使用golang+antlr4构建一个自己的语言解析器(二)
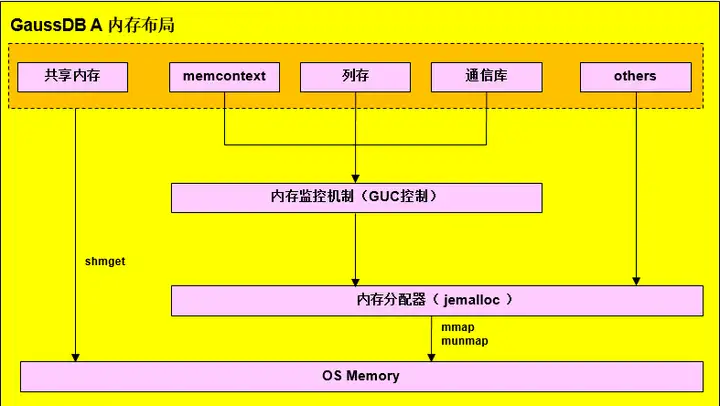
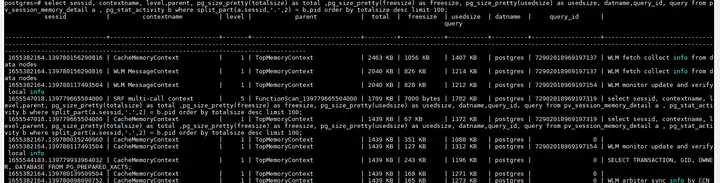
Antlr4文件解析流程

该图展示了一个语言应用程序中的基本流动过程
- 输入一个字符流,首先经过词法分析,获取各个Token
- 然后经过语法分析,组成语法分析树
Antlr4语法书写规范
语法关键字和使用
| 符号 | 作用 |
|---|---|
| ? | 表达式可选 |
| * | 表达式出现0此或多次 |
| + | 表达式至少一次 |
| EOF | 语法结尾 |
| expr expr1 expr2 | 序列模式,由多个表达式或Token组成一个语法规则 |
| expr|expr1|expr2 | 选择模式,指定一个语法规则可以选择多个匹配模式 |
| expr|expr1|expr* | 嵌套模式,自身引用自身 |
处理优先级、左递归和结合性
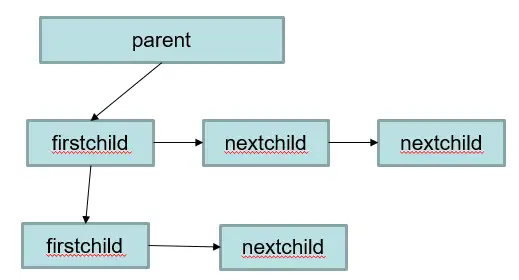
Antlr4默认使用自上而下,默认左递归的方式识别语法, 使用下面一个例子说明左递归的方式
expr:expr '*' expr
|expr '+' expr
|INT
;
输入1+2*3;识别的树为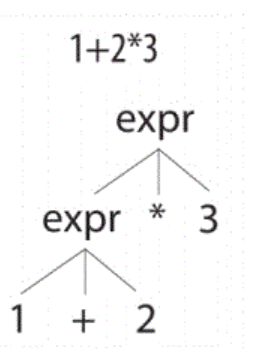
这是因为首先定义了乘法语法规则,然后定义了加法语法规则。
更改左递归的方式
expr:<assoc=right> expr '^' expr
|INT
;
指定第一个expr接受
expr的结果作为结合一个语法规则,输入1
2^3,识别的树为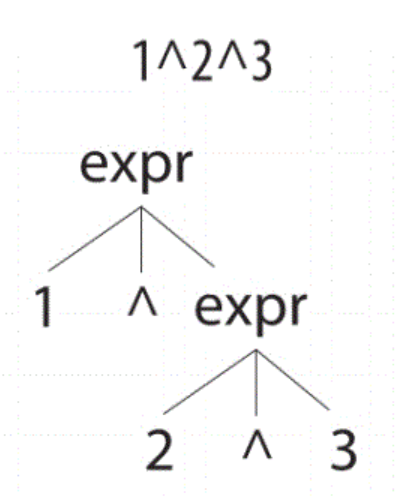
Antlr4的基本命令我们就了解到这,有兴趣研究的小伙伴,可以查看《Antlr4权威指南》这本书。
第一个脚本
避坑指南
使用go mode模式引用antlr4默认是1.X版本,这个是低版本antlr,无法识别最新的antlr语法,使用
go get -u github.com/antlr/antlr4/runtime/Go/antlr/v4
获取antlr4最新版本的golang包
语法文件
我这里使用的IDE是goland,这个大家根据自己的爱好自选就行。
新建文件夹:parser
在parser文件夹下新建文件:Calc.g4
输入一下内容:
grammar Calc;
//Token
MUL: '*';
DIV: '/';
ADD:+;
SUB-';
NUMBER' | [1-9] ('_'? [0-9])*);
WS_NLSEMI:[ \r\n\t]+ -> skip;
//Rule
expression:
expression op = (MUL | DIV) expression #MulDiv
| expression op = (ADD | SUB) expression #AddSub
| NUMBER
start:expression EOF
- g4文件是Antlr4的文件类型
- Token代表定制的语法中的关键字,Token都是全部大写
- Rule是语法规则,由驼峰样式书写,首字母小写,后续每个单词首字母大写
- EOF代表结尾
脚本命令
我们需要使用Antlr4命令生成Go语言的语法树和Listen方式的go文件
$ java -jar 'C:\Program Files\Java\antlr\antlr-4.12.0-complete.jar' -Dlanguage=Go -no-visitor -package parser *.g4
上述命令就是指定使用antlr4将文件目录下所有的.g4文件生成目标语言为Go的语言文件。
执行CMD命令:
cd .\parser\
执行上述命令,我们会在parser文件夹中看到生成了很多文件:
Calc.interp
Calc.tokens
calc_base_listener.go //监听模式基类的文件
calc_lexer.go //文法文件
calc_listener.go //监听模式的文件(定义多少个语法或者自定义类型就会有多少对Enter、Exit方法)
calc_parser.go //识别语法的文件
验证语法
func main(){
is := antlr.NewInputStream("1+1*2")`
lexer := parser.NewCalcLexer(is)
// Read all tokens
for {
t := lexer.NextToken()
if t.GetTokenType() == antlr.TokenEOF {
break
}
fmt.Printf("%s (%q)\n",lexer.SymbolicNames[t.GetTokenType()], t.GetText())
}
}
输入内容:
NUMBER ("1")
ADD ("+")
NUMBER ("1")
MUL ("*")
NUMBER ("2")
证明我们的每个Token都被识别
建立一个四则运算法则
type calcListener struct {
*parser.BaseCalcListener
stack []int
}
func (l *calcListener) push(i int) {
l.stack = append(l.stack, i)
}
func (l *calcListener) pop() int {
if len(l.stack) < 1 {
panic("stack is empty unable to pop")
}
// Get the last value from the stack.
result := l.stack[len(l.stack)-1]
// Remove the last element from the stack.
l.stack = l.stack[:len(l.stack)-1]
return result
}
func (l *calcListener) ExitMulDiv(c *parser.MulDivContext) {
right, left := l.pop(), l.pop()
switch c.GetOp().GetTokenType() {
case parser.CalcParserMUL:
l.push(left * right)
case parser.CalcParserDIV:
l.push(left / right)
default:
panic(fmt.Sprintf("unexpected op: %s", c.GetOp().GetText()))
}
}
func (l *calcListener) ExitAddSub(c *parser.AddSubContext) {
right, left := l.pop(), l.pop()
switch c.GetOp().GetTokenType() {
case parser.CalcParserADD:
l.push(left + right)
case parser.CalcParserSUB:
l.push(left - right)
default:
panic(fmt.Sprintf("unexpected op: %s", c.GetOp().GetText()))
}
}
func (l *calcListener) ExitNumber(c *parser.NumberContext) {
i, err := strconv.Atoi(c.GetText())
if err != nil {
panic(err.Error())
}
l.push(i)
}
func calc(input string) int {
// Setup the input
is := antlr.NewInputStream(input)
// Create the Lexer
lexer := parser.NewCalcLexer(is)
stream := antlr.NewCommonTokenStream(lexer, antlr.TokenDefaultChannel)
// Create the Parser
p := parser.NewCalcParser(stream)
// Finally parse the expression (by walking the tree)
var listener calcListener
antlr.ParseTreeWalkerDefault.Walk(&listener, p.Start())
return listener.pop()
}
func main(){
fmt.Println(calc(1+1*2))
}
至此,我们已经使用antlr4+golang开始自己第一个语法文件使用,接下来就是如何实现我们自定的语法了!!!