GetTreeItemByDictType(typeName).then(list =>{ if(list) {
list.forEach(item=>{ dictItems.value.push({ id: item.id, label: item.label });
});
}
});
我们也可以使用async/await的异步线程调用方法,如下所示。
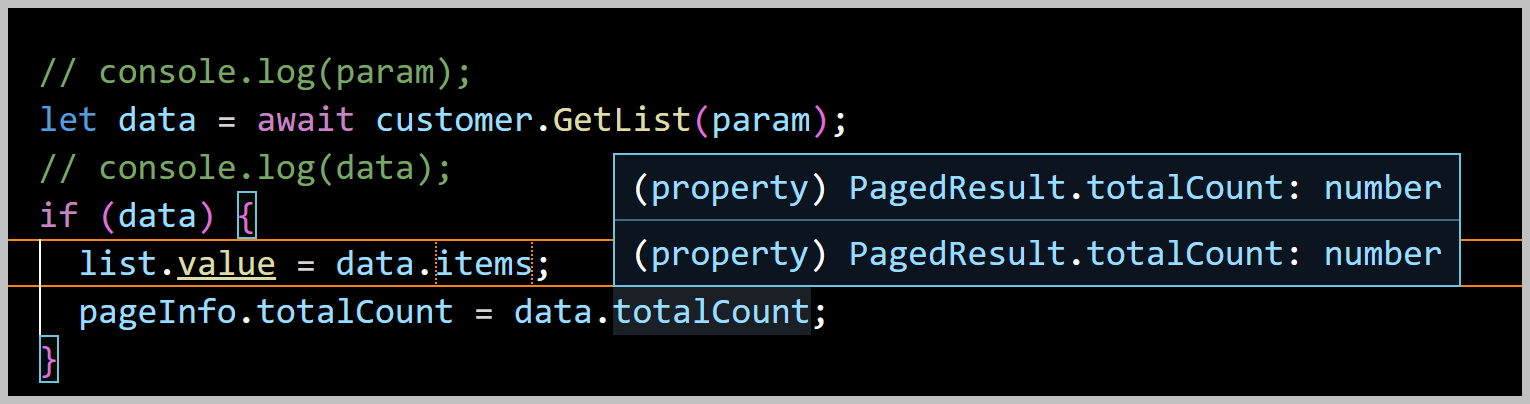
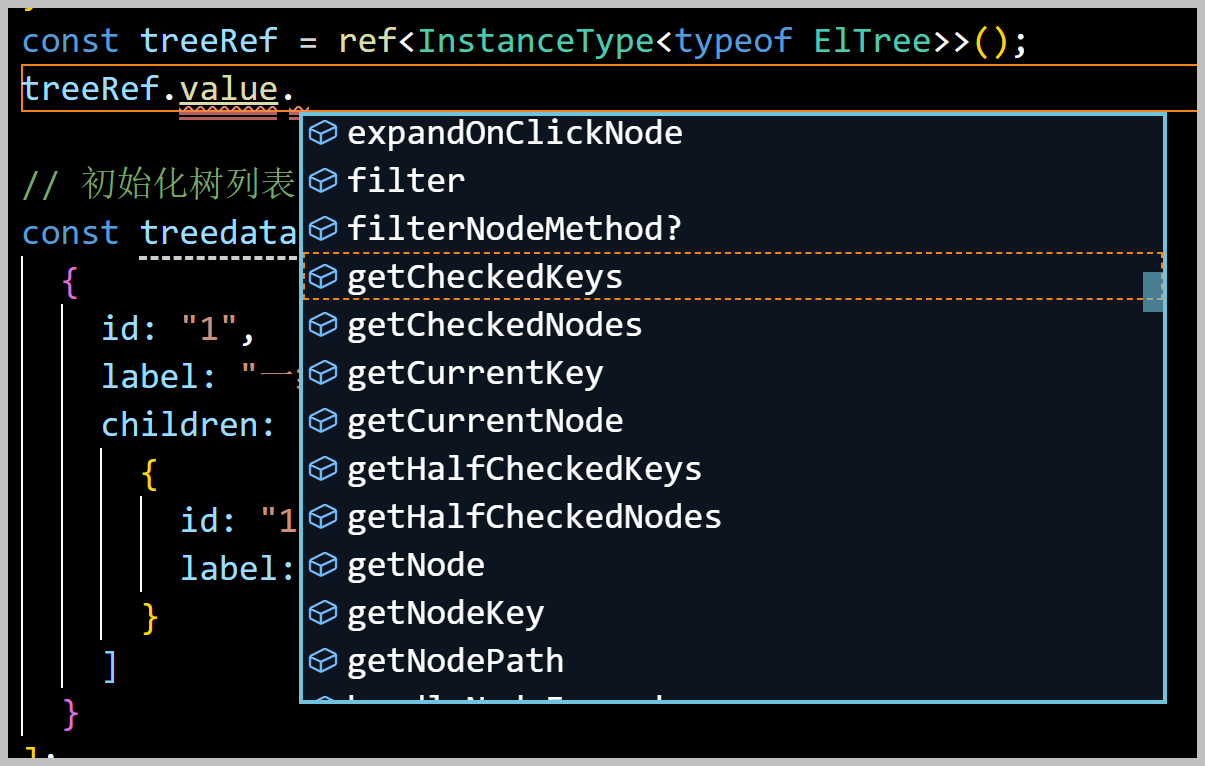
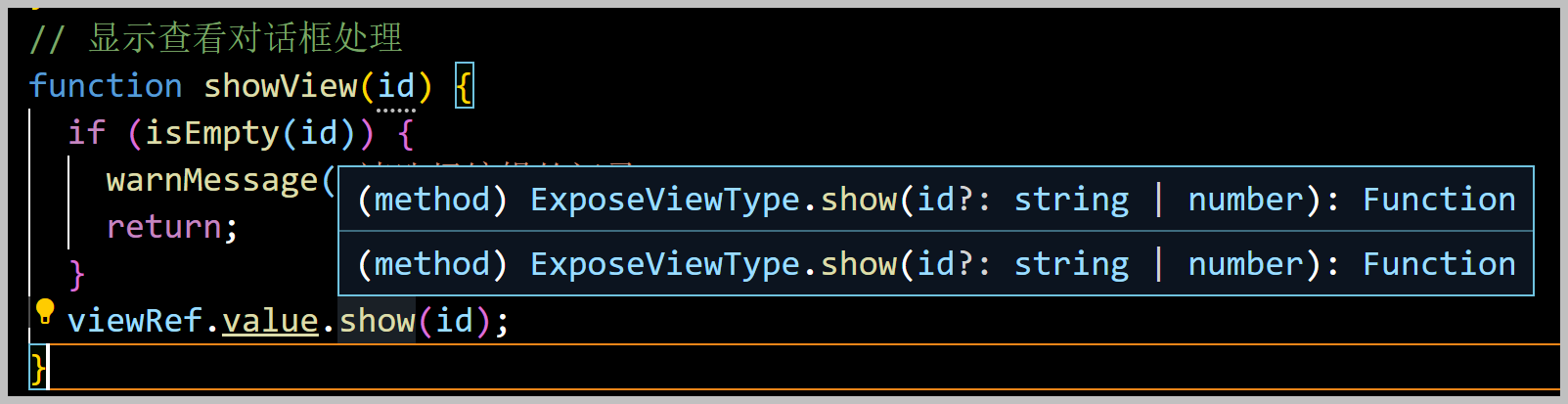
另外,由于我们的ES6接口定义,是基于TypeScript的,它的数据类型可以推断出来,因此在编码或者查看对应属性的时候,会有非常好的提示信息,如上所示。
最后我们来验证下实际的axios调用页面的效果。
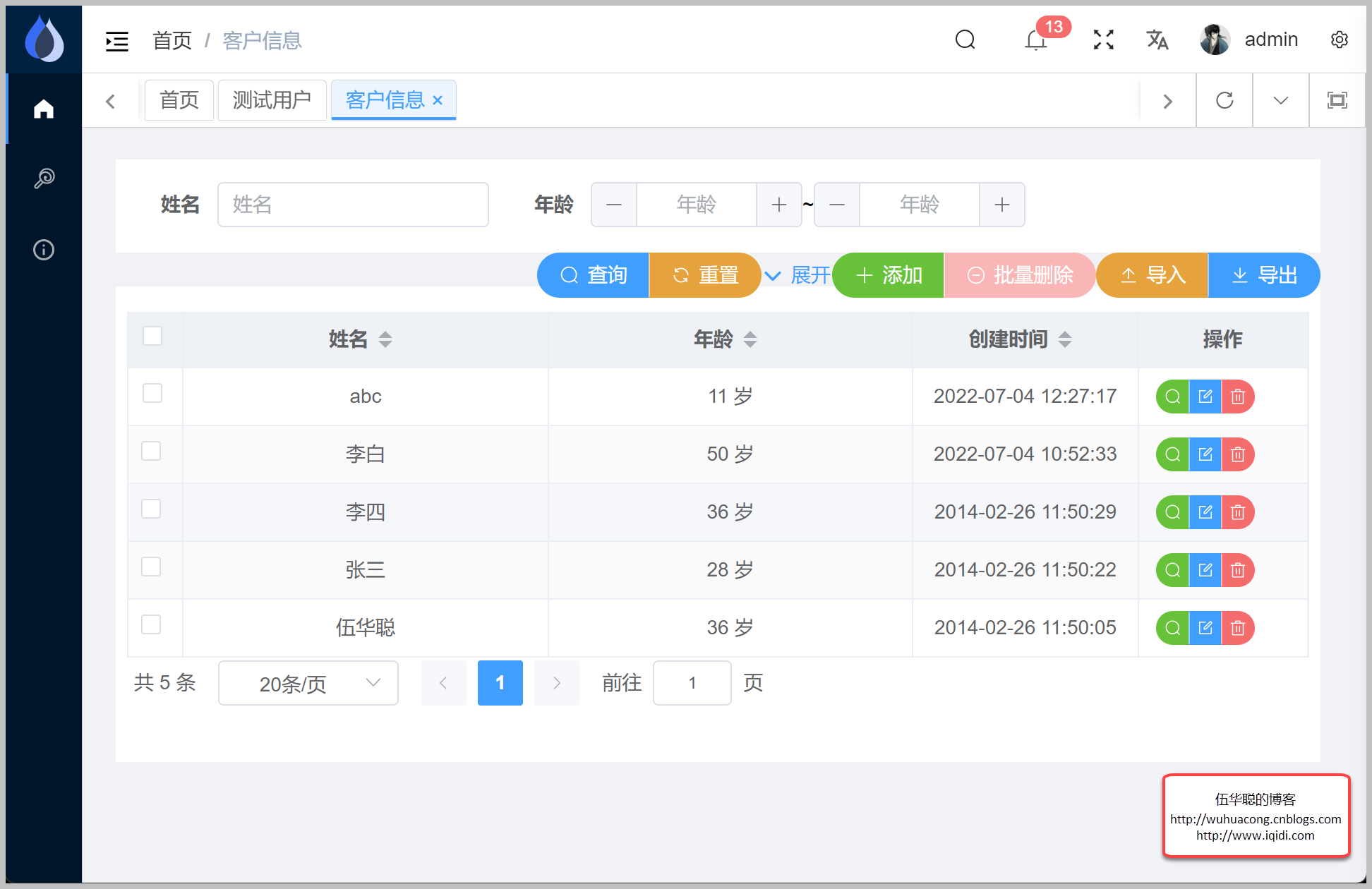
以及另外一个复杂一点的测试页面展示。
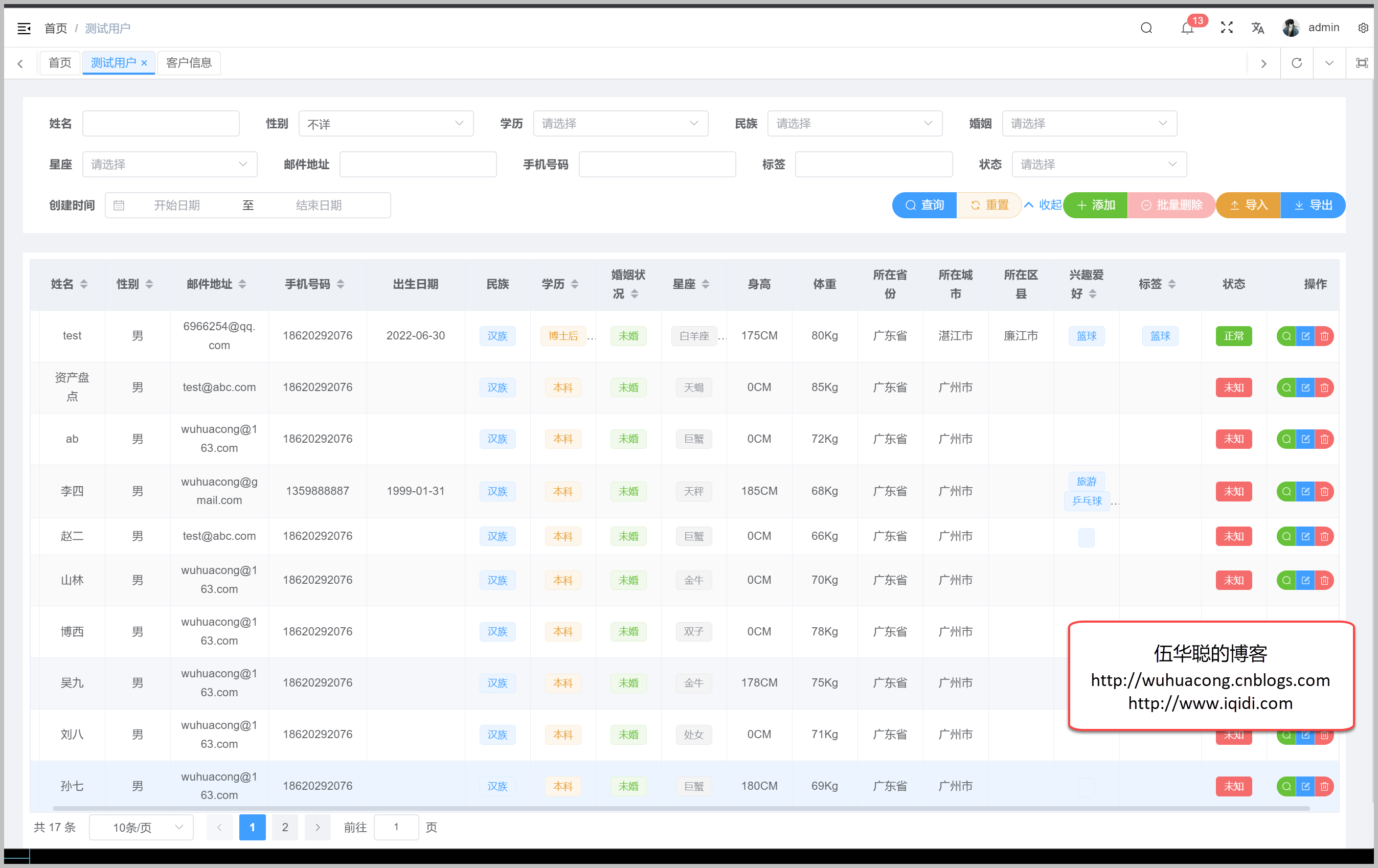
后续继续介绍Vue3+TypeScript+ElementPlus的相关技术点。
系列文章:
《
基于SqlSugar的开发框架的循序渐进介绍(1)--框架基础类的设计和使用
》
《
基于SqlSugar的开发框架循序渐进介绍(2)-- 基于中间表的查询处理
》
《
基于SqlSugar的开发框架循序渐进介绍(3)-- 实现代码生成工具Database2Sharp的整合开发
》
《
基于SqlSugar的开发框架循序渐进介绍(4)-- 在数据访问基类中对GUID主键进行自动赋值处理
》
《
基于SqlSugar的开发框架循序渐进介绍(5)-- 在服务层使用接口注入方式实现IOC控制反转
》
《
基于SqlSugar的开发框架循序渐进介绍(6)-- 在基类接口中注入用户身份信息接口
》
《
基于SqlSugar的开发框架循序渐进介绍(7)-- 在文件上传模块中采用选项模式【Options】处理常规上传和FTP文件上传
》
《
基于SqlSugar的开发框架循序渐进介绍(8)-- 在基类函数封装实现用户操作日志记录
》
《
基于SqlSugar的开发框架循序渐进介绍(9)-- 结合Winform控件实现字段的权限控制
》
《
基于SqlSugar的开发框架循序渐进介绍(10)-- 利用axios组件的封装,实现对后端API数据的访问和基类的统一封装处理
》
《
基于SqlSugar的开发框架循序渐进介绍(11)-- 使用TypeScript和Vue3的Setup语法糖编写页面和组件的总结
》
《
基于SqlSugar的开发框架循序渐进介绍(12)-- 拆分页面模块内容为组件,实现分而治之的处理
》
《
基于SqlSugar的开发框架循序渐进介绍(13)-- 基于ElementPlus的上传组件进行封装,便于项目使用
》
《
基于SqlSugar的开发框架循序渐进介绍(14)-- 基于Vue3+TypeScript的全局对象的注入和使用
》
《
基于SqlSugar的开发框架循序渐进介绍(15)-- 整合代码生成工具进行前端界面的生成
》
《
基于SqlSugar的开发框架循序渐进介绍(16)-- 工作流模块的功能介绍
》
《
基于SqlSugar的开发框架循序渐进介绍(17)-- 基于CSRedis实现缓存的处理
》
《
基于SqlSugar的开发框架循序渐进介绍(18)-- 基于代码生成工具Database2Sharp,快速生成Vue3+TypeScript的前端界面和Winform端界面
》