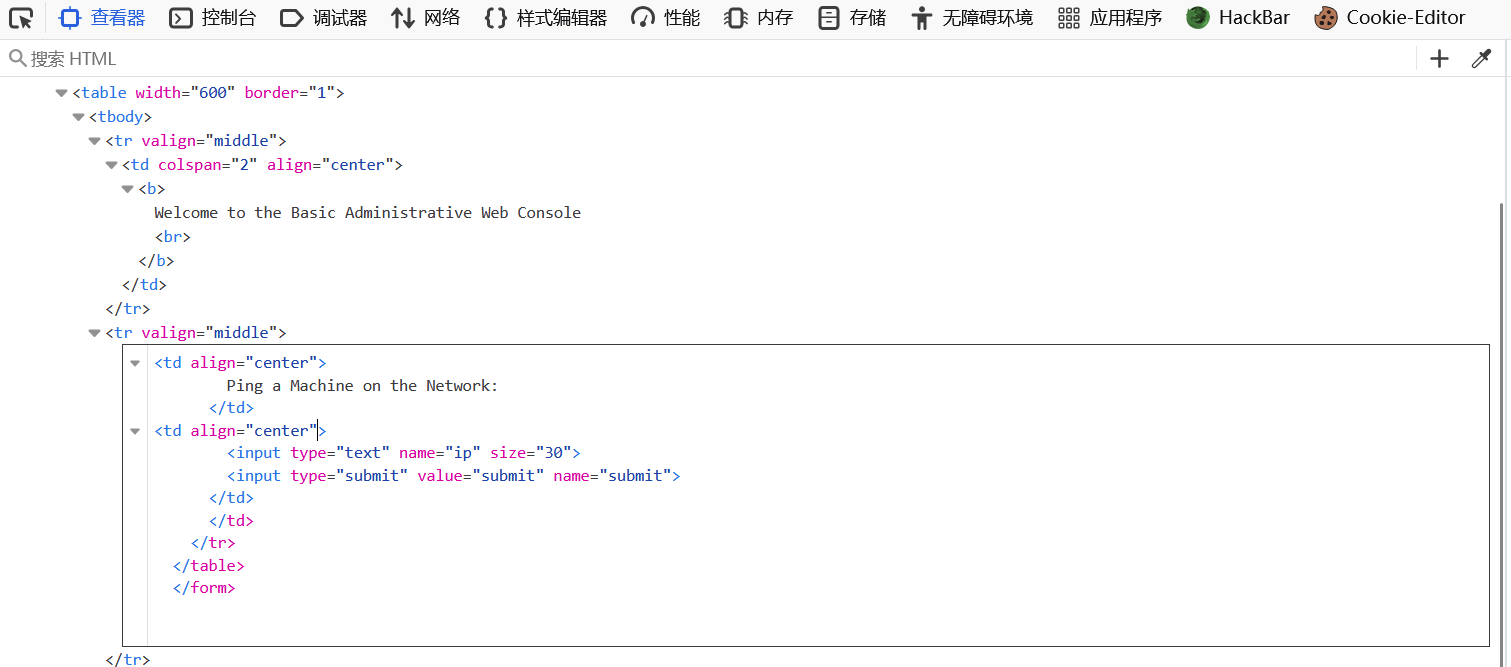
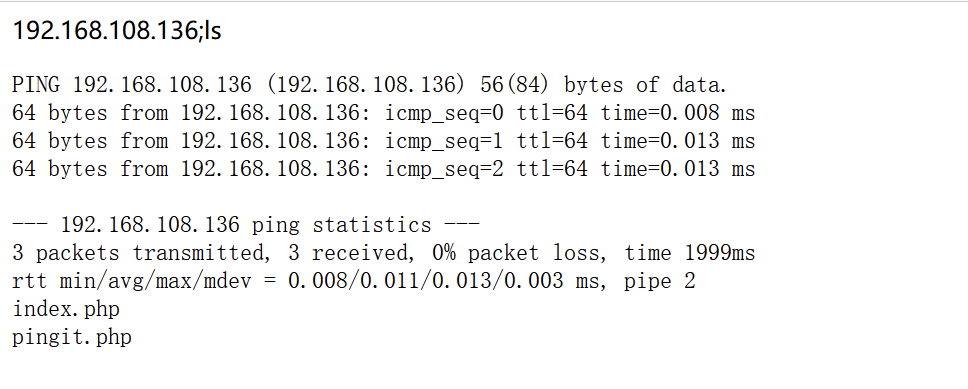
深入理解 Servlet:从基础概念到高级特性与实战应用
一、Servlet简介与工作原理
Servlet是Java Web开发中的重要组件,它运行在服务器端,用于处理客户端的请求并返回响应。其工作原理涉及多个组件和步骤,从客户端发起请求到服务器端的处理和响应,整个过程有条不紊地进行。
(一)Servlet容器与Tomcat
Servlet容器是Servlet运行的环境,负责管理Servlet的生命周期、资源分配和请求处理等工作。Tomcat是常用的Servlet容器之一,它具有强大的功能和良好的性能。在Tomcat中,Context容器直接管理Servlet的包装类Wrapper,一个Context对应一个Web工程。例如,在Tomcat的配置文件中,可以通过
<Context>
标签来配置Web应用的相关参数,如路径、文档库等。
(二)Servlet的生命周期
- 加载和实例化
- Servlet容器在启动时或首次检测到需要Servlet响应请求时,会加载Servlet类。它通过类加载器从本地文件系统、远程文件系统或网络服务中获取Servlet类。例如,在一个Web应用启动时,Tomcat会根据web.xml中的配置找到对应的Servlet类并加载它。
- 容器使用Java反射API创建Servlet实例,调用默认构造方法(无参构造方法),因此编写Servlet类时不应提供带参数的构造方法。
- 初始化
- 实例化后,容器调用Servlet的init()方法进行初始化。在这个方法中,Servlet可以进行一些准备工作,如建立数据库连接、获取配置信息等。例如,以下是一个简单的init()方法实现:
public void init(ServletConfig config) throws ServletException {
super.init(config);
// 在这里进行初始化操作,如获取初始化参数
String paramValue = config.getInitParameter("paramName");
// 其他初始化逻辑
}
- 每个Servlet实例的init()方法只被调用一次,初始化期间可以使用ServletConfig对象获取web.xml中配置的初始化参数。如果发生错误,可抛出ServletException或UnavailableException异常通知容器。
- 请求处理
- 容器调用Servlet的service()方法处理请求。在service()方法中,Servlet通过ServletRequest对象获取客户端信息和请求信息,处理后通过ServletResponse对象设置响应信息。例如,在一个处理登录请求的Servlet中:
protected void service(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
// 获取用户名和密码
String username = request.getParameter("username");
String password = request.getParameter("password");
// 进行登录验证等业务逻辑处理
if (isValidUser(username, password)) {
response.getWriter().println("登录成功");
} else {
response.getWriter().println("登录失败");
}
}
- 如果service()方法执行期间发生错误,可抛出ServletException或UnavailableException异常。若UnavailableException指示实例永久不可用,容器将调用destroy()方法释放实例。
- 服务终止
- 当容器检测到Servlet实例应被移除时,调用destroy()方法释放资源,如关闭数据库连接、保存数据等。例如:
public void destroy() {
// 释放资源的逻辑,如关闭数据库连接
if (connection!= null) {
try {
connection.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
super.destroy();
}
- destroy()方法调用后,容器释放Servlet实例,由Java垃圾收集器回收。若再次需要该Servlet处理请求,容器会创建新的实例。
(三)Servlet的体系结构
Servlet规范基于几个关键类运转,其中ServletConfig、ServletRequest和ServletResponse与Servlet主动关联。ServletConfig在初始化时传递给Servlet,用于获取Servlet的配置属性;ServletRequest和ServletResponse在请求处理时传递给Servlet,分别用于获取请求信息和设置响应信息。
在Tomcat容器中,存在门面设计模式的应用。例如,StandardWrapper和StandardWrapperFacade实现了ServletConfig接口,传给Servlet的是StandardWrapperFacade对象,它能保证Servlet获取到所需数据而不暴露无关数据。同样,ServletContext也有类似结构,Servlet中获取的实际对象是ApplicationContextFacade,用于获取应用的相关信息。
二、Servlet的基本使用与配置
(一)创建Servlet类
创建Servlet类需要继承HttpServlet类并重写相应方法。例如,创建一个简单的HelloWorldServlet:
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
import java.io.PrintWriter;
public class HelloWorldServlet extends HttpServlet {
@Override
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
// 设置响应内容类型为HTML
response.setContentType("text/html");
// 获取输出流对象
PrintWriter out = response.getWriter();
// 输出HTML内容
out.println("<html><body>");
out.println("<h1>Hello, World!</h1>");
out.println("</body></html>");
}
}
(二)在web.xml中配置Servlet
在web.xml文件中,需要配置Servlet的相关信息,包括名称、类名、初始化参数和映射路径等。以下是上述HelloWorldServlet的配置示例:
<servlet>
<servlet-name>HelloWorldServlet</servlet-name>
<servlet-class>com.example.HelloWorldServlet</servlet-class>
<init-param>
<param-name>greeting</param-name>
<param-value>Hello!</param-value>
</init-param>
</servlet>
<servlet-mapping>
<servlet-name>HelloWorldServlet</servlet-name>
<url-pattern>/hello</url-pattern>
</servlet-mapping>
(三)Servlet与JSP的关系
JSP本质上是Servlet的扩展,JSP页面在第一次被访问时会被翻译成Servlet并执行。在Tomcat中,通过JspServlet来处理JSP页面的翻译工作,其在conf/web.xml中有相应的配置,会拦截所有以.jsp或.jspx为后缀的请求并进行翻译。例如,一个简单的JSP页面:
<%@ page language="java" contentType="text/html; charset=UTF-8" pageEncoding="UTF-8"%>
<!DOCTYPE html>
<html>
<head>
<title>JSP Example</title>
</head>
<body>
<%
// 这里可以嵌入Java代码
String message = "This is a JSP page.";
%>
<h1><%=message%></h1>
</body>
</html>
当访问该JSP页面时,Tomcat会将其翻译成对应的Servlet类并执行,最终将生成的HTML内容返回给客户端。
三、Servlet 3.0新特性详解
(一)异步处理支持
- 解决的问题
- 在Servlet 3.0之前,Servlet线程在处理业务时一直处于阻塞状态,直到业务处理完毕才能输出响应并结束线程。这在业务处理耗时较长(如数据库操作、跨网络调用等)的情况下,会导致服务器资源占用过多,影响并发处理速度。
- 异步处理流程
- Servlet接收到请求后,可先进行预处理,然后将请求转交给异步线程处理,自身返回容器。异步线程处理完业务后,可直接生成响应数据或转发请求给其他Servlet。例如:
@WebServlet(urlPatterns = "/asyncDemo", asyncSupported = true)
public class AsyncDemoServlet extends HttpServlet {
@Override
public void doGet(HttpServletRequest req, HttpServletResponse resp) throws IOException, ServletException {
resp.setContentType("text/html;charset=UTF-8");
PrintWriter out = resp.getWriter();
out.println("进入Servlet的时间:" + new Date() + ".");
out.flush();
// 启动异步处理
AsyncContext ctx = req.startAsync();
// 执行异步业务逻辑
new Thread(new AsyncTask(ctx)).start();
out.println("结束Servlet的时间:" + new Date() + ".");
out.flush();
}
}
class AsyncTask implements Runnable {
private AsyncContext ctx;
public AsyncTask(AsyncContext ctx) {
this.ctx = ctx;
}
@Override
public void run() {
try {
// 模拟耗时业务操作,这里等待5秒
Thread.sleep(5000);
PrintWriter out = ctx.getResponse().getWriter();
out.println("业务处理完毕的时间:" + new Date() + ".");
out.flush();
ctx.complete();
} catch (Exception e) {
e.printStackTrace();
}
}
}
- 配置方式
- 使用传统web.xml配置时,在
<servlet>
标签中添加
<async-supported>true</async-supported>
子标签。使用注解配置时,在
@WebServlet
或
@WebFilter
注解中设置
asyncSupported = true
。
- 使用传统web.xml配置时,在
(二)新增的注解支持
- 简化配置
- Servlet 3.0新增了多个注解,用于简化Servlet、过滤器和监听器的声明,使web.xml部署描述文件不再是必选的。
- 常用注解介绍
- @WebServlet
:用于将类声明为Servlet,可配置名称、URL匹配模式、加载顺序、初始化参数、异步支持等属性。例如:
- @WebServlet
@WebServlet(urlPatterns = {"/demoServlet"}, asyncSupported = true, loadOnStartup = 1, name = "DemoServlet", displayName = "DS", initParams = {@WebInitParam(name = "param1", value = "value1")})
public class DemoServlet extends HttpServlet {...}
- @WebFilter
:用于声明过滤器,可配置过滤器名称、URL匹配模式、应用的Servlet、转发模式、初始化参数、异步支持等属性。例如:
@WebFilter(servletNames = {"DemoServlet"}, filterName = "DemoFilter")
public class DemoFilter implements Filter {...}
- @WebListener
:用于将类声明为监听器,被标注的类需实现至少一个相关接口,如ServletContextListener等。例如:
@WebListener("This is a demo listener")
public class SimpleListener implements ServletContextListener {...}
- @MultipartConfig
:辅助HttpServletRequest对上传文件的支持,标注在Servlet上,表示希望处理的请求的MIME类型是
multipart/form-data
,并可配置文件大小阈值、存放地址、允许上传的最大值等属性。例如:
@MultipartConfig(fileSizeThreshold = 1024 * 1024, location = "/tmp/uploads", maxFileSize = 1024 * 1024 * 5, maxRequestSize = 1024 * 1024 * 10)
@WebServlet("/uploadServlet")
public class UploadServlet extends HttpServlet {...}
(三)可插性支持
- 功能扩充方式
- 可插性支持允许在不修改已有Web应用的前提下,通过将按照一定格式打成的JAR包放到WEB-INF/lib目录下,实现新功能的扩充。
- web-fragment.xml文件
- Servlet 3.0引入了web-fragment.xml部署描述文件,存放在JAR文件的META-INF目录下,可包含web.xml中能定义的内容。例如:
<?xml version="1.0" encoding="UTF-8"?>
<web-fragment xmlns="http://java.sun.com/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" version="3.0"
xsi:schemaLocation="http://java.sun.com/xml/ns/javaee http://java.sun.com/xml/ns/javaee/web-fragment_3.0.xsd"
metadata-complete="true">
<servlet>
<servlet-name>FragmentServlet</servlet-name>
<servlet-class>com.example.FragmentServlet</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>FragmentServlet</servlet-name>
<url-pattern>/fragment</url-pattern>
</servlet-mapping>
</web-fragment>
- 加载顺序规则
- web-fragment.xml包含
<name>
和
<ordering>
两个可选顶层标签,用于指定加载顺序。
<name>
标识文件,
<ordering>
通过
<after>
和
<before>
子标签指定与其他文件的相对位置关系,还可使用
<others/>
表示除自身外的其他文件,其优先级低于明确指定的相对位置关系。
- web-fragment.xml包含
(四)ServletContext的性能增强
- 动态部署与配置
- ServletContext对象在Servlet 3.0中支持在运行时动态部署Servlet、过滤器、监听器,以及为Servlet和过滤器增加URL映射等。例如,动态添加Servlet:
ServletContext context = getServletContext();
ServletRegistration.Dynamic dynamicServlet = context.addServlet("DynamicServlet", DynamicServlet.class);
dynamicServlet.addMapping("/dynamic");
dynamicServlet.setLoadOnStartup(2);
- 与相关接口和类的配合
- 这些动态配置方法通常在ServletContextListener的
contextInitialized
方法或ServletContainerInitializer的
onStartup()
方法中调用。ServletContainerInitializer是Servlet 3.0新增接口,容器启动时使用JAR服务API发现其实现类,并将WEB-INF/lib目录下JAR包中的类交给
onStartup()
方法处理,通常需使用
@HandlesTypes
注解指定处理的类。
- 这些动态配置方法通常在ServletContextListener的
(五)HttpServletRequest对文件上传的支持
- 简化文件上传操作
- Servlet 3.0之前,处理上传文件需使用第三方框架,而现在HttpServletRequest提供了
getPart()
和
getParts()
方法用于从请求中解析上传文件,每个文件用
javax.servlet.http.Part
对象表示,该接口提供了处理文件的简易方法,如
write()
、
delete()
等。例如:
- Servlet 3.0之前,处理上传文件需使用第三方框架,而现在HttpServletRequest提供了
@WebServlet("/upload")
@MultipartConfig
public class FileUploadServlet extends HttpServlet {
@Override
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
Part filePart = request.getPart("file");
if (filePart!= null) {
filePart.write("/tmp/uploadedFile.txt");
response.getWriter().println("文件上传成功");
} else {
response.getWriter().println("没有选择文件上传");
}
}
}
- 配置与注意事项
- 需配合
@MultipartConfig
注解对上传操作进行自定义配置,如限制文件大小和保存路径等。注意,如果请求的MIME类型不是
multipart/form-data
,使用上述方法会抛出异常。
- 需配合
四、Servlet在实际应用中的场景与案例分析
(一)在Web应用中的常见应用场景
- 处理用户请求与业务逻辑
- Servlet可接收用户在浏览器中输入的URL请求,根据请求参数进行业务逻辑处理,如登录验证、数据查询与更新等。例如,在一个电商网站中,用户登录时,LoginServlet接收用户名和密码,与数据库中的用户信息进行比对,验证用户身份。
- 生成动态页面内容
- 通过获取数据库数据或其他业务逻辑处理结果,Servlet可以动态生成HTML、XML等格式的页面内容返回给客户端。比如,一个新闻网站的NewsServlet根据用户请求的新闻类别,从数据库中查询相关新闻数据,然后生成包含新闻列表的HTML页面返回给用户。
(二)案例分析:使用Servlet实现简单的用户登录系统
- 功能需求
- 用户在登录页面输入用户名和密码,点击登录按钮后,请求发送到服务器端的LoginServlet。LoginServlet验证用户名和密码是否正确,如果正确,跳转到欢迎页面;如果错误,返回错误提示信息到登录页面。
- 代码实现
- 登录页面(login.jsp)
:
- 登录页面(login.jsp)
<%@ page language="java" contentType="text/html; charset=UTF-8" pageEncoding="UTF-8"%>
<!DOCTYPE html>
<html>
<head>
<title>Login Page</title>
</head>
<body>
<h1>Login</h1>
<form action="login" method="post">
<label for="username">Username:</label><input type="text" id="username" name="username"><br>
<label for="password">Password:</label><input type="password" id="password" name="password"><br>
<input type="submit" value="Login">
</form>
</body>
</html>
- LoginServlet.java
:
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
import java.io.PrintWriter;
public class LoginServlet extends HttpServlet {
@Override
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
// 设置响应内容类型为HTML
response.setContentType("text/html");
// 获取输出流对象
PrintWriter out = response.getWriter();
// 获取用户名和密码
String username = request.getParameter("username");
String password = request.getParameter("password");
// 假设这里进行简单的用户名和密码验证,实际应用中应与数据库比对
if ("admin".equals(username) && "123456".equals(password)) {
// 登录成功,跳转到欢迎页面
response.sendRedirect("welcome.jsp");
} else {
// 登录失败,返回错误提示
out.println("<html><body>");
out.println("<h1>Login Failed</h1>");
out.println("<p>Invalid username or password.</p>");
out.println("</body></html>");
}
}
}
- web.xml配置
:
<servlet>
<servlet-name>LoginServlet</servlet-name>
<servlet-class>com.example.LoginServlet</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>LoginServlet</servlet-name>
<url-pattern>/login</url-pattern>
</servlet-mapping>
- 欢迎页面(welcome.jsp)
:
<%@ page language="java" contentType="text/html; charset=UTF-8" pageEncoding="UTF-8"%>
<!DOCTYPE html>
<html>
<head>
<title>Welcome</title>
</head>
<body>
<h1>Welcome, <%= request.getParameter("username") %>!</h1>
</body>
</html>
通过这个案例,可以看到Servlet在处理用户请求、验证用户身份以及控制页面跳转等方面的实际应用,它是构建Java Web应用的重要基础组件,在实际开发中还有更多复杂和高级的应用场景等待开发者去探索和实践。
五、总结与展望
Servlet作为Java Web开发的核心技术之一,在服务器端处理请求和生成响应方面有着不可替代的作用。从其基本的工作原理、生命周期到配置使用,再到Servlet 3.0带来的一系列新特性,都为Java Web开发提供了更强大、更灵活的工具。在实际应用中,它广泛应用于各种Web系统的构建,从简单的网站到复杂的企业级应用。随着技术的不断发展,Servlet也在不断演进,未来可能会在性能优化、与新兴技术的融合等方面有更多的突破,开发者需要持续关注其发展动态,以便更好地利用Servlet构建高效、稳定的Web应用。
作者:
代老师的编程课
出处:
https://zthinker.com/
如果你喜欢本文,请长按二维码,关注
Java码界探秘
.