ReentrantLock的条件队列是实现“等待通知”机制的关键,之前在《
java线程间通信:等待通知机制
》一文中讲过了使用ReentrantLock实现多生产者、多消费者的案例,这个案例实际上在java源码的注释中已经给了,可以看Condition接口上的注释中相关的代码:
class BoundedBuffer {
final Lock lock = new ReentrantLock();
final Condition notFull = lock.newCondition();
final Condition notEmpty = lock.newCondition();
final Object[] items = new Object[100];
int putptr, takeptr, count;
public void put(Object x) throws InterruptedException {
lock.lock();
try {
while (count == items.length)
notFull.await();
items[putptr] = x;
if (++putptr == items.length) putptr = 0;
++count;
notEmpty.signal();
} finally {
lock.unlock();
}
}
public Object take() throws InterruptedException {
lock.lock();
try {
while (count == 0)
notEmpty.await();
Object x = items[takeptr];
if (++takeptr == items.length) takeptr = 0;
--count;
notFull.signal();
return x;
} finally {
lock.unlock();
}
}
}
在文章《
详解AQS二:ReentrantLock公平锁原理
》中已经详细说了lock和unlock方法的实现原理,实际上就是利用了AQS队列实现阻塞、加锁、解锁。那么当lock、unlock方法中间夹杂着Condition的await、signal方法的调用,又发生了什么事情呢?
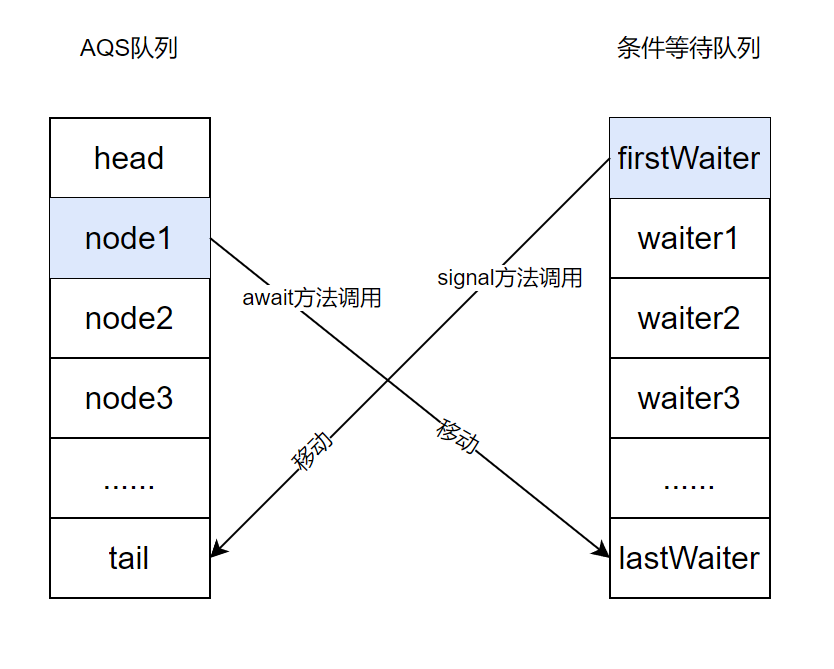
一、条件等待的原理:ConditionObject
一切都要从ConditionObject类说起,它是Condition接口的实现类,lock.newCondition方法调用实际返回的就是ConditionObject类的实例。那么
condition.await
方法调用和
condition.signal
方法调用到底发生了什么呢?这实际上就是AQS队列中的Node元素和条件等待队列中元素的相互移动:
复习一下lock和unlock的句式
private final Lock lock=new ReentrantLock(); // 创建一个Lock接口实例
……
// 申请锁lock,如果发生竞争且竞争锁失败,则当前线程进入AQS队列等待
lock.lock();
try{
// 阻塞被释放后,当前线程执行临界区代码
//await、signal方法调用
……
}finally{
// 在finally块中释放锁,当前线程节点从AQS队列中移除
lock.unlock();
}
await方法、signal方法都必须在临界区代码中执行,await方法调用之后大家都猜到了:当前线程会进入条件等待队列等待。但是明明当前线程还在AQS队列中,还没有调用unlock方法呢,那条件等待队列中和AQS队列中是不是都会有当前线程的等待实例?答案是否定的。实际上调用sinal方法之后当前线程会创建新Node等待在Condition队列尾部,同时释放AQS锁,本身节点将会在AQS队列中被移除。
同样的,当调用signal方法之后,Condition队列中的节点会被移除,同时会创建新节点到AQS队列中等待重新抢占锁。
二、await方法原理
await方法执行时当前线程在AQS队列中必然是头部节点,也就是已经获取锁的节点。await方法执行的原理就是将节点从AQS队列中的头部挪到Condition队列的尾部,之后释放锁并唤醒AQS队列的下一个节点让其抢占锁。
public final void await() throws InterruptedException {
//如果当前线程发生了中断,就抛出中断异常
if (Thread.interrupted())
throw new InterruptedException();
//将当前线程封装Node节点并加到Condition等待队列
Node node = addConditionWaiter();
//释放锁并获取释放锁时查询的锁状态值(重入次数),以便于以后重新进入AQS队列使用
int savedState = fullyRelease(node);
//中断状态暂存标记
int interruptMode = 0;
/*
* 循环查询节点是否在AQS队列中,如果在AQS队列中表示已经重新进入AQS队列了,
* 这意味着有别的线程调用了signal方法唤醒了当前线程
*/
while (!isOnSyncQueue(node)) {
//不在AQS队列中,那就继续挂起等待
LockSupport.park(this);
//检查中断状态,防止由于发生中断导致LockSupport.park(this);失效
if ((interruptMode = checkInterruptWhileWaiting(node)) != 0)
break;
}
//抢锁,如果在抢锁过程中发生了异常,则将中断标记设置为REINTERRUPT
if (acquireQueued(node, savedState) && interruptMode != THROW_IE)
interruptMode = REINTERRUPT;
//如果是因中断导致的LockSupport.park(this);挂起失效,则遍历等待队列中的节点,删除无效节点
if (node.nextWaiter != null) // clean up if cancelled
unlinkCancelledWaiters();
//判定是否应当抛出中断异常还是仅仅恢复中断标记
if (interruptMode != 0)
reportInterruptAfterWait(interruptMode);
}
await方法的代码延续了AQS的代码风格,非常精简,但是信息量很大,每一行代码都值得推敲。总体来说,await方法干了以下的事情:
(1)封装当前线程为新Node节点,并添加到等待队列尾部
(2)AQS队列释放锁,并唤醒AQS同步队列中头部节点的后继节点
(3)执行while循环,将该节点的线程阻塞,直到该节点离开等待队列,进入AQS同步队列;或者检测到了中断异常结束while循环。
(4)退出while循环后,执行acquireQueued方法尝试获取锁。
(5)执行善后工作,遍历等待队列中的节点删除无效节点。
(6)最后根据中断发生的时机,signal方法调用前,就抛出异常;否则就设置下中断标记,是否抛出异常看业务代码处理。
1、加入等待队列:addConditionWaiter
/**
* 添加一个新的等待节点到等待队列
* @return 添加到等待队列中的节点对象
*/
private Node addConditionWaiter() {
Node t = lastWaiter;
// 如果最后一个节点取消等待了,则执行unlinkCancelledWaiters方法遍历等待队列删除无效节点
if (t != null && t.waitStatus != Node.CONDITION) {
unlinkCancelledWaiters();
t = lastWaiter;
}
//封装当前线程为新Node节点,并且状态为CONDITION
Node node = new Node(Thread.currentThread(), Node.CONDITION);
if (t == null)
firstWaiter = node;
else
t.nextWaiter = node;//将新节点放到队尾
lastWaiter = node;
return node;
}
这个方法很简单,就是创建了新节点Node对象,并且置为CONDTION状态表示等待在等待队列中;最后将其放到等待队列的队尾。
等待队列是一个单向队列,节点和节点之间使用nextWaiter指针链接。
值得一提的是,等待队列中节点Node类和AQS同步队列中的Node类是同一个类,之前在分析AQS时没使用到的节点状态Node.CONDITION以及属性nextWaiter在等待队列中全都用到了。
addConditionWaiter方法中比较让人费解的是这段代码:
Node t = lastWaiter;
// 如果最后一个节点取消等待了,则执行unlinkCancelledWaiters方法遍历等待队列删除无效节点
if (t != null && t.waitStatus != Node.CONDITION) {
unlinkCancelledWaiters();
t = lastWaiter;
}
我们知道等待在等待队列中的节点必定是CONDITION状态,若不是这个状态,表示该节点已经取消等待了,那这时候就要将该节点从等待队列中移除。我们会有疑问,为什么该节点取消等待的时候不自己出队?感觉AQS所有的操作都似乎有“Lazy”的特性,包括AQS队列的初始化是在自旋入队的时候、AQS节点的出队在自旋抢占锁的时候。。都不是自己主动操作,而是“事件驱动”模式的。
2、删除无效节点:unlinkCancelledWaiters
节点入等待队列的时候可能会执行unlinkCancelledWaiters方法,该方法的作用是删除等待队列中已经取消等待的节点。
private void unlinkCancelledWaiters() {
Node t = firstWaiter;
Node trail = null;
while (t != null) {
Node next = t.nextWaiter;
if (t.waitStatus != Node.CONDITION) {
t.nextWaiter = null;
if (trail == null){
firstWaiter = next;
}else{
trail.nextWaiter = next;
}
if (next == null){
lastWaiter = trail;
}
}else{
trail = t;
}
t = next;
}
}
这段代码通过trail和t两个指针一前一后遍历整个等待队列,并剔除掉非Node.CONDITION状态的节点。
unlinkCancelledWaiters方法整体来说比较简单,该方法仅仅在当前线程持有锁的时候被调用,用于将取消等待的节点从等待队列中移除。在以下两个场景下该方法会被调用:
- 在条件等待期间线程取消等待
- 最后一个等待节点已经取消等待的前提下,插入新的等待节点(addConditionWaiter方法内的unlinkCancelledWaiters方法调用就是因为此)
该方法需要避免在signal方法没有被调用的情况下产生无法被回收的垃圾节点,全遍历等待队列中的所有节点也是无奈之举,好在该方法被调用有前提:sinal方法没有被调用,而且等待节点因为一些原因取消了等待。
该方法遍历了等待队列中的所有节点,这样做有个好处:如果有大量的等待节点取消了等待,可能会导致“取消风暴”,这样一次遍历就取消所有指向垃圾节点的指针,可以避免多次重新遍历以提高运行效率。
3、释放锁:fullRelease
节点加入等待队列以后会释放锁,并唤醒后继节点
final int fullyRelease(Node node) {
boolean failed = true;
try {
//获取锁状态,实际上就是当前线程的锁重入次数,以方便后续恢复
int savedState = getState();
//释放锁
if (release(savedState)) {
failed = false;
return savedState;
} else {
throw new IllegalMonitorStateException();
}
} finally {
if (failed)
node.waitStatus = Node.CANCELLED;
}
}
ReentrantLock公平锁和非公平锁锁释放都调用的同一个方法:release方法,fullRelease方法一直没有被提及,因为它是为等待队列准备的方法。fullRelease方法内部会调用release方法。
fullRelease方法和release方法最大的区别就是release方法只会返回true/false表示释放锁成功了还是失败了,fullRelease方法则会先保存锁的状态,释放完锁以后会将该state返回给调用方await方法,用于以后恢复线程在AQS同步队列中的状态。
4、是否在AQS队列:isOnSyncQueue
释放完成锁以后会执行while循环,不断执行isOnSyncQueue方法以判断节点是否在同步队列中,如果节点出现在了AQS同步队列中,说明节点已经被唤醒了,它可以重新尝试获取锁了。
final boolean isOnSyncQueue(Node node) {
/**
* 节点状态为CONDITION表示节点肯定在等待队列
* AQS同步队列是双向队列,等待在AQS同步队列中的所有节点prev都有值,
* 为null表示不在AQS同步队列中等待;反过来node.prev不为空并不表示node节点
* 一定在AQS同步队列。
*/
if (node.waitStatus == Node.CONDITION || node.prev == null)
return false;
/**
* 等待队列中的节点通过nextWaiter指针相互链接,next指针用于AQS队列
* next指针不为空表示节点必定在AQS同步队列;反过来,node.next为空说明不了
* node节点不在AQS队列
*/
if (node.next != null)
return true;
//从尾部到头部遍历节点
return findNodeFromTail(node);
}
/**
* 从尾部到头部遍历AQS同步队列查找指定节点
*/
private boolean findNodeFromTail(Node node) {
Node t = tail;
for (;;) {
if (t == node)
return true;
if (t == null)
return false;
t = t.prev;
}
}
得解释一下:
node.prev不为空说明不了node节点在AQS同步队列:
可以看下AQS的enq自旋入队方法

可以看到,在CAS操作入队之前,node.prev就已经设置了值了,而CAS可能会失败,所以就算node.prev有值,node节点也可能没有在队列中。
node.next为空说明不了node节点不在AQS同步队列:
这个很好理解,AQS同步队列tail节点的next指针是null。
最后一个问题是:为什么要从尾部到头部遍历AQS同步队列查找指定节点,而不是从头部到尾部查找?
一个重要的原因是当前节点刚加入AQS队列尾部的话,从尾部查找可能不会经历很多遍历就能查找到该节点,从尾部开始查找可以提高效率。
三、await方法中的中断
上一章节讲到了isOnSyncQueue方法,该方法判定当前节点是否在AQS同步队列中,如果在同步队列中,则结束while循环,开始执行acquireQueue方法抢占锁;否则执行LockSupport.park方法将线程阻塞。看似逻辑很简单,但是涉及到了中断相关的逻辑,比较复杂,需要单独拎出来掰扯掰扯。
public final void await() throws InterruptedException {
....省略之前的代码....
while (!isOnSyncQueue(node)) {
//不在AQS队列中,那就继续挂起等待
LockSupport.park(this);//①
//检查中断状态,防止由于发生中断导致LockSupport.park(this);失效
if ((interruptMode = checkInterruptWhileWaiting(node)) != 0)//②
break;
}
//抢锁,如果在抢锁过程中发生了异常,则将中断标记设置为REINTERRUPT
if (acquireQueued(node, savedState) && interruptMode != THROW_IE)
interruptMode = REINTERRUPT;
//如果是因中断导致的LockSupport.park(this);挂起失效,则遍历等待队列中的节点,删除无效节点
if (node.nextWaiter != null) // clean up if cancelled
unlinkCancelledWaiters();
//判定是否应当抛出中断异常还是仅仅恢复中断标记
if (interruptMode != 0)
reportInterruptAfterWait(interruptMode);
}
1、LockSupport.park放行的原因
在①处执行了LockSupport.park代码,线程被阻塞挂起,那什么时候线程会被释放继续运行临界区代码呢?
有三个可能的原因:
signal方法被调用后,线程节点自旋进入AQS同步队列,正常等待机会获取锁之后被前驱节点线程调用LockSupport.unpark方法唤醒
有别的线程调用了signal方法,signal方法中可能会调用LockSupport.unpark方法直接唤醒线程
线程发生了中断,LockSupport.lock方法阻塞失效了。
可能很多人都会想到signal方法会唤醒线程,但是想不到可能发生的中断会让LockSupport.lock方法失效仍然会释放线程让代码继续运行。这也是为什么接下来的代码要紧接着检查线程中断。
2、检查中断:checkInterruptWhileWaiting
确切的说是检查是否发生了中断,以及如果发生了中断,是在signal方法执行前发生了中断,还是signal方法执行后发生了中断。
/**
* 返回值有三种:
* 0:没有发生中断
* -1(THROW_IE):发生了中断,而且中断是在signal方法调用前发生的
* 1(REINTERRUPT):发生了中断,而且中断是在signal方法调用后发生的
*/
private int checkInterruptWhileWaiting(Node node) {
return Thread.interrupted() ?
(transferAfterCancelledWait(node) ? THROW_IE : REINTERRUPT) :
0;
}
/**
* 如果需要,在取消等待后将节点转移到AQS同步队列。
* 如果节点是在被唤醒前取消等待的,则返回true,否则返回false。
* 只有发生了中断才会调用该方法。
*/
final boolean transferAfterCancelledWait(Node node) {
/*
* 这里的CAS操作如果成功,说明当前节点的状态是Node.CONDITION
* 也就是说,当前节点必定是在等待队列,更进一步,说明了当前中断
* 是在被唤醒之前发生的,因为如果调用了signal方法,当前节点必然
* 已经在AQS同步队列中,已经是状态0了。
*/
if (compareAndSetWaitStatus(node, Node.CONDITION, 0)) {
//自旋入队
enq(node);
return true;
}
/*
* 代码执行到这里,并不能说明signal方法已经执行完毕,有可能signal方法
* 正在执行中,Node状态已经更改成了0,但是enq方法还没执行完成,节点还在
* 疯狂自旋入队。所以这里要判断是否完成了enq方法,就要判定下当前节点是否
* 已经在AQS同步队列中。如果enq方法还没执行完,就让出CPU时间片,稍稍等待
* 下,通常enq方法会很快完成,所以不用担心这里会浪费CPU资源。
*/
while (!isOnSyncQueue(node))
Thread.yield();
//singal方法执行后发生的中断,返回false
return false;
}
checkInterruptWhileWaiting方法有三个返回值:0、1(REINTERRUPT)、-1(THROW_IE)。在这里,要特别注意
Thread.interrupted()
方法的调用,该方法在上一章节《
详解AQS二:ReentrantLock公平锁原理
》就说过了,它有个很重要的特点是会重置中断状态为false,并且返回中断状态。checkInterruptWhileWaiting的返回值1和-1都代表发生过中断。不管是1还是-1,都会停止while循环,中断值则会暂存在
interruptMode
变量中。
while (!isOnSyncQueue(node)) {
//不在AQS队列中,那就继续挂起等待
LockSupport.park(this);//①
//检查中断状态,防止由于发生中断导致LockSupport.park(this);失效
if ((interruptMode = checkInterruptWhileWaiting(node)) != 0)//②
break;
}
3、抢锁以及重设中断状态
中断循环以后,当前线程就开始抢锁,抢锁方法是acquireQueued方法,该方法已经在文章《
详解AQS二:ReentrantLock公平锁原理
》中讲过,不再赘述。
acquireQueued方法返回值是true/false,true表示发生了中断,false表示未发生中断,这个中断是在抢锁过程中发生的;在抢锁之前,while循环中调用了checkInterruptWhileWaiting方法,该方法调用了
Thread.interrupted()
方法重置了中断状态,正是为了不影响acquireQueued方法的调用。
我们分析下抢锁代码
//抢锁,如果在抢锁过程中发生了异常,则将中断标记设置为REINTERRUPT
if (acquireQueued(node, savedState) && interruptMode != THROW_IE)
interruptMode = REINTERRUPT;
这段代码执行了如下代码流程:
- 执行acquireQueued方法抢锁,抢锁成功后返回中断标记
- 如果执行acquireQueued方法抢锁的过程中发生了中断,则判断之前在等待队列中是否发生了中断以及中断类型是否是THROW_IE
- 如果当前节点在等待队列中等待的时候发生了中断并且中断类型是THROW_IE,则将中断标记interruptMode修改为REINTERRUPT。
现在我们聚焦于
interruptMode != THROW_IE
这个判断条件,如果interruptMode不是THROW_IE,它会是什么值?只有可能是剩下的两种值:
在以上两种情况下,interruptMode会被修改成REINTERRUPT值(实际上第二种情况interruptMode的值已经是REINTERRUPT,重复修改也无妨)
这样,最终interruptMode一共只有可能有三种类型的值:
- 0:在等待队列中未发生中断,在执行acquireQueued方法抢锁的过程中也没发生中断
- 1(REINTERRUPT):有可能在等待队列中未发生中断,但是在执行acquireQueued方法抢锁的过程中发生了中断;也有可能在等待队列中发生了中断,而且中断是在signal方法调用后发生的,同时在执行acquireQueued方法抢锁的过程中也发生了中断
- -1(THROW_IE):在等待队列中发生了中断,而且中断是在signal方法调用前发生的;是否在执行acquireQueued方法抢锁的过程中发生了中断无法得知。
针对这三种类型的值,接下来会如何处理呢?
4、中断的处理方式
await方法最后一段代码:
//判定是否应当抛出中断异常还是仅仅恢复中断标记
if (interruptMode != 0)
reportInterruptAfterWait(interruptMode);
这里首先判断了interruptMode是否是0,只有非0的值才会被处理,也就是说,只有异常类型才会被处理。
private void reportInterruptAfterWait(int interruptMode)
throws InterruptedException {
if (interruptMode == THROW_IE)
throw new InterruptedException();
else if (interruptMode == REINTERRUPT)
selfInterrupt();
}
终于看到了对THROW_IE和REINTERRUPT类型的处理:
THROW_IE
:抛出InterruptedException异常
REINTERRUPT
:设置中断标记,这样如果在接下来的业务处理中出现了sleep等等待方法,将会抛出InterruptedException异常。
使用表格总结一下异常处理的各种情况

可以看到,是否要抛出异常还是设置中断标记,主要取决于节点在等待队列中发生中断的时机:
等待队列中在signal方法调用
前
发生的中断:
一定会抛出中断异常
,不管acquireQueued方法有没有发生中断
等待队列中在signal方法调用
后
发生的中断:
一定会设置中断标记位
,不管acquireQueued方法有没有发生中断
等待队列中没有发生中断:
如果抢锁过程中发生了中断,就设置中断标记位;如果抢锁过程中没有发生中断,就什么都不做。
思考一下,为什么要这么做呢?
acquireQueued是一个“uninterruptible”的类,也就是说,它不会抛出中断异常,但是它会将中断反馈给调用方,让调用方决定该如何处理异常,那await就作为调用方,结合了在等待队列中是否发生异常做出了综合决定:一切看是否在等待队列中发生的异常种类,如果没有发生异常,就向AQS同步队列处理异常类型一样,让业务自己决定是否抛出异常;如果在等待队列中发生了异常:
- 在signal方法调用前发生异常,说明临界区代码没打算执行,直接抛出中断异常中断临界区代码执行即可
- 在signal方法调用后发生异常,说明临界区代码本打算执行,临界区代码自己都没强制停止执行,是否要抛出中断异常停止临界区代码执行让业务代码自己判断去吧。
5、删除无效节点:unlinkCancelledWaiters
await方法最后会判定node.nextWaiter是否为null,如果是null则遍历等待队列中的节点,删除无效节点
//如果是因中断导致的LockSupport.park(this);挂起失效,则遍历等待队列中的节点,删除无效节点
if (node.nextWaiter != null) // clean up if cancelled
unlinkCancelledWaiters();
为什么会判断node.nextWaiter是否为null?想要知道这个答案,得看看signal方法的实现逻辑。
四、signal方法原理
signal方法就是把线程节点从等待队列转移到AQS同步队列,之后就是AQS正常获取锁并被前置节点线程唤醒后继续执行同步代码块中await方法之后的的临界区代码的过程。
public final void signal() {
//如果当前锁的持有线程不是当前线程,就抛出异常
if (!isHeldExclusively())
throw new IllegalMonitorStateException();
//firstWaiter是等待时间最久的线程,从它开始唤醒最公平
Node first = firstWaiter;
if (first != null)
doSignal(first);
}
1、判定锁的持有线程:isHeldExclusively
这个方法是个AQS的钩子方法,实现在ReentrantLock类中的Sync抽象类
protected final boolean isHeldExclusively() {
return getExclusiveOwnerThread() == Thread.currentThread();
}
这个方法特别简单,就是简单判定了下当前线程是否是持有锁的线程,什么情况下会发生不是持有锁的线程呢?明明当前线程正在运行中,它肯定是持有锁的线程啊,举个简单的例子如下所示:
/**
* @author kdyzm
* @date 2024/12/27
*/
public class AQSNotHolderThread {
public static void main(String[] args) {
Lock lock1 = new ReentrantLock();
Lock lock2 = new ReentrantLock();
Condition con1 = lock1.newCondition();
Thread thread = new Thread(() -> {
lock1.lock();
try {
con1.await();
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock1.unlock();
}
});
thread.start();
lock2.lock();
try {
//在lock2的临界区代码使用lock1的con1,会抛出IllegalMonitorStateException异常
con1.signal();
} finally {
lock2.unlock();
}
}
}
以上代码会抛出
IllegalMonitorStateException
异常。
isHeldExclusively方法调用的目的就是要保证Condition方法的调用必须在对应的锁下的同步代码块中。
2、doSignal方法
doSignal方法会从头部开始查找第一个没有被取消的节点,将其转移到AQS同步队列或者直接唤醒线程。
private void doSignal(Node first) {
do {
if ( (firstWaiter = first.nextWaiter) == null)
lastWaiter = null;
//不管后续有没有transferForSignal成功,都将nextWaiter指针置为null
first.nextWaiter = null;
} while (!transferForSignal(first) &&
(first = firstWaiter) != null);
}
在上面的代码中,
first.nextWaiter = null;
这块代码是亮点,虽然不经意的一行代码,却是解释第三章第五节:删除无效节点:unlinkCancelledWaiters 的关键,之前留下了一个疑问,在await方法的最后:
//如果是因中断导致的LockSupport.park(this);挂起失效,则遍历等待队列中的节点,删除无效节点
if (node.nextWaiter != null) // clean up if cancelled
unlinkCancelledWaiters();
会判定node.nextWaiter是否为null,如果不是null,就执行unlinkCancelledWaiters方法清除无效节点。
从doSignal方法中可以看到,只要调用了调用了doSignal方法,节点的nextWaiter就会被置为null;那await方法中在LockSupport.park方法调用之后发现了node.nextWaiter竟然不为空,那就表示signal方法没有被调用,换句话说,是因为中断才使得LockSupport.park失效最终导致代码运行到这里的,在signal方法调用前发生了中断,那节点是取消等待状态,需要将节点从等待队列中移除出去,执行
unlinkCancelledWaiters()
方法就合理了。
3、转移节点到AQS:transferForSignal
该方法的主要目的是将线程节点从条件等待队列转移到AQS同步队列。
final boolean transferForSignal(Node node) {
/*
* 如果节点已经取消等待,则不再尝试转移节点到AQS同步队列
*/
if (!compareAndSetWaitStatus(node, Node.CONDITION, 0))
return false;
/*
* 节点自旋转进入AQS同步队列,并返回前置节点
*/
Node p = enq(node);
int ws = p.waitStatus;
/**
* ws>0:前置节点状态是取消状态
* !compareAndSetWaitStatus(p, ws, Node.SIGNAL):设置前驱节点为Signal状态失败
*/
if (ws > 0 || !compareAndSetWaitStatus(p, ws, Node.SIGNAL))
LockSupport.unpark(node.thread);//唤醒节点线程
return true;
}
我们分析一下这段代码:
本来目标节点在await方法中已经是被LockSupport.park方法将线程阻塞了,enq方法完成之后,实际上该节点已经完成了入队,应该是是等待前驱节点唤醒它的状态,似乎等价于AQS的acquire方法
public final void acquire(int arg) {
if (!tryAcquire(arg) &&
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}
中的
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
方法调用,然而真的等价吗?实际上不一定等价,其区别就是前驱节点的状态,由于目标节点是“
先阻塞,后入队
”,和正常进入AQS队列等待的线程“
先入队,后阻塞
”的流程是反着来的,所以它没有调用过
shouldParkAfterFailedAcquire
方法校正前驱节点状态:
private static boolean shouldParkAfterFailedAcquire(Node pred, Node node) {
int ws = pred.waitStatus;
if (ws == Node.SIGNAL)
return true;
if (ws > 0) {
do {
node.prev = pred = pred.prev;
} while (pred.waitStatus > 0);
pred.next = node;
} else {
compareAndSetWaitStatus(pred, ws, Node.SIGNAL);
}
return false;
}
shouldParkAfterFailedAcquire方法执行完成后会将取消状态的节点剔除,并且将前置节点状态修正为SIGNAL。
在transferForSignal方法中的代码
if (ws > 0 || !compareAndSetWaitStatus(p, ws, Node.SIGNAL))
LockSupport.unpark(node.thread);//唤醒节点线程
实际上就是在快速验证前置节点状态,如果前置节点状态错误且无法修正,则将目标线程直接唤醒让其继续执行await方法中LockSupport.park方法之后的代码逻辑:
while (!isOnSyncQueue(node)) {
//不在AQS队列中,那就继续挂起等待
LockSupport.park(this);//①
//检查中断状态,防止由于发生中断导致LockSupport.park(this);失效
if ((interruptMode = checkInterruptWhileWaiting(node)) != 0)//②
break;
}
//抢锁,如果在抢锁过程中发生了异常,则将中断标记设置为REINTERRUPT
if (acquireQueued(node, savedState) && interruptMode != THROW_IE)
interruptMode = REINTERRUPT;
由于在signal方法中已经入队,所以这里会结束while循环,执行下一个if语句中的
acquireQueued(node, savedState)
,这个方法中如果获取锁失败,它会调用
shouldParkAfterFailedAcquire
方法:
/**
* 已经在队列中的线程通过独占模式获取锁的方法,该方法不受中断的影响。
* 该方法也同样用于等待在条件等待队列中的线程获取锁。
*/
final boolean acquireQueued(final Node node, int arg) {
boolean failed = true;
try {
boolean interrupted = false;
for (;;) {
final Node p = node.predecessor();
//如果前置节点是头部节点,当前节点就尝试抢占锁
if (p == head && tryAcquire(arg)) {
//抢锁成功后将抢锁节点设置为头结点
setHead(node);
//释放头结点利于GC
p.next = null;
failed = false;
return interrupted;
}
//如果应该阻塞等待就挂起线程进入阻塞状态
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
interrupted = true;
}
} finally {
if (failed)
cancelAcquire(node);
}
}
调用
shouldParkAfterFailedAcquire
方法就会重新校正前置节点状态为SIGNAL并且剔除掉前置节点中的取消状态的节点。
这样await方法将会在acquireQueued方法调用处阻塞,等待获取锁之后执行后续的临界区代码。
这样就完美闭环了。
最后,欢迎关注我的博客呀:
https://blog.kdyzm.cn
END.















