读懂华为开发者空间第一课,让云上开发如此简单
近日,华为云上线的《华为开发者空间快速入门》课程,汇聚了理论知识讲解、案例介绍和丰富的实践练习,通过循序渐进的学习路径
,开发者可以快速了解华为开发者空间
,体验更简洁、更高效、更友好的华为开发者空间应用开发旅程。
开发者通过课程学习,可以体验华为开发者空间具有的开发桌面(云主机)便捷访问、开发者工具合集开箱即用、开发者沙箱调测资源灵活调用、开发者成长数据云上保存等核心功能。
点击链接
,开始学习课程。

课程看点
课程由浅入深带领开发者了解华为开发者空间,包含鲲鹏、昇腾、鸿蒙等华为优质开发工具和资源、真实项目开发案例等,构建对华为开发者空间的系统性认知框架;
不同技术领域的案例演示,让开发者亲历开发应用,提升运用华为开发者空间解决实际编码场景问题的能力。
认知了解篇:华为开发者空间支持开发者工作旅程
课程从开发桌面、工具使用、调测环境、资产存储、会员权益、获取激励、技术支持方面详细介绍了华为开发者空间是如何支持开发者的工作旅程。
开发者通过云主机中预置好的CodeArts IDE等工具及运行时组件进行开发时,可以选择使用Java/Python/C/C++等语言。

接下来分享一个用户案例的实践
《Python语言程序课程设计》
环境搭建、维护,方便开发者更好理解:
某高校老师在实践类教学环境准备中面临缺少环境、缺少工具、重要数据易丢失等问题。
通过华为开发者空间云主机,将教学环境一次性预装好,形成一套标准化的开箱即用教学环境,学生和老师不仅节省了环境搭建的时间,而且老师的教学数据和学生的学习实践数据实时保存在华为开发者空间,学生能够保存和随时查看实践数据。
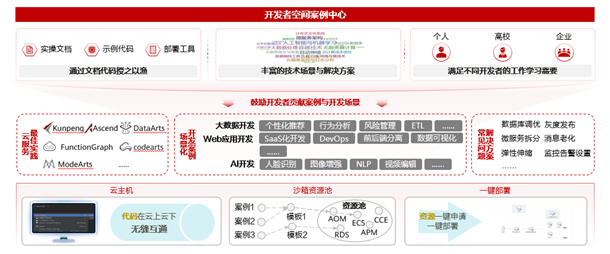
案例演示篇:华为开发者空间场景案例实践
案例演示课程包括理论讲解视频、案例演示视频、指导文档以及实践练习等,涉及人工智能、软件开发、Serverless不同技术领域的案例。这些案例均基于云主机操作,帮助开发者掌握云主机及华为工具的基本使用。在 “基于云主机的 Web 项目增添 AI 助手” 案例中,讲解和演示如何将 AI 技术融入 Web 项目,实现智能问答功能;“鲲鹏 DevKit 源码迁移” 案例则聚焦于让开发者亲身体验鲲鹏 DevKit 工具强大的代码迁移能力;“基于 FunctionGraph 的画图应用开发” 案例,开发者可以熟练操作函数创建、插件安装到应用部署以及与 API 网关集成等步骤,从而掌握 FunctionGraph 的基本使用方法。
实践练习篇:使用华为开发者空间构建个人应用
在华为开发者空间的课程体系中,我们配备了实践练习环节, 可以让开发者学以致用,完整的体验开发流程。本次实践主题为“基于云主机实现 AI 对春联”,让开发者在云主机内使用Python环境搭建,并完成模型训练以及推理预测,涉及使用CodeArts IDE、OBS、Ubuntu、Python等技术。在此过程中,开发者将熟练掌握运用华为开发者空间进行应用构建的技能,为日后的实际项目开发筑牢坚实基础。
拓展篇:Ubuntu系统和CodeArts IDE for Python使用入门
在本章节课程中,介绍了Ubuntu系统与 CodeArts IDE for Python 的基本使用方法,可以帮助开发者熟悉操作系统和使用工具。
课程介绍了Ubuntu系统里主要目录的用途,包括开关机、查看系统信息等基础命令和关键热键的操作。
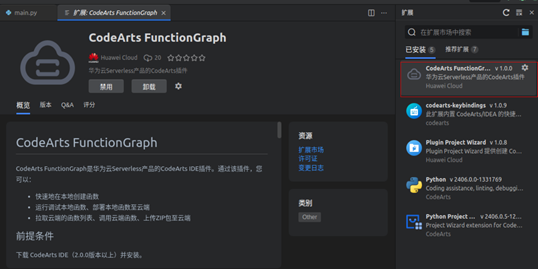
同时,课程还介绍了CodeArts IDE for Python的使用方法,如断点调试、添加注释等基础操作。CodeArts IDE 是面向华为云开发者提供的智能化可扩展桌面集成开发环境(IDE),它将精简的源代码编辑器与强大的开发者工具结合在一起。CodeArts IDE代码编辑-构建-调试的无缝循环使开发者不必在环境配置上花费太多时间,可以更多地专注于实现创意。
华为开发者空间是开发者专属的云上成长空间,汇聚了以华为云为底座的鲲鹏、昇腾、鸿蒙根技术工具和资源。华为开发者空间为每位开发者提供了一台云主机,让开发者可以低门槛使用华为工具、共享华为生态资源。未来,华为开发者空间将持续提升平台体验,集成更多的根生态资源,让开发者持续使用、持续成长、持续创新。