内核不中断前提下,Gaussdb(DWS)内存报错排查方法
摘要:
本文主要讲解如何在内核保证操作不能中断采取的特殊处理,理论上用户执行的sql使用的内存(dynamic_used_memory) 是不会大范围的超过max_dynamic_memory的内存的
本文分享自华为云社区《
Gaussdb(DWS)内存报错排查方法
》,作者: fighttingman。
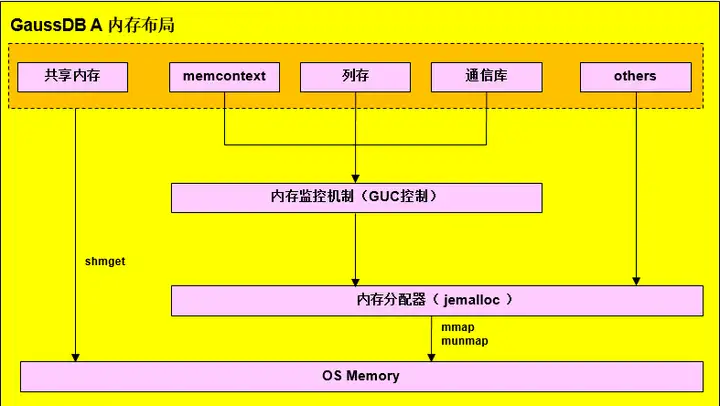
Gaussdb内存布局
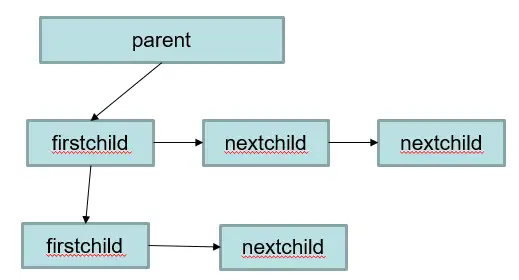
内存上下文memoryContext内存结构
一、内存问题定位方法
分析场景1:数据库日志出现ERROR:memory is temporarily unavailable
从报错信息可以找到是哪个节点的内存不足,例如 dn_6003_6004: memory is temporarily unavailable , 这个就是dn_6003的内存不足了
1.从日志分析
观察对应dn的日志,是否为“reaching the database memory limitation”,表示为数据库的逻辑内存管理机制保护引起,需要进一步分析数据库的视图;若为“reaching the OS memory limitation”,表示为操作系统内存分配失败引起,需要查看操作系统参数配置及内存硬件情况等。
1)reaching the database memory limitation情况实例
----debug_query_id=76279718689098154, memory allocation failed due to reaching the database memory limitation. Current thread is consuming about 10 MB, allocating 240064bytes.----debug_query_id=76279718689098154, Memory information of whole process in MB:max_dynamic_memory: 18770, dynamic_used_memory: 18770, dynamic_peak_memory: 18770, dynamic_used_shrctx: 1804, dynamic_peak_shrctx: 1826, max_sctpcomm_memory: 4000, sctpcomm_used_memory: 1786, sctpcomm_peak_memory: 1786, comm_global_memctx: 0, gpu_max_dynamic_memory: 0, gpu_dynamic_used_memory: 0, gpu_dynamic_peak_memory: 0, large_storage_memory: 0, process_used_memory: 22105, cstore_used_memory: 1022, shared_used_memory: 2605, other_used_memory: 0, os_totalmem: 257906, os_freemem: 16762.
此时,作业76279718689098154准备申请240064 bytes内存,dynamic_used_memory内存值为18770MB,二者之和大于max_dynamic_memory(18770MB),超出数据库限制,内存申请失败。
在811之后的版本还会打印top3的memoryContext内存占用,示例如下
----debug_query_id=72339069014641088, sessId: 1670914731.140604465997568.coordinator1, sessType: postgres, contextName: ExprContext, level: 5, parent: FunctionScan_140604465997568, totalSize: 950010640, freeSize: 0, usedSize: 950010640 ----debug_query_id=72339069014641053, pid=140604465997568, application_name=gsql, query=select * from pv_total_memory_detail, state=retrying, query_start=2022-12-13 14:59:22.059805+08, enqueue=no waiting queue, connection_info={"driver_name":"gsql","driver_version":"(GaussDB 8.2.0 build bc4cec20) compiled at 2022-12-13 14:45:14 commit 3629 last mr 5138 debug","driver_path":"/data3/x00574567/self/gaussdb/mppdb_temp_install/bin/gsql","os_user":"x00574567"}----debug_query_id=72339069014641088, sessId: 1670914731.140604738627328.coordinator1, sessType: postgres, contextName: ExprContext, level: 5, parent: FunctionScan_140604738627328, totalSize: 900010080, freeSize: 0, usedSize: 900010080 ----debug_query_id=72339069014641057, pid=140604738627328, application_name=gsql, query=select * from pv_total_memory_detail, state=retrying, query_start=2022-12-13 14:59:22.098775+08, enqueue=no waiting queue, connection_info={"driver_name":"gsql","driver_version":"(GaussDB 8.2.0 build bc4cec20) compiled at 2022-12-13 14:45:14 commit 3629 last mr 5138 debug","driver_path":"/data3/x00574567/self/gaussdb/mppdb_temp_install/bin/gsql","os_user":"x00574567"}----debug_query_id=72339069014641088, sessId: 1670914731.140603779163904.coordinator1, sessType: postgres, contextName: ExprContext, level: 5, parent: FunctionScan_140603779163904, totalSize: 890009968, freeSize: 0, usedSize: 890009968 ----debug_query_id=72339069014641058, pid=140603779163904, application_name=gsql, query=select * from pv_total_memory_detail, state=retrying, query_start=2022-12-13 14:59:22.117463+08, enqueue=no waiting queue, connection_info={"driver_name":"gsql","driver_version":"(GaussDB 8.2.0 build bc4cec20) compiled at 2022-12-13 14:45:14 commit 3629 last mr 5138 debug","driver_path":"/data3/x00574567/self/gaussdb/mppdb_temp_install/bin/gsql","os_user":"x00574567"}----allBackendSize=34, idleSize=7, runningSize=7, retryingSize=20
重要字段解释:
sessId:线程启动时间+线程标识(字符串信息为timestamp.threadid)
sessType:线程名称
contextName:memoryContext名字
totalSize:内存占用大小,单位Byte
freeSize:当前memoryContext释放内存总数,单位Byte
usedSize:当前memoryContext已使用的内存总数,单位Byte
application_name:连接到该后端的应用名
query:查询语句
enqueue:排队情况
allBackendSize:总线程个数,idleSize:idle线程个数,runningSize:活跃的线程个数,retryingSize:重试的线程个数
数据库还会在复杂作业中进行检查,查看复杂作业预估内存是否超过实际使用内存,如果存在,则打印下列信息,供分析。
----debug_query_id=76279718689098154, Total estimated Memory is 15196 MB, total current cost Memory is 16454 MB, the difference is 1258 MB.The count of complicated queries is 17 and the count of uncontrolled queries is 1.
上述信息表示全部复杂作业预计使用内存15196 MB,实际使用16454 MB,超出1258 MB。
复杂作业共17个,其中有1个作业实际使用内存超过预计内存。
----debug_query_id=76279718689098154, The abnormal query thread id 140664667547392.It current used memory is 13618 MB and estimated memory is 1102 MB.It also is the query which costs the maximum memory.
上述信息表示,异常线程id为140664667547392,该线程预估消耗内存1102MB,实际消耗13618MB。
----debug_query_id=76279718689098154, It is not the current session and beentry info : datid<16389>, app_name<cn_5001>, query_id<76279718688746485>, tid<140664667547392>, lwtid<173496>, parent_tid<0>, thread_level<0>, query_string<explainperformance with ws as (select d_year AS ws_sold_year, ws_item_sk, ws_bill_customer_sk ws_customer_sk, sum(ws_quantity) ws_qty, sum(ws_wholesale_cost) ws_wc, sum(ws_sales_price) ws_sp from web_sales left join web_returns on wr_order_number=ws_order_number and ws_item_sk=wr_item_sk join date_dim on ws_sold_date_sk = d_date_sk where wr_order_number is null group by d_year, ws_item_sk, ws_bill_customer_sk ), cs as (select d_year AS cs_sold_year, cs_item_sk, cs_bill_customer_sk cs_customer_sk, sum(cs_quantity) cs_qty, sum(cs_wholesale_cost) cs_wc, sum(cs_sales_price) cs_sp from catalog_sales left join catalog_returns on cr_order_number=cs_order_number and cs_item_sk=cr_item_sk join date_dim on cs_sold_date_sk =d_date_sk where cr_order_number is null group by d_year, cs_item_sk, cs_bill_customer_sk ), ss as (select d_year AS ss_sold_year, ss_item_sk, ss_customer_sk, sum(ss_quantity) ss_qty, sum(ss_wholesale_cost) ss_wc, sum(ss_sales_price) ss_spfrom store_sales left join store_returns on sr_ticket_numbe>.
上述信息进一步显示内存使用超过预估内存的作业信息的sql信息,其中datid表示数据库的OID,app_name表示application name,query_string表示查询sql。----debug_query_id=76279718689098154, WARNING: the common memory context 'HashContext' is using 1059 MB size larger than 989 MB.----debug_query_id=76279718689098154, WARNING: the common memory context 'VecHashJoin_76279718688746485_6' is using 12359 MB size larger than 10 MB.
上述信息表示超限的memcontext,76279718689098154号查询中,memory context预设值的最大值为989MB,实际使用了1059 MB。2)reaching the OS memory limitation
当GaussDB内存使用符合GUC中相关参数限制,但操作系统可用内存不足时,会出现与1.1中类似的日志信息,格式如下
----debug_query_id=%lu, FATAL: memory allocation failed due to reaching the OS memory limitation. Current thread is consuming about %d MB, allocating %ld bytes.----debug_query_id=%lu, Please check the sysctl configuration and GUC variable max_process_memory.----debug_query_id=%lu, Memory information of whole process in MB:" "max_dynamic_memory: %d, dynamic_used_memory: %d, dynamic_peak_memory: %d, dynamic_used_shrctx: %d,
dynamic_peak_shrctx:%d, max_sctpcomm_memory: %d,
sctpcomm_used_memory:%d, sctpcomm_peak_memory: %d,
comm_global_memctx:%d, gpu_max_dynamic_memory: %d,
gpu_dynamic_used_memory:%d,
gpu_dynamic_peak_memory:%d, large_storage_memory: %d,
process_used_memory:%d, cstore_used_memory: %d,
shared_used_memory:%d, other_used_memory: %d,
os_totalmem:%d, os_freemem: %d
其中,os_totalmem是当前OS中的总内存,即“free”命令中的total信息。os_freemem是当前OS中的可用内存,即“free”命令中的free信息。
第一条日志中“allocating %ld bytes”中的待申请的内存大于第三条日志中“os_freemem”项,且数据库可运行,无其他异常,则符合预期,说明OS内存不足。
2. 实例每个实例的内存使用情况,查询pgxc_total_memory_detail
内存报错后,语句使用的内存就会释放,当时占用内存高的语句可能会因为报错,导致现场没有了,查询内存视图查询不到的情况
with a as (select *from pgxc_total_memory_detail where memorytype='dynamic_used_memory'), b as(select * from pgxc_total_memory_detail wherememorytype='dynamic_peak_memory'), c as (select * from pgxc_total_memory_detailwhere memorytype='max_dynamic_memory'), d as (select * frompgxc_total_memory_detail where memorytype='process_used_memory'), e as (select* from pgxc_total_memory_detail where memorytype='other_used_memory'), f as(select * from pgxc_total_memory_detail where memorytype='max_process_memory')select a.nodename,a.memorymbytes as dynamic_used_memory,b.memorymbytes asdynamic_peak_memory,c.memorymbytes as max_dynamic_memory,d.memorymbytes asprocess_used_memory,e.memorymbytes as other_used_memory,f.memorymbytes asmax_process_memory from a,b,c,d,e,f where a.nodename=b.nodename andb.nodename=c.nodename and c.nodename=d.nodename and d.nodename=e.nodename ande.nodename=f.nodename order by a.nodename;

在查询这个视图也有可能会因为内存不足报memory is temporarily unavailable,导致视图查不出来,此时需要将disable_memory_protect设置为off。
set disable_memory_protect=off; 之后在查询视图就不会报错。
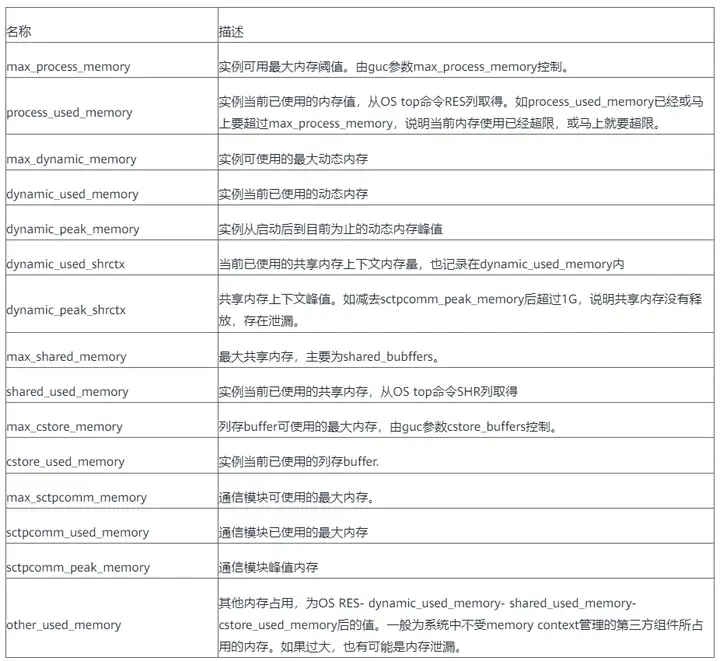
通过上边这视图可以找到集群中哪个节点的内存使用有异常,之后连接那个节点通过pv_session_memory_detail视图找到有问题的memorycontext。
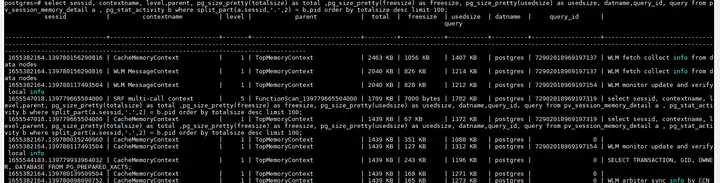
SELECT * FROM pv_session_memory_detail ORDER BY totalsize desc LIMIT 100;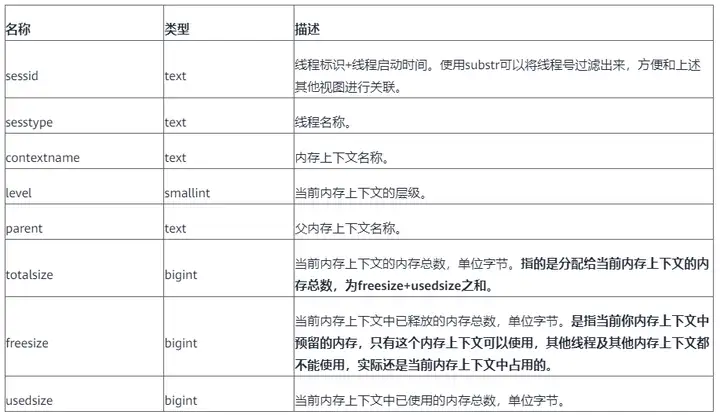
结合pg_stat_activity视图可以找到哪个语句使用的memcontext最多。
select sessid, contextname, level,parent, pg_size_pretty(totalsize) as total ,pg_size_pretty(freesize) as freesize, pg_size_pretty(usedsize) as usedsize, datname,query_id, query from pv_session_memory_detail a , pg_stat_activity b where split_part(a.sessid,'.',2) = b.pid order by totalsize desc limit 100;
紧急恢复
EXECUTE DIRECT ON(cn_5001) 'SELECT pg_terminate_backend(139780156290816)';
二、内存占用高的场景分析
1.空闲连接过多导致内存占用
先确认是哪个实例的内存占用高,确认方法如上查询pgxc_total_memory_detail,之后连上那个cn或者dn查询如下sql
select b.state, sum(totalsize) as totalsize, sum(freesize) as freesize, sum(usedsize) as usedsize from pv_session_memory_detail a , pg_stat_activity b where split_part(a.sessid,'.',2) = b.pid group by b.state order by totalsize desc limit 100;
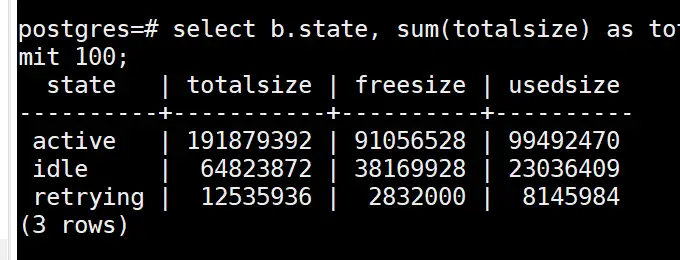
如果是上图的idle状态的totalsize占用很多内存,可以尝试清理idle状态的空闲连接释放内存
解决措施:清理idle状态的空闲连接
CLEAN CONNECTION TO ALL FORCE FOR DATABASE xxxx;
clean connection 只能清理pg_pooler_status中 in_used是f状态的空闲连接,不能清理in_used状态为t的连接,in_used为t 一般是执行了pbe语句导致cn和dn的空闲连接不能释放导致
如果上边方法清理不掉,只能尝试清理cn和客户端的连接,之后在执行clean connection清理cn和dn之间的连接,可以尝试在cn上找到是idle状态的空闲连接,此操作会断掉cn和客户端的连接,需要和客户确认是否可以执行
select 'execute direct on ('||coorname||')''select pg_terminate_backend('||pid||')'';' from pgxc_stat_activity where usename not in ('Ruby', 'omm') and state='idle';
将select的结果依次执行。2.语句占用内存过多,如果第一个步骤中的第一个语句查询的是active状态的语句内存占用多,说明是正在执行语句占用的内存多导致的
查询下边的语句找到内存占用多的语句
select b.state as state, a.sessid as sessid, b.query_id as query_id, substr(b.query,1,100) as query, sum(totalsize) as totalsize, sum(freesize) as freesize, sum(usedsize) as usedsize from pv_session_memory_detail a , pg_stat_activity b where split_part(a.sessid,'.',2) = b.pid and usename not in ('Ruby', 'omm') group by state,sessid,query_id,query order by totalsize desc limit 100;
找到语句后,根据query_id去对应的cn上进行查杀这个异常sql3.dynamic_used_shrctx内存使用较多
dynamic_used_shrctx是共享内存上下文使用的内存,也是通过MemoryContext分的,在线程之间共享。通过pg_shared_memory_detail视图查看
select * from pg_shared_memory_detail order by totalsize desc limit 10;
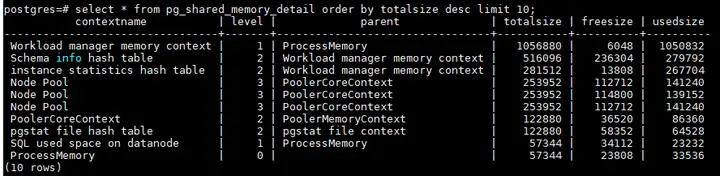
一般共享内存上下文分配和语句有关的, contextname都会带有线程号或者query_id,根据query_id或者线程号进行查杀异常sql,除此之外共享内存上下文一般是内核中各个模块使用的内存,比如topsql,需要排查内存使用是否合理,以及释放机制。
4. 内存视图pv_total_memory_detail 中,dynamic_used_memory > max_dynamic_memory的情况
1)GUC参数disable_memory_protect为on的时候
2)分配内存的时候,debug_query_id为0
3)内核在执行关键代码段的时候
4)内核Postmaster线程内的内存分配
5)在事务回滚阶段
以上情况都是内核保证操作不能中断采取的特殊处理,理论上用户执行的sql使用的内存(dynamic_used_memory) 是不会大范围的超过max_dynamic_memory的内存的