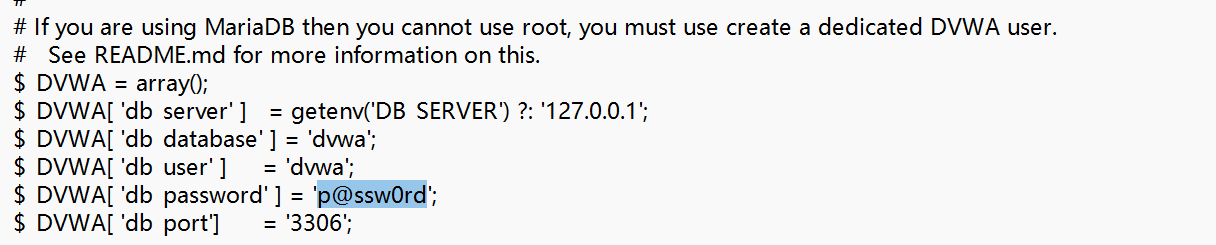
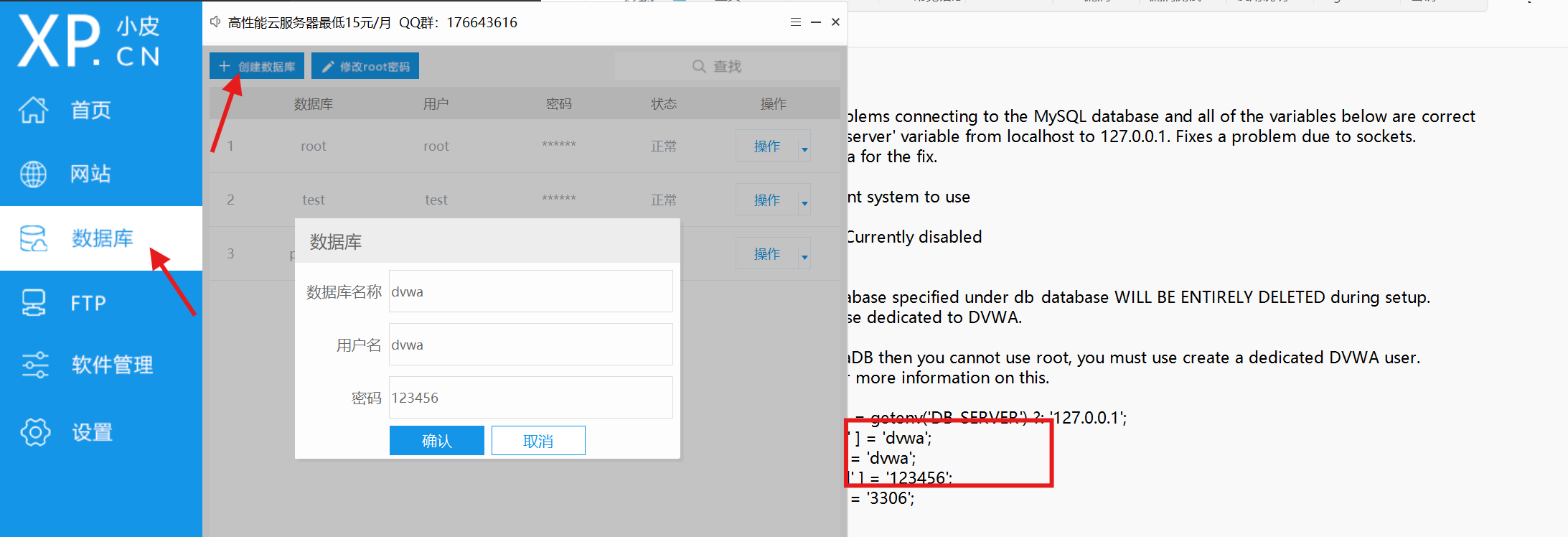
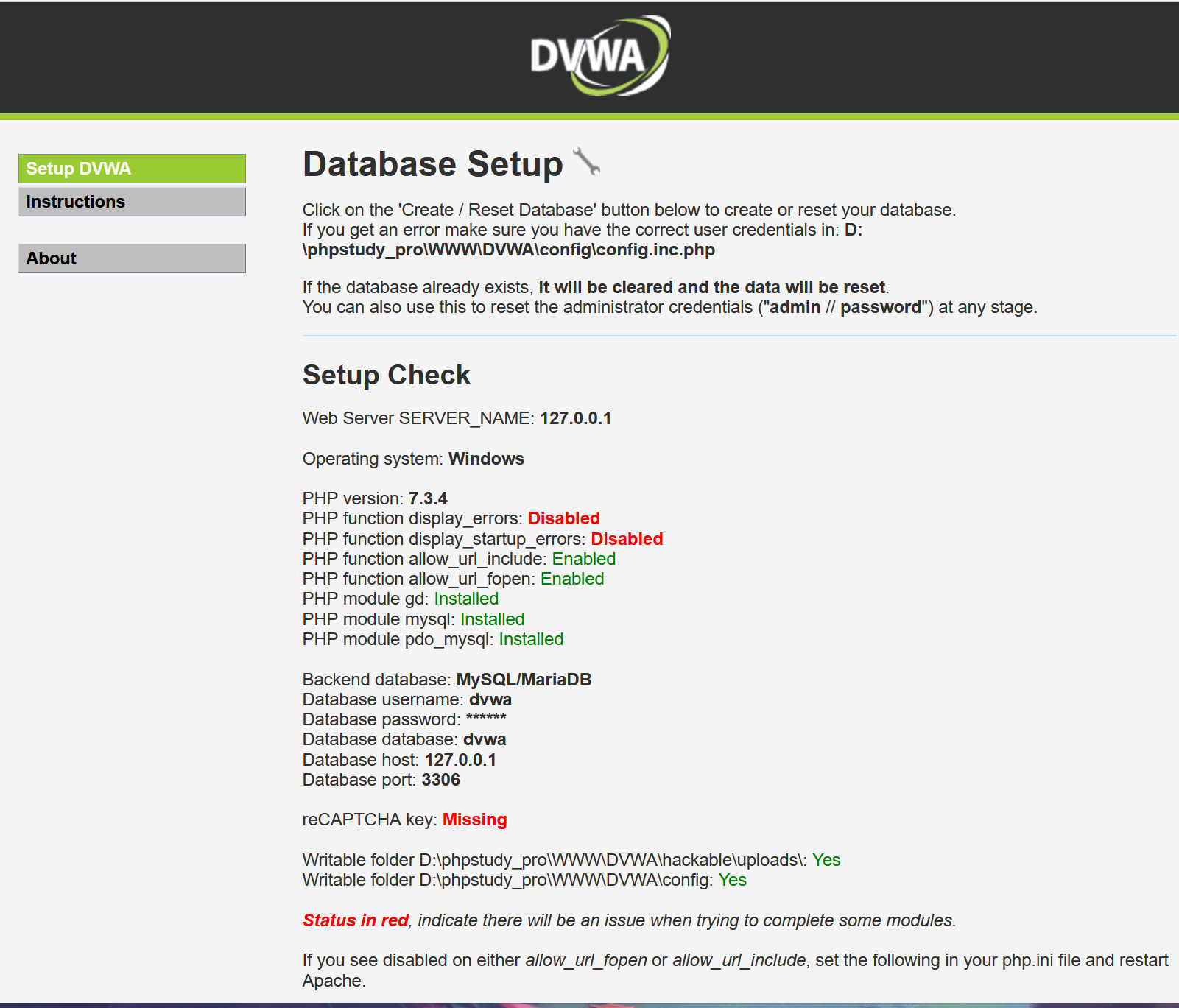
Stable Diffusion 是一个基于扩散模型的图像生成模型,可以用于生成高质量图像。其传统实现主要基于 PyTorch,最常用的开源实现是
CompVis/stable-diffusion
和 Hugging Face 的
diffusers
库。
如果你需要一个可以直接调用 Stable Diffusion 的接口,可以选择以下方法:
1.
使用 Hugging Face Diffusers
Hugging Face 的
diffusers
库提供了简单易用的接口,你可以通过以下代码调用:
from diffusers import StableDiffusionPipeline
# 加载模型(需要互联网)
pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4")
pipe.to("cuda") # 如果有 GPU,请使用 CUDA
# 生成图片
prompt = "a fantasy landscape, epic mountains and sunset"
image = pipe(prompt).images[0]
# 保存图片
image.save("output.png")
如果没有 GPU,可以改为 CPU 模式:
pipe.to("cpu")
需要注意,运行此代码需要安装
diffusers
库和依赖:
pip install diffusers transformers accelerate torch
2.
直接使用开源 Stable Diffusion 代码
CompVis/stable-diffusion
是最初的官方实现。安装完成后,可以使用以下命令行方式生成图像:
- 克隆项目并安装依赖:
git clone https://github.com/CompVis/stable-diffusion.git
cd stable-diffusion
conda env create -f environment.yaml
conda activate ldm
- 下载模型权重(需要去 Hugging Face 授权)并放置在
models/ldm/stable-diffusion-v1
文件夹中。
- 运行图像生成脚本:
python scripts/txt2img.py --prompt "a cat sitting on a table" --plms --n_samples 1 --n_iter 1 --H 512 --W 512
3.
调用 Stable Diffusion 的 Web API
如果不想在本地配置环境,可以使用提供 Stable Diffusion 的 API 服务。例如:
Replicate 是一个提供 Stable Diffusion 接口的平台,你可以通过简单的 API 调用生成图片。
以下是 Python 示例代码:
import replicate
# 设置 Replicate API Token
os.environ["REPLICATE_API_TOKEN"] = "your_replicate_api_token"
# 调用 API
model = replicate.models.get("stability-ai/stable-diffusion")
output = model.predict(prompt="a beautiful painting of a sunset over the ocean")
# 下载生成的图片
image_url = output[0]
print("Image URL:", image_url)
4.
其他 Stable Diffusion Web UI
可以考虑使用 Web UI,如
AUTOMATIC1111/stable-diffusion-webui
,它提供了功能丰富的图形界面,也支持通过 API 调用生成图像。
安装后可以运行以下 API 请求:
curl -X POST http://127.0.0.1:7860/sdapi/v1/txt2img \
-H "Content-Type: application/json" \
-d '{
"prompt": "a dog playing in the park",
"steps": 20
}'
这会返回生成图像的 Base64 编码,或者直接存储生成图片。
是的,基于开源 Stable Diffusion 代码,采样是生成图像的关键过程之一。Stable Diffusion 使用的是
扩散模型(Diffusion Model)
,其生成图像的过程包括两个主要阶段:
- 前向扩散过程(Forward Diffusion Process)
- 逆向扩散过程(Reverse Diffusion Process)
采样通常指的是逆向扩散过程,尤其是如何从随机噪声中逐步恢复清晰的图像。这一过程涉及到多个采样步骤,每一步都会减少图像中的噪声,直到最终生成清晰的图像。这个过程使用的是
采样算法
,例如 DDIM(Denoising Diffusion Implicit Models)和 PLMS(Pseudo Numerical Methods for Diffusion Models)等。
1.
采样过程概述
在 Stable Diffusion 中,采样的目标是从噪声(通常是高斯噪声)中反向推导出最终的图像。这个过程实际上是通过对扩散模型进行推理(inference)来完成的。它涉及以下步骤:
- 输入:
一个随机噪声图像(通常是高斯噪声)。
- 模型:
基于条件输入(如文本提示)和噪声图像的当前状态,模型预测下一个去噪步骤。
- 采样步骤:
反向扩散过程根据每一步的去噪结果来调整图像,直到图像趋近于清晰。
在采样过程中,模型通常会迭代多次,每次去噪一小部分。每次迭代的输出将作为下一步输入,直到最终图像产生。
2.
采样方法(Sampling Methods)
Stable Diffusion 中使用了几种不同的采样方法,其中最常见的包括
DDIM
和
PLMS
。以下是这些方法的简单介绍:
a.
DDIM (Denoising Diffusion Implicit Models)
DDIM 是一种非马尔可夫扩散模型,能够在更少的步骤中生成高质量的图像。它相较于传统的扩散模型在生成图像时更高效,并且能够控制生成的样式和细节。
b.
PLMS (Pseudo Numerical Methods for Diffusion Models)
PLMS 是另一种采样方法,它在生成过程中使用伪数值方法。PLMS 可以提供较为平滑的图像生成过程,减少一些常见的伪影问题。
c.
LMS (Laplacian Pyramid Sampling)
LMS 是一种增强型采样方法,通常用于提升图像质量并减少噪点,特别是在低分辨率下。
3.
开源 Stable Diffusion 中的采样实现
Stable Diffusion 的开源实现使用了 PyTorch 库,并通过不同的采样方法来生成图像。以下是典型的采样过程中的代码段:
a.
采样代码(以
diffusers
库为例)
在 Hugging Face 的
diffusers
库中,采样过程是在
StableDiffusionPipeline
中处理的。你可以通过设置
num_inference_steps
(推理步数)来控制采样过程中的迭代次数。
from diffusers import StableDiffusionPipeline
# 加载 Stable Diffusion 模型
pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4")
pipe.to("cuda")
# 设置提示词和采样参数
prompt = "a fantasy landscape, epic mountains and sunset"
num_inference_steps = 50 # 采样步数(迭代次数)
guidance_scale = 7.5 # 引导尺度,用于调整图像与提示词的匹配度
# 生成图像
image = pipe(prompt, num_inference_steps=num_inference_steps, guidance_scale=guidance_scale).images[0]
# 保存生成的图像
image.save("output.png")
b.
手动实现采样过程
在更底层的 Stable Diffusion 实现(例如在
CompVis/stable-diffusion
中),采样的过程通常是在
ldm.models.diffusion.ddim
或
ldm.models.diffusion.plms
文件中处理的。以下是一个简化的采样流程:
import torch
from torchvision import transforms
from ldm.models.diffusion.ddim import DDIMSampler
# 假设你已经加载了模型和权重
model = load_model_from_config('stable-diffusion-config.yaml')
sampler = DDIMSampler(model)
# 生成随机噪声
z = torch.randn([batch_size, channels, height, width]).cuda()
# 进行逆向扩散过程(采样过程)
for step in range(num_steps):
# 计算噪声的去噪
noise_pred = model(x_t, t)
# 更新图像
x_t = update_image(x_t, noise_pred)
# 每一步都去噪
if step % sampling_frequency == 0:
save_intermediate_image(x_t)
# 最终生成的图像
final_image = transform_to_image(x_t)
4.
采样步骤和参数
5.
采样方法的效果对比
- DDIM
方法可以在较少的步骤中得到质量不错的图像,非常适合高效生成。
- PLMS
在平滑图像的过程中表现更好,减少了图像的伪影,但可能需要更多的步骤来达到理想效果。
总结
在 Stable Diffusion 的开源实现中,采样过程是一个核心环节,直接影响图像生成的质量和效率。通过调整采样的步数、引导尺度以及选择不同的采样方法,可以在图像质量和生成速度之间找到平衡。你可以通过修改
num_inference_steps
、
guidance_scale
或选择不同的采样器(如 DDIM 或 PLMS)来调节生成过程。

根据你上传的文件结构,若要修改 Stable Diffusion 模型的行为,可以从以下文件和文件夹入手,具体取决于你想要修改的功能:
1. 修改核心模型逻辑
路径:
ldm/models/...
- 如果需要直接修改模型的架构,例如调整模型结构、权重加载逻辑或生成逻辑,可以查看
ldm
文件夹下的代码。
- 核心文件可能是与
ldm
相关的子模块(如
autoencoder
,
diffusion
,
unet
等)。
例如:
ldm/models/autoencoder.py
:处理潜在空间编码解码的逻辑。
ldm/models/diffusion/...
:控制扩散过程的采样、反推和生成过程。
ldm/models/unet.py
:UNet 模型的定义,这里是扩散模型的核心结构。
2. 修改推理和采样逻辑
- 路径:
scripts/txt2img.py
- 如果想修改 Stable Diffusion 如何生成图片(例如更改采样器、分辨率等),应该修改
scripts/txt2img.py
文件。
- 常见修改:
- 替换采样方法(如 PLMS 改为 DDIM)。
- 增加或修改输入参数(如
--prompt
的处理逻辑)。
- 修改输出图片的路径、格式等。
3. 修改配置文件
- 路径:
configs/...
- 配置文件通常包含模型参数、训练超参数等。如果需要更改模型的配置,可以查看
configs
文件夹下的文件。
- 示例修改内容:
- 调整网络层的配置。
- 修改分辨率、潜在空间大小等参数。
- 替换权重路径。
4. 添加或调整功能
- 路径:
main.py
或
scripts/...
- 如果想添加新的功能或命令行接口,可以修改
main.py
或
scripts
文件夹下的文件。
- 例如:
- 增加一个新脚本
txt2img_advanced.py
,实现自定义生成逻辑。
- 在
main.py
中定义额外的入口点。
5. 模型权重加载逻辑
- 路径:
ldm/util.py
或
scripts/txt2img.py
- 如果需要更改权重加载逻辑(例如加载不同的模型权重或新增模型),可以查看
ldm/util.py
中的代码,特别是加载
.ckpt
权重相关的部分。
推荐修改顺序
- 明确你的需求
:确定是要调整模型结构、生成逻辑,还是扩展功能。
- 阅读
scripts/txt2img.py
和
main.py
:理解目前的生成流程,明确需要调整的部分。
- 定位到核心模块
:深入
ldm
文件夹,分析
autoencoder
,
diffusion
和
unet
的实现。
- 测试和验证
:逐步修改代码并验证效果,避免大范围修改后难以排查问题。