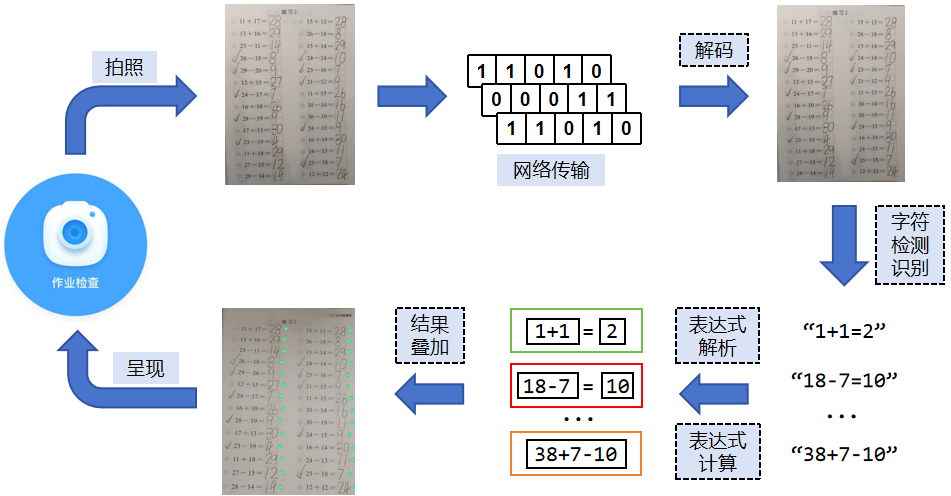
配置解析主体方法
public Configuration parse() {
if (parsed) {
throw new BuilderException("Each XMLConfigBuilder can only be used once.");
}
parsed = true;
//源码中没有这一句,只有 parseConfiguration(parser.evalNode("/configuration"));
//为了让读者看得更明晰,源码拆分为以下两句
XNode configurationNode = parser.evalNode("/configuration");
parseConfiguration(configurationNode);
return configuration;
}
/**
* 解析 "/configuration"节点下的子节点信息,然后将解析的结果设置到Configuration对象中
*/
private void parseConfiguration(XNode root) {
try {
//1.首先处理properties 节点
propertiesElement(root.evalNode("properties")); //issue #117 read properties first
//2.处理typeAliases
typeAliasesElement(root.evalNode("typeAliases"));
//3.处理插件
pluginElement(root.evalNode("plugins"));
//4.处理objectFactory
objectFactoryElement(root.evalNode("objectFactory"));
//5.objectWrapperFactory
objectWrapperFactoryElement(root.evalNode("objectWrapperFactory"));
//6.settings
settingsElement(root.evalNode("settings"));
//7.处理environments
environmentsElement(root.evalNode("environments")); // read it after objectFactory and objectWrapperFactory issue #631
//8.database
databaseIdProviderElement(root.evalNode("databaseIdProvider"));
//9.typeHandlers
typeHandlerElement(root.evalNode("typeHandlers"));
//10.mappers
mapperElement(root.evalNode("mappers"));
} catch (Exception e) {
throw new BuilderException("Error parsing SQL Mapper Configuration. Cause: " + e, e);
}
}
通过以上源码,就能看出,在mybatis的配置文件中:
- configuration节点为根节点。
- 在configuration节点之下,我们可以配置10个子节点, 分别为:properties、typeAliases、plugins、objectFactory、objectWrapperFactory、settings、environments、databaseIdProvider、typeHandlers、mappers。
配置文件元素
properties
<configuration>
<!-- 方法一: 从外部指定properties配置文件, 除了使用resource属性指定外,还可通过url属性指定url
<properties resource="dbConfig.properties"></properties>
-->
<!-- 方法二: 直接配置为xml -->
<properties>
<property name="driver" value="com.mysql.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost:3306/test1"/>
<property name="username" value="root"/>
<property name="password" value="root"/>
</properties>
那么,要是两种方法都同时配置了,那么最终会采用什么样的配置呢?
- 首先会先检查文件中的xml配置 和 外部指定的properties(也就是resource),如果两个同时配置了,那么就会报异常
- 接着会加载Java Configuration的配置
- 如果有Configuration的配置,那么最终会使用Configuration的配置
- 如果没有Configuration的配置,那么最终会使用上一步的xml的配置或resource配置
这是因为配置是存放在Properties,它继承自HashTable类,当依次将上述几种配置源put进去时,后加载的配置会覆盖先加载的配置。所以,最终应用配置时Configuration配置优先级最高,其次是另外两种中的一种。具体可以参考接下来的源码分析。
envirements
<environments default="development">
<environment id="development">
<!--
JDBC–这个配置直接简单使用了JDBC的提交和回滚设置。它依赖于从数据源得到的连接来管理事务范围。
MANAGED–这个配置几乎没做什么。它从来不提交或回滚一个连接。而它会让容器来管理事务的整个生命周期(比如Spring或JEE应用服务器的上下文)。
-->
<transactionManager type="JDBC"/>
<!--
UNPOOLED–这个数据源的实现是每次被请求时简单打开和关闭连接
POOLED–mybatis实现的简单的数据库连接池类型,它使得数据库连接可被复用,不必在每次请求时都去创建一个物理的连接。
JNDI – 通过jndi从tomcat之类的容器里获取数据源。
-->
<dataSource type="POOLED">
<!--
如果上面没有指定数据库配置的properties文件,那么此处可以这样直接配置
<property name="driver" value="com.mysql.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost:3306/test1"/>
<property name="username" value="root"/>
<property name="password" value="root"/>
-->
<!-- 上面指定了数据库配置文件, 配置文件里面也是对应的这四个属性 -->
<property name="driver" value="${driver}"/>
<property name="url" value="${url}"/>
<property name="username" value="${username}"/>
<property name="password" value="${password}"/>
</dataSource>
</environment>
<!-- 我再指定一个environment -->
<environment id="test">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="com.mysql.jdbc.Driver"/>
<!-- 与上面的url不一样 -->
<property name="url" value="jdbc:mysql://localhost:3306/demo"/>
<property name="username" value="root"/>
<property name="password" value="root"/>
</dataSource>
</environment>
</environments>
environments元素节点可以配置多个environment子节点, 怎么理解呢?
假如我们系统的开发环境和正式环境所用的数据库不一样(这是肯定的), 那么可以设置两个environment, 两个id分别对应开发环境(dev)和正式环境(final),那么通过配置environments的default属性就能选择对应的environment了, 例如,我将environments的deault属性的值配置为dev, 那么就会选择dev的environment。 那么这个是怎么实现的呢?
看源码: mybatis 是通过XMLConfigBuilder这个类在解析mybatis配置文件的,XMLConfigBuilder对于environments的解析:
public class XMLConfigBuilder extends BaseBuilder {
private boolean parsed;
// xml解析器
private XPathParser parser;
private String environment;
// 看看解析enviroments元素节点的方法
private void environmentsElement(XNode context) throws Exception {
if (context != null) {
if (environment == null) {
//解析environments节点的default属性的值
//例如: <environments default="development">
environment = context.getStringAttribute("default");
}
//递归解析environments子节点
for (XNode child : context.getChildren()) {
//<environment id="development">, 只有enviroment节点有id属性,那么这个属性有何作用?
//environments 节点下可以拥有多个 environment子节点
//类似于这样: <environments default="development"><environment id="development">...</environment><environment id="test">...</environments>
//意思就是可以对应多个环境,比如开发环境,测试环境等, 由environments的default属性去选择对应的enviroment
String id = child.getStringAttribute("id");
//isSpecial就是根据由environments的default属性去选择对应的enviroment
if (isSpecifiedEnvironment(id)) {
//事务, mybatis有两种:JDBC 和 MANAGED, 配置为JDBC则直接使用JDBC的事务,配置为MANAGED则是将事务托管给容器,
TransactionFactory txFactory = transactionManagerElement(child.evalNode("transactionManager"));
//enviroment节点下面就是dataSource节点了,解析dataSource节点(下面会贴出解析dataSource的具体方法)
DataSourceFactory dsFactory = dataSourceElement(child.evalNode("dataSource"));
DataSource dataSource = dsFactory.getDataSource();
Environment.Builder environmentBuilder = new Environment.Builder(id)
.transactionFactory(txFactory)
.dataSource(dataSource);
//将dataSource设置进configuration对象
configuration.setEnvironment(environmentBuilder.build());
}
}
}
}
//dataSource的解析方法
private DataSourceFactory dataSourceElement(XNode context) throws Exception {
if (context != null) {
//dataSource的连接池
String type = context.getStringAttribute("type");
//子节点 name, value属性set进一个properties对象
Properties props = context.getChildrenAsProperties();
//创建dataSourceFactory
DataSourceFactory factory = (DataSourceFactory) resolveClass(type).newInstance();
factory.setProperties(props);
return factory;
}
throw new BuilderException("Environment declaration requires a DataSourceFactory.");
}
}
还有一个问题, 在配置dataSource的时候使用了 ${driver} 这种表达式, 那么这种形式是怎么解析的?其实,是通过PropertyParser这个类解析:
/**
* 这个类解析${}这种形式的表达式
*/
public class PropertyParser {
public static String parse(String string, Properties variables) {
VariableTokenHandler handler = new VariableTokenHandler(variables);
GenericTokenParser parser = new GenericTokenParser("${", "}", handler);
return parser.parse(string);
}
private static class VariableTokenHandler implements TokenHandler {
private Properties variables;
public VariableTokenHandler(Properties variables) {
this.variables = variables;
}
public String handleToken(String content) {
if (variables != null && variables.containsKey(content)) {
return variables.getProperty(content);
}
return "${" + content + "}";
}
}
}
以上就是对于properties 和 environments元素节点的分析,比较重要的都在对于源码的注释中标出。
typeAliases
typeAliases节点主要用来设置别名,其实这是挺好用的一个功能, 通过配置别名,我们不用再指定完整的包名,并且还能取别名。
例如: 我们在使用 com.demo.entity. UserEntity 的时候,我们可以直接配置一个别名user, 这样以后在配置文件中要使用到com.demo.entity.UserEntity的时候,直接使用User即可。
就以上例为例,我们来实现一下,看看typeAliases的配置方法:
<configuration>
<typeAliases>
<!--
通过package, 可以直接指定package的名字, mybatis会自动扫描你指定包下面的javabean,
并且默认设置一个别名,默认的名字为: javabean 的首字母小写的非限定类名来作为它的别名。
也可在javabean 加上注解@Alias 来自定义别名, 例如: @Alias(user)
<package name="com.dy.entity"/>
-->
<typeAlias alias="UserEntity" type="com.dy.entity.User"/>
</typeAliases>
......
</configuration>
再写一段测试代码,看看有没生效:(我只写一段伪代码)
Configuration con = sqlSessionFactory.getConfiguration();
Map<String, Class<?>> typeMap = con.getTypeAliasRegistry().getTypeAliases();
for(Entry<String, Class<?>> entry: typeMap.entrySet()) {
System.out.println(entry.getKey() + " ================> " + entry.getValue().getSimpleName());
}
typeAliasesElement:
/**
* 解析typeAliases节点
*/
private void typeAliasesElement(XNode parent) {
if (parent != null) {
for (XNode child : parent.getChildren()) {
//如果子节点是package, 那么就获取package节点的name属性, mybatis会扫描指定的package
if ("package".equals(child.getName())) {
String typeAliasPackage = child.getStringAttribute("name");
//TypeAliasRegistry 负责管理别名, 这儿就是通过TypeAliasRegistry 进行别名注册, 下面就会看看TypeAliasRegistry源码
configuration.getTypeAliasRegistry().registerAliases(typeAliasPackage);
} else {
//如果子节点是typeAlias节点,那么就获取alias属性和type的属性值
String alias = child.getStringAttribute("alias");
String type = child.getStringAttribute("type");
try {
Class<?> clazz = Resources.classForName(type);
if (alias == null) {
typeAliasRegistry.registerAlias(clazz);
} else {
typeAliasRegistry.registerAlias(alias, clazz);
}
} catch (ClassNotFoundException e) {
throw new BuilderException("Error registering typeAlias for '" + alias + "'. Cause: " + e, e);
}
}
}
}
}
重要的源码在这儿:TypeAliasRegistry.java
public class TypeAliasRegistry {
//这就是核心所在啊, 原来别名就仅仅通过一个HashMap来实现, key为别名, value就是别名对应的类型(class对象)
private final Map<String, Class<?>> TYPE_ALIASES = new HashMap<String, Class<?>>();
/**
* 以下就是mybatis默认为我们注册的别名
*/
public TypeAliasRegistry() {
registerAlias("string", String.class);
registerAlias("byte", Byte.class);
registerAlias("long", Long.class);
registerAlias("short", Short.class);
registerAlias("int", Integer.class);
registerAlias("integer", Integer.class);
registerAlias("double", Double.class);
registerAlias("float", Float.class);
registerAlias("boolean", Boolean.class);
registerAlias("byte[]", Byte[].class);
registerAlias("long[]", Long[].class);
registerAlias("short[]", Short[].class);
registerAlias("int[]", Integer[].class);
registerAlias("integer[]", Integer[].class);
registerAlias("double[]", Double[].class);
registerAlias("float[]", Float[].class);
registerAlias("boolean[]", Boolean[].class);
registerAlias("_byte", byte.class);
registerAlias("_long", long.class);
registerAlias("_short", short.class);
registerAlias("_int", int.class);
registerAlias("_integer", int.class);
registerAlias("_double", double.class);
registerAlias("_float", float.class);
registerAlias("_boolean", boolean.class);
registerAlias("_byte[]", byte[].class);
registerAlias("_long[]", long[].class);
registerAlias("_short[]", short[].class);
registerAlias("_int[]", int[].class);
registerAlias("_integer[]", int[].class);
registerAlias("_double[]", double[].class);
registerAlias("_float[]", float[].class);
registerAlias("_boolean[]", boolean[].class);
registerAlias("date", Date.class);
registerAlias("decimal", BigDecimal.class);
registerAlias("bigdecimal", BigDecimal.class);
registerAlias("biginteger", BigInteger.class);
registerAlias("object", Object.class);
registerAlias("date[]", Date[].class);
registerAlias("decimal[]", BigDecimal[].class);
registerAlias("bigdecimal[]", BigDecimal[].class);
registerAlias("biginteger[]", BigInteger[].class);
registerAlias("object[]", Object[].class);
registerAlias("map", Map.class);
registerAlias("hashmap", HashMap.class);
registerAlias("list", List.class);
registerAlias("arraylist", ArrayList.class);
registerAlias("collection", Collection.class);
registerAlias("iterator", Iterator.class);
registerAlias("ResultSet", ResultSet.class);
}
/**
* 处理别名, 直接从保存有别名的hashMap中取出即可
*/
@SuppressWarnings("unchecked")
public <T> Class<T> resolveAlias(String string) {
try {
if (string == null) return null;
String key = string.toLowerCase(Locale.ENGLISH); // issue #748
Class<T> value;
if (TYPE_ALIASES.containsKey(key)) {
value = (Class<T>) TYPE_ALIASES.get(key);
} else {
value = (Class<T>) Resources.classForName(string);
}
return value;
} catch (ClassNotFoundException e) {
throw new TypeException("Could not resolve type alias '" + string + "'. Cause: " + e, e);
}
}
/**
* 配置文件中配置为package的时候, 会调用此方法,根据配置的报名去扫描javabean ,然后自动注册别名
* 默认会使用 Bean 的首字母小写的非限定类名来作为它的别名
* 也可在javabean 加上注解@Alias 来自定义别名, 例如: @Alias(user)
*/
public void registerAliases(String packageName){
registerAliases(packageName, Object.class);
}
public void registerAliases(String packageName, Class<?> superType){
ResolverUtil<Class<?>> resolverUtil = new ResolverUtil<Class<?>>();
resolverUtil.find(new ResolverUtil.IsA(superType), packageName);
Set<Class<? extends Class<?>>> typeSet = resolverUtil.getClasses();
for(Class<?> type : typeSet){
// Ignore inner classes and interfaces (including package-info.java)
// Skip also inner classes. See issue #6
if (!type.isAnonymousClass() && !type.isInterface() && !type.isMemberClass()) {
registerAlias(type);
}
}
}
public void registerAlias(Class<?> type) {
String alias = type.getSimpleName();
Alias aliasAnnotation = type.getAnnotation(Alias.class);
if (aliasAnnotation != null) {
alias = aliasAnnotation.value();
}
registerAlias(alias, type);
}
//这就是注册别名的本质方法, 其实就是向保存别名的hashMap新增值而已, 呵呵, 别名的实现太简单了,对吧
public void registerAlias(String alias, Class<?> value) {
if (alias == null) throw new TypeException("The parameter alias cannot be null");
String key = alias.toLowerCase(Locale.ENGLISH); // issue #748
if (TYPE_ALIASES.containsKey(key) && TYPE_ALIASES.get(key) != null && !TYPE_ALIASES.get(key).equals(value)) {
throw new TypeException("The alias '" + alias + "' is already mapped to the value '" + TYPE_ALIASES.get(key).getName() + "'.");
}
TYPE_ALIASES.put(key, value);
}
public void registerAlias(String alias, String value) {
try {
registerAlias(alias, Resources.classForName(value));
} catch (ClassNotFoundException e) {
throw new TypeException("Error registering type alias "+alias+" for "+value+". Cause: " + e, e);
}
}
/**
* 获取保存别名的HashMap, Configuration对象持有对TypeAliasRegistry的引用,因此,如果需要,我们可以通过Configuration对象获取
*/
public Map<String, Class<?>> getTypeAliases() {
return Collections.unmodifiableMap(TYPE_ALIASES);
}
}
由源码可见,设置别名的原理就这么简单,Mybatis默认给我们设置了不少别名,在上面代码中都可以见到。
TypeHandler
Mybatis中的TypeHandler是什么?
无论是 MyBatis 在预处理语句(PreparedStatement)中设置一个参数时,还是从结果集中取出一个值时,都会用类型处理器将获取的值以合适的方式转换成 Java 类型。Mybatis默认为我们实现了许多TypeHandler, 当我们没有配置指定TypeHandler时,Mybatis会根据参数或者返回结果的不同,默认为我们选择合适的TypeHandler处理。
那么,Mybatis为我们实现了哪些TypeHandler呢? 我们怎么自定义实现一个TypeHandler ? 这些都会在接下来的mybatis的源码中看到。
先看看配置:
<configuration>
<typeHandlers>
<!--
当配置package的时候,mybatis会去配置的package扫描TypeHandler
<package name="com.dy.demo"/>
-->
<!-- handler属性直接配置我们要指定的TypeHandler -->
<typeHandler handler=""/>
<!-- javaType 配置java类型,例如String, 如果配上javaType, 那么指定的typeHandler就只作用于指定的类型 -->
<typeHandler javaType="" handler=""/>
<!-- jdbcType 配置数据库基本数据类型,例如varchar, 如果配上jdbcType, 那么指定的typeHandler就只作用于指定的类型 -->
<typeHandler jdbcType="" handler=""/>
<!-- 也可两者都配置 -->
<typeHandler javaType="" jdbcType="" handler=""/>
</typeHandlers>
......
</configuration>
typeHandlerElement
老规矩,先从对xml的解析讲起
/**
* 解析typeHandlers节点
*/
private void typeHandlerElement(XNode parent) throws Exception {
if (parent != null) {
for (XNode child : parent.getChildren()) {
//子节点为package时,获取其name属性的值,然后自动扫描package下的自定义typeHandler
if ("package".equals(child.getName())) {
String typeHandlerPackage = child.getStringAttribute("name");
typeHandlerRegistry.register(typeHandlerPackage);
} else {
//子节点为typeHandler时, 可以指定javaType属性, 也可以指定jdbcType, 也可两者都指定
//javaType 是指定java类型
//jdbcType 是指定jdbc类型(数据库类型: 如varchar)
String javaTypeName = child.getStringAttribute("javaType");
String jdbcTypeName = child.getStringAttribute("jdbcType");
//handler就是我们配置的typeHandler
String handlerTypeName = child.getStringAttribute("handler");
//resolveClass方法就是我们上篇文章所讲的TypeAliasRegistry里面处理别名的方法
Class<?> javaTypeClass = resolveClass(javaTypeName);
//JdbcType是一个枚举类型,resolveJdbcType方法是在获取枚举类型的值
JdbcType jdbcType = resolveJdbcType(jdbcTypeName);
Class<?> typeHandlerClass = resolveClass(handlerTypeName);
//注册typeHandler, typeHandler通过TypeHandlerRegistry这个类管理
if (javaTypeClass != null) {
if (jdbcType == null) {
typeHandlerRegistry.register(javaTypeClass, typeHandlerClass);
} else {
typeHandlerRegistry.register(javaTypeClass, jdbcType, typeHandlerClass);
}
} else {
typeHandlerRegistry.register(typeHandlerClass);
}
}
}
}
}
接下来看看TypeHandler的管理注册类:TypeHandlerRegistry.java
/**
* typeHandler注册管理类
*/
public final class TypeHandlerRegistry {
//源码一上来,二话不说,几个大大的HashMap就出现,这不又跟上次讲的typeAliases的注册类似么
//基本数据类型与其包装类
private static final Map<Class<?>, Class<?>> reversePrimitiveMap = new HashMap<Class<?>, Class<?>>() {
private static final long serialVersionUID = 1L;
{
put(Byte.class, byte.class);
put(Short.class, short.class);
put(Integer.class, int.class);
put(Long.class, long.class);
put(Float.class, float.class);
put(Double.class, double.class);
put(Boolean.class, boolean.class);
put(Character.class, char.class);
}
};
//这几个MAP不用说就知道存的是什么东西吧,命名的好处
private final Map<JdbcType, TypeHandler<?>> JDBC_TYPE_HANDLER_MAP = new EnumMap<JdbcType, TypeHandler<?>>(JdbcType.class);
private final Map<Type, Map<JdbcType, TypeHandler<?>>> TYPE_HANDLER_MAP = new HashMap<Type, Map<JdbcType, TypeHandler<?>>>();
private final TypeHandler<Object> UNKNOWN_TYPE_HANDLER = new UnknownTypeHandler(this);
private final Map<Class<?>, TypeHandler<?>> ALL_TYPE_HANDLERS_MAP = new HashMap<Class<?>, TypeHandler<?>>();
//就像上篇文章讲的typeAliases一样,mybatis也默认给我们注册了不少的typeHandler
//具体如下
public TypeHandlerRegistry() {
register(Boolean.class, new BooleanTypeHandler());
register(boolean.class, new BooleanTypeHandler());
register(JdbcType.BOOLEAN, new BooleanTypeHandler());
register(JdbcType.BIT, new BooleanTypeHandler());
register(Byte.class, new ByteTypeHandler());
register(byte.class, new ByteTypeHandler());
register(JdbcType.TINYINT, new ByteTypeHandler());
register(Short.class, new ShortTypeHandler());
register(short.class, new ShortTypeHandler());
register(JdbcType.SMALLINT, new ShortTypeHandler());
register(Integer.class, new IntegerTypeHandler());
register(int.class, new IntegerTypeHandler());
register(JdbcType.INTEGER, new IntegerTypeHandler());
register(Long.class, new LongTypeHandler());
register(long.class, new LongTypeHandler());
register(Float.class, new FloatTypeHandler());
register(float.class, new FloatTypeHandler());
register(JdbcType.FLOAT, new FloatTypeHandler());
register(Double.class, new DoubleTypeHandler());
register(double.class, new DoubleTypeHandler());
register(JdbcType.DOUBLE, new DoubleTypeHandler());
register(String.class, new StringTypeHandler());
register(String.class, JdbcType.CHAR, new StringTypeHandler());
register(String.class, JdbcType.CLOB, new ClobTypeHandler());
register(String.class, JdbcType.VARCHAR, new StringTypeHandler());
register(String.class, JdbcType.LONGVARCHAR, new ClobTypeHandler());
register(String.class, JdbcType.NVARCHAR, new NStringTypeHandler());
register(String.class, JdbcType.NCHAR, new NStringTypeHandler());
register(String.class, JdbcType.NCLOB, new NClobTypeHandler());
register(JdbcType.CHAR, new StringTypeHandler());
register(JdbcType.VARCHAR, new StringTypeHandler());
register(JdbcType.CLOB, new ClobTypeHandler());
register(JdbcType.LONGVARCHAR, new ClobTypeHandler());
register(JdbcType.NVARCHAR, new NStringTypeHandler());
register(JdbcType.NCHAR, new NStringTypeHandler());
register(JdbcType.NCLOB, new NClobTypeHandler());
register(Object.class, JdbcType.ARRAY, new ArrayTypeHandler());
register(JdbcType.ARRAY, new ArrayTypeHandler());
register(BigInteger.class, new BigIntegerTypeHandler());
register(JdbcType.BIGINT, new LongTypeHandler());
register(BigDecimal.class, new BigDecimalTypeHandler());
register(JdbcType.REAL, new BigDecimalTypeHandler());
register(JdbcType.DECIMAL, new BigDecimalTypeHandler());
register(JdbcType.NUMERIC, new BigDecimalTypeHandler());
register(Byte[].class, new ByteObjectArrayTypeHandler());
register(Byte[].class, JdbcType.BLOB, new BlobByteObjectArrayTypeHandler());
register(Byte[].class, JdbcType.LONGVARBINARY, new BlobByteObjectArrayTypeHandler());
register(byte[].class, new ByteArrayTypeHandler());
register(byte[].class, JdbcType.BLOB, new BlobTypeHandler());
register(byte[].class, JdbcType.LONGVARBINARY, new BlobTypeHandler());
register(JdbcType.LONGVARBINARY, new BlobTypeHandler());
register(JdbcType.BLOB, new BlobTypeHandler());
register(Object.class, UNKNOWN_TYPE_HANDLER);
register(Object.class, JdbcType.OTHER, UNKNOWN_TYPE_HANDLER);
register(JdbcType.OTHER, UNKNOWN_TYPE_HANDLER);
register(Date.class, new DateTypeHandler());
register(Date.class, JdbcType.DATE, new DateOnlyTypeHandler());
register(Date.class, JdbcType.TIME, new TimeOnlyTypeHandler());
register(JdbcType.TIMESTAMP, new DateTypeHandler());
register(JdbcType.DATE, new DateOnlyTypeHandler());
register(JdbcType.TIME, new TimeOnlyTypeHandler());
register(java.sql.Date.class, new SqlDateTypeHandler());
register(java.sql.Time.class, new SqlTimeTypeHandler());
register(java.sql.Timestamp.class, new SqlTimestampTypeHandler());
// issue #273
register(Character.class, new CharacterTypeHandler());
register(char.class, new CharacterTypeHandler());
}
public boolean hasTypeHandler(Class<?> javaType) {
return hasTypeHandler(javaType, null);
}
public boolean hasTypeHandler(TypeReference<?> javaTypeReference) {
return hasTypeHandler(javaTypeReference, null);
}
public boolean hasTypeHandler(Class<?> javaType, JdbcType jdbcType) {
return javaType != null && getTypeHandler((Type) javaType, jdbcType) != null;
}
public boolean hasTypeHandler(TypeReference<?> javaTypeReference, JdbcType jdbcType) {
return javaTypeReference != null && getTypeHandler(javaTypeReference, jdbcType) != null;
}
public TypeHandler<?> getMappingTypeHandler(Class<? extends TypeHandler<?>> handlerType) {
return ALL_TYPE_HANDLERS_MAP.get(handlerType);
}
public <T> TypeHandler<T> getTypeHandler(Class<T> type) {
return getTypeHandler((Type) type, null);
}
public <T> TypeHandler<T> getTypeHandler(TypeReference<T> javaTypeReference) {
return getTypeHandler(javaTypeReference, null);
}
public TypeHandler<?> getTypeHandler(JdbcType jdbcType) {
return JDBC_TYPE_HANDLER_MAP.get(jdbcType);
}
public <T> TypeHandler<T> getTypeHandler(Class<T> type, JdbcType jdbcType) {
return getTypeHandler((Type) type, jdbcType);
}
public <T> TypeHandler<T> getTypeHandler(TypeReference<T> javaTypeReference, JdbcType jdbcType) {
return getTypeHandler(javaTypeReference.getRawType(), jdbcType);
}
private <T> TypeHandler<T> getTypeHandler(Type type, JdbcType jdbcType) {
Map<JdbcType, TypeHandler<?>> jdbcHandlerMap = TYPE_HANDLER_MAP.get(type);
TypeHandler<?> handler = null;
if (jdbcHandlerMap != null) {
handler = jdbcHandlerMap.get(jdbcType);
if (handler == null) {
handler = jdbcHandlerMap.get(null);
}
}
if (handler == null && type != null && type instanceof Class && Enum.class.isAssignableFrom((Class<?>) type)) {
handler = new EnumTypeHandler((Class<?>) type);
}
@SuppressWarnings("unchecked")
// type drives generics here
TypeHandler<T> returned = (TypeHandler<T>) handler;
return returned;
}
public TypeHandler<Object> getUnknownTypeHandler() {
return UNKNOWN_TYPE_HANDLER;
}
public void register(JdbcType jdbcType, TypeHandler<?> handler) {
JDBC_TYPE_HANDLER_MAP.put(jdbcType, handler);
}
//
// REGISTER INSTANCE
//
/**
* 只配置了typeHandler, 没有配置jdbcType 或者javaType
*/
@SuppressWarnings("unchecked")
public <T> void register(TypeHandler<T> typeHandler) {
boolean mappedTypeFound = false;
//在自定义typeHandler的时候,可以加上注解MappedTypes 去指定关联的javaType
//因此,此处需要扫描MappedTypes注解
MappedTypes mappedTypes = typeHandler.getClass().getAnnotation(MappedTypes.class);
if (mappedTypes != null) {
for (Class<?> handledType : mappedTypes.value()) {
register(handledType, typeHandler);
mappedTypeFound = true;
}
}
// @since 3.1.0 - try to auto-discover the mapped type
if (!mappedTypeFound && typeHandler instanceof TypeReference) {
try {
TypeReference<T> typeReference = (TypeReference<T>) typeHandler;
register(typeReference.getRawType(), typeHandler);
mappedTypeFound = true;
} catch (Throwable t) {
// maybe users define the TypeReference with a different type and are not assignable, so just ignore it
}
}
if (!mappedTypeFound) {
register((Class<T>) null, typeHandler);
}
}
/**
* 配置了typeHandlerhe和javaType
*/
public <T> void register(Class<T> javaType, TypeHandler<? extends T> typeHandler) {
register((Type) javaType, typeHandler);
}
private <T> void register(Type javaType, TypeHandler<? extends T> typeHandler) {
//扫描注解MappedJdbcTypes
MappedJdbcTypes mappedJdbcTypes = typeHandler.getClass().getAnnotation(MappedJdbcTypes.class);
if (mappedJdbcTypes != null) {
for (JdbcType handledJdbcType : mappedJdbcTypes.value()) {
register(javaType, handledJdbcType, typeHandler);
}
if (mappedJdbcTypes.includeNullJdbcType()) {
register(javaType, null, typeHandler);
}
} else {
register(javaType, null, typeHandler);
}
}
public <T> void register(TypeReference<T> javaTypeReference, TypeHandler<? extends T> handler) {
register(javaTypeReference.getRawType(), handler);
}
/**
* typeHandlerhe、javaType、jdbcType都配置了
*/
public <T> void register(Class<T> type, JdbcType jdbcType, TypeHandler<? extends T> handler) {
register((Type) type, jdbcType, handler);
}
/**
* 注册typeHandler的核心方法
* 就是向Map新增数据而已
*/
private void register(Type javaType, JdbcType jdbcType, TypeHandler<?> handler) {
if (javaType != null) {
Map<JdbcType, TypeHandler<?>> map = TYPE_HANDLER_MAP.get(javaType);
if (map == null) {
map = new HashMap<JdbcType, TypeHandler<?>>();
TYPE_HANDLER_MAP.put(javaType, map);
}
map.put(jdbcType, handler);
if (reversePrimitiveMap.containsKey(javaType)) {
register(reversePrimitiveMap.get(javaType), jdbcType, handler);
}
}
ALL_TYPE_HANDLERS_MAP.put(handler.getClass(), handler);
}
//
// REGISTER CLASS
//
// Only handler type
public void register(Class<?> typeHandlerClass) {
boolean mappedTypeFound = false;
MappedTypes mappedTypes = typeHandlerClass.getAnnotation(MappedTypes.class);
if (mappedTypes != null) {
for (Class<?> javaTypeClass : mappedTypes.value()) {
register(javaTypeClass, typeHandlerClass);
mappedTypeFound = true;
}
}
if (!mappedTypeFound) {
register(getInstance(null, typeHandlerClass));
}
}
// java type + handler type
public void register(Class<?> javaTypeClass, Class<?> typeHandlerClass) {
register(javaTypeClass, getInstance(javaTypeClass, typeHandlerClass));
}
// java type + jdbc type + handler type
public void register(Class<?> javaTypeClass, JdbcType jdbcType, Class<?> typeHandlerClass) {
register(javaTypeClass, jdbcType, getInstance(javaTypeClass, typeHandlerClass));
}
// Construct a handler (used also from Builders)
@SuppressWarnings("unchecked")
public <T> TypeHandler<T> getInstance(Class<?> javaTypeClass, Class<?> typeHandlerClass) {
if (javaTypeClass != null) {
try {
Constructor<?> c = typeHandlerClass.getConstructor(Class.class);
return (TypeHandler<T>) c.newInstance(javaTypeClass);
} catch (NoSuchMethodException ignored) {
// ignored
} catch (Exception e) {
throw new TypeException("Failed invoking constructor for handler " + typeHandlerClass, e);
}
}
try {
Constructor<?> c = typeHandlerClass.getConstructor();
return (TypeHandler<T>) c.newInstance();
} catch (Exception e) {
throw new TypeException("Unable to find a usable constructor for " + typeHandlerClass, e);
}
}
/**
* 根据指定的pacakge去扫描自定义的typeHander,然后注册
*/
public void register(String packageName) {
ResolverUtil<Class<?>> resolverUtil = new ResolverUtil<Class<?>>();
resolverUtil.find(new ResolverUtil.IsA(TypeHandler.class), packageName);
Set<Class<? extends Class<?>>> handlerSet = resolverUtil.getClasses();
for (Class<?> type : handlerSet) {
//Ignore inner classes and interfaces (including package-info.java) and abstract classes
if (!type.isAnonymousClass() && !type.isInterface() && !Modifier.isAbstract(type.getModifiers())) {
register(type);
}
}
}
// get information
/**
* 通过configuration对象可以获取已注册的所有typeHandler
*/
public Collection<TypeHandler<?>> getTypeHandlers() {
return Collections.unmodifiableCollection(ALL_TYPE_HANDLERS_MAP.values());
}
}
由源码可以看到, mybatis为我们实现了那么多TypeHandler, 随便打开一个TypeHandler,看其源码,都可以看到,它继承自一个抽象类:BaseTypeHandler, 那么我们是不是也能通过继承BaseTypeHandler,从而实现自定义的TypeHandler ? 答案是肯定的,
演示自定义TypeHandler:
@MappedJdbcTypes(JdbcType.VARCHAR)
//此处如果不用注解指定jdbcType, 那么,就可以在配置文件中通过"jdbcType"属性指定, 同理, javaType 也可通过 @MappedTypes指定
public class ExampleTypeHandler extends BaseTypeHandler<String> {
@Override
public void setNonNullParameter(PreparedStatement ps, int i, String parameter, JdbcType jdbcType) throws SQLException {
ps.setString(i, parameter);
}
@Override
public String getNullableResult(ResultSet rs, String columnName) throws SQLException {
return rs.getString(columnName);
}
@Override
public String getNullableResult(ResultSet rs, int columnIndex) throws SQLException {
return rs.getString(columnIndex);
}
@Override
public String getNullableResult(CallableStatement cs, int columnIndex) throws SQLException {
return cs.getString(columnIndex);
}
}
然后,就该配置自定义TypeHandler了:
<configuration>
<typeHandlers>
<!-- 由于自定义的TypeHandler在定义时已经通过注解指定了jdbcType, 所以此处不用再配置jdbcType -->
<typeHandler handler="ExampleTypeHandler"/>
</typeHandlers>
......
</configuration>
也就是说,我们在自定义TypeHandler的时候,可以在TypeHandler通过@MappedJdbcTypes指定jdbcType, 通过 @MappedTypes 指定javaType, 如果没有使用注解指定,那么我们就需要在配置文件中配置。
objectFactory
objectFactory是干什么的? 需要配置吗?
MyBatis 每次创建结果对象的新实例时,它都会使用一个对象工厂(ObjectFactory)实例来完成。默认的对象工厂需要做的仅仅是实例化目标类,要么通过默认构造方法,要么在参数映射存在的时候通过参数构造方法来实例化。默认情况下,我们不需要配置,mybatis会调用默认实现的objectFactory。 除非我们要自定义ObjectFactory的实现, 那么我们才需要去手动配置。
那么怎么自定义实现ObjectFactory? 怎么配置呢?自定义ObjectFactory只需要去继承DefaultObjectFactory(是ObjectFactory接口的实现类),并重写其方法即可。具体的,本处不多说,后面再具体讲解。
写好了ObjectFactory, 仅需做如下配置:
<configuration>
......
<objectFactory type="org.mybatis.example.ExampleObjectFactory">
<property name="someProperty" value="100"/>
</objectFactory>
......
</configuration>
objectFactoryElement源码:
/**
* objectFactory 节点解析
*/
private void objectFactoryElement(XNode context) throws Exception {
if (context != null) {
//读取type属性的值, 接下来进行实例化ObjectFactory, 并set进 configuration
//到此,简单讲一下configuration这个对象,其实它里面主要保存的都是mybatis的配置
String type = context.getStringAttribute("type");
//读取propertie的值, 根据需要可以配置, mybatis默认实现的objectFactory没有使用properties
Properties properties = context.getChildrenAsProperties();
ObjectFactory factory = (ObjectFactory) resolveClass(type).newInstance();
factory.setProperties(properties);
configuration.setObjectFactory(factory);
}
}
plugins
plugin有何作用? 需要配置吗?
plugins 是一个可选配置。mybatis中的plugin其实就是个interceptor, 它可以拦截Executor 、ParameterHandler 、ResultSetHandler 、StatementHandler 的部分方法,处理我们自己的逻辑。Executor就是真正执行sql语句的东西, ParameterHandler 是处理我们传入参数的,还记得前面讲TypeHandler的时候提到过,mybatis默认帮我们实现了不少的typeHandler, 当我们不显示配置typeHandler的时候,mybatis会根据参数类型自动选择合适的typeHandler执行,其实就是ParameterHandler 在选择。ResultSetHandler 就是处理返回结果的。
怎么自定义plugin ? 怎么配置?要自定义一个plugin, 需要去实现Interceptor接口,这儿不细说,后面实战部分会详细讲解。定义好之后,配置如下:
<configuration>
......
<plugins>
<plugin interceptor="org.mybatis.example.ExamplePlugin">
<property name="someProperty" value="100"/>
</plugin>
</plugins>
......
</configuration>
pluginElement源码:
/**
* plugins 节点解析
*/
private void pluginElement(XNode parent) throws Exception {
if (parent != null) {
for (XNode child : parent.getChildren()) {
String interceptor = child.getStringAttribute("interceptor");
Properties properties = child.getChildrenAsProperties();
//由此可见,我们在定义一个interceptor的时候,需要去实现Interceptor, 这儿先不具体讲,以后会详细讲解
Interceptor interceptorInstance = (Interceptor) resolveClass(interceptor).newInstance();
interceptorInstance.setProperties(properties);
configuration.addInterceptor(interceptorInstance);
}
}
}
mappers
mappers, 这下引出mybatis的核心之一了,mappers作用 ? 需要配置吗?
mappers 节点下,配置我们的mapper映射文件, 所谓的mapper映射文件,就是让mybatis 用来建立数据表和javabean映射的一个桥梁。在我们实际开发中,通常一个mapper文件对应一个dao接口, 这个mapper可以看做是dao的实现。所以,mappers必须配置。
<configuration>
......
<mappers>
<!-- 第一种方式:通过resource指定 -->
<mapper resource="com/dy/dao/userDao.xml"/>
<!-- 第二种方式, 通过class指定接口,进而将接口与对应的xml文件形成映射关系
不过,使用这种方式必须保证 接口与mapper文件同名(不区分大小写),
我这儿接口是UserDao,那么意味着mapper文件为UserDao.xml
<mapper class="com.dy.dao.UserDao"/>
-->
<!-- 第三种方式,直接指定包,自动扫描,与方法二同理
<package name="com.dy.dao"/>
-->
<!-- 第四种方式:通过url指定mapper文件位置
<mapper url="file://........"/>
-->
</mappers>
......
</configuration>
mapperElement源码:
/**
* mappers 节点解析
* 这是mybatis的核心之一
*/
private void mapperElement(XNode parent) throws Exception {
if (parent != null) {
for (XNode child : parent.getChildren()) {
if ("package".equals(child.getName())) {
//如果mappers节点的子节点是package, 那么就扫描package下的文件, 注入进configuration
String mapperPackage = child.getStringAttribute("name");
configuration.addMappers(mapperPackage);
} else {
String resource = child.getStringAttribute("resource");
String url = child.getStringAttribute("url");
String mapperClass = child.getStringAttribute("class");
//resource, url, class 三选一
if (resource != null && url == null && mapperClass == null) {
ErrorContext.instance().resource(resource);
InputStream inputStream = Resources.getResourceAsStream(resource);
//mapper映射文件都是通过XMLMapperBuilder解析
XMLMapperBuilder mapperParser = new XMLMapperBuilder(inputStream, configuration, resource, configuration.getSqlFragments());
mapperParser.parse();
} else if (resource == null && url != null && mapperClass == null) {
ErrorContext.instance().resource(url);
InputStream inputStream = Resources.getUrlAsStream(url);
XMLMapperBuilder mapperParser = new XMLMapperBuilder(inputStream, configuration, url, configuration.getSqlFragments());
mapperParser.parse();
} else if (resource == null && url == null && mapperClass != null) {
Class<?> mapperInterface = Resources.classForName(mapperClass);
configuration.addMapper(mapperInterface);
} else {
throw new BuilderException("A mapper element may only specify a url, resource or class, but not more than one.");
}
}
}
}
}
settings
<settings>
<setting name="cacheEnabled" value="true"/>
<setting name="lazyLoadingEnabled" value="true"/>
<setting name="multipleResultSetsEnabled" value="true"/>
<setting name="useColumnLabel" value="true"/>
<setting name="useGeneratedKeys" value="false"/>
<setting name="enhancementEnabled" value="false"/>
<setting name="defaultExecutorType" value="SIMPLE"/>
<setting name="defaultStatementTimeout" value="25000"/>
</settings>
setting节点里配置的值会直接改写Configuration对应的变量值,这些变量描述的是Mybatis的全局运行方式,如果对这些属性的含义不熟悉的话建议不要配置,使用默认值即可。
settingsElement:
private void settingsElement(XNode context) throws Exception {
if (context != null) {
Properties props = context.getChildrenAsProperties();
// Check that all settings are known to the configuration class
MetaClass metaConfig = MetaClass.forClass(Configuration.class);
for (Object key : props.keySet()) {
if (!metaConfig.hasSetter(String.valueOf(key))) {
throw new BuilderException("The setting " + key + " is not known. Make sure you spelled it correctly (case sensitive).");
}
}
configuration.setAutoMappingBehavior(AutoMappingBehavior.valueOf(props.getProperty("autoMappingBehavior", "PARTIAL")));
configuration.setCacheEnabled(booleanValueOf(props.getProperty("cacheEnabled"), true));
configuration.setProxyFactory((ProxyFactory) createInstance(props.getProperty("proxyFactory")));
configuration.setLazyLoadingEnabled(booleanValueOf(props.getProperty("lazyLoadingEnabled"), false));
configuration.setAggressiveLazyLoading(booleanValueOf(props.getProperty("aggressiveLazyLoading"), true));
configuration.setMultipleResultSetsEnabled(booleanValueOf(props.getProperty("multipleResultSetsEnabled"), true));
configuration.setUseColumnLabel(booleanValueOf(props.getProperty("useColumnLabel"), true));
configuration.setUseGeneratedKeys(booleanValueOf(props.getProperty("useGeneratedKeys"), false));
configuration.setDefaultExecutorType(ExecutorType.valueOf(props.getProperty("defaultExecutorType", "SIMPLE")));
configuration.setDefaultStatementTimeout(integerValueOf(props.getProperty("defaultStatementTimeout"), null));
configuration.setMapUnderscoreToCamelCase(booleanValueOf(props.getProperty("mapUnderscoreToCamelCase"), false));
configuration.setSafeRowBoundsEnabled(booleanValueOf(props.getProperty("safeRowBoundsEnabled"), false));
configuration.setLocalCacheScope(LocalCacheScope.valueOf(props.getProperty("localCacheScope", "SESSION")));
configuration.setJdbcTypeForNull(JdbcType.valueOf(props.getProperty("jdbcTypeForNull", "OTHER")));
configuration.setLazyLoadTriggerMethods(stringSetValueOf(props.getProperty("lazyLoadTriggerMethods"), "equals,clone,hashCode,toString"));
configuration.setSafeResultHandlerEnabled(booleanValueOf(props.getProperty("safeResultHandlerEnabled"), true));
configuration.setDefaultScriptingLanguage(resolveClass(props.getProperty("defaultScriptingLanguage")));
configuration.setCallSettersOnNulls(booleanValueOf(props.getProperty("callSettersOnNulls"), false));
configuration.setLogPrefix(props.getProperty("logPrefix"));
configuration.setLogImpl(resolveClass(props.getProperty("logImpl")));
configuration.setConfigurationFactory(resolveClass(props.getProperty("configurationFactory")));
}
}